Порой нам бывает нужно добавить избыточность какому-то сервису, который оказался публичной точкой входа в нашу инфраструктуру. Например, представьте, что мы хотим добавить второй балансировщик для высокой доступности. При этом балансировщики находятся на границе нашей сети и пересылают трафик доступным бэкенд-серверам.
┌─────────────┐
│ │
┌─────►│ Backend 1 │
│ │ │
│ └─────────────┘
│
│
│ ┌─────────────┐
│ │ │
┌────────────┐ ├─────►│ Backend 2 │
│ │ │ │ │
│ │ │ └─────────────┘
Public traffic │ Load │ │
───────────────────►│ ├────┤
│ Balancer │ │ ┌─────────────┐
│ │ │ │ │
│ │ ├─────►│ ... │
└────────────┘ │ │ │
│ └─────────────┘
│
│
│ ┌─────────────┐
│ │ │
└─────►│ Backend N │
│ │
└─────────────┘Мы не можем просто добавить ещё один балансировщик нагрузки перед парой наших балансировщиков, потому что иначе любой переключатель трафика перед нашей парой высокой доступности также сам станет единой точкой отказа. Но нам всё равно как-то нужно организовать переключение трафика между парой этих балансировщиков:
┌─────────────┐
│ │
┌─────►│ Backend 1 │
┌────────────┐ │ │ │
│ │ │ └─────────────┘
│ │ │
Public traffic │ Load │ │
───────────────────►│ ├────┤ ┌─────────────┐
▲ │ Balancer 1 │ │ │ │
│ │ │ ├─────►│ Backend 2 │
│ │ │ │ │ │
└────────────┘ │ └─────────────┘
Switching? │
│
│ ┌────────────┐ │ ┌─────────────┐
│ │ │ │ │ │
▼ │ │ ├─────►│ ... │
Public traffic │ Load │ │ │ │
─ ─ ─ ─ ─ ─ ─ ─ ─ ─►│ ├────┤ └─────────────┘
│ Balancer 2 │ │
│ │ │
│ │ │ ┌─────────────┐
└────────────┘ │ │ │
└─────►│ Backend N │
│ │
└─────────────┘Подходы обеспеченных людей
Давно существуют разнообразные решения для этой задачи. Все они так или иначе манипулируют сетевой коммутацией на каком-то уровне, чтобы направить входящий трафик на оба или только один балансировщик.
VRRP, CARP, Virtual IP, Floating IP, ...
По сути сопоставляет один или несколько IP-адресов одному или нескольким активным балансировщикам нагрузки. IP-адреса (пере-)присоединяются к рабочим серверам в случае отказа других серверов. Такие методы в конечном счёте используют сетевое оборудование в качестве того самого переключателя между рабочими балансировщиками нагрузки.
Стоит заметить, что упомянутое сетевое оборудование совсем необязательно имеет какую-либо избыточность (резервирование). Например, вполне возможна пара из двух балансировщиков нагрузки подключенных к одному Ethernet-свитчу, который будет в этом случае единой точкой отказа. И даже свитчи с резервированием компонентов могут быть склонны к одновременным отказам из-за схожих условий работы или общего широковещательного домена.
Это решение подходит только для балансировки нагрузки внутри одного датацентра.
Anycast, BGP и методы, основанные на динамической маршрутизации
Обычно используются не сами по себе, а в сочетании с балансировщиками внутри датацентра. Отправляют анонсы одного и того же блока IP-адресов из разных местоположений, фактически выстраивая обслуживание этих IP-адресов машинами из разных датацентров. Эти методы в конечном счёте используют своих сетевых соседей по пирингу и соседей этих соседей как переключатель трафика перед собственной инфраструктурой, анонсируя или не анонсируя блоки IP-адресов из некоторого расположения (датацентра).
Этот способ в особенности доступен только достаточно крупным сетевым операторам, вероятно даже эксплуатирующим собственные автономные системы.
Методы, использующие DNS
Производят переключение трафика на уровне DNS, приводя клиента к правильному серверу. Существуют следующие широкоизвестные варианты:
Round robin DNS - на самом деле, не-вариант, потому что обнажает все известные серверы сразу, надеясь, что клиенту либо повезёт подключиться к рабочему серверу, либо он будет достаточно упорным, чтобы перепробовать их по-очереди.
Динамический DNS, отслеживающий состояние балансируемых серверов (AWS Route53, Cloudflare DNS LB, PowerDNS dnsdist, ...). Отслеживают работоспособность серверов и отвечают на DNS-запросы адреса сервера адресом только одного работоспособного сервера.
Занимательный факт насчёт таких облачных сервисов балансировки нагрузки состоит в том, что они тарифицируются на основе принятых DNS-запросов, однако мы в общем-то не имеем возможности ни как-то влиять на объём входящих DNS-запросов, ни проверить как много DNS-запросов на самом деле было произведено клиентами.
Проблемы обеспеченных людей
Некоторые из этих методов сложно правильно реализовать. Даже для keepalived рекомендуется использовать отдельный канал связи для VRRP-протокола. Иначе дефицит полосы пропускания на рабочем соединении будет мешать протоколу выбора мастера. Некоторые из них просты в интеграции (такие как DNS GTM-ы), но могут обернуться достаточно дорогостоящими.
Решения выше подразумевают что цель пересылки трафика (локальный балансировщик нагрузки или просто сервер) либо работоспособны, либо неисправны, что является некоторым допущением. Это может быть не всегда так, в особенности для решений, переключающих трафик между разными датацентрами. Например, AWS Route53 производит периодические пробы жизнеспособности серверов из разных местоположений, чтобы убедиться, что целевой сервер доступен. Но положительный результат такой пробы не обязательно свидетельствует о глобальной доступности из всех возможных удалённых местоположений - возможность установления соединения в Интернете не всегда однозначна.
Босяцкий Кластер Высокой Доступности не делает таких допущений, не ограничен только лишь одним датацентром, не имеет "подвижных частей" и не стоит Вам практически ничего. С ним Вы можете быстро запускать глобальные отказоустойчивые сервисы, что позволяет посвятить больше времени сведению концов с концами.
Схема
Обычно процесс разрешения доменных имён выглядит следующим образом:
┌────────────┐ A? example.com ┌───────────────┐
│ │ (1) │ │
│ ├───────────────►│ DNS recursive │
│ Client │ │ │
│ │◄───────────────┤ resolver │
┌─┤ │ A example.com │ │
│ └────────────┘ (8) └┬────┬────┬────┘
│ │ ▲ │ ▲ │ ▲
│ ┌─────────────────────────────┘ │ │ │ │ │
│ │A? example.com (2) │ │ │ │ │
│ │ ┌─────────────────────────────┘ │ │ │ │
│ ▼ │NS com (3) │ │ │ │
│ ┌──┴──────────┐ ┌────────────────┘ │ │ │
│ │ ├┐ │A? example.com (4)│ │ │A? example.com (6)
│ │ ROOT ││ │NS example.com (5)│ │ │A example.com (7)
│ │ ││ ▼ ┌────────────────┘ │ │
│ │ nameservers ││ ┌──┴──────────┐ │ │
│ │ ││ │ ├┐ │ │
│ └┬────────────┘│ │ .COM ││ │ │
│ └─────────────┘ │ ││ ▼ │
│ │ nameservers ││ ┌──────┴──────┐
│ │ ││ │ ├┐
│ └┬────────────┘│ │ example.com ││
│ └─────────────┘ │ ││
│ │ nameservers ││
│ │ ││
│ └┬────────────┘│
│ └─────────────┘
│ ┌─────────────┐
│ │ ├┐
│Actual connection │ EXAMPLE.COM ││
└─────────────────►│ ││
(9) │ servers ││
│ ││
└┬────────────┘│
└─────────────┘Клиент желает установить соединение с некоторым хостом, указанным по его доменному имени. Клиент запрашивает DNS-резолвер (обычно это DNS-серверы, предоставляемые интернет-провайдером, и находящиеся в той же сети, что и клиент). DNS-резолвер, если не имеет адреса в кэше, следует по всей иерархии авторитативных DNS-серверов. На каждом шаге он оказывается или перенаправлен на следующий более конкретный сервер имён, куда запрошенный домен делегирован, или наконец получает запрошенную ресурсную запись.
Заметьте, что на каждом шаге DNS-рекурсору обычно доступно больше одного сервера имён для осуществления запросов. DNS имеет встроенные механизмы отказоустойчивости и, если какой-то нэймсервер не доступен, будет запрошен следующий в этой группе. Например, прямо сейчас доменная зона .COM обслуживается 13-ю серверами имён:
a.gtld-servers.net.
b.gtld-servers.net.
...
m.gtld-servers.net.Каждый из этих серверов имён может быть запрошен для получения нэймсерверов домена example.com, и DNS-рекурсор свяжется со следующим сервером имён, если не получит ответ от сервера из первой попытки. Мы можем использовать это свойство, чтобы построить переключение трафика между рабочими серверами, основанное на DNS. Идея состоит в следующем: мы можем развернуть два или больше авторитативных нэймсерверов для нашего домена на самих рабочих серверах и настроить их возвращать собственный IP-адрес. Таким образом будет причинно-следственная связь между адресом нэймсервера, который смог достигнуть DNS-рекурсор, и IP-адресом используемым для связи с целевым сервером.
В отличии от обычных решений с динамическим DNS, мы не пытаемся решить какой сервер работоспособен, мы не делаем никаких активных проб. Мы просто позволяем DNS-рекурсору определить самостоятельно, какой нэймсервер доступен, и он в свою очередь приведёт клиента к той же машине, которая предоставила успешный DNS-ответ. Фактически, это возлагает прощупывание рабочего сервера и переключение на него на DNS-рекурсор клиента, позволяя нам отделаться двумя DNS-серверами со статической конфигурацией. Диаграмма взаимодействий могла бы выглядеть следующим образом:
┌────────────┐ A? example.com ┌───────────────┐
│ │ (1) │ │
│ ├───────────────►│ DNS recursive │
┌─┤ Client │ │ │
│ │ │◄───────────────┤ resolver │
│ │ │ A example.com │ │
│ └────────────┘ (9) (=LB2) └┬────┬────┬─┬──┘
│ │ ▲ │ ▲ │ │ ▲
│ ┌─────────────────────────────┘ │ │ │ │ │ │
│ │A? example.com (2) │ │ │ │ │ │
│ │ ┌─────────────────────────────┘ │ │ │ │ │
│ ▼ │NS com (3) │ │ │ │ │
│ ┌──┴──────────┐ ┌────────────────┘ │ │ │ │
│ │ ├┐ │A? example.com (4)│ │ │ │
│ │ ROOT ││ │NS example.com (5)│ │ │ │ A example.com (8)
│ │ ││ ▼ ┌────────────────┘ │ │ │
│ │ nameservers ││ ┌──┴──────────┐ │ │ │ (=LB2)
│ │ ││ │ ├┐ │ │ │
│ └┬────────────┘│ │ .COM ││ │ │ │
│ └─────────────┘ │ ││ │ │ │
│ │ nameservers ││ │ │ │
│ │ ││ │ │ │
│ └┬────────────┘│ │ │ │
│ └─────────────┘ │ │ │
│ A? example.com (6) │ │ │
│ ┌─xxxxxxxxxxxxxxxx────────────────────┘ │ │
│ │ A? example.com (7)│ │
│ │ ┌──xxxxxxxxxxxxx ┌────────────────┘ │
│ ▼ │ ▼ │
│ ┌──┴──────────────┐ ┌─────────────────┐ │
│ │ │ │ ├─┘
│ │ example.com │ │ example.com │
│ │ │ │ │
│ │ nameserver1 & │ │ nameserver2 & │
│ │ │ │ │
│ │ loadbalancer1 │ │ loadbalancer2 │
│ │ │ │ │
│ │ (FAULTY) │ │ (HEALTHY) │
│ │ │ │ │
│ └─────────────────┘ └─────────────────┘
│ ▲
│ Actual connection (10) │
└───────────────────────────────────┘Как показывает диаграмма, рекурсор DNS спускается по иерархии как обычно. Когда дело доходит до разрешения фактического адреса ресурса example.com, он пытается связаться с первым нэймсервером, который так же является сервером, предоставляющим сервис example.com. Первый сервер неисправен и не предоставялет ответ рекурсору DNS. Рекурсор DNS пытается связаться с другим нэймсервером и преуспевает в этом. Второй (нэйм)сервер отвечает на запрос своим собственным IP-адресом, как и всегда. Это приводит к тому, что DNS-рекурсор вернёт запросившему клиенту IP-адрес живого нэймсервера, который по совместительству является IP-адресом живого балансировщика сервиса example.com.
Реализация
Рассмотрим чуть более практический пример, где нам нужно организовать балансировку некоторого хостнейма, но нам бы не хотелось делегировать всю доменную зону на наши собственные авторитативные нэймсерверы. Мы возьмём домен example.com и обеспечим высокую доступность для домена api.example.com, который указывает на пару балансировщиков перед рабочими серверами.
Шаг 1. Подготовка серверов
Подготовьте два сервера для обслуживания входящего трафика. Они могут находиться даже в разных датацентрах и пересылать трафик в местную группу рабочих серверов. Далее мы будем полагать, что IP-адреса развёрнутых серверов 198.51.100.10 и 203.0.113.20.
Проверка: убедитесь, что вы можете залогиниться на эти серверы и они доступны по их внешним адресам.
Шаг 2. Разверните полезную нагрузку на серверах
Разверните на этих серверах сервис или балансировщики нагрузки, предоставляющие настоящий сервис на этих IP-адресах.
Проверка: зависит от вашего сервиса.
Шаг 3. Установите всезахватывающие (catchall) DNS-серверы
На этом шаге нам нужно установить авторитативный DNS-сервер на каждую машину и настроить его отвечать на любые запросы IP-адресом этой машины. Почти каждый DNS-сервер может справиться с этой работой, даже простой dnsmasq. Однако разумным вариантом для этого будет сервер CoreDNS.
Установите CoreDNS на каждый сервер и примените следующую конфигурацию:
Первый сервер
/etc/coredns/db.lb:
@ 3600 IN SOA lb1 adminemail.example.com. 2021121600 1200 180 1209600 30
3600 IN NS lb1
3600 IN NS lb2
* 30 IN A 198.51.100.10/etc/coredns/Corefile:
example.com {
file /etc/coredns/db.lb
}Второй сервер
/etc/coredns/db.lb:
@ 3600 IN SOA lb1 adminemail.example.com. 2021121600 1200 180 1209600 30
3600 IN NS lb1
3600 IN NS lb2
* 30 IN A 203.0.113.20/etc/coredns/Corefile:
example.com {
file /etc/coredns/db.lb
}Проверка: команда dig +short api.example.com @198.51.100.10 должна возвращать адрес 198.51.100.10. Команда dig +short api.example.com @203.0.113.20 должна возвращать адрес 203.0.113.20.
Шаг 4. Добавьте A-записи для серверов в DNS
Создайте следующие DNS-записи в доменной зоне example.com:
lb1.example.com. 300 IN A 198.51.100.10
lb2.example.com. 300 IN A 203.0.113.20Процесс редактирования зоны DNS зависит от того, где вы её хостите. Иногда это панель управления Godaddy, иногда это Cloudflare. Вам виднее.
Проверка: команда dig +short lb1.example.com должна возвращать 198.51.100.10. Команда dig +short lb2.example.com должна возвращать 203.0.113.20.
Шаг 5. Наконец делегируйте хостнейм api.example.com на балансировщики/нэймсерверы
Удалите все имеющиеся DNS-записи для имени api.example.com. Добавьте следующие:
api.example.com. 300 IN NS lb1.example.com.
api.example.com. 300 IN NS lb2.example.com.Готово! Через несколько минут вы сможете обратиться к домену api.example.com через два балансировщика, которые мы настроили.
Проверка: команда dig +trace api.example.com должна давать вывод, указывающий на то, что lb1 и lb2 были затронуты при разрешении имени и результат должен давать один из их адресов.
Обслуживание
Если Вам нужно провести обслуживание одного из серверов, или сервер плохо себя ведёт, Вы можете снять с него нагрузку просто остановив CoreDNS на этом сервере и подождав TTL (30 секунд в нашем примере).
Комментарии (40)

Sap_ru
22.08.2022 10:56+3Да, но...
1) если ваш сервер сервер упадёт при сохранении физической доступности DNS, то будет ой. Причем, во можете сами захотеть вывести из работы один из серверов на время. Нужно будет все равно городить мониторинг и исправление зон, а тогда уже лучше сделать одного мастера, а уже в случае его недоступности, пусть клиенты стучатся куда получится.
2) кэширование DNS нужно отключить или сделать очень небольшим, а это замедляет доступ к ресурсам и повышает нагрузку на сам DNS. К тому же уменьшение времени кэширования запросов перемещает точку отказа вверх к DNS серверу.

YourChief Автор
22.08.2022 12:07+1Вы, видимо, невнимательно читали и не поняли сути изложенного.
если ваш сервер сервер упадёт при сохранении физической доступности DNS, то будет ой
Это буквально одни и те же машины.
Причем, во можете сами захотеть вывести из работы один из серверов на
время. Нужно будет все равно городить мониторинг и исправление зонЕсли на машине не отвечает её coredns, то трафик на неё не пойдёт. Об этом явно сказано в самом последнем абзаце.
кэширование DNS нужно отключить или сделать очень небольшим, а это замедляет доступ к ресурсам и повышает нагрузку на сам DNS.
Расскажите всем вендорам DNS-based GTM-ов, что они какой-то неправильный сервис сделали.

Revertis
22.08.2022 12:40+5Это буквально одни и те же машины.
Но это разные процессы. Если упадёт сервис, который обеспечивает работу api.example.com, а DNS-сервис будет жить, то кластер не выполняет свою работу.
И клиент, получив при резолве только одну запись не может положиться на Round-Robin и перебрать другие айпишники.

nick-for-habr
22.08.2022 12:08+1п.1 то же сразу бросился в глаза.
Схема в части обработки отказов будет работать только при полной недоступности всей ноды. Если отвалится только полезная нагрузка - DNS всё равно будет кидать "на себя" коннекты, в пустоту.
Очень длинное вступление, очень много текста - но фактически предложен ещё один костыль. <>Тут должна быть картинка с троллейбусом из буханки хлеба</>
Увы, чудес не бывает...
YourChief Автор
22.08.2022 12:25+1Схема в части обработки отказов будет работать только при полной
недоступности всей ноды. Если отвалится только полезная нагрузка - DNS
всё равно будет кидать "на себя" коннекты, в пустоту.Согласен, здесь есть пространство для улучшений. Желательно добиться, чтобы DNS там гасился в таких случаях. Однако haproxy или nginx редко сами по себе падают с концами, либо будут просто перезапущены systemd. По этой части риски минимальные.

Kotsusamu
22.08.2022 11:46+5Это не кластер высокой доступности, а не понятно что: при падении сервиса, пока запись в кеше DNS не "стухнет", юзеры будут резолвить "упавший" IP. При этом многие DNS сервера не обращают внимания на TTL зоны, а используют свои значения, чтобы снизить нагрузку. То есть время переключения клиентов на рабочий сервер вообще не прогнозируется.
YourChief Автор
22.08.2022 12:02-4Это не кластер высокой доступности, а не понятно что: при падении сервиса, пока запись в кеше DNS не "стухнет"
AWS Route53 работает так же, используя TTL в 30 секунд. Время переключения клиентов хорошо известно.
Kotsusamu
22.08.2022 13:08+130 сек недоступности, это не равно "кластер высокой доступности". Ну никак. Вводите людей в заблуждение.
Опять же 30 сек - это Ваш TTL, некоторые операторы не обращают внимания на TTL зоны и резолвят из кэша по своему усмотрению (тут и прописывание DNS гугла часто не помогает, так как оператор перехватывает DNS запросы - про QUIC не говорим пока). Или в AD/прокси (если про корпоративных пользователей) прописывают жестко время жизни записей.
YourChief Автор
22.08.2022 13:19-3Ну, опять же, скажите AWS тогда с их Route53 и вендорам всех других GTM, основанных на DNS, что они какой-то не такой продукт выпустили.

SergeyMax
22.08.2022 15:27А какое отношение route53 имеет к кластерам высокой доступности?
YourChief Автор
22.08.2022 15:37-1SergeyMax
22.08.2022 15:46DNS failover к высокой доступности имеет отношение весьма опосредованное из-за кэширования промежуточными DNS-серверами. Более того, этот файловер работает гораздо медленее, чем просто перебор A-записей клиентом. Сервис высокодоступной балансировки у амазона называется ELB.
YourChief Автор
22.08.2022 16:08DNS failover к высокой доступности имеет отношение весьма опосредованное из-за кэширования промежуточными DNS-серверами
И всё-таки имеет прямое отношение.
Более того, этот файловер работает гораздо медленее, чем просто перебор A-записей клиентом.
Нет. Может быть разве что при условии, что 1. клиент перебирает адреса (что обычно так для HTTP-клиентов, но в общем случае это не так), 2. Сбойный сервер будет не таймаутить, а слать TCP-reset.
Более того, в случае отказа предложенная мной схема через ~30 секунд приведёт всё в норму для всех без дополнительных задержек на каждый запрос, а схема с перебором A-записей так и будет таймаутить для части запросов.
SergeyMax
22.08.2022 19:38Более того, в случае отказа предложенная мной схема через ~30 секунд приведёт всё в норму
Сколько у винды например срок хранения в кэше днс?
YourChief Автор
22.08.2022 15:41На хабре, кстати, тоже есть статьи про него: https://habr.com/ru/post/122238/

ToSHiC
23.08.2022 02:39+4Вот именно, что время переключения хорошо известно.
Long story short: DNS TTL is a lie. Even though we have TTL of one minute for www.dropbox.com, it still takes 15 minutes to drain 90% of traffic, and it may take a full hour to drain 95% of traffic
Выглядит примерно вот так:
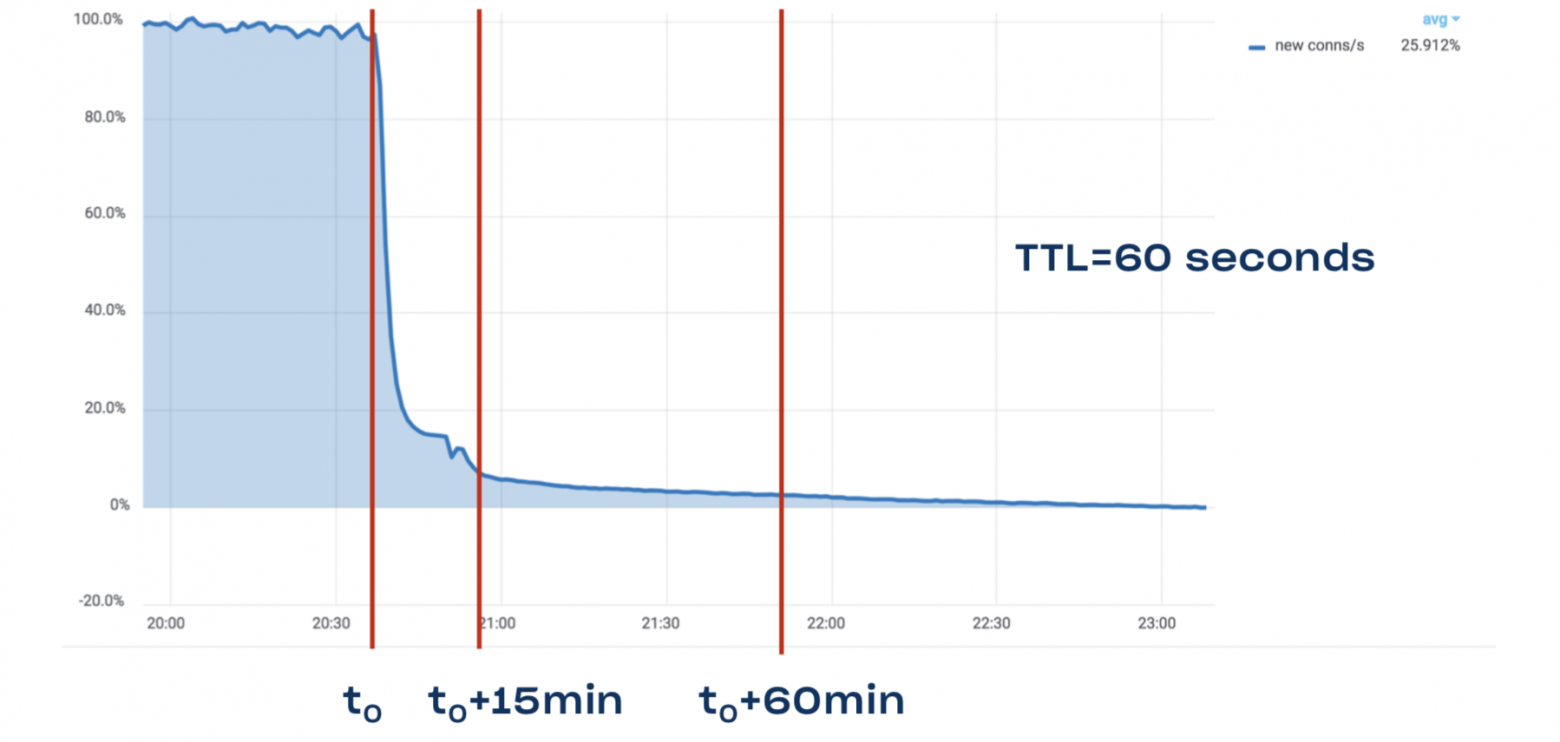
Источник: https://dropbox.tech/infrastructure/dropbox-traffic-infrastructure-edge-network


vladvul
22.08.2022 11:55+8решение неплохое.
Теперь нам нужна босяцкая междатацентровая симметричная репликация БД

AlexGluck
22.08.2022 12:17А что мешает настроить anycast на lvs (ipvs)? Для этого даже не надо владеть своей AS.
YourChief Автор
22.08.2022 12:29Не совсем понял сути вашего предложения. LVS это сам по себе лоадбалансер, кто или что будет подавать или не подавать нагрузку на него?
AlexGluck
22.08.2022 13:05Нагрузка идёт из канала на оба сервера сразу, далее на серверах в дело вступает динамическая маршрутизация для ipvs адресов, которые вы можете разместить на локальных петлях. Здесь в данном случае ipvs это балансировщик (может выполнять эту роль), а lvs название комплекса ПО. При этом всё что делает ipvs можно как всегда реализовать другим путём, отдельным сетевым неймспейсом и адресом на петле. А для синхронизации сетевых состояний используется conntrackd.
YourChief Автор
22.08.2022 13:12Так а почему она пойдёт на оба сервера сразу? В обычных условиях роутер направит трафик для конкретного IP-адреса на конкретный MAC, который подключён через конкретный порт. Что по итогу шлёт трафик для одного IP или VIP на оба сервера сразу?
AlexGluck
22.08.2022 13:24Через мультикаст получает трафик, далее уже ipvs эникастом через динамическую маршрутизацию отправит пакет на сервис. Сервис уже дубли сбрасывает, за счёт избыточности повышается надёжность.
YourChief Автор
22.08.2022 13:39А кто им его по мультикасту отправит?
AlexGluck
22.08.2022 14:01+1Маршрутизатор провайдера.
YourChief Автор
22.08.2022 14:04Ну интересно, подумаю как можно попробовать при случае. Не уверен правда, что мне провайдер позволит с нескольких машин слать с одного IP-адреса и согласится огранизовывать такой форвардинг. Тогда уж реальнее VRRP или CARP сделать.
AlexGluck
22.08.2022 14:07+1Провайдеры даже VRRP не всегда предоставляют, иногда приходится подбирать провайдера или использовать решение от провайдера. Иногда приходится реализовывать самостоятельно сервис балансировки, что создаёт точку отказа.

Night_Snake
22.08.2022 17:35За счёт кэширования ответов (в первую очередь на клиентах), long tail-drop может составлять минуты, иногда часы (вот тут есть хороший пример: https://www.youtube.com/watch?v=Hh9Ibckztds). Т.е. использовать DNS для HA можно только в очень специфических сценариях типа ConsulDNS
Использование своей AS доступно не только операторам, но и вполне себе обычным компаниям. Основные затраты - аренда IP-адресов.
YourChief Автор
22.08.2022 17:582 - ну, например в РФ вам потребуется лицензия сетевого оператора для этого. Что проще, получить AS, блок адресов, пириться с кем-то или просто установить демон на две виртуалки? Как по мне так вообще даже не сравнимо.
Night_Snake
22.08.2022 20:46+1Не потребуется, т.к. нет факта предоставления услуг по передаче данных. Да, РКН убедительно попросит завести ЛК в ЦМУ ССОП и ещё пару телодвижений, но именно лицензии (и связанных с этим обязательств, типа установки СОРМ) не потребуется.
Собственно, вопрос всегда в том, какую цель вы хотите достичь (например, доступность сервиса 99,99% времени в год), какой у вас на это есть бюджет и какая экспертиза (в крайнем случае, её можно купить). Создание "кластера высокой доступности", в общем случае, не решается установкой "демонов на две виртуалки".
Вы просто описали вариант балансировки нагрузки с помощью DNS с возможностью быстрого вывода из ротации в случае необходимости - он рабочий и довольно "дешёвый", но имеет ряд ограничений, и их нужно учитывать.

Ingtar
22.08.2022 17:45+1Интересное решение.
Вот ещё одна идея: на каждом сервере через крон чекать соседа и в случае фейла - через api днс провайдера удалять А запись соседа ????
Sap_ru
23.08.2022 17:12+1Не взлетит. Нужен третий наблюдатель и голосование 2 из 3. Если сервис видит ненорму второго сервиса и наблюдатель это подтверждает, то только тогда сервис перенастраивает DNS на себя. Иначе это сделать просто невозможно.
Ingtar
24.08.2022 13:00Как это невозможно? Как это не взетит?
В ДНС две А записи на домен - 10.0.0.1 и 10.0.0.2
На 10.0.0.1 крутится крон, который запрашивает у 10.0.0.2 главную страницу.
На 10.0.0.2 крутится крон, который запрашивает у 10.0.0.1 главную страницу.
Если 0.1 не ответит 0.2 - то 0.2 удалит из ДНС запись.
Если 0.2 не ответит 0.1 - то 0.1 удалит из ДНС запись.
Тут же решение из разряда "на коленке" - сервер чекает соседа и удаляет о нем запись если сосед не ответил.
Если нам нужен кворум, какая-то защита от дурака (когда 0.1 не видит 0.2, но 0.2 работает) то да, уже схема так себе :)
Sap_ru
24.08.2022 15:120.1 теряет связь и думает, что 0.2 не отвечает, и удаляет его запись из DNS. Но на самом деле потеряна связь внешнего мира именно с 0.1.
Короче, когда у вас пропадает связь с другим сервером, то вы никогда не знаете проблема у него или у вас.

alef13
22.08.2022 21:11+1Весёлая статейка, автор видимо не дождался первого апреля :). И кто так сделает - дуралей.
Объясняю - ещё лет 15-20 назад мне пришлось отказаться от стандартной схемы резервирования dns для клиентов (это где клиенту прописываем несколько серверов). Причина проста - если лёг первый DNS то клиент ждёт некое положенное время (заложено в операционке) и лезет к следующему серверу. Так вот этот значение этого таймаута выбирается с рациональной целью не зафлудить сеть и сервера запросами, поэтому он хоть и выглядит небольшим, но довольно ощутимый. Далее ответы сервера кэшируется на время ttl записи, но всё равно, при казалось-бы нормально работающем оборудовании, эта задержка при обращении к новому серверу напрягает конкретно и даёт ощущение офигенных тормозов сети.
У меня всё решилось созданием простейшего кластера высокой готовности для DNS, там ещё пяток сервисов кластеризовалось без напрягов, включая балансировщик нагрузки.
ЗЫЖ Схемы в аскях - такое было популярно в моей фидошной молодости (особенно в хаутушках) и в различных RFC :)

mnbck
Не читал, но ASCII схемы у вас крутые.