

Для многих разработчиков локализация ассоциируется с дополнительным пластом проблем: как поддерживать локализованные ресурсы в актуальном состоянии? А что если языков не 2-3, а 20-30? Как вовремя отправлять новые строки на перевод? А что если во время перевода разработка ушла вперед, и каких-то строк уже нет, а есть новые? Как мержить присланные переводчиками файлы ресурсов? Не секрет, что из-за этого многие просто забивают на локализацию или стараются отложить ее на потом.
Сейчас у Evernote более 150 млн пользователей по всему миру, более 70% этих пользователей находятся за пределами США, каждый месяц мы переводим по 15 тыс. новых слов в 40 с лишним проектах на более чем 26 языков, и выпускаем новые релизы наших продуктов одновременно на всех языках. При этом на техническую поддержку всей этой системы требуется один человек, и то изредка.
Как нам это удается?
Когда сервис Evernote только начинал развиваться, у нас было большое желание делать компанию международной с самого начала. Это требовало оперативной локализации приложений Evernote подо все платформы на большой перечень языков. И при этом мы хотели сделать этот процесс максимально прозрачным для разработчиков. Поэтому в 2008 году, мы начали создавать платформу, которая бы упростила и автоматизировала процесс локализации, сделала бы этот процесс непрерывным.
И вот семь лет спустя эта платформа, которую мы назвали Serge (String Extraction and Resource Generation Engine), стала доступной для каждого.
Serge позволяет настроить процесс, при котором строки, будучи закоммиченными в систему контроля версий, автоматически извлекаются и отправляются на перевод, а переводы автоматически интегрируются в локализованные файлы ресурсов и автоматически же попадают в систему контроля версий. Serge избавляет разработчиков от необходимости работать с локализованным файлами вообще (их забота — править только исходные ресурсы, например, английские), он избавляет переводчиков (или ваше локализационное агентство) от необходимости возиться с разными форматами файлов. Serge может быть интегрирован в любой процесс локализации — с помощью платных переводчиков или волонтеров, онлайновый или офлайновый.
Как эта штука работает?
Serge — это приложение командной строки, которое принимает в качестве входного параметра команду и один или несколько конфигурационных файлов. Каждый конфигурационный файл описывает один проект локализации (с каким удаленным репозиторием синхронизироваться, как общаться с сервером переводов, в какой локальной директории и по какой маске сканировать файлы, каким парсером их обрабатывать, как именовать файлы, отправляемые на перевод, где и в какой кодировке создавать локализованные файлы, какие дополнительные плагины использовать и т.д.).
Вот что происходит, когда Serge запускает команду sync для каждого конфигурационного файла:
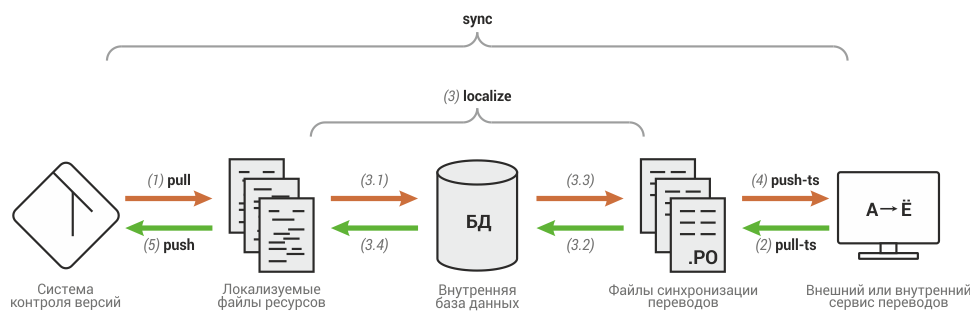
- (pull) выкачиваются изменения из удаленного репозитория с файлами ресурсов;
- (pull-ts) выкачиваются переводы из сервера переводов (обновляются локальные файлы);
- (localize) происходит, собственно, локализация:
- файлы ресурсов парсятся; сведения о файлах и строках попадают во внутреннюю базу;
- файлы с переводами парсятся; переводы попадают во внутреннюю базу;
- файлы с переводами обновляются в соответствии с изменившейся структурой исходных файлов ресурсов;
- файлы ресурсов обновляются в соответствии с изменениями в переводах;
- (push-ts) обновленные файлы с переводами выгружаются на сервер переводов;
- (push) обновленные локализованные файлы ресурсов выгружаются во внешний репозиторий.
Непрерывная локализация достигается тем, что как только Serge проходит этот цикл для каждого конфигурационного файла, цикл можно запускать снова. В случае с Evernote весь цикл по всем проектам занимает порядка 15 минут. Это значит, что как только инженер закоммитил какое-то изменение в файл ресурсов, в течение 15 минут приходит коммит от локализационного робота, симметрично меняющий все локализованные копии этого ресурса; когда переводчик добавляет перевод или изменяет существующий, в течение 15 минут его изменение коммитится в репозиторий. Эти изменения вызывают запуск CI-билда и последующее автоматическое тестирование, что позволяет максимально быстро выявлять ошибки, связанные с интернационализацией и локализацией, осуществлять перевод параллельно с разработкой продукта.
Архитектура Serge построена на плагинах. Serge поддерживает несколько видов систем контроля версий, более 20 форматов файлов, а также плагины, меняющие поведение системы (например, пре- и постпроцессинг локализованных файлов, возможность задавать список языков для перевода прямо в файле и т.д.). На сайте Serge находится документация по продукту, плагинам, установке и настройке.
Мы очень надеемся, что открытие исходников Serge позволит как индивидуальным разработчикам, так и большим компаниям, по-новому взглянуть на процесс локализации и тесно интегрировать локализацию в цикл разработки. Ну и, разумеется, будем рады комментариям, пожеланиям и сообщениям об ошибках.
Локализация — это просто!
Комментарии (15)

harlong
19.10.2015 10:55+3А предусмотрен ли какой-то способ борьбы с разницей между длинами строк на разных языках и необходимостью адаптации элементов интерфейса под эти строки?

SamDark
19.10.2015 12:32Сравнивать длину на английском с длиной перевода и маркировать как-то в UI для переводов?

afan
19.10.2015 17:52На уровне Serge есть только возможность протаскивать коммаентарии разработчиков из файлов ресурсов на сервер перевода. Уже на самом сервере переводчики видят эти комментарии, а также скриншоты, которые добавляют менеджеры по локализации. Интерфейс наши инженеры разрабатывают таким образом, чтобы он корректно работал с более длинными строками, а тестирование локализованных сборок позволяет нам выявлять косяки и переводить что-то покороче, когда это возможно, или файлить баги на разработчиков, чтобы они где-то переработали интерфейс.

DmitryKoterov
19.10.2015 12:11А почему все делается в режиме пребилда файлов, а не в рантайме? Казалось бы, имея центральную базу переводов, всегда можно её локально закэшировать и извлекать переводы во время работы программы/приложения/сайта/сервиса. И тогда можно вообще все переводы обновлять в реальном времени, ничего не пересобирая.
(Кстати, вопрос залу: а есть ли готовые сервисы, работающие по этому принципу по модели подписки?)SamDark
19.10.2015 12:31В реальном времени позволяет так делать Facebook. Но это он для себя, естественно. В виде сервисов такого не встречал.
afan
19.10.2015 17:58Сервисы такие есть. Qordoba, например. Но, во-первых, это платно (и цены обычно сильно зависят от размера компании). Во-вторых, ни одна уважающая себя компания не будет ставить свой продукт (рантайм) в зависимое положение от стороннего решения. Это усложняет код, делает его более медленным, это делает локализационное решение нестандартным (чего разработчики не любят), это усложняет тестирование. Наконец, зачем что-то делать в рантайме миллионы раз, когда можно сделать один раз статически?
DmitryKoterov
19.10.2015 19:37Ну да, так было 15 назад, когда не было AWS, Mandrill, CloudFlare и тысяч других сторонних решений, от которых современные веб-разработчики очень полюбили ставить себя в зависимость. Ну а на вопрос «зачем»… потому что быстро, удобно и позволяет нетехнарям править тексты и моментально видеть результат, например.
afan
19.10.2015 20:01Не все, что удобно в разработке, удобно и быстро для конечных пользователей продукта. Динамическая локализация удобна переводчикам (коих у нас около 30), но имеет свои минусы для инженеров (коих у нас сотня) и конечных пользователей (коих миллионы). Одно дело — перенос своих вычислительных мощностей на AWS. Это прозрачно для пользователей, и скорее всего даже призвано ускорить работу. Другое дело — локализация в рантайме (усложнение кода и процесса).

romangoward
20.10.2015 04:08+1Немного нелепо выглядит сей релиз сугубо внутренней наработки на фоне вливания evernote в pootle, ибо функционал вашего Серёжи практически идентичен translate-toolkit.
Плюсы использования промежуточной базы на обычном SQL для конвертации форматов — весьма сомнительны на первый взгляд: откат состояний там не предусмотрен, снапшотов нет, то есть никакой защиты от факапов: роллбэк не сделать при плохом вливании, ибо проще сразу базу переналивать. Я так понимаю, что ровно плыть вам помогает именно тот факт, что внутри компании есть «домашние» переводчики и менеджеры локализаций? Опять же, работа с памятью переводов реализована через обычный скрипт, а реалтаймовые матчинги для переводчиков делает вполне себе эластик же, да?
Получается, что в сухом остатке у вас, вероятно, имееются неплохие парсеры, ибо perl традиционно хорошо работает со строками… ну и всё.
Из всего этого вытекает вполне себе резонный вопрос: если perl лошадка сдохла, то надо ли с неё слезать? :3 Ну а если без сарказма, то планирует ли компания работать над расширением функционала pootle и соответствующих утилит, или вы таки только с Сережёй дружить будете? :-}
afan
20.10.2015 04:53+1Хорошие вопросы.
Образно говоря, translate-toolkit по сравнению с Serge — это Arduino по сравнению с iPhone. Мы активно помогаем разрабатывать Pootle, но рассматриваем его лишь как интерфейс для перевода, не более. Serge+Pootle = полноценная опенсорс-платформа для непрерывного перевода. translate-toolkit мы помогать развивать не намерены. Внутри самого Pootle есть также тенденция уйти от зависимости с translate-toolkit.
Serge не является конвертером форматов в прямом смысле этого слова. И это сильно больше, чем набор парсеров — рекомендую почитать документацию к управляющим плагинам, например. Снапшоты базы и .po-файлов мы делаем — ничего сложного тут нет. База не такая большая — можно делать бэкап хоть после каждого цикла. Elasticsearch — это TM внутри самого Pootle. Serge позволяет использует свою базу как TM, переиспользует известные переводы (сначала пытается находить 100% матчи внутри файла, потом внутри проекта, затем внутри всей базы).
Помогать развивать функционал Pootle мы, разумеется, продолжим. Есть много идей для улучшения.
ketrin7
На сколько понимаю, локализация — это не только перевод интерфейса на другой язык, но и обуспечение рподдержки национальных стандартов (как-то, формати даты и времени, дробных и многозначных чисел, система мер, вывод на экран символов языка и т.д.). Как это реализуется?
SamDark
То, что вы описали — это интернационализация. Локализация — это именно перевод строк и корректирование остальных данных вроде форматов времени. Часть данных при этом уже есть в проектах вроде CLDR, так что локализовать их заново не надо.
ketrin7
Интернационализация — это адаптация продукта для потенциального использования практически в любом месте, в то время как локализация — это добавление специальных функций для использования в некотором определённом регионе (тут и тут ). По-моему, это подтверждает мою мысль ;)
afan
Поддержка форматов даты и чисел обычно есть в операционной системе — ничего особенного в рамках локализации тут делать обычно не надо. Разработчикам нужно просто следовать правилам, заданным для их платформы.