Это вторая часть нашего рассказа о работе со смещениями оценок медиа активности респондентов онлайн-панелей. В предыдущей статье мы разобрали саму проблему, причины возникновения смещений и способы их коррекции, а теперь более подробно остановимся на практическом применении алгоритма Propensity Score Adjustment для коррекции реальных онлайн-данных.
Алгоритм Propensity Score Adjustment предназначен для калибровки вклада респондентов, которые набраны в панель неслучайно. В нашем случае – для коррекции выборки, участники которой были рекрутированы онлайн, под эталонную вероятностную оффлайн-выборку, набранную с помощью случайного телефонного обзвона.
Причины смещения онлайн-выборки могут быть разными и зачастую неизвестными. Так круг онлайн панелистов, как минимум, ограничен пользователями интернет-площадок, на которых размещалась реклама. Кроме того, в онлайн-панелях часто присутствует перекос в сторону людей, которые «профессионально» участвуют в интернет-исследованиях. Чтобы активность онлайн-панелистов стала близка к реальной картине происходящего, известные и неизвестные смещения нужно устранить. Применение Propensity Score коррекции – это один из возможных способов решения проблемы.
В одном из наших исследований мы анализируем активность пользователей в интернете. Данные для него мы собираем с панели, которую набрали оффлайн, с помощью телефонного обзвона. В каждом городе, включенном в исследование, генерируется заданное количество случайных телефонных номеров потенциальных панелистов. Такая процедура позволяет нам получить вероятностную выборку, обладающую известными социально-демографическими перекосами, которые легко поддаются коррекции.
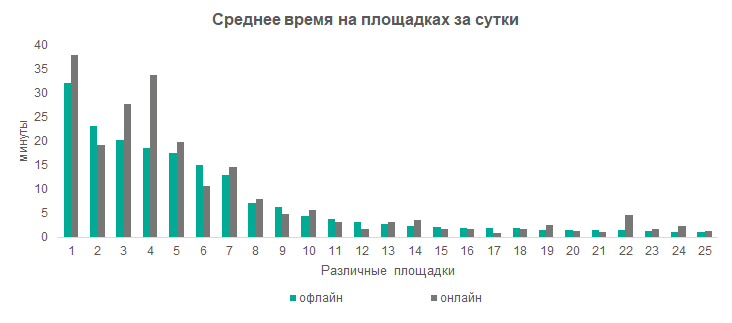
Проблема в том, что набрать достаточно большое количество панелистов оффлайн тяжело. Поэтому онлайн-рекрутмент мы изначально рассматривали как легкий способ расширения основной, более качественной оффлайн-панели до необходимого репрезентативного размера. После запуска рекрутирования и получения данных от онлайн-респондентов мы сравнили оценки активности этой панели с оценками активности оффлайн-панели и ожидаемо обнаружили ряд существенных отличий. Например, явные отличия наблюдались в среднем времени, проведенном на исследуемой интернет-площадке за сутки, и в количестве людей, просмотревших этот ресурс не менее одной минуты.

Мы изучили мировую практику решения подобных проблем и пришли к выводу, что в нашем случае для коррекции данных лучше всего применять методику Propensity Score Adjustment. Далее поделимся примером производственной реализации этого метода.
Процедуру Propensity Score коррекции можно разделить на несколько последовательных этапов.
1. Предварительный анализ и обработка данных
На этом этапе проводится анализ исходных данных и выделяются основные признаки, которые можно использоваться при моделировании. В нашем случае это социально-демографические и географические атрибуты респондентов, например – пол, возраст, город проживания, количество человек в семье, а также признаки на основании активности пользователей (суммарное время, которое респондент провел на каждой из интернет-площадок за исследуемые сутки).
cat_cols = ['educ', 'sag_wo18', 'hh_num', 'work', 'age', 'cubbb', 'y', 'use_loc', 'sem_pol', 'mat_pol']
for c in cat_cols:
dt[c] = dt[c].astype('category')
dt[:5]
Еще на этом этапе крайне важно выявить и устранить известные перекосы по значимым для исследования социально-демографическим атрибутам, присущие онлайн и оффлайн-выборкам. Это необходимо, чтобы известные нам смещения данных в дальнейшем не сказывались на результатах моделирования и процедуры в целом.
Чтобы произвести первичную коррекцию, мы воспользовались RIM-взвешиванием отдельно для онлайн и оффлайн-выборок. В результате с помощью весов universe_wei мы привели суммарные доли населения, которые приходятся на основные социальные и географические атрибуты каждой из выборок, к характерным значениям для генеральной совокупности (для интернет-пользователей в России).
Затем мы смогли определить степень неизвестных смещений оценок активности, присущих онлайн-выборке. В качестве показателей, которые отражают картину смещений, мы выбрали среднее время и количество респондентов, которые контактировали с исследуемыми интернет-площадками за расчетный день. Значимые отличия этих показателей во взвешенных выборках подтвердили наличие в онлайн-выборке неизвестного смещения, причина которого – неслучайная процедура рекрутирования.
2. Моделирование
Модель, которую мы использовали для коррекции, представляет собой классификатор, предсказывающий принадлежность респондента эталонной выборке. Респонденты эталонной выборки обозначаются единицей, а корректируемой – нулём. На «вход» модели подается взвешенная активность и демографические признаки респондентов, рассчитанные на первом шаге. На «выходе» для каждого панелиста получаем вероятность принадлежать эталонной выборке.
По итогам анализа, который мы провели на предыдущем этапе, в качестве используемой модели выбрали градиентный бустинг на деревьях решений XGBoost . Этот классификатор, помимо высокой точности, обладает рядом других достоинств. Например, он позволяет гибко учитывать веса респондентов и хорошо работает в условиях дисбаланса классов.
y = dt.pop('y')
X = dt.copy()
for c in X.columns:
if str(X[c].dtype) == 'category':
X[c] = X[c].cat.codessample_weight = dt['universe_wei'].values
X_train, X_val, y_train, y_val, w_train, w_test = train_test_split(X.values[:, :], y.cat.codes.values, sample_weight, random_state=2020)
dtrain = xgb.DMatrix(X_train, label=y_train, weight=w_train)
dval = xgb.DMatrix(X_val, label=y_val, weight=w_test)params = {'objective': 'binary:logistic', 'eval_metric': 'logloss', 'learning_rate': 0.3, 'gamma': 1.3, 'max_depth': 3, 'min_child_weight': 0.5, 'subsample': 0.8, 'reg_alpha': 0.01, 'reg_lambda': 0.01, 'max_delta_step': 5}watchlist = [(dtrain, 'train'), (dval, 'eval')]
clf = xgb.train(params, dtrain, 1000, watchlist, early_stopping_rounds=10, verbose_eval=10) 
pred = clf.predict(dval)
y_test = [round(value) for value in pred]
print('accuracy : ', accuracy_score(y_test, y_val))
print('recall : ', recall_score(y_test, y_val, average = 'binary'))
print('precision: ', precision_score(y_test, y_val, average = 'binary'))
print('f1_score : ', f1_score(y_test, y_val, average = 'binary'))
fpr, tpr, _ = roc_curve(y_test, y_val)
print('AUC : ',auc(fpr, tpr))
Оценка склонности prop_score для каждого респондента вычисляется как отношение p(1)/p(0), где в знаменателе – вероятность принадлежать корректируемой онлайн-выборке, а в числителе – вероятность принадлежать эталонной выборке.
sample_weight = dt['universe_wei'].values
tr = xgb.DMatrix(X.values, weight=sample_weight)
y_pred = clf.predict(tr)
predict = pd.DataFrame(y_pred, columns=['prb0', 'prb1'])
predict['prop_score'] = predict['prb1']/predict['prb0'];
predict.head()
3. Расчет корректировочных коэффициентов
Расчёт корректировочных коэффициентов мы провели на основе модельных вероятностей по методу Хорвица-Томпсона. Основные этапы расчёта:
массив оценок склонностей сортируется и делится на пять классов, на каждый из которых приходится по 20% объединенной выборки;
для корректируемой и эталонной выборок вычисляются взвешенные доли по упомянутым пяти классам;
корректировочные коэффициенты для каждого из пяти классов вычисляются как отношение долей для целевой и корректируемой выборок, рассчитанных на предыдущем шаге;
корректировочные коэффициенты подтягиваются к респондентам корректируемой выборки в соответствии с их классами.
4. Коррекция неизвестного смещения
Финальная коррекцию панели производим с помощью процедуры RIM-взвешивания. В качестве стартовых весов на «вход» взвешивания подаются рассчитанные корректировочные коэффициенты, нормированные на количество человек в выборке. В результате каждому респонденту присваивается вес, корректирующий одновременно два смещения: известное смещение основных социально-демографических атрибутов и неизвестное смещение, присущее онлайн-выборке.
5. Анализ результатов коррекции
Методология Propensity Score Adjustment помогает исправить смещения онлайн-выборок по неизвестным атрибутам, которые влияют на активность. Поэтому результаты коррекции можно оценивать на основе отличий в оценках активности исправленной и эталонной выборок. Например, мы анализировали отличие средней длительности посещения интернет-площадок с коррекцией от целевых оффлайн-статистик. Также анализировали приближение по количеству респондентов, которые контактировали с интернет-площадками. Ниже на графиках приведены результаты.
Основные значимые различия оценок активности для онлайн и оффлайн-выборки были устранены, что говорит о достаточно хорошем качестве коррекции смещения.
При использовании Propensity Score коррекции мы зафиксировали ряд преимуществ и возможных ограничений в применении метода.


Преимущества:
Описанная методология позволяет проводить коррекцию неизвестного смещения данных и для этого не обязательно знать точные причины смещения оценок активности.
На реальных данных метод показывает достаточно хорошее качество коррекции.
Методология Propensity Score Adjustment адаптирована для коррекции онлайн-панелей и позволяет одновременно исправлять известные и неизвестные смещения онлайн-данных.
Метод позволяет работать в многомерном пространстве атрибутов. При этом в модели можно использовать как соцдем признаки панелистов, так и необходимые оценки активности.
Propensity score коррекцию можно применять в комбинации с другими общеизвестными методами коррекции смещения – weighting и matching. Это позволяет гибко адаптировать её под производственные задачи.
Ограничения:
Для правильной коррекции данных авторы методологи рекомендуют использовать онлайн- и оффлайн-выборки размером не менее 2 тыс. человек.
Для качественной Propensity Score Adjustment коррекции важно выдерживать популяционные доли населения, которые приходятся на значимые для исследования соцдем атрибуты. Вынужденные известные смещения демографии онлайн и офлайн-панелей можно устранить при помощи взвешивания. Однако сильные перекосы по атрибутам взвешивания или отсутствие в панелях какой-либо из соцдем групп могут привести к ошибкам и негативно сказаться на итоговых результатах. Поэтому необходим жёсткий и регулярный контроль за наполняемостью групп взвешивания в каждой из панелей. При обнаружении систематических недоборов/переборов по значимым соцдем атрибутам необходим пересмотр процедуры рекрутирования.
При моделировании оценок склонностей нужно контролировать дисбаланс классов онлайн и оффлайн-выборок. Если дисбаланс классов оказывает значимое влияние на качество коррекции оценок активности, необходимо применить дополнительные методы: генерирование синтетической популяции по недостающему классу, калибровку вероятностей.
Технология Propensity Score Adjustment остается наиболее известной и признанной методикой коррекции онлайн-панелей. Ее практическая реализация может немного разниться в зависимости от структуры исходных данных и конечных целей исследования. Однако гибкость настройки этого алгоритма и возможность комбинировать с другими методами коррекции делает его интересным и перспективным способом решения проблемы смещения оценок активности онлайн-респондентов.
Сегодня нет «золотого» стандарта работы со смещениями, вызванных неслучайным онлайн-рекрутированием. Поэтому для медиаисследователей, которые столкнулись с этой задачей, важно понимать практическую ценность, достоинство и недостатки используемых методов коррекции. Надеемся, что наши выводы и пример реализации Propensity Score коррекции будут полезны при выборе алгоритма для улучшения данных онлайн-панелей.
Авторы: команда департамента Data Science, обработки данных и аналитики, Mediascope