
На собеседованиях с программистами я часто прошу их написать простую программу, подсчитывающую частотность слов в текстовом файле. Это хорошая задача, проверяющая множество навыков, а уточняющие вопросы позволяют зайти на удивление глубоко.
Один из моих уточняющих вопросов такой: «Что является узким местом производительности вашей программы?» Многие отвечают что-то типа «считывание из входящего файла».
На самом деле, написать эту статью меня вдохновил ответ на чей-то вопрос в Gopher Slack: «Я заметил, что много дополнительной работы приходится на разделение строки и тому подобное, но обычно всё это намного быстрее ввода-вывода, поэтому нас это не волнует».
Я не стал спорить… и пока не проанализировал производительность задачи с подсчётом слов, думал так же. Ведь всех нас этому учили, правда? «Ввод-вывод — это медленно».
Но это больше не так! Дисковый ввод-вывод мог быть медленным 10-20 лет назад, но 2022 году последовательное считывание файла с диска выполняется очень быстро.
Насколько же быстро? Я протестировал скорость чтения и записи моего ноутбука при помощи этой методики, но с параметром
count=4096, то есть с чтением и записью 4 ГБ. Вот результаты, полученные на моём Dell XPS 13 Plus 2022 года с накопителем Samsung PM9A1 NVMe и Ubuntu 22.04:| Тип ввода-вывода | Скорость (ГБ/с) |
|---|---|
| Чтение (без кэширования) | 1,7 |
| Чтение (с кэшированием) | 10,8 |
| Запись (с учётом времени синхронизации) | 1,2 |
| Запись (без учёта синхронизации) | 1,6 |
Разумеется, системные вызовы относительно медленны, но при последовательном чтении или записи один syscall нужно выполнять через каждые 4 КБ или 64 КБ (или другую величину, в зависимости от размера буфера). А ввод-вывод по сети по-прежнему медленный, особенно в нелокальной сети.
Так что же является узким местом в программе, считающей частотность слов? Это обработка или парсинг входящих данных, а также соответствующее распределение памяти: разбиение входящих данных на слова, преобразование в нижний регистр и подсчёт частотностей при помощи таблицы хэшей.
Я модифицировал свои программы подсчёта слов на Python и Go так, чтобы фиксировать время разных этапов процесса: считывания входящих данных, обработки (медленная часть), сортировки по самым частым и вывода. Потом выполнил проверку на текстовом файле размером 413 МБ, то есть на приличном объёме входящих данных (100 конкатенированных копий текста Библии короля Якова).
Ниже показаны усреднённые результаты трёх лучших прогонов в секундах:
| Этап | Python | Go (простая) | Go (оптимизированная) |
|---|---|---|---|
| Чтение | 0,384 | 0,499 | 0,154 |
| Обработка | 7,980 | 3,492 | 2,249 |
| Сортировка | 0,005 | 0,002 | 0,002 |
| Вывод | 0,010 | 0,009 | 0,010 |
| Всего | 8,386 | 4,000 | 2,414 |
Сортировка и вывод занимают пренебрежимо мало времени: так как входящие данные состоят из 100 копий, количество уникальных слов относительно невелико. Примечание: это приводит к ещё одному уточняющему вопросу на собеседовании. Некоторые кандидаты говорят, что узким местом будет сортировка, потому что её сложность O(N log N), а не обработка входящих данных, сложность которой O(N). Однако здесь легко забыть, что мы имеем дело с двумя разными N: общим количеством слов в файле и количеством уникальных слов.
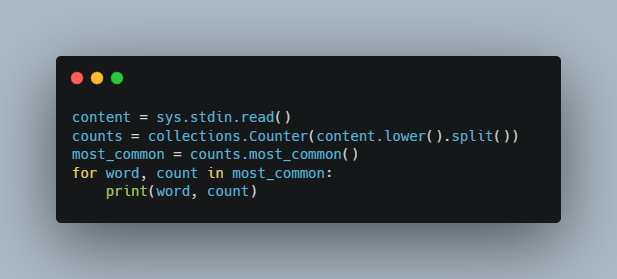
Внутренняя работа версии на Python сводится к нескольким строкам кода:
content = sys.stdin.read()
counts = collections.Counter(content.lower().split())
most_common = counts.most_common()
for word, count in most_common:
print(word, count)На Python запросто можно выполнять построчное чтение, однако это немного медленнее, поэтому здесь я просто считываю весь файл в память и обрабатываю его за раз.
В простой версии на Go используется тот же подход, однако стандартная библиотека Go не содержит
collections.Counter, поэтому выполнять сортировку «самых частых» нам нужно самостоятельно.Оптимизированная версия на Go существенно быстрее, однако и гораздо сложнее. Мы избегаем большинства распределений памяти, выполняя преобразования в нижний регистр и разделяя текст на слова с замещением. Это хорошее эмпирическое правило для оптимизации кода с интенсивными вычислениями: снижайте количество распределений памяти. Информацию о том, как это профилировать, читайте в моей статье об оптимизации подсчёта количества слов.
Я не показал оптимизированную версию на Python, потому что сложно оптимизировать Python ещё сильнее! (Время снизилось с 8,4 до 7,5 секунды). Код уже и так быстр, потому что базовые операции выполняются в коде на C; именно поэтому часто не важно, что «Python медленный».
Как видите, дисковый ввод-вывод в простой версии на Go занимает всего 14% от времени выполнения. В оптимизированной версии мы ускорили и чтение, и обработку, и дисковый ввод-вывод занимает всего 7% от общего времени.
Какой же я делаю вывод? Если вы обрабатываете «big data», то дисковый ввод-вывод, вероятно, не будет узким местом. Даже поверхностные измерения дадут понять, что основное время тратится на парсинг и распределение памяти.
Комментарии (23)

Brak0del
28.11.2022 15:06+5последовательное считывание файла с диска выполняется очень быстро
Поверхностное гугление показывает, что производительность чтения из кэша процессора составляет порядка терабайта/с, производительность чтения из RAM порядка 40ГБ/с. Т.е. диск всё ещё на 3 порядка отстаёт от кэша примерно как и в старые добрые времена, и на полтора от RAM.
Ниже показаны усреднённые результаты трёх лучших прогонов в секундах:
Сразу вопросы к эксперименту: у дисков есть свои кэши, последовательные прогоны в поисках лучшего наверняка осядут в этих кэшах и результаты будут уже не те, как по первому разу. Также наверно и в RAM после первого эксперимента прочитанное с диска частично тоже где-то закэшируется.

baldr
28.11.2022 15:16+4Диски-то тоже разные. Конечно, у большинства сейчас SSD в новейших макбуках. Но HDD тоже встречаются пока еще. А еще сетевые диски бывают. Например, в AWS облаке GP2 диски вообще хз что из себя представляют - там вполне может быть файл размазан по нескольким сетевым дискам и кроме вас еще 200 серверов с ними сейчас работают и время доступа будет непредсказуемым и нелинейным.

lgorSL
28.11.2022 18:28+3Позвольте уточнить - современные м.2 ssd способны читать последовательные данные со скоростью 7 Гб/секунду. ОС, файловая система и т.п. могут накладывать оверхед, но я предлагаю отталкиваться именно от теоретической верхней границы, как и для 40 Гб/сек для оперативной памяти.
Мне кажется, на старых компьютерах с жёсткими дисками соотношение скоростей было совсем не таким.
Переход от жёстких дисков к ssd m.2 выглядит действительно прорывом - раньше по sata нельзя было передавать больше 550 Мегабайт в секунду (на практике диски достигали 100-150 мегабайт в секунду при последовательном чтении), а рандомное чтение вызывало задержки, измеряемые в миллисекундах.
Сравнить 150 мегабайт/сек старого жёсткого диска и 7 гигабайт нового ссд - разница полтора порядка.
По оперативной памяти тоже есть прогресс, но не такой радикальный

LordDarklight
29.11.2022 15:36+1Ну вы и сравнили - старую практику и современный теоретический потолок

ReadOnlySadUser
28.11.2022 16:11+3Ну, из "ввод/вывод" в статье рассмотрен только ввод. Да и, в общем-то, мизерного объёма данных)
Что касаемо основного вопроса («Что является узким местом производительности вашей программы?), то единственный правильный ответ тут: без бенчмарков разговор бессмысленен :)

SadOcean
28.11.2022 16:38Очень спортное утверждение, все еще не подтвержденное ничем.
С точки зрения быстродействия процессора и чтение из случайного места ОП - медленное так то. И есть методики (типа ESC или векторизации), которые наглядно демонстрируют, насколько.
Поэтому то, насколько быстрее стали диски, все еще не опровергает утверждение, что I/O медленное.

mogaika
28.11.2022 19:53Первое апреля? Правда смешно! Особенно когда увидел что это в хабах "Совершенный код" и "Клиентская оптимизация"

thevlad
28.11.2022 20:52+1Хорошо бы еще помнить, что помимо throughput есть и latency. И совершенно различные паттерны доступа.

GbrtR
28.11.2022 22:28+1Есть очень интересная страничка с интерактиными измененниями latency по годам.
Последние данные за 2020


michael_v89
29.11.2022 00:00На одной работе было такое приложение. Есть хранилище с несколькими миллиардами документов, надо их проиндексировать. Надо получить порцию данных (20000 документов), декодировать JSON, взять поле, декодировать Base64, декодировать JSON еще раз, взять список полей, сгенерировать XML, вывести в STDOUT, который читает индексатор. Обработка на PHP. Сеть работала быстро, вывод в STDOUT тоже, тормозил PHP. Сделали много параллельных процессов по числу ядер на сервере со сбором данных в главном процессе и запуск с небольшой задержкой, чтобы не все сразу лезли в сеть. Тогда стало упираться в работу индексатора.
Когда много данных и работы со строками, сеть перестает быть узким местом.
LordDarklight
29.11.2022 15:52+1413Мб - это даже близко не BigData. Начали бы хотя бы с 413Гб - да и слов уникальных бы побольше (для теста можно брать не слова из текста а парные сочетания всех слов друг с другом, ну и книжек заодно не одну взять а 1000). А так вообще-то боле менее серьёзный уровень BigData обозначился бы на 413Тб или 413Пб - но это в "домашних" условиях уже моделировать очень сложно. Но и 413Гб началась бы уже совсем другая кухня - где текст так просто в память целиком не загнать. А с большим количеством слов (или как я предложил - парных словосочетаний из 1000 книг - ну или программно сгенерированный источник с миллиардами таких вот "сочетаний") началась бы ещё и проблема с хранением статистического массива. Да BigData - это не шутки, там совсем другие законы и подходы. Но, у Вас в компании видимо совсем не уровень BigData раз это всё для Вас не важно.
И как можно говорить об оптимизации и BigData, когда нет параллельной обработки (тем более то на Go) - а там сразу ещё и задачи конкуренции возникают (что тоже на собеседовании проверять неплохо бы).
Да и если говорить о файле (даже если он один - что даже интереснее, но в BigData такое бывает редко) очень большого объёма - то даже его чтение можно было бы немного распараллелить - раз ввод-вывод занимает почти на порядок меньше времени чем обработка!
И всё надо асинхронизировать!
А уж сколько оптимизационных финтов при обработке пропущено - да хотя бы то, что слова сразу можно было бы разделить по просто определяемым группам - и делать поиск только в нужной группе (например - поделив их по длинам, но можно и по другим критериям, например просто по первой букве, или вычислять простой числовой хеш и по нему определять подгруппу) - в общем организовать картотеку - а не единый массив. С выделением памяти тоже много чего упущено!

hard_sign
29.11.2022 22:47Как говорится, +1
Более того, для сетевого ввода это тоже может быть верно.
Пример – чтение таблицы целиком из PostgreSQL (SELECT * FROM <TABLE>) в Perl при помощи fetchall_arrayref. Если просто читать данные, то память под массив с результатом выделяется один раз, и чтение занимает примерно Х времени. А если попытаться эти данные обрабатывать, передавая полученный массив аргументом в какую-нибудь функцию, то уже 5×Х
aywan
30.11.2022 18:47Как показывает моя практика, чаще бывает так, что программисты в принципе не понимают как работает та или иная вещь на низком уровне. Как пример тоже самое выделение памяти, когда и в какой момент память копируется или возвращается по ссылке. При этом на ревью боятся если встречают 3 вложенных цикла и говорят что это слишком дорого, не приводя аргументов)

fireSparrow
30.11.2022 20:30А почему вы называете этих людей программистами?
Как-то странно выносить какие-то суждения о программистах вообще, приводя в пример людей, очевидно не являющихся квалифицированными программистами.LordDarklight
01.12.2022 09:56+1Не все же системные программисты, и не все даже знакомы с с Си и C++. Да и под разными средами исполнения память выделяется по-разному. "Управляемые приложения", в т.ч. скриптовые вообще создавались так, чтобы программисты меньше задумывались над этим вопросом. Хотя, вот C# - например не так уж прост вопросах выделения памяти (чем, скажем Java), особенно с версии NET CORE 3 - но там своя кухня и нюансы. И не надо говорить - что люди разрабатывающие приложения на высокоуровневых ЯП - не программисты, раз не углубляются в особенности памяти. Они да - не системные, а прикладные программисты. И современные ЯП развиваются так, чтобы разработка приложений на них шла так, чтобы больше думать о прикладной логике, чем о низкоуровневых заморочках. И даже BigData идёт путём к тому, чтобы меньше думать о нюансах той или иной низкоуровневой прослойки платформы, и больше об оптимизации логики обработки больших массивов. Мне трудно представить каким была бы разработка сайтов или прикладных приложений баз данных, если бы программистам приходилось думать о тонкостях выделения памяти
fireSparrow
01.12.2022 12:28Ну, я впервые узнал, что передача значения может быть копированием либо по ссылке, будучи чистым питон-программистом. Просто потому, что эти темы всё равно всплывают, когда начинаешь разбираться, почему код работает так как он работает — даже если это высокоуровневый язык.
vadimr
Естественно, что если 400 мегов зашарашить в оперативную память и там начать из них устраивать и реорганизовывать всякие коллекции, то производительность будет небольшой и по времени, и по памяти. А если 400 гигов, так вообще всё навернётся. Неверной дорогой идёте, товарищи.
Там в английской статье, на которую стоит ссылка, показано, что grep работает в 50 раз быстрее.
stdrone
работает быстрее по сравнению с чем?
Note that
grepandwcdon’t actually solve the word counting problem, they’re just here for comparison.vadimr
Чтоб сосчитать слова, в подавляющем большинстве случаев достаточно одного прохода по тексту, что и делают grep и wc. И пары массивов – например, счётчик частот, индексируемый 16- или 24-разрядным самым тупым хешем, и ссылки на сами слова (или их позиции в файле, если не хотим читать файл целиком). Только для разрешения коллизий хеша придётся делать второй проход.
arheops
Я недавно реально подофигел, что grep работает даже быстрее индекса в mysql
Тоесть на моих данных выгоднее выгрузить спискок в файл и пройти grep, чем искать с использованием индекса в памяти.
grep реально быстро работает.
mixsture
Думаю потому, что индексы оптимизированы для совпадения слева. А вы скорее всего ищете слова в центре и тогда индекс превращается в просто сокращенную версию таблицы, которую СУБД и перебирает — что, конечно, лучше перебора исходной полной таблицы, но сильно хуже поиска по двоичному дереву. Grep, подозреваю, выигрывает потому, что читает данные бОльшими порциями относительно mysql.
arheops
Неа, слева, от 3 до 8 символов, только цифры. Таблица в 30млн.
LordDarklight
Смотря какой Индекс Вы имели в виду