В прошлом году часть нашей команды, которая обеспечивает безопасность платформы Spotify for Artists (S4A), провела исследование ряда инцидентов, произошедших с S4A в 2021 году. Мы выдвинули несколько гипотез, а затем приступили к анализу каждой из них для того, чтобы разработать набор количественных и качественных метрик. И мы кое-что выяснили, а теперь хотим поделиться этим с вами.
Мы обмениваем нынешнюю производительность на производительность в будущем
Каждый раз, когда что-то идет не по плану, возникают как затраты, так и выгоды. Чаще всего мы думаем о тех негативных расходах, которые нам придется понести, если дело касается пользователей, но есть и другие цена — производительность.
Мы обнаружили, что большинство инцидентов оказывают умеренное или высокое влияние на производительность. Это означает, что при возникновении инцидента по крайней мере один сотрудник, отвечающий за реагирование, тратит большую часть дня на устранение проблемы. Фактически, в 23% случаев работник затрачивает еще больше времени.
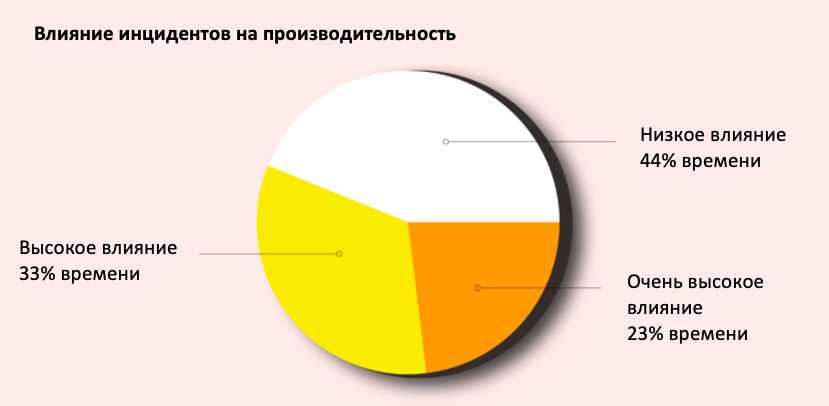
Теперь вы можете сказать: «Ого, как много времени уходит на решение проблем!» Но, как говорилось ранее, при правильном подходе эти затраты приносят пользу. Проводя анализ инцидента (мы привыкли называть это постмортем), у нас есть возможность изучить ситуацию и понять, как и где система вышла из строя. В то время как мы можем читать код и документацию, выдвигать гипотезы, откуда возникла проблема, анализ сбоя помогает лучше понять проблему и разобраться в ней. Таким образом, благодаря повышению квалификации наших инженеров можно достичь лучших результатов. Так мы покупаем производительность на будущее, жертвуя частью сегодня.
Большинство инцидентов (технически) можно предотвратить
Для каждого инцидента мы искали признаки того, что его можно предотвратить. Мы составили рейтинг оценок инцидентов со шкалой от 1 до 5, где 1 – «почти невозможно предотвратить», и 5 – «мы знали, что инцидент произойдет, и позволили этому случиться». К счастью, оценки 5 не было ни в одном инциденте!


Исходя из рейтинга, инциденты с оценками 2 и 1, как правило, находятся вне нашего контроля и поэтому их нельзя считать предотвратимыми. Инциденты с оценкой 3 и выше – это локальные сбои, которые можно предотвратить и/или смягчить последствия, приняв хорошо известные и подробно изученные превентивные меры.
Нельзя сказать, что превенция – это бесплатно или легко. Определяя целевой уровень обслуживания (SLO), мы рассчитываем бюджет на ошибки — если мы можем остаться в рамках нашего бюджета без принятия превентивных мер, мы должны это сделать. Это означает, что мы можем потратить время на улучшение пользовательского опыта и, в конечном счете, сосредоточиться на основной задаче.
Никто не любит работу с документацией
В течение последних нескольких лет организация DevOps Research and Assessment, или DORA, ежегодно выпускает отчет о состоянии DevOps. Эксперты компании опрашивают тысячи специалистов из разных областей и определяют от чего зависит производительность труда.
Согласно результатам исследования ключевые метрики – это «Среднее время восстановления» и «Изменение показателя отказов». Для разных компаний эти метрики могут иметь разное значение. Однако их не следует считать панацеей, они скорее карта, помогающая понять, где мы находимся и куда хотим прийти.
В ходе нашего исследования инцидентов, произошедших в 2021 году, мы тщательно изучали хронологию каждого инцидента, в том виде, в каком она была записана, а затем анализировали существующие доказательства, чтобы получить четкое представление о времени восстановления (TTR) после каждого инцидента.
Мы обнаружили, что примерно в 50% случаев время начала и окончания восстановления не записывалось. В ситуациях, когда время было записано, примерно в 81% случаях нам приходилось корректировать введенное время более чем на 5 минут, чтобы получить реальное число.
Это не ошибка операторов, а ошибка системы. Мы просили их заполнять документацию, но никак их не поощряли, и, как и ожидалось, они предпочитали тратить свое время на более важные занятия.
Синтетическое тестирование сокращает время восстановления
После проведенной работы, мы получили данные о времени восстановления (TTR). Мы обнаружили, что время восстановления действительно трудно соотнести с каким-либо аспектом наших систем.
Тем не менее, мы попали в цель. Одна из самых интересных вещей, о которой мы узнали в ходе нашего исследования, заключалась в том, что синтетическое тестирование работает. Мы потратили немало времени на оценку того, может ли тестирование действительно обнаруживать сбои, а затем сравнили TTR после инцидентов, которые уже были обнаружены синтетическим тестированием и инцидентов, которые не были обнаружены, потому что они не были покрыты тестами.
Результаты оказались даже более шокирующими, чем мы предполагали. Мы обнаружили, что время восстановления после инцидентов, связанных с функциями, в которых проводились синтетические тесты, было в 10 раз меньше. Нет, правда, прочтите это еще раз!
Это может показаться очевидным, но мы не можем недооценивать влияние данных на принятие решений. Это не просто любопытство. Мы скорректировали наши приоритеты, сделав больший акцент на тестировании, поскольку считаем, что очень важно как можно быстрее восстановить работоспособность.
Так что помните...
Я надеюсь, что из этой статьи вы вынесли для себя, что сила инцидентов в возможности дальнейшего обучения. Изучаете ли вы инциденты как коллекцию, как это делали мы, или уделяете время тому, чтобы извлечь из них уроки в своем собственном контексте, заменить это источник данных просто невозможно. Может показаться утомительным прерывать свой рабочий процесс для изучения сбоя. Однако мы считаем, что это жизненно необходимо, если вы хотите развивать и поддерживать работоспособность вашего сервиса.
Приглашаю тимлидов и всех, кому интересна тема технического менеджмента в свой телеграм канал Вы тимлид. Пишу заметки и делюсь интересными материалами на тему управления командой.