
Future Indefinite — Oculus (Cover art) by Rowye
Несколько лет назад дата-сайентистов часто называли «единорогами». Все искали гениального full-stack-инженера-математика, способного вникнуть во все бизнес-проблемы.
В последние два года мы пережили хайп по поводу AI/ML и стали свидетелями быстрого подъема профессии «дата-инженер». По данным отчета Dice о технических специальностях, в 2020 году потребность в дата-инженерах резко возросла ни много ни мало на 50 % — эта специальность быстро развивается.
Команда разработки облачной платформы VK Cloud Solution перевела статью о том, чего ждут от дата-инженеров сейчас и каким станет дата-инжиниринг в будущем.
Важный дисклеймер от автора: Я сам не дата-инженер. Эта статья и мои наблюдения основаны на многочисленных дискуссиях со специалистами по работе с данными: от сотрудников быстро развивающихся стартапов и скейлапов до крупных акционерных компаний.
Зарождение и эволюция профессии дата-инженера
В начале 2010-х в скейлапах и быстро развивающихся ИТ-гигантах вроде Facebook, Netflix, LinkedIn и Airbnb стал звучать только что появившийся на свет термин «дата-инжиниринг». Эти компании обрабатывали в реальном времени огромные объемы данных, которые могли бы оказаться полезными для бизнеса. Поэтому их разработчикам приходилось создавать инструменты, платформы и инфраструктуру, чтобы работать с этими данными быстро, надежно и с возможностью масштабирования.
Это был поворотный момент: работа дата-инженера стала превращаться в профессию, которая двигалась от использования традиционного ETL-инструментария к разработке собственного набора инструментов для управления растущими объемами данных.
Пока Big Data превращались из модного словечка, звучащего на советах директоров, в реальную технологию, дата-инженеры становились программистами, одержимыми данными — уже не инфраструктурой, а хранилищами, моделированием, первичной обработкой и не только.
Как отмечает Мэтт Тёрк (Matt Turck) в статье «Анализ общего положения дел в области машинного обучения, ИИ и данных»:
«Сегодня облачные хранилища и озера данных позволяют хранить огромные объемы даннх, причем так, чтобы из них можно было извлекать пользу, не слишком за это переплачивая и не нанимая целый штат технических специалистов для работы с ними. Иными словами, мы наконец-то научились хранить и обрабатывать Big Data».В плане эффективной работы с данными облачные решения оказались очень мощными. Как отмечает Зак Уилсон (Zach Wilson), для задач по обработке данных, которые с трудом можно было выполнить в мире Hadoop, проще и удобнее использовать Snowflake или BigQuery. С их помощью можно делать то, для чего раньше писали сотни строк кода на Java в десятках запросов SQL.
Когда хайп прошел и мы наконец осознали истинный потенциал Big Data, дата-инженеры сразу стали дефицитом. Сегодня они нужны любой современной Data-driven-компании — от стартапов и скейлапов до крупных предприятий.
Светлое будущее дата-инжиниринга
Статистика показывает, что профессия дата-инженера находится на подъеме и спада не предвидится. Например, в статье «Нам нужны не дата-сайентисты, а дата-инженеры», которая всколыхнула все сообщество дата-стартапов, Михаил Эрик (Mihail Eric) говорит, что в компаниях вакансий дата-инженеров на 70% больше, чем вакансий дата-сайентистов. В своих расчетах он использовал данные о найме, которые с 2012 года приводят в Y-Combinator.
В недавнем посте в своем блоге Seattle Data Guy опубликовал интересную статистику Indeed.com по восьми тысячам вакансий: на 9 мая 2021 года дата-инженеры зарабатывали в год на 10 000 долларов больше, чем дата-сайентисты.
Преимущества работы дата-инженером на этом не заканчиваются. По данным исследования The New Stack, конкуренция среди дата-инженеров ниже, чем среди других технических специалистов. The New Stack выяснили: на каждую вакансию дата-сайентиста на LinkedIn и Indeed.com претендуют в среднем 4,76 кандидата, а на вакансию дата-инженера — только 2,53. У подходящих кандидатов шансы получить работу дата-инженера почти в два раза выше.
Можно с уверенностью сказать: чтобы обеспечить себя хорошей работой и многообещающими перспективами на рынке труда, идите в дата-инженеры.
Новый виток эволюции профессии
В некоторых технических кругах саркастическим тоном говорят о «спаде» популярности дата-инженеров и новом витке эволюции этой профессии. Без сомнений, в профессии дата-инженера появляются новые специализации. Например, появляется направление «инженер-аналитик» — название придумали сотрудники компании dbt Labs. Об этом я в июне написал статью.
Скорее всего, со временем дата-инженеры станут более специализированными. Причем специализироваться они будут на разных платформах обработки данных, а не на аспектах работы вроде пайплайнов или отчетов.
Гадая о будущем работы дата-инженера на кофейной гуще, предположу, что эта профессиональная область станет слишком большой, чтобы один специалист смог охватить ее целиком. Да, единороги существуют, но найти такого — редкая удача.
Чтобы создать платформу для работы с данными, еще недавно дата-инженеру требовались знания мощных монолитных технологий, например: Hadoop, Spark, Teradata, Informatica, Vertica. Чтобы эффективно применять эти технологии, нужно было разбираться в нюансах разработки программного обеспечения, сетях, распределенных вычислениях, системах хранения и прочих тонкостях. В числе прочих узкоспециализированных технических задач дата-инженеру приходилось заниматься администрированием и техподдержкой кластеров, следить за накладными расходами, писать пайплайны и преобразовывать данные.
С появлением современной облачной инфраструктуры мы все больше приближаемся к децентрализованной работе команд по обработке данных, платформам самообслуживания для работы с данными, Data Mesh и прочему. А дата-инженеры все больше напоминают рабочую группу по эксплуатации платформы, которая оптимизирует разные параметры большого числа инструментов для работы с данными.
Каков дата-инжиниринг сегодня
На октябрь 2021 года Google выдавал 128 000 уникальных результатов в ответ на запрос «What is data engineering». Достаточно пролистать ответы на первой странице, чтобы понять: к единогласному ответу на вопрос мы еще не пришли.
Дата-инжиниринг — это разработка, развертывание и техподдержка инфраструктуры, систем и процессов, в которые поступают необработанные данные, а выходят высококачественные, единообразные и достоверные потоки данных.
Эти системы поддерживают дальнейшие сценарии использования: BI, аналитику и машинное обучение. Дата-инжиниринг обосновался где-то между управлением данными, DataOps, архитектурой данных, оркестрацией и разработкой программного обеспечения.
Иными словами, дата-инжиниринг формирует для бизнеса осмысленные достоверные данные с предсказуемым качеством. В его основе — инфраструктура и системы, поддерживающие эти данные: от потоковой передачи в реальном времени до пайплайнов пакетных данных, от операционных данных «в движении» до аналитических «в состоянии покоя».
Дата-инженеры — люди, которые с помощью специальных инструментов перемещают и преобразовывают сырые данные, а затем формируют из них надежные данные предсказуемого качества, которые можно использовать для аналитики. В каком-то смысле дата-инженеры — герои сегодняшних Data-driven-проектов, ведь именно они позволяют доверять результатам, полученным с помощью BI, аналитики и моделей машинного обучения.
Инжиниринг данных сегодня = пайплайны?
Сегодня самая важная задача дата-инженеров (и сердечно-сосудистая система дата-инжиниринга) — построение пайплайнов данных. Сбор и прием точной достоверной информации — ключ к организации работы Data-driven-компании.
В прошлом для пайплайнов и обработки данных чаще всего использовали пакетную обработку (Batch-подход. Данные передавали между системами в виде снапшотов и обрабатывали с периодичностью, которая определялась планировщиком заданий (Airflow, Luigi). Сейчас мы видим переход на пайплайны и системы обработки данных, работающие в реальном времени.
Как отмечает McKinsey, стоимость потоковой передачи и отправки данных в реальном времени значительно снизилась, что позволило ей широко распространиться. Интересно будет наблюдать за дальнейшим развитием этой области.
Вне зависимости от способа передачи системы дата-инжиниринга и данные, которые они выдают на выходе, — основа успешной аналитики. Сегодня пайплайны, которые перемещают данные из одного места в другое, — нервная система компании, а достоверность и качество данных — ее пульсирующее сердце. В Validio мы снова и снова слышим, что низкое качество данных — это налог на все, что делают современные Data-driven-компании.
Но сводится ли работа дата-инженеров к созданию пайплайнов данных? Это существенная часть их работы, но часто ее важность переоценивают. И мало кто считает, что пайплайны следует воспринимать всего лишь как средство, а не как конечную цель дата-инжиниринга.
Дата-инженеры выполняют множество других, иногда совершенно разных задач. Давайте как раз об этом и поговорим.
Не все дата-инженеры одинаковые
Чем конкретно занимается дата-инженер, зависит от двух факторов: компании, в которой он работает, и от него самого как от специалиста. Как заметил Зак Уилсон (Zach Wilson), дата-инженеры относятся к одной из двух групп:
-
Предприниматель. Любит Python и SQL, думает в первую очередь о ценности для бизнеса. Гуру дашбордов и мастер коммуникации. Такой специалист часто спрашивает: «Так, и что в результате?»
-
Технарь. Беззаветно предан передовым методам работы и возможностям масштабирования, гуру и творец дата-инжиниринга. Такой специалист часто спрашивает: «Это масштабируемая архитектура/инфраструктура?»
Оба эти амплуа достойные, но автор статьи немного ближе к технарям.
Как следует из названия профессии, дата-инженер внедряет в организации дата-инжиниринг — окультуривает необработанные данные и превращает их в полезные, которые в дальнейшем используют дата-сайентисты, аналитики и специалисты по машинному обучению.
Если посмотреть на пирамиду потребностей обработки данных, к задачам дата-инженеров прежде всего относят сбор, перемещение и хранение данных. А а также ряд задач, связанных с изучением и преобразованием данных. Но все зависит от компании.
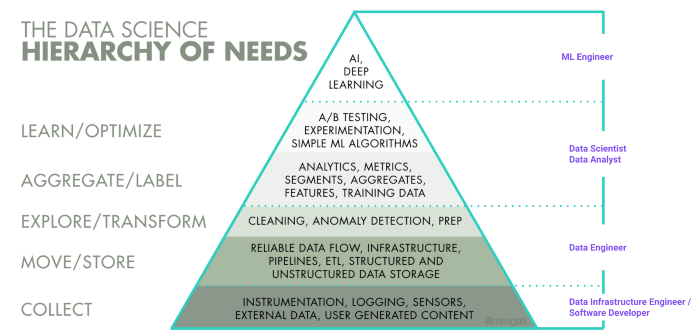 Иерархия потребностей обработки данных (Monica Rogati)
Иерархия потребностей обработки данных (Monica Rogati)Дата-инженеры также занимаются доступностью данных. Что это значит? Как пишет Seattle Data Guy, дата-инженеры часто создают пайплайны, чтобы упростить процесс создания специфических витрин данных. В таком случае данные становятся понятными и доступными, например, для дата-аналитиков или дата-сайентистов, которые могут не знать хорошо SQL. Для доступа и работы с активами им нужен упрощенный набор данных. Поэтому в некоторых компаниях дата-инженеры упорядочивают данные по времени, занимаются их первичной и предварительной обработкой, чтобы упростить жизнь коллегам, которые не слишком хорошо знакомы с преобразованием данных.
В разных компаниях дела обстоят по-разному и у дата-аналитиков и дата-сайентистов разные компетенции в плане работы с SQL, Pandas и другими инструментами по обработке данных.
Реальный пример из жизни: быстро развивающийся скейлап с современной командой по работе с данными
В качестве конкретного примера рассмотрим специалистов по работе с данными в продуктовом онлайн-магазине Oda, одном из самых динамичных скейлапов в Северной Европе. В статье на Medium они показали общее визуальное представление задач своих дата-аналитиков, дата-сайентистов и дата-инженеров.

На схеме видно, что в контексте быстро набирающего обороты европейского скейлапа с современной инфраструктурой данных и командой специалистов по работе с ними дата-инженеры больше всего занимаются тремя задачами:
- созданием и поддержкой платформы обработки или инфраструктуры данных;
- первичной обработкой данных и пайплайнами ETL/ELT;
- обучением сотрудников в дата-команде и в компании в целом.
Третий пункт кого-то удивит. Не исключено, что многим дата-инженерам хотелось бы больше времени посвящать копипастам из Stack Overflow (хи-хи), но, по нашему опыту, они все-таки тратят массу времени на взаимодействие с людьми. Много общаются с другими отделами, чтобы понять, что им нужно, и разобраться, с какими ограничениями придется столкнуться при выполнении задачи. Например, выясняют, какие наборы и потоки данных нужны и сколько времени понадобится, чтобы подключиться к источникам и выгрузить данные.
Среди задач дата-инженеров следует упомянуть техническую поддержку. Например, при создании любого пайплайна или модели данных дата-инженер также закладывает на будущее задачи по техподдержке. Они часто связаны со сбоями в пайплайнах из-за изменений в исходном приложении или API — такое происходит чаще, чем нам кажется на первый взгляд.
Это одна из причин, по которой многие компании переходят на автоматизированные коннекторы, а стартапы вроде Fivetran и Airbyte, работающие в этом направлении, недавно получили хорошее финансирование. Техническая поддержка коннекторов обходится дорого и требует много времени, и такая задача не особенно мотивирует. Поэтому многие Data-driven-компании с удовольствием передают ее на аутсорсинг.
Дата-инжиниринг = новенькие блестящие инструменты?
Несмотря на Кембрийский взрыв, который мы наблюдаем в области инструментария для инфраструктуры данных, сегодня управление и деплоймент в целом гораздо проще, чем десять лет назад.
Новые инструменты и платформы заметно упрощают задачи дата-инженера и рабочие процессы. Дата-инженер постепенно превращается из эксперта в нескольких сложных технологиях в специалиста, который ориентируется на Time-to-value, грамотно сочетает простоту использования и экономичность, чтобы принести компании реальную пользу.
Как недавно написал в своей статье на Medium Петр Янда (Petr Janda), CTO в финтех-компании Pleo, сегодня для создания всеобъемлющей аналитической платформы уже не нужно несколько месяцев. Теперь большие объемы данных можно загрузить в облачное хранилище и начать работать с ними в считанные дни.
Все это стало возможным благодаря современной облачной инфраструктуре. Но несмотря на эту новую суперсилу, работающие системы не появляются из ниоткуда по мановению волшебной палочки. Чтобы их развернуть, нужно разобраться с рядом проблем.
 Пример упрощенного стека данных в Validio
Пример упрощенного стека данных в ValidioВопрос, который я слышу все чаще (и вижу оживленные обсуждения на Hacker News или Reddit), — какие технологии нужно знать дата-инженеру? И знаете, чаще всего вопрос ставят неправильно.
Дата-инженеру нужно разумно воспринимать хайп по поводу технологий и оценивать сложность внедряемых решений, создавать гибкую архитектуру данных, способную меняться по мере появления новых тенденций.
Я бесчисленное количество раз наблюдал, как люди увлекаются «блестяшками». И думают, что дата-инжиниринг сводится к новейшим «революционным технологиям». Особенно в современной экосистеме данных, где инструменты, технологии и методы работы развиваются с головокружительной скоростью. «Революционная технология» = Databricks, Snowflake, dbt, Airflow, Fivetran, Airbyte и так далее и тому подобное.
Но дата-инжиниринг не сводится и никогда не сводился к какой-то определенной технологии. Суть работы дата-инженера — проектирование, создание и поддержка систем и платформ данных так, чтобы получать гибкое и экономичное решение. Инструменты должны приносить пользу, обеспечивать правильные варианты деплоймента и упрощать дата-инжиниринг.
Как указывают в Bessemer Venture Partners, чтобы увеличивать эффективность использования различных частей платформы, нужно обеспечить интеграцию разных инструментов. Для современной облачной инфраструктуры данных и набора различных инструментов по их обработке такая взаимная совместимость — абсолютная необходимость. Данные проходят через пайплайны от исходной системы к конечной, взаимодействуя с разными инструментами. Ни одна новая технология, призванная снизить сложность дата-инжиниринга, не может оставаться одиноким островом в большом океане.
Дата-инжиниринг существует ради Data Science?
Если коротко, то нет.
Но дата-инжиниринг окончательно взошел на почетный пьедестал как центральный компонент любой современной Data-driven-компании именно из-за хайпа вокруг искусственного интеллекта и машинного обучения, когда дата-сайентисты вдруг осознали, что тратят больше времени на преодоление технических сложностей, чем на работу с самими данными.
В 2016 году они 80% времени занимались очисткой и первичной обработкой данных. По данным опроса, проведенного Anaconda в 2020 году, они все еще тратят порядка 45% времени на подготовку данных, в том числе на их загрузку и очистку.

Изображение Marijn Markus
И тут дата-инженеры пришли к ним на выручку. Но в последние годы работа дата-инженеров переросла свои первоначальные задачи. Думаю, нам нужно больше статей о том, что дата-инженеры имеют право на существование и без дата-сайентистов.
Заключение
В современных Data-driven-компаниях количество исходных систем и пайплайнов данных, с которыми мы работаем, неуклонно растет, так что роль дата-инженера будет становиться все более важной в компаниях любого размера.
Так каким же мерилом измерять работу дата-инженеров? Вот несколько общих тезисов, которые, возможно, пригодятся Data-driven-компаниям:
-
Качество данных — количество известных или неизвестных сбоев и отклонений, которые влияют на работу специалистов или приложений с данными.
-
Time-to-production — сколько нужно времени, чтобы подготовить новые источники и потоки данных к использованию в продакшене.
-
Время безотказной работы — доля времени, когда набор данных предоставляют вовремя относительно ожидаемой частоты и требований SLA.
Сегодня качество данных почти всегда важнее их объема. Хотите оценить зрелость компании? Спросите, как в ней оценивают качество данных, а не сколько их есть.
Команда VK Cloud Solutions развивает собственные Big-Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Что почитать по теме:
vipassa
Спасибо. Интересно. Не программист, но прочитал все. Занимаясь технической диагностикой отчасти то же могу претендовать на звание дата-инженера)