
Короткая версия
Я набил API и python библиотеку, которые позволяют искать картинки похожую на искомую.
API бесплатный, на один запрос выдает до 20 похожих картинок.
Cейчас в базе данных 18 миллионов изображений. Надеюсь, в ближайшее время, добавлю еще 50M.
API: LINK
python wrapper: LINK
Web Demo: LINK. Можно загрузить свою картинку или воспользоваться текстовым поиском. Можно кликать на картинки в результате поиска и смотреть что найдет по ней. Хороший вопрос за сколько шагов можно дойти от чего-то невинного до порнухи или хотя бы обнаженки.
Длинная версия
В прошлом посте я рассказывал, как начал со сбора Feedback для open source библиотеки Albumentations.AI, а вырулил на то, что захотелось запилить сервис по поиску картинок.
Задача картиночного поиска не нова, люди занимаются им много лет и и сервисов, которых позволяют это сделать, отсюда и до завтра.
Типичная задача для нормального человека - вы пишете блог пост или делаете сайт, нужна стильная картинка в высоком качестве, вы идете на Pexels, Unsplash или Gettyimages.
ML инжерены на картинки смотрят под другим углом. Они им нужны для тренировки нейронных сетей.
Обычная рабочая история:
Есть 20 миллионов картинок.
Из них размечено 20k.
Вы натренировали модель на размеченных данных.
Модель имеет точность, ниже требуемой.
Есть бюджет на разметку 10k.
Как выбрать нужные 10k из десятков миллионов?
Когда мы говорим: "Модель работает плохо", мы имеем в виду: "На объектах / ситуациях A, B и C модель работает хорошо и уверенно, а вот на C, D, и F так себе".
Так себе получается потому что C, D, F - это сложные ситуации, либо потому что данных с ними в тренировочных данных маловато.
Например, в задаче Self Driving'а - в данных много обычных машин. А вот скорых, пожарных или полицейских на порядки меньше. Но на дороге относится к этому классу надо с большим трепетом, особенно если они под мигалками.
Как определить картинки с полицейскими машинами?
Стандартным решением для данного вопроса является техника Active Learing.
Берем натренированную модель, которая плохо и неуверенно находит машины служителей порядка.
Смотрим что она предсказывает на неразмеченных данных.
Берем те картинки на которых модель их нашла, но нашла неуверенно, скажем, с вероятностью [0.3-0.7]. Уверенные предсказания пропускаем.
Отправляем на доразметку, добавляем в тренировочные данные и перетренировываем модель.
Если после этого точность модели на данном классе нас не устраивает, а именно так обычно и бывает - повторяем процедуру.
Думаю, все ML инженеры чем-то таким занимались.
Метод настолько стандартный, что на него можно лепить лычку "Best Industry Practice", хотя недостатки он тоже имеет.
Если у вас мало размеченных примеров нужного класса, то модель натренированная на них, будет совсем слабая и мало что найдет на новых данных.
Предсказавать на большом объеме картинок долго и дорого. А если итерировать много раз то очень долго и очень дорого.
Модель будет увеличивать точность на тех типах картинок, которые она и раньше хоть как-то определяла, но если какие-то ситуации она оне могла определить никак, то и итерации не помогут.
Комментарий: у той техники есть единоутробный брат, хоть и не близнец, называется pseudo labeling. Это когда вы игнорируете картинки с неуверенными предсказаниями, но обращаете внимание на те, где модель уверенна с вероятностью [0.9-1]. Добавляете их в тренировочный сет и перетренировываете. Да, то, что модель очень уверенна что полицейская машина тут есть, не означает, что она там и правда есть, но работает техника хорошо, особенно если докинуть Test Time Augmentation, пост обработку, ансамбли из моделей, soft labels и прочие соревновательные трюки.
Есть альтернативный вариант.
Чем мы занимались выше? Мы искали картинки, похожие на искомую. Причем похожесть мы определяли как "модель неуверенно ведет себя на картинках A и B", значит они похожи.
Слово похожи можно определить по другому, а именно семантически.
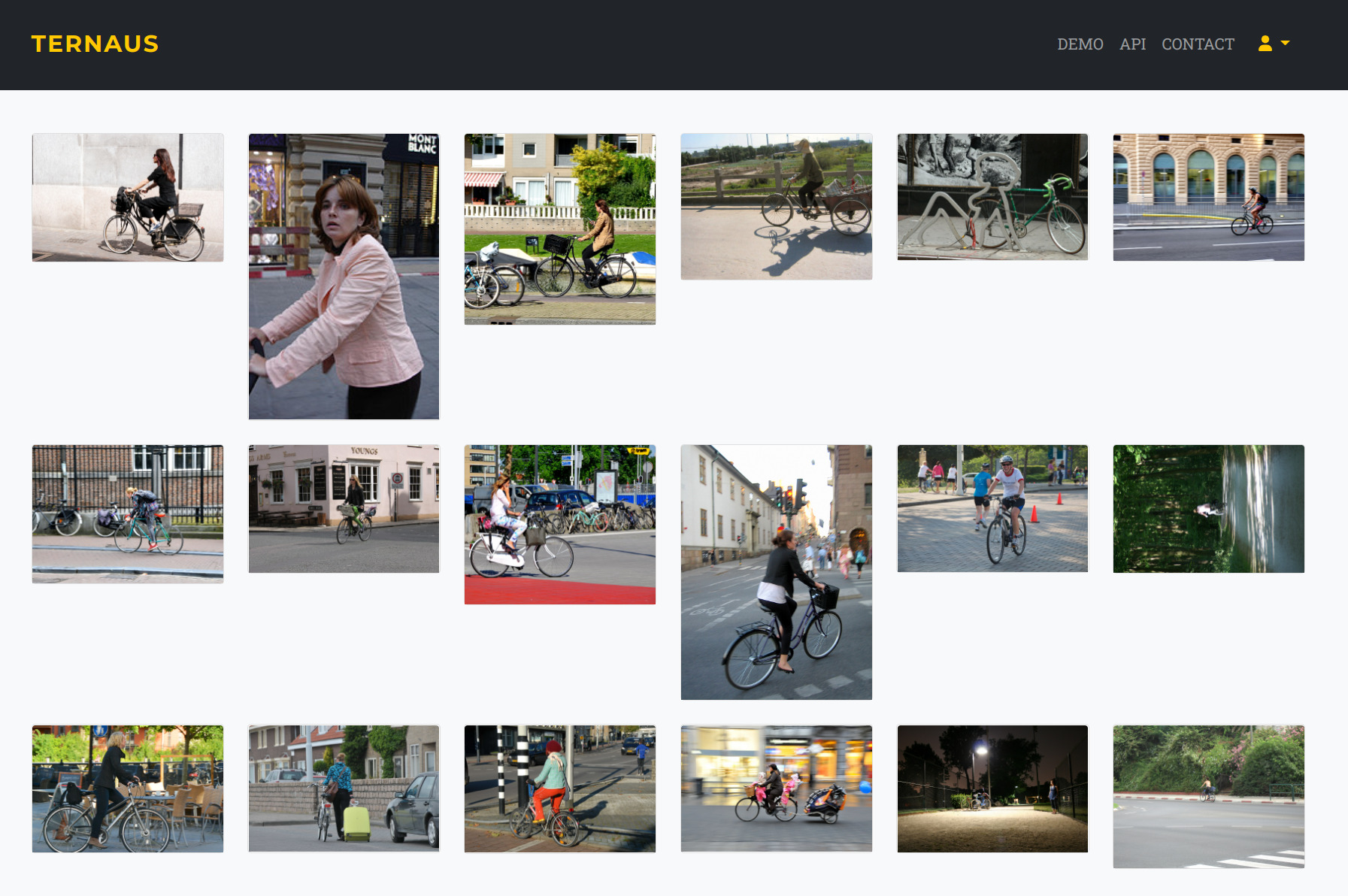
Пример того, что выдет мой сервис на запрос "woman on a bicycle". Картинки разные, но видно, что все они соответсвуют запросу.
С технологической точки зрения все прямлонейно:
Берется база данных картинок.
Каждая картинка перегоняется в векторное представление.
При поиске вектор исходной картинки сравнивается с векторами в базе данных. Чем меньше расстояние между ними, тем больше похожи картинки.
Любой картиночный поиск примерно так и работает, что в интернете, что Face ID в вашем iPhone.
Преимущество данного метода в том, что находить векторное представления нужно только один раз. И после этого можно искать, что полицейские машины, что девушек на велосипеде, что плюшевую панду.
Недостаток же состоит в том, что правильно перегонять в векторное представление, да так, чтобы это работало на картинках разного типа сложно. Причем сложность скорее научная, нежели инженерная. Обычная схема с - давайте возьмем Resnet50 / EfficientNet / InceptionNet, натренированные на ImageNet и будем их использовать как-то работает, но скорее плохо, нежели хорошо.
Q: Что мы имеем сейчас?
API, в котором можно сделать запрос картинкой, URL с картинкой или текстом и получить ссылки на 20 похожих картинок.
Python библиотеку, которая оборачивает запросы к API для более удобного использования.
Демо на сайте, где вы можете потыкать, позагружать и оценить качество поиска.
Q: А что дальше?
Сейчас это технология в поисках продукта. Нужны какие-то применения, причем воспроизводимые, причем не специалистами.
Cейчас все выглядит так, что дальше я буду писать плагины для бесплатных инструментов разметки и анализа датасетов и блог посты которые покажут как все удобно и полезно.
Хотя если у вас есть более оригинальные идеи - я весь внимание. Пишете - будем общаться и вместе думать.
Kwent
Спасибо за интересную статью, последнее время тоже играюсь в этом направлении
А можно приоткрыть завесу реализации? Или там сильно ноу хау? У меня проблемы что не совсем понимаю как учить в плане разметки классов, или тут тоже одна картинка с аугментациями == один класс?
По поводу применимости -- такая штука, но несколько специфичная нужна магазинам, в частности одежды, "поиск похожих сумок и туфлей" там работает либо 1в1, либо вообще мимо, а свои отделы не все держат, в плане API им бы зашло, но у меня косвенные контакты, на покупателя не выведу :)
ternaus Автор
Про разметку в плане классов я не очень понял.
В векторное представление я перегоняю комбинацией нейронных сетей, а сравниваю вектора, используя Faiss
В теории - да, на практике я не знаю. То есть да, это первая идея которая приходит в голову в обсуждении применения - по фото определять что за часы, галстук и джинсы на человеке и сразу ссылку на Amazon. И сколько-то проектов есть на эту тему, но почему-то чувство, что они не очень летят.
Kwent
То есть специальную сетку для получения векторов не тренируете, а берете готовые претрейны с обычной классификации вроде Imagenet? Вопрос да, откуда берутся эти сети
Про кейс - в том то и дело, что надо искать не те же часы, а похожие, грубо говоря эти не нравятся, а хочется "что-то вроде", внутри одного магазина, что-то вроде похожие товары, в случае одежды там сильно решает визуал, меты не всегда достаточно
ternaus Автор
Вот как раз где брать те сети, самому тренировать или брать чужиие и как это все комбинировать открытый. Как именно я это делаю оставим за кадром.
В целом - просто беру идеи с идущего сейчас ML соревнования в котором Google пытается разобраться как лучше это делать.
Блог пост на тему