
Методисты All Cups совместно с организаторами разработали алгоритмические задачи, добавив актуального контекста. Здесь много любителей головоломок: предлагаем попробовать свои силы в задачах и сравнить с решениями.

Задача «Маски»
Никита собирается открывать свой пункт выдачи заказов (ПВЗ). Для обеспечения безопасности посетителей Никита решил обеспечить ПВЗ одноразовыми медицинскими масками, которые будут поставляться каждый месяц в количестве
Примечание: Никита готов купить больше масок, чем ему нужно, если это позволит сэкономить.
Формат входных данных
В одной строке вводится одно целое число
Формат выходных данных
Требуется вывести три числа в одну строку через пробел — количество отдельных масок, упаковок и коробок, которые надо купить.
- Сначала купить как можно больше коробок
.
- Затем — как можно больше упаковок
.
- И остаток M докупить поштучно.
Однако такой подход не всегда самый выгодный, потому что можно купить лишние маски, если это позволит сэкономить. К тому же при таком подходе количества коробок и упаковок отличаются от оптимальных максимум на единицу. Давайте теперь проверим неравенство, при котором выгоднее купить упаковку, чем докупать поштучно:
Остаётся лишь представить эти формулы в коде.
Задача «Склады»
Компания-застройщик занимается строительством недвижимости промышленного назначения, а именно складских помещений. Каждый квадратный метр площади стоит
Формат входных данных
В первой строке вводится одно целое число
Формат выходных данных
Вывести одно число — максимальное количество денег, которое может заработать компания-застройщик.
Есть и другое, более быстрое решение задачи за линейное время! Для этого пройдём по массиву
Задача «Картины»
Максим решил заняться продажей картин на NFT-площадках, а для этого нужно придумать что-то свое и оригинальное. Максиму очень нравится, как выглядят цифры на черном фоне. Нужно написать программу, которая будет рисовать квадрат, состоящий из целых чисел и выводить информацию о его размере.
Формат входных данных
В одной строке через пробел вводится набор чисел или символов.
Формат выходных данных
В первой строке выводится сообщение «Квадрат со стороной N». В следующих строках требуется вывести квадрат, сформированный из набора чисел или символов, длина стороны — длина введённого массива.
- Для начала прочитаем массив из входных данных и узнаем его длину:
read line array=($line) len=${#array[@]} - Затем выведем фразу про «квадрат»:
echo "Квадрат со стороной $len" - И в завершение воспользуемся циклом со счётчиком и отобразим исходный массив
раз:
for (( i = 0; i < $len; i++ )) do echo $line done
Задача «Продажи»
В базе данных есть таблица
Invoice следующего вида: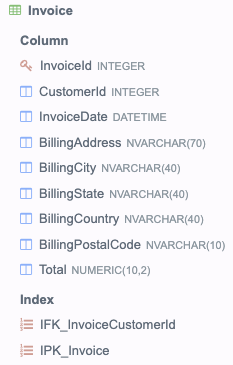
Напишите запрос, который покажет общие продажи по всем странам, отсортированные в порядке возрастания. На выходе в первой колонке должно быть название страны, а во второй показатель общих продаж.
На чемпионате во фразе «отсортированные в порядке» было некорректное склонение, что заставляло пользователей думать, что сортировать необходимо по странам. Это было оперативно исправлено и сейчас формулировка корректна.
Примечание: для решения задачи используется база данных Chinook Database в формате SQLite — см. файл Chinook_Sqlite.sqlite.
GROUP BY, а второе — командой ORDER BY. Тогда запрос, который покажет общие продажи по всем странам, отсортированные в порядке возрастания, может выглядеть так:SELECT
BillingCountry,
SUM(total)
FROM
Invoice
GROUP BY BillingCountry
ORDER BY SUM(total);
Функция
SUM в рамках GROUP BY посчитает именно то, что мы хотим — сумму всех продаж для каждой страны.Задача «Тайные покупатели»
Паша и Саша проживают в большом подмосковном городе, в котором
Примечание: Паша и Саша ходят вместе, а друзья поодиночке. Например, для
Формат входных данных
В первой строке вводится число
Участников соревнования могло ввести в заблуждение неопределенность в ограничении. Во время соревнования задание было дополнено, сейчас вам доступен финальный текст.
Формат выходных данных
Вывести
Занимательный факт: для любых
-
: ответ
.
-
: можно посчитать факториал по модулю за линейное время (нам это позволяет ограничение на значение
).
Если раньше вы не работали с факториалом по модулю, то вот пример псевдокода его подсчёта:
fact = 1
for i from 2 to n
fact = (fact * i) mod t
Задача «Маршруты»
Кирилл работает аналитиком в Ozon, и недавно ему в руки попал отчёт, из которого он понял, что время доставки товаров в пункты выдачи можно значительно сократить. Он заметил, что пункты выдачи в городе образуют выпуклый многоугольник с количеством вершин, равным
Можно выбрать какое-то число

Пояснение к примеру
- Если при
выбрать
(соединив каждую вершину только с одним ближайшим соседом слева и справа), то минимальное расстояние, например от узла
до узла
будет равно 3. Но
, значит это решение не удовлетворяет условию.
- Если при
выбрать
(соединив каждую вершину с двумя ближайшими соседями с каждой стороны), то минимальное расстояние между любой парой вершин получается равным 2. Это удовлетворяет условию
, значит это верное решение.
- Для треугольника (
) все вершины являются соседними друг другу, значит единственно возможным решением является
, что удовлетворяет условию
.
Формат входных данных
В первую строку вводится одно целое число
Формат выходных данных
Для каждого набора чисел выведите минимальное
А что будет, если
Задача «Даты»
Напиши скрипт, который будет получать на вход
stdin два параметра d1 и d2 в формате YYYY-MM-DD, и будет считать разницу между этими датами в днях. Скрипт проверяется на Bash 5.1.4 (запуск под Ubuntu 20.04).Формат входных данных
Две даты через пробел в формате YYYY-MM-DD.
Формат выходных данных
Одно целое число — разница в днях.
date, которая позволяет получить из строки дату и преобразить её в формат unix time. Давайте так и поступим, затем найдём разность и переведём её в дни:- Считываем даты из входного потока:
read s1 s2 d1=`date -d "$s1" "+%Y-%m-%d"` d2=`date -d "$s2" "+%Y-%m-%d"` - Переводим даты в unix time:
ut1=`date -d "$d1" +%s` ut2=`date -d "$d2" +%s` - Считаем разность секунд и переводим в дни:
diff=$(($ut1 - $ut2)) diff_days=$(($diff / (60 * 60 * 24))) - Выводим абсолютное значение разности (можно было бы написать
if, но такой «чит» выглядит лаконичнее: он переводит значение в строку и удаляет лидирующий минус, если он есть):echo ${diff_days#-}
Бонус: уже после написания разбора обнаружилось два забавных факта:
- Во всех тестах вторая дата идёт хронологически позже первой.
- Формат даты в условии не надо дополнительно парсить, а можно сразу переводить в unix time.
Таким образом, немного упрощённое решение выглядит так:
read d1 d2
ut1=`date -d $d1 +%s`
ut2=`date -d $d2 +%s`
diff=$(($ut2 - $ut1))
diff_days=$(($diff / (60 * 60 * 24)))
echo $diff_days
Задача «Анализ продаж»
В базе данных есть таблицы
Invoice, Customer, Employee следующего вида:
Напишите запрос, который будет искать трех продавцов на маркетплейсе, совершивших больше всего продаж, начиная с 2010 года. На выходе в первой колонке должны быть имя и фамилия продавца, а во второй количество их продаж, отсортированное в порядке убывания.
Примечание: для решения задачи используется база данных Chinook Database в формате SQLite — см. файл Chinook_Sqlite.sqlite. Также во время чемпионата у участников возникал вопрос относительно имени и фамилии в первой колонке таблицы. Поясним, что они должны быть через пробел.
Invoice и Сustomer можно объединить по CustomerId, а Сustomer и Employee по Customer.SupportRepId = Employee.EmployeeId.Теперь отфильтруем все продажи начиная с 2010 года. Для этого можно можно преобразовать даты с помощью
CAST и сравнить, либо воспользоваться выражением LIKE «201%», тестовые данные допускают оба варианта. Далее остается лишь соединить фамилию и имя и выполнить простейшую агрегацию. Пример финального запроса:
SELECT
Employee.FirstName || ' ' || Employee.LastName as Name,
COUNT(Customer.SupportRepId) AS Total
FROM
Invoice
INNER JOIN
Customer
ON
Invoice.CustomerId = Customer.CustomerId
INNER JOIN
Employee
ON
Customer.SupportRepId = Employee.EmployeeId
WHERE
Invoice.InvoiceDate LIKE "201%"
GROUP BY Name
ORDER BY Total DESC
LIMIT 3
Задача «Треки»
В базе данных есть таблицы
Invoice, InvoiceLine, Track следующего вида:
Напишите запрос, который составит рейтинг треков по их продаваемости, начиная с 2010 года. На выходе должны получиться две колонки. В первой колонке должны быть
Id трека, отсортированные в порядке возрастания, а во второй колонке — количество проданных копий трека, отсортированных в порядке убывания.Примечание: для решения задачи используется база данных Chinook Database в формате SQLite — см. файл Chinook_Sqlite.sqlite.
INNER JOIN. Облегчает задачу то, что у нас есть общее поле TrackId в таблицах Track и InvoiceLine, а также общее поле InvoiceId в таблицах InvoiceLine и Invoice. Затем отфильтруем все продажи начиная с 2010 года. Как и в предыдущей задаче, для этого есть два способа: применить к датам CAST и сравнить, или выполнить выражение LIKE «201%».Остаётся подсчитать сумму продаж по каждому треку: сгруппируем данные, применим функцию
SUM к значению InvoiceLine.Quantity, а затем отсортируем значения в получившейся таблице. Вариант финального запроса:SELECT
Track.TrackId AS TrackId,
SUM(InvoiceLine.Quantity) AS Total
FROM
Track
INNER JOIN
InvoiceLine
ON
Track.TrackId = InvoiceLine.TrackId
INNER JOIN
Invoice
ON
InvoiceLine.InvoiceId = Invoice.InvoiceId
WHERE
Invoice.InvoiceDate LIKE '201%'
GROUP BY Track.TrackId
ORDER BY Total DESC, TrackId ASC
Такие задачи были в отборочном и основном раунде для поступления на курс «Продвинутая разработка микросервисов на Go». Какая задача вам показалась самой лёгкой, а какая — наиболее сложной? А если вы нашли более эффективное или элегантное решение, делитесь в комментариях :)
Комментарии (24)

cruzo
13.04.2022 13:46+1Вот проводили раньше на Яндекс.Контесте и Кодфорсе - проблем с платформой не было таких, как в этот раз. Но благодаря задаче "Анализ продаж" я теперь знаю что Employee (работник, служащий или рабочий по найму) - это на самом деле таблица продавцов на маркетплейсе =) В остальном, спасибо, было интересно!

kusoff94
13.04.2022 13:53+3Условие Invoice.InvoiceDate LIKE '201%' неверное, т.к. скрипт не учитывает 2020 год, но при этом учитывает 20100 год. Верно будет указать условие strftime('%Y',Invoice.InvoiceDate)>='2010' Здесь по правилу лексикографической сортировки все будет корректно не только до 2020 года, но и после него.
Писал в поддержку, но ни смотря на это решение не учли. Вот скрипт, который засылал, но он не прошел проверку.
select track.TrackId,sum(InvoiceLine.Quantity ) as cnt
from Track
inner join InvoiceLine
ON Track.TrackId = InvoiceLine.TrackId
inner join Invoice
on InvoiceLine.InvoiceId = Invoice.InvoiceId
where strftime('%Y',Invoice.InvoiceDate)>='2010'
group by Track.TrackId
order by 1,2 desc

xe1by Автор
13.04.2022 15:50В задаче данных позже 2015 года не было.
Таким образом оба варианта условия, приведенных вами, должны привести к одинаковому результату. Возможно ошибка в прохождении теста была в чем-то другом.
Можно будет позже попробовать самостоятельно доработать решение, чтобы оно проходило все тесты по условиям задачи. Потому что пользователи, кто решили задачу, есть.
kusoff94
13.04.2022 18:33+1А если я Вам скажу, что в первом задании по SQL правильное решение, которое вы сейчас указали в решении не принялось, но при подборе чекер принял решение, которое не соответствует требованиям, Вы согласитесь пересмотреть результаты?
По поводу комментария о том, что в тестовых данных не было данных старше 2015 года - это уже странно. Мы же не видели данных, на которых проводились тесты.xe1by Автор
14.04.2022 11:45Если речь идет про задание "Продажи", то приведенное в разборе решение принимается на максимальный балл.
Это проверялось в момент подготовки разбора и по всем другим задачам в том числе.Этот комментарий скорее к тому, что приведенное решение в разборе тоже валидно для данного кейса.
zergular
13.04.2022 13:53Очень спорные задачи и решения. По многим задачам при прочих равных условиях с опубликованными решениями система не выдавала максимальный балл, а то и вообще выдавало 0 баллов.
xe1by Автор
13.04.2022 15:54Примеры решений, которые рассмотрены в статье в первую очередь проверялись на задачах контеста и проходили все тесты.
Сложно сейчас сказать, что именно из загруженных вами решений не соответствовало решениями из разбора :(
SergeiBogdanov
13.04.2022 13:53+4В двух последних задачах требуется рассмотреть строки с 2010 года. Адекватным кажется фильтрация уровня where year >= 2010. Авторы же делают LIKE '201%'. Под такую фильтрацию, как минимум, не попадут строки 2020 года и позднее, хотя они требуются условиями.
xe1by Автор
13.04.2022 15:56Да, мы уже выше ответили по другим комментариям.
В таблице не было данных старше 2015 года, поэтому это решение также проходит тесты.
zergular
13.04.2022 14:00Задача с баллами, одно из 12 моих решений:
#!/bin/bash read di1 di2 d1=$(date -jf %Y-%m-%d "$di1" +%s) d2=$(date -jf %Y-%m-%d "$di2" +%s) r=$(( (d2 - d1) / 86400 )) if [[ "$r" < 0 ]]; then r=$(( -r )) fi echo "$r"В чем решение не верно? Оно тянет на 0 баллов? 11 других решений тоже полностью удовлетворяют условию, но тоже 0 баллов!
xe1by Автор
13.04.2022 15:57+1Ваше решение работает под MacOS, но не работает под Linux. Про различия в синтаксисе команды date в разных ОС можно почитать, например, тут: https://www.shell-tips.com/linux/how-to-format-date-and-time-in-linux-macos-and-bash/#what-are-the-differences-between-linux-and-unixmacos&gsc.tab=0
zergular
13.04.2022 14:02+2С коллегами по sql выше полностью солидарен, все решения при сравнении типа поля DATETIME а не строки по LIKE (что уже выглядит очень глупо) получили 30 из 40 баллов. Что тут не так?
cruzo
13.04.2022 14:09По всей видимости, данные решения даны с поправкой на заявления Сергея Ивлиева, перед контестом, цитата: Во время контеста мы смотрим не на качество кода, корректное использование конструкций, а только на то, как он решает поставленную задачу и с какой скоростью;

dblokhin
14.04.2022 05:48+1Это правильно, так происходит в любом контесте в том числе самого высокого международного уровня, где рез-т работы оценивается в итоге по сводной таблице автоматической системы тестирования (ваш код никто не смотрит). Качество кода оценивает тестирующая система - в этом плане суть этой проверки лежит на качестве тестов.
Другое дело формулировка некоторых задач. Например, "Напишите запрос, который будет искать трех продавцов на маркетплейсе, совершивших больше всего продаж, начиная с 2010 года." - неясно что надо: больше всего продаж в рублях или по колчеству сделок-продаж? Чтобы ответить на этот вопрос, надо было отправлять неверную гипотезу в систему.
Или в задаче "Маршруты" не были указаны ограничения входных данных. Да, это сейчас они указаны, но тогда их не было: Ограничения: 2 < n < 10^18, 1 <= r < 10^7Или в этой же задаче, например: "В первую строку вводится одно целое число P(1<=R<=100)..."
Что за R? Понятно, что это опечатка, но осадочек остался.
Непонятно какую асимптотику ожидает автор задачи.
Но контест, все равно был достаточно легкий и эпичный (в плане сбоев).
Отмечу как минус - было слишком мало задач: по 2 задачи go/sql маловато, имхо.

PetrovSerega
13.04.2022 19:49В задаче «Анализ продаж» предлагается решение с группировкой по значению
Employee.FirstName || ' ' || Employee.LastName as NameРазве это верно? Среди продавцов могут быть сотрудники с одинаковыми именем и фамилией.
PetrovSerega
13.04.2022 20:01Задача "Треки".
В условии:
В первой колонке должны быть Id трека, отсортированные в порядке возрастания, а во второй колонке - количество проданных копий трека, отсортированных в порядке убывания.В решении:
ORDER BY Total DESC, TrackId ASCМожете прокомментировать, как из этого условия следует, что данные необходимо сначала сортировать по количеству проданных копий?
На мой взгляд, из условия следует, что сортировать нужно сначала по Id трека (и далее какая-то сортировка теряет смысл, так как это первичный ключ, по которому группируем записи).
Конечно, в начале задачи сказано "Напишите запрос, который составит рейтинг треков по их продаваемости", но дальнейшие формулировки затрудняют понимание =(.
arkashaErema
13.04.2022 23:08Задача «Треки».
Решение вида:SELECT TrackId, SUM(Quantity) as total FROM InvoiceLine il JOIN Invoice i ON i.InvoiceId = il.InvoiceId WHERE strftime('%Y', i.InvoiceDate) >= '2010' GROUP BY TrackId ORDER BY total DESC, TrackId ASCпроходило ровно половину тестов, что с ним не так, я не смог разобраться...

SpyzeR
14.04.2022 10:26Задачи интересные, но я так и не понял что в них специфического для Go-разработчиков?
sHinE
В задаче с треками у вас в тестовых данных не было продаж за 2020+ года?
Вот такой запрос отработал 3 из 4 тестов на конкурсе, либо я не вижу какого-то существенного отличия, либо даты как-то неправильно сравниваю:
xe1by Автор
Нет, самые поздние даты в тестовых данных относились к 2015 году
Касательно второго вопроса напрямую проконсультировать не сможем. Можно будет позже прорешать эту задачу самостоятельно и прийти к решению, которое проходит все 4 теста.
sHinE
А когда планируется открыть доступ к тестированию снова?
xe1by Автор
В ближайшее время, нужно подождать анонса :)