
Jovian Blues by ShootingStarLogBook
Рефакторинг написанного в Notebook кода для запуска в продакшене — трудная и ресурсоемкая задача. Команда VK Cloud Solutions перевела материал о том, как с помощью MLOps-инструментов и приемов сократить время от исследования до запуска решения. Описанное в статье — результат структурированного опыта дата-сайентистов и ML-разработчиков из сотен компаний.
Что следует помнить при деплое модели в продакшен
Когда я думаю о продакшене, первое, что приходит на ум, — это передача продукта другой команде внутри компании или за ее пределами. Значит, при деплойменте нам нужны надежные и измеримые результаты. Плюс важно снизить риск появления багов на проде. Поэтому мы должны тестировать не просто код, а проект целиком: модель, данные, пайплайн и т. п.
Если во время работы возникнет баг (а рано или поздно это случится), мы должны воспроизвести рабочее окружение. Значит, нам нужен доступ ко всем компонентам и версиям. И наконец, нужно максимально автоматизировать процесс деплоймента, чтобы уменьшить количество трудностей при передаче кода между командами исследований и MLOps.
Вернемся к исходной точке. Обычно мы начинаем проект с тестирования и прототипирования гипотезы, и Notebooks — наш незаменимый помощник в этом деле.
Project Jupyter
Project Jupyter появился на свет в 2014 году на основе IPython. Его с энтузиазмом приняли в Data-Science-сообществе и де-факто признали стандартным инструментом для прототипирования. В 2017 году признание стало официальным: Project Jupyter получил награду ACM Software Systems Award, удостоившись той же чести, что и Unix, Web, Java и другие выдающиеся решения.
Google Trends для Project Jupyter
Однако в некоторых Data-Science-сообществах о Notebook говорят как о вселенском зле. Я с этим не согласен и думаю, что Notebook — это прекрасно! Он позволяет нам работать с кодом в интерактивном режиме.
Множество компаний, в том числе DagsHub, размещают инструкции и интерактивные руководства в интерфейсе Notebook. В нем есть встроенные визуализации, с помощью которых можно поделиться работой с коллегами по техническому цеху или стейкхолдерами, которые не хотят углубляться в технические детали. Благодаря всему этому он отлично подходит для быстрого создания прототипов.
Недостатки использования Notebook в продакшене
По мере развития и усложнения проекта, не говоря уже о его запуске в продакшене, вы, вероятно, упретесь в стену. В нашем исследовании мы выявили пять основных трудностей, с которыми сталкиваются дата-сайентисты:
-
Воспроизводимость. Notebook позволяет запускать код в произвольном порядке и редактировать ячейки после выполнения кода. Это огромная проблема с точки зрения воспроизводимости: при проведении эксперимента приходится тратить много сил на отслеживание состояния окружения и переменных.
-
Контроль версий. Notebook Jupyter — это большие файлы JSON, которые Git различает не слишком хорошо. Отсюда сложность проверок и объединения изменений.
-
Отладка. У Notebook есть инструмент отладки, но по мере увеличения объема кода использовать этот инструмент все неудобнее.
-
Тестирование и повторное использование. Код в ячейках Notebook нельзя вызвать из внешних систем или легко протестировать.
-
CI/CD. Не хватает хороших CI-/CD-инструментов для автоматизации процесса деплоймента.
Некоторые заходят так далеко, что даже развертывают Notebook в продакшене, что лично я делать не рекомендую. Это не соответствует отраслевым стандартам, рабочим процессам и передовым методам работы.
Кроме того, в Notebook нет подходящих CI/CD-инструментов для поддержки жизненного цикла деплоймента. Notebook нуждается в основательной чистке и упаковке библиотек, что не входит в компетенцию дата-сайентиста. Кроме того, Notebook сложно запускать, когда на проде используются и другие инструменты.
«Да ну? Netflix развертывает свои Notebook на проде», — аргумент, который я часто слышу в MLOps-сообществе. Да, некоторые классные компании используют этот инструмент в продакшене, но они вкладывают много ресурсов в поддержку таких процессов. У вас этих ресурсов, скорее всего, нет, как и желания их создавать под эту конкретную задачу.
С разрешения HamelHusain
Компоненты решения проблем с Notebook
С учетом описанных выше трудностей и нюансов продакшена, я собрал вместе передовые практики и объединил их в структурированную схему, основанную на шести компонентах:
-
Преобразование в скрипты. Преобразуем код в функции, реализуемые в скриптах.
-
Стратегия монорепозитория. Используем структуру «единый репозиторий для анализа данных», чтобы снизить сложность и масштабы работы.
-
Версионирование ВСЕГО. Отслеживаем версии всех компонентов проекта — кода, данных, модели и т. п.
-
Трекинг экспериментов. Автоматизируем процесс логирования хода экспериментов. Так нам будет проще понять историю проекта, а другим — проверить общие результаты.
-
Логика экспорта. Переносим логические шаги во внешние скрипты, чтобы не использовать Notebook в продакшене и работать с единой кодовой базой.
-
Модульное тестирование. Пишем тесты для компонентов проекта и больше занимаемся тестированием базовых компонентов, которые являются основой для других.
Пример сценария
В нашем примере тимлид только что поговорил с советом директоров, и на горизонте замаячил новый проект «Спасем мир». Нам только что выслали набор данных, и, само собой, готовая модель нужна ASAP! Так что мы открываем новый Notebook и беремся за дело.
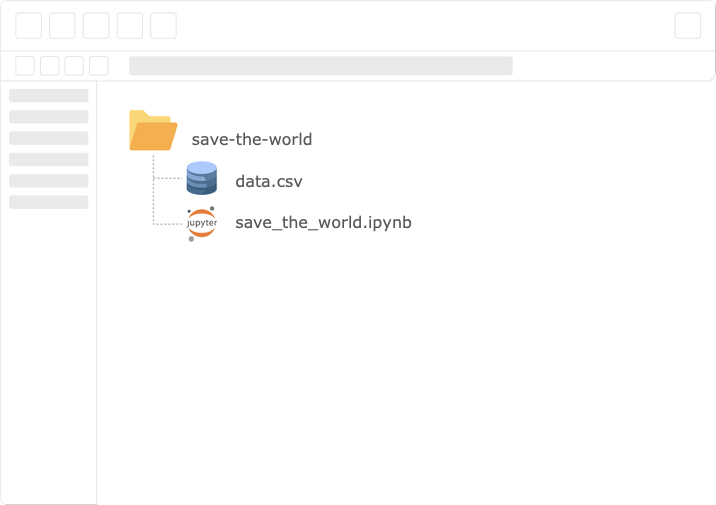
Структура проекта
Преобразование в скрипты
Прежде всего изучим имеющиеся данные. Например, проверим их распределение.
Псевдокод в Jupyter Notebook
Теперь перейдем к важному концептуальному изменению, которое нам нужно сделать. Получаем первоначальный фрагмент кода, который выполняет то, для чего его написали, и рефакторим код в функцию Python, которая не полагается на глобальные переменные и принимает все как аргументы. Сохраняем функцию в скрипте Python, не в Notebook. Теперь ее можно вызвать из любой части проекта.
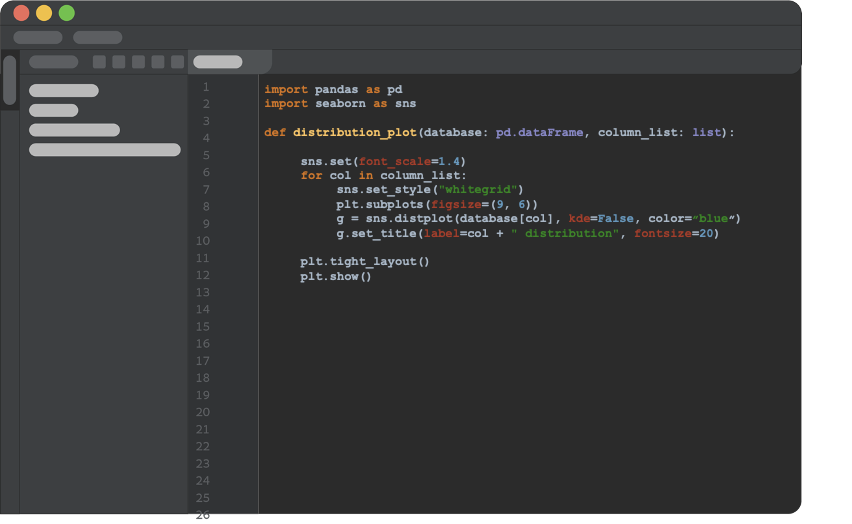
Псевдокод IDE
Далее импортируем функцию в Notebook и работаем.
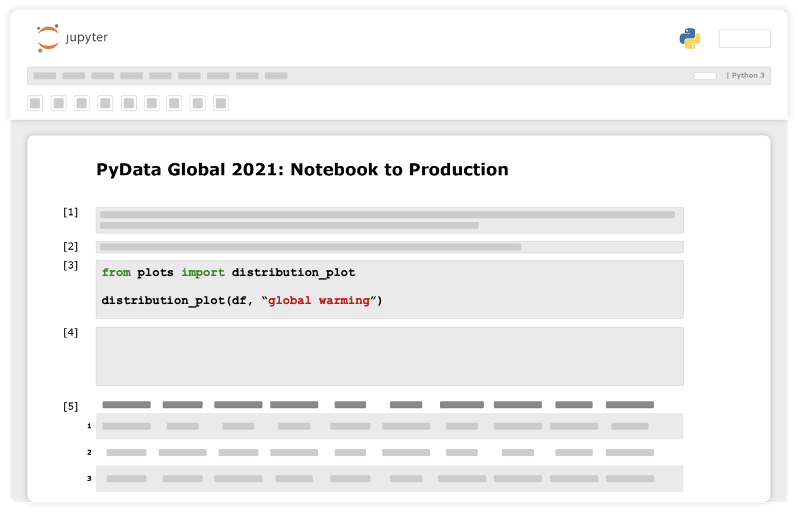
Псевдокод в Jupyter Notebook
Преобразование в скрипты дает следующие возможности:
-
Версионирование кода. Теперь можно контролировать версии кода с помощью стандартных инструментов.
-
Нет скрытого состояния. Входные и выходные параметры функции четко определены, побочных эффектов нет. Код стал повторяемым, более чистым и лучше поддается тестированию.
-
Не нужно делать одну и ту же работу дважды. Можно повторно использовать код как в этом, так и в других проектах.
-
Проверка оформления кода. Доступны стандартные для отрасли инструменты статического анализа, чтобы находить ошибки, баги и подозрительные конструкты.
Монорепозиторий
Теперь наш проект гораздо проще разбить на модули, и это преимущество надо использовать. Повысить масштабируемость, внедряя старую добрую стратегию единого репозитория, — принцип разработки, когда код для разных проектов хранится в одном репозитории. Эту стратегию используют такие компании, как Google, Microsoft и другие.
Что связывает единый репозиторий и Data Science? Любой Data-Science-проект можно разделить на несколько этапов, которые совершенно не связаны друг с другом, например EDA, обработку данных, работу с ML-моделями.
Если отнестись к каждому этапу как к отдельному компоненту, то можно разделить проект на подзадачи или подпроцессы. Мы сможем ускорить работу, если разделим задачи между разными членами команды — они будут реализовывать части проекта параллельно.
В такой разработке каждый следующий этап зависит только от результатов предыдущего. Например, для тренировки ML-моделей нужны только результаты обработки данных. Поэтому мы хотим расширить возможности минимального рабочего пайплайна и сделать так, чтобы каждая подгруппа приступила к работе над своей задачей. Как только команда завершает пригодный к использованию продукт, она выпускает его в виде обновления.
Итак, у нас есть модуль Python для каждой подзадачи, которая, с одной стороны, стоит особняком, а с другой — выступает неотъемлемым компонентом разрабатываемого проекта. Более того, вместо одного длинного Notebook для всего проекта у нас по одному Notebook на задачу.
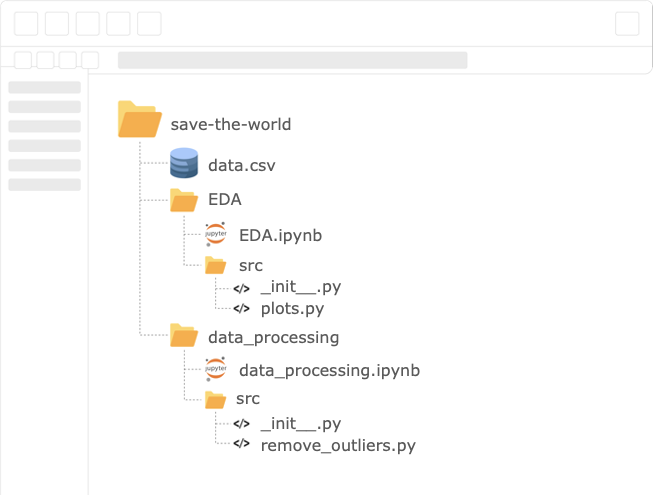
Структура проекта
Монорепозиторий дает следующие возможности:
-
Масштабирование. Мы можем увеличивать количество специалистов, работающих над проектом, оптимизировать время выпуска продукта и двигаться к цели в несколько раз быстрее.
-
Поддержка, проверка и устранение багов. С небольшими Notebook, приспособленными под конкретную задачу, удобнее работать, проверять код и устранять ошибки.
-
Знакомство новых сотрудников с проектом. Благодаря четкой структуре проекта новым сотрудникам проще вникнуть в курс дела.
Контроль версий
В совместной работе самое главное — контроль версий. Для этой задачи мы используем Git, который отлично подходит для параллельной работы и отслеживания версий кода. Git позволяет использовать стандартные CI-/CD-инструменты, одним щелчком возвращаться на предыдущий этап, изолировать продакшен и делать много других вещей. Подробнее о том, как все это работает, можно прочитать в статье Мартина Git for Data Science.
А что насчет других артефактов? Допустим, команда по обработке данных подготовила новый набор данных — нужно ли им просто перезаписать старую версию? А может, зафиксировать ее, создав новую папку со значимым именем (например, new_data_v3_fixed_(1)_best.csv)? Ни один из вариантов нам не подходит, ведь нужно контролировать версии больших файлов.
Git задумывался как инструмент управления проектами по разработке программного обеспечения и контроля версий текстовых файлов и файлов с программным кодом. Следовательно, для больших файлов он не подходит.
Чтобы решить проблему версионирования больших файлов, создали расширение Git LFS (систему для работы с большими файлами), которая справляется с этой задачей лучше, чем Git, но все-таки сбоит при наращивании масштаба.
Кроме того, ни Git, ни Git LFS не оптимизированы для работы с Data-Science-процессами. Чтобы преодолеть эту трудность, в последние годы создали много мощных инструментов, например DVC, Delta Lake, LakeFS и другие.
В DagsHub мы интегрировали DVC. Это Open-Source-решение, в котором реализована поддержка версионирования пайплайнов и удаленного хранения у многих облачных провайдеров. Кроме того, DVC функционирует как расширение Git, которое позволяет и далее использовать в работе стандартный Git-процесс.
Если вы не хотите использовать оба инструмента, я рекомендую FDS — Open-Source-инструмент, с которым контроль версий для машинного обучения становится простым и непринужденным. В нем под одной крышей уживаются Git и DVC, можно отслеживать версии кода, данных и модели. Обратите внимание: FDS разработан в DagsHub.
Контроль версий дает следующие возможности:
-
Воспроизводимость. Когда состояние всех компонентов проекта отслеживается под единым номером версии, результаты можно воспроизвести одним щелчком мыши.
-
Отсутствие бессистемного версионирования в именах файлов. Код сохраняется в тот же файл и определяет его версию.
-
Не нужно перезаписывать сделанную работу из-за незначительных ошибок. Файлы можно легко и быстро восстановить.
-
Синхронизация и возможность поделиться версией упрощают совместную работу над проектом.
Мониторинг экспериментов
После рефакторинга кода в функции нам проще контролировать исходные параметры. Это помогает управлять конфигурацией на каждом этапе и с легкостью отслеживать гиперпараметры каждого эксперимента. Мы переносим конфигурации во внешний файл, и каждый модуль импортирует релевантные для него переменные.
Но отслеживать каждый эксперимент в Git — дело хлопотное. Мы хотели бы автоматизировать регистрацию каждого запуска. Как и с версионированием больших файлов, для регистрации хода экспериментов создали множество инструментов: W&B, MLflow, TensorBoard и другие. В этом случае не так важно, каким именно молотком забивать гвозди.
Не забудьте: используя внешние инструменты, вы отслеживаете только параметры эксперимента — воспроизвести его не удастся. Так что я советую подбирать инструмент под сценарий использования.
Чаще всего прототипирование новой гипотезы не даст осмысленных результатов, поэтому мы используем внешний инструмент для отслеживания хода эксперимента. Однако получив осмысленный результат, мы версионируем все компоненты проекта и инкапсулируем их с помощью Git commit — теперь проект можно воспроизвести одним щелчком мыши.
Мониторинг экспериментов дает следующие возможности:
-
История исследований. Автоматизированное отслеживание эксперимента позволяет регистрировать всю историю исследования, понять общие результаты и не делать одну и ту же работу дважды.
-
Совместная работа. Теперь можно поделиться результатами эксперимента с командой и сравнить подобное с подобным.
-
Воспроизводимость. Эксперименты до некоторой степени удастся воспроизвести.
-
Отсутствие бессистемного трекинга экспериментов, когда каждый сотрудник команды ведет записи по-своему.
Экспорт логики в скрипты
Прежде чем выполнить деплоймент на прод, мы бы хотели перенести все логические шаги, сохраненные в Notebook, в скрипты на Python. Но при этом не отказываться от возможностей Notebook. Так что мы импортируем их обратно в Notebook.
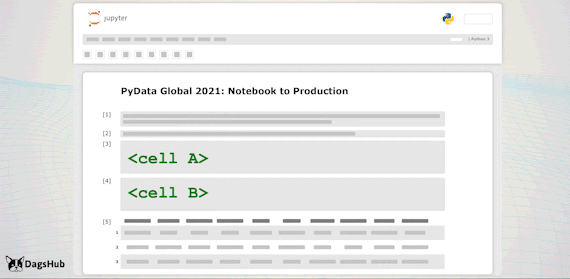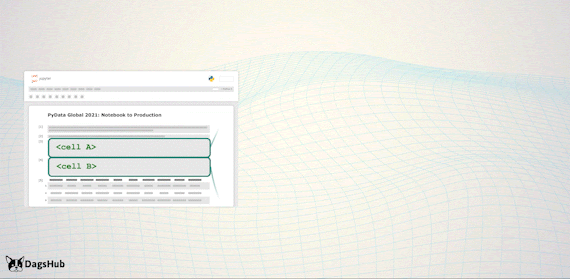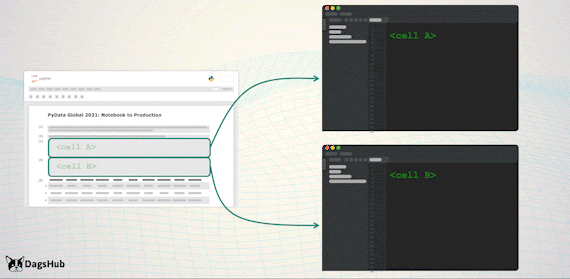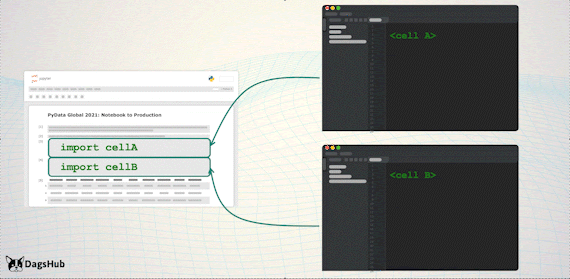
Экспорт логики в скрипты позволяет:
-
Использовать в продакшене только скрипты. Это отраслевой стандарт, который облегчает работу.
-
Поддерживать одну кодовую базу вместо двух — в Notebook и скриптах.
-
Продолжать работать с Notebook и пользоваться их преимуществами.
Юнит-тестирование
Как и в разработке программного обеспечения, нам нужно удостовериться, что код или модель справляются с задачами, для которых их создавали. Это касается обработки данных, моделирования и всех этапов работы пайплайна.
Когда пишешь тесты прямо во время разработки, это ускоряет работу. Получается короткий цикл обратной связи, сразу же выявляющий баги. И гораздо проще исправить ошибки по отдельности в каждом модуле, а не заниматься отладкой готовой системы в целом.
Модульное тестирование позволяет уменьшить количество багов на проде, а значит, уменьшить количество бессонных ночей за их исправлением.
Заключение
Jupyter Notebook — отличный инструмент для прототипирования и работы с данными, который в конечном счете наделяет нас сверхспособностями. Однако в продакшене становятся очевидны некоторые ограничения этого решения.
Если на горизонте маячит новый проект, я настоятельно рекомендую подумать о том, как все будет устроено в продакшене, какие инструменты лучше использовать для проекта, и как повысить эффективность работы. Возможно, вы оцениваете свою работу по результатам готовой ML-модели, но вас оценивают по времени, которое потребовалось для решения задачи, начиная от стадии экспериментов до деплоймента в прод сервиса на основе ML, а также по качеству готового решения. Не забывайте об этом.
Команда VK Cloud Solutions развивает собственные Big-Data-решения. Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Читать по теме:
ruslaniv
Я лично сразу в ноутбуке пишу код, который (в меру моих знаний естественно) соответствует принципам "чистого кода" с использованием шаблонов ООП и прочего. При этом у меня стоит расширение https://github.com/mwouts/jupytext/ которое автоматически синхронизирует ноутбук в питоновский скрипт, при этом в настройках можно указать минимальное копирование метаданных ноутбука и в таком случае в скрипте остается только код.
Соответсвенно в гите отслеживаются все файлы, но при ревью смотрим дифы только у скриптов, не обращая внимания на ноутбуки. В прод деплоятся тоже только готовые скрипты, которые всегда соответствуют последнему состоянию ноутбука.
Но в целом да, вопрос организации/синхронизации всей этой "машинерии" очень актуален, особенно для компаний уровня гораздо меньшего чем Нетфликс, так что мы все еще в поиске оптимального решения )