
Цифровые ассистенты — тренд в массовом обслуживании. Они автоматизируют работу поддержки, помогают пользователям найти и подобрать услуги, записаться на прием, развлекают.

Привет, меня зовут Никита. Я руковожу командой, создающей Робота Макса, цифрового ассистента Госуслуг. Еще год назад у ассистента не было команды, потом появилось 7 человек. Сейчас нас 70, мы стараемся быть лидерами изменений на Госуслугах и внедрять новые практики командной работы.
При создании ассистента важно не только правильно сформировать технологический стек, но и быть глубоко погруженным в контекст сферы, для которой создается умный помощник. У Госуслуг важные задачи, уникальная специфика и терминология, многомиллионная аудитория. Как оформить ребенку паспорт, получить выплату к школе или компенсацию билетов в театр, записаться к врачу или сообщить о нарушении? Во всем этом вам должен помочь цифровой ассистент.
Сегодня я расскажу из чего состоит Макс и как он таким стал.
Как возник ассистент Макс и какая у него цель
Текущий поиск Госуслуг написали 13 лет назад. C++, сильная команда разработчиков и опыт создания глобального поиска. Но время шло, развивался мир и госуслуги, а поиск — нет. Разница в темпе развития привела к десяткам заплаток, состав команды сменился, документация устарела. Legacy-код повлиял на мотивацию и производительность. Время релиза услуги в поиске достигло суток. При обновлении Sitemaps старые услуги пропадали, новые не появлялись. Ранжирование задавалось вручную. Autocomplete не знал морфологии и не работал, если фраза содержала стоп-слова. Так мы поняли, что быстрее и правильнее создать новое.
Границы получения услуг, кому можно или нельзя, когда и как, описываются официальными формулировками. Часто используются канцеляризмы и аббревиатуры. Вместо «налоговая» — «ФНС» или «Федеральная налоговая служба». Вместо «ремонтировать» — «производить ремонт». Люди так не разговаривают. Но завтра же изменить язык государство не сможет. Законы и акты придется переписать, для новых внедрить редакционную политику, научить сотрудников. А госуслуги нужны сейчас. Так мы поняли, что людям нужен переводчик с «государственного».
При проработке концепции нового поиска аналитики обратили внимание на поведение пользователей в социальных сетях. Люди организуют группы, где создают пошаговые инструкции «как получать госуслуги». Читатели идут по понятному пути, быстро и без переживаний. Так мы поняли, что Госуслугам нужен проводник, который поймет с полуслова, поможет подготовиться и даст подробный совет.
Боль наших пользователей — техническая поддержка. Команда провела независимые замеры среднего времени ожидания оператора в чатах поддержки. Показатель по лидерам российского рынка — до 3 минут. А пользователи Госуслуг ждут помощи оператора 2 или 3 часа. При этом больше 60% обращений типовые. Так мы поняли, что Госуслугам нужен спасатель, который ответит без оператора.
Цель Робота Макса — сопроводить, поддержать и помочь. Найти услугу, рассказать о ней, объяснить, как действовать. И все это на понятном языке.

Из чего же, из чего же, из чего же
Рассказывать о Максе можно долго, поэтому, чтобы вы не заскучали, в этой статье я остановлюсь на ключевых компонентах. А также поделюсь схемой архитектуры, если вас заинтересует какая-то конкретная область — пишите в комментариях и мы раскроем её в следующих статьях.

Схему в высоком разрешении можно посмотреть по ссылке.
«Мозг» Макса — брокер, который асинхронно опрашивает сервисы предоставления ответов и выбирает релевантный. Для выбора используется информация о длине введенной фразы, способе ввода, намерении пользователя и наличии ответа в сервисе. Брокер разработан на Python 3.9 с использованием асинхронных пакетов, таких как FastApi, aiologger, aioredis, httpx. Стратегию выбора сервиса может настроить любой пользователь без привлечения разработчиков. Количество параметров в стратегии не ограничено, но при конфликтах пользователю сообщается о наличии ошибки. Для хранения стратегии используется БД PostgreSQL.
Интеграционная шина брокера связывает компонент с функциональностью персонализации, хранилищем диалогов, хранилищем контекстов, единым аналитическим кластером Госуслуг, кэшем и ELK. Все эти сервисы регулируются через feauture flags, а при повышенной нагрузке могут отключаться, чтобы сократить количество внутрисистемных запросов. При необходимости Макс сохранит контакт только с одним-двумя сервисами ответов и продолжит помогать пользователям. Через конфигурирование брокера настраивается А/Б тестирование и канареечные релизы. Взаимодействие с фронтом идет через socket-соединение, за счет хранения контекстов происходит зеркалирование и пользователь может работать одновременно с нескольких устройств. Кроме сокетов поддерживается long-polling и rest.
Системное логирование ведётся в LogStash, что позволяет наглядно изучать работу приложения в Kibana, с удобной фильтрацией и отображением графиков.

Анализ обращений пользователей к Максу показал, что 71% запросов это короткие фразы, длиной до 3 слов. 49% пользователей отправляют 1 слово, 14% - 2, 8% - 3.
Чтобы правильно реагировать на короткие запросы, команда провела кластеризацию и выявила, что в 51% случаев в запросе содержится только домен услуги. Домен — обобщенное обозначение услуги или группы услуг. Например, домен COVID включает в себя такие услуги как «Запись на вакцинацию», «ПЦР-тест», «Сертификат переболевшего», «Проблема с лечением COVID».
31% запросов содержит только запрос к действию без обозначения домена услуги или услуги. Например, «запись», «регистрация», «оформление».
И 14% содержат название услуги, например, «Запись к врачу», «Замена паспорта» или «Пособие беременным».
При выборе решения для ответов на короткие запросы мы ориентировались на высокий уровень управляемости, быструю настройку и, конечно, точность ответа. В результате проработки сформировались 2 варианта: нейросеть на основе fastText и обратный поиск Elasticsearch - percolate, по основам слов, который вызывает квизы — JSON’ы с графом переходов между вариантами ответов.
Проверка концепции показала, что нейросеть из-за схожести домена услуги и полного названия услуги часто ошибалась при ответе. Средний уровень точности составлял 40%, что недостаточно для запуска в продуктивную среду. Было решено работу с нейросетью выделить в отдельный поток, чтобы найти ей оптимальное применение. Квизы показывали точность в 2 раза выше при том же времени на настройку. Чтобы сократить время поиска, квизы настроены на перехват запроса, поэтому при настройке используются основы слов, а не полное их значение. Для квизов был переиспользован плеер услуг, разработанный специально для новой версии портала. Это не только сократило время на встраивание, но и позволило заполнять услуги в интерфейсе Макса.
Итак, 71% запросов у нас короткие, но 29% — больше 3 слов. Что делать с ними? Кластеризация показала, что подавляющая доля длинных фраз — конкретные вопросы об услуге. Примеры запросов: «какой размер пошлины за замену паспорта?» или «нет сертификата о вакцинации, хотя я привился». Ответы на такие вопросы содержатся в базе знаний раздела «Помощь», это стандартный FAQ-формат. Для сохранения единства информации было принято решение индексировать базу знаний.
Первой концепцией было переиспользовать обратный поиск, который мы применяли на коротких запросах. Но для запросов такого типа он не показал достаточного уровня точности и занимал слишком много времени на обучение из-за длины фразы и количества ключей.

Вторая идея заключалась в применении Elastic, но уже в формате обычного поиска. Для индексации была настроена предобработка морфологии с использованием словаря hunspell, словарь стоп-слов, ориентированный на предлоги и местоимения, а также словарь синонимов. Поиск по телу статьи на предварительных тестах показал ужасные результаты, точность составляла 10%. Причина заключалась в редакционной политике. Что полезно человеку — роботу полезно не всегда. Политика «пиши-сокращай» позволила ясно доносить информацию, но индексировать ответ стало невозможно. Например, для вопроса «Заверять ли анкету для загранпаспорта на месте работы» ответ из базы знаний был — «нет, не нужно».
К индексу по телу статьи попробовали добавить заголовок, точность выросла до 45%, но и этого было недостаточно. Формулировки запросов расходятся с названием статей, заголовки услуг в различных доменах близки по названию, что мешает точному поиску. На брифинге возникла идея — добавить к каждой статье 5 скрытых заголовков, аналог разметки, отражающий вариативные запросы пользователей. Результат вышел отличный, точность ответа выросла до 92%.

Новая проблема возникла, когда количество индексированных вопросов превысило 700. Близкие домены и вопросы в них стали путать поиск, точность снизилась до 60%, часто Elastic отдавал откровенную чушь. Чтобы исправить ситуацию, были сформированы две гипотезы. Первая – что для точного поиска нужна предварительная классификация домена услуги, тогда поиск будет сравнивать меньшее количество статей и риск ошибиться будет ниже. Вторая – что для точного поиска нужно доработать запрос, не использовать стандартный «query_string».
Для проверки первой гипотезы был разработан классификатор на облаке слов с применением TF-IDF-меры. Он показал точность 80% и позволял в короткий срок встроить данные в ассистента. Для повышения точности классификатора была использована вышеупомянутая нейронная сеть на fastText. За счет обучения каждого класса на выборке из 500-1000 фраз пользователей и совмещения его с TF-IDF-классификатором точность выросла до 94%
Для проверки второй гипотезы поисковый запрос был изменен на «multi_match», с дополнительным коэффициентом сложения значений релевантности всех полей документа. Таким образом, каждое из 6 полей, участвующих в поиске, дополняет и усиливает друг друга. Появилась возможность гибко настраивать ранжирование результатов. Без применения классификатора новый запрос привел к точности 80%. Включение в пайплайн классификатора и нового поискового запроса вернуло качество поиска на прежний уровень.

Создание классификатора позволило решить еще одну проблему. Обучить ассистента всему и сразу невозможно. В качестве вех для обучения используются услуги, об этом процессе мы расскажем отдельно, но главное — непрерывный процесс пополнения Макса новыми знаниями. Чтобы не терять уровень покрытия, для поиска услуг, которым Макс не обучался, используется старый поиск. Разработанный классификатор был применен не только для повышения точности поиска на Elastic, но и для определения, настроена ли услуга в навыках Макса или стоит отправить запрос в старый поиск. Таким образом Макс сохраняет уровень покрытия услуг, выводя их на новый уровень качества.
Контролировать качество работы Макса, выявлять всплески пользовательских запросов и количество аудитории позволяет компонент логирования бизнес-метрик. Макс запоминает количество входов в виджет и выходов из него, введенные и отправленные запросы пользователей, время и дату запросов, выявленный класс, переход к предложенному ответу или переход по ссылке. Обезличенная статистика попадает в аналитический кластер Госуслуг через Kafka. С полученной информацией работает команда анализа данных. В аналитическом кластере есть настроенные дашборды по посещаемости, конверсии отвечающих сервисов, ТОП отправленных фраз, ТОП фраз, на которые не отреагировали сервисы ответов. ТОП статей FAQ, ТОП квизов и ТОП ссылок, по которым переходили пользователи. Кстати, поздравьте нашу команду, ночью 29 октября мы вышли на главную Госуслуг и побили рекорд своей посещаемости, с Максом работали 1 353 999 граждан за сутки. В первую неделю запуска количество пользователей в сутки не превышало 45 000.

Хайрез, как всегда, по ссылке.
Работа со статистикой
У Макса есть две основные метрики оценки работы — покрытие и точность. Покрытие означает насколько знания Макса соответствуют запросам пользователей. Точность — насколько правильно Макс отвечает на вопросы, которым его обучили. Для анализа этих показателей применяются методы предварительной кластеризации и ручная разметка. Частота обновления — от 2 до 4 недель. Резкие всплески отображаются на дашбордах, но методичное обновление метрик покрытия и качества позволяет отследить результат на длительном промежутке времени.
Первый шаг при анализе покрытия — выявить покрытие доменов в запросах пользователей. Какая доля фраз задается по услугам, которым Макса обучали, какая доля фраз по доменам, которым Макса не обучали, и какая доля запросов не является сутевой, например, мат, абракадабра или фразы приветствия. Каждый домен тщательно размечается и на выходе команда имеет список тем для обучения. Следующий шаг — разметка непокрытых вопросов внутри доменов, где обучали Макса и анализ распределения. Для дообучения в первую очередь берутся самые популярные услуги.

При анализе качества в первую очередь ведется анализ доли ответов, где Макс правильно ответил на вопрос, где ответил неверно и где вообще не ответил. За этим следует декомпозиция на сервисы — квизы, поиск по FAQ и старый поиск. Следующий шаг — декомпозиция на категории проблем. Например, отсутствие ключевых слов, некорректная работа словаря стоп-слов.
Сейчас команда работает над добавлением метрик оценки пользователем ответов Макса. Мы хотим знать от пользователей, помог ли ответ Макса, и, если нет, как можно его изменить, чтобы помог.

Напоследок
О чем еще можно рассказать…
Например, как мы выявили нетривиальное поведение пользователей и сформировали классы для обработки таких запросов.
Как наши дизайнеры переработали внешний вид Макса и как мы встроили анимацию.
Как мы меняем работу с операторами.
Как мы обнаружили запросы пользователей о статусе своего заявления и как работаем с направлением персонализации и рекомендательным движком.
Как мы работаем над сохранением контекста диалога, чтобы быть еще ближе к пользователю и лучше его понимать.
Как мы проверяли гипотезы перехода к оператору.
Как мы работаем с инфраструктурой и системными компонентами.
Как мы развиваем предобработку.
Как организован процесс вывода навыков и как мы сократили время вывода с 5 дней до 24 часов.
Выбирайте, что интереснее. Обсудим в следующий раз.
Если у вас есть идеи, что можно улучшить и как, присылайте их на почту нашей команды: robot_maks@rtlabs.ru или пишите в комментарии к статье.
Спасибо.
Иллюстрации: Михаил Голев
Комментарии (26)

ne555
03.11.2021 13:43+4Еще год назад у ассистента не было команды, потом появилось 7 человек. Сейчас нас 70
Только вдумайтесь над этой прогрессией! Над одним ботом 'трудятся' 70ч. и каждому нужно платить зарплату из кармана налогоплательщиков (я это так понял из статьи).

Nikita_Us Автор
03.11.2021 15:05+3Добрый день! Команда ассистента не только "разрабатывает" бота :)
Наши сотрудники формируют и редактируют контент, чтобы пользователи получали полезную информацию. Полезный контент применяется не только в Максе, но и размещается в разделе "Помощь" - FAQ Госуслуг.
Мы собираем и анализируем данные, от которых зависит не только качество поиска, но и всего портала. Выявляем точки возникновения проблем и вместе с командой Customer Success устраняем их.
Чтобы система функционировала качественно, нужна команда тестирования, автоматизация тестов. Вывод новых навыков необходимо тестировать максимально тщательно, чтобы они не мешали друг-другу и пользователь получал релевантную информацию.
Чтобы бот помогал и работал точно, нужны специалисты в области нейронных сетей и поисковых технологий.
У Робота Макса ~1 300 000 уникальных пользователей и ~2 200 000 сессий в сутки. И это только за выходной день. Больше 40 000 000 пользователей в месяц. Чтобы выдерживать высокую нагрузку нужны devops-специалисты и инженеры поддержки. Нужен качественный код, чтобы масштабировать нагрузку.
Согласитесь, 70 человек - не так и много, чтобы сделать удобным получение услуг для десятков миллионов наших пользователей.vak0
03.11.2021 18:44+2Подскажите, если конечно это не секрет, а у вас есть какой-то внутренний регламент по срокам исправления ошибок, найденных пользователями на портале Госуслуг? Про стандартные ответы «работы занимают до трёх рабочих дней, но может потребоваться больше времени» я в курсе, но интересно узнать, есть ли внутренние нормативы, которые определяют реальные сроки. Или, быть может, подскажете способ получить плановый срок по конкретному тикету?
Nikita_Us Автор
09.11.2021 11:29Добрый день! Напишите на почту нашим коллегам из отдела Customer Success: cs@rtlabs.ru
Они проконсультируют, помогут разобраться с возникшей проблемой, предложат пути решения
ne555
16.11.2021 07:34Согласитесь, 70 человек - не так и много,
Нет, я не могу согласиться с тем, что для разработки бота, наполнения справки требуется 70ч. Это - из ряда вон выходящее. И даже предполагаю, что за сложившуюся ситуацию, найдут "виновного" и накажут.
Проблема ваша, что публично заявили от лица госуслуг о таком сумасшедшем факте.
ps/
Минцифры сообщили, что это была рекордная по своей мощности кибератака на портал.
После этого местный бот Макс начал вести себя странно… На вопрос о том, как получить QR-код после прививки, он пожелал одной из пользовательниц «покоиться с миром». А корреспонденту «Дождя»* сообщил, что QR-код — это «план мирового правительства по сегрегации населения»



ChePeter
03.11.2021 15:00+1Правильно ли я понял, что тезаурус и его структуру никто не строил?
А вопросы
"какой размер пошлины за замену паспорта?"
И "сколько платить за замену паспорта" это разные вопросы.
Правильно ли я понял, что при поступлении 1000 идентичных вопросов ваш робот будет обрабатывать их все отдельно, как разные?
Nikita_Us Автор
03.11.2021 19:45Здравствуйте!
Про тезаурус: у Макса есть несколько контролируемых словарей, которые мы постоянно пополняем. Морфология, которая позволяет распознать слово независимо от части речи, используемых приставок, суффиксов или окончаний. Словарь синонимов, который позволяет указать отношения между одинаковыми по смыслу терминами или фразами. Словарь стоп-слов.
Приведенные примеры - да, это будут немного разные запросы за счет слова "какой". Оно содержится в разметке для статьи "Штраф за просрочку замены паспорта", т.к. люди часто спрашивают именно: "Какой штраф...".
Если вы введете фразы "размер пошлины за замену паспорта" и "сколько платить за замену паспорта", то Макс предложит одинаковые результаты.

Реакция на фразу: "размер пошлины за замену паспорта" 
Реакция на фразу: "Сколько платить за замену паспорта" Если добавляется слово "какой", то в ТОП выдачи Макса попадает статья "Штраф за просрочку замены паспорта". Релевантный первый ответ останется неизменным.

Результат по запросу: "какой размер пошлины за замену паспорта" Мы рассматривали возможность включения вопросительных слов в словарь стоп-слов. Но отказались от этого. Вопросительные слова не мешают работе поиска, часто наоборот повышают релевантность выдачи.
Про 1000 идентичных вопросов: нет, для обработки идентичных запросов у Макса есть кэширование. Для самых частотных запросов мы используем Redis. Помимо Redis, у Elastic есть shard кэш, который добавляет еще уровень оптимизации.

ildarz
03.11.2021 15:23+1Из личного опыта. Сейчас для регистрации корп. симкарты для сотрудника нужно подтверждение через госуслуги. Приходит СМС от оператора с инструкциями. Логинюсь, вбиваю в поисковую строку бота название соответствующей услуги. Выдает что угодно, кроме того, что мне нужно - собственно ссылки на оформление услуги. Попытался прокликать по ссылкам от бота - снова мимо, там тоже нужных ссылок нет. Пришлось вернуться на старую версию сайта, там с первого же попадания нашел что надо.
Nikita_Us Автор
03.11.2021 19:49+1Спасибо за обратную связь! Действительно, мы заметили, что у пользователей возникают сложности с поиском этой услуги и её оформлением. Первые обновления уже выведены в продуктив.
На короткие запросы Макс предлагает перейти к услуге:

Пример со запросом "симкарты" А на сложные вопросы предлагает ответы из базы FAQ (в релевантной статье тоже есть ссылка на услугу):

Пример с запросом "Как получить корпоративную сим-карту на госуслугах"

vadimk91
03.11.2021 18:38+3Интересно было бы почитать, чем руководствуются дизайнеры. В моем детстве (ещё в советские времена) всякие мультяшные герои были только в детском саду, ну может в начальной школе. Нынче заходишь на сайт даже солидного, как говорили раньше, банка и опа - тебе показывают мультики, хорошо не про розовых пони, но кажется, и до этого недалеко. Отстал я видимо от жизни совсем.



eaa
03.11.2021 22:56+1На слово "погранпропуск" эта штука не среагировала, пришлось гуглить гуглом на сайте госуслуг. Зачем тогда там вообще такая штука, если гугл решает проблему лучше?
Nikita_Us Автор
09.11.2021 11:41+1Добрый день! Спасибо, что обратили наше внимание на поиск данной услуги.
Обнаружили, что по введенному запросу "Погранпропуск" в старом поиске тоже не находится информация.

Добавили данную формулировку, теперь Макс помогает найти услугу:
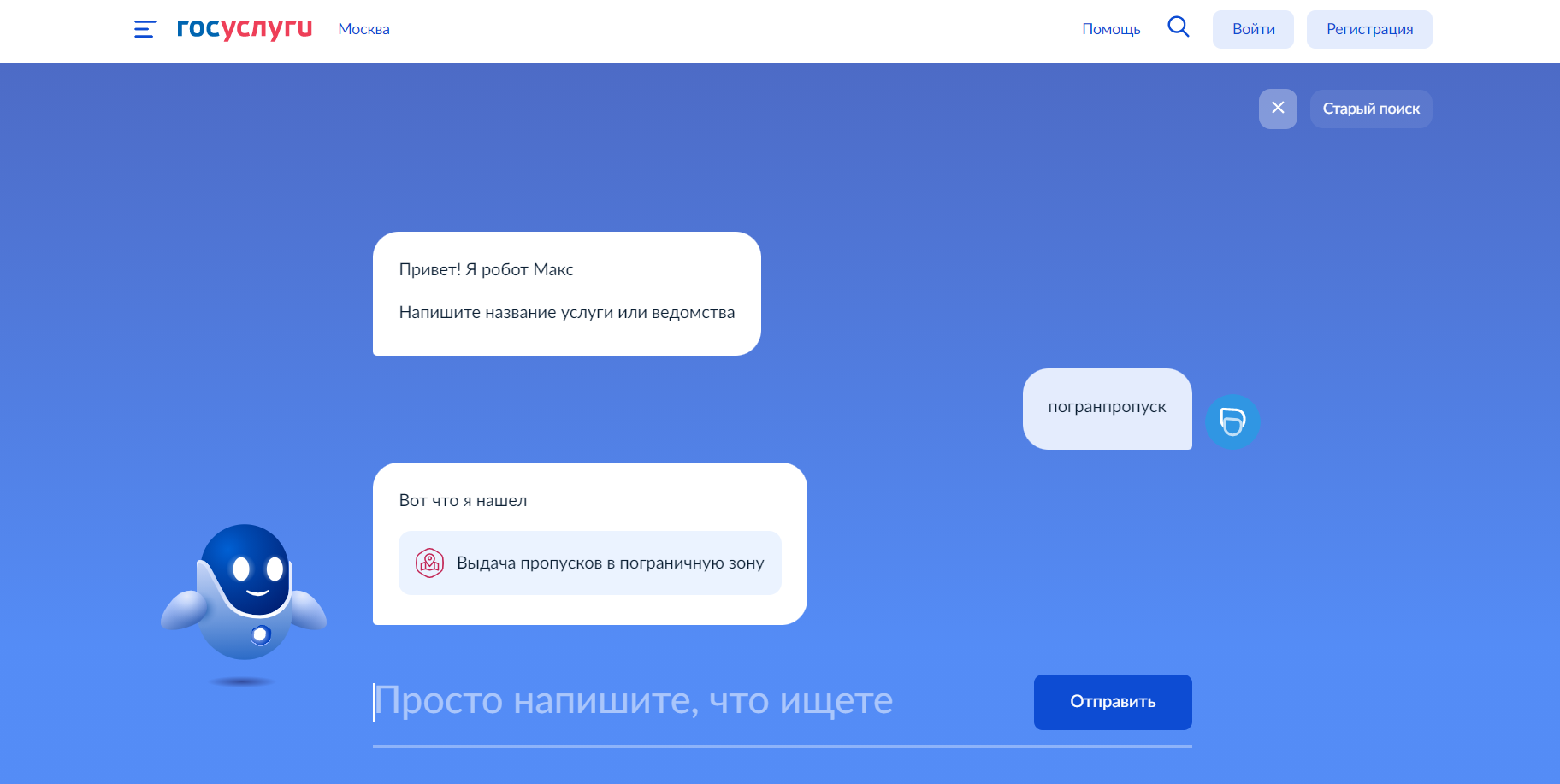
Еще реагирует на запросы, связанные с пограничной зоной:

eaa
11.11.2021 18:44Замечательно, не ожидал, что что-то изменится.
У меня есть еще один вопрос, на который я год не могу получить ответ, про ту же услугу выдачи пропуска в погранзону. Мне для альпинистских маршрутов нужна формулировка в виде "По маршрутам 1-131 согласно реестра .....<тут номера и даты реестра и т.п.>....."
А вот форма заказа пропуска позволяет ввести только конкретные населенные пункты, и размер поля ограничен, так что я не могу туда даже просто вписать всю эту тарабарщину про реестр маршрутов. Вы можете как-то решить этот вопрос или передать его соответствующим компетентным лицам? А то по старинке заказываю пропуск по эл. почте.

Akr0n
04.11.2021 03:12+1Логично было бы выкладывать в Open Source все инструменты, разработанные на деньги налогоплательщиков..? Что думаете на этот счёт?

Ashmanov
16.11.2021 10:39Да, это было бы логично, мы об этом регулярно говорим на всех собраниях про импортозамещение и отечественный софт.
Как минимум с доступом из остальных госпроектов, если не для всех вообще.
Я бы открыл для всех в принципе - но без попыток писать комментарии на английском.


Ashmanov
16.11.2021 10:32Мужики, вы переоткрываете для себя все мельчайшие грабли обычного информационного поиска по базе знаний. И рассказываете об этом, как об откровении.
Прямо по всем шагам, умилительно. Разработчики внезапно узнают про машинную морфологию и основы слов! ШОК, Фото!!!
Потом про синонимы! Потом про проблему коротких текстов! Потом про поиск по каталогу!!!
И т.п.
Вы, похоже, делали всё с нуля, "с мороза". Причём, похоже, сначала вам казалось, что нужно просто "правильно сформировать стек технологий" - и он всё сделает.
И вы в итоге справились: построили штуку уровня примерно 2001 года. На hunspell и таком же всяком.
А нельзя было просто нанять кого-то, кто знает, как это на самом деле делается? Люди же в отрасли есть. Куча народу работала в поиске Яндекса, в Мыле и т.п.
Более того, у вас там рядом должен был кто-то остаться из Спутника, где также все эти проблемы давно решены, и морфология своя, и поисковик, всё принадлежит РТ. Да хоть того же Кеву взять и попросить его сделать за небольшую мзду.
MockBeard
только вчера воспользовался вашим помощником на госуслугах, ищет нужное мне намного лучше, чем через строку поиска, понравилось!
Nikita_Us Автор
Спасибо за обратную связь! Такие комментарии воодушевляют нашу команду))