

Результаты выборов в государственную думу, которые проходили 17-19 сентября 2021 вызывают сомнения у многих экспертов. Независимый электоральный аналитик Сергей Шпилькин оценил количество голосов, вброшенных за партию власти, примерно в 14 миллионов. В данной работе применены методы машинного обучения для того, чтобы выявить избирательные участки, на которых подсчет голосов происходил без нарушений и установить истинный результат на тех участках, где , предположительно, были зарегистрированы ошибочные данные.
Результаты выборов можно найти на сайте ЦИК. Кроме того, результаты были выгружены с сайта и помещены в телеграмм канал RuElectionData. В рамках данной работы исследуются результаты выборов для партий «Единая Россия» и «КПРФ», которые по результатам, опубликованным ЦИК, получили 49,82 и 18,93 процента голосов избирателей. В данном исследовании в качестве источника результатов используется часть данных, которые были сохранены в файл ‘edata.csv’. Этот файл можно скачать совместно с исходным кодом с GitHub.
Для начала загрузим данные и проверим их полноту:
#%% Загружаем данные
import pandas as pd
uiks = pd.read_csv('data/edata.csv', index_col=0)name |
region |
kprf |
er |
voted |
total_voters |
lat |
lon |
|
0 |
УИК №592 |
Алтайский край |
57 |
49 |
178 |
385 |
51.885025 |
85.307478 |
1 |
УИК №593 |
Алтайский край |
189 |
174 |
569 |
1515 |
51.934707 |
85.326494 |
2 |
УИК №594 |
Алтайский край |
157 |
141 |
464 |
1175 |
51.930130 |
85.333621 |
3 |
УИК №595 |
Алтайский край |
303 |
339 |
962 |
2257 |
51.943233 |
85.336853 |
4 |
УИК №596 |
Алтайский край |
264 |
282 |
843 |
1924 |
51.961639 |
85.335227 |
... |
... |
... |
... |
... |
... |
... |
... |
... |
Подсчитаем итоговый результат выборов для партии КПРФ и Единая Россия:
#%% Итоговый результат КПРФ
kprf = uiks['kprf'].sum()/uiks['voted'].sum()
0.18925488494610923
#%% Итоговый результат Единой России
er = uiks['er'].sum()/uiks['voted'].sum()
0.4982132868119814Итоговый результат совпадает с результатом на сайте ЦИК, будем считать данные полными.
Как видно из результатов ЦИК, Единая Россия опередила КПРФ более чем в два раза. Однако есть регионы, где КПРФ одержала победу. Для каждого из участков добавим параметр 'k-e' , который равен разнице результата Единой России и КПРФ в регионе, в котором находится участок. Кроме того, создадим таблицу с регионами, где победу одержала КПРФ:
uiks['k-e'] = 0.0
regions = uiks['region'].drop_duplicates()
reg = pd.DataFrame()
for region in regions:
region_data = uiks[uiks['region'] == region]
voted = region_data['voted'].sum()
kprf_total = region_data['kprf'].sum()
kprf_percent = kprf_total/voted
er_total = region_data['er'].sum()
er_percent = er_total/voted
uiks.loc[uiks['region'] == region, 'k-e'] = kprf_percent-er_percent
if er_total>kprf_total:
uiks.loc[uiks['region'] == region, 'color'] = 'blue'
else:
uiks.loc[uiks['region'] == region, 'color'] = 'red'
reg = reg.append(pd.DataFrame({'name': region,'kprf':[kprf_total], 'kprf_percent':[kprf_percent],'er':[er_total],'er_percent':[er_percent]}), ignore_index=True)
reg[reg['kprf']>reg['er']]
name |
kprf |
kprf_percent |
er |
er_percent |
|
1 |
Ненецкий автономный округ |
4917 |
0.319763 |
4469 |
0.290629 |
2 |
Республика Марий Эл |
89018 |
0.362999 |
81969 |
0.334255 |
3 |
Республика Саха (Якутия) |
118683 |
0.351483 |
112160 |
0.332165 |
4 |
Хабаровский край |
113691 |
0.265075 |
105112 |
0.245072 |
Нанесем участки на карту России с помощью библиотеки plotly.express.
import plotly.express as px
fig = px.scatter_mapbox(uiks, #our data set
lat="lat",
lon="lon",
color="k-e",
range_color = (-0.5,0.5),
zoom=2,
width=1200, height=800,
center = {'lat':60,'lon':105},
title = 'По данным ЦИК')
fig.update_layout(mapbox_style="open-street-map")
fig.update_traces(marker=dict(size=5))
fig.show(config={'scrollZoom': True})
На этой карте участки окрашены в различные цвета, в соответствии с разницей результата КПРФ и Единой России по региону, в котором находится участок(параметр ‘k-e’). Цвет может меняться от темно синего (Результат Единой России на 50% и более выше, чем у КПРФ) до желтого(результат КПРФ на 50% выше, чем у Единой России). На карте преобладают холодные тона. Преимущество Единой России очевидно.
Построим теперь график зависимости результатов Единой России и КПРФ от явки c помощью matplotlib:
import matplotlib.pyplot as plt
uiks = uiks[uiks['kprf']>10]
uiks = uiks[uiks['er']>10]
uiks['er_percent'] = uiks['er'] / (uiks['voted'])
uiks['kprf_percent'] = uiks['kprf'] / (uiks['voted'])
uiks['turnout'] = uiks['voted']/uiks['total_voters']
plt.scatter(uiks['turnout'], uiks['er_percent'], color='blue', s=0.01)
plt.scatter(uiks['turnout'], uiks['kprf_percent'], color='red', s=0.01)
plt.show()
На графике можно выделить две характерные зоны. Плотное ядро в районе явок 0.2-0.6 и расходящиеся «хвосты» в районе явок свыше 0.6. В своих работах, независимые электоральные аналитики показывают, что подобная картина может наблюдаться при вбросе голосов за партию, результат которой растет с явкой. Причем в ядре находятся участки с «нормальной явкой», на которых не было фальсификаций, а хвосты соответствуют участкам с «аномальной явкой», где результаты выборов недостоверны.
Отделим участки с нормальным голосованием от участков с аномальным голосованием.
Чтобы выделить участки в ядре используем алгоритм DBSCAN(Density Based Scan) из библиотеки scikit-learn. Этот алгоритм выделяет кластеры, в которых для каждой точки в радиусе “eps” имеется количество точек равное “min_samples”. Хороший результат дает eps = 0.009 и min_samples = 175:
#%% Выделение кластера участков с нормальной явкой
from sklearn.cluster import DBSCAN
er = uiks[['turnout', 'er_percent']]
er = er.to_numpy()
db = DBSCAN(eps=0.009, min_samples=175).fit(er)
plt.scatter(er[:, 0], er[:, 1], c=db.labels_, s=0.01)
plt.show()
uiks['db'] = db.labels_
uiks_normal = uiks[uiks['db'] == 0]
uiks_abnormal = uiks[uiks['db'] != 0]

Далее будем использовать участки из ядра для того, чтобы обучить модель. В качестве алгоритма будем использовать алгоритм k ближайших соседей. В sklearn он реализован в виде класса KNeighborsRegressor. Кроме того, мы создадим объект класса Pipeline, чтобы автоматически нормализовать данные с помощью StandardScaler.
#%% Создаем pipeline для машинного обучения
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
pipe = Pipeline([("scale", StandardScaler()), ("model", KNeighborsRegressor())])
pipe.get_params()Для обучения модели мы разделим участки в ядре на три части(cv = 3) и проведем оптимизацию результатов по количеству ближайших соседей ('model__n_neighbors'):
#%% Задаем параметры кросс валидации
from sklearn.model_selection import GridSearchCV
mod = GridSearchCV(estimator=pipe, param_grid={'model__n_neighbors': [45, 50, 55,60,65,70,75,80,85,90]}, cv=3)
Мы исходим из предположения, что на участках с аномальной явкой недостоверно регистрировался результат партии «Единая Россия» и соответственно явка. А такие параметры, как количество проголосовавших за партию «КПРФ», общее количество человек, которые могли принять участие в голосовании и координаты участка зарегистрированы верно. Именно эти переменные будем использовать для обучения модели:
#%% Обучаем модель
X = uiks_normal[['kprf', 'total_voters', 'lat', 'lon']]
y = uiks_normal['er']
Xx = uiks_abnormal[['kprf', 'total_voters', 'lat', 'lon']]
mod.fit(X, y)Полученную модель используем для того, чтобы рассчитать результат партии «Единая Россия» на участках с аномальной явкой:
#%% Рассчитываем результат Единой России используя модель
prediction = mod.predict(Xx)
uiks_abnormal['prediction'] = prediction
uiks_abnormal['er_predicted'] = prediction.round()Так как мы предполагаем, что результат Единой России не мог быть скорректирован в меньшую сторону в момент фальсификаций, на участках, где расчетные значения выше официальных результатов, оставим официальные результаты.
#%% Корректируем результаты, так как предполагаем, что за Единую Россию не было вбросов
for index, row in uiks_abnormal.iterrows():
if row['er'] < row['prediction']:
uiks_abnormal.loc[index, 'er_predicted'] = row['er']
uiks_normal['er_predicted'] = uiks_normal['er']Теперь, когда у нас есть расчетные результаты партии Единая Россия на аномальных участках, можно пересчитать явку и другие параметры. Кроме того, создадим объект uiks_predicted, который будет содержать результаты выборов на участках с нормальным и аномальным голосованием:
#%% Вычисляем явку по результатам машинного обучения
uiks_abnormal['voted_predicted'] = uiks_abnormal['voted'] - uiks_abnormal['er'] + uiks_abnormal['er_predicted']
uiks_normal['voted_predicted'] = uiks_normal['voted']
uiks_abnormal['turnout_predicted'] = uiks_abnormal['voted_predicted'] / uiks_abnormal['total_voters']
uiks_normal['turnout_predicted'] = uiks_normal['turnout']
uiks_abnormal['er_percent_predicted'] = uiks_abnormal['er_predicted'] / uiks_abnormal['voted_predicted']
uiks_normal['er_percent_predicted'] = uiks_normal['er_percent']
uiks_abnormal['kprf_percent_predicted'] = uiks_abnormal['kprf'] / uiks_abnormal['voted_predicted']
uiks_normal['kprf_percent_predicted'] = uiks_normal['kprf_percent']
uiks_predicted = uiks_normal.append(uiks_abnormal)Используем данные из uiks_predicted для построения графика зависимости результатов на участках от явки.
#%% Строим график зависимости результатов на участках от явки по результатам машинного обучения
plt.scatter(uiks_predicted['turnout_predicted'], uiks_predicted['er_percent_predicted'], color='blue', s=0.01)
plt.scatter(uiks_predicted['turnout_predicted'], uiks_predicted['kprf_percent_predicted'], color='red', s=0.01)
plt.show()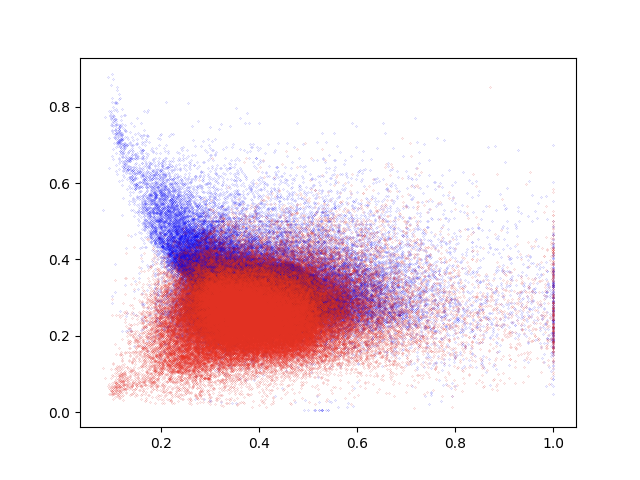
После применения машинного обучения картина больше похожа на ту, что наблюдалась в регионах севера России, где выборы традиционно проходят на высоком уровне. «Расходящиеся хвосты» в области большой явки больше не наблюдаются. Подсчитаем итоговый результат для партии Единая Россия и КПРФ по результатам полученных данных. Кроме того, установим количество вброшенных голосов:
#%% Считаем итоговый результат после применения машинного обучения
er_real = uiks_predicted['er_predicted'].sum() //12155992.0
kprf_real = uiks_predicted['kprf'].sum() //10610737
voted_real = uiks_predicted['voted_predicted'].sum() 40145581.0
er_real_percent = er_real / voted_real //0.30279775998259933
kprf_real_percent = kprf_real / voted_real //0.26430647497666054
fake_votes = uiks_predicted['er'].sum() - uiks_predicted['er_predicted'].sum() //14595980.0
Таким образом, после восстановления результатов с помощью модели машинного обучения Единая Россия набирает около 30 процентов при средней явке 40 процентов. Разница количества голосов за Единую Россию в исходных данных и данных, полученных в результате моделирования составляет 14595980. КПРФ набирает 26 процентов. Посмотрим, изменился ли состав регионов, в которых лидирует КПРФ:
#%% Таблица регионов, где победила КПРФ после применения машинного обучения
reg_true = pd.DataFrame()
for region in regions:
region_data = uiks_predicted[uiks_predicted['region'] == region]
kprf_total = region_data['kprf'].sum()
er_total = region_data['er_predicted'].sum()
voted = region_data['voted'].sum()
kprf_percent = kprf_total/voted
er_percent = er_total/voted
uiks_predicted.loc[uiks['region'] == region, 'k-e'] = kprf_percent-er_percent
if er_total>kprf_total:
uiks_predicted.loc[uiks_predicted['region'] == region, 'color'] = 'blue'
else:
uiks_predicted.loc[uiks_predicted['region'] == region, 'color'] = 'red'
reg_true = reg_true.append(pd.DataFrame({'name': region,'kprf':[kprf_total],'er':[er_total]}), ignore_index=True)
reg_true[reg_true['kprf']>reg_true['er']]
name |
kprf |
er |
|
1 |
Алтайский край |
224806 |
205960 |
2 |
Ивановская область |
84969 |
84383 |
3 |
Кабардино-Балкарская Республика |
77074 |
72990 |
4 |
Костромская область |
57588 |
56026 |
5 |
Ненецкий автономный округ |
4863 |
3883 |
6 |
Омская область |
190454 |
162625 |
7 |
Приморский край |
173429 |
142138 |
8 |
Республика Алтай |
22244 |
20992 |
9 |
Республика Калмыкия |
25485 |
24826 |
10 |
Республика Марий Эл |
89013 |
69266 |
11 |
Республика Саха (Якутия) |
118362 |
87085 |
12 |
Ростовская область |
333737 |
333235 |
13 |
Сахалинская область |
43471 |
38457 |
14 |
Ульяновская область |
147069 |
120774 |
15 |
Хабаровский край |
113312 |
85935 |
16 |
Ярославская область |
98695 |
90208 |
17 |
город Москва |
871223 |
529986 |
Количество регионов, где КПРФ одержала победу над Единой Россией, увеличилось с четырех до семнадцати. Проверим, как изменилась раскраска регионов на карте России:
#%%Карта России с разноцветными участками по результатам машинного обучения
fig = px.scatter_mapbox(uiks_predicted, #our data set
lat="lat",
lon="lon",
color='k-e',
range_color = (-0.5,0.5),
zoom=2,
width=1200, height=800,
center = {'lat':60,'lon':105},
title = 'После машинного обучения')
fig.update_layout(mapbox_style="open-street-map")
fig.update_traces(marker=dict(size=5))
fig.show(config={'scrollZoom': True})

Карта окрасилась в более теплые тона. Во всех регионах результат у партий КПРФ и Единая Россия очень близкий.
В результате моделирования результатов выборов на участках с аномальной явкой можно сделать следующие выводы:
Разница количества голосов за партию Единая Россия при подсчетах ЦИК и с использованием модели машинного обучения составила более 14 миллионов.
Результат партии Единая Россия составил около 30%
Результат партии КПРФ составил 26 %
Средняя явка составила около 40%
Количество регионов России, в которых результат КПРФ превзошел результат Единой России, увеличилось с четырех до семнадцати.
P.S. К статье уже достаточно много комментариев. Часть из них критические. И это хорошо, когда комментаторы подробно описывают недостатки статьи. В работе используется простая модель с малым количеством признаков. Ее можно улучшить. Пожалуйста, напишите, как бы вы улучшили исследование, если у вас есть идеи.
Многие исходные предположения в работе базируются на исследованиях Сергея Шпилькина. Из некоторых комментариев понятно, что в статье не хватает контекста в этом плане. Я рекомендую посмотреть это видео всем, кто его еще не видел:
Комментарии (77)

aamonster
13.11.2021 19:24+63Да уж, такой профанации машинного обучения с хайпом на модной теме я давно не видел.
Суть статьи можно выразить кратко: "Предположим, что выборы прошли так. Обучим на этом модель. Смотрите – результаты модели совпали с нашим предположением!".
Хорошо хоть за основу взяли выкладки Шпилькина – результат сколько-то правдоподобный получился.

sunsexsurf
13.11.2021 20:06+2абсолютно. у нас пол-страны - выбросов, по сути. Москва, "южные регионы" с сильным административным давлением и т.д. Там кластеров должно быть штук 30. Да уж (( грустно, что МЛ так поверхностно прикрутилось. А по поводу выкладок Шпилькина - вот его код посмотреть гораздо интереснее.

anonymous
00.00.0000 00:00zzzzbh Автор
14.11.2021 00:42+1Здравствуйте! Спасибо за комментарий, хотя он не вполне мне понятен. Можете подробнее описать в чем заключается "профанация", как это сделал Ordscarrid? Можете описать как бы вы решали подобную задачу? В каком месте делается предположение, что «выборы прошли так?»

Lepidozavr
14.11.2021 02:55+19Мы исходим из предположения, что на участках с аномальной явкой недостоверно регистрировался результат партии «Единая Россия» и соответственно явка."Мы считаем, что А - неправильно. Мы обучаем модель, говоря ей что А - неправильно. Мы получаем результат, что всё, что говорило нам А - неправильно"
Я понимаю ход ваших мыслей, но вот этот момент в тексте выглядит очень уязвимым и необоснованным. Соответственно, всё что далее может восприниматься как информация, которой нельзя верить.
Выглядит как искажение в экспериментальных данных, которое связано с тем, каким образом данные были интерпретированы и группированы. Ещё напоминает confirmation bias (предвзятость подтверждения).
Со стороны выглядит как обучение машинного алгоритма с заранее определённой когнитивной ошибкой.
Я бы рекомендовал этот момент сильно расписать, снабдить ссылками, где подчёркиваются особенности различных вбросов/искажений статистики, расписать теорию и практику очистки данных от вбросов (опять же, со ссылками на уважаемые источники), тем самым подвести неподготовленного читателя к пониманию того, что вот так обучать модель - адекватно и обоснованно. Текст в этом блоке рекомендую сделать "гуманитарным")
maxim_zverev
14.11.2021 11:52+6Фактически решалась задача "В предположении, что А - неправильно, посчитать количественно насколько сильно А неправильно." Единственно к чему можно придраться - к формулировке заголовка статьи.

Arqwer
14.11.2021 16:18+3И даже эта задача решена некорректно. K nearest neighbours не даёт хоть сколько-нибудь обоснованный результат для экстраполяции. Проще говоря - нельзя его применять для экстрополирования, совсем совсем совсем нельзя! Более того, даже для интерполяции этот метод не даёт никакой доказательной базы. DBSCAN рисует кластеры основываясь только лишь на близости точек друг к другу, и также не имеет никаких теоретических основ. Это не критика алгоритмов kNN и DBSCAN - они вполне годятся там, где нужно что-нибудь как-нибудь нашаманить, лишь бы оно работало. Проблема в том, что то, о чём говорит автор имеет не больше доказательной силы, чем рисование кластеров и трендов от руки.
zzzzbh Автор
14.11.2021 21:53+1Здравствуйте! Спасибо за комментарий! Какие алгоритмы вы считаете корректно применить для решения задачи?
don_rumata03
14.11.2021 17:47+1Казалось бы, здесь берётся за основу вполне разумное предположение, которое другие, «гуманитарные» исследователи выборов берёт за основу: стратегия ЕР на выборах ровно такая. Называние статьи соответствует содержанию — в ней содержится попытка оценить это количественно (причём использование таких незамысловатых методов политиками могло бы вывести дискуссию на новый уровень).
Нет ведь претензии на какой-то искусственный интеллект, который проанализировал все выборы за всю историю человечества, который сам понял, какие бывают фальсификации и понял, что они есть. Это классическое применение знаний из предметной области и комбинации с методами машинного обучения. Тут МЛ — это не цель, а всего лишь средство.
zzzzbh Автор
14.11.2021 21:47Здравствуйте! Спасибо за комментарий! Я добавил в конце статьи ссылку на видео. Там Сергей Шпилькин все в подробностях все объясняет. Будет время тоже напишу обзор, хотя лучше у меня вряд ли получится.
aamonster
14.11.2021 13:20+2Коротко: у вас нет данных для ML модели.
zzzzbh Автор
14.11.2021 21:36Хотелось бы подробнее. Какие данные вы бы добавили для корректного обучения модели? Можете подробнее описать как вы бы решали задачу? Можете закомитить свой код на гитхаб? У вас самый популярный комментарий. Но вы пишите общие фразы. Из них я не могу понять что точно вы подразумеваете. Хотелось бы разобраться.
aamonster
14.11.2021 22:28+6Кажется, мы с вами друг друга не понимаем. Вы, похоже, исходите из того, что здесь можно применить ML, и оно решит задачу. Я практически уверен в обратном.
Смотрите. Как выглядит типичная задача ML? Допустим, задача классификации? У нас есть набор исходных данных (вектора свойств объектов) и проставленные кем-то классы для этих векторов. Модель (нейронная сеть или ещё что) учится, а потом, когда ей предъявляют объект, определяет его класс.
Ключевой момент: расклассифицированная обучающая выборка.
Задача приближения функции – аналогично, но для входного вектора задаётся значение-результат.
У нас в задаче ничего такого нет. Есть только значения векторов, но нет истинных результатов. Модель учить не на чем.
Можно было бы создать обучающую выборку, если нарушить закон и проследить за избирателями (делать это надо незаметно как для них самих, так и для персонала УИК и наблюдателей, чтобы не повлиять на результат). Причём на самых разных участках. Нереально.
Так что у вас просто нет данных для обучения.
И внезапно вы берёте ожидаемые значения выхода из модели Шпилькина. Ok, ML отработает – но это будет не решение исходной задачи, а приближение модели Шпилькина. Т.е. вы решили не ту задачу, которую заявили, и даже не заметили этого :-(
ЗЫ: Уверен, что часть плюсов к тому моему комменту не за дело, а просто от людей, не согласных с полученными вами результатами (и положенными в их основу гипотезами – тут достаточно таких комментариев). Но моя претензия не к этому (эти гипотезы – отдельная тема, заслуживающая внимательного рассмотрения... В этом плане мне понравилась ваша статья про изменения результатов в зависимости от расстояния до крупных городов), а именно к методологии.
zzzzbh Автор
16.11.2021 15:24Спасибо за более развернутый комментарий. Очень приятно, что вы и предыдущую мою статью прочитали! Я так понял вам не нравится та часть статьи, в которой решалась задача регрессии. Обстоятельства, следующие: у нас есть массив данных об объектах класса УИК. Объекты характеризуются такими признаками как: местоположение, размер участка, количество проголосовавших, результат КПРФ, результат ЕР. Все множество участков разбито на два кластера: «ядро» и «хвост». Для участков из хвоста мы потеряли результат Единой России. Нам нужно сделать наилучшую попытку угадать результат партии Единая Россия на участках в хвосте. Поэтому мы используем ядро для обучения модели. С помощью модели предсказываем результат ЕР в хвосте. Я правильно вас понял? Вы считаете, что в ядре нет истинных результатов?

Darel13712
16.11.2021 16:00+1По сути вы сказали "вот эта часть данных нам не нравится, поэтому мы её выкинем". Ок, это действительно странно, что результат зависит от явки, можно поверить экспертам, но потом вы сказали "а теперь заполним эти данные тем же, что в той части данных, что нам нравится".
Во-первых, это очень смелое предположение, что можно по четырем признакам предсказать результат выборов.
Во-вторых, эта модель не предсказывает количество вбросов. Для этого нет ни признаков, которые могут содержать подобную информацию, ни целевых значений, чтобы построить модель. Нет ни одного УИК, на котором известно, сколько было вброшено голосов -- нет задачи регрессии количества вброшенных голосов. У вас есть только предположительные УИК, на которых было 0 вбросов.
Вместо этого просто заменяете часть данных на среднее значение из близких УИК. Примерно такие результаты получились бы, если бы вы сказали "а вот теперь, когда мы выбрали данные, которые нам нравятся, предположим, по всей стране такие же результаты". И не нужно было никакие модели для этого обучать и создавать иллюзию искусственного интеллекта.
Даже при условии, что задача регрессии количества вбросов была заменена на регрессию количества голосов, это не серьезно делать по тем признакам, что есть, используя KNN.
zzzzbh Автор
16.11.2021 17:15-1Здравствуйте!
Во-первых я не спорю, что модель простая. Буду рад, если кто-то разовьет тему, добавит признаков и напишет статью, сравнит с моим результатом и покажет, что его модель лучше.
Во-вторых мы не пытаемся предсказать количество вбросов. Мы пытаемся предсказать результат партии Единая Россия. Если не нравится такой вариант, можно попробовать предсказать явку на участках.
Последнее утверждение, насколько я понял, это повторение во-первых. Возможно, вы порекомендуете, какие признаки использовать?
kraidiky
14.11.2021 15:36+6Так Шпилькин тем же самым занимается последнее время. В своём последнем анализе голосования за поправки он фактически написал: Предположим, что вот этот сгусток ЦИК-ов, относящихся к крупным городам, продемонстрировавшим наименьшую явку является единственными настоящими результатами, а вся остальное - подтасовка. Посмотрите, какая огромная оказывается у нас подтасовка. Если бы он такое на экзамене по матстатистике выдал, его бы выперли с экзамена с двойкой, но для наших несогласных вполне проканывает.
https://st.golosinfo.org/store/upload/doc/152193/cover-71047b4320407cde9a9ede7d71e83669.jpg по его утверждениям только кластер на явке 0.4 является настоящим, а всё остальное подтасовка. Если проканало у шпилькина, то почему бы автору статьи не проделать то же самое. Ну не проканало и не проканало, в следующий раз поверят.

uhf
13.11.2021 20:18+27Почему-то электоральные аналитики свои расчеты строят на гипотезе, что социальная среда в России однородна, и близко расположенные участки должны показывать похожие результаты.
На деле это не так. Я уже приводил пример, что допустим, есть УИК в ЗАТО (Закрытое административно-территориальное образование) — по сути, это военный городок, там большинство военнослужащие.
Тут же недалеко, есть УИК в поселке с крупным предприятием, на котором трудятся большинство местных жителей, получают неплохую, по местным меркам зарплату, и директор которого является членом ЕР.
И еще один УИК, в соседнем селе — в котором нет ни военных, ни работы, ни дорог, ни перспективы.
Так вот, результаты с этих трех УИК сильно отличаются без всяких вбросов.
Я не утверждаю, что вбросов вообще нигде не было, но так просто «обрезать» и «усреднять», объявив «аномалиями», тоже нельзя.
kAIST
13.11.2021 20:52+3Даже в пределах одного района города бывает очень разный контингент людей. Тут живут относительно довольные жизнь молодые семью, на соседней улице озлобленные пенсионеры, а чуть дальше в основном маргиналы. Вот тоже не понимаю, почему они все должны голосовать одинаково.
FinExpert
14.11.2021 00:25+13утопическая картина. по факту с точечной застройкой жители новостроек и домов где больше пенсионеров ходят на один участок.
В нормальной картине отличия есть, но не превышающие критических значений. Дальше как с военными голоса аномальные, потому что сфальсифицировали. Мифы про лояльных бюджетников и пенсионеров в значительной степени - мифы.
zzzzbh Автор
14.11.2021 00:50+1Спасибо за комментарии! Я с вами согласен. Я использовал примитивную модель. Но ее можно улучшить и повысить точность. Нужно добавить дополнительные данные. Есть идеи, где их добыть?
anonymous
00.00.0000 00:00Forget
13.11.2021 21:22+13Когда о таком говорят, то речь обычно не о близко расположенных участках, а об участках которые находятся буквально в одном здании. Причем если на таких участках мало наблюдателей, и они "правильные", то явка отличается на десятки процентов. Так же наблюдается интересная закономерность - чем выше на участке явка, тем более однообразно люди на участке голосуют - это и есть "хвост кометы", который объясняют вбросами. Собственно если отбрасывать все такие странные УИКи люди в нашей стане оказываются вполне себе однородными, по крайней мере без резких пиков на пустом месте.
Примеры были, выборы в дугих старанах, выборы РФ 2000
Выборы 2000 г

Явка в целом большая, но большая часть голосов, как ни удивительно, кучкуется в одной области. Посмотрим что было в 2016
2016
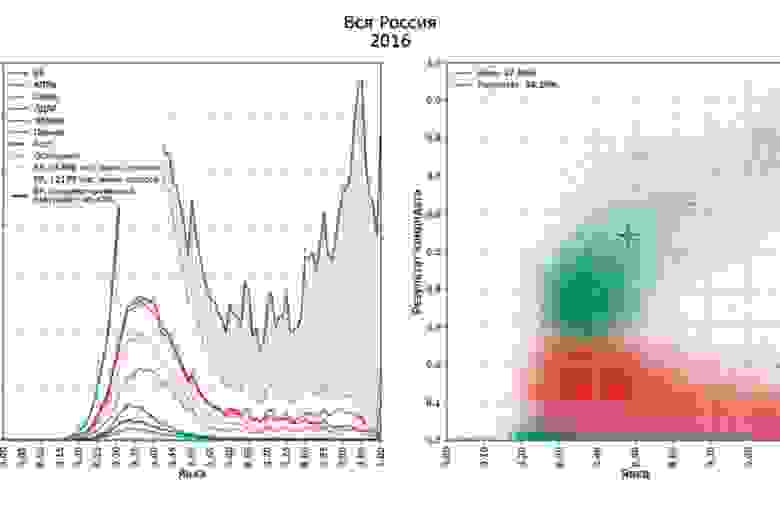
Чем больше людей приходит, тем более размазанным оказывается ядро. График в статье тоже выглядит интересно, не нем можно заметить регулярную сетку в верхней части графика:

Самое забавное что это не ошибка - это крайне похоже на результат "подгона" на участков результатов под конкретный процент. Похожую сетку можно увидеть на голосовании за поправку:
2020, голосование за поправку
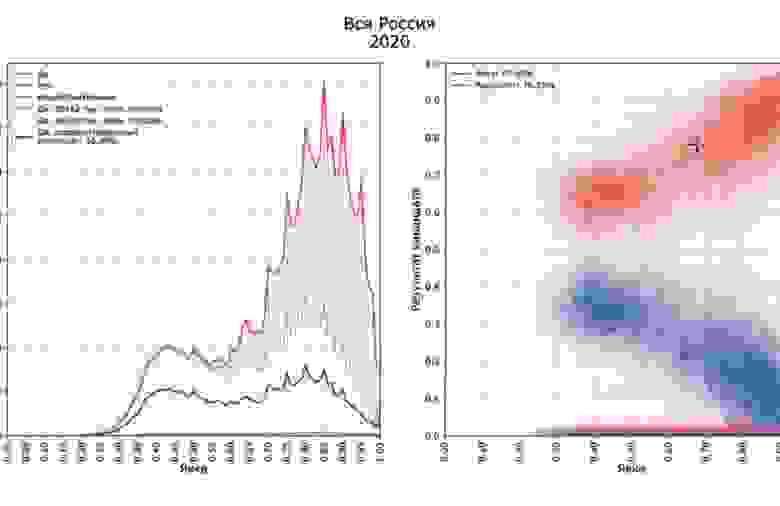
Не знаю как вам, а мне такой способ поиска проблем кажется вполне убедительным. И он показывает что в среднем результаты по стране вполне себе монотонные, пусть на вашем примере какие-то участки и будут выделяться, но на масштабах страны с большей вероятностью будут выделятся именно проблемные участки. К сожалению, по данным текущей детализации (участок-процент за каждый пункт) более точной картины (чтоб отличить действительно странные участки) построить нельзя. Более интересны в этом смысле результаты электронного голосования, там можно выделить каждый отдельный голос, и отделить время голосования (с определенной, пусть и загрубленной точностью). Но это уже другая история
Картинки взяты отсюда
uhf
14.11.2021 08:00Да я не возражаю, странности есть. Ту же «пилу» вряд ли можно объяснить естественными процессами. Однако выше привел примеры, когда высокая явка с однообразным голосованием могут быть следствием территориальной неоднородности избирателей.
С 2000 года страна изменилась, ускорилось расслоение, возросла напряженность, появилось много людей, заинтересованных в сохранении текущей политической системы, усилились их возможности по административному давлению. Сложно это все учесть в математической модели.
tyomitch
14.11.2021 13:20+2ускорилось расслоение
В чём именно? Федерализацию, наоборот, развернули вспять -- татарам запретили писать латиницей, всем остальным республикам запретили называть своих глав президентами, и т.д.
uhf
14.11.2021 13:46Имелось в виду классовое расслоение.
tyomitch
14.11.2021 14:09+1ОК, просто в первой части комментария речь шла про "территориальную неоднородность избирателей" -- я подумал, что и во второй про неё же.
А почему вы считаете, что классовое расслоение ускорилось? Коэффициент Джини между 2000 и 2015 почти не изменился:
uhf
14.11.2021 15:24-1Моя оценка субъективна. Авторитаризм укрепился — значит, и классовое неравенство усилилось. Одно без другого не бывает.
Конкретно к коэффициенту Джини есть вопросы: насколько достоверны исходные данные (по официальной статистике, например, у нас безработица 5%), учитывается ли теневая экономика и коррупционные доходы, и т.д.
avshukan
16.11.2021 14:10Не хватает обоснования, что классы как-то кучкуются по разным избирательным участкам. Тем более на таких больших числах (УИКов - тысячи).
И хуже всего, что есть подтверждения (к сожалению не найду сейчас пруфы), что во время президентских выборов, там где были наблюдатели в Чечне - результат был похож на среднероссийский, а там где не было - зашкаливало.Расслоение скорее не среди избирателей, а среди фальсификаторов





anonymous
00.00.0000 00:00zzzzbh Автор
14.11.2021 00:57Здравствуйте! Спасибо за комментарий! Я согласен с вашей логикой и модель можно уточнить. Но такие подробные данные, как вы описываете(какая у кого зарплата и доволен ли ей человек) сложно добыть. Можно использовать данные Росстата по регионам по крайней мере. В рамках данной работы использована простая модель.
zzzzbh Автор
14.11.2021 01:01Здравствуйте! Спасибо за комментарий! Я согласен с вашей логикой и модель можно уточнить. Но такие подробные данные, как вы описываете(какая у кого зарплата и доволен ли ей человек) сложно добыть. Можно использовать данные Росстата по регионам по крайней мере. В рамках данной работы использована простая модель.

SergeyMax
14.11.2021 10:38УИК в ЗАТО (Закрытое административно-территориальное образование) — по сути, это военный городок, там большинство военнослужащие.
Вы путаете, ЗАТО - это не военный городок, это обычный город, военнослужащих здесь столько же, сколько и в остальных городах.
alex1spb
14.11.2021 17:47+2А какие есть доказательства, что военный городок голосует за Единую Россию?)

monane
13.11.2021 20:33-3А вы храбрый. Будьте готовы сейчас вам расскажут что нейронка ваша ошиблась и вы резулт подогнали. Особенно много их будет в рабочие часы, ну кому за что платят)), но могут быть и вечерние смены. А то что она сложила и резулт совпадает (даже мягче 14 против 20) с выкладками Шпилькина, вам ответят в таком ключе https://www.kp.ru/daily/27152/4249203/ ;-) .
kAIST
13.11.2021 20:45+12То есть люди, которые несогласны с чьим то мнением и достаточно аргументированно своем мнение высказывают, это ни что иное как кремлеботы? Конструктивные дискуссии у нас сейчас не в почете?
MilesSeventh
14.11.2021 07:58-1Не вижу чтобы в комментарии это утверждалось.
MilesSeventh
15.11.2021 22:27+1Вы чем минусовать, объясните мне, олуху, каким кретином надо быть чтобы утверждение с квантором существования понять как утверждение с квантором всеобщности, а потом с умным лицом еще предъявлять за какие-то конструктивные дискуссии?

Popadanec
14.11.2021 09:16Ну вообще то да, и давно. Особенно в темах связанных с политикой. Есть правильное мнение и «не правильное», за которое не смотря на конструктивность/ссылки/подтверждения сливают карму, чтобы пользователь по меньше оставлял комментариев, а лучше вообще свалил с ресурса.
Popadanec
14.11.2021 13:54Ну вот собственно явное подтверждение. Вместо возражений что это не так, молча сливают карму потому что не нравится мой комментарий. Кучка отщепенцев радикалов, запугала существенную часть аудитории, в результате высказываться можно либо радикально против власти, либо имея большой резерв кармы, иначе ограничения на комментирование.
Некоторым на столько не нравится, что они перейдут в профиль и пройдутся палкой по всем комментариям подряд, даже не читая что там написано. Не раз такое наблюдал на себе.
monane
15.11.2021 12:00-1То есть люди, которые несогласны с чьим то мнением и достаточно аргументированно своем мнение высказывают, это ни что иное как кремлеботы?
Это вы написали, а не я. Часто обвиняют? ;)
Конструктивные дискуссии у нас сейчас не в почете?
Конструктив бывает разный, заболтать, создать видимость массовой поддержки/неприятия тоже для кого то конструктив. Заказчика например. Этого можно избежать, если например сломать привычный для оппонента ход действий. Один из методов провокация. Мне безразличны минусы и карма, но цель как минимум у назовем это так "воображаемых оппонентов" )) не достигнута. В данном треде почти отсутствует "а в америке негров линчуют" И обсуждение тех деталей присутствует. Аж первый пост человека регнутого в день статьи это попытка раскатать сетку ТС. В общем все). Изучать можно всегда и методы бывают разные.
Popadanec
15.11.2021 15:33+1Меня обвиняли и не раз. Просто по одному нейтральному комментарию в сторону власти. Их не смутило что акк у меня старый, комментов на нём уже за три тысячи и что большинство комментов темы политики не касается.
Минус в карму весь диалог от них, добиться ответов от таких бесполезно, да и спорить с дублем(акк чтобы оставлять сообщения и чтобы не слили карму на основном) нет никакого смысла.
anonymous
00.00.0000 00:00aamonster
13.11.2021 21:31+8Да смысл критиковать его результаты? Какие данные заданы для обучения (полученные из модели Шпилькина), такие и на выходе – с возможным искажением от плохо настроенной ML модели.
Вот результаты Шпилькина интересны. Простые, понятные, без хайпа на ML, с чётко объяснёнными ограничениями модели, без чёрного ящика в виде нейронной сети. Можно критиковать, можно строить более сложные и совершенные модели.
zzzzbh Автор
14.11.2021 01:25Здравствуйте! Спасибо за комментарий! Вы правы, что моя работа основывается на исследованиях Шпилькина. Я ссылаюсь на него в первом абзаце. Хотя, конечно, нужно было бы сослаться на конкретные работы. Однако, я поставил перед собой задачу рассчитать результат выборов для каждого из участков по отдельности. И здесь нужно было применить какой-то инструмент. Можно было и без машинного обучения обойтись. Одну и ту же задачу можно решить с помощью разных инструментов.
aamonster
14.11.2021 13:29+1Нужно было без машинного обучения обойтись. У вас есть модель – просто применить её ко всем данным. Вы же вместо этого применили модель к части данных, построив обучающую выборку, а потом на обучающей выборке создали ML-модель и применили её к остальным данным.
Аналогия: у нас есть 100 чисел, надо посчитать для них значение синуса. Выбираем 10 точек, считаем для них, а для остальных интерполируем (например, сплайнами или полиномом Лагранжа). В лучшем случае получим для них значения с некоторой погрешностью, в худшем – полный бред.

DancingOnWater
13.11.2021 21:04+8А можно посмотреть результаты работы вашей нейронки для выборов во Франции, Англии, США за последние 70 лет?
aamonster
13.11.2021 21:33+2А откуда автор возьмёт для них входные данные? (не просто официальные результаты, а пары официальные/реальные для части участков – желательно случайно выбранных).
DancingOnWater
13.11.2021 22:07+9Я прочитал статью несколько раз, но я так и не нашел упоминание того, что авторы откуда-то откопали реальные результаты хотя бы для одного участка.

besteady
14.11.2021 17:48-2Там ж нет таких топорных вбросов, чтобы хвост был. Аномалии можно поискать, но это другое. Это в РФ легко понять как результаты фальшивые, а какие нет и соответственно на основе первых обучиться и скорректировать вторые

vanxant
13.11.2021 22:04А если отбросить все участки, где ер набрала больше 40%, и прогнать через волшебный бигдатамашинленинг, кпрф вообще долж6а победить!111
Ordscarrid
13.11.2021 23:35+26Начну с похвалы - по посту видно, что автор умеет видеть потенциальные применения машинного обучения в реальной жизни и уже знает о необходимости нормализации. Конец похвалы.
Откровенно говоря, на пост смотреть несколько больно.
"...В своих работах, независимые электоральные аналитики показывают..." - argumentum ad populum собственной персоной. К тому же, ответьте, пожалуйста, существуют ли НЕЗАВИСИМЫЕ аналитики? Любой человек зависит от тех, кто платит ему/ей деньги, а аналитики не из тех, кто работает на себя/развивает бизнес. Словом, зависимость хоть от кого-то да присутствует. Осталось проследить цепочку спонсирования и узнать, от кого на самом деле зависят "независимые" аналитики.
"Нормальная явка" - это нечто интересное. Обычно используют некие статистические показатели, чтобы показать, какая явка является "нормальной". Ну, мода там, медиана... Может, по квантилям пройдётесь. Словом, вариантов много. Но нет же, у Вас "нормальная" явка именно там, где результаты примерно равны. Хотя это решение ничем не обосновывается.
DBSCAN- почему именно такие параметры? Что есть "хороший результат" в случае с кластеризацией? Вам понравился кластер и поэтому Вы считаете данный результат "хорошим"? Тут уже включается субъективность. Вы бы хоть какие-то метрики кластера включили для подобия объективности (ну, туда попадает 90% точек, к примеру [хотя там дай Бог 20% - во всех остальных случаях были фальсификации?]).KNeighboursRegressorвкупе с Вашим выбором участков с "нормальной явкой" приводит к просто невообразимо плохим последствиям. Значение голосования за ЕР, предсказанное KNN, будет НЕ ВЫШЕ наибольшего значения, которое было в местах с "нормальной явкой". Если у вас на "нормальном" участке максимум 400 человек проголосовало за ЕдРо, тоKNNникогда не скажет, что хоть на каком-то участке проголосовали за ЕдРо 400+! Я уж молчу о том, что Вы не использовали параметрweights = 'distance'вKNN.Наконец, НЕ ДОСТАТОЧНО использовать информацию о расположении участка, проценту за КПРФ и количестве проголосовавших. Вы как минимум не учитываете информацию о том, в каком регионе происходит дело. Есть условно Хакасия Коновалова. Если Коновалов - хороший руководитель, то рейтинг у КПРФ в Хакасии высокий. Рядом есть Красноярский край Усса, представителя ЕдРа. Если Усс - хороший руководитель (да, и от партии власти бывают такие), то в Красноярском крае у ЕдРа будет высокая поддержка. Однако инфрмацию о регионах Вы не учитываете. Более того, Вы можете ПОЛНОСТЬЮ убрать из своих данных регион с обоснованно высокой поддержкой ЕдРа. И тогда даже если у ЕдРа было на самом деле 60%, Вы впишете им условных 40%.
Вишенка на торте - посмотрите на предпоследний график. Видите забавный хвост слева? Он вызван тем, что автор пытается предсказать количество проголосовавших за ЕдРо с помощью
KNN. На одном участке проголосовало условно 100 человек - из них 40 за ЕдРо, - на соседнем, в деревушке, проголосовало 10 человек - 6 за ЕдРо, 4 за КПРФ - этот участок посчитали аномальным и решили засунуть в модель.KNNсмотрит, что на соседнем участке проголосовало 60 человек за ЕдРо и говорит: "В этой деревеньке, потому что она рядом, 60 же человек проголосовало за ЕдРо!" Отсюда и берётся хвост слева. То есть когда автор пытался в машинное обучение, он создал ужасного левиафана, КОТОРЫЙ КАК РАЗ ЯВНО И ФАЛЬСИФИЦИРУЕТ РЕЗУЛЬТАТЫ. Если кто-то попросит, повторю весь эксперимент и на конкретных примерах покажу, в каких участках способ автора приводит к ОТКРОВЕННЫМ ФАЛЬСИФИКАЦИЯМ.
P.s. если я не ошибаюсь, в Хабр (и сайты в целом) можно вставлять изображения
Plotly, а не "скринить" их и вставлять картинчками. Теряется интерактивность, гражданин!zzzzbh Автор
14.11.2021 00:33+3Здравствуйте! Спасибо за комментарий развернутый! Начну с похвалы. Он тянет на целую отдельную статью!
В целом я согласен с вашей критикой, так как модель, которую я использовал очень примитивная и ее можно сильно улучшить. Одна из целей публикации этой статьи - получение критических комментариев для улучшения модели.
Подробнее по пунктам:
1. Согласен. Здесь надо бы сослаться на конкретные работы. Желательно в рецензируемых журналах. Сделаю.
2. Согласен. Термин не вполне корректен и может вызывать ассоциацию с нормальным распределением, хотя я и взял его в кавычки. Можно заменить, например, на участки из плотного кластера.
3. Выбрал такие параметры, чтобы площадь ядра была максимальна и все еще не появлялись дополнительные кластеры, кроме основного. В основном кластере около 42 процентов от общего числа избирателей. Так как он более плотный, площадь его существенно меньше, чем у "хвоста". Насколько я понял Сергей Шпилькин использует k-means для выделения основного кластера. И у него он получается размером немного больше.
4. Можно провести эксперимент и оценить, насколько последствия невообразимо плохи. Что вы порекомендуете использовать вместо KNN? weights = 'distance' попробую.
5. Согласен. Важное замечание. Для уточнения модели можно использовать, например, данные Росстата по регионам.
6. Предпоследний график мне тоже не нравится. В идеале там должно быть два облака похожих по форме на эллипс. Одно выше другого. Что касается вашего предположения, боюсь от хвоста оно не избавит. В модели используется в качестве параметра размер участка. И разница в 10 раз будет учтена. Есть другие предложения?
7. На счет Plotly посмотрю, как это реализовать. Можно еще скачать ноутбук с гит хаба. Там интерактивность присутствует.
Если вас заинтересовал объект исследований, напишите мне в личку. Можем обсудить как доработать модель. Еще раз спасибо за критические замечания!

buratino
14.11.2021 09:44+2С вишенкой у вас неувязочка, которая говорит о том, что вы несколько не в теме. Избирательного участка "в этой деревеньке" нет, потому как избирательные участки делаются так, чтобы на каждый участок приходилось примерно одинаковое число избирателей. Избирательный участок для этой деревеньки находится в соседнем селе, а то и в городе, и нарезка избирательных участков "правильным образом" - это отдельный вид эээ деятельности, который частично нивелирует утверждения выше про довольных властью избирателей с одной улицы и старых бабок, традиционно голосующих за красных, с другой. Ежели подобный расклад обнаруживается, то власть перекраивает границы избирательных участков так, чтобы "неправильная улица" была разбита на две части, приписанные к разным избирательным участкам, так чтобы нивелировать возможное протестное голосование на конкретном участке

egnodus
14.11.2021 20:01А доказательства подбной "эээ деятельности" можно?
buratino
14.11.2021 22:08+1эээ... это надо быть в курсе местной географии и истории изменения избирательных участков.Я например, в курсе своей местной, но в соседнем районе уже не в курсе. С историей еще хуже. На сайте ЦИКа хрен найдешь не только историю, но и текущее соотношение "адрес-избирательный участок". С постановлениями местных администраций о границах округов еще хуже - их во-первых хрен найдешь, во-вторых в них встречаются косяки, в-третьих, к этим постановлениям выпускаются дополнительные, которые еще более хрен найдешь. Но кроме ползучей "оптимизации" избирательных участков встречаются еще и радикальные изменения - например с преобразованием районов в городские округа в Московской области ЕР протащила выборы в местные советы с многомандатными избирательными округами. Если раньше по отдельному одномандатному округу имел все шансы пройти местный бузотер (мало участков, много лично знакомых и в избирательных комиссиях и в наблюдателях), то теперь такой номер провернуть труднее, т.к. округ больше в пять раз, участков на округ в три раза больше (да, часть участков сократили), бузотёру сложнее проводить и агитацию, и наблюдение (даже чисто физически, т.к. в один округ попали участки, находящиеся до 60 км друг от друга)

ivodopyanov
14.11.2021 11:02+3В своих работах, независимые электоральные аналитики показывают, что подобная картина может наблюдаться при вбросе голосов за партию, результат которой растет с явкой. Причем в ядре находятся участки с «нормальной явкой», на которых не было фальсификаций, а хвосты соответствуют участкам с «аномальной явкой», где результаты выборов недостоверны.Кто еще из "электоральных аналитиков", кроме Шпилькина?
А еще подобная картина может наблюдаться, потому что одна партия хорошо мобилизует свой электорат, а другие - нет. Или потому что электорат сам по себе политически активный по каким-то причинам, и голосует за одну партию. Исходная предпосылка сама по себе висит в воздухе.
tyomitch
14.11.2021 13:34+2Например https://kireev.livejournal.com/tag/выборы%20в%20Госдуму%202021
Нет, кратное различие явки и рейтинга одной партии между УИКами в одном здании не может наблюдаться ни при каких реалистичных предпосылках.

n0isy
14.11.2021 14:04Не в угоду власти, а науки для: постулат, что явка и выбор не зависят друг от друга необходимо доказать! Допустим контр пример: люди разочарованы во власти и правящей партии и не верят в выборы => из этого следует => И низкая явка, И голосование оставшихся за условную "оппозицию".
tyomitch
14.11.2021 14:25+1И количественные оценки объема манипуляций совпадают, например, с оценками, которые были получены при анализе результатов участков с наблюдателями и без в других работах. Есть довольно много разнообразных свидетельств, которые подтверждают, что никакой неоднородности на самом деле нет, а есть нормальное довольно однородное население страны со своими отклонениями и особенностями в разных местах, но, в общем, отклоняющиеся от одного общего среднего. Например, в этот раз были наблюдатели в Чечне, и они привезли результаты голосования, очень похожие на результаты голосования по всей стране, то есть чуть выше процент Путина, чуть ниже процент Грудинина, но в целом никаких запредельных показателей нет, – сказал Сергей Шпилькин.
Подробности и графики на примере одного города в Кузбассе: https://www.golosinfo.org/articles/145561

{kind=link}
sunsexsurf
Гитхаб пустой (This repository is empty), можете перезалить?
zzzzbh Автор
Спасибо! Поправил.