
Данные из боевых баз в нашей архитектуре асинхронно попадают в аналитическое хранилище (Clickhouse), где уже аналитики создают дашборды для продуктовых команд и делают выборки. Базы здоровые и под ощутимой нагрузкой: мы в день отправляем флот самолётов средней авиакомпании, несколько поездов и кучу автобусов. Поэтому взаимодействий с продуктом много.
ETL-процесс (извлечение данных, трансформация и загрузка в хранилище) часто подразумевает сложную логику переноса данных, и изначально нет уверенности в том, что данные доставляются без потерь и ошибок. Мы используем Kafka как шину данных, промежуточные сервисы на Benthos для трансформации записей и отправки в Clickhouse. На этапе создания пайплайна нужно было убедиться в отсутствии потерь с нашей стороны и корректной логике записи в шину данных.
Проверять вручную расхождения каждый раз не хотелось, кроме того мы нуждались в сервисе, который умел бы сверять новые данные по расписанию и показывать наглядно, где и какие имеются расхождения. Поэтому мы сделали сервис сверок, о котором я и расскажу, потому что готовых решений не нашёл.
Что такое сервис сверок
Сервис забирает данные из базы-источника (в нашем случае — это реплика боевой базы — MySQL, MongoDB), берёт данные из базы, в которую данные доставляются (Clickhouse), сверяет данные между собой и выдаёт аналитику по тому, насколько эти данные корректно доехали.
Если в одной базе 10 тысяч, а в другой 10,1 или 9,6 — как вы поймёте дальше, что именно не приехало? Будете смотреть вручную или писать скрипт сверки? Разница между скриптом сверки и сервисом сверки уже после нескольких ручных сверок не очень большая.
В аналитическую базу данные складываются не по той же логике, что в production-базы. Данные могут трансформироваться или объединяться из нескольких таблиц в плоскую, чтобы дальше аналитик не делал сложные join-ы. Те же преобразования в обратном порядке выполняются при сравнении. Затем становится понятно, где проблемы.
Где могут быть проблемы
Проблемы встречаются на разных частях пути:
- Данные могут не отправляться в шину — например, сложная логика, модель заказа забирается из трёх таблиц. Где-то можно упустить отправку и данные не доедут, поэтому важно понять, какие именно данные не доезжают, иначе проверка руками займёт примерно вечность.
- Проблемы с переносом. Неправильно положили в шину, неправильно достали, не так трансформировали. Данные в таком случае имеют другой вид — начиная с лишних пробелов или других разрывов и заканчивая условным сложением вместо сложения по модулю.
- Технические проблемы. Например, сеть моргнула и не все данные доехали.
По итогу могу сказать, что только десятые доли процента в наших расхождениях приходились на технические проблемы сети. Остальное — логика.
Когда мы перетащили первые потоки в Clickhouse, мы предложили аналитикам использовать эти данные, ведь они удобнее и аналитическая база больше подходит под специфику запросов. По первым запросам было ясно, что данные расходятся, но был непонятен масштаб проблемы. В итоге сверка показала много косяков, до 70% расхождений в одной таблице. И выявить все типы ошибок помогли автоматические сверки, без которых такое можно либо никогда не заметить, либо работать с исключениями, либо время от времени писать кучу скриптов на проверки. Это долго. Потоки данных увеличиваются, неудобно руками сверять.
Как мы это реализовывали
Какие технологии?
При выборе стека технологий мы ориентировались на то, что данных будет много и в перспективе нужно будет каждый день сверять десятки таблиц. Сервис написали на Python + Spark, который выглядит хорошим кандидатом с учётом его параллелизации запросов и обработки данных.
Забираем данные
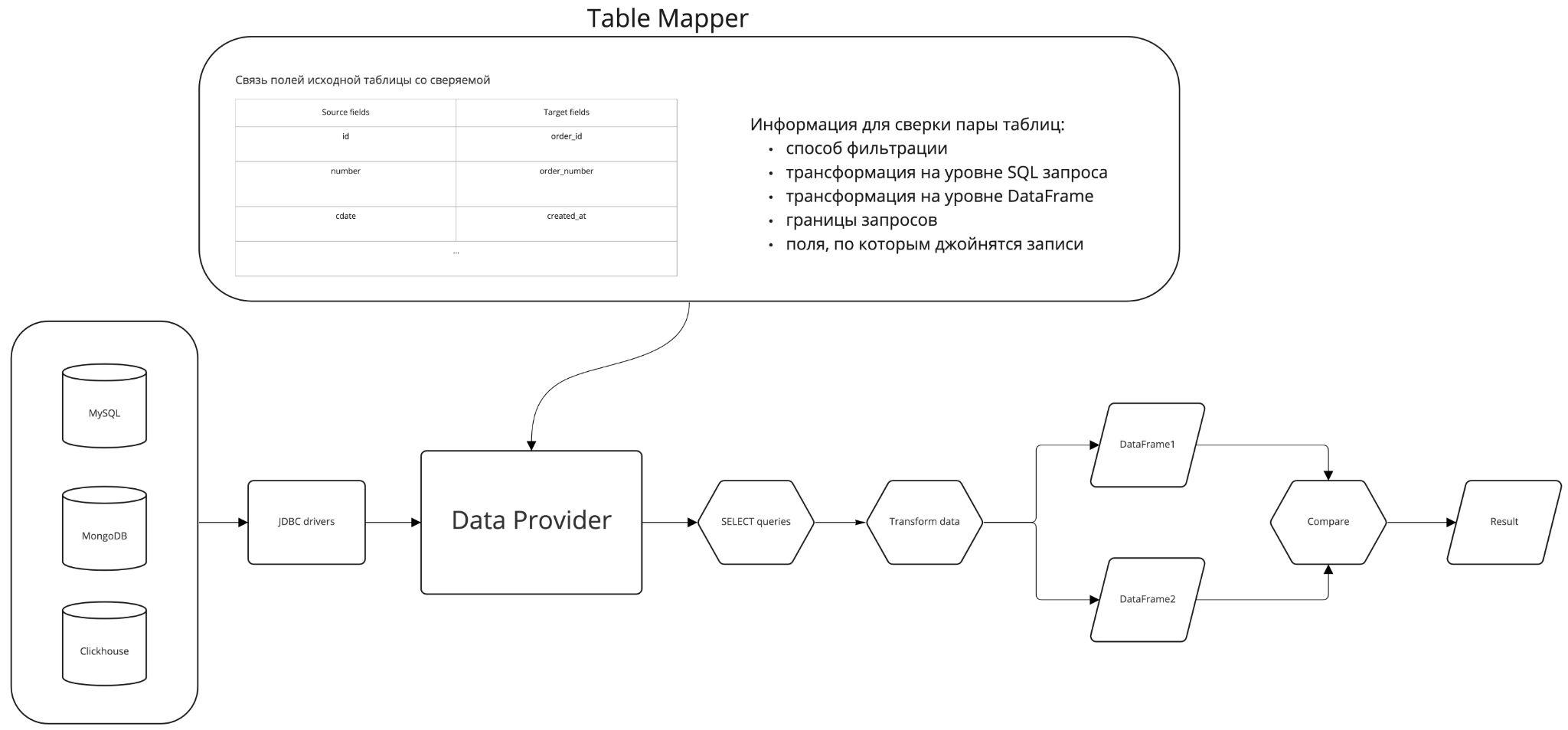
Для начала нужно было понять, как единообразно забирать данные из разных баз — в нашей компании используются MySQL, MongoDB, Clickhouse и т.д. JDBC-драйверы со Spark-ом с этим успешно справляются, что позволило единообразно подключаться к разным базам данных, вытаскивать оттуда данные и работать с ними как с DataFrame-ами (эта логика сосредоточена в сущности Data Provider на схеме).
Делим на партиции
У каждой базы есть свои синтаксические особенности SELECT-запросов. Поскольку у нас конечное количество памяти сервиса и мы не хотим аффектить базы своими запросами, вытаскивать данные будем партициями. Границы SELECT-запросов определяем сами, об остальном позаботится Spark: у него внутри есть свои партиции, которые позволяют выполнять все операции параллельно — от сбора данных до их обработки.
Как только мы получили нужные данные из таблиц, превращаем их в DataFrame и далее уже работаем индивидуально по каждой таблице.
Определяем таблицы
Следующим шагом нам нужно определить логику работы с данными в каждом конкретном случае, а именно: определить пару таблиц с их структурой и подготовкой данных. Желательно — без лишних заморочек и так, чтобы всем было понятно.
В лучшем случае — надо просто указать названия полей, которые нужно сверить между собой. В худшем — нужно данные предварительно преобразовать к одному виду.
Какие случаи нужно сразу иметь в виду?
- Данные могут агрегироваться: из нескольких исходных табличек данные могут попадать в одну плоскую табличку в целевом хранилище.
- Данные могут изменяться согласно некоторой логике.
- В разных базах могут быть свои особенности типов данных.
- Данные могут изначально храниться в json-формате (привет документоориентированным СУБД).
Конечно, этим всё не ограничивается, но в >90% случаев этого будет достаточно.
Определяем сверку
Итого в самом простом случае для новой сверки нужно создать два класса:
SPECIFIC_MAP_SCHEMA = [
M(source_field='id', target_field='id'),
M(source_field='state', target_field='state'),
M(source_field='cdate', target_field='cdate'),
M(source_field='mdate', target_field='mdate'),
]
SpecificMapConfig = MapConfiguration(
source_join_field='id',
target_join_field='ch_id',
source_partition_field='id',
target_partition_field='ch_id',
)Например, так в коде формируется SELECT-запрос с переданными параметрами:
query = """
select {comparison_fields}
from {db_table}
where {part_field} > {lower_bound} AND {part_field} <= {upper_bound} AND {filter_condition}
order by {part_field}
""".format(
comparison_fields=self.get_query_columns,
db_table=db_table,
lower_bound=lower_bound,
upper_bound=upper_bound,
part_field=self.partition_field,
filter_condition=self.filter_condition
)Непосредственно этап сверки
На этом этапе мы имеем два DataFrame-а с большим количеством данных (партиции), которые нужно сверить. Что это значит? Надо посчитать количество различающихся значений по каждому ID, залогировать примеры этих различий. Для этого нужно поджойнить данные по ID-записей:
import pyspark.sql.functions as sf
joined = df1.join(
df2,
get_join_condition(df1, df2, data1.join_field, data2.join_field),
how='inner'
)
def get_join_condition(df1: DataFrame, df2: DataFrame, df1_join_field: str, df2_join_field: str) -> t.List[t.Any]:
fields_join_condition = None
for df1_col, df2_col in zip(df1.columns, df2.columns):
if df1_col == df1_join_field and df2_col == df2_join_field:
continue
if fields_join_condition is None:
fields_join_condition = (sf.col(df1_col) != sf.col(df2_col))
continue
fields_join_condition |= (sf.col(df1_col) != sf.col(df2_col))
return [df1[df1_join_field] == df2[df2_join_field], fields_join_condition]Эта функция отрабатывает быстро, и этого достаточно, чтобы посчитать статистику по всей таблице. На больших данных (десятки миллионов записей с сотней столбцов) это также работает хорошо.
Когда что-то пошло не так
Сложность началась в момент, когда мы решили считать статистику по каждому столбцу в отдельности (процент расхождений, примеры). Здесь мы подошли к тому, что сложность работы со Spark для нас стала принципиальной. Потратив некоторое время на исследование, мы пришли к выводу, что простого и очевидного решения, как ускорить этот участок кода, нет. Можно было подключить spark extension библиотеку, реализованную на Scala, либо искать сложное решение в рамках работы с датафреймами, что за несколько попыток сделать не получилось. Мы пробовали использовать разные параметры партиционирования, но добиться желаемой скорости сравнения таблиц поколоночно не получилось. Само существование специальных библиотек на Scala для подобного подсчета различий в данных говорит о том, что нет готового и легкого API Dataframe для подсчета нужной нам статистики.
Spark показался достаточно сложным инструментом в разработке, требующим дополнительных знаний о его устройстве, но при этом у нас не было на изучение вглубь много времени в рамках проекта сверок.
Это не значит, что этот инструмент не стоит использовать в своих проектах, в других сервисах он у нас есть, но его сложность является важным фактором при выборе стека технологий. Мы наткнулись на это в сервисе сверок, получили новый опыт, пришли к выводу, что стоит отказаться от Spark в этом проекте и пошли дальше.
Какие есть альтернативы работы со Spark DataFrame? Конечно, это популярные для аналитики библиотеки Pandas и NumPy, которые также работают с DataFrame и массивами данных.
Просто ради примера, чтобы посчитать статистику по всем столбцам сразу, в случае векторизованных функий в NumPy достаточно сравнить две матрицы с одинаковыми размерностями:
np.array(diff_df[columns1]) == np.array(diff_df[columns2])Мы получим матрицу тех же размеров с True и False в случае совпадения и несовпадения значений. А далее столбцы уже можно просуммировать для получения процента расхождений.
А если нужно переопределить операцию сравнения:
diff = np.where([
self.compare_columns(diff_dataframe, join_field, column1, column2)
for column1, column2 in zip(df1.columns, df2.columns)
])И это все еще работает быстро!
Итого, если брать реализацию на Spark с перебором пар столбцов, табличка в десятки млн записей более 100 столбцов на нашей реализации с джойнами отрабатывала дольше, чем вышеуказанная реализация на NumPy. Последняя успевала отработать за 4-6 часов. И при этом не потребовалось никакой многопоточности и других усложнений, достаточно делить данные на партиции чтобы они помещались в память. Такой подход взлетел сразу.
Поскольку основная функция Spark — параллелизация — нам в конечном счете не пригодилась, в будущем мы планируем все-таки убрать использование этой технологии из проекта.
Результаты сверок
Что мы получаем в результате сверки?
- Информацию о количественных различиях в записях таблиц.
- Записи, которые есть в одной базе, и которых нет в другой.
- Информацию о проценте совпадающих данных по каждому столбцу.
- Примеры различий в каждом случае.
Как мы используем эти результаты?
Они помогают нам сформировать отчёт для команды, которая отвечает за эти данные, чтобы они поправили все проблемы в доставке данных.
Также эти результаты можно предъявить аналитикам и другим клиентам наших продуктов, чтобы они знали, на какие данные они могут полностью опираться, а какие ждут доработок.
Логи
В результате работы сверки мы получаем чудесные логи, которые отражают все проблемы в данных и примеры этих проблем:
- Rows count diff: 123 — количество различающихся записей
- Mismatched_rows: { 1, 5, 12, 20,… } — примеры ID записей, которые есть в одной базе, но нет в другой
- Rows values diff: 5 — количество различающихся значений.
- Column comparison: status, count: 6 — количество различающихся значений в каждом столбце (на графике уже считаем процент)
- Mismatched column column_name id: 123 != ch_id: 124 — примеры различающихся значений по каждому столбцу
Как мы считаем расхождения
Мы учитываем количество строк и количество различающихся значений в колонках для подсчёта расхождений.
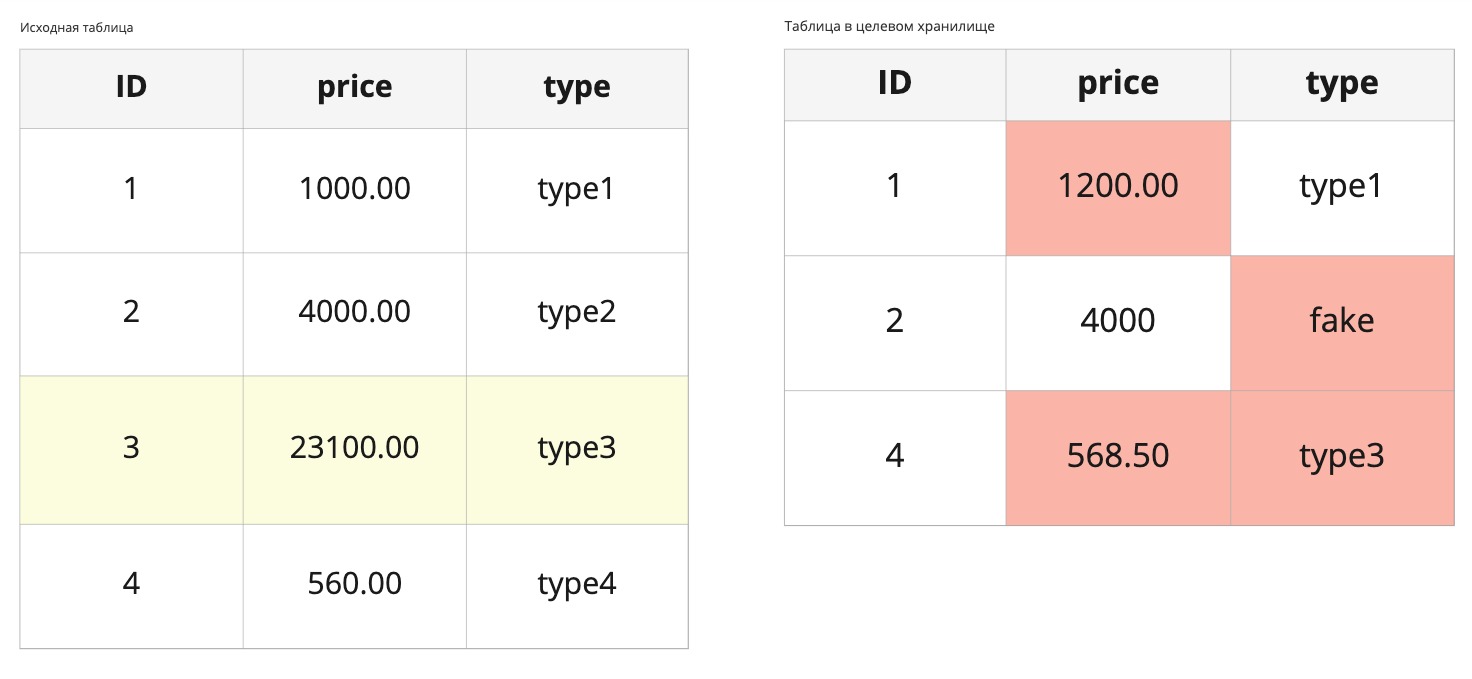
Если взять две таблицы из картинки ниже, то получим следующую математику:
Количество колонок: 3.
Количество строк: 4.
Всего значений: 3 * 4 = 12.
Кол-во различий в значениях: 4.
Процент расхождений в значениях: (4 / 12) * 100 = 33%.
Расхождения по количеству строк: 1.
Расхождений по количеству строк с учётом кол-ва колонок: (1 * 3) = 3.
Процент расхождений в значениях, учитывая пропущенные записи: ((4 + (1 * 3)) / 12) * 100 = 58,3%.
Общий процент расхождений: 58,3%.
Мониторинг
Мы используем этот сервис не только для разовых проверок, но для ежедневного мониторинга качества данных, которые доезжают в real-time-режиме. Для запуска регулярных задач на сверки таблиц мы используем airflow, а количественные результаты отображаем на дашборде. По мере необходимости также можно быстро добавлять сверки за последний день/неделю/месяц/всю историю.


SELECT-запросы не особо нагружают базу-источник, но мы всё равно на всякий случай обращаемся к ней по ночам, когда нагрузка минимальная. Ни разу не наблюдалось такого, чтобы сверка увеличивала нагрузку более-менее значимо.
Благодаря мониторингу любой человек в компании может зайти на дашборд и посмотреть корректность данных в аналитическом хранилище в любой момент времени. Например, если в бизнес-аналитике возникли неожиданные изменения, в первую очередь нужно убедиться, что с данными в аналитическом хранилище всё ок. Теперь это можно делать без лишних коммуникаций.
Как это поддерживается
Базу из миллиардов записей никто не пытается сверить напрямую. Самый простой способ — сверить количество записей: в одной базе 10 тысяч, в другой 10 тысяч. Значит, данные корректны. Но значения могут расходиться. Вопрос в том, какой процент потерь, огромный или незаметный.
Маппер для сверки двух таблиц в идеальном мире должен писаться сразу при создании потока данных в аналитическое хранилище самой командой разработки, но мы пока ещё не довели этот процесс до совершенства, чтобы можно было этот этап передавать разработчикам из продуктовых команд. Поэтому такой маппер сейчас делает инфраструктурная data-team (то есть мы). Расследованиями, соответственно, тоже занимаемся мы. Уходит плюс-минус по одному рабочему дню на таблицу: совсем быстро на маппер и существенно больше на разбор того, что случилось с недоставленными данными. Естественно, бывают сложные случаи с большими агрегациями на несколько дней, когда надо всё распутать, а бывает так, что таблица волшебным образом передаётся без потерь.
Вместо заключения
Сверки уже на первом этапе помогли нам исправить с десяток потоков данных. Аналитики начали доверять данным в аналитическом хранилище, в дальнейшем на них будут строиться новые витрины и переводиться старые.
Дальше мы планируем упростить создание новых сверок, отказаться полностью от Spark, добавлять новые потоки по запросу.
Статьи, которые мы писали ранее
Комментарии (19)

barloc
22.09.2022 16:43+1Выглядит как очень ресурсоемко и не совсем понятно какой риск вы закрываете.
Что должно случиться для расхождение между столбцами в одной строке?
И выглядит, что можно проще решать такие штуки через сверку распределений в двух датасетах - это будет дешевле, чем такой джойн.
gladkikhtutu Автор
22.09.2022 17:02+1Не более ресурсоемко, чем руками каждый поток данных сверять, учитывая что их со временем все больше становится, а новую сверку на обкатанном подходе добавить достаточно легко.
Причин для расхождений может быть много - например в столбце updated_at/modified_at не всегда актуальная дата приходит - надо разбираться, почему. Либо статусы заказов при отправке в шину маппятся не так как ожидается. Либо с форматом данных накосячили. Тут при желании можно на отдельную статью материала набрать :)
Насчет датасетов не совсем понял идею, привести данные к одному виду все равно придется, но было бы интересно узнать, если у вас есть альтернативное решение

sshikov
22.09.2022 20:46+1Мы пробовали контролировать путем вычисления некоторой функции свертки на одной стороне, и ее сравнения с такой же функцией на другой (контрольная сумма). Знаете, в чем проблема? Что пока сумма совпадает — все хорошо. А как только она расходится — становится совершенно невозможно понять, что именно не совпадает. То есть, функция должна быть не какая попало, а должна позволять диагностировать, в какой колонке расхождение. А при наличии нетривиальных типов данных (у автора есть json в колонках, а у нас просто есть различия в поддерживаемых типах данных на двух сторонах, скажем, timestamp with timezone где-то есть, а где-то его нет) становится совсем нетривиально, и проще иметь дело с самими данными — там хотя бы видно, где не совпало.
И еще, контрольная сумма или распределения — это тоже далеко не бесплатно с точки зрения ресурсов (особенно когда таблицы большие). И потом, они снова вам не показывают, что именно различается. Ну так, для примера, вот автор пишет: «Базу из миллиардов записей никто не пытается сверить напрямую.». Вообще говоря, на базе из миллиарда даже простой count(*) это далеко не бесплатно может оказаться, и не быстро. Быстро — это только из статистики можно взять, а статистика — она по определению может быть не актуальна.
Ivan22
22.09.2022 23:02ну так идеальная проверка будет такой же сложности как и исходный ETL - и работать столько же времени :)
gladkikhtutu Автор
23.09.2022 12:48В нашей компании сам ETL на самом деле достаточно ограниченный, это скорее доставка до stage-слоя сырых данных, с адаптированной структурой под хранилище. Основная трансформация происходит на слое витрин, но в этот момент мы уже имеем информацию о качестве этих данных.
Ivan22
23.09.2022 12:50так а качество витрин вы чтоли не проверяете??
Сами же пишете: "только десятые доли процента в наших расхождениях приходились на технические проблемы сети. Остальное — логика."
А витрины - это место концентрированной логики - там она прямо гнездится как пчелы в улье. Это самое то место за качеством данных в котором надо следить. Мы все DQ метрики в первую очередь для витрин и создаем
gladkikhtutu Автор
23.09.2022 13:27У нас в текущей организационной структуре нет большой боли в этом, витрины создаются и поддерживаются аналитиками, которые погружены в процессы изменения продуктов и специфику данных в них. И за качество витрин отвечают аналитики. То есть, проблемы на слое витрин тоже случаются, но гораздо реже.
Возможно, в будущем доберемся до DQ и в этом слое, но текущие сверки все таки ориентированы на качество данных в самом хранилище, и тут проблем оказалось достаточно
Ivan22
23.09.2022 15:09Видимо у вас модель 1:1 аля одна витрина на каждого аналитика. Все таки в более взрослой структуре - уже появляются общие витрины актуальные для многих людей или даже всей компании.И они должны быть 100% релевантными, т.к. на них уже базируется не песочница одного аналитика а отчетность для целых отделов или топов
sshikov
23.09.2022 18:20Ну, не обязательно. У нас ETL реплицирует 1:1, а все отчеты строятся потом, в хадупе. Поэтому логика проверки сводится к тупому равенству колонок (на самом деле не такому тупому, но это не важно). Сложность в плане объема конечно никуда не девается, и может например выглядеть так: репликация через OGG BD, приносит там миллиард изменений по таблице в сутки. После анализа оказывается, что это 250 миллионов уникальных ключей, то есть по одной записи была одна вставка, два обновления, и скажем одно удаление (ну или типа того). Следовательно, когда мы лезем за данными в источник, чтобы их сравнить, нам уже не нужен миллиард, достаточно в четыре раза меньше (понятно, при определенных условиях — что нам интересен только текущий срез данных, а не история). В общем, разница кое-какая есть, но в целом вы конечно правы — у нас одной из серьезных проблем является то, чтобы проверка не грузила базы данных настолько же, как репликация, и укладывалась в определенное время (ну хотя бы чтоб репликация + проверка в сутки уложились). Причем эти требования противоречивы — потому что ускорить мы скажем можем, распараллелив выборку, но нагрузка на базу при этом вырастет в разы, а уже скажем и ночь закончилась, и на базе уже люди работают, транзакции свежие и все такое.
Это отдельная большая история, впрочем.
gladkikhtutu Автор
23.09.2022 11:36+1Да, сумму можно использовать для предварительной оценки, что с данными все ок. Если не ок, то в дальнейших исследованиях это ничем не поможет.
А еще, я добавил абзац "Логи", чтобы было видно, что мы все проблемы видим сразу с примерами, и все проблемные ID-шники под рукой.
sshikov
22.09.2022 19:11+2готовых решений не нашёл
Думаю и не найдете. Вот смотрите, я делаю такой же сервис (ему уже лет пять или шесть). Он внутренний.
Потребности наши похожи, но в тоже время, постановка нашей задачи достаточно сильно отличается от того, что у вас. Я вообще не уверен, что это можно просто унифицировать. Например, возможно я не увидел, но у вас вообще не рассматривается вопрос, что источник и реплика не синхронны. В тоже время у нас это практически всегда так — репликация периодическая, и производится раз в сутки или в час. Всех устраивает Т-1 в реплике, потому что это система для отчетности. Соответственно, так как данные не синхронны, возникает вопрос синхронизации их на одно время. А лучше на одну транзакцию.gladkikhtutu Автор
23.09.2022 13:49Да, мы пока не уперлись в эту проблему, чтобы бороться с задержкой в синхронности реплики. Также какое-то время может уходить на доставку данных до хранилища. Если проблемы есть, они в любом случае проявятся на сверке после того как реплика будет синхронизирована, и запущена сверка, которую мы запускаем пока раз в сутки. Хотя для более чувствительных и важных данных возможно будем запускать чаще и проводить сверки за меньшие периоды.
На требование сверки в рамках одной транзакции конечно текущий сервис не заточен, но мы пока так нашли свой баланс между требованиями и вложениями в этот проект. В целом нет уверенности, что движение в эту сторону подсветит какие-то неизвестные проблемы с данными.
sshikov
23.09.2022 18:08Мы даже не пытаемся. Одну транзакцию можно более-менее гарантировать, если у вас есть привилегия и ваша база Oracle — тогда вы можете себе позволить AS OF scn, и наслаждаться. В остальных случаях — увы.
Но зато у нас при репликации нет никаких преобразований, кроме изменения типов данных (там где нет совместимых). Все прочие изменения производятся уже на хадупе, который является целью.

vasyaabr
23.09.2022 10:27+1У нас есть полностью аналогичная структура, множество продакшн-узлов на MySQL и один аналитический на Clickhouse. Тоже шина данных и весьма сложные процессы трансформации (вплоть до того что сверять по количеству нельзя, надо сверять суммы или другие показатели, да и таблицы не переносятся as is).
Но мы пошли немного другим, более простым, как мне кажется, путем: прокинули туннели от clickhouse к продакшн-базам, подключили их через движок clickhouse, дальше аналитики написали запросы для сверок, и мы обернули их в примитивную систему которая запускает запросы по крону и кидает алерты в слак, если запросы что-то возвращают (разницы).
Это работает, и при том довольно легко масштабируется и дорабатывается. С учетом того что clickhouse выполняет всю работу с данными - ещё и достаточно быстро.
Ivan22
по-скольку скрипты сверки такой же сложности как и исходные скрипты трансформаций - как доверять тому что сами скрипты сверки верные?
gladkikhtutu Автор
Мы пока не преисполнились настолько, чтобы писать тесты на тесты, но всё же сверки это проще, чем целый пайплайн данных. Начиная с того, что проблемы могут возникать в отправке данных из продуктов, а исходной табличке мы верим изначально. В целом по запросам аналитиков и ручным действиям новых проблем, которые бы не показали сверки, найдено не было, поэтому пока нет причин им не доверять.
К тому же за трансформацию и отправку данных в Clickhouse у нас отвечают сервисы, написанные на Benthos (он позволяет в декларативном стиле на yaml-е описать правила трансформации), что совсем не похоже на сервис на Python. Поэтому разница в подходах помогает подсветить все несовпадения.
Ivan22
а что делать с тем что при изменении логики пайплайна - тесты сами автоматически не меняются?
gladkikhtutu Автор
В плане поддержки и мониторинга, конечно, нужен баланс, между количеством сверяемых данных и частотой обновления схем. Пока мы актуализируем схемы вручную, тут ничего хитрого еще не изобретали. Когда сделаем единый дата-каталог, возможно, с его помощью будет легче это автоматизировать, но пока выглядит как overengineering в наших масштабах