
В данной статье я хочу рассказать про то, как технически устроены бот-атаки типа парсинг цен на e-commerce сайтах, какие механизмы используют атакующие, как противостоять бот-атакам самостоятельно и с помощью прикладных решений.
Я поделюсь практическим опытом нашей компании в защите e-commerce приложений и продемонстрирую реальные кейсы противодействия парсинга и бот-атакам.
Практика парсинга цен в современном e-commerce
В рамках статьи мы сосредоточимся на атаках, которые относятся к типу Scraping по классификации OWASP. Детальную классификацию автоматизированных угроз веб-приложениям можно изучить в документе OWASP Automated Threats to Web Applications. Конечно, противодействие бот-атакам данного типа позволит остановить и другие автоматизированные атаки, но в нашей практике мы видим, в основном, именно атаки типа price scraping – автоматизированный сбор информации о товарах и ценах, или парсинг цен.
Я не рассматриваю юридические и морально-этические вопросы парсинга цен в данной статье. Как мы видим, в ритейле и e-commerce, маркетинговый посыл предоставления “лучшей цены” является широко распространённым.

Делать такой анализ цен вручную для ассортимента в тысячи или десятки тысяч товаров не представляется возможным, поэтому я уверенно могу заявить, что практика парсинга цен в российском ритейле и e-commerce существует, применяется, и даже появился отдельный рынок услуг для парсинга.

Упрощенная классификация заказчиков и исполнителей парсинга цен
Прежде чем говорить об инструментах, давайте посмотрим на самих атакующих и их профиль – мотивацию, цели и доступные ресурсы.
Скрипт-кидди и школьники. Мотивация – поиск личной выгоды, например, поймать лучшую цену, забронировать дефицитный товар и так далее. Доступные ресурсы минимальные, часто это технически простейшие способы парсинга.
-
Невредоносные боты-парсеры, такие как новые и нишевые поисковые движки, инструменты анализа эффективности онлайн-маркетинга и так далее. Например, в ходе одного из проектов в области фуд-ритейла мы обнаружили следы активности специализированного поискового сервиса, который собирает и анализирует цены на вино.
Мотивация коммерческая, но такие акторы не будут идти на явные атаки, явные обходы систем защиты. Скорее, они используют базовые методы парсинга, не скрывают себя и не обходят системы защиты целенаправленно. Могут соблюдать robots.txt, а могут и нет.
Допускать таких клиентов на сайт или нет - решает владелец e-commerce ресурсы, часто такой парсинг цен - это полезный симбиоз, а не атака.
-
Профессиональные сборщики коммерческой информации.
Самая интересная категория, используют все доступные техники парсинга, маскировки и заметания следов, от сложных до самых продвинутых.
Заказчики таких атак — это конкуренты по рынку/сегменту.
Атака проводится либо силами самой компании-конкурента, либо руками компаний, предлагающих профессиональные услуги по парсингу данных.
Как меняются инструменты парсинга цен
Из практики мы видим, что по мере возрастания степени активного противодействия парсингу, инструменты проходят путь от самых простых до более продвинутых. Действительно, зачем сразу делать сложную систему парсинга, если на большинстве e-commerce сайтов вообще нет никакой системы противодействия парсингу или бот-атаками и срабатывают даже простые методы?
Вот какие инструменты мы наблюдаем, по мере возрастания сложности атаки.
Простые утилиты – wget, curl, например, в цикле на bash. Данные клиенты банально выполняют запросы с дефолтными параметрами, иногда меняют User Agent на более похожий на “человеческий”, то есть присущий обычному браузеру.
Кастомизированные скрипты. Используется скрипт, который выполняет целевой запрос или цепочку запросов, но это чуть более сложные системы, чем скрипт на bash. Как правило запросы выполняются с помощью таких библиотек как python-requests, атака может быть как с одного IP, так и распределенная со множества машин.
Эмуляторы браузеров. Это полноценные браузеры, как правило работающие в headless режиме, реализуются использованием комбинации таких инструментов как Selenium WebDriver, Headless Chrome, Puppeteer. Для масштабного парсинга запускается множество машин с различных серверов и работают в несколько потоков одновременно. Так как это браузер, то он может проходить проверки на поддержку Cookie, JavaScript и другие “технические” проверки.
“Эмуляторы человека”. Это более продвинутые инструменты и сценарии атак, использующие эмуляторы браузера, stealth-механизмы скрытия реальных параметров среды исполнения, использование резидентных прокси и интеграцию с системами обхода Captcha – так называемыми Captcha Farms. Captсha Farms представляют собой программные продукты с наборами API для передачи картинки или объекта Captcha для ее последующего автоматического или ручного решения, то есть включают инструменты распознавания текста (OCR) и десятки или сотни реальных живых людей, готовых за 2 доллара распознать 1000 светофоров, мостов или гидрантов.
Источники бот-трафика
По мере возрастания хитрости атакующего можно выделить следующие источники бот-трафика:
Дешевые VPS и хостинг, подсети облачных провайдеров. Здесь все просто – атакующий за пару долларов в месяц арендует виртуальную машину с IP адресом, запускает на ней свой инструментарий и начинает парсинг. Как правило, используются хостинг провайдеры, которые не сильно реагируют на abuse письма, но встречаются и вполне лигитимные облачные провайдеры. По своим проектам защиты мы часто видим в логах атаки десятки или сотни IP адресов, принадлежащих одному провайдеру.
Прокси-серверы. Все то же, что в первом пункте, но трафик проходит через прокси. Как раз для “маскировки” источника атаки. Частный случай – TOR, он больше используется для попыток эксплуатации уязвимостей прикладного характера, но иногда встречается и при парсинге.
-
IP адреса домашних и мобильных сетей в основном регионе присутствия онлайн-ритейлера. Это более сложный с точки зрения детектирования случай, так как используются сети типовых провайдеров и просто по анализу подсети парсинг-трафик совершенно не выделяется в общем потоке трафика.
Для организации такой схемы используются как “резидентные” прокси, так и зараженные браузеры и устройства ни в чем не подозревающих пользователей. Резидентные прокси стоят дороже, чем обычные, поэтому их реже используют, но, если мы говорим о целевой атаке, имеющей целью получение коммерческого преимущества – затраты на такие прокси несущественны для атакующего конкурента.
Как усложнить атакующим парсинг цен в e-commerce
Мы поговорили о проблеме, давайте перейдем к решению. Я приведу несколько типовых методов борьбы с ботами-парсерами, большую часть из которых можно реализовать самостоятельно, без использования специальных системы защиты.
Что можно сделать своими силами:
-
Ограничения по User Agent. Например, заблокировать “python-requests”.
-
Плюсы:
Очень просто внедрить.
-
Минусы:
Очень просто обойти. Помогает только от самых маленьких атакующих или от ботов, которые не пытаются маскироваться (специализированные инструменты и поисковики).
-
-
Ограничения по странам. Если вы продаете книги или еду в России, то скорее всего, трафик из Китая и Бангладеш не является для вас целевым, если у вас нет доставки в эти страны.
-
Плюсы:
Относительно просто внедрить.
Отсекает много лишнего.
-
Минусы:
Со временем, после блокировок всех нежелательных стран, бороться с атаками станет сложнее, так как атакующие перетекают в целевую страну. Например, если ранее боты приходили из Индии, то после блокировки страны этот же трафик будет идти из России. Это немного дороже для атакующего, но точно не остановит целевую парсинг-атаку.
Есть риск заблокировать соотечественников на отдыхе или в других странах. В нашей практике заказчик заблокировал Кипр, но не учел, что в стране большая русскоязычная тусовка и люди оттуда действительно делают заказы на российских онлайн-площадках.
-

-
Ограничения по провайдерам. Если вам не нужен трафик с Amazon или Digital Ocean, их подсети можно заблокировать.
-
Плюсы:
Довольно просто отсекается много хостингов, VPN и прокси-серверов.
-
Минусы:
Возможные ложные срабатывания, так как именно на этих хостингах размещаются VPN провайдеры, которыми могут пользоваться ваши покупатели.
Их много – сложно успевать контролировать.
-
-
Внедрение Captcha. Да, те самые веселые картинки с гидрантами и парковочными счетчиками, которые мы так любим.
-
Плюсы:
Captcha может быть довольно кастомизированной, ее можно встроить на те действия или в те области приложения, которые является критичными.
Отсекает подозрительный трафик, используется как средство дополнительной проверки.
-
Минусы:
Требуется модификация кода приложения.
Есть риск помешать реальным пользователям, это правда раздражает.
Эффективность далека от 100% - существуют готовые системы по обходу Captcha за три копейки - те самые Captcha Farms. Как с ними бороться - смотри другие разделы про продвинутую защиту.
-
-
Rate limiting. Ограничение количества/скорости запросов с одного IP или в рамках одной сессии.
-
Плюсы:
Эффективный механизм для остановки большого количества атак, удорожает атаку для злоумышленника.
-
Минусы:
Сложно настраивать вручную и управлять большим количеством разных лимитов для разных эндпоинтов.
-
Специализированные системы защиты от парсинга и бот-атак
Специализированные решения для защиты от парсинга и бот-атак используют и комбинируют все вышеперечисленные методы защиты, добавляя и более продвинутые технологии.
-
Внедрение механизмов fingerprinting. Это оценка клиента по множеству параметров, присвоение токена/идентификатора клиенту и последующий анализ собранных данных.
Позволяет классифицировать клиентов и идентифицировать клиентов, сопоставлять активность клиента во времени, даже если клиент приходит без cookie.
Не так сложно это внедрить, как анализировать большой объем данных и использовать его результаты для противодействия атакам - сам по себе fingerprinting не останавливает атаку, но позволяет реализовать более сложным механизмы защиты.
Проблемы связаны с обработкой больших данных, обеспечения срабатывания защиты в режиме реального времени, с минимальной задержкой на обработку.
-
Классификация и аттестация клиентов. Обычно этот процесс идет после фингерпринтинга. Классификация – отнесение к одному из классов трафика, например, к “хорошим ботам”, “плохим ботам”, “браузерам” или подозрительным клиентам.
Аттестация клиентов – принятие решения о том, является ли клиент, отправивший запрос в веб-сервер, легитимным. Как правило, после идентификации и классификации клиента становится понятно, разрешать ли такой трафик.Для веб-браузерных клиентов процесс классификации включает обработку специального JavaScript кода, который проводит заданные проверки клиента.
Для мобильных клиентов классификация проходит за счет встраивания мобильного SDK в приложения iOS/Android. Уже задача кода в SDK - провести проверку и встроить результаты проверки в исходящий трафик, генерируемый мобильным приложением к веб-серверу.
Продвинутые системы классификации учитывают сотни параметров:За кого клиенты себя выдают - анализ User Agent и других заголовков запросов.
Кем являются на самом деле на основе таких параметров как источник трафика (сети, провайдеры, страны), реакции на различные проверки.
Что делают и как себя ведут – частота запросов, паттерны поведения и тд.
-
Рейт-лимитинг.
Специализированные системы защиты от ботов упрощают управление для множества лимитов - для разных URL и типов клиентов.
В таких системах возможно простое создание лимитов по количеству запросов в минуту, за одну сессию, по длительности сессии в минутах и тд.
-
Классификация на основе машинного обучения и статистических методов.
С помощью статистических методов можно выявить закономерности в трафике, в поведении клиента.
Например, системы выявляют клиентов, делающих больше запросов, чем обычный пользователь.
-
Поведенческий анализ пользователей.
Помимо паттернов поведения, системы защиты от парсинга могут анализировать биометрию – движения и положение мобильного устройства, движения мыши. Такой функционал может быть встроен в мобильные SDK для анализа мобильных клиентов.
-
Базы репутации.
Глобальные вендоры, строящие системы защиты от ботов, видят трафик десятков/сотен тысяч топовых веб-сайтов и миллионов клиентов. Информацию можно переиспользовать, чтобы защитить веб-сайты от тех клиентов, которые уже совершали подозрительные или вредоносные действия на других веб-сайтах. В базах репутации содержатся как данные по IP адресам, так и по конкретным клиентам, на основе отпечатков клиентов.
Кейс из нашей практики – защита онлайн-ритейлера от парсинга
Ниже я приведу статистику по одному из наших заказчиков, без указания названия компании. Данные приведены примерно за месяц от начала проекта. Статистика по трафику – около 600-800 запросов в секунду (без учета статики), несколько доменов, работающие мобильные приложения, все работает на основе API.
Начинается проект с подключения системы защиты, но без включения каких-либо блокировок и без какого-либо влияния на трафик – полностью пассивный режим.
Для начала посмотрим на трафик, которые система сама определяет как “хороший бот-трафик” – это трафик поисковых систем и прочих легитимных ботов, в общепринятом смысле.
Здесь и далее на графике указано количество запросов (хитов), минимальное деление времени – 1 час. Данные приведены без учета запросов к статическим файлам.
")
Далее мы собрали достаточно данных для понимания, какой бот-трафик является легитимным именно для данного веб-сайта и добавили его в исключения, чтобы никакие дальнейшие настройки системы защиты не сказывались на данном трафике.
У каждого сайта будут свои исключения – партнерские боты, системы интеграции с какими-то внешними ресурсами, выгрузка в маркетплейсы, колл-бэки платежных систем и тд. Данный трафик мы классифицировали и “разметили” как исключения, то есть добавили в белый список – на графике обозначено как Whitelisted.

Включение защиты в активный режим. Лучше это делать после добавления исключений, но не всегда сам владелец ресурса знает, какой трафик считать легитимный, с кем еще есть интеграции и тд. Поэтому процесс добавления исключений будет продолжаться еще какое-то время после включения активной защиты.

После включения защиты владельцев e-commerce приложений интересует вопрос, а не заблокировали ли мы кого-то из легитимных пользователей? Здесь можно рекомендовать анализировать бизнес-метрики, например количество успешных заказов. Если не изменилось — значит все хорошо, и можно продолжать использовать включенную защиту.
Для примера ниже я покажу только легитимный трафик – как видим, объем трафика не изменился, даже несмотря на то, что мы включили активную блокировку. Пики на графике - это промо-акции ритейлера, при которых клиентам активно рассылались push-уведомления и сообщения по другим каналам связи, что привело к всплеску запросов.

Общий график количества запросов по категориям трафика представлен ниже.
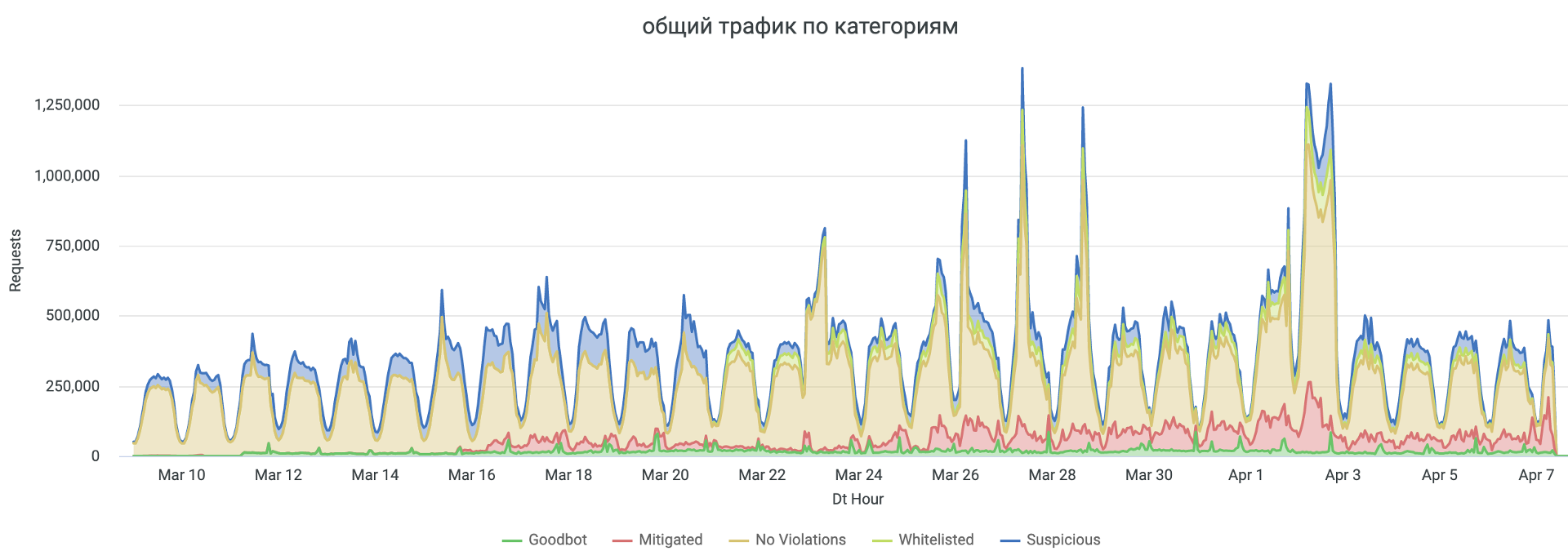
На графике в категории Mitigated показано количество запросов, но это не обязательно именно заблокированные запросы – часть из них, это проверки клиентов с помощью дополнительных механизмов классификации, после которых уже отсекается часть автоматизированных клиентов просто не проходя проверку, а часть из подозрительных клиентов получает оценку “нормального” пользователя и продолжает работу. Поэтому мы можем видеть всплески Mitigated трафика и в пиковые часы наплыва легитимного трафика – часть из клиентов вызвала подозрения у системы, прошла прозрачную проверку (не Captcha) и продолжила работу с сайтом.
В результате общие данные по запросам в ходе 1 месяца с начала проекта представлены следующей диаграммой.

Как видим, примерно треть общего трафика поступает от бот-клиентов, которые не относятся к известным хорошим ботам. По нашему опыту, от отрасли к отрасли процент бот-трафика может отличаться, и в среднем составляет от 25% до 85%, в зависимости от ниши ритейлера и других факторов. Максимальный процент вредоносного бот-трафика и парсеров цен мы наблюдаем в travel отрасли.
Рекомендации по упрощению встраивания защиты
Детально механизмы защиты от автоматизированных атак описаны в уже упомянутом руководстве по защите от автоматизированных атак от OWASP. Реализовывать ли их самостоятельно на уровне приложения, или же использовать готовые системы защиты от ботов – решать владельцу e-commerce приложения исходя из оценки затрат, скорости получения результата и других бизнес-критериев.
Хотелось бы добавить несколько рекомендаций, которые мы прочувствовали на собственном опыте.
Используйте различные API эндпоинты для браузеров и мобильных приложений. Это поможет упростить внедрение защиты для веб-браузеров, не дожидаясь внедрения мобильных SDK, реализующих возможности классификации клиентов, в приложения на iOS/Android.
Разделяйте общедоступные API и все остальные. Чем меньше ценных данных доступно для публики – тем меньше поверхность атаки и тем проще защищать эти данные и API. В данном случае речь идет именно о ценах и характеристиках товаров.
Выдавайте ключи для легитимного использования API и внедряйте rate limiting на стороне сервера. На нашей практике даже авторизованные клиенты использовали механизмы автоматизации для получения большего количества данных, чем изначально хотел владелец веб-ресурса. Контролировать это проще на стороне самого сервера, чем на стороне отдельной системы защиты.
Выводы
Невозможно полностью ограничить доступ к публичным данным в сети. Если данные можно считать в браузере, их скорее всего считают и попытаются автоматизировать процесс. Вопрос лишь в стоимости осуществления таких мероприятий, то есть в конечном итоге – в мотивации атакующих. Коммерческая выгода от использования данных о ценах товаров конкурентов может в сотни/тысячи раз перекрывать стоимость организации сложных атак, использующих множество техник маскировки и обхода систем защиты.
Можно усложнить задачу парсинга цен для большого масштаба обработки ваших данных. Сюда входят внедрение механизмов защиты на стороне приложения, внедрение специализированных систем защиты. Часть мер можно внедрить самостоятельно, использование специализированных решений по защите от ботов дает дополнительные и продвинутые инструменты в борьбе с парсингом.
Сложность парсинга будет только возрастать по мере противодействия ему – это постоянный процесс борьбы щита и меча. Владельцам e-commerce приложений не стоит расслабляться после успешно отбитой парсинг-атаки, ведь атакующий сделает выводы, перегруппируется и запустит парсинг с новыми параметрами. В такой ситуации важно иметь возможность оперативной реакции и изменения настроек системы защиты.
Комментарии (16)

maxzh83
22.02.2022 12:27+4Интересно, почему вы называете этот процесс атакой?
Атака на информационную систему — это совокупность преднамеренных действий злоумышленника, направленных на нарушение одного из трех свойств информации — доступности, целостности или конфиденциальности
Исходя из этого определения на вики, у вас не происходит нарушения доступности, целостности или конфиденциальности.

bezkod Автор
22.02.2022 12:31-2Как указал в начале, я не рассматриваю юридические и этические вопросы, связанные с парсингом данных. Для владельцев e-commerce ресурсов - это именно атака, так как данные о ценах, остатках товаров в магазинах, характеристики товаров - ценная информация и ее использование конкурентами влечет реальные коммерческие убытки для владельцев данных.

JekaMas
22.02.2022 12:37+8Простите, а если у вас будет магазин продуктов, то вы обяжите охрану пресовать покупателей, фотографирующих стелажи, товары или ценники?
bezkod Автор
22.02.2022 12:49-1Решения подобного рода принимают владельцы e-commerce, будь то физический магазин или онлайн-каталог, я не могу ответить за всех e-commerce.

d7s2di
22.02.2022 13:05Ха-ха, видел и такое. Фотографируешь в магазине ценник, и тут появляется какой-нибудь хрен с претезниями, кто мол съему разрешал и вообще "удоли!!!1111".

Jeka_M3
22.02.2022 14:29В крупных магазинах / супермаркетах ни разу не подходили. А если надо сфотографировать товар на витрине в небольшом магазинчике, то всегда спрашиваю сотрудников, не против ли они . Обычно никогда не отказывают.
maxzh83
22.02.2022 15:07+5Для владельцев e-commerce ресурсов - это именно атака
Владельцы e-commerce ресурсов могут как-угодно это называть. Хоть горшком, хоть террористическим актом. Они же не пишут статью на профильный ресурс.
я не рассматриваю юридические и этические вопросы, связанные с парсингом данных
Так это не этический и не юридический вопрос. Это вопрос профессиональной терминологии. Я не против того, что люди с этим борются, просто не понимаю почему называют это "атакой".
bezkod Автор
22.02.2022 15:25-3Если Вам интересно технически верное определение, то тогда Вы, наверное, согласитесь с признанным определением от OWASP. Они используют термин threat ("угроза"):
Scraping is an automated threat.
Также эта угроза относится к типу атак Abuse of functionality:
OWASP Attack Category / Attack IDs:
Abuse of Functionality
d7s2di
22.02.2022 13:00+9Лет несколько назад искал нужную мне вещь на авито. Найти и купить ее по вменяемой цене удалось только после написания простенького парсера.
Для чего препятствовать парсингу понятно: к примеру, чтобы "пользователь" (а точнее - пользуемый) не мог ослеживать динамику цен и радостно покупался на акции невиданной щедрости из серии "получи скидку 50% от утроенной цены".
Статья из серии как сделать Интернет еще хуже.


Yser
23.02.2022 06:10Интересный обзор, хотелось бы конечно больше технических деталей.
У меня есть опыт в икомерс и я прекрасно понимаю зачем это делать, особенно если речь идет о развивающихся рынках, где порог входа все еще достаточно низкий, а демпинг является чуть ли не базовым маркетинговым инструментом.
Внедрял пару очень простых решений для себя, и недавно и для клиента, которому спамили форму заказа реальными данными, тем самым создавая левую нагрузку на коллцентр (интересный был кейс), пару мыслей оттуда:
- JS. Сейчас он уже значительно дешевле, но все еще достаточно дорог для массового использования среди школьников, имхо, и даже базовая проверка (я записывал тайминг в токен для клиента) дает хороший результат. Вижу он у вас упомянут как часть идентификации клиента (внешней системой я полагаю), мой посыл в том что его можно внедрить еще до капчи (а то и вместо).- "Коллеги" меняли HTML разметку динамически (не знаю насколько эффективно).
- Блокировка как промежуточный результат. Блокируя запрос мы даем однозначный ответ на вопрос "чё происходит" возникающий у атакующей стороны, тем самым удешевляя им часть задачи "исследование". Я отдавал парсерам цены чуть выше, увеличивая себе "временное окно" для торговли, или не возвращал ошибку на сабмит данных, имитируя "ОК".Разумеется применимость тех или иных методов сильно зависит от кучи факторов, и как уже сказано в статье - это всегда игра в кошки-мышки на ресурсы.
yoigo
24.02.2022 00:42- "Коллеги" меняли HTML разметку динамически (не знаю насколько эффективно).
не эффективно, так как селектор по слову легко

npocmu
23.02.2022 12:38+1Почему не упомянут 100% надежный способ борьбы с парсингом? Убрать цены нахрен с сайта! Хотите что-нибудь купить — пишите заверенное нотариусом письмо и вам вышлют прайс в экселе. Хотя, пардон, какой эксель? Его же легко обработать. Нет, только скан распечатки внутри PDF, только хардкор!
Это и есть настоящий Ё-commerce!

Skyuzi
23.02.2022 22:22Невозможно избавиться от грамотных парсеров, а подобные защиты - это защиты от студентов
Kwisatz
Тщетно искал ответ на простой вопрос: «а нафига?» Ну серьезно, вы же сами пишете что стоит это дорого а целей своих вы все равно не добьетесь, для чего столько ресурсов тратить?
bezkod Автор
Целей мы добиваемся, цель в данном случае - усложнение и замедление атаки, а также цель - сделать атаку настолько сложной, что атакующие переключаются на более простые сайты. Коммерческие данные стоят очень дорого для владельцев e-commerce, поэтому они готовы тратить средства на их защиту.