Всем привет! Вот уже почти 3 года я занимаюсь разработкой и поддержкой программ для такой платформы как IBM i (краткое описание что это такое есть, например, тут и здесь). Как вы понимаете, данный вид деятельности неразрывно связан с тем, что тексты исходного кода надо преобразовывать в исполняемые файлы или, как будет правильнее для IBM i, в объекты системы. И вот тут начинается самое интересное...
Вспомним как все начиналось
Хотелось бы сразу заметить, что 3 года назад опыта работы программистом я не имел. У меня были лишь небольшие пет-проекты, которые создавались в C++Builder, и большое желание стать разработчиком. Естественно, что ни о каких системах сборки тогда речи не шло: C++Builder магическим образом делал из разных исходников одну программу. Да и мне было совершенно фиолетово как он это делает. Нет, я конечно знал об этапе компиляции, объектных файлах и линковке, но не как в целом это все происходит. Устроившись на должность мечты я в процессе двухмесячной стажировки начал изучать систему, ее командный язык (control language — CL), специфичный для IBM i язык программирования RPG, а так же как писать программы на языке С в данной системе. Ну и, конечно, выполнял сборку...
Устоявшийся путь сборки
В начале сборка учебных поделок производилась набором нужных CL команд в консоли. Естественно, эта рутина быстро надоела и захотелось выполнять сборку более удобным способом. Решением стали CL скрипты: все нужные команды компиляции и сборки записывались в один файл, он компилировался в программу, и когда требовалось собрать исходники, выполнялся запуск этой программы. И вот здесь хотелось бы отметить то, что сборка программ и других объектов системы по настоящее время у практического большинства наших разработчиков происходит именно таким способом. Ничего другого более умного надежного, гибкого, стандартного и т. д. почему-то никто с 90-х годов не применял...
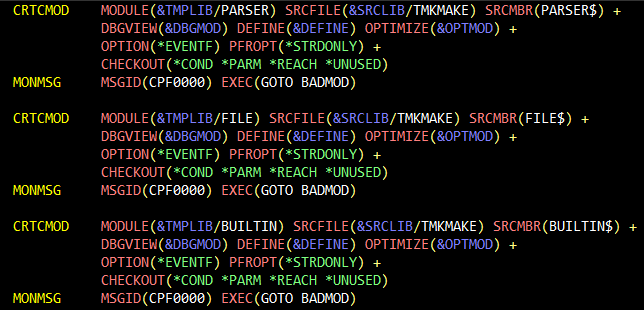
Пример CL-скрипта
Проблема ошибок сборки
Сборка проекта посредством CL скрипта, конечно, имела недостатки. И поначалу главным недостатком лично для меня было то, что ошибки сборки необходимо было смотреть в так называемом спул-файле (или джоблоге). Для этого в команду компиляции добавлялась опция, которая заставляла компилятор создавать листинг сборки (тот самый спул-файл). Далее разработчик добавлял/правил/удалял код в исходнике и запускал программу-сборщик. Если все собиралось, то и слава Богу (при этом никого не волновали предупреждения компилятора, ведь объект собрался, значит все хорошо). А если сборка падала, то чтобы узнать почему все пошло не так, надо было открыть спул-файл, найти сначала описание ошибки, затем на какой строке она случилась, перейти в исходник на нужную строку и поправить ошибку. В некоторых случаях в конце спул-файла список ошибок отсутствует. Тогда надо просто глазами по коду искать заветную надпись о том, что все плохо. Вы меня, конечно, простите, сеньоры-помидоры ibm i, но от этого способа поиска причин ошибок компиляции и сборки хочется сначала горько плакать, а потом удавиться...

Сначала в конце спул-файла смотрим какой ID у ошибки...

… затем обычным поиском ищем ее в остальной части спул-файла
RDi и компиляция исходника
Для правки исходных кодов у нас изначально была и есть такая среда как IBM Rational Developer for i (RDi). Она умеет парсить как специфичный синтаксис IBM i исходников (CL, RPG), так и обычный (С, С++). Я не буду скрывать, у этой среды есть много недостатков, но этот пост не о них. Итак, данная среда позволяет открыть исходный код напрямую из сервера IBM i. Код можно править и сохранять. Но кроме этого, RDi умеет выполнять компиляцию исходного кода. По правде говоря, компилятора на борту RDi нет. Компиляторы под все языки программирования есть только в самой системе. Поэтому она просто выполняет команду компиляции на сервере. Начав пользоваться этим способом компиляции, я нашел то, чего так не хватало: легкий и непринужденный переход к предполагаемому месту ошибки в коде: надо просто щелкнуть дважды на строке ошибки в специальном окне Error List. В целом, почти все так же, как в обычных IDE...

Список ошибок компиляции
RDi и сборка проекта
Безусловно, компиляция исходников по отдельности из RDi была удобной в плане исправления ошибок, но так же заставляла слезиться глаза, когда надо было собирать несколько объектов. К счастью, я быстро нашел как в RDi решить такую проблему — через создание iProject. Во первых этот способ позволяет хранить исходники на локальной машине, что, в свою очередь, дает возможность использовать при разработке Git. А во вторых, iProject позволяет использовать скрипт сборки всех объектов проекта и выполнять его вызовом нужного меню в RDi. При этом последняя сама заботится об отправке исходников на сервер IBM i (причем только тех, которые изменились — первое приближение к инкрементности сборки), компиляции скрипта сборки и его запуске. Ну и, конечно, выше описанный метод регистрации ошибок так же прекрасно работает. Здесь, конечно, мне пришлось повозиться с написанием "универсального" скрипта сборки, чтобы он оставлял для RDi информацию о своей работе и был легко модифицируем для других проектов. К тому времени я уже вовсю занимался боевыми задачами и использование iProject в купе с Git и "универсальным" скриптом облегчало работу в разы. Но к хорошему быстро привыкают и начинаются новые хотелки...

iProject со скриптом сборки COMPILE.CLLE (слева) и часть содержимого скрипта
Попытка велосипедостроения
Использование нового способа сборки облегчило труд, но мне стали не нравится некоторые нюансы самого процесса. Например, сборка всегда выполнялась полностью, хотя я менял только один исходник. Кроме этого, всегда собирался весь проект, хотя мне требовалось доработать лишь один объект из него. Попытки написать скрипт, который бы решал данные проблемы, не увенчались успехом. Но в этих попытках родилась идея написать отдельную программу, которая выполняла бы сборку по определенному сценарию и сама имела бы параметры запуска. Коллеги не дадут соврать, я им высказывал данную идею, но они отнеслись прохладно: мало того, что нужно написать программу, так еще надо придумать язык сценария. Тогда для меня было невдомек, что я пытаюсь заново изобрести make...

Открытие TMKMAKE
К счастью, я не начал реализацию своего make-велосипеда. Этому помешала загруженность по рабочим проектам, а так же сообщение на одном из зарубежных форумов по IBM i (уже не могу найти ссылку). Там я спрашивал, не существует ли реализации GNU make для IBM i и получил ответ, что есть такая система сборки как TMKMAKE. На просторах интернета нашлось всего две страницы 1998 года по данной системе (раз, два). Сама система в виде исходного кода была доступна на нашем IBM i сервере. Зная то, что GNU make решил бы мои вопросы, я собрал TMKMAKE и начались эксперименты...
# Variables
srclib = CSNSRC
dstlib = CSNTST
all: $(dstlib)/TEST<PGM>
$(srclib)/CMOD<MODULE>: $(srclib)/csrc.TEST
CRTCMOD MODULE($(@L)/$(@F)) SRCFILE($(srclib)/TEST) SRCMBR(CSRC) +
PFROPT(*STRDONLY) CHECKOUT(*COND *PARM *REACH *UNUSED)
$(dstlib)/TEST<PGM>: $(srclib)/CMOD<MODULE>
CRTPGM PGM($(@L)/$(@F)) MODULE($(srclib)/CMOD)Пример tmkmake-файла
БаGNUтый TMKMAKE
Буквально с первых попыток сборок учебных проектов мы с коллегами поняли, что синтаксис мейкфайла TMKMAKE не совсем соответствует стандарту GNU make и не поддерживает многих из его современных возможностей. Кроме этого, в самой TMKMAKE были обнаружены очевидные баги. С первым нам пришлось мириться, так как TMKMAKE был сделан с учетом особенностей IBM i, да и создан он был в лохматых 90-х и, вероятно, на тот момент поддерживал большую часть стандартных возможностей GNU make. По второй проблеме были сложности. IBM больше не поддерживала этот продукт (который входил в состав QUSRTOOL) и отправить им багрепорт мы не могли. Поэтому я взял на себя смелость исправить баги сам. На данный момент все обнаруженное удалось исправить, но возникли хотелки...

Изменение и расширение TMKMAKE
Изменений изначальной работы TMKMAKE на текущий момент два.
Первое изменение. Синтаксис мейкфайла у TMKMAKE был таков, что если имя цели задано строкой менее 11 символов и не имеет спецификатора типа объекта (в угловых скобках), то эта цель считалась программой (объектом с типом *PGM). Нам показалось это неудобным и неочевидным (почему именно программа, а не модуль, например?). Общим собранием мы приняли постулат: если цель не специфицирована типом, то это фальшивая цель. Сказано — сделано.
Второе изменение. Мейкфайл не поддерживал экранирование символа # обратным слешем \, а у нас многие объекты содержат этот символ в имени. Да и GNU make умеет в такое экранирование. Поэтому данное изменение так же было реализовано.
Кроме данных изменений были выполнены следующие расширения функционала TMKMAKE.
Опция EXCEPT. Добавление данной опции при запуске заставляет TMKMAKE "падать" с выбросом исключения, если обнаруживается ошибка в мейкфайле или не удается выполнить системную команду из него (до этой доработки в подобных случаях запуск завершался лишь возвратом кода ошибки и записью в джоблог). Смысл данной доработки будет ясен в разделе "Другие системы сборки".
Опция EVENTF. Применение данной опции заставляет TMKMAKE при выполнении команд из мейкфайла создавать отчет об ошибках — объект EVFEVENT. Именно благодаря этому объекту RDi показывает список ошибок и места в исходном коде, соответствующие этим ошибкам.
В итоге, использование TMKMAKE решает обе выше указанные проблемы: собираются только те цели, которые указаны при запуске TMKMAKE; если требуемый для цели пререквизит собран и его исходник не менялся, то он не будет снова собираться. Мейкфайл для проекта создается один раз и более не меняется (если не меняется состав проекта). Наверное, после всех предыдущих способов сборки, идеально!

Error List после успешной сборки из RDi через TMKMAKE
Другие системы сборки
Сборщик дядя Боб
В какой-то момент времени я нашел еще одну интересную систему сборки — BOB — better object builder. Однако ее использование, во первых, требовало наличия доступа в серверу IBM i по SSH, который у нас не поддерживается, а во вторых, поиск ошибок нужно осуществлять по спул-файлу.
Сборка на основе gradle
В настоящее время у нас развернуто построение системы сборки на основе gradle, работающего с IBM i через специальный плагин (разрабатывается подрядчиком). Данная система по gradle-файлам создает сборщик, пушит его с исходными кодами в IBM i, компилирует сборщик и запускает его. С одной стороны это хоронит все наработки по TMKMAKE. Но с другой стороны, почему бы не использовать их в тандеме? Тем более, новая система позволяет создавать свой кастомный инсталлятор, в котором можно вызвать TMKMAKE. Здесь и пригодится опция для "падения" TMKMAKE, так как новая система лишь по такому признаку понимает, что все плохо.
Как по мне, то эта новая система идеальна для релизной сборки: запустил, все собрано, все счастливы. Но она ужасно не удобна при разработке. Во первых, нет инкрементности. Да, можно указать для сборки конкретные объекты из проекта, но если сам объект состоит из нескольких подобъектов, то они будут собираться все всякий раз. Во вторых — поиск ошибок по спул-файлу — возврат на 3 года назад...
Заключение
Есть еще много интересных идей относительно TMKMAKE и я попытаюсь их реализовать. Мне хотелось бы выразить благодарность коллегам за помощь в нахождении багов TMKMAKE, тестировании разработанных фич, подкидывании идей и за интерес к этой системе сборки. Ну и отдельная благодарность тебе, читатель, что выдержал до этих строк :). Может быть получилось сумбурно, сжато/растянуто, много, непонятно, но прошу простить — это мой первый пост на Хабре. Всех с наступающим!
P.S. Кому интересно, исходный код TMKMAKE с описанными доработками лежит тут.
lumag
Расскажите, а откуда в принципе IBM i, почему эта система, и что на ней делаете?
d7d1cd Автор
Не понял Вашего вопроса "откуда в принципе IBM i". Из США, оттуда же, где фирма IBM )))
Почему у нас именно эта система сказать не могу. Она у нас с 90-х годов. На этой системе у нас работает ядро банка, мы разрабатываем и поддерживаем банковский софт, его back end.
lumag
Банк, понятно :-)
SpiderEkb
IBM i - платформа для коммерческих middleware серверов (на процессорах PowerS, не знаю, может и на других бывает). Достаочно распосранена на западе в банках, страховых компаниях etc.
Характерна тем, что там поставляется "все сразу в одной коробке" - все средства администрирования, интегрированная в систему база данныз DB2 с поддержкой как SQL, так и прямого доступа к данным, встроенные в систему компиляторы языков RPG, COBOL, C/C++, CL (командный язык системы, но на нем и программы писать можно).
Оринтирована на многопроцессный режим работы (одновременная работа множества заданий - jobs, интерактивных - терминальные сессии или фоновых - batch). Внутри система построена таким образом, что накладные расходы на переключение контекста задания сведены практически к нулю. Возможно, одним из способов для того является использование одноуровневой памяти не требующей перезагрузки сегментных регистров (размерость указаьеля в системе составляет 128 бит и кроме собственно указателя содержить еще некоторую служебную информацию). Как следствеие - очень высокая производительность именно в таком режиме - многопроцессном.
Принципы построения системы не похожи ни на что другое. Она "объектная" - там "все есть объект", который характризуется именем, типом (одним из множества предопределенных) и дополнительный атрибутами внутри типа. Для каждого объекта допустим только тот набор действий, который определен для данного типа (так, например, нельзя что-то изменить для объекта типа *PGM - программа - для этого типа не предусмотрена опреция изменения).
В целом, система специфична, но имеент очень много достаточно интересных свойств с точки зрения разработчика. Например, концепция ILE - интегрированная языковая среда. В двух словах это значит что можно написать несколько модулей на разных языках (из моддерживаемых системой) и собрать их в одну программу. Т.е. те функции, которые удобнее писать на RPG, пишем на RPG. То, что удобнее на С/С++ - пишем на С/С++. А потом собираем в одну программу и вызываем сишные функции из рпгшных и наоборот.
В РФ не сильком популярна, возможно по причине дороговизны, да и разработчиков под нее не так много. Но знаю что несоклько банков на ней работают, возможно еще какие-нибудь крупные конторы.
В целом - быстро, стабильно, надежно. Но требует достаточно глубокого вникания.
lumag
Спасибо за расказ.
Сегментные регистры — это что-то из мира x86. В большинстве других архитектур их нет. Есть таблицы трансляции их их кэши в MMU. Основная проблема возникает при сбрасывании этих кэшей. Если там аппаратные ASID (address space identifiers), это удобно. Сейчас это проникает и на другие платформы, спасибо IBM (видимо) за идею. На ARMv7(-A, -R) есть восьмибитное поле для ASID.
128-битные указатели реализованы программно или аппаратно?
В линковке модулей, скомпилированных из текстов на разных языках, ничего особо удивительногого сейчас нет. Хотя, если это сделано удобно, это хорошо. А CL тоже компилируется (и может линковаться с кодом на C)?
Сборка, я так понимаю, идет только на самой IBM i? Есть ли возможность кросс-компиляции кода? Есть ли ассемлер (POWER-овский или какой-то еще?)?