В этой статье мы рассмотрим основные принципы миграции БД без даунтайма и дадим быстрые рецепты для наиболее распространенных случаев.
Как работает выкладка в прод?
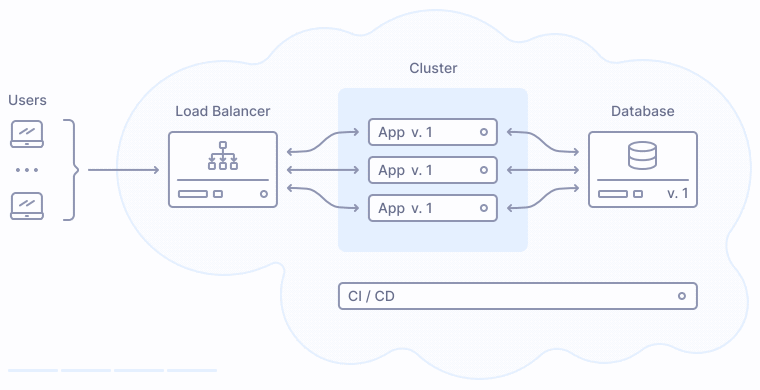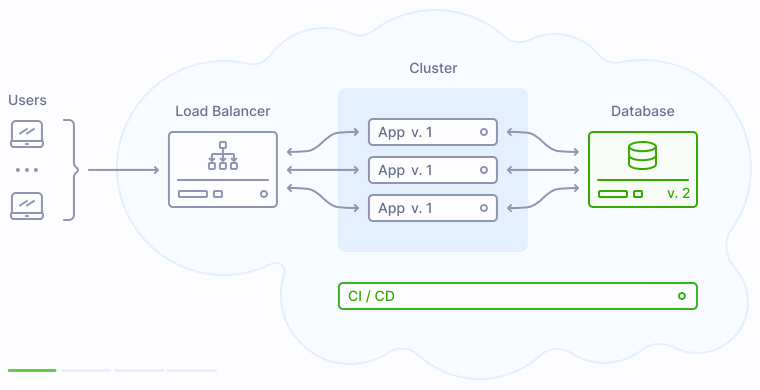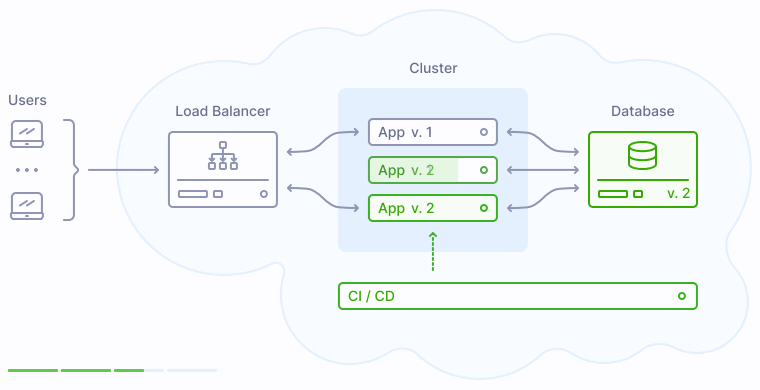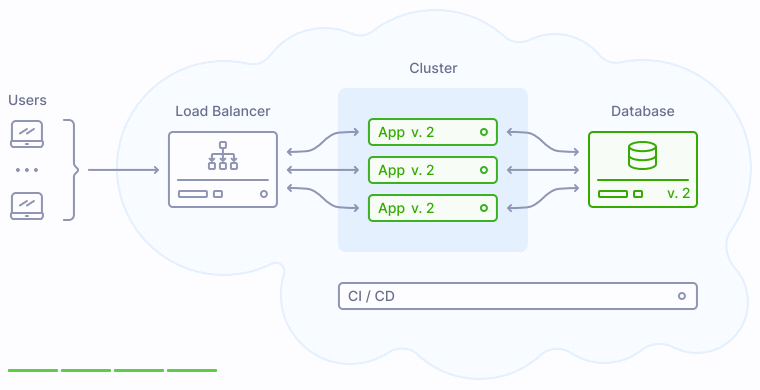
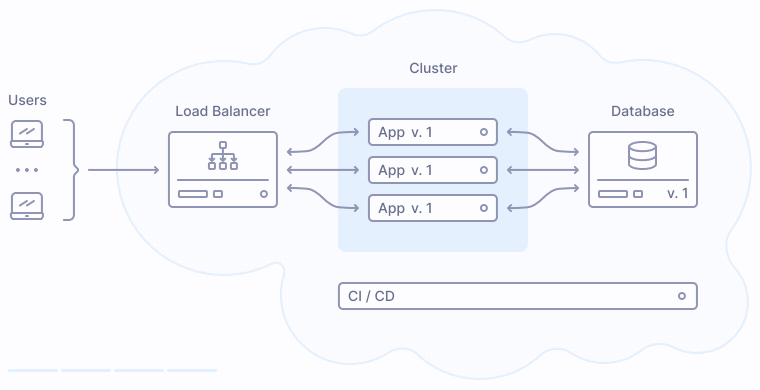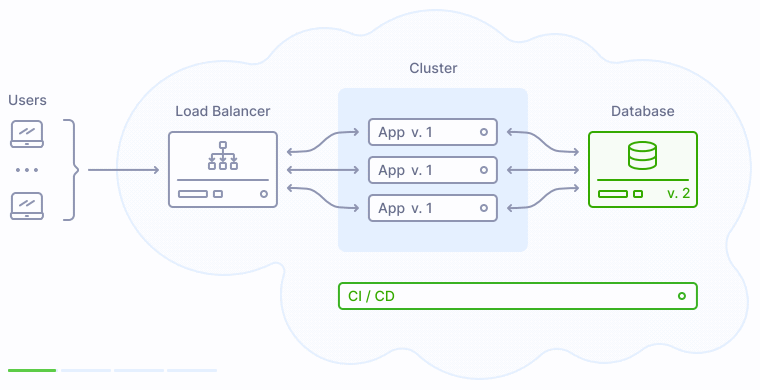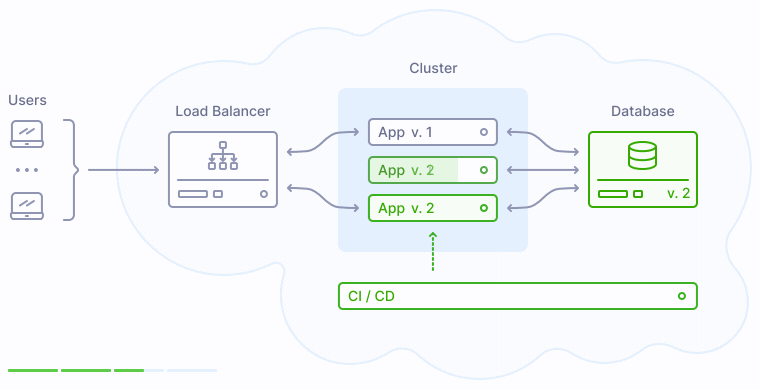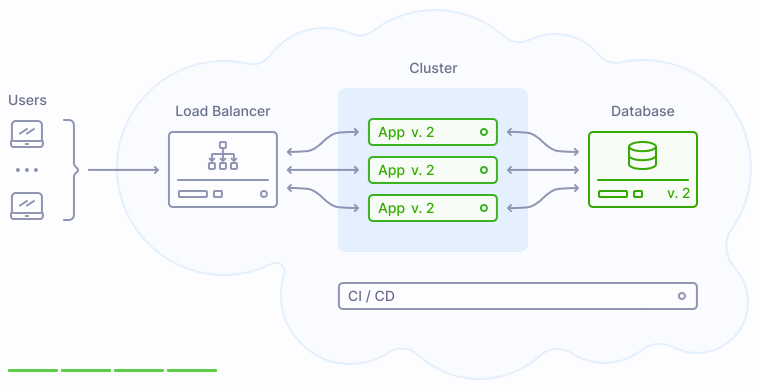
Давайте взглянем на типовой процесс выкладки веб-приложения в прод. Большинство приложений, рассчитанных на выкладку без даунтайма, сегодня опираются на балансировщики нагрузки и оркестрацию контейнеров:

Что происходит во время публикации новой версии приложения? Процесс деплоя заменяет прежние экземпляры приложения на новые поочередно, сначала выводя их из кластера, затем производя обновление, и затем включая обратно в кластер:
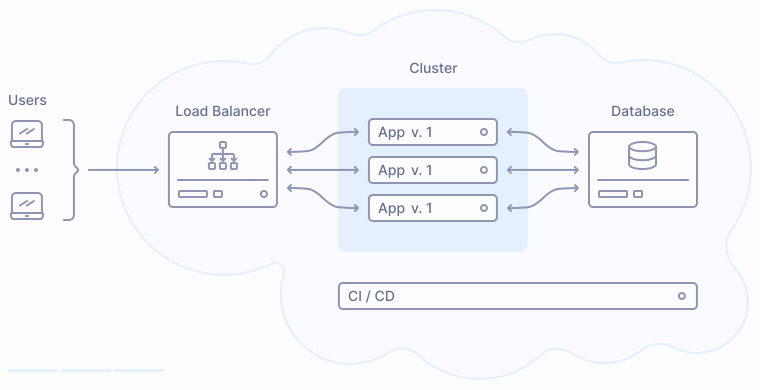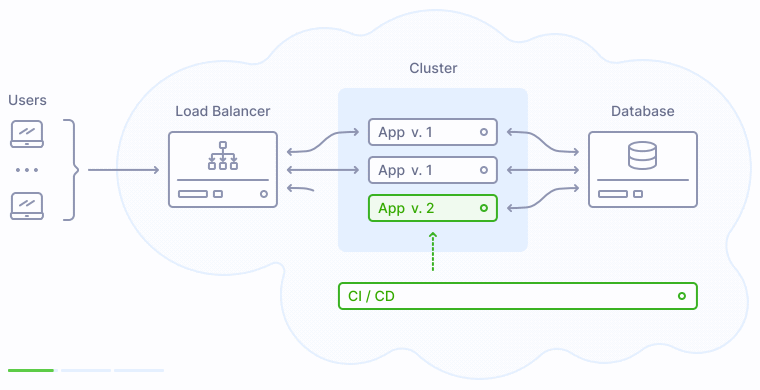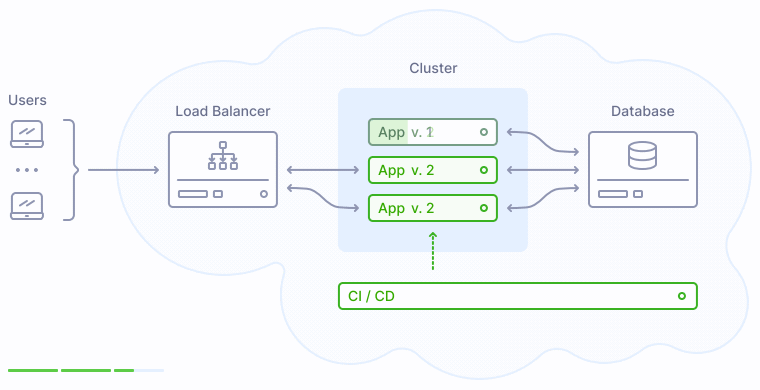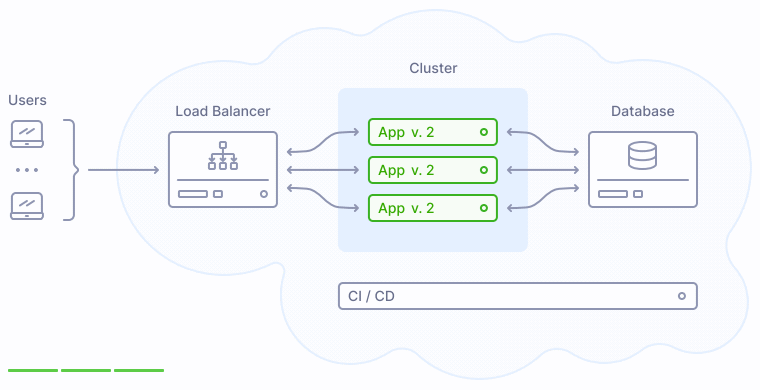
Как показано на иллюстрации выше, версия 2 заменяет прежнюю версию приложения 1 постепенно, таким образом у пользователей не возникает никаких перебоев в обслуживании.
Это все здорово, но что если в новой версии изменения были внесены не только в сам код приложения, но и в структуру базы данных? В отличие от контейнеров с приложением, база данных является общим ресурсом, который обладает собственным состоянием, поэтому мы не можем ее просто клонировать и использовать ту же технику, что и для контейнеров с приложением. Единственный реалистичный вариант - обновлять ее прямо на месте. В какой момент должно быть выполнено обновление?
Поскольку приложение версии 2 опирается на обновленную структуру базы данных, база данных должна быть обновлена до того, как первый экземпляр новой версии приложения будет запущен в продакшене. Соответственно, процесс деплоя, включающий обновление БД, будет выглядеть следующим образом:
Как запускать скрипт миграции БД
Способ запуска скрипта миграции БД важен. На первый взгляд, может показаться заманчивым просто сделать его частью команды старта приложения, типа такого:
<run-db-migrations> && <launch-the-app>
Идея такого подхода заключается в том, что первый экземпляр приложения выполнит миграцию БД, а для остальных скрипт миграции не будет делать ничего, т.к. база данных уже обновлена.
Пожалуйста, НЕ ДЕЛАЙТЕ ТАК.
Во-первых, поскольку мы параллельно запускаем множество экземпляров приложения на нашем кластере, скрипт миграции БД должен корректно обрабатывать попытки параллельного запуска. В зависимости от фреймворка, применяемого для миграций, и того, как написан скрипт, он может или обрабатывать параллельный запуск корректно, или нет. В миграции БД можно выделить три основных состояния - еще не начата, выполняется, закончена. Скрипт должен будет уметь обнаруживать, что миграция уже выполняется в другом процессе, и если так - то ждать. Если он не будет ждать, это может закончиться ошибками приложения, а в худшем случае - испорченными данными.
Во-вторых, даже если скрипт миграции БД обрабатывает попытки параллельного запуска корректно, есть проблема с повторными запусками. Важно, чтобы скрипт миграции попытался выполниться строго один раз, и если произошел сбой - выкладка должна быть немедленно остановлена и произведен откат назад. Например, если скрипт миграции упал из-за таймаута на выполнение долгой SQL-операции, не стоит пытаться повторять его автоматически снова и снова. Разумная стратегия в этом случае - немедленно все отменить, разобраться, починить скрипт и только после этого пробовать еще раз.
Именно поэтому скрипт миграции БД в иллюстрации выше запускается с CI/CD сервера. Разумеется, это не единственный вариант. К примеру, можно запускать его в виде разовой задачи в Kubernetes-кластере как часть процесса деплоя или каким-то другим образом. Главное, помнить об основном принципе - запустить скрипт миграции БД строго один раз, и если что-то пошло не так - отменить выкладку.
Как миграции БД могут вызвать даунтайм?
Как правило, даунтайм происходит по двум основным причинам:
Нарушение обратной совместимости. Как можно видеть на иллюстрациях выше, деплой не является моментальным. В какой-то момент времени база данных уже оказывается обновленной, но при этом в продакшене все еще работают экземпляры прежних версий приложения. Если обновленная база данных несовместима с прежними версиями приложения, это приводит к сбоям, продолжающимся до тех пор, пока новая версия приложения не заменит полностью старую.
Повышенная нагрузка на БД. Миграция может включать в себя “тяжелые” операции, которые приводят к повышенной нагрузке на базу данных или длительным локам, в результате чего приложение в этот момент работает медленно или не работает вовсе.
Давайте рассмотрим на конкретных примерах, как соблюсти обратную совместимость в наиболее распространенных случаях. В конце статьи также коротко поговорим о нагрузке на БД.
Пример 1: добавление нового столбца в таблицу
Представим, что мы разрабатываем новую фичу - аватарки для пользователей. Каждому пользователю после регистрации будет автоматически генерироваться случайная аватарка, и также будет возможность загрузить свою собственную. Для реализации этой фичи нам потребуется новая колонка avatar в таблице Users:

Как обновлять базу от версии 1 к версии 2 в таком случае? Скрипт миграции БД должен будет сделать следующие действия:
Добавить nullable-колонку
avatarв таблицуUsers;Обновить все существующие записи в
Users, сгенерировать случайные аватарки;Когда все данные заполнены, сделать колонку
avatarnon-nullable.
В коде приложения нам потребуется добавить:
Генерацию новых случайных аватарок при регистрации пользователей;
Отображение аватарок там, где это применимо;
Функционал загрузки своей собственной аватарки.
Что случится, если мы просто выкатим все это в продакшен одним махом? Как мы обсуждали ранее, скрипт миграции базы данных выполнится первым. После этого прежние версии приложения будут постепенно заменяться новыми. Сразу после выполнения скрипта миграции у нас будет ситуация, когда в продакшене все еще работают старые версии приложения, но база данных уже обновлена и содержит новую колонку avatar, о которой старые версии приложения ничего не знают.
Результатом будет сломанная регистрация пользователей во время выкладки, потому что прежние версии приложения будут пытаться вставлять записи в таблицу Users, не указывая никаких данных для avatar, которое теперь является обязательным полем. Разумеется, через некоторое время проблема починится сама собой, когда новые версии приложения полностью заменят старые. Однако, поскольку мы говорим о выкладке без даунтайма, нас это не устраивает. Давайте посмотрим, как выложить эту фичу без даунтайма.
Решение примера 1
Давайте не будем пытаться выкладывать эту фичу целиком в один прием, а разобьем выкладку на две фазы. Сначала мы отправим в прод первую фазу, и только после того, как ее деплой полностью завершится - отправим вторую.
Фаза 1
Скрипт миграции БД:
– Добавить nullable-колонкуavatarв таблицуUsersНовые фичи приложения:
– Начать генерировать рандомные аватарки для всех новых пользователей
Поскольку скрипт миграции БД только добавляет nullable-колонку, это не вызовет никаких проблем со вставками новых записей из старой версии приложения. Затем выкладывается обновленная версия приложения, которая начинает заполнять колонку avatar для новых пользователей
Фаза 2
Скрипт миграции БД:
– Сгенерировать случайные аватарки для всех записей вUsers, у которых аватарка пока пустая;
– Сделать колонкуavatarnon-nullableНовые фичи приложения:
– Все оставшиеся фичи связанные с аватарками - отображение их везде, где нужно, функция загрузки своей аватарки, и т.д.
Скрипт миграции БД заполняет все пустые значения avatar для существующих пользователей и затем делает эту колонку non-nullable. Даже если во время этой операции случатся новые регистрации в приложении, колонка avatar для них уже будет заполнена, потому что версия приложения, которую мы задеплоили в фазе 1, уже знает о ней. Таким образом, у нас не должно возникнуть никаких проблем с тем, чтобы сделать колонку avatar обязательной и выложить все оставшиеся фичи, которые от нее зависят.
Пример 2: удаление столбца из таблицы
Что если аватарки для пользователей, которые мы рассматривали в предыдущем примере, не оправдали наших ожиданий? Фича так и не стала достаточно популярной, поэтому мы хотим ее удалить. Мы собираемся удалить весь код, работающий с аватарками, а также удалить колонку avatar из таблицы Users:

Как и в предыдущем примере, если мы просто попробуем выложить такое изменение в прод, это приведет к даунтайму.
Приложение будет серьезно сломано во время деплоя. Как мы обсуждали выше, скрипт миграции БД выполнится первым. Сразу после его выполнения сложится ситуация, когда прежняя версия приложения, опиравшаяся на колонку avatar, все еще работает в продакшене, но самой этой колонки в БД уже нет. Поэтому, пока не закончится деплой и не выложится обновленная версия приложения, весь функционал, зависевший от колонки avatar, будет сломан. Как этого избежать?
Решение примера 2
Используем тот же подход, что и в примере №1 - разобьем деплой на две фазы:
Фаза 1
Скрипт миграции БД:
– Сделать колонкуavatarnullableНовые фичи приложения:
– Удалить весь функционал, связанный с аватарками, убрать все упоминания колонкиavatarиз кода
Превращение колонки avatar в nullable не вызовет никаких поломок в предыдущей версии приложения, которая все еще работает в продакшене. В то же самое время, этот шаг позволяет выложить новую версию приложения, которая больше не использует avatar.
Фаза 2
Скрипт миграции БД:
– Удалить колонкуavatarНовые фичи приложения:
–
После того, как фаза 1 выложена, приложение больше не зависит от колонки avatar, так что мы можем ее безопасно удалить.
Пример 3: переименование столбца таблицы или изменение его типа
Предположим, мы хотим расширить функционал аватарок, обсуждавшийся в примере №1. Вместо хранения названий файлов с картинками аватарок, мы хотим хранить их полные URL, чтобы поддерживать аватарки размещаемые на разных доменах. Полные URL заметно длиннее, поэтому нам потребуется увеличить максимальную длину для столбца avatar. Помимо этого, уже существующие данные нужно будет преобразовать в новый формат. Наконец, сам столбец avatar было бы неплохо переименовать в avatar_url, чтобы его название лучше отражало содержимое:

В этом случае скрипт миграции БД включал бы:
Изменение типа данных столбца
varchar(100) -> varchar(2000);Преобразование существующих данных в новый формат, конвертация названий файлов в полные URL;
Переименование столбца
avatar -> avatar_url.
В код приложения были бы внесены следующие изменения:
Запись данных в новом формате;
Чтение данных в новом формате и необходимые изменения для работы с ними.
Если мы просто выложим все это в прод, произойдет даунтайм.
Приложение будет серьезно сломано во время деплоя. Как мы обсуждали выше, скрипт миграции БД выполнится первым. Сразу после его выполнения в проде все еще будет работать прежняя версия приложения, опирающаяся на колонку avatar в ее прежнем виде. Первая часть скрипта миграции БД, которая увеличивает максимальную длину этой колонки, что само по себе не вызывает никаких сбоев. Однако вторая часть скрипта, конвертирующая данные в новый формат, вызовет некорректное отображение аватарок везде, где они используются. Ну и третья часть, переименовывающая столбец таблицы, вызовет поломку приложения, включая сломанную регистрацию новых пользователей. Прежняя версия приложения не сможет ни читать, ни писать данные об аватарках, потому что имя столбца таблицы изменилось. Приложение будет оставаться сломанным до окончания деплоя, пока не выложится его обновленная версия. Как мы можем этого избежать?
Решение примера 3
Используем ту же технику, что и в примерах 1 и 2 - разобьем деплой этой фичи на фазы и будем выкладывать их последовательно. Данный пример несколько сложнее предыдущих, нам потребуются четыре фазы:
Фаза 1
Скрипт миграции БД:
– Добавить новую nullable колонкуavatar_url
– Не вносить пока никаких изменений в существующую колонкуavatarНовые фичи приложения:
– При записи, сохранять данные в обе колонки - и вavatar, и в новуюavatar_url, в соответствующем формате для каждой
– Не вносить пока никаких изменений в логику чтения данных - продолжать читать аватарки из столбцаavatar
Сначала скрипт миграции БД только добавляет новую nullable-колонку avatar_url, такое действие не вызывает никаких сбоев. Версия приложения, выкладываемая на этом этапе, начинает записывать данные сразу в обе колонки - и в новую, и в старую, подготавливаясь к следующей фазе.
Фаза 2
Скрипт миграции БД:
– Заполнить все пустые значения вavatar_urlданными изavatar, конвертируя их в новый формат (имена файлов в полные URL);
– Сделать колонкуavatar_urlnon-nullableНовые фичи приложения:
– Переключить логику чтения данных на новую колонкуavatar_url;
– Пока что продолжать писать данные в обе колонки - и вavatar, и вavatar_url
Скрипт миграции БД заполняет все пустые значения в новой колонке, конвертируя имена файлов из старой колонки в полные URL в новой. Затем он делает новую колонку non-nullable. Это должно сработать, потому что версия приложения, выложенная в фазе 1, уже начала заполнять avatar_url данными для всех новых записей. Версия приложения, публикуемая в этой фазе, переключается на чтение данных из новой колонки avatar_url, однако все еще продолжает писать данные в обе колонки, чтобы обеспечить обратную совместимость с версией приложения выложенной в фазе 1.
Фаза 3
Скрипт миграции БД:
– сделать колонкуavatarnullableНовые фичи приложения:
– Прекратить писать данные вavatarи удалить все упоминания ее из кода
Скрипт миграции БД делает старую колонку avatar nullable, таким образом мы можем прекратить писать данные в нее и удалить все упоминания avatar из кода.
Фаза 4
Скрипт миграции БД:
- удалить колонку avatar из таблицы UsersНовые фичи приложения:
-
После того, как фаза 3 успешно задеплоена, мы можем удалить старую колонку avatar из базы. Никаких изменений приложения на данной стадии не требуется, оно уже было полностью обновлено в предыдущих фазах.
Общий подход к обеспечению обратной совместимости
Как вы могли заметить, все три примера выше используют одну и ту же технику для избегания даунтайма - разделение деплоя новой фичи на две или более фаз. Разумеется, три примера выше не покрывают все возможные ситуации при миграциях БД, но они призваны помочь понять главную идею, как подходить к этому. Если вы уловили идею и полностью понимаете, как работает ваш процесс выкладки в прод, вы сможете разработать решения для других случаев самостоятельно.
Напомним:
Во время деплоя скрипт миграции БД выполняется первым;
После этого образуется ситуация, когда в проде все еще работают прежние версии приложения, но БД уже обновлена. Это потенциально рискованный момент, в который могут случиться сбои из-за нарушения обратной совместимости;
Вы можете избежать даунтайма, разбивая деплой новой фичи на несколько фаз при необходимости. Планируйте эту разбивку таким образом, чтобы прежняя версия приложения, которая все еще работает в продакшене, всегда была совместима с обновлением базы данных, которое вы собираетесь выкатить;
Примеры выше иллюстрируют, как конкретно планировать фазы деплоя, чтобы избежать нарушения обратной совместимости.
Повышенная нагрузка на БД
Вторая распространенная причина сбоев во время миграции БД - некоторые операции по внесению изменений в базу данных могут создать повышенную нагрузку на сервер БД или же вызвать длительные локи, что приведет к замедлению работы приложения или к его полной недоступности.
Как правило, подобные проблемы возникают при попытках внести изменения в таблицы, которые хранят много данных. Создание новых таблиц происходит быстро, удаление таблиц - также быстро, и внесение изменений в таблицы небольшого размера тоже обычно не создает проблем. Однако, если вы пытаетесь внести изменения в таблицу с большим количеством данных, например, добавить или удалить колонки, создать или изменить индексы или contraint’ы, это может занять много времени, порой недопустимо много. Что можно с этим поделать?
Совет №1. Используйте современную версию БД. Базы данных постоянно развиваются. Например, одной из наиболее желанных фич в MySQL-сообществе была возможность выполнять быстрые DDL-операции, которые не приводили бы к полной перезаписи таблицы. И разработчики прислушались - в MySQL 8.0 представлены значительные улучшения, включая моментальное добавление новых столбцов в таблицу при соблюдении определенных условий. Другой пример - в Postgres версий 10 и более ранних добавление новой колонки со значением по умолчанию приводило к полной перезаписи таблицы, что было исправлено в Postgres v11. Разумеется, нельзя сказать, что производительность любых DDL операций уже находится на безупречном уровне, но все же обновление версии БД потенциально может сделать вашу жизнь легче.
Совет №2. Проверяйте, что будет происходить “под капотом” при внесении изменений в большие таблицы. Во многих случаях можно снизить риск даунтайма за счет использования несколько другого набора операций, выполнить которые серверу БД будет легче. Пара полезных ссылок по этой теме:
Postgres - документация к пакету django-pg-zero-downtime-migrations содержит подробное объяснение, как работают локи в Postgres и какие операции могут считаться безопасными.
Совет №3. Выполняйте обновления в период наименьшего трафика. Если обновление затрагивает большую таблицу, рассмотрите возможность выполнить его в период низкой активности пользователей. Это помогает сразу двумя способами. Во-первых, сервер БД будет меньше нагружен и возможно завершит миграцию быстрее. Во-вторых, даже несмотря на тщательную подготовку, такие миграции могут быть рискованными. Порой бывает сложно полностью протестировать, как обновление сработает в условиях реальной нагрузки на продакшене. Если проблемы все же случатся, во время низкого трафика урон от них будет меньше.
Совет №4. Рассмотрите возможность применения вялотекущих миграций. Некоторые таблицы могут быть настолько большими, что традиционный скрипт миграции БД для них не выглядит жизнеспособным вариантом. В таком случае вы можете внедрить код миграции данных непосредственно в само приложение, чтобы оно работало над фоновым преобразованием данных прямо в продакшене, или использовать специальную утилиту, вроде GitHub's online schema migration for MySQL. Такая миграция обрабатывает данные небольшими порциями и может выполняться дни и даже недели. У вас будет возможность аккуратно балансировать нагрузку на БД от миграции, чтобы она не создавала проблем для конечных пользователей.
Заключение
Миграция базы данных без даунтайма требует определенных усилий, но все же это не прям уж настолько сложно. Две основные причины, по которым происходит даунтайм:
Нарушение обратной совместимости;
Повышенная нагрузка на БД.
Для решения первой проблемы вам может потребоваться разбить деплой новой фичи на несколько фаз, вместо того, чтобы выкатывать в продакшен все сразу. В этой статье мы подробно разбираем три наиболее распространенных примера и даем общие рекомендации, как избегать даунтайма в других случаях.
Секция про повышенную нагрузку на БД описывает общие рекомендации для решения связанных с этим проблем и содержит ссылки для дальнейшего чтения.
Надеюсь, эта статья поможет вам снизить риски даунтайма во время деплоев. Меньше даунтайма - чаще деплои - быстрее движется разработка. Удачных миграций!
Комментарии (48)

VVitaly
04.05.2022 08:22+1:-) Осталось "так же легко" решить еще несколько "проблем" обновления...
1) Штатный откат на "старую установленную версию" (app и db) без downtime
2) Установка обновления (app и db) не с предыдущей версии, а с какой-то более старой (2-3 версии "назад")
Akina
04.05.2022 09:271) Ну это просто. Вставка поля откатывается удалением поля. Переименование поля откатывается переименованием поля. А то что процедуру обновления, откатывающую предыдущее обновление, надо рисовать с нуля - так это мелочи...
2) Ну собственно аналогично... хотя именно в предложенной схеме нет места для "более старой" версии.
VVitaly
04.05.2022 09:441) Поле/поля (а впрочем и таблицы приложения) при смене версии могут быть не только добавлены или изменены, но и удалены... Т.е. "по логике" именно "новая версия" приложения просто должна "знать и уметь" работать с несколькими "версиями/структурами" БД (особенно в распределенных БД). Начиная с того что в определенный момент времени БД находится в "промежуточном" состоянии (часть структур "новая", а часть "старая"), а приложение работать должно безотказно.
2) Вариант "отката без простоя" должен быть предусмотрен "по определению" (углубляться в эту тему наверно не стоит)...

Xeldos
04.05.2022 11:47Откат на старую версию это сложный философский вопрос. Что делать с новыми данными, которые не ложатся на старую схему? Откуда вообще откат, что происходит с бизнес-процессами в физическом мире? Они тоже откатились?
Автору - было бы неплохо добавить обзор различных средств автоматизации. "Просто разбейте на три этапа" это конечно хорошо, но не очень понятно для невырожденных случаев..

FanatPHP
04.05.2022 09:05+5Я понимаю, что статьи пишутся для читателей разного уровня подготовки, но конкретно я как читатель был разочарован, и в какой-то степени чувствую себя обманутым.
Проблема миграций без даунтайма является для меня весьма актуальной, но в итоге я прочитал 10 экранов масла масляного, описывающего очевидные вещи, а в ключевом для меня пункте — только пара абзацев с "общими рекомендациями".В общем, получилось как в старом советском анекдоте:
В клубе объявили лекцию на тему "народ и партия едины".
никто не пришел. Через неделю была объявлена лекция "Три вида
любви". Народу набилось — тьма.
— Существуют три вида любви, — начал лектор. — Первый вид — патологическая любовь. Это — нехорошо, и на эту тему говорить не стоит. Второй вид — нормальная любовь. Это вам хорошо известно, об этом тоже говорить нет смысла. Остается третий вид любви
— советского народа к Коммунистической партии. Вот на этом мы остановимся подробнее...
stebunovd Автор
04.05.2022 09:55+3Я очень рад, что для вас многое здесь является очевидным, серьезно :) Для многих разработчиков это, к сожалению, не так. У нас есть такой вопрос в техническом опроснике на собеседованиях, и после нескольких сотен проведенных собеседований могу сказать что очень редко люди на него отвечают. Что, собственно, и побудило написать эту статью.
Так что если вы хотя бы в общих чертах представляете, как мигрировать БД без даунтайма - поздравляю, вы входите в небольшой процент людей, которые хотя бы знают с чего начать. Уверен, вы сможете разобраться и дальше, и может даже напишете свой пост, покрывающий более продвинутые аспекты - будет интересно почитать.
FanatPHP
04.05.2022 10:26А не будет слишком большой наглостью попросить конкретную формулировку этого вопроса? Может быть как раз на него я тоже не отвечу.
Потому что всё-таки, вопрос "что делать, если база данных уже обновлена и содержит новую колонку avatar, о которой старые версии приложения ничего не знают" выглядит высосанным из пальца (та ничего не делать, у нас половина колонок не используется, и никого это не парит, руки не дойдут их повыкидывать), а вопрос "что делать, если код пытается писать в колонку, которой нет" не выглядит настолько неберущимся. Как минимум, идея сначала проверить, есть ли эта колонка, должна прийти в голову многим.
stebunovd Автор
04.05.2022 10:40Вопрос звучит так:
Как провести миграцию базы данных в продакшене без даунтайма, на примере добавления и удаления колонки для существующей таблицы?
Если видно, что к вопросу требуется пояснение, то добавляем: представьте - вы разрабатываете новую фичу, в рамках которой добавляется новая колонка в существующую таблицу в БД, или же наоборот, удаляется. Как выложить это в продакшен так, чтобы во время выкладки приложение всегда работало, чтобы не было никаких сбоев?
FanatPHP
04.05.2022 11:25Странно, в такой формулировке я не вижу здесь проблемы. Здесь даже нет обязательного условия, что колонка должна быть не nullable (не говоря уже про чехарду с контейнерами в кубере). В итоге добавление вообще нас никак не колышит (ну добавили и добавили — коду, который про неё не знает, на неё и пофиг), а при удалении просто разносим по времени — сначала убираем функционал, который с ней работает, и таким образом сводим задачу к уже решённой, а потом просто дропаем колонку.
То есть с девелоперской точки зрения я вообще не вижу здесь проблемы, упражнение на логику, кто на ком стоял.
Для меня проблема даунтайма — это на 100% ДБА-шная проблема, и вот её решение как раз меня очень и интересовало бы.

omlin
04.05.2022 18:05+2Я кстати согласен с автором касательно того, что многие программисты не представляют, как менять схему данных на живой системе именно с точки зрения процесса выгрузки и программирования. У нас тоже есть такой вопрос в собеседованиях, правда мне больше нравится спрашивать про сплит полей.
А что касается "technicalities", из серии как дропнуть колонку в таблице с 100млн строк "на живую" и не положить мастер при этом, это несколько другая задача, к которой программисты часто не имеют никакого отношения и этот процесс, как вы правильно заметили, лежит в сфере интересов ДБА.
Кстати, вдруг вам поможет, мы для этого использовали gh-ost, очень хорошо работает.
В общем, это две разные темы, и мне кажется, их описывать в одной статье даже может и не стоит, ведь аудитории совершенно разные.
Автору на заметку: может быть имеет смысл уточнить целевую аудиторию статьи.
FanatPHP
04.05.2022 18:12О, спасибо, уже смотрю! Идея интересная.
… и даже очень интересная
Если я правильно понял, они сами руками читают бинлог, и накатывают все DML запросы на таблицу-призрак. И я так глубоко ещё не прочёл, но так понимаю что накат должен идти по таким правилам- вставки идут как есть
- апдейты и делиты проверяют наличие строки и если нету — то задерживают до появления
В общем, задачка не из простых…
Но вот это уже да — реальная рекомендация по миграции без даунтайма. Так что статья свою роль сыграла в итоге! :)
stebunovd Автор
04.05.2022 18:31Спасибо, добавил ссылку на gh-ost в раздел про вялотекущие миграции. Ну и подумаю как можно было бы уточнить ЦА для статьи :)

poxvuibr
04.05.2022 19:59Добавьте ещё liquibase и flywaydb в раздел про то, что нельзя, чтобы на БД в один момент времени работало больше одной миграции. Эти инструменты как раз помогают этого достичь
stebunovd Автор
04.05.2022 21:06Там же не только про то, что нельзя чтобы в один момент времени работало несколько миграций. Там еще и про ретрайи, поэтому меня настораживает фраза у flywaydb про "Auto-migration on startup". Наверняка существуют окружения в которых это допустимо, но если у нас традиционное веб-приложение на кластере - то я бы так не рисковал.
poxvuibr
04.05.2022 21:46Там же не только про то, что нельзя чтобы в один момент времени работало несколько миграций.
И у вас в статье не только про это и инструменты не только такую проблему закрывают ))
Там еще и про ретрайи, поэтому меня настораживает фраза у flywaydb про "Auto-migration on startup".
Вы наверное тут имели в виду, что миграция не должна накатываться два раза по какой-нибудь роковой случайности, да? liquibase это обеспечивает, flywaydb тоже. Хотя я сам использую только liquibase.
Наверняка существуют окружения в которых это допустимо, но если у нас традиционное веб-приложение на кластере — то я бы так не рисковал.
Ваш ответ сначала привёл меня в шок, потому что как раз для традиционных веб приложений liquibase это традиционное решение ))). Но потом я посмотрел на теги и не нашёл там java. Тут то всё и встало на свои места.
liquibase это в мире java считай стандартный инструмент для миграций. Или flywaydb, они делают плюс-минус одно и то же. Их можно интегрировать в приложение или запускать как отдельную утилиту. Если в вашем мире подобных стандартных утилит нет, то рекомендую попробовать.
Правда, для запуска пока что ещё нужна java. Думаю рано или поздно это починят и сделают бинарник без дополнительных зависимостей, но пока вот так.
stebunovd Автор
04.05.2022 22:28+1Каким образом flywaydb, при запуске в виде
<run-db-migrations> && <launch-the-app>, в Kubernetes или другом оркестраторе (ECS, Swarm, ...), в случае сбоя миграции на первом инстансе остановит дальнейшую раскатку приложения, которая выполняется одновременно и параллельно на нескольких инстансах?

nikolai-averin
05.05.2022 01:39Я не большой эксперт в kubernetes, но вроде как это можно решить с помощью настройки maxUnavailable и maxSurge.
stebunovd Автор
05.05.2022 08:41Наверняка можно при помощи настройки закрутить конфигурацию так, чтобы по сути отказаться от параллельного запуска новых инстансов и запускать их последовательно и строго по одной попытке.
Даже если риск с повторными миграциями и уйдет, на мой взгляд это неоправданная жертва, которая серьезно затормозит процесс раскатки новой версии, и которой можно легко избежать, заменив запуск миграций на старте приложения запуском их отдельно перед началом раскатки на кластер.
poxvuibr
05.05.2022 11:07Каким образом flywaydb, при запуске в виде <run-db-migrations> && <launch-the-app> в случае сбоя миграции на первом инстансе остановит дальнейшую раскатку приложения, которая выполняется одновременно и параллельно на нескольких инстансах?
Ну вы же сами написали, что не надо так делать )). Что надо раскатывать миграции через CI.
Однако, если вам интересно обсудить именно <run-db-migrations> && <launch-the-app>, то тут всё просто. flywaydb сделает так, что одновременно будет работать только одна миграция. Когда эта миграция упадёт с ошибкой, приложение, естественно, запущено не будет.
Но, как вы справедливо отметили, миграция одновременно запускается на нескольких инстансах. На одном она работает, остальные ждут. Когда миграция на одном инстансе упадёт, то сразу заработает такая же миграция на другом инстансе, которая сразу же упадёт, потому что начнётся с того места на котором закончил предыдущий инстанс. Всё попадает, деплой завершится неудачей, можно спокойно разобраться по логам, что пошло не так.
Плюс ещё есть небольшая вероятность, что первая миграция упала по таймауту. Допустим больше пяти минут работала. Вторая миграция тогда тоже скоре всего упадёт по таймауту, но впустую потратит при этом пять минут. И так далее, по пять бесполезных минут на инстанс
Для того, чтобы так не получалось обычно поступают следующим образом. Второй инстанс он же ждёт, пока первый закончит миграцию. Максимальное время ожидания — параметр, который можно задать в настройках. Если он будет равен, допустим четырём минутам, то после пятиминуной миграции на первом инстансе, остальные инстансы даже не будут пробовать, а сразу упадут по таймауту.
P. S. Да, если вас интересует подробности того, как liquibase добивается того, чтобы больше одной миграции не работало — то ответ простой. С помощью локов в специальной таблице в БД ))
nikolai-averin
05.05.2022 01:53"Auto-migration on startup" - это одна из стратегий. Есть еще режим "Validate", который сверяет миграции в приложении с теми, что были применены в БД. Это позволяет, например, реализовать схему, когда один экземпляр приложения отвечает за накатку миграций, а остальные делают только валидацию.
poxvuibr
04.05.2022 14:58+1Я очень рад, что для вас многое здесь является очевидным, серьезно :) Для многих разработчиков это, к сожалению, не так.
Полностью поддерживаю! Я сам, знаете ли, своего рода разработчик и написал практически точно такую же статью, как ваша, только другую ))). Правда ещё не опубликовал. И мне тоже многие говорят, что ничего нового тут нет и так далее.
И, наверное, самым красноречивым доказательством того, что такие статьи очень нужны будет тот факт, что у вас в процедуре миграции баг ))). Возможно не фатальный, но самый настоящий. Получается что те люди, которым содержимое вашей статьи кажется очевидным, его не заметили. А значит такие статьи нужны!
P. S. Я не стал рассказывать в чём баг, потому что возможно вам хочется самому разобраться где он. Если вам интересно, я скажу в каком месте он спрятался. Или могу сразу рассказать что за баг, где он и к чему может привести, только напишите )))
stebunovd Автор
04.05.2022 15:46спасибо! Вполне возможно что есть баг, все люди ошибаются. Если подскажете где - буду признателен
poxvuibr
04.05.2022 17:37Если подскажете где баг — буду признателен
Он в сценарии переименования таблицы ))
На втором шаге из кода приложения полностью убирается работа с полем avatar. А на первом шаге чтение происходит именно из этого поля.
Если раскатать код из второго шага и дать ему совсем немного поработать, то он запишет новые значения в avatar_url. Дальше возможно придётся делать откат.
После отката старый код будет читать значения из поля avatar. А там значение устаревшее.
Чтобы такого не могло случиться, нужно делать дополнительный шаг. Вторым шагом не прекращать работу с полем avatar, а по прежнему писать и туда и туда, но читать уже из новой колонки.
Фаза 2 у вас соотвественно превращается в Фазу 3, а Фаза 3 в Фазу 4
stebunovd Автор
04.05.2022 17:57+1Спасибо, понимаю ваш пойнт. Не уверен, правда, что это можно считать багом. Например, в моей любимой парадигме "Continuous Deployment" откаты в таком виде вообще не делаются. Там стратегия "всегда только вперед", то есть если нужно сделать откат, то это git revert - push в репозиторий - и опять вперед. Соответственно, в таком случае откат включал бы в себя не только возврат к прежнему коду приложения, но и скрипт для обратной миграции данных.
Разумеется, разные приложения используют разные стратегии для выкладки, да и риск связанный с миграцией данных может сильно отличаться. Для каких-то случаев предложенный вами подход наверняка был бы полезен и помог бы дополнительно подстраховаться от сбоев. Однако, я не уверен что его стоит применять строго всегда и везде.
poxvuibr
04.05.2022 18:14Спасибо, понимаю ваш пойнт. Не уверен, правда, что это можно считать багом.
Всё зависит от контекста. Если в вашем случае в потере нового аватара нет ничего страшного, то это действительно не баг ))
Например, в моей любимой парадигме "Continuous Deployment" откаты в таком виде вообще не делаются.
На откатах проще объяснять, но вообще точно такая же проблема будет когда на среде одновременно работает два инстанса с первой и второй версией кода. Вторая версия кода обновит аватар в avatar_url, а первая версия этого обновления не увидит, потому что будет смотреть на поле avatar.
Для каких-то случаев предложенный вами подход наверняка был бы полезен и помог бы дополнительно подстраховаться от сбоев. Однако, я не уверен что его стоит применять строго всегда и везде.
Вы о дополнительном шаге? Думаете в в вашем случае он не актуален?
stebunovd Автор
04.05.2022 18:38+1Вторая версия кода обновит аватар в avatar_url, а первая версия этого обновления не увидит, потому что будет смотреть на поле avatar.
да, действительно. Вероятность не очень большая, потому что записи, как правило, случаются сильно реже чтений, но для популярных нагруженных сервисов может проскочить. Спасибо что заметили!
stebunovd Автор
04.05.2022 21:01поправил. К сожалению, вместе с исправлением пришлось убрать искрометную фразу про "трехфазный деплой", жаль...
FanatPHP
04.05.2022 16:15+2Я, кстати, не говорил, что статьи по основам, "которые всем известны" не нужны. Основы тоже надо подтягивать до современного уровня. Просто замах конкретно здесь не соответствует содержанию. И проблема именно в этом несоответствии.

Rukis
04.05.2022 11:12+1И всё же, второй раздел "Повышенная нагрузка на БД" в рамках названия статьи раскрыт недостаточно. Советы - это хорошо, но всё же хотелось бы посмотреть конкретные примеры, как в первом разделе. Типа "вот гигантская таблица и нам надо добавить в неё колонку, операция блокирующая - не беда, просто возьмите обычный советский..."
stebunovd Автор
04.05.2022 11:27Полностью согласен, тема нагрузки большая и затронута лишь поверхностно. Почему - во-первых, и так уже длинная простыня получилась :) Во-вторых, в этом месте уже начинаются заметные различия между БД. Как говорится, что мускулю хорошо - то постгре смерть, или наоборот. Ну и в-третьих, статья рассчитана в качестве вводной, чтобы побудить людей этим заниматься. По моим наблюдениям, на многих проектах люди просто даже не пытаются. Если они пробуют делать первые миграции без даунтайма и достигают успехов - то дальше, как правило, все получается. И решения для больших таблиц находят самостоятельно, и все такое. Главное, начать :)

alan008
04.05.2022 23:22Создать копию таблицы, но уже с новой колонкой, и постепенно переключать приложение на эту копию, а потом дропнуть исходную таблицу.


oragraf
04.05.2022 12:20+1Вообще тема миграции довольно обширна. Для более-менее успешного выполнения еще на этапе проектирования структуры БД необходимо предусмотреть как жизненный цикл данных, так и возможность миграции. Для миграции, например, нужно чтобы приложение обращалось к логическому слою БД. Т.е. приложение->(view, ХП, instead of триггера и т.д.)->физические таблицы, служебные представления, удаленные подключения к другим БД и т.д. Метаданные в БД обновить можно быстро(не всегда, увы), как с увеличением версии, так и с уменьшением. А обновление физической структуры можно сделать асинхронным. К сожалению, на этапе проектирования мало кто задумывается об этом. Причина, имхо, в том, что разработчиком-архитектором выступает, как правило, архитектор приклада(джавер, питонист, пхпшник etc). Он знает БД на уровне "select * from table t"(я тут утрирую, конечно). А потом начинается "веселье".
Akina
04.05.2022 13:28Он знает БД на уровне "select * from table t"(я тут утрирую, конечно). А потом начинается "веселье".
К сожалению, тут нет никакого утрирования - оно сплошь и рядом. И первое веселье - это когда сервер БД используется как тупая помойка для данных, а абсолютно вся обработка выносится на прикладной уровень - сперва волочём всю таблицу на клиента, там долго жуём, и затем выплёвываем обратно... даже индексов, и тех порой нету. Увы, достаточно частая штука, да к тому же интенсивно поощряемая различными фреймворками и библиотеками.

dph
05.05.2022 01:35Стоило бы еще указать, что alter table add column - не совсем безопасная операция. Хотя в современных СУБД изменяются только метаданные, но она все равно требует эксклюзивную блокировку. И, например, в сценарии "длинный отчет, alter table, мелкие пишущие транзакции", все мелкие транзакции будут ждать окончания отчета (т.е. фактически таблица будет заблокирована). Перед миграциями обязательно нужно закрыть все длинные транзакции на таблице (или достоверно знать, что их не может быть).
nikolai-averin
05.05.2022 01:47При использовании CI/CD сервера для накатки миграций каким образом накатывать их на локальные окружения разработчиков?
Одно из удобств упомянутых ранее инструментов вроде flyway и liquibase, а если быть точнее в целом стратегии обновления схемы через приложение, в том, что процесс одинаков для всех окружений - где бы приложение не запустилось, оно либо обновит схему до нужной версии, либо упадет, сообщив, что схема несовместима.
stebunovd Автор
05.05.2022 08:29CI/CD в статье упомянут только в контексте накатки миграций в проде. Это только способ запуска, который никак не ограничивает какой фреймворк для миграций будет использован. Я абсолютно ничего не имею против flyway, liquibase и любых других инструментов. Речь всего лишь о том, как их запускать.
В окружении разработчика, разумеется, CI/CD не нужен. Мы же не пытаемся обеспечить там zero-downtime, верно? И вообще, зачем пытаться запускать окружение разработчика на кластере и за балансировщиком нагрузки?
nikolai-averin
05.05.2022 14:25Мы же не пытаемся обеспечить там zero-downtime, верно? И вообще, зачем пытаться запускать окружение разработчика на кластере и за балансировщиком нагрузки?
Конечно, нет. Но мы пытаемся сделать процесс разработки удобным и безопасным не только в контексте выкатки на прод, но и для разработчиков, верно?
Поймите меня правильно, я не оцениваю предлагаемый вами подход как правильный или неправильный, а хочу понять как он в целом работает на практике.
poxvuibr
05.05.2022 15:25+1Но мы пытаемся сделать процесс разработки удобным и безопасным не только в контексте выкатки на прод, но и для разработчиков, верно?
Да, действительно. Поэтому накат миграций через liquibase при старте приложения на проде будет выключен средствами конфигурации. А в конфигурации для локального окружения разработчика он будет включен. И будет всё очень удобно.
На практике, конечно, когда у нас есть большая многокомпонентная высоконагруженная система, то скорее всего разработчики не будут разворачивать её локально, а будут запускать локально какой-то компонент и подключать его к удалённой среде. И тут автоматический прогон ликви скриптов конечно скорее вреден. В таком воркфлоу автоматом скрипты прогоняются только для того, чтобы создать стуруктуру БД под юнит тесты ))
stebunovd Автор
05.05.2022 18:16... накат миграций через liquibase при старте приложения на проде будет выключен средствами конфигурации. А в конфигурации для локального окружения разработчика он будет включен. И будет всё очень удобно
+1, отличный вариант.
Конечно, есть старая програмистская мудрость, что надо стремиться чтобы окружение разработки было максимально приближено к продакшену. Однако, в современных реалиях веб-разработки абсолютно точного сходства прямо во всем-всем-всем добиться очень сложно, да и не нужно. Касательно ОС, версий библиотек и фреймворков - без проблем, дело важное и нужное, тем более что системы сборки и всякие докеры значительно упростили задачу, грех не пользоваться.Однако, когда дело касается инфраструктуры - на мой взгляд, стремиться к точному сходству не стоит. В продакшене у нас может быть Kubernetes, а локально - Docker Compose, и это нормально. В продакшене приложение запускается в нескольких экземплярах, а локально - в один, и это хорошо. В продакшене миграции запускаются одним образом, а локально - другим, и так удобнее.
Akina
Непонятно, почему генерация значения вынесена на вторую фазу миграции. Во-первых, она совершенно не помешает ничему, если будет выполнена на первой фазе, во-вторых, эта генерация может быть выполнена неявно присвоением полю свойства DEFAULT, в третьих, это позволит сразу задать NOT NULL для вставляемого поля, в четвёртых, при создании новой записи старой версией кода, не присваивающей значения полю, оно будет присвоено автоматически.
PostgreSQL: https://dbfiddle.uk/?rdbms=postgres_12&fiddle=1718110eda671e2d6ce06ba2e4604c2e
MySQL: https://dbfiddle.uk/?rdbms=mysql_8.0&fiddle=1718110eda671e2d6ce06ba2e4604c2e
SQL Server: https://dbfiddle.uk/?rdbms=sqlserver_2017&fiddle=cc70d13f81018504022fb7a90161a241
Как итог - разделение миграции на две фазы становится абсолютно бессмысленным мероприятием.
Точно так же, свойство DEFAULT поля упрощает процедуру. Достаточно на первой фазе обновить приложение и выпилить работу с полем, а на второй фазе дропнуть само поле.
По той же схеме можно упростить и решение третьего примера.
PS. Подозреваю, что неявной причиной усложнённой схемы миграции является неаккуратное программирование. Например, многие гражданы очень любят опускать список полей присвоения в запросах INSERT - типа, структура таблицы известна, значения лягут куда надо, зачем лишние буквы в запросе? Ну так за такие вещи надо просто надавать по рукам, чтобы в следующий раз неповадно было...
MadridianFox
Вы приводите решение для простой ситуации, когда значение нового столбца можно рассчитать средствами СУБД. Такое не всегда возможно, да и если логика формирования значения столбца настолько проста и стабильна что мы её помещаем в БД, то потребность в столбце вообще отпадает.
Автор же показывает обобщённое решение, которое подходит в любой ситуации. Да, его можно оптимизировать в частных случаях, но будет неправильно говорить, что раз в частных случаях можно проще, то описанный подход вообще не нужен.
Akina
Я в общем согласен с Вашими возражениями. Однако я оперирую именно приведённым текстом. И именно для него обобщённое более сложное решение - избыточно. Потому либо сам пример должен быть усложнён, либо должно быть явно описано, почему выбран более сложный подход к решению - вот нечто вроде Вашей ремарки.
Вот именно эта причина - лично для меня крайне сомнительна. Речь идёт не о кастомном значении (например, задаваемом пользователем), а о статическом значении по умолчанию, ссылке на "заглушку", которое хорошо известно и либо вообще фиксированное, либо, как максимум, задаётся в некоей служебной таблице базы данных. Но в момент миграции это значение - гарантированно статическое и неизменное.
chesar
Стоит избегать значения по умолчанию при добавлении столбца в таблицу, иначе на больших объёмах все запросы к таблице будут блокироваться, пока таблица не перепишется полностью. Это может занять часы.
stebunovd Автор
Возможно, речь идет про Postgres версий 10 и раньше. Такая проблема была устранена в Postgres v11, я упоминал об этом в статье.