
JDK 17 был выпущен 14 сентября. Это релиз Long-Term Support (LTS), что означает, что он будет поддерживаться и получать обновления в течение многих лет. Также это первый выпуск LTS, в который включена продакшн-реди версия ZGC. Освежим вашу память: экспериментальная версия ZGC была включена в JDK 11 (предыдущий выпуск LTS), а первая продакшн-реди версия ZGC появилась в JDK 15 (выпуск не LTS).
В JDK 17 ZGC получил 41 исправление и улучшение, и я остановлюсь на некоторых из них. Но прежде чем перейти к этому, если вам интересно узнать больше о возможностях/улучшениях ZGC в предыдущих выпусках JDK, прочитайте мои прошлые сообщения.
Теперь давайте рассмотрим, что нового в JDK 17 с точки зрения ZGC.
Динамическое количество потоков GC
В JVM уже давно существует опция -XX:+UseDynamicNumberOfGCThreads. Она включена по умолчанию и указывает GC на то, что он должен разумно подходить к определению количества потоков GC, которые он использует для различных операций. Количество используемых потоков будет постоянно переоцениваться и поэтому может меняться со временем. Эта опция полезна по нескольким причинам. Например, бывает трудно определить оптимальное количество потоков GC для данной рабочей нагрузки. Обычно это происходит так — вы пробуете различные настройки -XX:ParallelGCThreads и/или -XX:ConcGCThreads (в зависимости от того, какой GC вы используете), чтобы понять, какая из них дает наилучший результат. Что усложняет ситуацию: оптимальное количество потоков GC может меняться со временем, когда приложение проходит через различные фазы, поэтому установка фиксированного значения в данном случае может быть неоптимальной по своей сути.
До JDK 17 ZGC игнорировал -XX:+UseDynamicNumberOfGCThreads и всегда использовал фиксированное число потоков. Во время запуска JVM ZGC использовал эвристику, чтобы решить, каким должно быть это фиксированное число (-XX:ConcGCThreads). После того, как такое число было установлено, оно больше не менялось. Начиная с JDK 17, ZGC теперь учитывает -XX:+UseDynamicNumberOfGCThreads и пытается использовать как можно меньше потоков, но достаточное их количество, чтобы поддерживать сбор мусора с той скоростью, с которой он возникает. Это помогает избежать использования большего количества времени CPU, чем требуется ZGC, что, в свою очередь, делает его доступнее для потоков Java.
Также обратите внимание, что когда эта функция включена, значение параметра -XX:ConcGCThreads меняется с "Использовать столько-то потоков" на "Использовать не более стольких-то потоков". Но если у вас нестандартная рабочая нагрузка, как правило, вам не нужно возиться с -XX:ConcGCThreads. Эвристика ZGC сама подберет для вас оптимальное максимальное количество потоков, основываясь на размере системы, в которой вы работаете.
Чтобы проиллюстрировать эту функцию в действии, давайте посмотрим на некоторые графики при выполнении теста SPECjbb2015.
Первый график показывает количество потоков GC, используемых в течение всего времени работы. SPECjbb2015 имеет начальную фазу разгона, за которой следует более длительная фаза, где нагрузка (скорость закачки) постепенно увеличивается. Мы видим, что количество потоков, используемых ZGC, отражает объем работы, которую ему необходимо выполнить, чтобы не отставать. Только в некоторых случаях ему потребуются все (в данном случае 5) потоков.
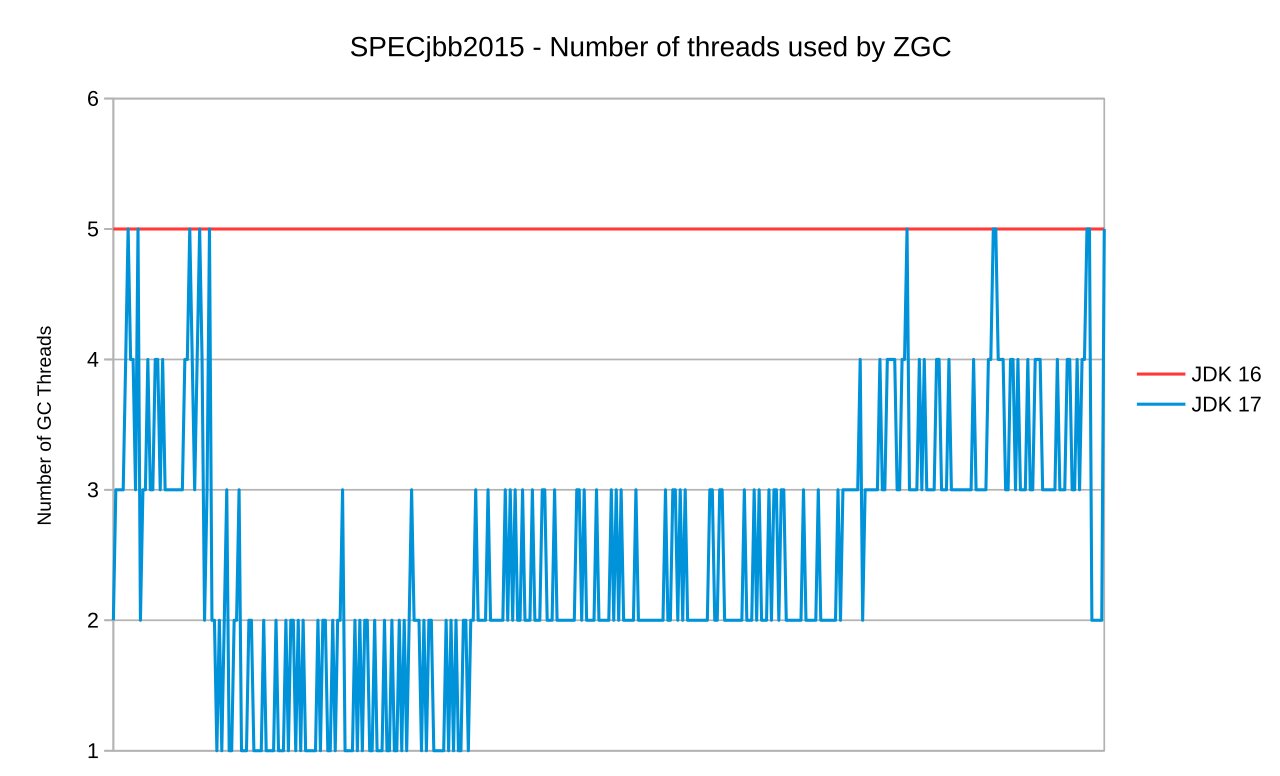
На втором графике мы видим результаты бенчмарков. Поскольку ZGC больше не использует все потоки GC постоянно, мы отдаем больше времени CPU для Java, что приводит к лучшей пропускной способности (max-jOPS) и лучшей латентности
(critical-jOPS).
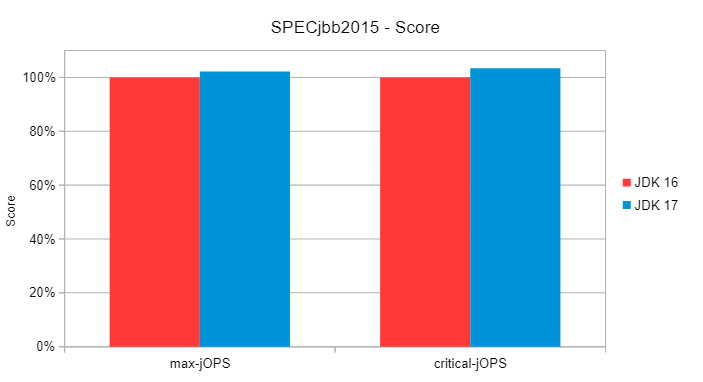
Если вы по какой-то причине хотите всегда использовать фиксированное количество потоков GC (как в JDK 16 и более ранних версиях), то можете отключить эту функцию, используя -XX:-UseDynamicNumberOfGCThreads.
Быстрое завершение работы JVM
При использовании ZGC вы могли заметить, что завершение запущенного Java-процесса (например, нажатием Ctrl+C или вызовом приложения System.exit()) не всегда происходит мгновенно. Иногда может потребоваться некоторое время (в худшем случае немало секунд), чтобы JVM действительно завершилась. Это может раздражать и создавать проблемы в средах, где возможность быстрого завершения очень важна.
Почему же при использовании ZGC JVM иногда требуется время для завершения работы? Причина в том, что последовательность завершения работы JVM должна координироваться с GC, чтобы GC перестал выполнять свою работу и перешел в "безопасное" состояние. ZGC находился в "безопасном" состоянии только тогда, когда он простаивал, т.е. не собирал мусор. Если к моменту поступления сигнала завершения выполнялся очень длинный цикл GC, то последовательность выключения JVM была вынуждена ждать завершения этого цикла GC, прежде чем ZGC становился нерабочим и снова переходил в "безопасное" состояние.
Эта проблема была решена в JDK 17. Теперь ZGC может прервать текущий цикл GC, чтобы быстро перейти в "безопасное" состояние по требованию. Завершение работы JVM с запущенным ZGC происходит теперь практически мгновенно.
Уменьшение использования памяти стека маркировки
ZGC выполняет маркировку по полосам (stripe). Это означает, что куча (heap) делится на полосы, и каждый поток (thread) GC получает задание разметить объекты в одной из них. Это помогает минимизировать общее состояние между потоками GC и сделать процесс маркировки более дружественным к кэшу, поскольку два потока GC не будут помечать объекты в одной и той же части кучи. Такой подход также приводит к естественной балансировке рабочей нагрузки между потоками GC, так как полосы выполняют примерно одинаковое количество работы.
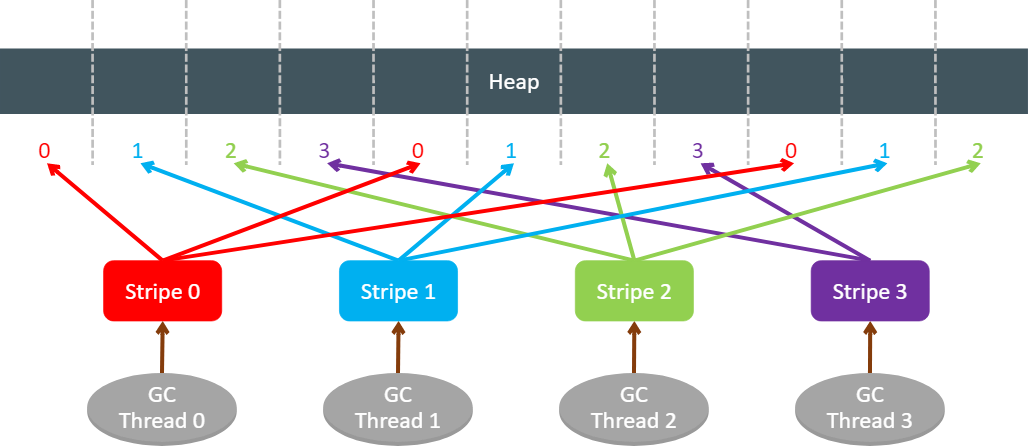
До JDK 17 маркировка ZGC строго соответствовала разбивке на полосы. Если поток GC, в процессе отслеживания графа объектов, натыкался на объектную ссылку, указывающую на часть кучи, которая не принадлежала назначенной ему полосе, то эта объектная ссылка помещалась в локальный стек меток потока, связанный с этой другой полосой. Как только этот стек заполнялся (254 записи), он передавался потоку GC, который был назначен на выполнение маркировки для этой полосы. Java-поток, загружающий объектную ссылку на еще не размеченный объект, делает то же самое, за исключением того, что он всегда помещает объектную ссылку на связанный с ним локальный стек меток и никогда не выполняет никакой фактической работы по маркировке.
Этот подход хорошо работает для большинства рабочих нагрузок, но есть и патологическая проблема. Если у вас есть граф объектов с одной или несколькими связями N:1, где N - очень большое число, то вы рискуете использовать много памяти (например, много гигабайт) для стеков меток. Мы всегда знали, что это потенциальная проблема, и можно написать небольшой синтетический тест, чтобы спровоцировать ее, но действительности нам никогда не приходилось сталкиваться с реальной нагрузкой, которая бы ее выявила. Так было до тех пор, пока разработчики OpenJDK из Tencent не сообщили, что они столкнулись с этой проблемой на практике. Значит, пришло время что-то с этим делать.
Исправление этой проблемы в JDK 17 заключается в ослаблении строгого страйпинга (разделения по полосам) следующим образом:
Для потоков GC, независимо от того, на какую полосу указывает ссылка на объект, сначала пытаются пометить объект (т.е. потенциально выйти за пределы назначенной полосы потока GC), и если он еще не был помечен, перемещают ссылку на объект в связанный стек меток.
Для потоков Java сначала проверьте, помечен ли уже объект, и если он еще не был помечен, переместите ссылку на объект в связанный стек меток.
Эти твики помогают остановить чрезмерное использование памяти стека меток в патологическом случае N:1, когда потоки GC снова и снова встречают одну и ту же ссылку на объект, помещая множество их дубликатов в стек меток. Такие копии бесполезны, потому что объект должен быть помечен только один раз. Если маркировать объект перед его переносом и перемещать только ранее немаркированные объекты, производство дубликатов прекратится.
Поначалу мы несколько колебались, по этому поводу, поскольку потоки GC теперь выполняют атомарные операции сравнения и замены, чтобы пометить объекты в памяти, принадлежащие полосам, над которыми должны работать другие потоки GC. Это нарушает строгий страйпинг, делая его менее удобным для кэширования. Потоки Java теперь также выполняют атомарные загрузки, чтобы увидеть, помечены ли объекты, чего они не делали раньше. В то же время, другие действия, выполняемые потоками GC (сканирование/отслеживание полей объектов и контроль количества активных объектов/байт в каждой области кучи), по-прежнему придерживаются строгого страйпинга. В итоге, бенчмаркинг показал, что наши первоначальные опасения были необоснованными. Время выполнения маркировки GC не увеличилось, и влияние на потоки Java также не было заметным. С другой стороны, у нас теперь есть более надежная схема разметки, не склонная к чрезмерному использованию памяти.
Поддержка macOS на ARM
Некоторое время назад компания Apple объявила о долгосрочном плане перехода линейки компьютеров Mac с x86 на ARM. Вскоре после этого в документе JEP 391: macOS/AArch64 Port было предложено перенести JDK на эту новую платформу. Кодовая база JVM является достаточно модульной, с кодом, специфичным для ОС и CPU, изолированным от общего, независимого от платформы. JDK уже поддерживал macOS/x86 и Linux/Aarch64, поэтому основные компоненты, необходимые для поддержки macOS/Aarch64, там имеются. Конечно, всем, кто планирует поставлять и поддерживать сборку JDK для macOS/Aarch64, еще предстоит работа: инвестиции в новое оборудование, интеграция новой платформы в CI-пайплайны и т.д.
С ZGC дело обстоит примерно так же. И macOS/x86, и Linux/Aarch64 уже поддерживались, так что в основном речь шла о включении сборки и тестирования этой новой комбинации OS/CPU. Начиная с JDK 17, ZGC работает на следующих платформах (см. таблицу для более подробной информации):
Linux/x64
Linux/AArch64
macOS/x64
macOS/AArch64
Windows/x64
Windows/AArch64
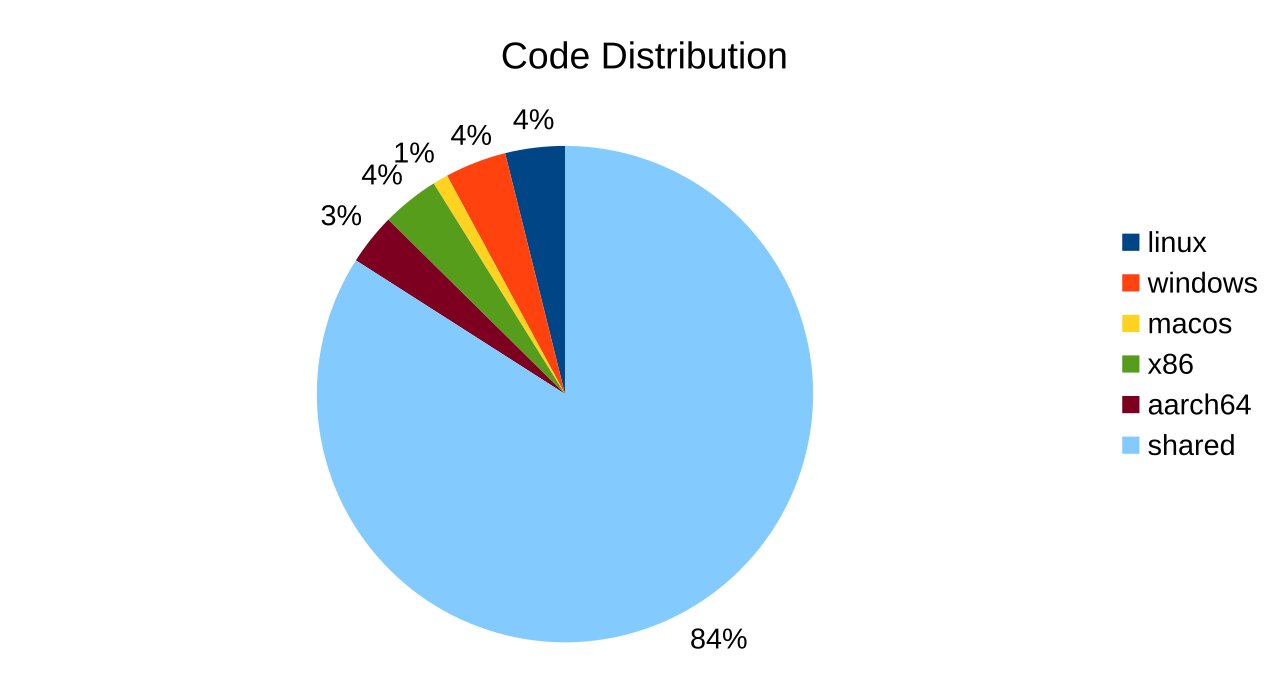
Большая часть кодовой базы ZGC продолжает оставаться независимой от платформы. Текущее распределение кода выглядит следующим образом:
GarbageCollectorMXBeans для циклов и пауз
GarbageCollectorMXBean предоставляет информацию о GC. С помощью этого бина приложение может извлекать сводную информацию (количество GC, сделанных на данный момент, общее время, потраченное на GC, и т.д.) и слушать уведомления GarbageCollectionNotificationInfo для получения детализированной информации об отдельных GC (причина GC, время начала, время окончания и т.д.).
До JDK 17 ZGC публиковал единственный бин под названием ZGC. Он предоставлял информацию о циклах ZGC. Цикл включает в себя все фазы GC от начала до конца. Большинство фаз являются одновременными, но некоторые из них представляют собой паузы Stop-The-World. Хотя информация о циклах полезна, может еще интересно знать, сколько времени, затраченного на GC, было потрачено на паузы Stop-The-World. Данная статистика была не доступна ни для одного бина ZGC. Чтобы решить эту проблему, ZGC теперь создает два бина, один из которых называется ZGC Cycles, а другой - ZGC Pauses. Как следует из названий, информация, предоставляемая каждым из них, связана с циклами и паузами, соответственно.
Вот небольшой пример, иллюстрирующий разницу между JDK 16 и 17. В примере сначала выполняется 100 вызовов System.gc(), а затем извлекается сводная информация из имеющихся GarbageCollectorMXBean(ов).
import java.lang.management.ManagementFactory;
public class ExampleGarbageCollectorMXBean {
public static void main(String[] args) {
// Run 100 GCs
for (int i = 0; i < 100; i++) {
System.gc();
}
// Print basic information from available beans
for (final var bean : ManagementFactory.getGarbageCollectorMXBeans()) {
System.out.println(bean.getName());
System.out.println(" Count: " + bean.getCollectionCount());
System.out.println(" Total Time: " + bean.getCollectionTime() + "ms");
System.out.println(" Average Time: " + (bean.getCollectionTime() / (double)bean.getCollectionCount()) + "ms");
}
}
}Запуск этой программы с JDK 16 приводит к следующему результату:
$ java -XX:+UseZGC ExampleGarbageCollectorMXBean
ZGC
Count: 100
Total Time: 424ms
Average Time: 4.24msИ запуск этого с JDK 17 дает следующий результат:
$ java -XX:+UseZGC ExampleGarbageCollectorMXBean
ZGC Cycles
Count: 100
Total Time: 412ms
Average Time: 4.12ms
ZGC Pauses
Count: 300
Total Time: 2ms
Average Time: 0.006666666666666667msВ обоих случаях мы видим, что GC выполнил 100 циклов, и каждый цикл занял в среднем ~4 мс. В JDK 17 мы также видим, что в каждом цикле было 3 паузы Stop-the-World, и каждая пауза длилась в среднем ~0,007 мс (~7 мкс).
Резюме
Опция JVM
-XX:+UseDynamicNumberOfGCThreadsтеперь поддерживается. Эта функция включена по умолчанию и указывает ZGC на то, что он должен разумно подходить к количеству используемых потоков GC, что обычно приводит к повышению пропускной способности и снижению латентности на уровне Java-приложения.Завершение работы JVM под управлением ZGC теперь происходит практически мгновенно.
Алгоритм маркировки теперь в целом использует меньше памяти и больше не склонен к ее чрезмерному потреблению.
ZGC теперь работает на macOS/Aarch64.
В настоящее время ZGC публикует два файла
GarbageCollectorMXBeans, чтобы предоставить информацию как о циклах GC, так и о паузах GC.
Дополнительную информацию о ZGC можно найти в OpenJDK Wiki, в разделе GC на Inside Java или в этом блоге.
Материал подготовлен в рамках специализации «Java Developer»
seidzi
Уже JDK 17, а я до сих пор в 8й живу, как же я отстал от жизни :(