

«Гарри Поттер и философский камень», (2001)
ИТ-шником (программистом) нынче быть привлекательно. Дата саентистом тоже неплохо. Создаются и множатся курсы. Только вот они все однобокие. Несмотря на большое количество языков, большое количество технологий и алгоритмов, несмотря на весь накопленный в ИТ области багаж, 99% датасаенс курсов строятся по пути python-pandas.
Наблюдая за типовыми мучениями в решении тривиальных задач выпускников таких курсов, даже неважно какого они года выпуска, со всей очевидностью становятся видны архитектурные просчеты питона в области аналитики. На фоне жутких питон конструкций аналогичные решения, написанные на R, выглядят стройными, прозрачными, компактными и работают сильно быстрее.
Вся аргументация «за питон» строится исключительно по принципу «не думать», «рука рынка, «ну у нас же уже есть в проде 10 строк кода на питоне, что же делать?». Хотя элементарные технологические тесты и оценка экономической эффективности частенько дают неопровержимые доказательства, что DS питон является безответным поглотителем доли ИТ бюджета компаний. Взглянем ниже более пристально на отдельные моменты.
ООП и DS плохо совместимы
Классическая схема работы с данными и их анализ строится по функциональному подходу. Есть набор датасетов, который вполне может быть размером 50-80% RAM. К этому набору последовательно применяются различные инструменты и преобразования. Датасеты эти структурированные: массивы (вектора), матрицы, списки, таблицы. Все оптимальные подходы давно уже отработаны в классическом Computer Science. Но ведь нет, надо идти своим путем. Применительно же к простым прямоугольным данным введение прослойки в ООП на ровном месте увеличивает накладные расходы на CPU и RAM, иногда до неприемлемых масштабов.
Концепция ООП, когда общие данные инкапсулируются, прячутся, к ним создается куча методов для усложнения жизни, на самом первом шаге принудительно надевается ярмом на аналитика, который вообще далек от программирования. В DS во главе стоят алгоритмы и расчеты, а не игры в наследования и подборы методов. Да и сама по себе концепция ООП не является безусловным добром. «Чем быстрее вы забудете ООП, тем лучше для вас и ваших программ».
Конечно, не сам ООП плох, плохо его неуместное и неуемное применение. Модели, графики, конекты к БД и т.д. — отдельные самодостаточные сущности, их не трогаем.
В R есть совсем упрощенный элемент ООП в виде возможности добавления атрибута "class" и использования S3 диспетчеризации, применяемой для переопределения функций для разных классов. Например, перегрузка функции print для разных объектов. Например, есть обычная переменная типа матрица на 10 Гб и у нее добавляется атрибут class = matrix. И есть data.frame с атрибутом class = data.frame. Пишем print(a), в зависимости от значения атрибута объекта будет вызвана функция print.matrix или print.data.frame. Просто, дешево, сердито.
Конечно, есть и более развитые варианты — S4 и R6, но это все не особо актуально при работе с данными.
Недостаточность базовых типов данных
Изначально питон придумывался как язык общего пользования для задач далеких от DS. Сложная логика с небольшими данными. Поэтому в питоне отсуствует нативная поддержка базовых для DS типов. Например, См. Built-in Types. В базисе нет чрезвычайно важных типов как настоящий числовой массив без обвеса (Numpy для этого придумали астрономы), дата и время (datetime и сателлиты, а также numpy datetime array). Особого внимания заслуживает отсутствие полноценной поддержки отсутствующих данных, см. подробное объяснение проблем в «Python Data Science Handbook». Handling Missing Data. Все эти типы в настоящей аналитической системе должны быть 1-st class citizen, а не выступать в качестве суррогатов и костылей. Неконсистентность и множественность суррогатов базовых типов данных, отсутствие согласованных библиотек и унифицированных подходов вызывают постоянные проблемы в аналитике, вне зависимости от того, сколько лет стажа за плечами.
В R в этом смысле все прекрасно. Все базовые типы встроены в язык. integer, logical, numeric, character, missing data, категориальные переменные, списки и массивы (одномерные и матрицы), Date, POSIXct. Причем массивы — честные С-шные массивы. Просто цельный кусок памяти с индексацией элементов по смещению. Кратко можно поглядеть, например, здесь: Advanced R. Vectors. Можно сказать, что не хватает нативной поддержки integer64, но это не является серьезной проблемой. Требуется не так часто и есть пакеты, которые позволяют использовать float для использования его как integer64 — float же как раз использует 8 байт. Можно почитать хорошую популярную публикацию «Floats have 15-digit accuracy in their normal range».
Векторизация
Векторизация — это очень математическое (физическое) понятие. Много лет учились складывать вектора сил, учились стрелочки сверху писать над буквами. Приходим в питон и откатываемся в 18-ый век.
В базовом питоне ее в контексте DS просто нет. Циклы и list comprehension. А еще супер медленный apply и лямбда функции. Для тривиальнейших операций.
Есть одна отдушина. Поскольку Numpy писали астрономы, см. «Array programming with NumPy», то Numpy написан с учетом векторизации, люди от науки понимали ценность этого подхода. Но возможности ее применения достаточно ограничены.
В R же векторизация является базисом языка. Скорость расчетов, компактность кода, универсальность применения.
Pandas
Пандас является одной из самых мрачных задумок. Медленный; ресурсоемкий; однопоточный; в одних частях функционально избыточный, в других — недостаточный; ОО-ориентированный, неочевидный и далее по списку.
Колонки
Что представляет собой data.frame в классическом Computer Science? Это список указателей на массивы. Массивы — это колонки. Ближайший аналог — навесные шкафы на кухне, смонтированную на одну общую шину. Так было на ассемблере, так было на С/С++, Паскале и т.д. Во всех языках, которые предполагали работу в ограниченных аппаратных ресурсах.
Что имеем в пандасе? Да ничего подобного. Поддерживается странная концепция эквивалентности работы как по вертикали, так и по горизонтали. Что приводит к снижению качества и скорости работы в обоих случаях. Да, формально колонки могут быть организованы как массивы Numpy, которые как раз и являются нормальной реализацией настоящих массивов, как они должны были быть сделаны. Но это тянет за собой ряд проблем.
- Первая — над базовым питоном создается два различных пакета со своими мантейнерами, планами развития, типами даных, функциями и т.д. Консистентность оставляет желать лучшего.
- Вторая — колонки (массивы) легко могут оказаться с типом
object, что разрушает концепцию массива как единого куска памяти. Таблица рассыпается на атомарные объекты. Типичный случай можно посмотреть на следующем кусочке. И питон нисколько не возмутится и позволит спокойно вытворять такие вещи. - Третья — попытка BlockManager решать за разработчика и консолидировать однотипные колонки в одну кучу (странный концепт) привели к полному фиаско, что в производительности, что в требованиях к ресурсам. Ссылки в конце текста.
import pandas as pd
from ppretty import ppretty
from objexplore import explore
# initialize data of lists.
data = {'Name': ['Tom', 'nick', 'krish', 'jack', 'Nobody'],
'Age': [20, 21, 19, 18, 'Zero']}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
df
print(ppretty(df))
print(ppretty(df.Age))
explore(df.Age)Индекс
Индекс является постоянной болевой точкой для аналитиков. Изначально придуманный для удобства, он начинает постоянно мешать. Подкапотная логика, требующая постоянного ресета индекса; синхронизация индексов колонок; множественная логика по фильтрации и выборке; постоянные вопросы из серии loc vs iloc, мультииндекс и т.д.
Проблема, которая создана на абсолютно ровном месте. В классических таблицах / data.frame индекс может быть, а может и не быть, чаще всего он позволяет ускорять выборку и не более. Для этих задач его и придумывали, а не для культа индекса. Дополнительно, массивы в памяти можно физически сортировать. Для большого набора задач работа с упорядоченными данными на больших объемах позволяет получать прирост в скорости в несколько порядков, в т.ч. за счет конвейерной специфики работы современных компьютеров. Можно почитать интересный технологический Daniel Lemire's blog, в частности статьи про сортировки, например «To improve your indexes: sort your tables!», «Sorting is fast and useful». После этого бессмысленность и бесполезность реализации индекса в пандасах становится очевидной.
В R, как это ни удивительно слышать питонистам, data.frame и data.table устроены именно так, как написано в начале — список указателей на вектора одного типа, см., например Advanced R. Vectors. Можно было бы возразить, что нельзя произвольные объекты в колонку включить, но и тут шах и мат. Есть такое понятие: List columns. Колонка представляет собой список (базовый тип), элементы которого могут быть чем угодно.
Copy-paste
Классический антипаттерн, когда необходимо многократно упоминать имя фрейма с которым работаешь. Пандас, увы, заставляет работать именно так.
Вот типичная конструкция (это еще без шампура операций):df[(df.val < 0.5) | (df.val2 == 7)]
Необходимо постоянно упоминать датафрейм, хотя уже и ежу ясно, что мы работаем в контексте. Поменял позже имя фрейма, в 99 местах исправил, в одном забыл — все не работает. Читаемость тоже от этого никак не улучшается. Эмуляция языка запросов через метод query — антагонист всех остальных методов, но он не обладает универсальностью.
В R же все просто и лаконично. Механизм NSE (Non-Standard Evaluation) вкупе с пайпами позволяет упомянуть имя датафрейма только в первой строчке и больше его не использовать.
Правда ведь так проще и понятее?df[val < 0.5 | val2 == 7]
Отсутствие полноценной конвейерной обработки (pipe)
Pipes были придуманы очень давно, годах в 70-х, в unix. Чрезвычайно удобный инструмент. Позволяет передавать выходные потоки одних функций на входные потоки других. Без разрывов, без заведения ненужных временных переменных.
В питоне нет ничего такого на уровне языковых конструкций. Пакеты типа pipes или перенос длинных операций по . являются костылем. Особую радость доставляют протуберанцы ООП, когда нужно через точку постоянно иерархически получать доступ к данным или методам. Самое печальное, что все замешано в кучу. Тут мы получили доступ к данным, теперь мы применили метод, теперь опять достали из ответа метод и опять применили уже его метод. Это элементарно нечитаемо.
В R все прекрасно. С версии 4.1 даже есть нативный пайп |>, встроенный в синтаксис языка. Но давно существующий пакет magrittr обладает широким спектром различных пайпов и позволяет очень элегантно и компактно проводить сложные расчеты. Код при этом становится предельно понятным даже при беглом взгляде.
Производительность
Про практическую непригодность pandas для данных чуть больше небольших давно известно но старательно умалчивается.
Упоминал здесь: «R vs Python в продуктивном контуре», еще раз конспективно:
Про Dask, polars,… не говорим — это другая весовая категория и на подобные решения найдется масса альтернативных нейтральных ответов. Тот же Clickhouse.
R data.table молотит десяки и сотни гигов без каких-либо проблем.
Бенчмарки
В DS задачх очень часто бывает нужно протестировать различные подходы к вычислениям, чтобы выбрать оптимальный вариант или найти узкое место. Отнюдь не модуль, скрипт целиком или программный комплекс. Всего лишь функция, пара строк преобразований или еще что-то такое малое. В питоне ничего для этого нет. Многие могут сказать, а как же %timeit?
df = pd.DataFrame(np.random.randint(0,1000,size=(1000, 4)), columns=list('ABCD'))
%timeit df['A'].map('{:0>15}'.format) best of 5: 437 µs per loop
%timeit df['A'].map(lambda x: f'{x:0>15}') best of 5: 565 µs per loop
%timeit df['A'].astype(str).str.zfill(15) best of 5: 1.42 ms per loop
%timeit [f'{x:0>15}' for x in df['A'].values] best of 5: 466 µs per loopОтвет — да никак, это просто псеводнаучная профанация.
- Требует юпитер ноутбука, нельзя в консоли запустить.
- Неправильная методика эксперимента. тесты гонятся не вперемешку, а блоками. результат может быть подвержен внешним воздействиям (иные процессы на машине).
- Среднее — не лучший показатель, нужно распределения смотреть. квартили или медиану и мин/макс.
- Нет информации по потреблению памяти, а это важно.
- Среднее по n минимальным (5 из 1000) — это вообще треш метрика. На этот показатель полагаться нельзя. Статистики рыдают.
В R пакетов для бенчмарка масса и они крайне удобные. Один из лучших на настоящий момент — bench. Просто поглядите, как это должно быть сделано по уму.
Заключение
Упоминать можно многое, практически во всех концептах видны зияющие дыры. И не секрет, что большая часть DS пакетов в питоне «слизаны» с R. О чем в документации на пакеты честно пишется. Вот есть хорошие расширенные подборки с примерами, можно тоже взглянуть:
- R advantages over python
- WTF Python!. Exploring and understanding Python through surprising snippets
- I don't like notebooks. Joel Grus, JupyterCon 2018
И, конечно же, бессменный тест «Database-like ops benchmark», безусловно доказывающий блеск и нищету связки python-pandas.
Так что всем, кто решил погружаться в DS через питон — есть смысл подумать, а действительно ли это будет жар-птица в руках. Чаще всего в обычных задачах это все выглядит как ободраный воробей.
Заглядывайте в группу, задавайте вопросы.
Предыдущая публикация — «Разработчики и колпак».
P.S. Уточнение по результатам комментариев. Фокус здесь на «civil data science». Не придумывайте, пожалуйста петабайты данных, MLOps и highload прод. В тексте ничего про это нет и эти вопросы даже не затрагивались. Это не значит, что вопросы не имеют ответов. Это значит, что текст про другие задачи.
Комментарии (207)

Stormwalker
08.06.2022 10:53+23Из того, что я вижу, ваша основная претензия в том, что pandas медленный и не очень удобный. Проблема R в том, что он хорош только в расчётах. Если вам нужно сделать буквально что угодно, кроме манипуляций с датафреймами, вы в большой беде. Спарсить данные из интернета - хм, поднять сервер с дашбордом - со скрежетом, сделать сервер с моделью - упс. А Python умеет делать всё остальное довольно хорошо, а как оптимизировать pandas хорошо известно.

i_shutov Автор
08.06.2022 10:57-4Почитайте все прошлые публикации.
R умеет делать это все куда круче питона.
Вы просто немного не в теме.

maoch
08.06.2022 11:02+4Спарсить данные из интернета - можно без проблем
Поднять сервер с дашбордом - можно без проблем
Сделать сервер с моделью - можно без проблем

avraam-inside
08.06.2022 11:14+5Так R это всё умеет делать спокойно же

Hardcoin
08.06.2022 13:20+5Умеет, но менее удобно. Не так уж мало людей пробуют R и если бы он обладал заметными преимуществами, они оставались бы на нём. Я статистику учил на R и буквально пару операций там делать заметно удобнее, чем на Питоне. Но в среднем преимущество за питоном.

MentalSky
08.06.2022 13:37Умеет, но менее удобно.
Да как то? немного строк - и готов докер-контейнер с апи за которой сидит моделька, или дашбоард на Shiny, встраиваем в CI/CD и живем счастливо. Что же тут неудобного?
Имхо, спор весь из-за вкусов, кому что ближе-удобнее и из-за отсутствия опыта решения конкретных задач на R, язык тут ни при чем, говорю на основе опыта в стартапах - там важно задачу решить с 1 раза и бежать дальше, R нам очень помог в этом
i_shutov Автор
08.06.2022 13:44+2Тот же Dash начали списывать с Shiny. Но до последнего ему еще очень далеко.
Можете книгу почитать https://mastering-shiny.org/.
Или демки поглядеть: https://appsilon.com/
Можно контесты взглянуть:- [Winners of the 1st Shiny Contest](https://blog.rstudio.com/2019/04/05/first-shiny-contest-winners/), 2019-04-05 - [Winners of the 2nd Annual Shiny Contest](https://blog.rstudio.com/2020/07/13/winners-of-the-2nd-shiny-contest/), 2020-07-13 - [Winners of the 3rd annual Shiny Contest](https://blog.rstudio.com/2021/06/24/winners-of-the-3rd-annual-shiny-contest/), 2021-06-24

sanchovy
09.06.2022 11:54+1Лично я делаю почти весь скрапинг только в R — он просто намного удобнее. Python как-то не зашёл


MentalSky
08.06.2022 11:19+8Спарсить данные из интернета - хм, поднять сервер с дашбордом - со скрежетом, сделать сервер с моделью - упс
это мягко говоря не так, и уже давно, говорю от своего опыта использования R в телеком стартапе, на R было сделано:
- kafka producer-ы и consumer-ы, завернутые в systemd-скрипты, работающие как сервисы linux;
- отдельные step-ы в ETL-pipelines в Pentaho Data Integration (c выходом пакета targets пентаха не особо нужна);
- биллинг (на Shiny - GUI + бэкенд);
- REST JSON API для интеграций с поставщиками данных (RestRserve в Docker);
- всякие разные штуки для интеграций с системой мониторинга и ServiceDesk;
- приложение Bitrix24 для анализа бизнес-процессов (Shiny);
- приложение Bitrix24 для расчетов KPI персонала;
- всяких разных ad-hoc отчетов не счесть;
Почему R? ну разрабов было всего два, а R уже использовался для анализа данных, да и параметр time to market у R таки хорош и многое "в две строки", ну и пакетов в нем тьма - есть все, от добычи сырых данных, до выдачи пользы наружу.
Ну и да - RStudio - очень уютная IDE, по моему мнению.
Ну и про парсинг с инета - это Вы совсем зря - пакеты rvest и RSelenium не дадут мне соврать.
Так что причины НЕ использования R - не в ограниченности языка.wiwrel
08.06.2022 12:46Так что причины НЕ использования R - не в ограниченности языка.
Разверните пожалуйста свой ответ, в чем тогда причины?
MentalSky
08.06.2022 13:02+5Разверните пожалуйста свой ответ, в чем тогда причины?
Мое мнение такое, и касается оно только РФ:
В нашей стране до сих пор про язык R говорят - "это язык для математиков", предыстория влияет на выбор - а что изучить? Выбираем питон - это же язык общего назначения!
В нашей стране моду (а отсюда и рынок труда) на выбор тех или иных инструментов задают крупные ИТ-компании, а эти компании выбрали Питон, разумеется работодатель не выбирает что круче, а выбирает - что дешевле с точки зрения ФОТ, так что вакансий много именно под Питон. Кстати - зарубежом вакансий под R есть.
Питон проще в изучении в самом начале, R (речь про базовый язык) классическому разработчику сначала не очень понятен, впрочем - пакеты семейства tidyverse эту трудность значительно снижают.
Т.к. обертки над tensorflow или libtorch сначала появились для Питон, а потом уже на R (дада, на R есть torch, и это не обертка над pytrorch), то что молодые управленцы внедряют? Конечно питон, там же нейронки!

Alexwoodmaker
08.06.2022 15:44+2Один немаловажный аспект выпал из сопоставления Python vs R, который в России-матушке перевесил все и вся. Для R есть упопомрачительное awsome расширение под web: SHINY, но это за деньги. 10 строк кода и у вас витрина данных на R Shiny. На Python всяк свой web api точит как умеет и развивает. В этом вся штука. Лично я пользуюсь R и считаю, что лучше его ничего нет. Если Мелкософт вставил в Azure поддержку, то стало быть есть перспектива и профит. STATISTICA долго упрямилась, используя VB, но и она таки вставила поддержку R.
MentalSky
08.06.2022 15:52+1. Для R есть упопомрачительное awsome расширение под web: SHINY, но это за деньги
да нет же, Shiny бесплатный! есть платный вариант хостинга своих shiny-приложений в https://www.shinyapps.io/ там много плюшек удобных, включая горизонтальое масштабирование, но лично мне удобнее своя VPS/VDS, ставим туда shiny-server и все. Хотим масштабирование и аутентификацию из коробки - shiny-proxy в помощь

NickKolok
08.06.2022 11:38+4У меня от работы с R сложилось впечатление, что это такой специальный язык, в котором принципиально уничтожают возможности узнать, в какой же строке ошибка - "потому что головой думать надо, а не на компилятор надеяться". Как по мне, неуказание на координаты ошибки - это хамство. Как минимум, по отношению к тем, кто собирается язык осваивать. Язык, созданный экономистами для выколачивания денег за курсы из таких же экономистов, но помоложе.
Впрочем, питон я тоже недолюбливаю.
i_shutov Автор
08.06.2022 11:45+1Сстранно, с дебагом там все в порядке.
И stacktrace можно поглядеть.
Наверное, от Вас что-то скрыли.
Вот прям на Ваш вопрос: https://www.tidyverse.org/blog/2021/12/rlang-1-0-0-errors/
Люди знают потребности, люди постоянно работают над улучшением.NickKolok
08.06.2022 11:54+7mtcars %>%group_by(cyl) %>%mutate(new = add1("foo"))#> Error in `mutate()`:#> ! Problem while computing `new = add1("foo")`.#> ℹ The error occurred in group 1: cyl = 4.#> Caused by error in `1 + x`:#> ! non-numeric argument to binary operatorИ это "новый" вариант из 2021. Я, вероятно, "познакомился" с R чуть раньше. Так вот, где тут координаты ошибки в виде номера строки и, желательно, символа, как в нормальных языках?
i_shutov Автор
08.06.2022 12:00-7Вы путаете ошибки на этапе компиляции, когда компилятор точно знает что именно он сейчас парсит и какая лингвистическая ошибка возникла.
В обычной программе Вы просто получите голубой экран при сбое. И там без дебаг сборки будет вообще hex адрес в RAM.
Здесь же ошибка на этапе исполнения, когда подсунули кривые данные.
И ошибка четко указывает место и причину.
Так что Вы немного попутали фазы компиляции и исполнения.NickKolok
08.06.2022 12:05+20В JS голубого экрана не будет, будет относительно внятный стектрейс. В Java, Python и т.д. - тоже. А здесь, в R - просто набор обруганных выражений безо всякой возможности загуглить ошибку (да, это важно!). "Мне не нравится x+1", и всё тут!
А как весело что-то гуглить про язык с однобуквенным названием!
Нет, язык решительно и сознательно недружелюбен, и потому место ему в /dev/null
i_shutov Автор
08.06.2022 12:10-2Все есть в языке, Вы просто матчасть не изучили до конца и Вам никто не рассказал.
https://rstats.wtf/debugging-r-code.html
https://rlang.r-lib.org/reference/trace_back.html
Но у Вас просто задачи другие -- и это в порядке вещей. Язык и экосистема совершенно ни при чем.NickKolok
08.06.2022 12:21+14Признаю, матчасть не изучил. Потому что "вот софтина на R, её надо запустить и чуть-чуть поправить". Двух-трёх месяцев на изучение языка системно у меня не было. В питоне в аналогичной ситуации всё было гораздо проще.
По Вашим ссылкам всё ещё нет ни одного примера сообщения "ошибка в строке N". А это действительно важно при знакомстве с языком.
Благодарю Вас, кстати, за спокойствие и терпение. Вероятно, их в Вас развил язык R ;-)
i_shutov Автор
08.06.2022 12:28R -- это "100500"-ый язык из списка используемых. Идеала все равно в этом мире нет. Но в контексте актуальных задач что-то приближается ближе, что-то находится дальше.
Давненько даже доводилось компилятор писать.

0xd34df00d
09.06.2022 02:00У меня типы свернулись в w-дерево от такого ответа от человека, критикующего питон.
В языке здорового человека таких ошибок просто не должно быть.
i_shutov Автор
09.06.2022 11:20О сколько нам открытий чудных
Готовят просвещенья дух
И опыт, сын ошибок трудных,
И гений, парадоксов друг,
И случай, бог изобретатель.А.С. Пушкин, 1829
А еще можно законы Мёрфи почитать.
0xd34df00d
09.06.2022 16:26Ну тут как — залез в комментарии статьи про R, совершил такое открытие чудное, совершил закрытие вопроса с R.
i_shutov Автор
09.06.2022 16:30«Пух открыл Северный Полюс», сказал Кристофер Робин. «Правда замечательно?»
Пух скромно потупился.
«Это что ли?», говорит И-Ё.
«Да», говорит Кристофер Робин.
«Это то, что мы искали?»
«Да», говорит Пух.
«О!», говорит И-Ё. «Ладно, по крайней мере не было дождя», говорит.
Они воткнули Полено в землю и Кристофер Робин привязал к нему надпись:
СЕВЕРНЫЙ ПОЛЮС ОТКРЫТ ПУХОМ ПУХ ЕГО ОБНАРУЖИЛ

nikitazvonarev
08.06.2022 14:29+2Для этого вам нужна функция
traceback().Вообще вот тут есть достаточно полезная информация о том, как отлаживать код под R: https://adv-r.hadley.nz/debugging.html

Bromles
09.06.2022 18:48+1Для мимокрокодила, который далек от DS сферы и работает на Java и Typescript, это выглядит примерно на уровне ассемблера в смысле Quality of Life. Про Rust и заикаться больно, сравнение с его дружелюбными сообщениями об ошибках вообще будет избиением младенца

avshkol
08.06.2022 12:34R формален и математичен, это нравится людям с соответствующим складом ума (кого слово "вектор" не коробит, а умение складывать и умножать вектора - это обязательный навык, как обычные числа)...
python - это язык в смысле "текст" - уход от фигурных скобок и отступы - для меня, например, - это та самая киллер-фича...
ООП - это опять же для имеющих более гуманитарный склад ума. Объект класса - существительное, свойства - прилагательное, метод - глагол ("Вася, делай вот это вот так/с такими свойствами!")
i_shutov Автор
08.06.2022 12:40В DS формализм и математика являются фундаментом.
Вектора проходят в средней школе.
Странно все это не использовать при решении аналитических задач.
Про ООП первый раз такую трактовку слышу. Наверное, потому что приходилось с этим ООП в промышленных разработках плотно взаимодействовать, С++ разрабы -- суровые люди.
avshkol
08.06.2022 13:35Для меня код - это не только математика и логика, но в первую очередь это текст, повествование... Питон и панды искренне полюбил за это)
i_shutov Автор
08.06.2022 14:05+3Почитайте https://bookdown.org/yihui/rmarkdown/
Это Literate Progamming, как его Кнут задумывал.
0xd34df00d
09.06.2022 02:04Я люблю формализм и математику, и в R для меня нет ничего из этого. Начать можно с инопланетного ad-hoc-синтаксиса для совместимости с чьей-то проприетарной софтиной, который вылетает из головы, если отложить R на три месяца. Закончить можно отсутствием типов.
i_shutov Автор
09.06.2022 10:12-2Это Ваше частное мнение на которое Вы имеете полное право. Строится оно на полном знании вопроса или на полном незнании -- мне неведомо.
Похоже, что R вам показали не те люди и не с той стороны. Если вдруг захотите взглянуть с другой точки зрения -- приходите с вопросами в телеграм канал. Откроете новое для себя.0xd34df00d
09.06.2022 16:17Похоже, что R вам показали не те люди и не с той стороны.
Курс прикладной статистики в вузе плюс какие-то личные эксперименты.
Впрочем, подавляющее большинство других языков я освоил самостоятельно, и там проблем нет, а это очень разные языки, от плюсов до всяких хаскелей с коками.
i_shutov Автор
09.06.2022 16:21В ВУЗ-ах есть кадровая проблема.
И не секрет, что в части программирования лекторы/семинаристы будут далеки от индустриальных подходов. Математики -- не самые лучшие преподаватели по программированию. По разработке алгоритмов -- да, по эффективному программированию и современным подходам -- скорее нет.0xd34df00d
09.06.2022 16:22В МФТИ нормально с кадрами.
Конкретно этот курс читал семер лет 25-30, который зарабатывал на жизнь машинным обучением.

Ananiev_Genrih
08.06.2022 12:40+5Отличная статья
Спарсить данные из интернета - хм, поднять сервер с дашбордом - со скрежетом, сделать сервер с моделью - упс
По всем этим пунктам все в полном порядке и даже более того : там где на поляне царствовал питон (deep learning) - всё тоже ок!
Вот еще ссылка где автор не поленился и сравнил "влоб" нечитабельность Python и лаконичность R

economist75
08.06.2022 12:46+11Автор, кмк, искренен и во многом прав, перечисляя недостатки Pandas на фоне "glance" R. Еще не все фишки "слизаны" с R, панды развиваются, не почивают на лаврах как монополист. Вот почти уверен что скобки и избыточность упоминания df в срезах df[(df.col1==...) & (df.col1>...)] скоро уберут.
Но на поставленный статьей вопрос "Кто решил что Python лучше?" - ответа статья не дала. Решили и выбрали Python не директора курсов и вузов, не тренеры, а... сами аналитики, их работодатели и другие программисты, которым переход на Python+Pandas и интероперабельность такой связки показались выше, чем с R.
Вакансии Python vs R соотносятся как 10:1. Мы видим по всем рейтингам популярности ЯП что доля R падает, а у Python растет, и мы понимаем что это не просто корреляция, это функциональная связь. R медленно умирает на фоне роста DS, как бы странно это не выглядело. Причин тут несколько:
1) Python настоящий "универсальный клей", среди его 400k+ библиотек найдутся тысячи, которых нет в R.
2) ООП все-таки является наиболее частой парадигмой в больших проектах и исследованиях. DS-проекты сейчас все большие. Я пишу UDF func() и тут же ее объявляю методом фрейма pd.DataFrame.func = func() и далее просто вызываю ее через точку df.func() При наборе кода это в 5 раз быстрее чем печатать df.apply('func'), а в реальном анализе такой код занимает половину, и всё это заметно даже со стороны.
3) Блокноты Jupyter выросли из IPython и стали "стандартом" исследования. R кажется застывшим в развитии. "Доказательная экономика" строится и живет сейчас в блокнотах, Питон занимает 98% кода из 2+ млн. блокнотов на Github. Это просто факты, которые "вещь упрямая".
4) Все таки синтаксис Python няшен, принудительная "пробельность" дает структурность коду, есть громадный выбор IDE на любой вкус, линтеры, IntelliSense и AI в автодополнении делают его модным и молодежным, несмотря на возраст. У R есть все это, но оно не такое и не то.
Для DS-новичков отказ от Python в пользу R, Julia или low-code ML-решений - сейчас выглядит по меньше мере странно. Вполне можно использовать лучшее из 2-х миров в блокноте, поддерживающем 100+ ЯП.
i_shutov Автор
08.06.2022 12:49Не совсем так. На чем обучают, то потом и пытаются применять. Наблюдается засилье курсов на питоне, в т.ч. вузовских программ.
В RStudio IDE в R Notebook (считайте, аналог юпитера) можно писать код, перемежая чанки в r, python, sql. Все давно уже есть.По R есть отличный авторский учебник (это Филиппа Управителева): https://textbook.rintro.ru/index.html и курс.

kozlyuk
08.06.2022 13:23Наоборот, учить стараются тому, что востребовано. Мне кажется, выбор Python делают тогда, когда открывать новое направление в компании, связанное с DS, поручают сначала обычным программистам, которые берут то, что они сами и окружающие знают. И включается обратная связь: начали на Python, нанимаем со знанием Python, вот он и востребован.
Возможно, надо обучать R не только как отдельному инструменту для расчетов, а как логичной части большой системы. Когда я учился, у нас еще не было курса по R, но когда в рамках проекта по другому предмету нужно было получить регрессионную модель (из большей программы), решение сделать эту часть на R и дернуть извне было популярно.
R позволяет полноценно программировать, но это прежде всего все-таки DSL для статистики. По сравнению с "нормальными" языками то, что
cylвcylотдельно и вdf[cyl > 5]означает разное, воспринимается не как удобство, а как неконсистентность и необходимость держать в голове лишний контекст, что противно всем инстинктам разработчика.i_shutov Автор
09.06.2022 10:27-2В настоящем промышленном DS необходимо совмещать навыки математика, художника, алгоритмиста, настоящего разработчика, dba, сисадмина и devops. Пусть не с полным погружением, но хотя бы иметь некоторые представления об отдельных вопросах.
Чтобы включать инстинкты, их надо иметь. Чтобы их иметь, надо иметь немалый опыт за плечами в исполнении сложных командных проектов. Но такой опыт уже позволяет философски смотреть на ряд вещей.
Ananiev_Genrih
08.06.2022 12:56-41) Python настоящий "универсальный клей", среди его 400k+ библиотек найдутся тысячи, которых нет в R.
R - настоящий "универсальный клей", среди его 19 тысяч пакетов абсолютно все пакеты предназначены для анализа данных, ML, статистики и богатой визуализации. А сколько из 400К питоновских для этого? Какой процент? Давайте откровенно, он даже в статистике и визуализации по числу пакетов/алгоритмов до сих пор отстает. А то что какого-то питоновского пакета нет в R - значит это к аналитике данных не имеет отношения (иначе давно бы в нём было)
economist75
08.06.2022 13:20+3Мы по разному понимаем термин "ЯП - универсальный клей". Из 400k либ Python - треть является "обертками" к чужим другим либам на С, JS, R итд. Это очень эффективно, ведь сопровождением кода "материнской" либы занимается ее автор, а автор питон-либы - лишь изредка переписывает новые API-вызовы и документацию (и то не всегда). Плюс добавляет синтаксический "сахар", который, с учетом времени и опыта разработчика, часто оказывается полезным и удачным.
i_shutov Автор
08.06.2022 14:00-1под клеем все понимают единообразно.
"No matter how complex and polished the individual operations are, it is often the quality of the glue that most directly determines the power of the system." — Hal Abelson
обертки на С-шными либами и там и там есть.
мериться надо не количеством, а качеством. И не забываем, что питон для не DS задач -- это другой питон, другой стиль разработки и дополнительно другие либы.

SirEdvin
08.06.2022 17:56+3R - настоящий "универсальный клей",
значит это к аналитике данных не имеет отношения
Это же именно та проблема, про которую пишут. Вне рамок "аналитики" R не нужен (или является экзотическим) и это вытесняет его из рынка, так как специфические языки не нужны.i_shutov Автор
08.06.2022 18:10-3Посмотрите предыдущие публикации.
R такой же язык общего назначения и на нем можно делать массу всяких вещей.
А про ненужности "руке рынка" специфических языков можно в SAS рассказывать.SirEdvin
08.06.2022 18:13+2Ну, мне не интересны предыдущие публикации. Я то знаю, что и Prolog можно назвать языком общего назначения.
Проблема (для автора коммента и языка) то в том, что у автора коммента выше, язык R в голове таким не считается.
i_shutov Автор
09.06.2022 10:29-2Было уже в истории "Не читал, но осуждаю". В этой точке траектории разошлись.
i_shutov Автор
08.06.2022 13:16-3Тезисы субьективны.
Можно разные графики взять, R очень сильно развивается и сильно популярен в отдельных вертикалях. И на западе он очень широко применяется.
Линтеры и дополнения есть в RStudio, все работает и удобно. И автотесты есть. Есть весь DevOps стек.
Гвидо же почти остановил развитие питона. Периодически пользуюсь питоном с 2006-года.
Ну вот не смешно ли, что `switch case` завезли только в 3.10?
Про аналитику в блокнотах посмотрите последнюю ссылку в тексте https://www.youtube.com/watch?v=7jiPeIFXb6U
Все не так очевидно и прозрачно, как Вы написали.SirEdvin
08.06.2022 17:54+2Лол, что. Остановил?) А вы точно разбираетесь в том, что пишите?
i_shutov Автор
08.06.2022 18:08Можно всякие штуки читать типа таких саммари (кроме what's new):
- https://antonz.org/python-stdlib-changes/
- https://nedbatchelder.com/text/which-py.html
- PEP
- ...В силу архитектурных особенностей вещи типа полноценной векторизации и NSE принципиально не завезут.
Для задач DS все эти изменения идут почти в параллельном фоне. Ацент совсем на другом.
SirEdvin
08.06.2022 18:12+1Ну, я то читаю. И развитие языка сейчас не выглядет как остановленное, особенно после 3.4
А зачем они нужны, если есть numpy?
Даже перемножение матриц и asyncio куски?
i_shutov Автор
08.06.2022 18:23Вы читаете через несколько строк. Посмотрите приведенные ссылки. Еще раз, Numpy придумали ученые астрономы, они это сделали по уму и хорошо. Но это исправление нашлепкой сбоку. И нашлепка все равно инородна.
Про параллельные вычисления пока речи нет. В R с этим все отлично. Но, если интересно, можете поглядеть предыдущие публикации.
У Вас есть сложившаяся точка зрения и видение. Оно не изменится ни при каких ответах. Например, потребность в векторизации возникает при решении соотв. задач. Нет задач -- нет потребности. Может тогда и не стоит копья ломать?

enchantner
09.06.2022 10:12Нет, конечно. Половину ваших претензий из статьи можно просто перечеркнуть фразой "просто возьмите numpy". Низкоуровневые типы? Numpy. Векторизация? Numpy. R - узкоспециализированная штука, которая умеет это из коробки - ну и молодец. А для питона это всего лишь еще одна из функций.
Питон офигительно развивается с точки зрения производительности и с точки зрения параллельности. Погуглите по словам Mark Shannon, Pyston и multiprocessing shared memory. Вот буквально только что JIT зарелизили, например https://opennet.ru/57320/
R непригоден для промышленной разработки. Я проходил курсы по нему от нескольких университетов, и в каждом из них были фразы в духе "почему эти функции называются lapply/rapply/xapply/tapply? никто не знает, надо просто зазубрить" и "если у вас при импорте датасета возникает сегфолт - попробуйте другую версию библиотеки". Это язык, созданный в академической среде для этой самой академической среды. Давайте будем честны и не будем делать вид, что он отлично подходит для разработки тех же микросервисов. Это примерно как разработка десктопных приложений на PHP - по фану можно, но на деле язык не для этого.
MentalSky
09.06.2022 15:41+1Это язык, созданный в академической среде для этой самой академической среды.
и применять его вне академической среды - моветон?
и может быть академическая среда применяет R по академически, не по программистки? ) ругают же python-код от DS, если его смотрят python-разработчикиДавайте будем честны и не будем делать вид, что он отлично подходит для разработки тех же микросервисов
микросервисы на R? легко, пакет RestRserve + Docker и вперед, другое дело - что так не принято, там свой мейнстрим, и есть другие более подходящие инструменты
Какие-то претензии к языку из прошлого в основном, имхо
enchantner
10.06.2022 10:48и применять его вне академической среды - моветон?
Разумеется, моветон. Это нецелевое использование инструмента.
и может быть академическая среда применяет R по академически, не по программистки?
Нет, потому что R - не язык программирования. R - язык статистического анализа. Для этого он подходит хорошо, а языком общего назначения он отродясь не был.
микросервисы на R? легко, пакет RestRserve + Docker и вперед
Ничего "легкого" в этом нет. Нормальная поддержка Swagger-спек? Асинхронности? ORM? Валидации структур? Есть несколько костылей, которые позволяют сделать что-то отдаленно похожее, но по факту язык просто для этого не подходит.
MentalSky
10.06.2022 11:13+1Нет, потому что R - не язык программирования. R - язык статистического анализа. Для этого он подходит хорошо, а языком общего назначения он отродясь не был.
Проще жить в статических рамках, ну ок, хотя по моему практическому опыту R - прекрасно подходит для обработки данных, и создания Web-приложений, да, на NodeJS будет эффективнее в большом ентерпрайзе с хайлоадом, но для внутренних продуктов - почему нет?
Ничего "легкого" в этом нет. Нормальная поддержка Swagger-спек?
есть там swagger
Асинхронности?
да, из коробки
ORM
ORM - зло )) сначала весело и легко, потом медленно и больно
Валидации структур?
а в чем проблема? что не так строг как Rust?
но по факту язык просто для этого не подходит.
не участвуй в holywar, пустое это - говорю я себе, но иногда, когда все делится строго на 0 и 1 - бывает не сдерживаюсь ) что ж так строго то?
enchantner
10.06.2022 12:15Почти все решения для R, которые я нашел навскидку для асинхронного HTTP и сваггера, не обновлялись уже несколько месяцев минимум (нет коммитов), а то и несколько лет. Это не значит, что не существует более свежих и широко используемых, конечно, но немного настораживает. И я согласен, что ORM - зло, но все-таки лучше, когда есть возможность на нем быстро собрать и сделать миграции, чем совсем без него писать все руками.
Так что да, я даже не считаю это за холивар - R действительно не подходит для решения задач общего назначения. Это не делает его плохим языком, хотя лично мне его синтаксис кажется весьма неудобным по сравнению с промышленными языками. Просто за пределами его основной области (статистический анализ) он несравним с более крупными игроками, а то, что питон по функциональности даже в анализе практически перегнал - не очень хороший знак для языка в целом. Скорее всего, он так и останется академическим, и это отлично для него. Лучше расти вглубь, чем вширь.
MentalSky
10.06.2022 12:39ORM - зло, но все-таки лучше, когда есть возможность на нем быстро собрать и сделать миграции, чем совсем без него писать все руками.
зачем руками то? dplyr/dbplyr транслирует dplyr-глаголы соединенные пайпами в родной SQL в любую поддерживаемую БД
Это не делает его плохим языком, хотя лично мне его синтаксис кажется весьма неудобным по сравнению с промышленными языками.
если брать базовый R - да, тут не поспорить, сначала непривычно на общих задачах, но как только работаем с данными (и не важно, статистика это или нет) - как раз язык во всей красе себя показывает
R действительно не подходит для решения задач общего назначения
Ну как так то??? не подходит - нельзя и невозможно, или не подходит - так не принято?
а то, что питон по функциональности даже в анализе практически перегнал
эмн, в чем меряли этот факт? кол-ве вопросов на stackoverflow? метрика то какая? ) если что - мое мнение о причинах популярности питона-а у нас в стране я выше по треду озвучивал
P.S. я поясню - я не топлю за то что - а давайте R везде применять, нет, я просто триггернулся на крайности - "не подходит, невозможно, неудобно, криво" и т.д.
это давно не так в задачах вокруг данных, от их добычи до выдачи пользы наружу
enchantner
10.06.2022 12:55dplyr/dbplyr транслирует dplyr-глаголы соединенные пайпами в родной SQL в любую поддерживаемую БД
Я могу на основе этого подхода в проекте завести миграции, которые можно будет одной командой накатывать и откатывать? Нет же?
это давно не так в задачах вокруг данных, от их добычи до выдачи пользы наружу
для работы с данными, анализа их и построения статистики - несомненно, я с этим и не спорил. Я говорил именно про применение в качестве языка общего назначения. Представьте себе сайт веб-приложений из нескольких вебсервисов, например. Там, где нужна интеграция с биллингами, внешними API, работа с отложенными задачами, конвертации форматов данных. Кто для этой задачи возьмет R? Да никто, потому что он для этого не подходит. Если вы фанатик, то вы сможете все это при помощи такой-то матери реализовать, да, но зачем, если гораздо проще взять языки, лучше подходящие для этой задачи?
Вот поэтому я и говорю - R решает задачи статистики и делает это отлично. Он удобен для статистиков и аналитиков, математичен и лаконичен. Но когда речь идет о написании коммерческого решения на бэкенде, с интеграциями, дальнейшим развитием и поддержкой, он не подходит.
i_shutov Автор
10.06.2022 13:08Представьте себе, вот очень даже и работает. Пока джависты пыхтят и классы рисуют, прототип на R уже в среде и бизнес понимает, что хотеть надо совсем не то, что они сначала просили.
enchantner
10.06.2022 14:18Пока джависты уже пыхтят и пишут код, бизнес до сих пор ищет хотя бы одного разработчика на рынке, способного поддерживать легаси на R. И как эту ерунду интегрировать с их вебсайтом и настроить для нее мониторинг. В итоге просто нанимают джуна на питоне, который за пару вечеров переписывает модельку на аналогичную откуда-нибудь из scikit-learn, и это перестает быть проблемой.
i_shutov Автор
10.06.2022 14:52Джуны про регэкспы не слышали, а Вы заливаете, что он тут задачу возьмет и решит левой задней. Какую модельку? Что аналогичного?
Ага, прогноз пополнения остатков для Озона нарисует.
Как там учили???
fit-predict.
Подумайте сначала внимательно что Вы пишете. Николай, ну ведь DS -- это же не ваше поле. Много делали проектов по аналитической поддержке, бизнес-аналитике? Не агрегацию за месяц, а полный цикл от формирования требований и выработки алгоритмов решения на имеющихся огрызках данных, до вывода в прод на 24x7?
Драйвера и сервера -- это другое и не аналогичное.
Хоть людей своим комментариями не сбивайте с толку.
"Модельку аналогичную найдет..."
enchantner
10.06.2022 15:06Если учесть, что я работаю архитектором по построению DS-решений... Если бы вы имели дело с коммерческой разработкой подобных вещей, то наверняка знали бы, что в случае классического ML особых изысков бизнес не требует, чаще всего достаточно взять ансамбль простых моделей, какой-нибудь xgboost и все будет работать. На каком языке будут эти модели - не особо важно, но питон лучше и легче интегрируется с остальными компонентами системы.
А про то, что примерно весь DL (там, где он реально нужен) сейчас на питоне, вам уже ниже рассказали в деталях в других комментариях, не буду повторяться.
i_shutov Автор
10.06.2022 15:22Архитектор -- круто, так что тогда в штыки так воспринимаете и закрываетесь?
В проде должно быть все равно, что там в кубере/докере/опеншифте крутится. API и response time.
ML -- это маленькая вишенка на торте, чтобы до этого добраться нужно пропахать вдоль и поперек не один раз перед этим. Я нигде не писал слов ML/DL, это вообще на 80% инфраструктурные задачи, MLOps, как он есть.
Был компактный текст, затрагивающий ограниченный ряд вопросов. Не было никаких заходов в бигдату, в мл, в физику высоких энергий... Но ведь нет же.
На тезис "пандас медленный" следует реакция -- "а R на ноутбуке 10 Тб не перелопатит, зуб даю".
На тезис "индексы неудачно построены" -- "наберись опыта, а в промышленной разработке на R не пишут, а перепиши библиотеки, да ты пакетов в питоне не видел, да все вообще в excel считают" и пр...
Ну что это такое?
Вам пачку референсов коммерческих нужно? Ну право слово, не на площади же.
enchantner
10.06.2022 16:45Так я не воспринимаю в штыки. У R есть сильные стороны и он отлично применим в своей нише. Но порой создается впечатление, что люди, которые топят за то, что он там, оказывается, умеет еще и какие-то вебсервисы и что-то еще, просто плохо знают текущие стеки в индустрии. Практически весь MLOps везде на питоне - MLFlow, DVC, Airflow. Пандас медленный, да. Но при правильном приготовлении пережевывает датасеты размером больше, чем R.
Вы все правильно написали, просто почему-то из этого делаете противоположный очевидному вывод - если вся индустрия пишет на питоне, найти питониста легко, найти обертку/модель/что угодно, которая есть в R, но нет в питоне, весьма сложно - так зачем брать R в реальном коммерческом стеке? Ну нет у него преимуществ толком, не-ту. Только для статистиков и аналитиков, только для академических целей. И это его сильная сторона, не надо его натягивать, как сову на глобус, на все подряд.
i_shutov Автор
10.06.2022 17:11Ну не одним же MLOps-ом все живет, уже давал комментарий. Тем и задач выше крыши.
У нас ansible AWX вполне успешно оркестрирует R-овские докеры в проде. Да и airflow тоже может.
И не надо никакую сову натягивать, зачем животное мучать. Без этого все вполне органично встраивается и интегрируется.
H2O automl нравится. лучше джуниоров :)
i_shutov Автор
10.06.2022 17:44Ну и почему опять MLOps?
Я не говорил про него в тексте.
Исследования, ad-hoc, различные аналитические приложения, rmarkdown отчеты в неимоверных количествах и сложности соответствующей, счетные сервисы в режиме черного ящика или API, да 100500 классов задач.
Если правда интересно, посмотрите предыдущие публикации.
MentalSky
10.06.2022 15:27но питон лучше и легче интегрируется с остальными компонентами системы.
лучше легче - потому и так вокруг питон?
В чем разница:
питон - обучили модель, сохранили в peakle, добавили в микросервис, используем;
R - обучили модель, сохранили в RDS, добавили в микросервис, используем;
в чем легкость у питона? другое дело - если не хотим прятать за API, и напрямую вызывать в airflow, ну ок, да, но это же не проблема языка R, верно? Просто есть выбранный стек, и все.
enchantner
10.06.2022 16:48Да, аргумента "потому что и так вокруг питон" уже достаточно. Не говоря уже о том, что разница между питоном и R по части целевых библиотек и производительности не настолько большая, чтобы предпочитать узкоспециализированный язык общему. Достаточно даже просто посмотреть на объемы баз пакетов.
i_shutov Автор
10.06.2022 16:56Ваша логика предельно понятна. Классический архитектурный подход. Думай глобально, решай локально.
Даже каждый непрограммист, который занимался стройкой, сталкивался с этим. А потом выясняется... здесь жесткости не хватает, здесь не учли структуру грунта, здесь мощности выделить не могут, здесь отступы нарушены, а тут не пролезает, а тут сэкономили две копейки ...
Но это все будет потом.
enchantner
10.06.2022 19:02Да, примерно так и бывает, когда исключительно академичные люди на академичном языке пишут академичный код. Хорошо, что с питоном в этом плане сильно легче, и читать код на нем базово может даже джун
i_shutov Автор
10.06.2022 20:47Это Вы вообще или конкретно мне? Если мне, то поглядите примеры кода в предыдущих публикациях и ткните пальцем где там увидите академичность на академичном языке.
Найдете хоть строчку? Тогда хоть будет понятно, что именно Вы подразумевали. Просто с голословным утверждением сложно что-либо делать.
MentalSky
10.06.2022 16:56+1Да, аргумента "потому что и так вокруг питон" уже достаточно.
вот это, да - аргумент,
а то что R не подходит, потому что R - не аргумент )
MentalSky
10.06.2022 14:11Я могу на основе этого подхода в проекте завести миграции, которые можно будет одной командой накатывать и откатывать? Нет же?
и это ограничение языка???? когда-то и на питоне не было этого пакета, его написали, ибо было нужно
как и прекрасные targets и mlr3 для R - их тоже написали, потому что было надо
так при чем тут R и его ограниченность?Представьте себе сайт веб-приложений из нескольких вебсервисов, например. Там, где нужна интеграция с биллингами, внешними API, работа с отложенными задачами, конвертации форматов данных. Кто для этой задачи возьмет R?
я так понял, весь тред не читали?
https://habr.com/ru/post/670250/comments/#comment_24419934и это стартап, где надо результат сразу и что бы потом не отвлекало
Если вы фанатик, то вы сможете все это при помощи такой-то матери реализовать, да, но зачем, если гораздо проще взять языки, лучше подходящие для этой задачи?
фанат? хммм, а ведь да, фанатею от баз данных, анализа данных, BI, ML, статистики, разработки и вообще решения инженерных задач, и R в нашей экосистеме хорошо зашел, просто такой бизнес, получилось эффективно
Еще раз - я Вас не переубеждаю, мне это ни к чему, как и Вам, я просто против категоричных утверждений, и все )
enchantner
10.06.2022 14:24и это ограничение языка????
это ограничение его экосистемы. Тот же Rust, например, несмотря на всю свою красоту и низкоуровневость, до сих пор не очень подходит для решения задач анализа данных в силу слабой интеграции с BLAS и отсутствием стабильного набора тулинга для подобных задач. Это не значит, что в будущем его нельзя будет развить в эту сторону, но это значит, что в текущем виде это не очень хороший выбор для подобного класса задач. То же самое в случае R и почти любых не-статистических задач.
весь тред не читали?
читал. Называется несколько мелких проектов для частных случаев. Это мило, но как это сравнимо с тысячами проектов и оберток в этих же сферах для питона? Судя по аргументам в том комментарии, R взяли просто потому что команда быстрее и проще всего умела на нем фигачить, а не потому, что он прям идеален для подобных задач. И это вполне логично, но никак не является аргументом в поддержку языка. Могли бы взять с тем же успехом любой другой, с которым просто умели работать
MentalSky
10.06.2022 14:34это ограничение его экосистемы
и в чем это ограничение? мне правда интересно
Называется несколько мелких проектов для частных случаев. Это мило, но как это сравнимо с тысячами проектов и оберток в этих же сферах для питона? Судя по аргументам в том комментарии, R взяли просто потому что команда быстрее и проще всего умела на нем фигачить, а не потому, что он прям идеален для подобных задач
все куда то ушло не туда, в идеальность-неидеальность, ну это ж такое, правда?
То же самое в случае R и почти любых не-статистических задач.
не согласен с такой категоричностью, ну да и ладно, многообразие мнений это хорошо
i_shutov Автор
10.06.2022 15:03Увы, стиль "не читал, но осуждаю" превалирует.
R прекрасно заходит во всех вертикалях.
Где-то один, где-то вкупе с тяжелой артиллерией в виде баз, балансировщиков, серверов приложений, шин и пр.
SirEdvin
10.06.2022 18:01За что я не люблю всяких "евангелистов языков",так это за откровенную неспособность реально относится к проблемам языка. То go с его "дженерики не нужны", то "r отлично заходит везде, а те вещи, которых там нет, вам не нужны".
Не думайте, пожалуйста, что вы умный, а все ошибаються. Очень часто наоборот.
i_shutov Автор
10.06.2022 20:44Не любите -- Ваше право. Но давайте уж логику проследим.
1. Есть исходный текст. В нем нет никаких призывов, никаких бигдат и промышленных применений. Рассматривается ряд предельно конкретных вещей. С примерами и отсылками на доп. материалы.
2. В комментариях возникает масса вопросов далеко за пределами исходного текста. Я стараюсь ответить. Без каких-либо призывов, просто ответить.
3. Вы читаете комментарии, вырываете из контекста и делаете свои выводы, которые никак не относятся к исходному тексту.
Как относиться к Вашим высказываниям? С большим сомнением.
i_shutov Автор
10.06.2022 14:41Вы ведь в курсе, что коммерческие решения во многих случаях представляют сборную солянку из языков и технологий. R себя там очень хорошо проявляет в качестве "мат. сопроцессора" и аналитического окна.
Но при чем здесь промышленная разработка и аналитика, как про нее изначально было написано? Что Вы в кучу мешаете все?
enchantner
10.06.2022 15:07Так и numpy отлично себя проявляет, и scipy. Зачем брать то, что плохо интегрируется, если можно взять то, что интегрируется хорошо? Из-за того 0.01% статмоделей, которые еще не портировали из R в Python? Сомнительно.
i_shutov Автор
10.06.2022 15:25Что Вы к статмоделям привязались? Спектр задач гораздо шире и без ML/DL. Интегрируется все на ура. Вообще нет вопросов. Вы ведь знаете, например, что в телекоме до сих пор (о ужас!) идет интеграция с биллингом через файлы (CDR)? Просто как пример.
i_shutov Автор
09.06.2022 16:02Есть масса других языков, которые более пригодны для промышленной разработки и куда производительнее.
https://habr.com/ru/post/488644/ -- прекрасный доклад. Golang рулит для многопоточных задачек.Полмира сидит на аналитических микросервисах на R. Ажур с радостью предоставит.
Стыдно за курсы тех "нескольких университетов". Честно, стыдно. Что хоть за универы?
enchantner
10.06.2022 10:56Я на этом докладе был лично. То, что вы приводите его в пример, показывает, что вы вообще не понимаете, о чем речь - Go не является заменой питона, тем более в DS, и у него масса проблем с экосистемой. Он отлично подходит для быстрых асинхронных сетевых сервисов и вещей потипу параллельных ETL, но это весьма специфическая вещь.
Про полмира вы, мягко говоря, лукавите. Полмира сидит как раз на питоне, а R знает только по отдельным статьям, и то ищут, как те же вещи перетащить в питон. Ведущие университеты курсы переводят на питон.
P.S. Да, если что, вам "стыдно" за курсы Johns Hopkins University, например. Не говоря уже о том, что предложенный пойнт про "почему так методы называются" самоочевиден, с ним сложно спорить. Это еще одна из слабых сторон R.
i_shutov Автор
10.06.2022 11:24Вы заметили, что я настойчиво пытаюсь вернуть в область DS, но вопросы задают вообще из других областей. Джависты, бигдатовцы, разработчики корп. систем. И вопрос был "вообще" и ответ был про промышленную разработку. И да, го для другого, но это не мешает показать, что питон не универсален. Есть вещи и получше для определенного класса задач. и голэнг модули куда приятнее в прод тащить, чем питон.
Видел я многие курсы, не надо старье пихать 20-ти летней давности. Курсы надо актуализировать периодически, хоть это и трудозатратно.
Утомили уже эти комментарии без привязки к темы, без ссылок, без доказательств. А также желание каждого второго облить грязью. Нацепили каски и давай палить, даже не прочитав от начала до конца. Ну вот с чего Вы взяли, что что-то там про го непонятно? Но есть другой факт, когда говорят про ds в энтерпрайзе, зачастую подразумевают %30-40 загрузки/перезагрузки данных. и ETL там выше крыши.
Есть хоть одно возражение к тезисам в исходном тексте? Там ведь масса материалов и ссылок была дана?enchantner
10.06.2022 11:53В области DS все просто - Python умеет примерно все то же самое, что и R, но еще и многое другое сверху, что и делает его более желательной целью для изучения и продвижения. А еще вы подменяете понятия - фразы "го лучше питона в конкретной сфере" и "питон не универсален" логически не связаны. Да, лучше. Но нет, универсален.
Видел я многие курсы, не надо старье пихать 20-ти летней давности. Курсы надо актуализировать периодически, хоть это и трудозатратно.
Эти курсы сейчас актуализируют тем, что переводят их на Python. Потому что он более востребован и удобен для широкого круга задач.
Не надо воспринимать эти заявления, как личные нападки. Это очень удобная позиция, бесспорно, но никто лично на вас не наезжает. Просто почти все пункты вашей статьи не по делу.
1) "ООП и DS плохо совместимы" - возможно, только Python тут ни при чем. Он позволяет использовать как ООП, так и процедурный подход при желании. Мимо.
2) "Недостаточность базовых типов данных" - import numpy решает эту проблему. Мимо.
3) "Векторизация" - см предыдущий пункт. Мимо.
4) "Колонки", "Поддерживается странная концепция эквивалентности работы как по вертикали, так и по горизонтали" - это прямым текстом неправда. Pandas хранит данные в колоночно-ориентированном формате и оптимизирован для векторных операций на колонках. То, что можно, перебирать ряды - просто костыль и общепризнанный антипаттерн. Мимо.
5) "Индекс" - редкая валидная претензия, которая, тем не менее, чинится просто чтением документации один раз
6) "Copy-paste" - про метод query мы умолчим, а то идея развалится. Мимо.
7) "Отсутствие полноценной конвейерной обработки (pipe)" - то, что вы не знаете про генераторы в Python, не значит, что они отсутствуют. Мимо.
8) "Производительность" - да, согласен, Pandas довольно медленный. Но, во-первых, ему есть масса альтернатив (как лихо вы выкинули из рассмотрения Dask и polars, ни к селу ни к городу приплетя Clickhouse). А во-вторых - вот новость - статистический анализ в питоне не ограничивается пандасом.
9) "Бенчмарки" - написана лютая чушь, извините, конечно. Вы бы ради приличия хотя бы разведали, что существуют Scalene и Memray, ничего хотя бы близкого к которым в мире R не существует в принципе. Мимо.
Вот отсюда и подобная реакция на сей опус - он делает ряд мало связанных с реальностью заявлений и сравнивает бензопилу и швейцарский нож.
i_shutov Автор
10.06.2022 12:55Панда ООП-шная. И сам питон по своей идеологии ООП-шный. И все там ООП пропитано снизу доверху
В панде почитайте про blockmanager. Просто почитайте.
Никуда не деться от множественного написания переменной. Факт, проверяемый каждым лично.
Генератор и пайп -- разные вещи. Хотел бы сказать генератор -- сказал.
Здесь не затрагивались распределенные вычисления. Это отдельная область. Считаем на одной машине.
Вы спутали профилировщики с бенчмаркингом. Это две разные вещи, ну просто поглядите хотя бы. Хотел бы я написать про профилировщик -- ну так бы прямо и написал. И в R хорошо и с этим и с другим.
https://rstudio.github.io/profvis/
https://r-prof.github.io/proffer/index.html
enchantner
10.06.2022 14:151) Нет. Не знаю, откуда вы это взяли, это просто неверно. Более того, несмотря на то, что все - объекты, именно ООП-подход в питоне довольно куцый и не очень удобный
2) Читал. Костыли для управления памятью есть везде, но только вот в пандасе они вполне работают. Более того, у меня был на практике случай, когда большой csv-файл спокойно прочитался пандасом в память (и не сильно много занял), а R выдал...сегфолт. Без объяснений, просто не работало
3) Я привел конкретный пример, как избавиться. Не говоря уже о том, что явное лучше неявного, а переменных без объявления в середине выражения быть реально не должно
4) Не настолько разные. Если вам просто нужно организовать цепочку вычислений, где следующий шаг получает результаты предыдущего - для этого есть генераторы. Пайп - это конструкция в первую очередь операционной системы, а в языках есть разные свои обертки, которые реализуют что-то похожее
5) Не понял, причем тут распределенные вычисления. Питоном тоже можно считать на одной машине
6) Профилировщик - сюрприз - в том числе может запускать бенчмарки по коду. По вашим ссылкам всего лишь простейшие инструменты для флеймграфов, при этом тот же Scalene умеет, например, в рандомизацию окружения, бенчмарки на GPU, бенчмарки многопоточных и многопроцессных программ, отдельный вывод статистики не только по user time vs kernel time, но и по Python time vs C time
P.S. Ваша нумерация ответов полностью игнорирует нумерацию в моем комментарии, в результате сбивает с толку и игнорирует часть пунктов, которые были упомянуты выше. Это не очень хороший прием в обсуждении
i_shutov Автор
10.06.2022 16:26Давайте попробуем с сохранением нумерации.
Выхожу за рамки одномерных массивов из numpy. Попадаю во фреймы -- объекты. Работа с файлами, графиками, бд, модельками -- опять ООП.
Если читали, то видели архитектурные косяки панды? А что там было на практике -- неизвестно. Что, где, когда, при каких условиях... чем читали.
`query` никак не спасает в большом количестве случаев.
пайпы много функциональнее в R. И никак не генераторы. Вы просто почитайте, я же ссылку дал. Это не просто передача выход-вход. И они очень удобны. Обертками это не решается в питоне.
на одной машине
data.tableвсех обыгрывает, не надо огород городить. есть еще `apache arrow` как хорошее дополнение.бенчмарк алогоритмических конструкций. ну не дают профилировщики полноты картины, что надо при оптимизации вычислений.

kkirsanov2
08.06.2022 14:02+1>>Вот почти уверен что скобки и избыточность упоминания df в срезах df[(df.col1==...) & (df.col1>...)] скоро уберут.
Это невозможно без изменения самого языка. Выражение (col==...) должно быть вычислено первым а переменная col1 - не определена.
В текущем питоне можно либо превратить это в вызов функции df.slice(col1==...) но смысла нет, либо заменить строкой df["(col1==..."] но и это плохо.

apastukhov
08.06.2022 13:09+6Я R-ом пользуюсь каждый день и обучаю ему студентов. И проблема в том, что чем глубже в R, тем страшнее им пользоваться для сложных проектов, потому что base R построен по-принципу "удобство важнее надёжности" и "костылей в куче много не бывает". Неправильные индексы не то что ошибку, ворнинг не дают. Зачем, если можно вернуть NA или NULL, хуман сам разберётся. И это только самый базовый, но постоянно используемый функционал. Вот человек не поленился копать и там такие глубины ада разверзлись... https://github.com/ReeceGoding/Frustration-One-Year-With-R
Позитив что медленно, но верно это всё фиксят. Строки уже не факторы по-умолчанию, && и || наконец выдают ошибку при более чем одном элементе (а не молча игнорируют всё кроме первого элемента). Но ударение на слово "медленно".i_shutov Автор
08.06.2022 13:21-3Аналитика и промышленное программирование сильно отличаются.
Весь Tidyverse стек построен именно в контексте работы кода в проде.
Немного писал здесь: https://habr.com/ru/post/543552/
Приходите в группу в телеграме -- подскажем.apastukhov
08.06.2022 23:23Да, Tidyverse действительно гораздо строже и поэтому гораздо надёжней. (Честно говоря, я вообще плохо понимаю кому нужен R без Tidyverse, но на вкус и цвет...) Но от базового R всё равно ни куда не денешься. И Tidyverse постоянно меняется, pivot_longer/wider это уже у нас 3-я версия функционала? Я до сих пор им не могу простить, что они устроили с summarize превратив его в универсальную функцию, которая и mutate, и исходный summarize, и вообще хоть сколько строк можно, давай всё.
i_shutov Автор
09.06.2022 10:31Приходите в телеграм канал, разберемся. Хадли и его команда, действительно, очень хорошо систематизировали. И, конечно же,
data.table, который просто превосходен.
MentalSky
08.06.2022 13:11Решили и выбрали Python не директора курсов и вузов, не тренеры, а... сами аналитики, их работодатели и другие программисты, которым переход на Python+Pandas и интероперабельность такой связки показались выше, чем с R.
Ну то есть выбор-то уже был сделан, наличием питон-стека на предприятии или наличия опыта в питоне, а не потому что R это фу, остальные причины - экономика рынка труда и вкусовщина, кому то синтаксис питона красив и понятен, а я после C++ и подобных не могу себя заставить питонить ))

N-Cube
08.06.2022 13:18+4Про R многое можно сказать, но стоит начать с главного - к нему отсутствует вменяемая документация. Помнится, я сталкивался с тем, что вычисление квартилей работает иначе, чем это документировано - чтобы найти причины, пришлось залезть аж в фортрановские исходники. Ну просто замечательный язык, где авторы просто подключают неведомые сторонние либы вообще без документации и комментариев в них, и даже не находят нужным протестировать получаемые результаты. Использовать этот черный ящик для сложных задач типа машинного обучения, серьезно? Мне это очень напоминает подход авторов пакета GMT, которые делают ровно так же - волосы дыбом становятся, если почитать их исходники и чэнджлог, где одни сторонние библиотеки заменяют другими раз за разом, каждый раз получают разные результаты и никак не могут договориться, какой же результат считать правильным! На питоне, при всех его недостатках, я ни разу не сталкивался с тем, чтобы метод и результат вычислений абсолютно не соответствовал документации.
P.S. Вместо pandas можно использовать Sqlite3, в среде Jupyter Notebook запросы выполняются с помощью %sql (или %%sql) и результаты легко преобразуются в датафрейм pandas.
MentalSky
08.06.2022 13:23+2Вместо pandas можно использовать Sqlite3
Лучше R + apache arrow или DuckDB - очень удобно и очень быстро ;)
i_shutov Автор
08.06.2022 13:29По R сейчас просто изумительная документация. Дайте вопрос, приведу ответ.
И книги прекрасные выпущены и переведены.
По квантилям -- вот пример. https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/quantile
Все написано, 9 вариантов различных вычислений (ну так уж накопилось в науке), есть ссылки на научные публикации.
А CRAN вообще закрутил гайки и ввел репрессии в части CI/CD по репозиторию пакетов.N-Cube
08.06.2022 16:39+5Смотрим исходники:
See R-3.2.2/src/library/stats/R/quantile.R
r_quantile <- function(x, probs)
{x <- sort(x)
n <- length(x)
nppm <- n * probs
j <- floor(nppm)
if ( nppm > j ) {
qs <- if (j<n) x[j+1] else x[n]
} else {
qs <- x[j]
}
qs
}
Как итог, получаемые результаты несовместимы ни с одной стандартной реализацией. А теперь покажите, где в документации R сказано, что они взяли и сломали реализацию вычисления квартилей, используя функцию floor() вместо необходимого round()? Нарушать без предупреждения реализацию базовых функций - такое только в ранних версиях PHP лет двадцать назад случалось, и то там быстро чинили.
i_shutov Автор
08.06.2022 16:47-3Без репрекса сложно понять. Да и код исходной фунции сильно сложнее:
https://github.com/wch/r-source/blob/trunk/src/library/stats/R/quantile.Rтам же еще есть параметр
type, который влияет на логику расчетов.просто это серьезный вопрос, требующий тщательной подготовки примеров в коде. Вы точно уверены, что все параметры правильно выставляли: https://www.amherst.edu/media/view/129116/original/Sample+Quantiles.pdf ?
N-Cube
08.06.2022 20:29+3Я уверен, что ни один из вариантов вычисления этой функции не возвращал ожидаемый результат, в отличие от Python Numpy. Как видим, код реализации внутренних функций R безобразный, недокументированный и не комментированный, потому что вот это вот вообще нечитаемо:
if(type == 7) { # be completely back-compatible
и вы ничего не можете понять, глядя в этот код. По сути, существует единственная неопределенность вычисления квартилей дискретного распределения, которая сводится к тому, что считать медианой для четного количества элементов - если взять среднее от двух элементов, то оно не является членом исходного ряда, в то время как медиана по определению должна им являться (в том числе, это приводит к тому, что медиана целочисленного ряда оказывается дробным значением, что не всегда допустимо), поэтому стандартный подход это вернуть левое или правое значение, ближайшее по величине к этому среднему. В R же реализовано нечто неведомое.
i_shutov Автор
09.06.2022 10:44+1Набор безапеляционных утверждений.
Вот статья из Statistical Computing, за автором известного математика Rob J. Hyndman, где описаны все подходы к вычислению квантилей. https://www.amherst.edu/media/view/129116/original/Sample+Quantiles.pdf
Пакеты в R построен в полном соответствии с ней. Если действительно хотите разобраться в вопросе -- давайте в конструктивный диалог в телеграм канал. Различные участники помогут. Если не хотите, а просто вбрасываете слоганы -- ну пусть будет так.
0xd34df00d
09.06.2022 02:13Ух ты, сортируем весь массив, чтобы достать из него всего один элемент. К продакшену готово!
N-Cube
09.06.2022 09:06Насколько мне помнится, разработчики R официально гордятся тем, что они презирают такие низменные материи, как оптимизация программ, это идеология языка. К примеру, уже для несложной обработки CSV файла (оценка распределения данных, подсчет регрессий и корреляций… все эти алгоритмы отлично распараллеливаются до такой степени, что можно просто построчно данные с диска считывать и обрабатывать, несложно самому за несколько часов написать реализацию, которой хватит знаменитых 640 КБ памяти) в несколько гигабайт в R можно было получить ошибку, что программе не удалось аллоцировать больше 64 ГБ памяти (независимо от доступной RAM и свопа, там внутренний лимит был), в то время как на Python+Pandas хватает 8 ГБ - даже если данные загрузить в память целиком. В общем, в свое время у меня было много заказов от университетов по портированию их «научного багажа» с R (и Matlab, но это отдельная история) на Python, потому что данных стало больше и обработать их на R невозможно даже на университетских кластерах, в то время как на Python+Numpy+SciPy+Pandas+Dask то же самое легко сделать на типовом лаптопе. Впрочем, с помощью Dask на типовом лаптопе (8 GB RAM, по тем временам) можно и терабайты данных обработать, и даже без модификации программы запустить ее на многоядерном сервере или кластере серверов с автоматическим распараллеливанием и удобной панелью визуализации. Так что R это конкурент Microsoft Excel, а не Python с его научными библиотеками.
i_shutov Автор
09.06.2022 10:47-2Вам просто сильно не повезло и у Вас совсем нерелевантный опыт.
Досадно, что так получилось.
В реальности все прекрасно работает.
Дело в руках (или в очках).
Kanut
09.06.2022 10:51+2Хм. А давайте предположим что выяснится что у большинства такой вот "досадный нерелевантный опыт" и "дело в руках (или в очках)".
О чём это по вашему будет говорить?
i_shutov Автор
09.06.2022 11:03Ваш случай легко проверяется на практике. От разговоров переход на стенд и простая демонстрация как надо было делать. Факты -- вещь упрямая. Делал так бесчисленное количество раз.
Посмотрите https://github.com/gedeck/practical-statistics-for-data-scientists
Там примеры к книге на R и Python.
С вычищенными комментариями во всех случаях R лаконичнее.
Про перформанс ссылку давал, можете поглядеть, там очень обширные тесты.Kanut
09.06.2022 11:07+1Ваш случай легко проверяется на практике.
У вас есть статистика?
Факты — вещь упрямая. Делал так бесчисленное количество раз.
Какие "факты"? Если у вас всё нормально получается, то и у всех остальных автоматом должно всё нормально получаться? И в принципе не может быть иначе?
Посмотрите https://github.com/gedeck/practical-statistics-for-data-scientists. Там примеры к книге на R и Python.
С вычищенными комментариями во всех случаях R лаконичнее.Ну так давайте допустим что я посмотрел и получил "досадный нерелевантный опыт". И большинство других людей посмотрели и тоже получили его же. О чём по вашему будет говорит такая вот гипотетическая ситуация?
А потом можно будет обсудить насколько эта гипотетичская ситуация совпадает или не совпадает с реальностью. Если в этом ещё будет необходимость...
i_shutov Автор
09.06.2022 11:17-2Понимаете, разговор плавно переходит в тон обоюдных наездов.
Это неприятно и деструктивно. Тем более что мы вообще ничего не знаем про опыт оппонента. Я мог бы много чего рассказать и показать, частично рассказывал на митапах. Если Вам действительно что-то интересно, приходите в группу в телеграм. Гладко все бывает только на бумаге.Kanut
09.06.2022 11:24+1Вы по моему не особо понимаете что я пытаюсь до вас донести. У вас всё хорошо и всё работает. Есть какие-то единомышленники у которых тоже всё хорошо и всё работает.
Но вы в статье задаёте вопрос: почему у нас есть такой хороший и замечательных язык R, но при этом им мало кто хочет пользоваться. А пользуются все не таким хорошим и замечательным питоном.
И когда вам люди говорят что они пробовали R и у них это не работало, то вы удивляетесь и хотите им обьяснить как это делать правильно. Приглашаете в телеграм, на митапы, даёте полезные ссылки. И так далее и тому подобное.
И не видите что на самом деле "поезд уже ушёл". Потому что люди не хотят в телеграм, на митапы и читать кучу полезных ссылок и разбираться. Они хотят взять и чтобы сразу работало. Ну максимум глянуть что-то на stackoverflow. И похоже с питоном оно так получается. А с R не получается. И в этом-то и проблема...
i_shutov Автор
09.06.2022 11:29Ничего сразу нигде не работает. Все требует больших усилий по освоению. А если уж и работает, то в R с этим куда проще.
Никакой поезд никуда не ушел, да и поезда нет никакого. Спиральное развитие. А первоначально входящие на этот рынок труда могут критически посмотреть на спектр предлагаемых инструментов и возможностей. Просто не стоит воспринимать питон "даром богов".
С утверждением "я попробовал и у меня не получилось" работать ну никак невозможно. Даже поддержка тикет не откроет в такой постановке вопроса.
На западе R занимает сегмент примерно такой же как питон. Целая индустрия. Это у нас исторический перекос возник.
Если есть серьезный вопрос, то он требует тщательного разбора с `reprex`, уточнениями по разным моментам и т.д. Формат комментариев для этого совсем неудобен. Вот и все.
Kanut
09.06.2022 11:34+1Ничего сразу нигде не работает. Все требует больших усилий по освоению.
У меня приходят практиканты с нулевым опытом, а иногда даже знаниями по питону. Я им даю питон и они через пару недель спокойно что-то там на нём себе делают. С R я лично так естественно не пробовал. Но даже по вашим словам получается что скорее всего оно так работать не будет.
А первоначально входящие на этот рынок труда могут критически посмотреть на спектр предлагаемых инструментов и возможностей.
Первоночально входящие смотреть могут что угодно. Вот только они обычно ничего не решают.
С утверждением "я попробовал и у меня не получилось" работать ну никак невозможно. Даже поддержка тикет не откроет в такой постановке вопроса.
А никого никакие тикеты и не интересуют. Вася попробовал Р и у него не получилось. Потом он попробовал питон и у него получилось. Для Васи тема закрыта. И если таких Вась много, то вот вам и ответ на вопрос почему питон популярнее.
i_shutov Автор
09.06.2022 11:38Вы посмотрите на вопросы начинающих и не очень.
Нет никакого "попробовал и получилось". Опыт накапливается через множество шишек. И чаще всего, если руку не ставить, то код будет являться скопищем антипаттернов.
Практиканты -- это любопытно. Где это так? Если искорка осталась, можете дать тест драйв для R, результаты могут превзойти ожидания.
Kanut
09.06.2022 11:42+1Вы посмотрите на вопросы начинающих и не очень.
Смотрю. И вижу людей у которых сходу не получилось. То есть что-то не так с порогом вхождения. По крайней мере для меня это выглядит так что у R он выше чем у питона.
Практиканты — это любопытно. Где это так?
В смысле "где"? На фирме. А у вас на фирмах практикантов нет?
Если искорка осталась, можете дать тест драйв для R, результаты могут превзойти ожидания.
Так нет этой самой искорки. И откуда ей взяться то? В той нише где мы применяем питон он нас в принципе устраивает. Наши клиенты тоже в основной своей массе использует его. Зачем нам что-то менять?
i_shutov Автор
09.06.2022 11:49Со "студентами" вообще морока.
Очень много времени до выхода на безубыточость.
3-4 месяца надо учить методам командной работы и промышленной разработки, чтобы их код можно было в гит вливать.
С прошедшими "экспресс" курсы приходится проводить предварительную зачистку, выкорчевывать сорняки антипаттернов. В обучении же "быстрей-быстре", без какого-либо серьезного фундамента. Если я сажусь и переписывают несколько строчек, получая ускорение в 1000 раз -- ну это непозволительная роскошь для кода в проде.
Искорки нет -- понятно. Выгорание, рутина сжирает. Не Вы первый, не Вы последний.
Kanut
09.06.2022 11:53Если я сажусь и переписывают несколько строчек, получая ускорение в 1000 раз — ну это непозволительная роскошь для кода в проде.
А если нет этого ускорения? Или если оно никого не интересует? Ну то есть вам принципиально будует скрипт бегать 0,1 секунду или 0,0001 секунду? А если между запусками скрипта у вас "человеческий фактор" на 20-30 секунд?
Искорки нет — понятно. Выгорание, рутина сжирает. Не Вы первый, не Вы последний.
Не-не-не. Искорка у меня есть. Но в других контекстах. Питон это у нас так, ниша. Зачем мне там "гореть"?
i_shutov Автор
09.06.2022 11:59Я мог бы ответить на большинство Ваших вопросы (они достаточно типичны), но формат перепалок в комментариях очень неудобен. Я постарался максмально четко раскрыть ответы, но матрешки бесконечной глубины требуют бесконечного времени, которого нет ни у кого.
Тематика "What-If" требует погружения в конкретный кейс и составление модели. Я частенько занимаюсь симуляцией и цифровыми двойниками, чтобы немного понимать сложность этого вопроса. Маловероятные ветки на первых итерациях нужно прибивать сразу, иначе Ктулху утащит.
N-Cube
09.06.2022 16:49+1Выше я дал отсылку на код апстрима R, который ужасен и работает некоректно. Вы сами этот код даже понять не смогли, хотя я привел сокращенную его версию, демонстрирующую проблему. И вместо того, чтобы заняться проверкой и починкой, вы имеете наглость заявить, что это просто программистам на R «не повезло», что они R используют? Ок, больше не будем, я с этого и начал свой комментарий. Далее, про обработку больших данных - вот у меня есть открытый проект на Python - пакет спутниковой интерферометрии, размер обрабатываемых данных от пары гигабайт (меньше никак не получится, в силу природы исходных данных) до терабайт - попробуйте сделать аналог на R, раз уж вы утверждаете, что R это нечто большее, нежели замена Excel, и вы умеете им пользоваться. В репозитории есть ссылки на «живые» Jupyter ноутбуки на Google Colab, ждем от вас альтернативной реализации на R, также работоспособной на Google Colab за сравнимое время. Ссылка на репозиторий: https://github.com/mobigroup/gmtsar Лично мне для получения вменяемых результатов для подобной обработки на R приходилось писать либы на фортране с оберткой на R (да, не на си даже), причем на Python+Numpy обработка все равно выполняется на порядок быстрее (потому что можно избежать лишних копирований и работать с одним экземпляром данных).
i_shutov Автор
09.06.2022 17:21-1Поглядел проект — здорово. Когда-то тоже приходилось считать квантовые эффекты и взаимодействие света с веществом. Гигабайтами не пугайте, считаем-считаем. И терабайты тоже.
Но так вот наскакивать и грубо публично хамить незнакомому человеку — ну негоже это для учёного. Не находите?
N-Cube
09.06.2022 21:18+2Так ведь наскакивали и грубо публично хамили именно вы - что мол руки кривые (см. выше), а теперь еще и спрашиваете, нормально ли это? Нет, не нормально. Более того, по сути перечисленных проблем R и по показанным кейсам вам и сказать нечего, кроме вот хамства. То есть мало того, что R очень проблемный язык, так еще и его сторонники вот так себя ведут, ну и какой нормальный человек захочет в такое комьюнити? На всякий случай процитирую вас:
у Вас совсем нерелевантный опыт.
В реальности все прекрасно работает. Дело в руках (или в очках).
Так что, проверять и править core libraries R будете или ограничитесь оскорблениями? Вы просили примеров проблем - вам их показали. Проблему с избыточными копированиями данных в этом же коде уже тоже подробно обсудили, вдобавок. В Python+Numpy подобных проблем нет (как и многих других, отравляющих работу в R, типа F-ordering и C-ordering при использовании внешних библиотек и прочих).
i_shutov Автор
09.06.2022 22:38Вы не показали никаких кейсов, только какие-то куски кода с гитхаба и много-много-много слов.
1. Что именно в медиане для четного числа чисел Вас не устраивает? Поддерживается аж 9 вариантов вычислений, которые описаны в статье в уважаемом журнале. Wolfram Alpha считает и не переживает -- можете поглядеть: https://www.wolframalpha.com/input?i=median&assumption={"F"%2C+"MedianCalculator"%2C+"list"}+->"{1%2C+2%2C+3%2C+4}"&assumption={"C"%2C+"median"}+->+{"Calculator"}. Откуда Вы взяли свою версию расчетов? Можно привести источник? Можете привести воспроизводимый пример, чтобы показать, что считается в питоне правильно и не так в R? Не словами, а цифрами. Вы же, в конце концов, околонаучный сотрудик? Сравним с Wolfram, Matlab, Maple, Statistica и т.д. Не нравитсяstats::quantile, возьмите https://sebkrantz.github.io/collapse/reference/fnth.html
2. Что Вы так рьяно рветесь править core library без наличия доказательной базы? И не забывайте правил корректировки любого софта -- если обещали обратную совместимость -- надо поддерживать. Да даже если отложить разработку -- на любом научном семинаре требуют (раньше точно требовали) предъявлять веские доказательства своих утверждений.
3. По активному упоминанию фортрана и "того времени" я полагаю, что Вы еще на 386 это писали. Но не надо сравнивать свой опыт использования R в 2004-м году с нынешней парадигмой. Все совсем иное.
И как можно закрыть вопрос безапеляционными утвержениями, что в R все работает через копии, если и окружения работают по ссылкам и весь пакетdata.tableработает по ссылкам? То, что Вы его не упоминаете и игнорируете как раз и показывает, что познания в R откровенно слабы.
4. Чем Вам сдались F-ordering и C-ordering? Это всё протуберанцы фортрана. Ну вот правда? Кто из читателей вообще в курсе этих штук? Какая разница как матрицы индексируются? Кэширование и все такое -- тонкая материя, время теряют далеко не там. Тем более, что Вы можете сами указать порядок свертки, а в памяти они все равно живут одномерным куском, меняются атрибуты и формула адресации через индекс.
5. А что мне остается думать, когда Вы раз за разом пеняете на те вещи, которые либо давно неактуальны, либо вообще непрозрачно сформулированы, либо противоречат реальным фактам (поглядите бенчмарки в конце)? Басни Крылова вспоминаются, это что, запрещено?
Горьковский радиофак -- это знаковое место. Но сдается, что мне найдется что паритетно ответить на многие вещи из Вашего профиля.
i_shutov Автор
09.06.2022 10:45Интересно, но ничего не понятно!
Вы знаете как считаются квантили и ранги? И всякая непараметрическая статистика как устроена?0xd34df00d
09.06.2022 16:22+1Интересно, но ничего не понятно!
Тут была какая-то шутка то ли про уровень программистов на R, то ли про уровень датасайентистов.
Если код делает, условно,
sort(someArray); return someArray[computeIndex()];где
computeIndexне зависит от относительного порядка элементов вsomeArray, то ежу понятно, что это существенно неоптимальный код, причём асимптотически неоптимальный — там вылезает лишний логарифм. Понимать, что код делает, не обязательно, это чисто синтаксическое наблюдение.Вы знаете как считаются квантили и ранги? И всякая непараметрическая статистика как устроена?
Да, знаю. Это было частью моей практически ежедневной работы, пока я не свалил из машинного обучения. И частью моего образования тоже было.
N-Cube
09.06.2022 17:07Это еще цветочки. В R еще и на месте сортировку выполнить нельзя, то есть необходимо передать копию данных в функцию сортировки, которая вернет такой же по размеру упорядоченный результат, итого мы уже имеем две избыточные копии данных (и необходимость их удаления в дальнейшем). Так что экземпляры одних и тех же данных тут множатся, как кролики, сжирая уйму памяти. И да, хотя нам нужен на самом деле только поиск значения, в R реализации использование сортировки означает поиск и перестановку данных. Итого, имеем два избыточных экземпляра данных, один из которых активно модифицируемый, вместо необходимого и достаточного единственного не модифицируемого исходного экземпляра данных. Ясно, что в итоге и потребление памяти растет кратно, и время обработки, причем еще и нелинейно от объема данных.
i_shutov Автор
09.06.2022 17:18+1Голый base R — да.
Надо использовать
data.table. Он уж лет 14-15 существует. Все что Вы написали к нему неприменимо, там работа по указателям. Просто Вы не совсем ознакомились с матчастью.

muxa_ru
08.06.2022 14:15+4Почитал статью. Почитал обсуждение.
Сделал для себя вывод, что для анализа статистики и разной механизации, мне по прежнему хватает php и немножечко javascript :)
i_shutov Автор
08.06.2022 14:21+4Да вы просто гость из параллельной вселенной! Но здорово, что заглянули на кофеёк.
MentalSky
08.06.2022 15:24Сделал для себя вывод, что для анализа статистики и разной механизации, мне по прежнему хватает php и немножечко javascript :)
Как сделавший когда-то многое с помощью php - поддержу, что можно и на этом стеке, но на R/python все же быстрее и удобнее )
i_shutov Автор
08.06.2022 15:27+1Доводилось один раз видеть код аналитики, написанной на php, и разбираться в его логике работы. Хотелось бы развидеть.
MentalSky
08.06.2022 15:45Доводилось один раз видеть код аналитики, написанной на php, и разбираться в его логике работы. Хотелось бы развидеть.
как говорится - из буханки хлеба и вилки можно сделать троллейбус, но зачем?
i_shutov Автор
09.06.2022 10:48это философский вопрос.
система была кем-то ранее построена и с этим артефактом надо было что-то делать.
muxa_ru
08.06.2022 23:13Самый короткий путь и самый эффективный инструмент - не которые знаешь :)
i_shutov Автор
09.06.2022 10:50Можно всю жизнь использовать неэффективные методы и думать, что это верх возможностей. А человечество за это время придумало кратно превышающие методы.
Весь ИТР этим и занимается.muxa_ru
09.06.2022 14:10и думать, что это верх возможностей.
Ну так не думайте про мифический "верх возможностей", и проблем не будет.
Идеи про "верх возможностей" выдуманы продавцами, а в реальности их нет.
В реальности есть решаемые задачи и целесообразность использования инструментов.

kmatveev
08.06.2022 14:47+4Я не знаю питон совсем, и верю автору, что R лучше для обработки таблиц. Но в восхвалении R автора периодически заносит.
Что представляет собой
data.frameв классическом Computer Science? Это список указателей на массивы. Массивы — это колонки. Так было на ассемблере, так было на С/С++, Паскале и т.дкакой "классический Computer Science" имеет тут в виду автор - я не знаю, думаю, просто выпендривается. С и Паскаль содержат такие типы данных как структуры/записи, и таблицы реализуются массивом структур. Это одинаково компактно по памяти по сравнению с колоночным хранением.
Механизм NSE (Non-Standard Evaluation) вкупе с пайпами позволяет упомянуть имя датафрейма только в первой строчке и больше его не использовать
NSE - жуткая штука, работает магически, отлаживать её страшно. Но я соглашусь с тем, что компактный язык запросов в функциональном языке можно сделать только макросами или специальным парсером.
i_shutov Автор
08.06.2022 14:52-3Computer Science: https://en.wikipedia.org/wiki/Computer_science. Кстати, многие западные курсы имеют аббревиатуры CS-XXX, оно отсюда проистекает.
Почитайте по ссылкам про структуру pandas, про BlockManager, полистайте внутреннее представление сами. Про R объекты можете почитать в картинках здесь: https://www.brodieg.com/2019/02/18/an-unofficial-reference-for-internal-inspect/
NSE отличная штука. Как только поймете иерархию окружений (по сути аналог стека вызовов) и про отложенное разыменование все встает на свои места. Во тнеплохие статьи:
- https://milesmcbain.xyz/the-roots-of-quotation/
- https://www.brodieg.com/2020/08/11/quosures/Хотите сами во всем разобраться -- спускайтесь в ассемблер. Как Даниэль делает, например, здесь: https://lemire.me/blog/2021/10/09/for-software-performance-can-you-always-trust-inlining/

speshuric
08.06.2022 15:35+8Не встревая в спор R vs Python, замечу, что если ЯП А в нише сильно популярнее ЯП Б в той же нише, а вы считаете, что первый сильно лучше, то тут есть как минимум 3 варианта: 1) вы ошибаетесь в том, что ЯП А лучше, 2) вы ошибаетесь, что ЯП А лучше в этой нише или в том, как вы видите нишу, 3) в этой нише выбор ЯП вторичен по сравнению с какими-то другими факторами.
В индустрии постоянно есть очень странные популярные технологии. Ну вот, например, VB/VBA/VBS - в 2001-2003 годах это был язык популярнее нынешнего Python. Даже тогда было сложно придумать язык программирования более ущербный, чем VB. Но интеграция в Windows, Office и IIS вместе с низким порогом вхождения, возможность использовать COM/OLE и куча готовых примеров работали на VB. И таких примеров можно привести десятки - где-то сыграли накопленные наработки (как в Fortran году к 1998), где-то низкий порог входа (VB, PHP старых версий), где-то удачное стечение локальных маркетинговых обстоятельств (как в РФ с 1С в учёте), где-то удачный инструментарий, где-то преподавание в ВУЗах на этом ЯП, где-то еще какие-то факторы.
Если вы хотите сделать R более популярным, чем Python, и считаете, что он лучше подходит, то ищите не те места, где он сильнее, а где слабее и смотрите, как его усилить.
i_shutov Автор
08.06.2022 15:41+5Все логично. Я вот вижу основную слабость в недостоточном информационном поле. Многие даже не в курсе, что существует что-то кроме питона. И эта публикация как раз и дает ответ в этом канале -- да есть и да, по ряду параметров лучше.
speshuric
08.06.2022 15:55+1Я бы предложил не отмахиваться только "слабым информационным полем". Всё-таки, например в SQL Server, например, R пришёл раньше Python.
В любом случае - спасибо за статью.
i_shutov Автор
08.06.2022 16:00Да, Microsoft прикупил RevolutionAnalytics и встроил в SQL. Но для DBA это не сильно важно, а обычные аналитики даже PowerPivot не изучают. Поэтому это неплохой тезис, но не у нас.
Kanut
08.06.2022 16:04Да почему же. Люди вполне себе в курсе что существует что-то кроме питона. Вот только мало кто хочет переучиваться, менять существующие процессы, переписывать всю кодовую базу и так далее и тому подобное.
То есть не видят они смысла заваривать кашу ради "по ряду параметров лучше"....
i_shutov Автор
08.06.2022 16:10Мало кто хочет, согласен.
Но, с другой стороны, есть масса внешних факторов, которые почти ежедневно требуют изучения нового, перестройки, изменений. Нет теперь такой стабильности, что после школы пошел на завод и там проработал до пенсии. Так что, как в небезызвестной игре ["Перестройка"](https://www.youtube.com/watch?v=7uDrgNkQu14) наступает момент, когда надо прыгать.Kanut
08.06.2022 16:17Но, с другой стороны, есть масса внешних факторов, которые почти ежедневно требуют изучения нового, перестройки, изменений.
Угу. Вот только если человек скажем двадцать лет работал в куче разных фирм и везде был питон, то вы вряд ли его убедите что ему надо срочно учить что-то другое.
И самое главное если у вас есть фирма, в которой всё на питоне, то попробуйте убедите начальство что надо срочно всё менять и переучивать весь персонал.
наступает момент, когда надо прыгать.
Ну так вот если он действительно наступит, то есть если питон по какой-то причине в принципе больше не будет вариантом, то люди начнут искать альтернативы.
А пока просто есть ситуация когда какая-то альтернатива "лучше по ряду параметров", то из-за этого никто особо дёргаться не будет.
i_shutov Автор
08.06.2022 16:34Не существует только 1 и 0. Все время смешанные состояния.
Касательно больших контор - там вообще есть все и на всех языках. А еще есть конкурирующие внутренние подразделения :)Kanut
08.06.2022 17:23Ну тогда ваш оппонент тем более прав. И вы что-то не видите. Потому что иначе давно бы уже питон вытеснили.
i_shutov Автор
08.06.2022 17:29В природе вообще все описывается колебательными процессами.
При низкой добротности все может за один цикл затухнуть экспоненциально. При высокой -- будет перекачка энергий.
https://studme.org/412961/meditsina/lisy_zaytsami_zhivut
Но все это не имеет ни малейшего отношения к исходной теме. Описаны недостатки питона, Вы можете сами все воспроизвести и проверить.
SirEdvin
08.06.2022 18:10+8Основная слабость этой публикации - манипуляция.
> ООП и DS плохо совместимы
Этот раздел причем к python? Сам по себе язык мультипарадигменный, а numpy убирает затраты памяти на дополнительную адресацию примитивных типов
> Недостаточность базовых типов данных
А есть прям существенная разница между built-in data-type и built-in library в этом случае? И опять же, numpy
> Векторизация
numpy
> Pandas
Пандас не для тех, кому нужна скорость работы, он для тех, кому нужна прототипизация. А тот вариант, который используется при скорости работы вы откинули. Ну да.
> Отсутствие полноценной конвейерной обработки (pipe)
Нечитаемость чего-то это субьетивщина. Я вот R считаю нечитаемым, потому что практически не имею с ним дело (как и вы с Python, похоже)
> Производительность
> Про практическую непригодность pandas для данных чуть больше небольших давно известно но старательно умалчивается.
> Про Dask, polars,… не говорим — это другая весовая категория и на подобные решения найдется масса альтернативных нейтральных ответов. Тот же Clickhouse.
А почему polars то внезапно out-of-scope? Сам по себе polars может быть практически drop-in заменой pandas
> Бенчмарки
Пакет для R нашли, а поискать подходящий пакет для python - это не судьба.
> Заключение
Вся статья - полная профанация. Реальное преимущество можно было бы показать, если бы вы сфокусировались на "standart r" и "standart python", но это в целом никого не интересует
i_shutov Автор
08.06.2022 18:17-4питон изначально объекто ориентированный, он так проектировался. почитайте базовые типы. Все есть объект, народ это постоянно разжевывает, например: https://www.pythonmorsels.com/everything-is-an-object/
почитайте про пайпы по приведенным сслыкам. перенос по точке в питоне -- это просто костыль через форматирование.
разница между базовыми типами и суррогатами огромная. почитайте ссылки про missing data, например
в R и прототипирование и скорость и компактность можно получить одним махом в
data.tableприведите аналогичный пакет для бенчмарка -- это будет ответ.
Polars -- слизан с `apache arrow` который сам по себе хорош и универсален. И он не может заменить пандас целиком.
SirEdvin
08.06.2022 18:30+1Да, и для решения этой проблемы у вас есть numpy. Или массив с методами это тоже катастрофа?
Я читал про пайпы, я знаю про пайпы, я использовал пайпы в linux. Да, они удобные, да с форматированем выглядит не так классно. Но это субьетивная оценка про "нечитаемость". Нечитаемость чего-то всегда субьективна.
Опять же, для аналитики в рамках numpy это решено, нет?
Это аргумент для "standart R"
Хороший вопрос, надо будет найти. Я то не из DS
Так-то он не слизан, а "обертка". И почему он не может pandas заменить? Я не эксперт, но беглым взглядом вроде почти все есть. Часть можно дописать через стандартные функции
питон изначально объекто ориентированный, он так проектировался. почитайте базовые типы. Все есть объект, народ это постоянно разжевывает, например: https://www.pythonmorsels.com/everything-is-an-object/
питон изначально объекто ориентированный, он так проектировался. почитайте базовые типы. Все есть объект, народ это постоянно разжевывает, например: https://www.pythonmorsels.com/everything-is-an-object/
i_shutov Автор
08.06.2022 18:38Питон отличный язык, тут нет вопросов. Но вот применительно к DS задачам -- масса неудобств. Они реально неудобства, но пока в детали не погрузишься, все кажется простым и надуманным.
Мне, правда, не хочется ни оставлять серьезные вопросы без ответа, ни разводить холивар. Очень-очень много специфики выплывает на микроуровне.
А бесконечная сумма малых величин дает значимый дефект. Приходите в группу в телеграм, если интересно. DS аналитики действительно другими вопросами и категориями мыслят.SirEdvin
08.06.2022 19:08+2Опять же, я не спорю с этим фактом. Вполне логично ожидать, что язык, который разрабатывался для задач аналитики, будет для них удобнее.
Но мне показалось, что статье немного не про это. Ведь если писать про это, то сразу возникает вопрос "ага, а для чего тогда R менее удобен", ответ на который, скорее всего, вернет нас к тому, что проблема не в информировании.
AlexSbb
08.06.2022 16:31+2Из личного опыта. В R я вляпался поле Python потому, что новые коллеги пишут на нем. Было больно, но через полгода я акклиматизировался. Сейчас мне очень нравится связка tideverse + ggplot для анализа данных. Но, в то же время, чтобы обучить нейросеть, первый пункт это - установить библиотеку, чтобы вызывать Python! Не костыль, а прямо-таки забор!
i_shutov Автор
08.06.2022 16:32Не знаю о какой именно нейросети идет речь, но в R нынче подвезено почти все и многое нативно.
Еще такая штука есть: https://www.tidymodels.org/
И черезreticulatepython код сосуществует вперемешку с R-овским в одном ноутбукеAlexSbb
08.06.2022 17:00+1Вот он, reticulate, мне и не нравится совсем. По факту, вся работа с tensorflow идет через него и через Python. А tidymodels просто делает это удобным https://www.tidymodels.org/learn/models/parsnip-nnet/. Вот тут https://torch.mlverse.org/ люди портируют PyTorch под R без Python-а в середине, но им еще много работать...
MentalSky
08.06.2022 17:03+1люди портируют PyTorch под R без Python-а в середине
делают интерфейс в R для libtorch, с ней же и PyTorch работает

karon
08.06.2022 16:39+3Если еще важный момент. Как быстро и дорого заменить человека на питоне и на R? И это во многом является решающим фактором.
i_shutov Автор
08.06.2022 16:41из практики 1-1.5 мес достаточно для уверенного старта.
karon
08.06.2022 17:52+3Это джун. Актуальны спецы уровнем минимум пару лет. Сколько таких на рынке? Какая у них ЗП. За сколько найдется спец? Если переучивать, Какая вероятность, что кто то захочет переучиваться. Сколько других вакансий на R. Смотрите более масштабно.
i_shutov Автор
08.06.2022 17:58-3Давайте не переходить рубикон и не переходить на личности. Начинают сыпаться вопросы министерского уровня, если не выше.
karon
08.06.2022 19:13+3Это ни в коем случае не оскорбления. Это прямые вопросы, которые должен учитывать лид\продакт при старте проекта. Отсюда и проблема, что выбирают не всегда лучшее техничесское решение. А наиболее удобное и дешевое решение в поддержке.
i_shutov Автор
08.06.2022 19:32Много лет играю в тендеры всякие. В зависимости от матрицы приоритетов и методики оценки и рисков в т.ч. возможна любая степень вариативности результата.
Но вопросы применительно к проектной активности важные. Но именно здесь я сфокусировался на технике, оценочная часть в 90% случаев оставляет сильный осадок субъективности. Это не только про ЯП и даже далеко не про них.
Не хотелось сейчас туда залезать, да и предпосылок нет.

dimnsk
08.06.2022 16:53может просто потому, что низкий барьер входа в Python? мм ?
далее популярность растет...
PS крещение Руси помните?i_shutov Автор
08.06.2022 16:55нет низкого порога, он везде одинаков и минимально таков:
- изучение базовых типов;
- изучение конструкций языка;
- изучение типовых операций и подходов для решаемых задач.
если и из этого сделать "брифли", то ценность такого специалиста вызывает большие сомнения.dimnsk
08.06.2022 16:58ну ок. А популярность откуда?
Hidden text
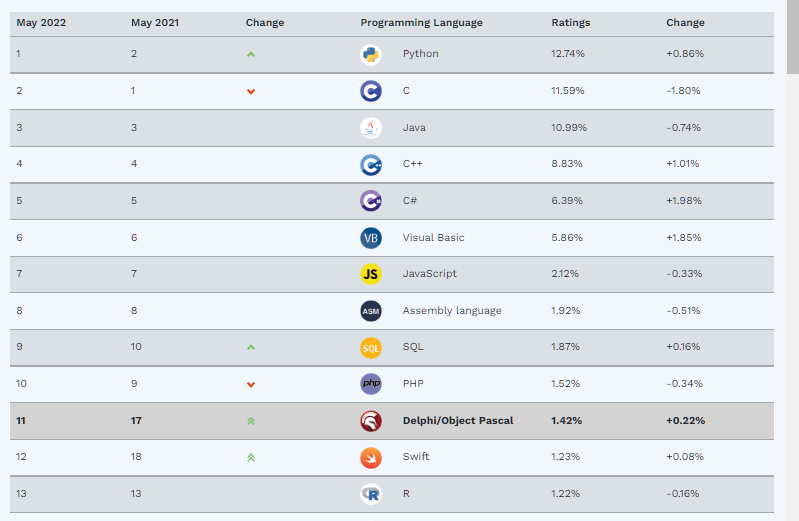
i_shutov Автор
08.06.2022 17:26Ну Вы вопросы задаете...
Это ж кого спрашивать и как считать.
И питон надо разделять. Отдельно для DS страту вытягивать.
dimnsk
08.06.2022 17:47+2А зачем выделять страту DS, это же не сферический конь в вакууме?
i_shutov Автор
08.06.2022 17:56Я постарался в тексте дать все комментарии. Еще там есть масса ссылок на тесты и публикации. Можете прочесть, если действительно интересно.
Мне неясен смысл Ваших вопросов и они сильно удаляются от исходного текста. Вы не согласны -- это очевидно. С чем и почему -- развожу руками.
i_shutov Автор
08.06.2022 17:40-1По приведенным в публикации фактам и тезисам у Вас вопросы есть?
А то задаете мне какие-то отстраненные вопросы как гуглу.



ratatosk
08.06.2022 18:36+11Люди, работающие с R, должны знать статистику, а люди, знающие статистику, должны знать, что то, чем вы занимаетесь в этой статье называется систематической ошибкой отбора.
Вы отобрали примеры, когда R лучше Python, проигнорировав случаи где все наоборот, и, никак не учли актуальность ваших примеров.
Приведу только один пример, который для меня является решающим в выборе R vs Python. 99% нейросетевого коммюнити использует Python, и, работая с R, исследователь оказывается в изоляции, не может использовать код из свежих (и не очень свежих) статей, и, имеет огромные проблемы при взаимодействии с коллегами.i_shutov Автор
08.06.2022 18:46+1Вовсе нет.
Я же писал в ответах, что в рамках одного ноутбука можно запускать куски кода и на R и на SQL и на python. Ставится питон (желательно чистый, без анаконд), ставятся черезpipпакеты и пишется микс без проблем, если надо.
Правда, нет никаких проблем. Нет ИЛИ, есть И.
И Apache Arrow как средство межплатформенного обмена.
А в тексте фокус на самых базовых вещах, фундаменте любых преобразований.


lea
08.06.2022 19:03Как-то странно сравнивать специализированный язык (R) с языком общего назначения (Python).
Есть набор датасетов, который вполне может быть размером 50-80% RAM.
Применительно же к простым прямоугольным данным введение прослойки в ООП на ровном месте увеличивает накладные расходы на CPU и RAM, иногда до неприемлемых масштабов.
Память дешевая, а время дорогое. Оверхэд ООП незаметен на фоне того, сколько памяти сжирается при распараллеливании вычислений путем запуска нескольких экземпляров интерпретатора R.
В R все прекрасно. С версии 4.1 даже есть нативный пайп |>, встроенный в синтаксис языка. Но давно существующий пакет magrittr обладает широким спектром различных пайпов и позволяет очень элегантно и компактно проводить сложные расчеты. Код при этом становится предельно понятным даже при беглом взгляде.
На мой взгляд, пайпы превращают R в write-only language. Пару раз доводилось срочно исправлять чужой код с пайпами (там и без них можно было голову сломать из-за сложности обработки), с тех пор заворачивал такое во время ревью.
i_shutov Автор
08.06.2022 19:07-1Заметно все, а про пандас почитайте по ссылкам. 10-ти кратное превышение требуемой памяти -- это жесть. И по тестам (опять же, ссылки), он почти никогда не доезжает до конца, падает.
Писать красивый код надо уметь. Пайпы здесь ни при чем.


Spiritschaser
08.06.2022 20:07IMHO как писали выше - дело в том, что python общего назначения + cython + c/c++. Ну и общее назначение вплоть до всякой дичи через win32com. Ну и не понятно, почему всякие прибамбасы типа dask не учитываются.
i_shutov Автор
09.06.2022 10:53dask -- переход в параллельные вычисления. для этого неплохо сначала с азами разобраться и понимать специфику вопроса распределенки.
и в R с этим тоже все прекрасно, но будет подтягиваться тяжелая артиллерия, соответствующая dask

Helltraitor
08.06.2022 20:32+2А почему он, а не я?
Суть статьи в одном предложении. Если выбрали Python, тогда, просто возможно, людям так удобнее?
ynikitenko
08.06.2022 20:47Анализ данных в Питоне - это далеко не только pandas. Лично я ей не пользуюсь.
Согласен, что ФП гораздо ближе к анализу данных, чем ООП. Хотя объекты со многими атрибутами удобны для объединения данных (собственно, точка - это когда 3 числа, а не 3 элемента разных векторов).
Питон просто очень удобный и гибкий язык. ФП и ООП, а также обычное императивное программирование (да, есть языки, где с ним сложновато) в нём представлены.
Я ранее писал про свой фреймворк для анализа данных на Питоне, если интересно: https://habr.com/ru/post/490518/ Он использует ленивые вычисления, может работать в PyPy (в этом смысле оптимизирован) и более высокоуровневый, чем С++ (но если нужна не гибкость, а скорость, то я пишу на С++ также).


yokotoka
09.06.2022 15:53+1Как кто-то метко пошутил: "Python - лучший язык №2 для чего угодно".
Что на практике выливается в то, что владея R - ты великолепный статист, но владея Python - ты чуть менее великолепный статист, но при этом ещё и программист общего назначения. Что лучше сказывается на зарплате и карьерных перспективах. Нишевые языки всегда будут лучше Python'а в своих нишах. Но змей от того и толстый, что подъедает за всеми ними недоеденное.


kaza4ka
09.06.2022 19:46О, неоднократно ломалась на повторных именах фрейма и индексах, тут люто плюсую, спасибо автору, что показали питон трезвого человека
starik-2005
Предположу, что если бы всех учили на R, то на Хабре рано или поздно появилась бы статья с таким текстом:
i_shutov Автор
Зачем создавать виртуальные миры и заниматься абстрактной комбинаторикой? Смотрите на состояние "здесь и сейчас", работайте с фактами.
На случай беспокойства братья Гримм даже сказку написали: https://www.grimmstories.com/ru/grimm_skazki/umnaja_elza
starik-2005
А факты в большинстве своем указывают лишь на то, что закончившие учебные программы "специалисты" достаточно слабо представляют предметную область - что уже "что-то". А слабо что-либо представляя, достаточно сложно добиться того, чтобы код на чем угодно работал быстро, был понятен, прост и красив. И тут не важно, R это будет, Pyton или C++, на котором уж точно можно написать быстрее, но вряд ли проще и красивее. А все, что можно написать на C++, можно воткнуть и в питон.
Да, наверное стоит согласиться, что многое в Python тащится отовсюду, где оно уже есть. Но чем это плохо? Возможно, стоит обратить внимание на то, что есть где-то в части аналитики данных, чего нет в Python. Это было бы полезно на мой взгляд.
muxa_ru
Что-то мне подсказывает, что именно так и думал тот "Кто за всех решил, что python удобен для «гражданской» аналитики".
Зачем создавать виртуальные миры с векторизацией, типами данных и ООП, когда можно здесь и сейчас использовать питон.
i_shutov Автор
Мысль непонятна. Вы знали, что R и Python почти погодки?
muxa_ru
Речь об иронии ситуации.
@starik-2005 рассматривает ситуацию "а что было бы, если бы было по другому"
Вы говорите, что не стоит создавать виртуального мира и надо жить с теми фактами которые есть.
При этом, Ваша статья как раз о том, что было бы если бы было по другому, и Вы создаёте виртуальный мир.
Что характерно, и его виртуальны мир и Ваш, это один и тот же виртуальный мир, в котором вмеcто Python доминирует R
Это не важно.
Ответ на вопрос "Кто за всех решил, что python удобен для «гражданской» аналитики?" не сильно зависит от самого возраста продукта.
Если смотреть на историю техники, то важна готовность аудитории и наличие тех кто будет на этой аудитории зарабатывать.
Прямо сейчас, юный падаван попадающий в айти видит:
- кучу ГОТОВЫХ примеров использования
- кучу людей РАССКАЗЫВАЮЩИХ о том какие они успешные
- кучу ПРЕДЛОЖЕНИЙ (как реальных, так и полного фуфла) научить его питону
Поэтому, полный и исчерпывающий ответ на Ваш вопрос: "Так сложилось исторически"
Хотите изменить ситуацию?
Ну, тогда создайте информационное давление на аудиторию, с рассказами какой полезный этот R , раскидайте примеры кода, создайте ажиотаж и убедите обучаторов ввести курсы по R.
Если будете настойчивым и целеустремлённым, то через 15 ситуация может измениться в нужную Вам сторону.
i_shutov Автор
Спасибо за ценные советы. Записал в блокнотик.
DaneSoul
Но с ростом популярности Python падала популярность R.
ИМХО, основная причина в том, что R — это очень специфический язык с узкой сферой применения. Python же универсален, решения на нем можно легко интегрировать в другие продукты. Соответственно изучать Python разработчику выгодней, так как он может применять его для разных задач.
i_shutov Автор
В этом рассуждении есть одна большая ошибка. Сила не в языках, а в библиотеках, алгоритмах и навыках. Есть прекрасная книга на эту тему: https://habr.com/ru/company/productivity_inside/blog/348116/
R позволяет решать практически все те же самые задачи, что и питон. Это тоже язык универсального назначения. В сети масса различных примеров есть.
DaneSoul
Это не чьи-то сторонние фантазии, а строки описания языка на его официальном сайте.
i_shutov Автор
Так про питон можно на основании сайта сказать, что ему в DS делать нечего. Тоже с сайта официального: Python is a programming language that lets you work quickly and integrate systems more effectively.
В чем Вы хотите убедить?
CrocodileRed
Очень странный вопрос из уст человека, размышляющего об околоматематической дисциплине :-)
i_shutov Автор
Если несложно, переформулируйте вопрос, если он тут вообще есть.
В этом потоке вовсе неочевидно понять что Вы хотели сказать.
CrocodileRed
Я хотел сказать, что умение мыслить абстрактно, а не здесь и сейчас, очень выгодно отличает человека от остального животного мира. И если вы отказываетесь от этих упражнений, ценность ваших умозаключений для меня лично сомнительна.
Надеюсь, сейчас я понятно написал ))
i_shutov Автор
Да-да, подозревал, но не хотел так думать.
В целом, весь поток обсуждений вместо техники сваливается на личности и завуалированные оскорбления. Причем мы на брудершафт не пили.
Каждый раз на хабре одно и то же.
И даже уже раздражать перестало, неизбежный шлейф.
"Ну вот... опять поехало..."
Но комментаторы могут подумать, как именно они себя выставляют?
Про какие умозаключения Вы ведете речь -- тоже неведомо. Берете консоль и запускаете код и повторяете результаты. Берете статьи и книги по ссылкам (между прочим, уважаемые люди писали) и читаете. Берете код на гитхабе и разбираетесь в нем.
CrocodileRed
Вы совершенно напрасно считаете что я хотел вас как-то задеть -- это не так. Если же мои слова вас каким-то образом оскорбили, прошу извинить.
i_shutov Автор
Ценность моих "умозаключений" в том, что все подкреплено материалами, ссылками и тестами различных, очень уважаемых людей.
Многие тезисы можно проверить и измерить самостоятельно и сделать свое собственное заключение на основании полученных результатов.
Ничего не надо принимать на веру.