
При создании разных сервисов очередей часто возникает вопрос: «А как лучше реализовать систему уведомлений о событиях в очереди?» Она часто бывает сложнее в реализации, нежели сам сервис очереди. Система распространения уведомлений встречается во многих программных комплексах. Как правило, клиентов у таких систем немного: десятки, реже — сотни.
Давайте обсудим способы построения таких систем в случаях, когда клиентов не сотни, а сотни тысяч.
Предположим, что нам надо построить сервис, способный уведомить множество подписчиков. Причём это множество достаточно велико — десятки или сотни тысяч на экземпляр.

Какие проблемы нас ожидают при решении этой задачи?
Клиентская сторона:
-
Клиент должен иметь информацию о том что происходит на сервере:
консистентно;
с минимально возможной задержкой.
Среди тысяч клиентов обязательно будут быстрые и медленные, работающие и зависающие.
Серверная сторона:
Система уведомлений клиента X не должна зависеть от скорости канала у клиента Y.
Система уведомлений вообще не должна зависеть от скоростей клиентов (обобщение предыдущего пункта).
Если порефлексировать над этими проблемами, то можно понять, какие обязательные свойства будут у системы доставки событий от сервера к клиенту. А вариативность остальных свойств даст нам множество решений.
Требования к системе
Итак, обязательные свойства:
Система доставки событий должна записывать отправляемые события в буфер (а не сокет). Запись в память даст максимальную производительность и предотвратит блокировку записывающего.
Вариативные свойства:
Либо: Клиент должен получать все отправляемые ему сообщения вне зависимости от скорости канала.
Либо: Клиент должен уметь диагностировать разрыв соединения и восстанавливать консистентность своего состояния после сбоя.
Поиск вариантов
Резиновая очередь
Рассмотрим первый из вариантов. В общем случае, с учётом обязательных свойств это можно реализовать при помощи «резинового» буфера (или очереди неограниченных размеров). Недостатки этого подхода очевидны:
При наличии медленных клиентов растёт потребление памяти системой передачи сообщений.
При наличии хотя бы одного клиента, который всегда (на протяжении очень длительного времени) не справляется с передаваемым ему потоком сообщений, мы гарантированно придём к тому, что в гости к системе постучится ООМ-киллер.
Очередь фиксированного размера
Первое, что приходит в голову, это ограничение размера очереди. Но если мы его вводим, то должны сразу предусматривать протокол действий при переполнении буфера (или очереди). Пример алгоритма работы сервера может быть приблизительно таким:
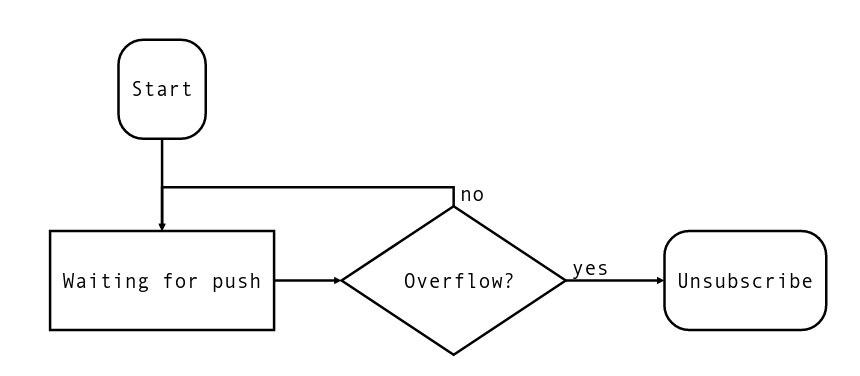
Если обнаруживается переполнение буфера, то он очищается, при этом сохраняется пометка об этом событии. Клиент реализует примерно такой алгоритм:
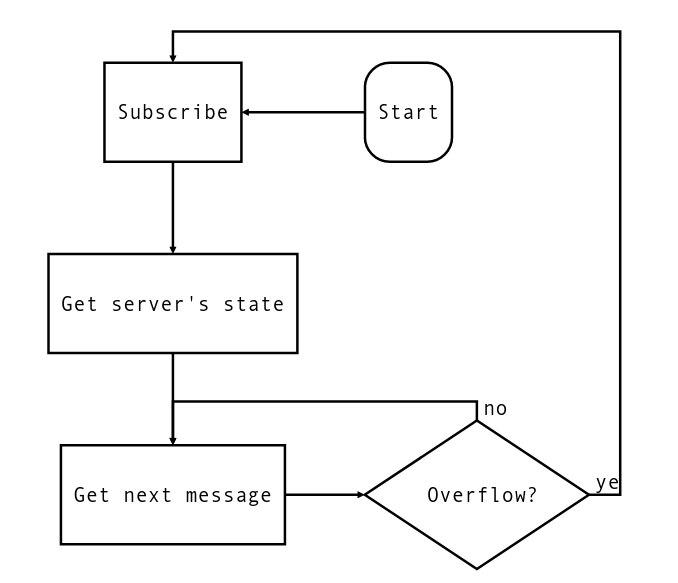
Этот алгоритм подписки требует устойчивости клиента к повторной обработке события (идемпотентность).
Реальные приложения
Если мы рассмотрим реальные приложения, то увидим такую ситуацию:
Крайне редко через канал связи pub/sub передаются сами данные. В основном передаётся самый минимум данных.
Если это чат, то через канал уведомлений передаётся информация о появлении новых сообщений в таком-то чате, об изменении пользователем своего статуса и т.д. Если это подписка-репликация, то по каналу уведомлений передаются номера последних изменённых сообщений и другая информация.
В некоторых случаях по каналу уведомлений передаются все данные, но, как правило, это сделано потому, что данных очень мало. И даже тогда предусматривается режим восстановления состояния с нуля: канал может быть разорван, клиент или сервер быть перезапущен, и т.п.
Передача состояния
Множество приложений с архитектурой pub/sub передают через систему уведомлений не сообщения, а некое состояние. Вернее, при помощи сообщений передаётся информация о состоянии сервера. Например:
Сервер присылает сообщение «на сервере 40 заказов».
Клиент сверяет со своим «у меня 38 заказов, надо получить ещё два».
Или:
Сервер присылает сообщение «клиент отправил сообщение в чат XXX и в нём стало YYY сообщений».
Клиент сверяет со своим «мой клиент смотрит в чат XXX?». И если смотрит, то «сколько у моего клиента сообщений в чате XXX?».
Редко когда архитектуру передачи уведомлений нельзя свести к передаче состояния. Обычно, если это не сделано, то, во-первых, это можно сделать. А во-вторых, если это сделать, то, скорее всего, система станет лучше (повысится производительность, отзывчивость и т.д.).
Однако мы отвлеклись. Итак, давайте выпишем проблемные вопросы системы передачи сообщений, когда через неё передаются именно уведомления. В частности, уведомления об изменении состояния.
Проблема 1: Батчинг сообщений.
Часто встречается, особенно при интеграции разнородных систем. Сервер загружает CRON-скриптом с другого сервера 100500 данных, а в систему уведомлений приходит большой пакет событий, который переполняет рассмотренные выше буферы.
Проблема 2: Клиент медленнее сервера.
Встречается не так редко. Клиент не успевает обрабатывать весь поток сообщений с сервера. В этом случае обычно стремятся к тому, чтобы клиент обрабатывал сообщения в режиме батчинга либо периодически полностью перевостанавливал своё состояние.
Примечание: «медленный клиент» может означать как недостаток вычислительной мощности на клиенте, так и низкую пропускную способность канала к нему.
Проблема 3: Большой объём памяти, требуемый для буферов между клиентом и сервером (следствие проблемы 1 и иногда 2).
Если мы будем рассматривать все эти проблемы, то увидим, что поскольку код восстановления после переполнения буфера всё равно необходим, и для медленных клиентов чем больше буфер, тем хуже, то неизбежно придём к выводу, что систему уведомлений можно редуцировать до буфера с размером 1. То есть вариант «Отписываемся при каждом отправлении сообщения в канал». Алгоритм работы сервера получается таким:
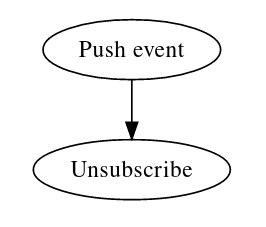
Алгоритм работы клиента:
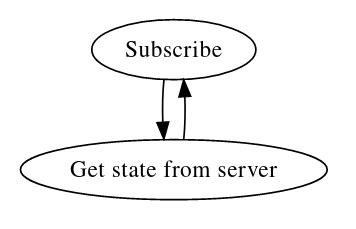
Если протокол между клиентом и сервером асинхронный, то, памятуя о паттерне «передача состояния», можем написать такой алгоритм обработки запроса subscribe на сервере:

А алгоритм обслуживания серверного push будет таким:
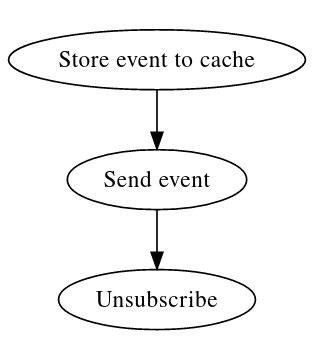
То есть:
Клиент отправляет запрос «подписаться».
В ответ получает текущее состояние.
Получает информацию о произошедшем событии.
Переподписывается.

Данные, передаваемые при изменении состояния, не имеют большого значения, поскольку на момент их получения клиент де-факто отписан от наблюдения за состоянием.
Ещё оптимизируем
Если сервер между переподписками клиента будет хранить статус изменения состояния в период отключенности клиента, то можно сэкономить дополнительный запрос состояния. Но эта оптимизация доступна только в случае, когда мы можем контроллировать разницу между:
клиент не переподписывается, потому что обрабатывает состояние;
клиент не переподписывается, потому что отключился.
Если между клиентом и сервером установлено постоянное соединение (например, TCP), то эта разница легко диагностируется: TCP установлен, значит клиент в порядке.

Достоинства получившейся схемы доставки уведомлений:
Схема крайне хорошо переносит “батчинг”.
Схема максимально толерантна к медленным клиентам.
Недостатки:
Схема оптимизирована именно под передачу состояния. Передача просто потока уведомлений ложится в схему плохо.
Request-Response?
Схема очень похожа на обычную пару запрос-ответ. Отличие в том, что сервер между запросами «помнит» о подписывавшихся клиентах, и на основании этого ответ может быть как выдан сразу, так и задержан.
Tarantool
Традиционно в Tarantool pub-sub подписки делались следующим образом: клиент выполнял запрос subscribe, который «задерживался» до появления события или до таймаута. Классический long-polling. На сервере при этом «ожидала» события хранимая процедура, со всеми связанными с её запуском накладными расходами. Какие недостатки у такого подхода?
На сервере есть поток, ожидающий событие.
На клиенте есть поток, ожидающий ответ на запрос.
Это приводило к тому, что одним Tarantool'ом было сложно обслужить больше нескольких тысяч клиентов (ограничения по числу файберов, по размеру потребляемой памяти LuaJIT и т.п.). Но начиная с версии 2.10 протокол и ядро Tarantool'а будет поддерживать систему однократных подписок, описанную выше. Ни серверу ни клиенту больше не требуется «содержать» поток, обслуживающий систему доставки событий. С помощью этой технологии теперь можно писать приложения, позволяющие одному Tarantool'у обслуживать десятки тысяч подключённых клиентов.
Между Tarantool'ами этот механизм будет выглядеть примерно так:
-- Клиент
net_box.watch(
key,
function(key, state)
-- Состояние, определяемое ключом `key`
-- поменялось на новое значение
...
-- Переподписка произойдёт после завершения
-- этой функции
end
)
-- Сервер
-- уведомляем подписчиков о том, что состояние, определяемое
-- ключом `key` теперь имеет новое значение - `new_state`
box.broadcast(key, new_state)
Старые решения pub/sub в Tarantool'е продолжат работать без изменений. Новые могут использовать этот механизм для того, чтобы поддерживать огромное количество клиентов или потреблять меньше ресурсов. Помимо того, что пользователи смогут строить свои приложения с использованием этого механизма, Tarantool будет распространять через него информацию о таких событиях:
смена мастера (лидера) в кластере;
предстоящее выключение узла;
некоторые статусы сервера.
Приложения смогут реагировать на подобные изменения и реже попадать в ситуации обработки ошибок, связанные с ними.
Применения
Пример 1
Схема типового кластера Tarantool с шардингом будет выглядеть примерно так:

Каждое хранилище — это маленький кластер (replica set) из Tarantool'ов. Роутер удерживает соединения с каждым хранилищем (с каждым его узлом), и благодаря этому:
обнаруживает лидеров replica set'ов;
мониторит работоспособность узлов;
перенаправляет пользовательские запросы к хранилищам.
Если в кластере, скажем, 50 хранилищ, каждое из которых представляет собой replica set из трёх нод, то только для обнаружения лидеров роутер вынужден «держать на балансе» 150 потоков (файберов). Это значительные накладные ресурсы как на память, так и на CPU. Но начиная с версии 2.10 требования роутеров к ресурсам значительно уменьшатся благодаря внедрению данного механизма.
Ещё пример
Несколько лет назад мы строили систему оповещения множества пользователей о происходящих на сервере событиях. Она использовалась для уведомления примерно 100 тыс. исполнителей (преимущественно водителей такси) о появляющихся заказах. Об этой системе даже написали статью. В то время для масштабирования мы выделяли одно ядро CPU на 3-5 тыс. водителей. Система уведомления 100 тыс. исполнителей использовала два 16-ядерных сервера. И основным ограничителем была память LuaJIT. С использованием описанного механизма можно редуцировать сервис всего до одного ядра.
Заключение
Tarantool иногда называют базой данных, иногда сервером приложений. Но это нечто большее. Tarantool — это конструктор, с помощью которого вы можете построить что-то мощное и серьёзное, и при этом не требовательное к ресурсам. В статье описан один из новых «кубиков», позволяющий сделать недорогую систему уведомлений огромного числа подписчиков.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.