

SQL - декларативный язык - то есть вы описываете "что" хотите получить, а СУБД сама решает, "как" именно она будет это делать. Некоторые из них при этом позволяют им "подсказывать", как именно лучше выполнять запрос, но PostgreSQL - нет.
Тем не менее, "синтаксический сахар" некоторых языковых конструкций позволяет не только писать меньше кода (учите матчасть!), но и добиться, что ваша база будет делать часть вычислений "лениво", только при фактической необходимости.
-
COALESCE
-
CASE
TABLE
Наверное, самый часто используемый "в быту", он же - наиболее простой способ вывести все поля таблицы или выборки - оператор TABLE:
TABLE my_table; -- эквивалентно SELECT * FROM my_table;Увы, его нельзя комбинировать с WHERE или GROUP, зато отлично можно использовать для передачи CTE вида "одна строка - один столбец" в функции:
WITH src AS(
SELECT ARRAY[1, 2, 3]
)
SELECT
unnest((TABLE src));COALESCE - выполняем шаг за шагом
Иногда бывает необходимо выполнить несколько сложных запросов, чтобы потом взять первый не-NULL'овый из них:
SELECT
CASE
WHEN a IS NOT NULL THEN a
ELSE b
END r
FROM
(
SELECT
(SELECT CASE WHEN random() < 0.5 THEN 1 END) a -- в половине случаев тут NULL
, (SELECT 2) b
) T;В половине случаев значение a у нас будет не-NULL, но в плане мы каждый раз все равно увидим вычисление InitPlan 2 для второго вложенного запроса:

Перепишем, использовав оператор coalesce:
SELECT
coalesce(
(SELECT CASE WHEN random() < 0.5 THEN 1 END)
, (SELECT 2)
) r;Теперь в половине случаев, как и ожидалось, для второго вложенного запроса вычисление происходить не будет (never executed на узле плана):

COALESCE и "невозможное значение"
Иногда возникает необходимость проверить совпадение некоторого значения с определенным набором или с NULL, но "просто" сравнивать через оператор = с NULL нельзя - поэтому нельзя просто написать v IN (1, 3, NULL).
Подробнее о проблемах сравнения с
NULLи помощи оператораIS DISTINCT FROMв этом деле - в статье "PostgreSQL Antipatterns: сражаемся с ордами «мертвецов»".
Это приводит к появлению разных не очень красивых конструкций:
SELECT
v IS NULL OR v = 1 OR v = 3 cond
FROM
(
VALUES
(1)
, (2)
, (3)
, (NULL)
) T(v);Но если использовать coalesce и точно знать значение, которого "не может быть" по прикладной логике, то запрос можно переписать:
SELECT
coalesce(v, -1) IN (-1, 1, 3) cond -- coalesce + IN
FROM
(
VALUES
(1)
, (2)
, (3)
, (NULL)
) T(v);ANY/ALL
Раз уж мы затронули оператор IN, который сам является "синтаксическим сахаром" к OR-цепочке значений, стоит вспомнить и про родственные ему операторы ANY и ALL.
Их можно использовать для проверки присутствия значения в выборке:
SELECT 'a' = ANY(
(
SELECT 'a'
UNION
SELECT 'b'
UNION
SELECT 'c'
)
);... или массиве:
SELECT 'a' = ANY(ARRAY['a', 'b', 'c']);... или отсутствия там же:
SELECT 'x' <> ALL('{a,b,c}'::text[]);LIKE ANY
Но помимо операторов = и <>, ANY/ALL могут комбинироваться и с LIKE:
SELECT
*
FROM
pg_class
WHERE
relname LIKE ANY('{pg_publication%,pg_subscription%}'::text[]);
-- NOT LIKE ALL(...)CASE WHEN <простое условие> THEN <сложный запрос>
В более общей ситуации, когда условие подразумевает не просто проверку на NULL, можно "заизолировать" внутри CASE выполнение сложных операций более легко вычислимыми простыми условиями:
SELECT
CASE
WHEN random() < 0.5 THEN (SELECT 1)
WHEN random() < 0.5 THEN (SELECT 2)
ELSE (SELECT 3)
END r;
Прикладной пример использования такой конструкции для ускорения запроса можно увидеть в статье "PostgreSQL Antipatterns: редкая запись долетит до середины JOIN".
CASE <сложный запрос> WHEN <значение>
Если нам необходимо вычислить некоторое значение на основании результата какого-то сложного запроса, то предыдущий вариант уже будет выглядеть не очень хорошо:
SELECT
CASE
WHEN (SELECT ...A) = 1 THEN 'one'
WHEN (SELECT ...A) = 2 THEN 'two'
WHEN (SELECT ...A) = 3 THEN 'three'
END;Однако, если вложенный запрос возвращает значение 3, то и выполняться он тут будет трижды. Мало того, в некоторых случая (например, при использовании random() или любой другой не-STABLE-функции) это просто нельзя использовать, поскольку приведет к ошибке.
Тем не менее, если воспользоваться CASE-конструкцией проверки значения выражения, можно записать и короче, и правильнее:
SELECT
CASE (SELECT ...A)
WHEN 1 THEN 'one'
WHEN 2 THEN 'two'
WHEN 3 THEN 'three'
END;Подстановка по словарю
К сожалению, такой подход требует прописывания всех пар значение-результат еще на этапе создания запроса или его динамической генерации, что нехорошо почти всегда.
Но есть способ обойти это ограничение - использовать словарь соответствий, который можно собирать и при выполнении запроса или передавать в качестве параметра:
SELECT
(
'{"1" : "one", "2" : "two", "3" : "three"}'::json
) ->> (SELECT ...A)::text;Сравнение разных вариантов "ословаривания" данных можно увидеть в "PostgreSQL Antipatterns: ударим словарем по тяжелому JOIN".
AND/OR-цепочки запросов
Поскольку порядок вычисления условий в SQL не определяется и отдается на откуп оптимизатору, мы не можем гарантировать зависимость выполнения одного запроса от другого, как это делается в обычных ЯП:
... = condA() && condB() // condB выполняется только при истинности condA
... = condA() || condB() // condB выполняется только при ложности condAО проблемах работы со сложными условиями можно ознакомиться в статьях "PostgreSQL Antipatterns: вычисление условий в SQL" и "PostgreSQL Antipatterns: скованные одной цепью EXISTS".
OR-цепочка
Фактически, приведенный выше прием с CASE позволяет преобразовать OR-цепочку запросов с неопределенным порядком выполнения:
(SELECT ...A) OR (SELECT ...B) OR (SELECT ...C)... к заведомо определенному порядку:
CASE
WHEN (SELECT ...A) THEN TRUE
WHEN (SELECT ...B) THEN TRUE -- выполнится только при ложности ...A
WHEN (SELECT ...C) THEN TRUE -- выполнится только при ложности ...A и ...B
ENDВ качестве условия тут может использоваться любой запрос, возвращающий boolean - например, EXISTS(SELECT ...).
AND-цепочка
А что если у нас условия связаны не через OR, а через AND?
(SELECT ...A) AND (SELECT ...B) AND (SELECT ...C)В этом случае нам помогут вложенные CASE:
CASE
WHEN (SELECT ...A) THEN
CASE
WHEN (SELECT ...B) THEN
(SELECT ...C)
END
ENDА в процедурном коде того же можно добиться с помощью вложенных IF:
IF (SELECT ...A) THEN
IF (SELECT ...B) THEN
IF (SELECT ...C) THEN
...
END IF;
END IF;
END IF;UNION ALL + LIMIT
Еще один способ заставить PostgreSQL не выполнять часть запроса - ограничить размер целевой выборки для блока UNION ALL:
(
SELECT 1
WHERE
random() < 0.5
)
UNION ALL
(
SELECT 2
)
LIMIT 1;В половине случаев второй вложенный запрос не станет выполняться:

Интересные прикладные задачи, ускоряемые таким способом, разобраны в статьях "PostgreSQL Antipatterns: вредные JOIN и OR" и "PostgreSQL Antipatterns: сказ об итеративной доработке поиска по названию, или «Оптимизация туда и обратно»" - например, как вовсе избавиться от сортировки при выполнении запроса.
LATERAL
Посмотрим на простом примере, где мы хотим нагенерировать "вложенный цикл":
SELECT
a
, b
FROM
(
SELECT
generate_series(1, 4)
) X(a)
JOIN
(
SELECT
generate_series(1, 4)
) Y(b)
ON b <= a;
Чем плох этот план? Как минимум, мы тут нагенерили и сразу отфильтровали лишних 6 записей, поскольку условие a <= b применяли только к результату. А ведь a можно передать во второй запрос с помощью LATERAL - обратимся к мануалу:
Ключевое слово
LATERALможет предварять вложенный запросSELECTв спискеFROM. Оно позволяет обращаться в этом вложенномSELECTк столбцам элементовFROM, предшествующим ему в спискеFROM. (БезLATERALвсе вложенные подзапросыSELECTобрабатываются независимо и не могут ссылаться на другие элементы спискаFROM.)
То есть, помимо штатной цели, использование LATERAL заставляет планировщик запроса обеспечить вычисление тех его частей, на которые мы будем ссылаться - то есть так мы можем управлять порядком выполнения JOIN:
SELECT
a
, b
FROM
(
SELECT
generate_series(1, 4)
) X(a)
, LATERAL
(
SELECT
generate_series(1, a)
) Y(b);Тут уже более эффективный план без лишних фильтраций:

А можно попроще?
Но не будем останавливаться на достигнутом и прочитаем мануал дальше:
Слово
LATERALможно также добавить перед вызовом функции в спискеFROM, но в этом случае оно будет избыточным, так как выражения с функциями могут ссылаться на предыдущие элементы спискаFROMв любом случае.
SELECT
a
, b
FROM
generate_series(1, 4) X(a)
, generate_series(1, a) Y(b);
Интересно, что несмотря на облегчение плана, время его выполнения оказалось вдвое хуже предыдущего варианта на таких микро-выборках, хоть и лучше исходного.
Более сложные варианты оптимизации через
LATERAL- "PostgreSQL Antipatterns: «где-то я тебя уже видел...»" и "PostgreSQL Antipatterns: редкая запись долетит до середины JOIN".
WITH ORDINALITY-нумерация
Раз уж коснулись особенностей работы с функциями, не стоит забывать про такую замечательную возможность как встроенная нумерация строк с помощью WITH ORDINALITY.
То есть, конечно, можно это делать и с помощью row_number():
SELECT
id
, row_number() OVER() ord
FROM
unnest('{1,2,4,8,16}'::integer[]) id;WindowAgg (actual time=0.014..0.019 rows=5 loops=1)
-> Function Scan on unnest id (actual time=0.009..0.009 rows=5 loops=1)А можно "стильно, модно, молодежно" - с тем же результатом, но чуть быстрее:
SELECT
*
FROM
unnest('{1,2,4,8,16}'::integer[])
WITH ORDINALITY T(id, ord);Function Scan on unnest t (actual time=0.008..0.008 rows=5 loops=1)А еще
WITH ORDINALITYможно использовать для связывания элементов массивов. Или не использовать, если вы прочитали "PostgreSQL Antipatterns: сизифов JOIN массивов".
ROW-конструктор
Читаем в мануале, что это такое:
Конструктор табличной строки — это выражение, создающее строку или кортеж (или составное значение) из значений его аргументов-полей. Конструктор строки состоит из ключевого слова
ROW, открывающей круглой скобки, нуля или нескольких выражений (разделённых запятыми), определяющих значения полей, и закрывающей скобки.
Перебор индекса
Допустим, нам требуется найти следующее по порядку индекса значение в таблице - на этом способе основан алгоритм "быстрого DISTINCT", рассмотренный в статье "PostgreSQL Antipatterns: убираем медленные и ненужные сортировки".
Рассмотрим на примере системной таблицы pg_attribute и ее индекса (attrelid, attnum), где попытаемся найти первое поле таблицы pg_class с положительным номером, если оно есть, или следующее за ним по индексу:
SELECT
*
FROM
pg_attribute
WHERE
(
attrelid = 'pg_class'::regclass AND -- если таблица есть
attnum > 0 -- надо взять "следующее" поле
) OR
attrelid > 'pg_class'::regclass -- если вдруг нету - "следующую" таблицу
ORDER BY
attrelid, attnum
LIMIT 1;
Пришлось прочитать 161 лишнюю запись. А теперь - то же самое через эквивалентное условие для ROW:
SELECT
*
FROM
pg_attribute
WHERE
(attrelid, attnum) > ('pg_class'::regclass, 0)
ORDER BY
attrelid, attnum
LIMIT 1;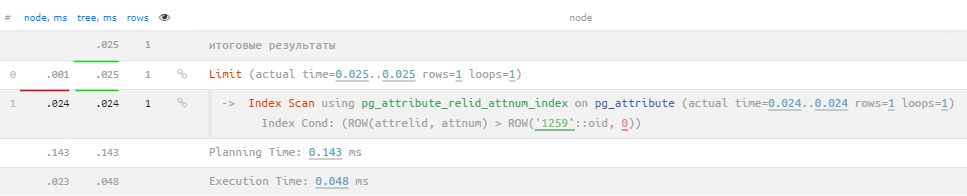
Теперь уже никакой фильтрации, все по индексу!
Проверка наличия в списке
Выше мы сложное условие заменили на простое, но с ROW. И точно так же, как целостное значение, его можно воспринимать для оператора IN:
SELECT
(1, 2) IN ((1, 2), (3, 4), (5, 6));SELECT
('pg_class'::regclass, 0) IN (
SELECT
attrelid, attnum -- тут не нужно оборачивать в ROW
FROM
pg_attribute
);Правда, по описанным в начале статьи причинам, нужно гарантировать, что нигде не возникнут NULL'ы.
Ссылки на все упомянутые статьи (и даже много больше!) с разбивкой по темам можно найти в моем профиле.

Комментарии (15)

MVN63
30.05.2022 15:19Кирилл, благодарю за материал.
У меня запрос на улучшение документации (https://postgrespro.ru/docs/) — чертовски неудобно пользоваться!Предлагаю, как минимум:
– в блоках Синтаксиса сделать ключевые слова ссылками на соответствующие пункты описаний (т.н. "Предложения")
– изменить стиль заголовков Предложений — выделить Жирным само ключевое слово вместо префикса Предложение.

Z55
31.05.2022 09:38Нет ли здесь опечатки?
CASE WHEN random() < 0.5 THEN (SELECT 1) WHEN random() < 0.5 THEN (SELECT 2)
Kilor Автор
31.05.2022 09:40Вроде нет. Тут подразумевается "любое простое условие, от предыдущего никак не зависящее".
Z55
31.05.2022 09:56Т.е. выполнятся оба селекта последовательно, если рандом вернём менее 0.5? Интересно!
А рандом будет запускаться два раза или один?Kilor Автор
31.05.2022 10:01Во-первых,
random()- non-STABLE-функция, поэтому будет запускаться каждый раз, выдавая разные значения - пока какое-то по порядкуWHEN-условие не выполнится.Во-вторых, выполнится только один
SELECT- первый, для которогоWHEN-условие окажется истинным.

sanederchik
31.05.2022 11:27На самом деле в PostgreSQL можно, как оказалось, подключить плагин pg_hint_plan, через который по аналогии планировщику можно указывать, как искать определенные данные.
Сам не пробовал ещё, оставляю ссылочку для желающих:
https://github.com/ossc-db/pg_hint_plan
Kilor Автор
31.05.2022 11:30Да, только надо или собирать-устанавливать вручную, что явно не "из коробки", или ставить сборку Postgres Pro Enterprise (мануал).
sanederchik
31.05.2022 12:28Все верно, однако другие языки программирования активно используют либы / фреймворки, так что почему нет? :)
Тем более, обычно когда ставят "слона", то сразу с включенными плагинами для генерации hhid, секретов и тд, так что в целом чаще всего настроить плагины не проблема.

K_Chicago
31.05.2022 23:12Я не совсем понял пример с TABLE.
можно написатьSELECT unnest(ARRAY[1,2,3])и получать тот же результат что и
WITH src AS( SELECT ARRAY[1, 2, 3] ) SELECT unnest((TABLE src));в чем преимущество?
grufos
Добрый день, спасибо за ваши статьи.
Вот здесь вкралась опечатка
v IS NULL OR v ON v = 1 OR v = 3 condнаверное имелось ввиду:
v IS NULL OR v = 1 OR v = 2 OR v = 3 condKilor Автор
спасибо, fixed:
v IS NULL OR v = 1 OR v = 3 cond