Это история о том, как я писал код на Python 3, который собирает и систематизирует данные по избирательным комиссиям в моём родном городе Санкт-Петербурге. Ну, и про то, что я там накопал в извлечённых данных.
Интродукция
С 2018 года я работаю в разных качествах в избирательных комиссиях от одной из наблюдательский организация Санкт-Петербурга. Вношу свой посильный вклад в построение гражданского общества, так скажем. И да, может с учётом контекста сегодняшнего времени, не очень я вовремя с этой статьёй, ну а что поделать.
Интерес к тому, чтобы систематизировать данные по избирательным комиссиям появился у меня в тот момент, когда я участвовал в выборах 2021 года в качестве ЧПРГ ТИК№31. Учиться программировать я стал относительно недавно, 2 месяца в относительно ленивом темпе (на момент начала июня 2022).
3 июня я приступил к работе и начал осуществлять свою давнюю задумку.
S'il vous plait - хронология.
Глава 1. Сбор данных
Сайт, с которого я собирал данные выглядит так.
Слева структура комиссий в открывающихся списках. Честно говоря, я пока что понятия не имею, как устроена веб-страница на практике, но заметил, что если открывать разные комиссии, то сайт остаётся один и тот же, меняется только длинный номер в конце адреса. Я попробовал понять, есть ли какая-нибудь связь между номером комиссии и её номером в адресной строке, но быстро понял, что никакой генеральной закономерности там нет, хоть фрагментами и можно так подумать.
Переписывать ссылки вручную - дело долгое и неблагодарное, поэтому полез в веб-инспектор сафари. Полу-наугад стал там искать, где есть ссылки, на которые ведут номера комиссий. Сначала копался в ресурсах и увидел, что если раскрыть список - появляется файл st-petersburg, в котором перечислены несколько айдишников. Уже неплохо, но всё ещё многовато действий.

Продолжил поиски и во вкладке Аудит нашёл то, что искал, как на ладони (Result Data -> data-domAttributes. Для того, чтобы там появилось всё, что мне надо, пришлось вручную пооткрывать все списки, но это не заняло много времени.

Экспорт был в файл с расширением json. Я что-то об этом слышал, поэтому решил не разбираться (может быть слишком долго), а просто скопировал из окошка строки с айдишниками в обычный текстовый файл.
Также с сайта втупую выделил и скопировал список комиссий в текстовый файл, они там в таком же порядке, как и их айди на картинке, поэтому можно будет составить словарь или типа того.
Глава 2. Очистка данных
Эффективнее было бы очистить числа от html-мусора в любом текстовом редакторе, но это неспортивно, я ж в конце концов программировать учусь, а не текстовым редактором пользоваться.
Немного освежил память, как там обращаться к файлам и написал незамысловатый код для очистки:
out_string_indexes = ''
file_name = 'Indexes List.txt'
with open(file_name, mode='r') as file:
for line in file:
if '<' in line: #это чтоб отфильтровать нужные строки, они
# там странновато скопировались
out_string_indexes += line.split('id=')[1].split('"')[1]
out_string_indexes += '\n'
file_name = 'indexes_processed.txt'
with open(file_name, mode='w') as file:
file.write(out_string_indexes)
Затем проверил, ничего ли не потерялось:
file_name = 'indexes_processed.txt'
with open(file_name, mode='r') as file:
i = 0
for line in file:
i += 1
print('There are {} indexes'.format(i))
file_name = 'commissions_list.txt'
with open(file_name, mode='r') as file:
i = 0
for line in file:
i += 1
print('There are {} commissions in the list’.format(i))Всё оказалось хорошо, выдало по 2017 и тех и других.
Нашёл в интернете вот это, для тех, что проникся дзеном пайтона
sum(1 for line in open('file', ‘r’))Но я ещё не проникся настолько, побаиваюсь вообще таких функций. Мне лучше для начала понятно и надёжно (как Tegridy farms(r))
Глава 3. Общение с вебсайтом
С такой проблемой я ещё не сталкивался, поэтому стал читать, как вообще обратиться к вебсайту. Спустя пару минут выяснил, что с помощью urllib.request. Открыл, сразу же столкнулся с такой проблемой:
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)>
Догадался скопировать ошибку в гугл и быстро нашёл, что нужно в папке пайтона тыкнуть на установку сертификата. Попробовал подсоединиться снова, получил вот это:
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
Упс, кажется, мне тут не рады. А ещё похоже, что он меня по айпи забанил, потому что и через браузер перестал входить, а через терминал пингуется нормально. (апд: потом разбанил через сутки)
Ничего страшного, раздал интернет с телефона. Там, если я что-то в чём-то понимаю, айпи присваивается динамически при подключении, и такая блокировка не сработает, если переподключаться. В интернете я быстро вычитал, что к запросу надо добавить хедер, типа имитировать, что я с браузера захожу.
Если что, у меня ОЧЕНЬ поверхностные знания обо всём этом.
from urllib.request import Request, urlopen
req = Request('http://www.st-petersburg.vybory.izbirkom.ru/region/st-petersburg?action=ik&vrn=27820001006425',
headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req).read()
result = webpage.decode('utf-8', 'ignore')
print(result)На этот раз получилось, но получилось всё ещё не то. Если я правильно понял, то страница-то загрузилась, но не выполнился скрипт, который подгружает на страницу все нужные мне данные.
Разумеется, я не единственный, кто с этой проблемой столкнулся, поэтому вновь углубился в чтение. За это время моим любимым сайтом стал Stack Overflow.
Собственно, загрузив нужный модуль requests_html, которых там почему-то сразу загрузилась целая гирлянда, я написал это, и оно наконец сработало! Лёд тронулся, господа присяжные.
from requests_html import HTMLSession
session = HTMLSession()
url = 'http://www.st-petersburg.vybory.izbirkom.ru/region/st-petersburg?action=ik&vrn=4784001269007'
r = session.get(url, headers={'User-Agent': 'Mozilla/5.0'})
r.html.render
result = r.text.encode('utf-8')
result = result.decode('utf-8')
print(result)Кодировать и раскодировать пришлось по той причине, что вместо кириллицы он выдавал ерунду, а как ещё декодировать эту хрень - я не догадался, так что прошу прощения, если говнокод. Тем не менее, результата я достиг.

Дело осталось за малым: нужно теперь вытащить оттуда саму табличку и написать программу, которая прогонит этот алгоритм через все 2017 комиссий. Предварительно придумав, каким образом эти данные структурировать, чтобы потом можно было по ним всё что нужно искать.
Кстати, я тут подумал, может повытаскивать у них адреса и разметить на карте

Глава 4. Построение программы
Сначала я писал команды в императивном стиле, чтобы понять, что мне именно нужно и как этого достичь, затем уже распихал всё это по функциям и слепил из них мастер-функцию.
Если кратко описать, то отрезал страницу по начало таблицы, удалил все <штуки>, некоторые заменив на разделители, затем командой split сделал из получившейся строки массив, из которого дальше сделал двумерный массив. Приблизительно так:
def text_cleanup(txt=text):
# Обрезаю таблицу
start = txt.index('ФИО') #начало таблицы
txt = txt[start::]
start = txt.find('1') #начало первой нужной строки таблицы
txt = txt[start - 4::]
end = txt.index('</table') #конец таблицы
txt = txt[:end:]
#Удаляю следы html
txt = txt.replace('</tr>', '')
txt = txt.replace('<tr>', '...') #строки
txt = txt.replace('<td>', ',,,') #столбцы
txt = txt.replace('</td>', '')
txt = txt.replace('<nobr>', '')
txt = txt.replace('</nobr>', '')
txt = txt.replace('<br>', '')
txt = txt.replace('</br>', '')
txt = txt.replace('\r', '')
txt = txt.replace('\t', '')
txt = txt.replace('\n', '')
return txtДальше так
txt = text_cleanup()
result = txt.split(‘…’) #разбиваю текст по строкам
for i in range(len(result)): #разбиваю каждую строку на элементы
result[i] = result[i].split(',,,')
return result
И лёгким движением руки таблица с сайта превращается... превращается таблица с сайта... в двумерный массив.
Дальше я создал функцию, которая берёт веб-страницу через session.get и render, как я писал выше, прогоняет полученное через функцию очистки, записывает в текстовый файл или эксель, и всё это в цикле, который из списка подгружает айдишники, которые до этого были в него записаны из файла ещё одной функцией. Как писать в эксель - это я прочитал статью про модуль pyopenxl, мне очень понравилась там функция append, которую я и использовал в своей программе.
Короче, сущностно происходит следующее:
Из файлов выгружается в двумерный список названия комиссий и их айди
Циклом по очереди из этого списка читаются айди
Добавляются к постоянной части адреса, загружается код страницы
Очищается от мусора и преобразуется в двумерный список
Построчно вместе с номером комиссии записывается в файл
Код получился здоровый, поэтому публиковать не буду, основные его элементы и логику я в принципе описал. Итого 2 минуты код отработал как часы и на выходе получилась здоровенная таблица!


Тут я ненадолго остановлюсь и опишу свои ощущения:
Я хоть и продвинутый, но обычный юзер, поэтому когда вся эта штука сработала - я ощутил себя каким-то, блин, Нео. Вообще то, что я написал программу, которая сама в интернете ковыряется - это крайне странно. Ни разу не выходил в интернет не через браузер. Вот уж был действительно hello world!
И это пока что первая программа, которая выполняет что-то не абстрактное, а вполне конкретное. Собственно, испытываю гордость за себя:)
Глава 5. Анализ
В принципе, всю аналитику можно было бы сделать в экселе, но это неспортивно, я же программировать учусь. Какую-то сложную аналитику я производить не буду, меня интересуют довольно простые вещи. Гипотеза в том, что представителей крупных партий кроме Единой России непропорционально мало среди руководства комиссий, а может и в принципе среди всех членов комиссий.
Чтобы мой дорогой читатель не подумал, что я сразу выдумал всю программу, сначала я написал код несколько меня интересующих случаев, но потом решил, что нужно более универсальное и гибкое решение.
Написал сначала функцию analysis(*args), которая делает вот что:
создаёт пустой словарь
считывает из текстового файла строку
ищет в ней слова из *args
если находит, проверяет, есть ли в словаре название партии
если есть - делает +=1, если нет - добавляет со значением 1
выдаёт в итоге общее количество найденных строк и словарь, в котором напротив названия партии указано количество человек
Так это выглядело на выходе, если не фильтровать (только без процентов сначала):

Фильтр работал нормально, но с таким результатом сделать что-то сложно. У меня возникли идеи: надо сделать отдельную функцию фильтр с аргументом, переключающим режимы И / ИЛИ, а также создать список основных партий и сверять с ним, потому что читать данный результат трудно. Можно ещё отметить, что Единая Россия внимательнее всех относится к тому, чтобы написать именно конкретное отделение своей партии.
В итоге следующая версия выглядела так:
parties_list - это список более крупных партий, который я выделил
def filter_keywords(line='', und=False, *args):
"""Returns True if arguments are in line.
Basically, und is and:
If und=True -> every argument must be in line,
If und=False -> at least one argument must be in line"""
if und:
for word in args:
if word.lower() not in line.lower():
return False
return True
else:
for word in args:
if word.lower() in line.lower():
return True
return False
def analysis(unite_minors=True, und=False, *args):
"""Returns vocabulary with parties and a number of members in it and overall quantity of members.
unite_minors collects every minor party/association to keyword 'Остальные'.
und is about filtering style 'and' or 'or', und is and in a nutshell.
args is keywords for filtering"""
result = {'Остальные': 0}
counter = 0
with open('master_table.txt', mode='r') as file:
for line in file:
if filter_keywords(line, und, *args):
party = line.split(' : ')[6]
if not unite_minors: #если не объединять партии, не входящие в список
if party in result:
result[party] += 1
else:
result[party] = 1
counter += 1
else: #если объединять партии, не входящие в список
for major_party in parties_list:
if filter_keywords(line, False, major_party):
if major_party in result:
result[major_party] += 1
else:
result[major_party] = 1
counter += 1
break
else: #если за цикл не нашлось совпадений
counter += 1
result['Остальные'] += 1
# сортировка словаря, скопировал из интернета дзен-функцию
# на этот раз было лень писать самому
result = dict(sorted(result.items(), key=lambda item: item[1], reverse=True))
return result, counter
Я решил отправить в return помимо словаря сколько всего строчек обработано. Для учёта и чтоб сразу проценты можно было высчитывать, хотя не знаю, насколько это целесообразно. Но если что - легко переделывается.

Так гораздо лучше, но спустя некоторое количество запросов я понял, что такая функция не позволяет мне узнать, например, кто выдвинул Председателя, Зама и Секретаря только в Территориальных комиссиях. Поэтому решил сделать новую, которая будет фильтровать отдельно по уровню комиссий и должностям. Она стала концептуально проще и принимает строки с ключевыми словами через пробел.
def filter_or(line, *args):
for word in args:
if word.lower() in line.lower():
return True
return False
def analysis2(level='', position='', unite_minors=True):
"""Returns vocabulary with parties and a number of members in it and overall quantity of members.
unite_minors collects every minor party/association to keyword 'Остальные'.
level is keywords for level filter, type with spaces between keywords!
position is keywords for position filter, type with spaces between keywords!"""
result = {'Остальные': 0}
counter = 0
level = level.split(' ')
position = position.split(' ')
with open('master_table.txt', mode='r') as file:
for line in file:
t_party = line.split(' : ')[6]
t_position = line.split(' : ')[5]
t_level = line.split(' : ')[0]
if filter_or(t_level, *level) and filter_or(t_position, *position):
if not unite_minors:
if t_party in result:
result[t_party] += 1
else:
result[t_party] = 1
counter += 1
else:
for major_party in parties_list:
if filter_or(t_party, major_party):
if major_party in result:
result[major_party] += 1
else:
result[major_party] = 1
counter += 1
break
else:
counter += 1
result['Остальные'] += 1
result = dict(sorted(result.items(), key=lambda item: item[1], reverse=True))
return result, counterНа этот раз я получил весь функционал, который хотел. И да, немного кода, который всё это выводит на консоль. А затем ещё и в графики вместе с модулем matplotlib.pyplot, о котором я только что прочитал.
voc, quantity = analysis2(level='спбик тик уик',
position='председатель зам секретарь член',
unite_minors=True)
print('****Всего {}****\n'.format(quantity))
for item in voc:
print('{} or {}% : {}'.format(voc[item],
round(voc[item] / quantity * 100, 1),
item))
values, keys = list(voc.values()), list(voc.keys())
plt.pie(values, labels=keys, autopct='%.1f%%') #так неочевидно процент выводится
plt.title('Винни-Пух и все, все, все')
plt.show()Глава 6. То, ради чего это всё задумывалось
Тут будут таблички и графики с минимальными комментариями.
Если есть желание понять субъект анализа, типа как эти все комиссии устроены и кто в них что делает, то лучше об этом почитать подробнее в любом разделе "Обучение" наблюдательский организаций или даже официальных порталов. А я опишу кратко:
УИК - участковая избирательная комиссия, обеспечивает выборы на местах непосредственно. Принимает всё что нужно для работы от ТИК, отчитывается туда же.
ТИК - территориальная избирательная комиссия, выполняет административно-хозяйственные функции, то есть, грубо говоря, материальная база и вопросы формирования, назначения/освобождения членов нижестоящих комиссий (разумеется через заявления).
Комиссия - коллегиальный орган, право голоса имеют все, вопросы решаются через голосование большинством. Кворум для открытия заседания в общем случае - больше половины.
Председатель - по сути спикер комиссии, должностное лицо
Секретарь - думаю, более-менее и так понятно
Поскольку у комиссий разного уровня сильно разные функции, то и обобщать их особого смысла я не вижу.
Для начала посмотрим, что мы имеем по Участковым избирательным комиссиям:
УИК, все


По месту работы - это по сути работники бюджетных организаций. По месту жительства в большинстве случаев тоже, ну или близкие к. Возможно среди них есть и просто активные жители, но очень сомневаюсь, что таких там хоть сколько-то много. Думаю, где-то описаны схемы набора таковых, да и догадаться несложно
Остальные - это представители многочисленных организаций, о которых в основном никто никогда и не слышал. Обычно около-административные. (Личная оценка)
Как видно, средняя комиссия наполовину состоит из этих трёх категорий, а партии распределены более-менее ровно с предпочтением к самым крупным.
Теперь посмотрим, а что там в руководстве УИКов.
УИК, Руководство (Председатель, Зам.Председателя и Секретарь)


Ой, а что это у нас тут случилось? Я думаю, что комментарии тут излишни, а изменения очевидны. Ради интереса можно посмотреть, кто такие эти трудовые партии, союзы труда и партия "За женщин России". У-ух!
Теперь посмотрим, что там по Территориальным комиссиям.
ТИК, Все члены


Да тут прям почти полноценный плюрализм, мамочки родные!
А теперь руководство ТИК:
Руководство ТИК

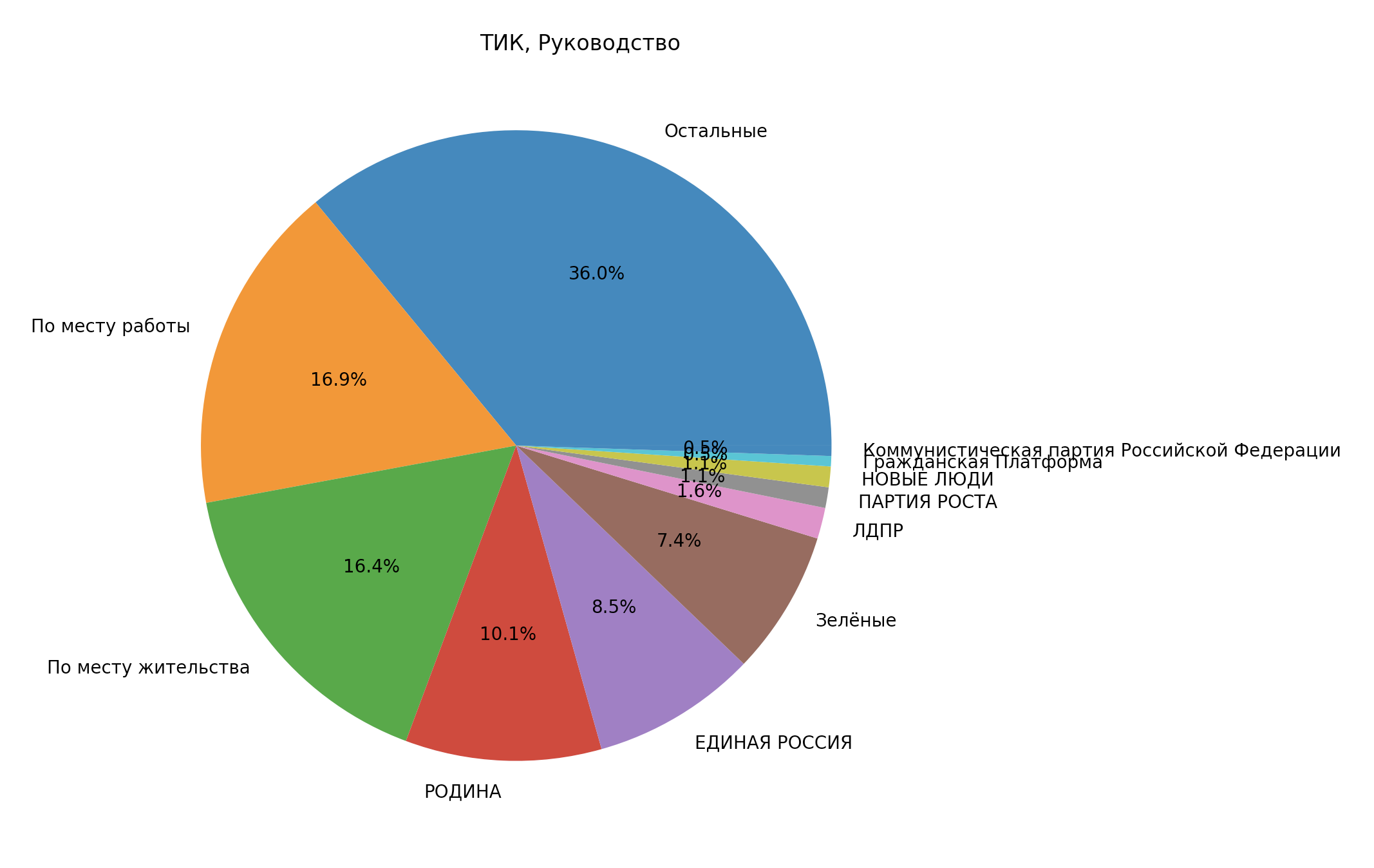
...Ну, что тут сказать можно, картинка достаточно красноречива
Очень большой сегмент “Остальные”, я бы посмотрел подробнее, кто у нас там.
voc, quantity = analysis2(level='тик',
position='председатель зам секретарь',
unite_minors=False)
print('****Всего {}****\n'.format(quantity))
for item in voc:
print('{} or {}% : {}'.format(voc[item],
round(voc[item] / quantity * 100, 1),
item))32 or 16.9% : собрание избирателей по месту работы
31 or 16.4% : собрание избирателей по месту жительства
29 or 15.3% : территориальная избирательная комиссия предыдущего состава
16 or 8.5% : Региональное отделение ВСЕРОССИЙСКОЙ ПОЛИТИЧЕСКОЙ ПАРТИИ "РОДИНА" в городе Санкт-Петербурге
16 or 8.5% : Санкт-Петербургское региональное отделение Всероссийской политической партии "ЕДИНАЯ РОССИЯ"
12 or 6.3% : представительный орган муниципального образования
11 or 5.8% : Региональное отделение в Санкт-Петербурге Политической партии "Российская экологическая партия "Зелёные"
6 or 3.2% : Санкт-Петербургское региональное отделение политической партии "ПАТРИОТЫ РОССИИ"
4 or 2.1% : Политическая партия "ПАТРИОТЫ РОССИИ"
3 or 1.6% : Региональная общественная организация поддержки и развития молодежного творчества "Гаудеамус"
3 or 1.6% : Санкт-Петербургское региональное отделение Политической партии ЛДПР - Либерально-демократической партии России
3 or 1.6% : ВСЕРОССИЙСКАЯ ПОЛИТИЧЕСКАЯ ПАРТИЯ "РОДИНА"
3 or 1.6% : Политическая партия "Российская экологическая партия "Зелёные"
2 or 1.1% : Межрегиональная общественная организация "Ассоциация ветеранов, инвалидов и пенсионеров"
2 or 1.1% : Региональное отделение в Санкт-Петербурге Всероссийской политической партии "ПАРТИЯ РОСТА"
2 or 1.1% : Региональная общественная организация поддержки и развития молодежного творчества "Гуадеамус"
2 or 1.1% : Региональное отделение в Санкт-Петербурге политической партии "НОВЫЕ ЛЮДИ"
1 or 0.5% : Межрегиональная общественная организация "Центр содействия реализации социальных инициатив "Живой Питер"
1 or 0.5% : Региональное отделение в городе Санкт-Петербурге Политической партии "Гражданская Платформа"
1 or 0.5% : Политическая партия "Российская экологическая партия "Зеленые"
1 or 0.5% : Санкт-Петербургская региональная общественная организация содействия детям сиротам "Радуга"
1 or 0.5% : САНКТ-ПЕТЕРБУРГСКОЕ ГОРОДСКОЕ ОТДЕЛЕНИЕ политической партии "КОММУНИСТИЧЕСКАЯ ПАРТИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ"
1 or 0.5% : Санкт-Петербургская Региональная Общественная Организация инвалидов "Радонежец"
1 or 0.5% : Местное отделение Санкт-Петербургской общественной организации ветеранов (пенсионеров, инвалидов) войны, труда, Вооруженных сил и правоохранительных органов "Кировское" на территории муниципального округа "Дачное"
1 or 0.5% : Региональная общественная организация инвалидов "Радонежец"
1 or 0.5% : Санкт-Петербургская Общественная Организация в поддержку молодежи "МИР МОЛОДЕЖИ"
1 or 0.5% : Санкт-Петербургская общественная организация "Жители блокадного Ленинграда"
1 or 0.5% : Политическая партия СОЦИАЛЬНОЙ ЗАЩИТЫ
1 or 0.5% : Санкт-Петербургская ассоциация общественных объединений родителей детей-инвалидов “ГАООРДИ"
Я подчеркнул тех, что вошёл как “Остальные”. И ещё заметил, что партия Зелёные вошла тоже туда, потому что для компьютера Е и Ë - разные символы. Надо будет учесть этот момент, хоть он принципиально ни на что и не влияет.
Конечно, я подтолкнул к мысли о том, что не так с этой системой. На самом деле не я, а данные, я их лишь обнажил.
Заключение
Мне очень понравилось, что спустя уже небольшое время я смог применить на практике то, чему научился. Я очень рад, если было хоть немного интересно это занудство читать, если статья открыла какое-то новое виденье, вдохновила, или повлияла ещё каким-то образом.
Открыт для любых дискуссий, пожеланий, советов, критики или чего там ещё.
Комментарии (39)

HemulGM
16.06.2022 19:34+7Для парсинга страниц html есть специальные инструменты для многих языков (в том числе и для питона). Они позволяют отправиться к нужной области и получать нужные значения. Ко всему будут корректно прочитаны спец символы.
Т.е. большую часть вашего кода можно было заменить парой циклов и вызовов.
Помимо этого, большую часть проблем с доступом к сайту и странице можно было решить эмулятором браузера (например, селениум)
В итоге алгоритм такой:
1. Подключаем нужные модули селениума
2. Переходим по странице и получаем её содержимое (включая то, что будет подгружено скриптами)
3. Скармливаем всю страницу парсеру
4. Переходим к нужной области указав актуальный xpath
5. Идём по циклу и забираем готовые значенияНа всё это, в худшем случае уйдёт около 40 строк

DocHannibal
17.06.2022 01:05Использовать эмуляторы браузеров такая себе идея для парсинга, только если api совсем никакого нет. Ибо это все очень долго.

danilkat
18.06.2022 22:50Ещё можно вносить записи не в эксель, а в базу данных, и получать нужные группировки для визуализации через SQL запросы


sergei_shirkin
16.06.2022 20:20+5Вместо двумерных массивов прямо-таки напрашиваются таблицы, так что смело можно использовать pandas и орудовать датафреймами. Ну и если уж заниматься анализом данных, то, помимо pandas, также пригодятся библиотеки numpy, scikit-learn, matplotlib, seaborn и т.д. А лучше сразу поставить Anaconda, там уже всё это есть, и графики прямо там (в Jupyter Notebook) можно строить.

ViacheslavZagriichuk Автор
17.06.2022 01:05+1А что вы имеете ввиду под таблицами вместо двумерных массивов? Какой-то класс для этого есть?
sergei_shirkin
17.06.2022 02:58+1В библиотеке pandas для создания таблиц есть класс DataFrame, он бы для задачи из этой статьи идеально подошел.

yason2
16.06.2022 21:11Девтулз- Нетворк, смотрим запросы, курл - на основную таблицу - греп айдишники, курл в цикле по айдишникам, сложить в SQL. Grafana - и крутить графики как хотите. И вообще не нужно выполнять скрипты со стороны клиента
ViacheslavZagriichuk Автор
17.06.2022 01:04+5Я попробую понять, что вы написали

extempl
17.06.2022 06:56+4Chrome -> Devtools -> Network - это место, где можно посмотреть все запросы на сайте, куда они идут, с какими параметрами, какие данные приходят в ответе.
cURL - это утилита для запросов из консоли, в devtools/network можно нажать правой кнопкой на запросе и скопировать его как cURL для вызова из консоли (ну или любым другим инструментом поддерживающим cURL или вызов консольных команд, ака, питон).
grep - утилита поиска по данным, можно использовать с результатом любой другой командой (cURL, например).
В Grafana можно скормить таблицу из БД и получить желаемые графики.
yason2
16.06.2022 21:23Все начинающие почему-то бегут кодить, ух вы все дураки а я вот щаз (это не камень в огород автора, он молодец, а констатация факта)..
Программист, это не про кнопки жмакать, а про достичь решения минимальными усилиями и быстро. И вот погружать страницу и выполнять J's с нее, тут точно не требуется.

Liroluka
17.06.2022 00:53+10Ну это как раз правильно - бежать кодить, будучи начинающим. Конечно если есть какой-нибудь наставник или какой-то пример, чтобы ориентироваться на него, то это куда полезнее. Но в любом случае сначала надо ручками все прочувствовать. Тот же говнокод начинаешь видеть только после того, как сам наговнокодил и через день вернулся что-то доделать))
ViacheslavZagriichuk Автор
17.06.2022 01:02+4Я лишь недавно начал программировать, и мне было интересно решить задачу, используя понятные мне инструменты на практике, что я и сделал. Не потому, что самый умный, а очень даже наоборот:)
Понятно, что есть условно электромясорубка, которая при должной настройке проблему перемелет и это будет в итоге проще. Но зачем тогда в школе учат считать, если калькулятор умеет это делать лучше и быстрее?
Спасибо за комментарии и проявленный интерес. Правда из первого я не понял приблизительно ничего. Он в духе «х*як, потом ещё х*як и вот так-то вот», субъективно для меня на данном этапе, по крайней мере.
yason2
17.06.2022 11:03+1Про обучение в школе и калькулятор: в данном случае закладываются основы, так сказать технический бэк, благодаря которым, вы примерно знаете что гуглить, и как это работает. Я встречал людей, которые сдачу в 40 рублей на калькуляторе считают ). Их видимо в школе не учили.

Kudesnick33
17.06.2022 08:29Программист, это не про кнопки жмакать, а про достичь решения минимальными усилиями и быстро.
Вот как раз это у автора прекрасно получилось.
yason2
17.06.2022 10:01Получилось что?
Kudesnick33
17.06.2022 12:05Достичь практически значимого результата с минимальными затратами усилий. Данные получены? Графики построены? Какая разница, что там внутри, если цель была: спарсить один конкретный сайт и визуализировать полученные данные?
yason2
17.06.2022 12:57Про минимальные усилия, я бы поспорил.
Результат получен - да, я про это написал выше и автора похвалил.
Какая разница, что внутри - после такого и появляются одностраничники, которые жрут по 2-3 гб памяти и проц в 100%Kudesnick33
17.06.2022 13:31+5Одностраничники на 2-3 Гб появляются, когда выбирают неправильный инструмент и неверно определяют цели. Поясню свою мысль: У автора статьи не было цели сделать универсальный супербыстрый аналитический инструмент с возможностью его развития и поддержки группой разработчиков (да поправит меня автор). Мы говорим про код, который пишется один раз для запуска 10 раз на одной конкретной машине. Если у меня на даче упала береза, я возьму топор и порублю её за несколько часов, а не буду учиться и сдавать на права на работу со спецтехникой, которая позволит мне поднять это бревно за пять минут не напрягаясь. Знать про существование бензопилы полезно, но если под рукой только топор, то почему бы и нет?
yason2
17.06.2022 13:51-1Так и здесь решение не оптимальное. Тащить выполнение J's который загрузит по урлу файл, когда можно просто глянуть какие запросы идут и без всего огорода просто скачать файл. В вашем примере, это нанять для березы дровосека, вместо использования топора.
ViacheslavZagriichuk Автор
17.06.2022 14:13+2Тащить выполнение J's который загрузит по урлу файл, когда можно просто глянуть какие запросы идут и без всего огорода просто скачать файл
Если действительно есть возможность вытянуть файл без рендера страницы - это замечательно. Я логически понимал, что такая возможность должна быть, что откуда-то он данные тянет и поймать бы их. Но в силу своей неосведомлённости я так и не смог понять, как это сделать, поэтому сделал то, что нашёл по своим запросам в гугл, что и описал, в общем-то:)
Насчёт оптимизации - согласен полностью, сам сторонник осмысленного использования ресурсов компьютера, просто ещё многому предстоит научиться.
Kudesnick33
17.06.2022 19:44+1В вашем примере, это нанять для березы дровосека, вместо использования топора.
Не совсем. В моем примере это скорее попросить у соседа бензопилу, которую я в глаза не видел и убить пару дней на её освоение. И еще желательно не сломать её при этом. Подход правильный, если цель: "освоить новый инструмент" или "срубить еще 5-10 берез за выходные". Нанять дровосека, в данном случае, это найти фрилансера, который всё сделает.
ViacheslavZagriichuk Автор
17.06.2022 14:09Не поправлю, составы комиссий не сильно часто меняются и делать полноценную программу с возможностью настройки и поддержкой у меня цели действительно не было. Тем не менее результат получился, работает чётко, возможности подстроить программу оставил, все ключевые моменты закомментил, так что вы правы.

Oborotenby
16.06.2022 21:54+5Очень интересно, но мало что понятно. Я так понимаю, что автор скрыл некоторые выводы, т.к. боялся их публиковать, но именно эти выводы я и хотел бы почитать.
ViacheslavZagriichuk Автор
17.06.2022 00:37В оригинале статьи были и мои выводы об этом, и причина, почему они сюда не попали, не в страхе. Я вам их в лс отправлю, рад, что поинтересовались!

Vlad2001MFS
18.06.2022 23:16А можно и мне скинуть?
viksav
17.06.2022 01:08это лучше вам обратиться к эстонским программистам. у них там крутой опыт по разработке электронного голосования и причем там все это работает как часы


RoboShop
17.06.2022 02:29+9О, родной Питер. Был я на выборах 21 года членом УИК от Вишневского, того самого, которому едросня клонов плодила. Ну, что сказать, когда я на подсчёте голосов в последний день обнаружил на пакете с билютенями за 1 день голосования следы кустарной перепайки пакета, на меня сначала начали орать председатель УИК, она же директрисса, и её подруги, тоже местные. Потом приехали мусора (да, сотрудники полиции, которые участвуют в фальсификации выборов, могут называться только мусорами), забрали вещдок - перепаянный пакет, и увезли меня в отделение, за то что умный такой. Потом был суд для отмены результата на участке, пакет, естественно "потерялся", на отснятых видео "судья" ничего не увидела. Так что тут всё и без анализа понятно.
ViacheslavZagriichuk Автор
17.06.2022 11:39+2С одной стороны да, просто когда перешёл в комиссию старше, мне захотелось именно увидеть систему, как это организовано на уровне города.

saipr
17.06.2022 09:32+1Это история о том, как я писал код на Python 3, который собирает и систематизирует данные по избирательным комиссиям в моём родном городе Санкт-Петербурге.
Эта история напомнила мне о том как проходила подготовка к аналогичным мероприятиях в 90-ые годы прошлого столетия. С точки зрения IT-индустрии и IT-технологий, это были тяжелейшие годы, компьютеров и принтеров не просто не хватало, во многих местах их просто не было.
Речь тогда шла о подготовке ваучеризации.
30 лет назад 1 октября 1992 года во всех отделениях Сбербанка РФ г. Химки стали выдавать ваучеры.

Satim
17.06.2022 11:22Чтение файлов лучше через yield сделать, фиг его знает какого размера файл на вход придет.

slavius
17.06.2022 14:50+2Это Вам еще повезло, что русские буквы текстом, а не с использованием специальных шрифтов со схожим начертанием, и разные для разных страниц, как было на сайте центризбиркома во время выборов... https://habr.com/ru/post/579492/
А тут описаны неплохие инструменты https://habr.com/ru/post/588989/
ViacheslavZagriichuk Автор
В оригинале статьи были и мои выводы об этом, и причина, почему они сюда не попали, не в страхе. Я вам их в лс отправлю, рад, что поинтересовались!