Под термином “клиент” будем понимать зону ответственности за совокупность сетевых устройств.
Требуется обеспечить доступ для нескольких сотен клиентов к неким общим ресурсам в таком режиме, чтобы:
- Каждый клиент не видел трафик остальных клиентов.
- Неисправности одного клиента (broadcast-storm, конфликты IP-адресов, не санкционированные DHCP-сервера клиента и т.п.) не должны влиять на работу как других клиентов, так и всей системы в целом.
- Каждый клиент не должен напрямую получать доступ к ресурсам других клиентов (хотя, как специальный случай, можно предусмотреть и разрешение данного трафика, но с его централизованным контролем и/или управлением ).
- Клиенты должны иметь возможность получения доступа к общим внешним ресурсам (которыми могут быть как отдельные сервера, так и сеть Интернет в целом).
- Общие ресурсы должны также иметь возможность доступа к ресурсам клиентов (конечно при условии, что известен общему ресурсу известен IP-адрес ресурса клиента).
- Адресное пространство для клиентов выделяется централизованно и его администрирование не должно быть чрезмерно сложным.
В качестве примеров практического применения можно назвать изоляцию локальных сетей отделов в крупной организации, организацию VoIP-связи или доступа в сеть Интернет для нескольких независимых потребителей и т.п.
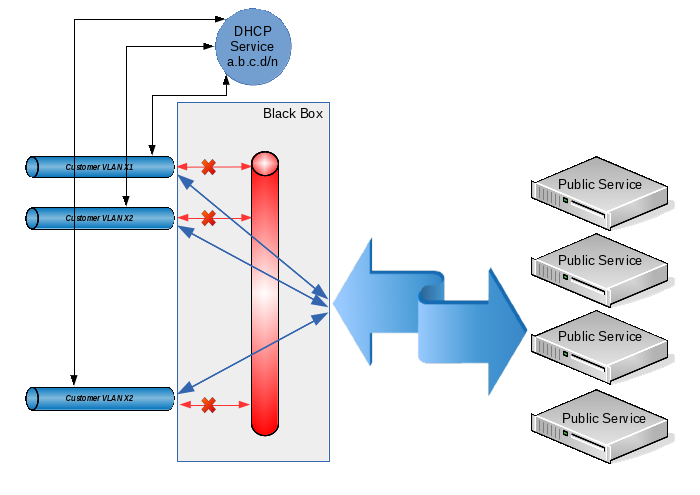
Условия 1 и 2 достигаются выделением каждому клиенту собственного VLAN. Условия 3-5 можно выполнить путем объединения клиентских VLAN с запретом прямой передачи трафика между ними. В некоторых источниках эта технология называется “private VLAN”, в некоторых “port isolation”, а смысл ее такой: из каждого клиентского VLAN можно беспрепятственно попасть в некий общий VLAN (и, соответственно, обратно), но вот между клиентскими VLAN передача трафика запрещена. Ну а для выполнения условия 6 выделим для всех клиентов общее адресное пространство вида 10.12.8.0/23, а конкретные IP-адреса будем выдавать по запросу при помощи DHCP.
Таким образом, при появлении у клиента нового устройства адрес для него будет выдан автоматически (и у нас не будет проблем из-за того, что один клиент может использовать для своих нужд единицы IP-адресов, а другому потребуются их десятки или сотни), а при добавлении нового клиента мы просто создадим еще один VLAN и добавим его в нашу общую группу. Даже если из-за большого количества клиентских устройств первоначально выделенное нами адресное пространство будет исчерпано, то мы всегда сможем его расширить, изменив настройки всего в двух местах (на DHCP-сервере и на интерфейсе, который объединяет все клиентские VLAN).
Технически описанное выше решение можно реализовать только аппаратными средствами на коммутаторах уровня L3 или программно-аппаратными средствами на коммутаторах уровня L2 (лишь бы они понимали 802.1q) и каком-либо компьютере с linux-подобной операционной системой. Так как у меня уже был сервер (являющийся, к тому же, целевым для клиентов), то логично было бы остановиться на аппаратно-программном варианте.
Итак, программируем коммутатор таким образом, чтобы на каждом клиентском VLAN был один физический порт коммутатора в “access mode”, и один общий порт в режиме 802.1q (к этому порту будет подключаться наш сервер). Подробно технология настройки не расписывается, т.к. она достаточно тривиальна и зависит от конкретной модели используемого коммутатора.
Далее приступаем к созданию конфигурации для сервера. Пусть физический интерфейс, который подключается к порту 802.1q коммутатора, имеет имя eth0. Для моей конкретной задачи понадобилось 200 клиентских VLAN с VLAN ID от 600 до 799 включительно, так что будем их создавать:
Общая настройка видов имен VLAN-интерфейсов. Я хочу, чтобы имена VLAN-интерфейсов имели вид “vlanXXX”, где XXX — VLAN ID:
vconfig set_name_type VLAN_PLUS_VID_NO_PAD
Непосредственно создаем VLAN на базе интерфейса eth0:
vconfig add eth0 600 ifconfig vlan600 up vconfig add eth0 601 ifconfig vlan601 up … vconfig add eth0 799 ifconfig vlan799 up
Создаем бридж, в который будем объединять созданные vlan:
brctl addbr br1 ifconfig br1 up
Объединяем созданные интерфейсы в бридж:
brctl addif br1 vlan600 brctl addif br1 vlan601 … brctl addif br1 vlan799
Теперь прописываем на интерфейс br1 адрес, который будет выступать для всех наших клиентов в качестве шлюза по умолчанию:
ifconfig br1 10.12.8.1/23
И запрещаем трафик между клиентскими VLAN средствами ebtables:
ebtables -A FORWARD --logical-in br1 --logical-out br1 -j DROP
(в данном случае используется таблица ebtables ‘filter’, запрещающая передачу трафика между интерфейсами, входящими в бридж в виде логических портов). Если все-таки необходимо разрешить возможность передачи трафика между клиентами под нашим контролем (см. п. 3 техзадания), то вместо вышеприведенного правила устанавливаем следующие:
ebtables -t broute -A BROUTING -p ipv4 --logical-in -j DROP ebtables -t broute -A BROUTING -p arp --logical-in -j DROP
Здесь мы работаем с таблицей ‘broute’. В ней не стандартные действия для целей ACCEPT и DROP. Цель ACCEPT разрешает форвардинг трафика с заданными условиями (т.е. трафик передается на уровне L2), а цель DROP запрещает форвардинг трафика и обеспечивает его передачу на роутинг (и, соответственно, мы сможем им управлять посредством iptables). Однако т.к. все адреса принадлежат одной IP-подсети но могут находиться в разных клиентских VLAN, на интерфейсе br1 необходимо будет разрешить arp proxy:
sysctl -w net.ipv4.conf.br1.proxy_arp=1
Замечу, что у меня не не стояло задачи пропуска трафика между клиентами, поэтому описанное выше расширение чисто умозрительное и на практике не проверялось!
Осталось только настроить сервер DHCP и поселить его на интерфейс br1. Эта операция также тривиальна, поэтому в рамках данной статьи не описывается.
Ну что, все работает? А вот как бы не так:
# tcpdump -e -v -n -i br1 udp port 67 or port 68
tcpdump: listening on br1, link-type EN10MB (Ethernet), capture size 65535 bytes
14:26:38.164169 00:0b:82:3b:9c:96 > ff:ff:ff:ff:ff:ff, ethertype IPv4 (0x0800), length 590: (tos 0x0, ttl 64, id 0, offset 0, flags [none], proto UDP (17), length 576)
0.0.0.0.68 > 255.255.255.255.67: BOOTP/DHCP, Request from 00:0b:82:3b:9c:96, length 548, xid 0x3c12d61a, Flags [none]
Client-Ethernet-Address 00:0b:82:3b:9c:96
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: Discover
Client-ID Option 61, length 7: ether 00:0b:82:3b:9c:96
Vendor-Class Option 60, length 16: "GXV dslforum.org"
T125 Option 125, length 36: 3561,520160816,808469048,838994992,808469048,842220089,1127822851,122116182,858862640
Parameter-Request Option 55, length 11:
Subnet-Mask, Time-Zone, Default-Gateway, Domain-Name-Server
Hostname, Domain-Name, BR, NTP
Vendor-Option, TFTP, Option 125
14:26:38.171041 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype IPv4 (0x0800), length 336: (tos 0x0, ttl 64, id 0, offset 0, flags [none], proto UDP (17), length 322)
10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294, xid 0x3c12d61a, Flags [none]
Your-IP 10.12.8.200
Client-Ethernet-Address 00:0b:82:3b:9c:96
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: Offer
Server-ID Option 54, length 4: 10.12.8.1
Lease-Time Option 51, length 4: 7200
Subnet-Mask Option 1, length 4: 255.255.254.0
Default-Gateway Option 3, length 4: 10.12.8.1
Здесь все нормально: получили один broadcast запрос DHCPDISCOVER, ответили одним broadcast-ответом DHCPOFFER.
А теперь давайте посмотрим, что происходит на физическом интерфейсе:
# tcpdump -e -n -i eth0 udp port 67 or port 68 tcpdump: WARNING: eth0: no IPv4 address assigned tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes 14:31:07.829289 00:0b:82:3b:9c:96 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 594: vlan 603, p 0, ethertype IPv4, 0.0.0.0.68 > 255.255.255.255.67: BOOTP/DHCP, Request from 00:0b:82:3b:9c:96, length 548 14:31:07.834962 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 799, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834966 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 798, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834968 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 797, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834970 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 796, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834972 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 795, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834974 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 794, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834976 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 793, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 14:31:07.834978 00:25:90:d3:5e:fa > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 340: vlan 792, p 0, ethertype IPv4, 10.12.8.1.67 > 255.255.255.255.68: BOOTP/DHCP, Reply, length 294 …
Что произошло? Да все, как мы сконфигурировали:
- DHCPDISCOVER был получен с VLAN 603;
- запрос был передан через интерфейс br1 нашему серверу DHCP;
- сервер в ответ на него передал на интерфейс br1 ответ DHCPOFFER;
- интерфейс br1 размножил этот ответ (т.к. он, по стандарту DHCP, является broadcast как по уровню L3, так и по уровню L2) по всем клиентским VLAN.
Мало того, что мы засветили всем клиентам MAC/IP адреса одного из них, так еще и вдобавок получили не хилый broadcast storm на физический коммутатор. Кстати, от такого шторма у некоторых коммутаторов просто едет крыша: работающий у нас QTECH не только не смог пропустить broadcast на все заявленные 200 клиентских VLAN (т.е. конечный клиент с произвольной вероятностью либо получал свой адрес от DHCP сервера, либо не дожидался от него вообще никакого ответа), но и даже забыл таблицу известных ему MAC-адресов (во всяком случае в консоли он показывал только один MAC-адрес для всех портов). А вот коммутатор ASOTEL справлялся с такой нагрузкой и клиенты могли получить адреса от нашего DHCP-сервера.
Ну ладно, будем исправлять ситуацию. Надо заставить сервер посылать broadcast только в тот VLAN, от которого пришел первоначальный запрос, а не размножать его по всем доступным местам.
Модуля трекинга DHCP broadcast-ов я не нашел. Как выяснилось позднее, он бы в данном случае все равно не помог, т.к. broadcast-ответ DHCP-сервером формируется при помощи системного вызова
socket(PF_PACKET, SOCK_DGRAM, htons(ETH_P_IP))
который не проходит ни через одну из таблиц ebtables или iptables. Т.е. если входящие broadcast отловить еще можно, то вот ответы передаются драйверу минуя стек протоколов. И это логично: если уж мы сами формируем ethernet-заголовок, то какой смысл дополнительно обрабатывать его средствами ядра?
Ладно, попробуем повесить на каждый клиентский VLAN по DHCP Relay Agent и уже запросы от него передавать на обработку DHCP серверу. Однако оказалось, что Relay Agent не отлавливает запросы от интерфейсов, входящих в бридж (ну это тоже, наверное, логично). Стоило убрать интерфейс из бриджа, как Relay Agent начинал вылавливать запросы, передавать их серверу и отсылать ответы обратно в тот VLAN, в который нужно. При повторном добавлении VLAN в бридж работоспособность агента опять нарушалась и DHCP становился недоступным для клиентов.
“Ну ладно!” — сказали суровые сибирские мужики. Будем делать все по-взрослому.
Для начала вспомним, что в современных linux-ядрах есть такие вкусности, как Virtual Ethernet Device (из них можно делать хорошие pipes для перегонки ethernet-трафика внутри нашего компьютера) и Network Namespace (средство для изоляции сетевого стека. В аппаратных маршрутизаторах это, обычно, называется VRF). В принципе для данной задачи можно обойтись исключительно Virtual Ethernet (veth), но для красоты решения (и упрощения связки DHCP Server — DHCP Relay Agent) будем использовать также и Network Namespace (netns).
После инициализации сети в linux по умолчанию имеется только один root netns, в котором находится единственная копия сетевого стека, таблицы маршрутизации, интерфейсы и т.п. В дальнейшем описании для определенности будем использовать следующую терминологию:
Network Namespace назовем “слоем” (layer);
root netns назовем слоем “backplate” (хотя в реальности этот netns имеет имя в виде пустой строки);
Идея у нас такая:
каждый клиентский VLAN добавляем в отдельный bridge, на интерфейс которого будем вешать DHCP Relay Agent. Через этот интерфейс клиенты смогут посылать broadcast-запросы агенту и принимать от него broadcast-ответы.
из каждого клиентского bridge сделаем ethernet pipe до нашего основного br1. Через связку “customer vlan”-”customer vlan bridge”-”virtual ethernet”-”br1” будет проходить полезный трафик между клиентским сервисом и общими внешними ресурсами.
Сам DHCP Relay Agent живет в одном экземпляре (он может слушать несколько клиентских интерфейсов) на специальном ethernet pipe, на другой стороне которого находится наш DHCP Server.
весь прикладной уровень (т.е. все, что не касается DHCP), расположим на уровне backplate;
все, что связано с DHCP Relay Agent, расположим на уровне с именем “relay”;
собственно сервер DHCP должен быть доступен как для DHCP Relay Agent (для обработки сообщений, распространяемых в виде broadcast и преобразуемых агентом в unicast и обратно), а также непосредственно для клиентов DHCP (для обработки специального случая: сообщения DHCPRELEASE, отправляемого unicast клиентом напрямую тому DHCP-серверу, который выдавал этот адрес).
С учетом данных требований сам DHCP-сервер расположим на уровне backplate на интерфейсе br1, но для предотвращения приема им broadcast-запросов от конечных клиентом на интерфейс будут наложены специальные фильтры.
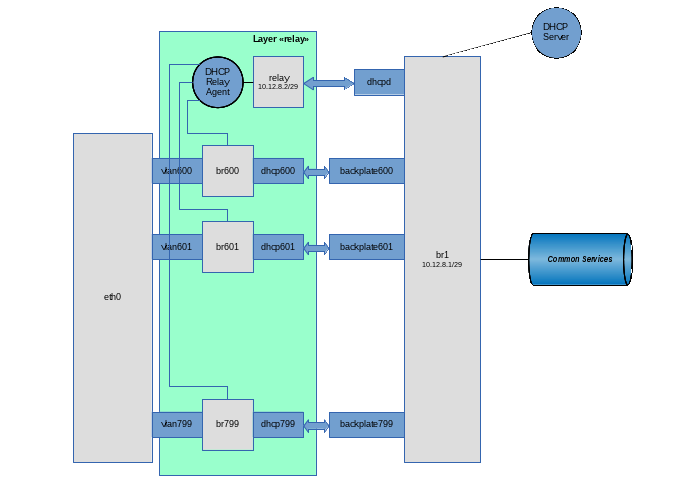
Ну, поехали… Создаем слой “relay”
ip netns add relay
Создаем на слое backplate виртуальный pipe, предназначенный для общения DHCP Relay Agent и DHCP Server:
ip link add relay type veth peer name dhcpd
Переносим хвост dhcpd (интерфейс, на котором будет работать Relay Agent) в слой relay:
ip link set dhcpd netns relay
Настраиваем в слое relay интерфейс dhcpd:
ip netns exec relay ifconfig dhcpd 10.12.8.2/23 ip netns exec relay ifconfig dhcpd up
Создаем наш основной бридж br1:
brctl addbr br1
Пусть этот бридж работает как умный коммутатор (т.е. хранит у себя таблицу MAC-адресов и выполняет форвардинг на конкретный порт в зависимости от наличия на нем целевого адреса). Для этого устанавливаем время обучения равным 30 секундам:
brctl setfd br1 30
Ну и клиенты — личности своеобразные, вполне могут и кольца сотворить. Ежели кто этим и займется, то пусть страдает сам, не затрагивая при этом других. Т.е. запустим на нашем виртуальном коммутаторе STP:
brctl stp br1 on
Т.к. этот бридж является также шлюзом по умолчанию для клиентов, то повесим на него IP-адрес (вместе с сеткой) и поднимем непосредственно сам интерфейс:
ifconfig br1 10.12.8.1/23 ifconfig br1 up
Добавляем в бридж интерфейс, по которому DHCP сервер будет общаться с агентом:
brctl addif br1 relay
Запрещаем трафик между клиентскими VLAN средствами ebtables:
ebtables -A FORWARD --logical-in br1 --logical-out br1 -j DROP
Запрещаем обработку DHCP-сервером broadcast-запросов (они должны вылавливаться агентом и отсылаться серверу в виде unicast):
ebtables -A INPUT --logical-in br1 --pkttype-type broadcast --protocol IPv4 --ip-protocol udp --ip-destination-port 67 -j DROP
Для подстраховки разрешаем использование адреса, выделенного для DHCP Relay Agent только на интерфейсе с именем relay:
ebtables -A INPUT --in-interface ! relay --protocol IPv4 --ip-source 10.12.8.2/32 -j DROP
Ладно, последний мазок. Так как я категорически не доверяю клиентам, заставим ядро убеждаться в том, что приходящие от них IP-пакеты имеют source address вида 10.12.8.0/23 (а не, к примеру, 192.168.1.1). Для этого включаем на интерфейсе rp filter:
sysctl -w net.ipv4.conf.br1.rp_filter=1
Физический интерфейс eth0 мы не будем переносить с backplate на слой relay (ну, допустим, нам надо будет повесить на него еще какие-то application VLANs, не имеющие отношения к данной схеме). Поэтому мы будем сначала создавать VLAN-интерфейсы на слое backplate, а потом переносить их в слой relay:
Общая настройка видов имен VLAN-интерфейсов. Я хочу, чтобы имена VLAN-интерфейсов имели вид “vlanXXX”, где XXX — VLAN ID:
vconfig set_name_type VLAN_PLUS_VID_NO_PAD
Непосредственно создаем VLAN на базе интерфейса eth0:
vconfig add eth0 600
Переносим созданный интерфейс vlan600 из слоя backplate в слой relay:
ip link set vlan600 netns relay
Поднимаем интерфейс vlan600, но уже в слое relay:
ip netns exec relay ifconfig vlan600 up
Создаем в слое relay бридж для данного клиентского VLAN (на который будем вешать DHCP Relay Agent).
ip netns exec relay brctl addbr br600
Мы хотим, чтобы этот бридж работал в качестве хаба (т.е. выполнял бы трансляцию пакета сразу же после его получения, не используя период сбора информации о MAC-адресах). Для этого до момента добавления первого интерфейса в бридж устанавливаем его параметры:
ip netns exec relay brctl setfd br600 0
Кроме того, STP на данном бридже нам явно не нужен:
ip netns exec relay brctl stp br600 off
Поднимаем интерфейс бриджа:
ip netns exec relay ifconfig br600 up
И добавляем в него клиентский VLAN:
ip netns exec relay brctl addif br600 vlan600
Создаем на слое backplate (ну все равно он туда придет) ethernet pipe для связки клиентского бриджа br600 и нашего основного бриджа br1:
ip link add dhcp600 type veth peer name backplate600
Переносим второй конец pipe в слой relay:
ip link set backplate600 netns relay
И добавляем этот конец трубы в бридж:
ip netns exec relay brctl addif br600 backplate600
Ну и добавляем конец pipe, оставшийся в слое backplate, в бридж br1:
brctl addif br1 dhcp600
Повторяем в цикле операции создания клиентских VLAN в нужном количестве.
Теперь достаточно запустить сам DHCP сервер в слое backplate и DHCP Relay Agent в слое relay. В моем случае используется сборка из BusyBox, что в данном случае не критично. Использование ISC агента и сервера не должно вызвать больших затруднений.
Итак, запускаем агента. В качестве клиентских интерфейсов используются br600-br799, в качестве интерфейса для связи с DHCP-сервером используется интерфейс dhcpd, а сам DHCP сервер имеет адрес 10.12.8.1:
ip netns exec relay /usr/sbin/dhcprelay br600,br601,...,br799 dhcpd 10.12.8.1
Ну и, наконец, запускаем DHCP сервер:
/usr/sbin/udhcpd /etc/udhcpd.conf
В файле /etc/udhcpd.conf единственная строчка, которая относится к данной схеме:
# Имя интерфейса, на котором у нас живет сервер DHCP interface br1
Все, теперь broadcast-запросы в пользовательском VLAN отлавливаются DHCP Relay Agent через соответствующий br-интерфейс, после чего запрос unicast-ом передается на серверу через интерфейс dhcpd. Сервер отсылает unicast-ответ через интерфейс relay, который агент получает из интерфейса dhcpd и транслирует broadcast-ом в исходный VLAN.
Клиенты стали получать адреса через DHCP, broadcast-storm исчез. И клиент может послать DHCPRELEASE непосредственно серверу на адрес 10.12.8.1
Copiright 2015 by Vedga. Копирование текста на другие ресурсы без согласия автора запрещено.
Что посмотреть к этой статье:
Комментарии (30)

ibKpoxa
06.10.2015 18:21А зачем использовать relay agent, если linux используется для терминации влано, а в этом случае на нем прекрасно запускается dhcpd и слушает все нужные вланы? Все работает с конфигами в раз 10 меньшего размера, соответственно меньше шансов на ошибку.

Vedga
06.10.2015 18:27На каждый VLAN вешать свою подсеть со своим default gateway. Разруливать маршрутизацию iptables. При добавлении vlan добавлять еще одну подсеть. Точно проще будет?

evg_krsk
06.10.2015 18:31+1Разбираться — точно проще. В т.ч. и самому после пары лет безпроблемной работы :-)
Просто я такого наслышался: «Досталось мне тут в наследство...». Ведь правильный дизайн он ещё и по возможности простой, в т.ч. и для понимания.Vedga
06.10.2015 20:04Вот я спрашиваю: дизайн с кучей сетей, соответствующими правилами в firewall, с периодическим добавлением/удалением сетей будет проще? Здесь единственный входной параметр: кол-во требуемых VLAN, все остальное может быть создано скриптом с единственным циклом, который создает интерфейсы и добавляет их в бридж.
evg_krsk
06.10.2015 18:28Роутер/L3-свитч с маршрутизацией между вланами и фильтрацией трафика? Провизить оборудование атрибутами DHCP (давая ссылка на сервер телефонии). Адресация меняется путём измнения IP/mask и DHCP-пула на устройстве. dot1q-сабинтерфейсы добавляются/удаляются там же. При умирании устройства бэкап конфига заливается на ЗИП. Вроде все шесть условий выполняются.
Vedga
06.10.2015 19:58Так я же и говорю: «или чисто аппаратное решение на коммутаторе L3, или аппаратно-программное решение на коммутаторе с (как минимум) поддержкой 802.1q». Второе выбрал в том числе и потому, что система встраиваемая, и вся эта логика зашивается более-менее жестко. В моем случае конфигурация вообще создается скриптами, а входным параметром является единственное число — кол-во необходимых VLAN. Соответственно требование к обвязке снижается до L2-коммутатора и админа-школьника, способного прописать на нем VLAN-ы.
evg_krsk
06.10.2015 20:48+1Каждому своё.
Вам проще сделать сложный конфиг сервера и отдать сетевику контроль над голым L2 (который тоже не так то прост). Я же предпочту отдать сетевику сеть (и поставлю для этого железку для коммутации/маршрутизации вместо L2-коммутатора, раз уж он у вас по сути не коммутирует вне влана), разумной сложности, а админу сервера админскую работу (пусть сделает простой и понятный конфиг tftp или через что там провизятся железки).
А конфигурацию к сетевому железу тоже со временем начинаешь генерировать, а не мышой щёлкать :-)

Ptica79
06.10.2015 20:29+4Не понял зачем было городить такой огород о_О.
У большинства управляемых свитчей L2 уровня всё это уже есть.
Блокировка трафика между пользователями у D-Link называется traffic_segmentation. У остальных (эджкоры, тп-линк и т.д.) то же есть.
DHCP_Relay есть прямо в свитче, соберёт с разных VLAN и портов и отправит на 1 сервер. Ответ вернётся только конкретному клиенту.
ip unnumbered разве что… Но аппаратных решений умеющих это без такого огорода — ОЧЕНЬ много. Даже то же программное. Но не этот огород.
Пока что не понятен смысл… Но как сферический конь в вакууме — интересно :)Vedga
06.10.2015 20:37DHCP Relay в коммутаторе означает L3. Причину отказа от него см. выше. А вот о «программном решении, но без этого огорода» можно поподробнее? Идею на пальцах или ссылку на реализацию?
Ptica79
07.10.2015 12:54+1DHCP Relay совсем не означает L3. Чистый L2 D-Link DES-3200 или DES-1210/ME прекрасно умеет DHCP Relay. Забирать пакет из VLAN пользователя и направлять его юникастом на DHCP сервер через свой управляющий VLAN. Бродкастовый пакет DHCP даже на соседние порты в общем-то не попадёт. Ответ сервера попадёт юникастом на свитч, а оттуда туда, откуда пришёл. У других производителей то же есть аналогичные свитчи. Больше работал с D-Link, поэтому мне проще их модели сказать.
Опять же изоляция портов пользователей друг от друга traffic_segmentation или Assymetric Vlan (опять же в терминологии D-Link).
Остаётся вопрос, а надо ли ip unnambered вообще. Если нет, задача сводится к правильной архитектуре L2 уровня на нормальных управляхах + нормальный маршрутизатор в ядре (как программный, так и аппаратный).
Правда при использовании варианта из статьи можно использовать СОВСЕМ тупые свитчи, где по факту есть только VLAN и всё. Соответственно экономия. Это единственный плюс который я вижу. Хотя тут легко нарваться на правило — жадный платит дважды.Vedga
07.10.2015 16:34Если что-то имеет DHCP (в т.ч. и relay) не на management, а как сервис, то это уже L3 (по модели OSI).
С тем, что сделать изоляцию средствами коммутатора проще и грамотнее, никто не спорит. Но без relay в любом случае это вызовет broadcast storm.
Ладно, заканчиваем полемику о причинах выбора именно этого решения? Я его запихнул в embedded систему, соответственно обвязка ей потребуется более слабая (ну а область применения новой железяки расширится).
AlexBin
08.10.2015 17:43>> Если что-то имеет DHCP (в т.ч. и relay) не на management, а как сервис, то это уже L3 (по модели OSI).
По сути да, но подобные функции реализуют на L2 свитчах, которые не занимаются маршрутизацией. Например всякие снупинги и аклы работают на коммутаторах, хоть и на сетевом уровне. Но это не делает коммутатор еще и маршрутизатором. Хотя функции L3, да.

Ivan_83
07.10.2015 20:44+1«DHCP Relay в коммутаторе означает» — L2+ в терминологии длинка, есть даже во всяких вебсмартах, например в DGS-1210 ревизии А1 оно приехало в последних прошивках.
По тасканию пингвинов за хвост я специалист, на фре это решается проще: цепляем на реальный физ интерфейс ng_bpf, заливаем в него программу по ловле DHCP пакетов, цепляем сокет, цепляемся к сокету своей прогой и релеем в дхцп сервер.
Сами тэгируем/растегируем пакеты, придётся обзавестись табличкой mac-vlan или mac+dhcpReqId-vlan (что более правильно).
Ради прикола можно даже номер влана в опцию82 или ещё куда записывать перед отсылкой на сервер.
Хотя можно попробовать тоже самое делать через BPF, он и в линухе должен открывать физ интерфейс для чтения/записи пакетов, стандартные DHCP сервера обычно им же и пользуются.
Те мой мессаж в том, чтобы в своём релей агенте обрабатывать вланы, а не анонировать на стопку интерфейсов через кучу прокладок.Vedga
08.10.2015 11:20Спасибо за наводку с bpf, надо будет поиграться. Хотя внятную реализацию пока не нашел.


martin74ua
08.10.2015 09:39для оценки сложности решения — зайдите в соседнюю контору и попросите быстренько поправить проблему с dhcp )
Ну и считайте к-во мата, по мере постижения.
Наворочено, необслуживаемо, немасштабируемо. Вот что вы будете делать после 4к клиентов? ;)
Ну и из личного опыта — подобные навороты на серверах приводят к тому, что в случае возникновения проблем — сетевики кивают на админов, админы на сетевиков, а юзера сидят и матерятся.Vedga
08.10.2015 09:56Вообще-то в комментариях проскакивало, что это решение не для сервера, а для embedded-системы. Необслуживаемо — это верно, обслуживать просто нечего. Схема проста до невозможности и, практически, не использует ip-адресации.
Масштабируемо достаточно сильно: новый клиент добавляется одним шагом цикла в скрипте, который создает для него набор интерфейсов. Кол-во клиентов ограничено кол-вом поддерживаемых VLAN на обвязке. Вы ведь не думаете, что эта конфигурация создается вручную? Один маленький скрипт, получающий на входе требуемое кол-во клиентов и начальный номер VLAN для них (на самом деле еще и распределение VLAN-ов по физическим ethernet, но не суть).
Отлов проблем: зная VLAN с проблемным клиентом просто запустят на нем tcpdump.

achekalin
08.10.2015 09:59Для начала, Вы бы писали, под какую платформу ведете рассуждения. А то «надо сделать», а затем сразу «сделать это можно так — раз-раз».
Уже не говорю, что access mode — термин не совсем чтобы универсальный, так что бренд коммутатора тоже бы не помешала.
Понимаю, что звучит это занудно, но Вы же не во конторскую wiki (где все ваши читатели примерно понимают, о чем речь идет) пишете пост, а на ресурс «чуть большей» аудитории — уважайте читателей!Vedga
08.10.2015 10:21Платформа не важна. Отладка вообще велась на десктопной машине, а целевая система собиралась при помощи buildroot. Но замечание о терминологии принимается, по-возможности внесу в статью исправления. И, возможно, стоит указать минимально необходимые опции сборки ядра для поддержки используемых фич. Хотя в современных generic ядрах все они присутствуют по умолчанию. Интересно, а есть здесь хаб для embedded programming?
achekalin
08.10.2015 13:10Прозвучит пОшло, но linux — это далеко не дефолтная платформа в современном мире, а всего лишь одно из ядер в части дистрибутивов (да Вы это и сами отлично знаете). И «generic ядро», «buildroot» и прочее, что Вы упоминаете в тексте, на части «других» платформ может даже отсутствовать, не говоря, что для сходных задач и понятий могут использоваться другие средства и названия.
Повторюсь: отличный рассказ, но написанный для вашего коллеги, который ваши перипетии знает вдоль и поперек, и который в общем-то в курсе даже версии ядра в вашем дистрибутиве. Представьте, что Вы то же рассказываете не коллеге, а человеку с ИТ-ной подготовкой, но приехавшему к Вам в гости с другого конца страны — Вы же ему хотя бы расскажете явно чуть более подробно, чем написали в посте? Вот и ориентируетесь на такой подход, ведь не все не Хабре по тому, что увидели до ката (да и в тексте), хорошо поняли, о чем разговор.

mickvav
08.10.2015 10:34+1Cлушайте, а зачем, собственно, весь этот дико геморройный огород с бриджем, если можно тупо слушать в каждом интерфейсе на своём ip-нике и раздавать? Ну, придётся dhcp-сервер ребутать при добавлении абонентов, но это ж быстро и если конфиги генерить автоматом по шаблонам, а не руками писать — безопасно. Нафига весь этот огород?
Vedga
08.10.2015 10:49Сейчас есть только 2 используемых IP: DHCP Server (он же default gateway для клиентов из всех VLAN) и DHCP Relay Agent. Если селить сервер на каждый VLAN, то имеем следующее:
— добавление/удаление клиента повлечет за собой операцию выделения/освобождения ip-адреса на интерфейсе (а какую маску ставить будем? На каждый VLAN выделять свою подсеть вместо ее динамического распределения?)
— при изменении общей размерности сети придется изменить параметры на всех интерфейсах;
— разрастание таблицы маршрутизации пропорционально кол-ву клиентов;
— уменьшение пропускной способности из-за увеличения нагрузки на CPU (вместо работы на L2 сначала разберем пакет до уровня L3, затем выполним фильтрацию/маршрутизацию, потом снова L3 соберем в L2).mickvav
08.10.2015 10:561. Если клиентов не ограничивать, то глючный или злонамеренный клиент выберет у вас весь пул dhcp лиз всех клиентов. Скриптик продемонстрировать или сами догадаетесь?
2. И что, если это делает скрипт?
3. Сюрприз — даже full-view таблица работает в ядре очень быстро.
4. Вы в любом случае всю работу делаете на CPU в ядре. Вы сравнивали реальную производительность L2 и L3 стеков ядра и не написали про это в статье?Vedga
08.10.2015 11:06Не выберет, т.к. DHCP Relay Agent в запросе к серверу вполне может отправлять и dhcp option 82. А сервер может ограничить кол-во выдаваемых адресов по клиенту. Просто в моем конкретном случае это излишне (подразумевается наличие клиента с кривыми руками, способного воткнуть не то и не туда, а не злонамеренного хакера).
Каюсь, производительность не сравнивал. Возможно Вы и правы. Хотя что-то мне подсказывает, что дополнительная обработка пакета все-таки должна потреблять какое-то количество времени CPU.
Ovsiannikov
10.10.2015 03:05Прикольно, у самого была подобная задача пару лет назад, но ядро было 2.6.18 или что-то типа того, а то бы я нагородил что-то подобное :)
Решилось тогда довольно просто: нашёл релей агент, который ответы отсылает не бродкастом, а юникастом. Т.е. получателем ставит мак клиента в явном виде. Тогда никаких проблем с бродкастом не наблюдается и проблема отсутствует как таковая.
ещё комментариев:
1. вланы (ИМХО) правильнее добавлять так: ip link add link eth0 vlan600 type vlan id 660
(не нужно ничего доставлять, нет неявного именования новых интерфесов,
а то, например, на моей системе «vconfig add eth0 600» добавляет eth0.600 а не vlan600 )
2. включение stp на br1 вобщем-то лишено смысла, ведь вы включаете изоляцию клиентов. Т.е. петля/кольцо не поломают вам нечего, т.к. трафик ходить «по кругу» не сможет, а странные проблемы иногда могут появляться в итоге.Ovsiannikov
10.10.2015 03:13да, кстати, ещё вспомнил:
серьёзно штормит от исходящих с самого бриджа арп запросов, т.е. тех которые генерирует «шлюз».
рекомендую выкрутить срок жизни арп записей на максимум.
evg_krsk
Очень круто. Каких только трюков люди не делают, чтобы не делать правильный дизайн сети :-)
У меня лишь один вопрос: как человек после вас будет в этом сервере разбираться? :-)
Vedga
А что тут сложного? Слой relay по умолчанию пользователю не виден. Слой backplate — обычный switch.
Ладно, давайте о дизайне. Прикладная задача для embedded-системы: подключить VoIP-оборудование к общему серверу телефонии.
Каждый VLAN — логически изолированный узел (этаж здания, само здание, отдельный арендатор). Количество оконечных устройств на VLAN-е изначально не определено и может изменяться в процессе эксплуатации. Количество VLAN также может изменяться (арендаторы появляются и пропадают). Какие будут предложения?
evg_krsk
Упс. По ошибке ответил ниже.