Вовремя обратить внимание на желание сотрудника сменить работу, понять, что стало причиной и попробовать сохранить кадры – задачи, с которыми очень часто сталкиваются HR и пытаются справиться своими методами. Мы в НОРБИТ нашли техническое решение для этой проблемы, основанное на применении искусственного интеллекта.

Обычно борьба с кадровой текучкой разбивается на две разные задачи.
Заблаговременный подбор профильных специалистов – чаще задача более релевантна для сотрудников на массовых должностях. Например, для операторов колл-центра, где, с одной стороны, важно не допустить сокращение штата, а с другой - не держать сотрудников без рабочей нагрузки.
Удержание ценных кадров. Это особенно актуально для наукоемких отраслей и высококвалифицированных специалистов, серьезно вовлеченных в специфику задач компании. Это, в частности, разработчики ПО для специфических платформенных решений.
Так как наша компания работает в сфере информационных технологий и большинство наших сотрудников как раз и являются такими высококвалифицированными специалистами, именно вторая задача для нас наиболее интересна.
Для ее решения мы пошли дальше и разработали HR-платформу с интеллектуальной системой оценки вероятности увольнения каждого сотрудника с использованием Data Science технологий. Алгоритмы позволяют находить характерные паттерны, которые могут свидетельствовать о возможном желании сотрудника сменить место работы.
Несколько примеров таких паттернов.
Сотрудник внезапно уходит в более продолжительный отпуск (сравниваем со средним количеством дней во всех остальных).
Чаще берет выходные дни за свой счет (сопоставляем со средним числом дней в более ранние периоды).
Посещает сайты по поиску работы.
Качество действия прогнозных моделей зависит от уровня цифровизации и объема информации в учетных кадровых системах, а также глубины накопленных исторических данных. В одних компаниях есть доступ только к данным корпоративного exchange mail-сервера о переписке сотрудников, а в других можно даже использовать информацию о MCC-кодах (четырехзначный код, который присваивается торговой точке в зависимости от ее вида деятельности) в транзакциях сотрудников или видеоаналитику с типами активности на рабочем месте.
Еще примеры данных, которые можно использовать для улучшения качества моделирования:
данные СКУД;
записи разговоров в колл-центре;
посещение сайтов для поиска работы;
среднее время ответа на сообщения;
количество писем в день;
число проектов, над которыми работает сотрудник;
количество дней с последнего технического ассессмента.
Архитектура типового решения в зависимости от используемого стека организации может выглядеть примерно так:

Принцип работы
По расписанию (например, раз в месяц) загружаются данные из всех корпоративных систем-источников.
Из полученных данных формируются доработки для дальнейшего обучения и прогнозирования.
С установленной периодичностью запускается DAG airflow со скриптами переобучения моделей на основе сгенерированных пользовательских фич. Обученные модели вместе с метриками загружаются в виде артефактов с помощью MLflow в S3 (Minio) и БД.
Для запуска прогнозов из MLflow берется модель с наилучшими показателями метрик. Модель готовит прогноз на следующий отчетный период, в который включает сотрудников, склонных к оттоку.
Затем запускается скрипт по формированию рекомендаций по удержанию.
После получения прогнозов стартует скрипт поиска линейных руководителей тех сотрудников, которые попали в прогноз оттока, и система отправляет письма с рекомендациями по удержанию и ссылками на отчет (например, в SuperSet).
MLflow — это платформа, предназначенная для управления жизненным циклом моделей машинного обучения, которая в данной задаче упрощает процесс выкатки моделей в прод, а также мониторинг моделей машинного обучения. MLflow позволяет версионировать обученные модели, сохранять различные артефакты, например, метрики, и предоставляет возможность выбирать, какая из моделей будет использоваться в самом продукте.
У MLflow есть хорошие реализации методов автоматического логирования для различных библиотек машинного обучения, которые значительно упрощают версионирование моделей и их артефактов (список их можно посмотреть здесь). В платформе использован четвертый сценарий, когда S3(Minio) выступает в качестве хранилища моделей, а Postgres – для хранения метрик.
В этом списке нет, например, catboost (он применяется при прогнозировании). Поэтому модуль autolog не используется в коде. Ниже приведен код декоратора, логирующий необходимые артефакты при обучении.
def mlflow_train(train_function):
def _train_with_mlflow(self, df):
model, algorithm_name, metrics, params = train_function(self, df)
model_save_path = _get_path_for_model(self, model_path=self.save_path)
artifacts = _create_artifacts_dict(model_save_path)
wrapped_model = ModelWrapper(model, model_save_path)
with mlflow.start_run() as active_run:
mlflow.log_params(params)
mlflow.log_param("algorithm_name", algorithm_name)
mlflow.log_metrics(metrics)
mlflow.pyfunc.log_model(
artifact_path=model_save_path,
python_model=wrapped_model,
artifacts=artifacts,
)
return
return _train_with_mlflowДля логирования самой модели используется метод mlflow.pyfunc.log_model, который на вход принимает инстанс класса ModelWrapper, наследуемый от PythonModel
class ModelWrapper(mlflow.pyfunc.PythonModel):
"""
Class to train and use Models
"""
def __init__(self, model, model_save_path):
self.model = model
self.path = model_save_path
def load_context(self, context):
"""
This method is called when loading an MLflow model with pyfunc.load_model(), as soon as the Python Model is constructed.
Args:
context: MLflow context where the model artifact is stored.
"""
self.model = pickle.load(open(context.artifacts["model_path"], "rb"))
def predict(self, context, model_input):
"""This is an abstract function. We customized it into a method to fetch the model.
Args:
context ([type]): MLflow context where the model artifact is stored.
model_input ([type]): the input data to fit into the model.
Returns:
[type]: the loaded model artifact.
"""
return self.model.predict(model_input)Разработка модели
Задачу предсказания оттока можно переформулировать следующим образом: для каждого сотрудника определить вероятность ухода в следующие n месяцев (дней, недель).
При разработке платформы мы опросили несколько компаний и пришли к выводу, что оптимальный горизонт прогноза – четыре месяца. Меньший срок реализовать сложно из-за задержек поступления в кадровые системы обновленной информации (так, получение бонуса сотрудником может привести к снижению вероятности оттока, но данные об этом появятся только в следующем месяце). Предсказание на больший срок тоже не стоит рассматривать, мир вокруг меняется слишком быстро и сложно представить, что будет через условные месяцев восемь.
Создание датасета для модели происходит следующим образом: по окончании каждого месяца работы сотрудника получаем его характеристики, после преобразования они станут факторами для нашего датасета. Обычно набирается от 40 до 300 таких факторов. Также фиксируем целевую переменную для модели машинного обучения – факт увольнения в течение выбранного периода.

Очевидно, что количество людей, которые остались работать, и тех, кто уволился из компании, за месяц различается в разы, и выборка получается несбалансированной. Модели машинного обучения не всегда хорошо работают с такими данными. Для борьбы со снижением качества из-за дисбаланса, можно, например, воспользоваться библиотекой SMOTE. Она создает искусственные данные, тем самым выравнивая количество сотрудников, которые ушли и которые остались.
Ниже представлена работа данной библиотеки.
Для примера генерируем искусственные данные в соотношении 99:1 и визуализируем их:
X, y = make_classification(n_samples = 10000, n_features = 2,
n_redundant = 0, n_clusters_per_class = 1, weights = [0.99], flip_y = 0, random_state = 1)
counter = Counter(y)
print(counter)
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()Код для создания и отрисовки данных

Применим библиотеку SMOTE для выравнивания отношения классов:
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
counter = Counter(y)
print(counter)
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
pyplot.show()Применение библиотеки SMOTE

На следующем шаге, после feature engineering, нужно выбрать модель машинного обучения, которая хорошо решает задачу классификации. В подобных задачах часто лучше всего себя показывает градиентный бустинг. Стоит попробовать и другие модели машинного обучения, но в нашем случае все они уступили в бенчмарках по результатам именно бустингу.
В ходе экспериментов было протестировано три модели градиентного бустинга: lightgbm, xgboost и catboost. Последний показал наилучшие метрики, поэтому было принято решение в продакшн использовать catboost.
def _get_prediction_label(prediction):
return 1 if prediction > TRESHOLD else 0
def get_metrics(X, y, model):
prediction = model.predict_proba(X)[:, 1]
prediction_label = prediction.map(_get_prediction_label)
return {
'roc_auc_score': roc_auc_score(y, prediction),
'accuracy_score': accuracy_score(y, prediction_label),
'precision_score': precision_score(y, prediction_label),
'recall_score': recall_score(y, prediction_label),
'f1_score': f1_score(y, prediction_label),
'confusion_matrix': confusion_matrix(y, prediction_label)
}Код для получения метрик
Метрики


В данном примере модель catboost предсказала, что есть 15 сотрудников, которые хотят покинуть компанию. 10 из них действительно уволились. Также были 19 человек, которые тоже ушли, но модель этого не предсказала.
Во время обучения модели используется метрика roc auc, о которой хорошо рассказано здесь. При оценке результатов прогнозирования рассматриваются precision, recall, а также f-score, которые демонстрируют, насколько хорошо алгоритм умеет детектировать сотрудников, склонных к оттоку.
Здесь следует упомянуть о случаях, когда модель верно предсказала намерения сотрудника, но, благодаря рекомендациям, человека удалось удержать в компании. Такие случаи сложно или невозможно отследить. Это создает проблему в будущем при обучении модели на подобного рода данных, так как сотрудников со схожими поведенческими паттернами следует классифицировать как склонных к оттоку.
Если у вас есть идеи, как можно решить эту проблему, поделитесь, пожалуйста, в комментариях.
Рекомендации по удержанию сотрудников

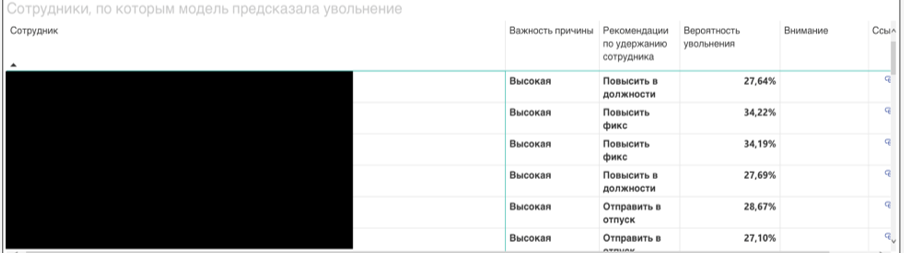
Следующий шаг в разработке платформы – внедрение в бизнес-процессы компании результатов прогноза, а именно уведомление линейных руководителей о том, что их подчиненные попали в зону риска. Просто сообщения «Петров с вероятностью 89% уволится» недостаточно для принятия управленческого решения, поэтому есть необходимость в разработке модуля рекомендаций.
Для сотрудников с наибольшей вероятностью оттока определяем возможные причины ухода, признаки, которые оказали наибольшее влияние.
Среди них могут оказаться:
количество дней с технического ассессмента,
сумма бонусов,
отсутствие отпуска.
Для каждого сотрудника в прогнозе платформа определяет, какие признаки больше всего отклоняются от средних значений, затем готовится понятная рекомендация для HR или линейного руководителя, что делать:
направить на дополнительное обучение по направлению,
отправить в отпуск на … дней,
дать проект в … области,
провести личную встречу.
Модуль отчетности
В нашем решении используется генератор отчетов в Excel. Он по расписанию ежемесячно отправляет линейным руководителям список сотрудников, которые попадают в отчет.

При ежемесячном запуске скриптов происходит обновление базы данных, таблички из которой подтягиваются в Power BI.

Выводы
Платформу не следуют воспринимать как человека, стоящего за спиной каждого сотрудника. Это, скорее, напоминалка для руководителей, что кому-то стоит порекомендовать сходить в отпуск, повысить зарплату, дать новый интересный проект, просто обратить внимание на те или иные проблемы и наконец с сотрудником нужно просто поговорить. Также стоит сказать, что ни сама модель, ни строящий ее специалист, не знают фамилии сотрудников, видны лишь абстрактные идентификаторы, которые ничего не говорят о самом человеке.
Такое предсказание увольнения – шанс для компании сохранить ценные кадры, а для человека – получить столь необходимую поддержку руководителя.
Комментарии (18)

pehat
20.12.2022 11:05+10Конечно, сотрудники уходят от того, что проклятый линкедин посещают, а не потому что начальник мудак и расти некуда. Больше надзора за скотом!

ddemidov
20.12.2022 12:30+1ну смысл статьи в другом :-)
Я бы даже сказал что больше надзора за менеджерами даже :-)

dairok Автор
20.12.2022 12:36+3Причины увольнений могут быть совершенно разные, в том числе и про взаимоотношения с руководством. Система только подсвечивает возможные проблемы, решение увольняться или нет всегда остается только за сотрудником.

shybovycha
21.12.2022 06:12мне кажется что модель не совсем правильная - система подсвечивает (категоризирует сотрудников) только проблеммы которые вы ей показали. а показали выпо сути "негативное настроение" (из записей разговоров), "долго не было отпуска" (среднее по больнице), "долго на одном проекте" (мало того что среднее по больнице - так еще и крайне субъективно), "редко ассессмент".
в то время как причины могут на самом деле быть совершенно другие - неинтересные задачи, много задач не из джиры, несоответствие рабочих задач с требованиями от позиции, "перерост" позиции, несоответствие вознаграждения и позиции.
много из этих пунктов достаточно сложно отследить автоматически. тот же employee engagement - даже если попросить сотрудников заполнить форму, нужно чтобы она была максимально правдиво заполнена, без боязни сотрудников получить backfire от менеджера, а это - долго и тонко надо выстраивать отношения и процессы в фирме, а не трекать все переписки и разговоры.
ddemidov
21.12.2022 09:13Естественно что эта модель работает на тех данных которые есть. С учетом развития текущих моделей для работы с текстом я предполагаю что через некоторое время можно будет анализировать комменты руководителя в жире :-). Но пока это за гранью доступного из-за сложной структуры таких данных.


ReadOnlySadUser
20.12.2022 11:10+5Платформу не следуют воспринимать как человека, стоящего за спиной каждого сотрудника
А почему? Ведь в сущности ровно это она и делает. Если что-то можно использовать как инструмент давления на сотрудника - это рано или поздно будет сделано. Ни разу не видел исключений из этого правила.
dairok Автор
20.12.2022 12:35+2Так можно про любую систему сказать. Jira тоже следит за выполнением задач сотрудников, но никто же не отрицает пользу таск-менеджеров
ReadOnlySadUser
20.12.2022 13:26+4Вы только забываете, что эта польза не для сотрудников) Мне как линейному разрабу от всего этого пользы никакой и чем больше шпионского ПО использует работодатель, тем меньше мне с ним хочется работать.
Предлагаемая вами система - это типичный пример такого ПО :) Можно декларировать любые благородные цели, но правда в том, что использовать этот AI будет бесчеловечная корпоративная машина со всеми вытекающими)


KongEnGe
20.12.2022 13:30+2Еще примеры данных, которые можно использовать для улучшения качества моделирования
Не хватает номограммы, связывающей нагрев паяльника и сговорчивость пока еще сотрудника на ежегодном ревью производительности.
Все эти "да мы про тебя такое знаем, чего ты сам не понимаешь" -- нехороший такой колокольчик, свойственный очень специфическим местам работы.

diogen4212
21.12.2022 00:12«Ведущая многопрофильная группа ИТ-компаний в РФ» — вполне ожидаемая «специфичность». Как и многих крупных компаний.


gesitnikov
21.12.2022 08:57+1Почему столько негатива в комментах? Такой инструмент имеет гораздо больше перспектив на светлой стороне, чем на тёмной. Он подсветит факторы, которые, в конечном итоге, помогут и компании, и сотруднику вырасти. Это, если хотите, штатный цифровой психолог, который неустанно и без выходных обеспечит улучшение рабочей атмосферы.
aimfirst
ddemidov
Да, такие штуки как описано в статье нужны не для тех кто еще не решил базовые задачи в работе с сотрудниками.