Чтобы такого не происходило, мы обычно заранее, до релиза, стараемся оценивать качество тестирования: насколько хорошо и тщательно мы проверяем продукт? Каким областям не хватает внимания, где основные риски, какой прогресс? И чтобы ответить на все эти вопросы, мы оцениваем тестовое покрытие.
Зачем оценивать?
Любые метрики оценки – трата времени. В это время можно тестировать, заводить баги, готовить автотесты. Какую такую магическую пользу мы получаем благодаря метрикам тестового покрытия, чтобы пожертвовать временем на тестирование?
- Поиск своих слабых зон. Естественно, это нам нужно? не чтобы просто погоревать, а чтобы знать, где требуются улучшения. Какие функциональные области не покрыты тестами? Что мы не проверили? Где наибольшие риски пропуска ошибок?
- Редко по результатам оценки покрытия мы получаем 100%. Что улучшать? Куда идти? Какой сейчас процент? Как мы его повысим какой-либо задачей? Как быстро мы дойдём до 100? Все эти вопросы приносят прозрачности и понятности нашему процессу, а ответы на них даёт оценка покрытия.
- Фокус внимания. Допустим, в нашем продукте около 50 различных функциональных зон. Выходит новая версия, и мы начинаем тестировать 1-ю из них, и находим там опечатки, и съехавшие на пару пикселей кнопки, и прочую мелочь… И вот время на тестирование завершено, и эта функциональность проверена детально… А остальные 50? Оценка покрытия позволяет нам приоритезировать задачи исходя из текущих реалий и сроков.
Как оценивать?
Прежде, чем внедрять любую метрику, важно определиться, как вы её будете использовать. Начните с ответа именно на этот вопрос – скорее всего, вы сразу поймёте, как её лучше всего считать. А я только поделюсь в этой статье некоторыми примерами и своим опытом, как это можно сделать. Не для того, чтобы слепо копировать решения – а для того, чтобы ваша фантазия опиралась на этот опыт, продумывая идеально подходящее именно вам решение.
Оцениваем покрытие требований тестами
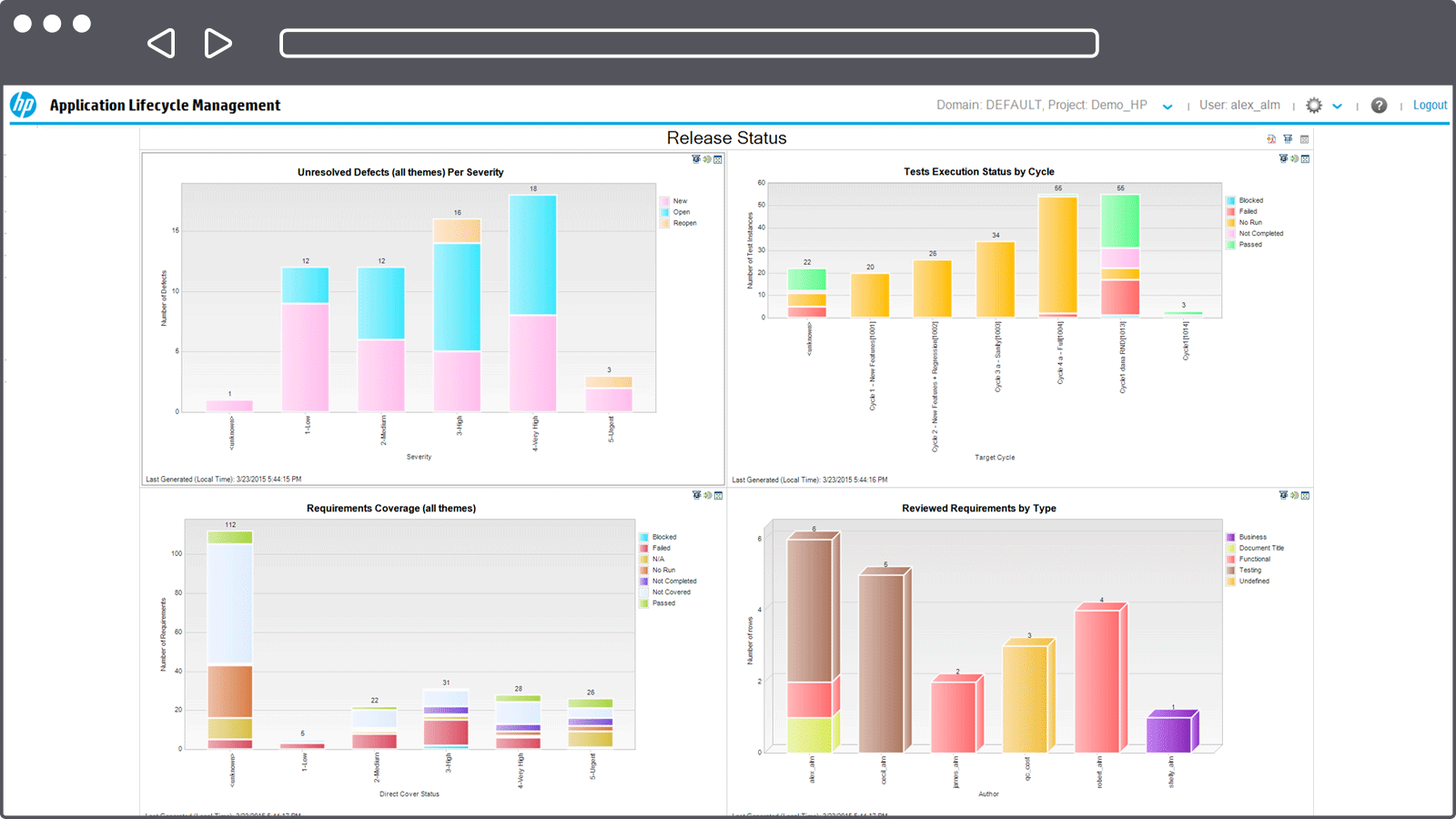
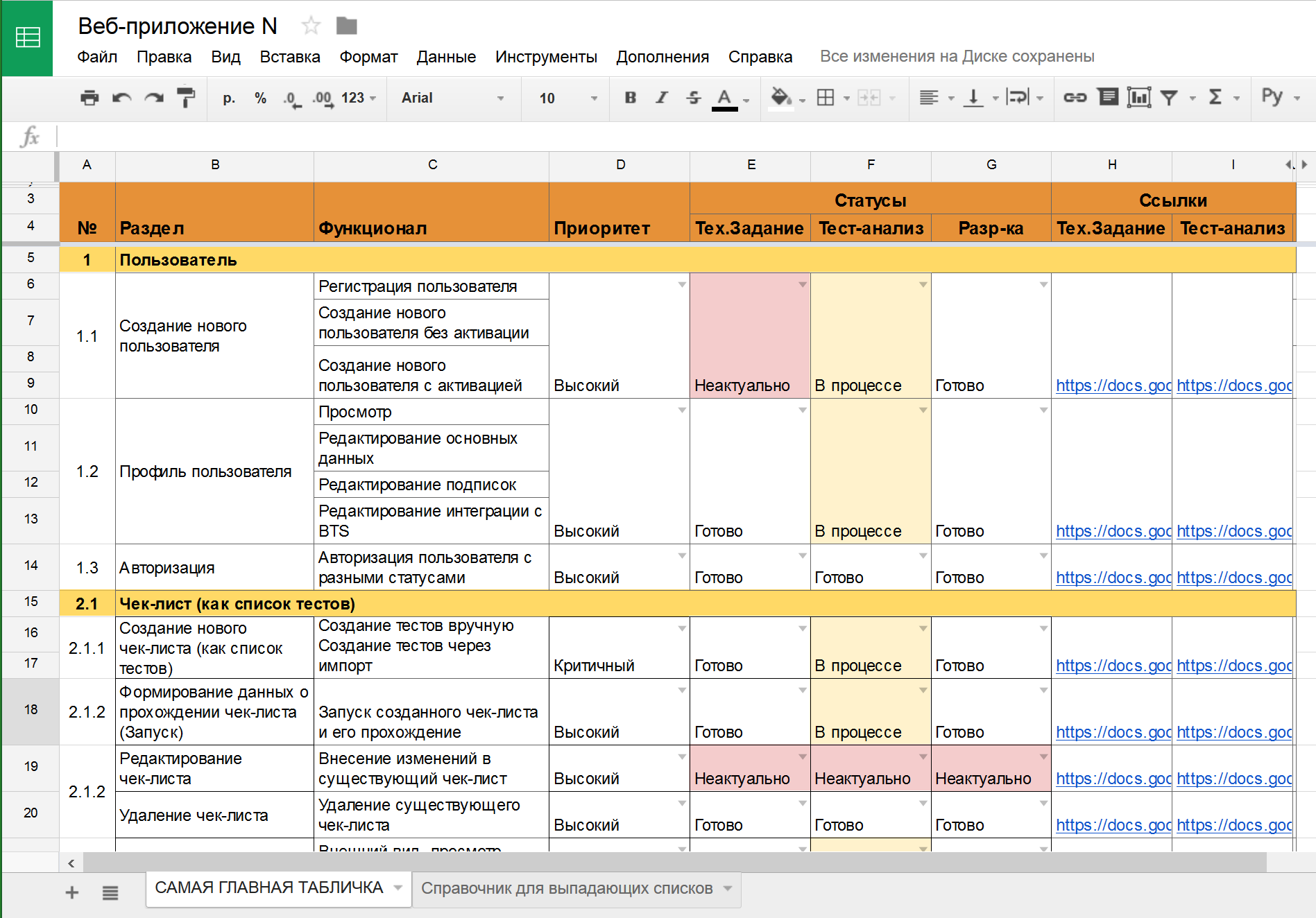
Допустим, у вас в команде есть аналитики, и они не зря тратят своё рабочее время. По результатам их работы созданы требования в RMS (Requirements Management System) – HP QC, MS TFS, IBM Doors, Jira (с доп. плагинами) и т.д. В эту систему они вносят требования, соответствующие требованиям к требованиям (простите за тавтологию). Эти требования атомарны, трассируемы, конкретны… В общем, идеальные условия для тестирования. Что мы можем сделать в таком случае? При использовании скриптового подхода – связывать требования и тесты. Ведём в той же системе тесты, делаем связку требование-тест, и в любой момент можем посмотреть отчёт, по каким требованиям тесты есть, по каким – нет, когда эти тесты были пройдены, и с каким результатом.
Получаем карту покрытия, все непокрытые требования покрываем, все счастливы и довольны, ошибок не пропускаем…
Ладно, давайте вернёмся с небес на землю. Скорее всего, детальных требований у вас нет, они не атомарны, часть требований вообще утеряны, а времени документировать каждый тест, ну или хотя бы каждый второй, тоже нет. Можно отчаяться и поплакать, а можно признать, что тестирование – процесс компенсаторный, и чем хуже у нас с аналитикой и разработкой на проекте, тем больше стараться должны мы сами, и компенсировать проблемы других участников процесса. Разберём проблемы по отдельности.
Проблема: требования не атомарны.
Аналитики тоже иногда грешат винегретом в голове, и обычно это чревато проблемами со всем проектом. Например, вы разрабатываете текстовый редактор, и у вас могут быть в системе (в числе прочих) заведены два требования: «должно поддерживаться html-форматирование» и «при открытии файла неподдерживаемого формата, должно появляться всплывающее окно с вопросом». Сколько тестов требуется для базовой проверки 1-го требования? А для 2-го? Разница в ответах, скорее всего, примерно в сто раз!!! Мы не можем сказать, что при наличии хотя бы 1-го теста по 1-му требованию, этого достаточно – а вот про 2-е, скорее всего, вполне.
Таким образом, наличие теста на требование нам вообще ничего не гарантирует! Что значит в таком случае наша статистика покрытия? Примерно ничего! Придётся решать!
- Автоматический расчёт покрытия требований тестами в таком случае можно убрать – он смысловой нагрузки всё равно не несёт.
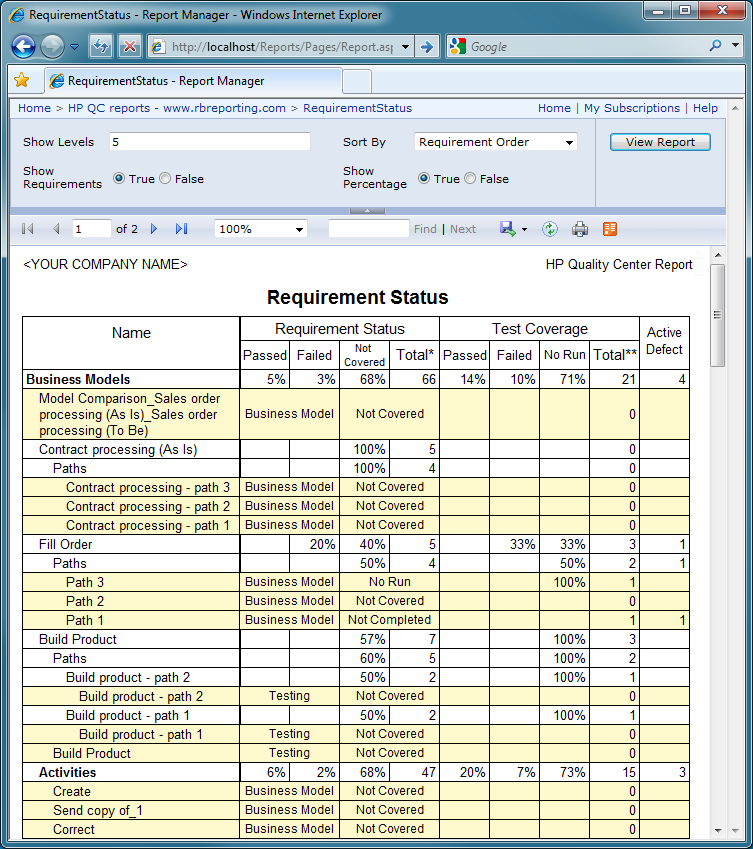
- По каждому требованию, начиная с наиболее приоритетных, готовим тесты. При подготовке анализируем, какие тесты потребуются этому требованию, сколько будет достаточно? Проводим полноценный тест-анализ, а не отмахиваемся «один тест есть, ну и ладно».
- В зависимости от используемой системы, делаем экспорт/выгрузку тестов по требованию и… проводим тестирование этих тестов! Достаточно ли их? В идеале, конечно, такое тестирование нужно проводить с аналитиком и разработчиком этой функциональности. Распечатайте тесты, заприте коллег в переговорке, и не отпускайте, пока они не скажут «да, этих тестов достаточно» (такое бывает только при письменном согласовании, когда эти слова говорятся для отписки, даже без анализа тестов. При устном обсуждении ваши коллеги выльют ушат критики, пропущенных тестов, неправильно понятых требований и т.д. – это не всегда приятно, но для тестирования очень полезно!)
- После доработки тестов по требованию и согласования их полноты, в системе этому требованию можно проставить статус «покрыто тестами». Эта информация будет значить значительно больше, чем «тут есть хотя бы 1 тест».
Конечно, такой процесс согласования требует немало ресурсов и времени, особенно поначалу, до наработки практики. Поэтому проводите по нему только высокоприоритетные требования, и новые доработки. Со временем и остальные требования подтянете, и все будут счастливы! Но… а если требований нет вообще?
Проблема: требований нет вообще.
Они на проекте отсутствуют, обсуждаются устно, каждый делает, что хочет/может и как он понимает. Тестируем так же. Как результат, получаем огромное количество проблем не только в тестировании и разработке, но и изначально некорректной реализации фич – хотели совсем другого! Здесь я могу посоветовать вариант «определите и задокументируйте требования сами», и даже пару раз в своей практике использовала эту стратегию, но в 99% случаев таких ресурсов в команде тестирования нет – так что пойдём значительно менее ресурсоёмким путём:
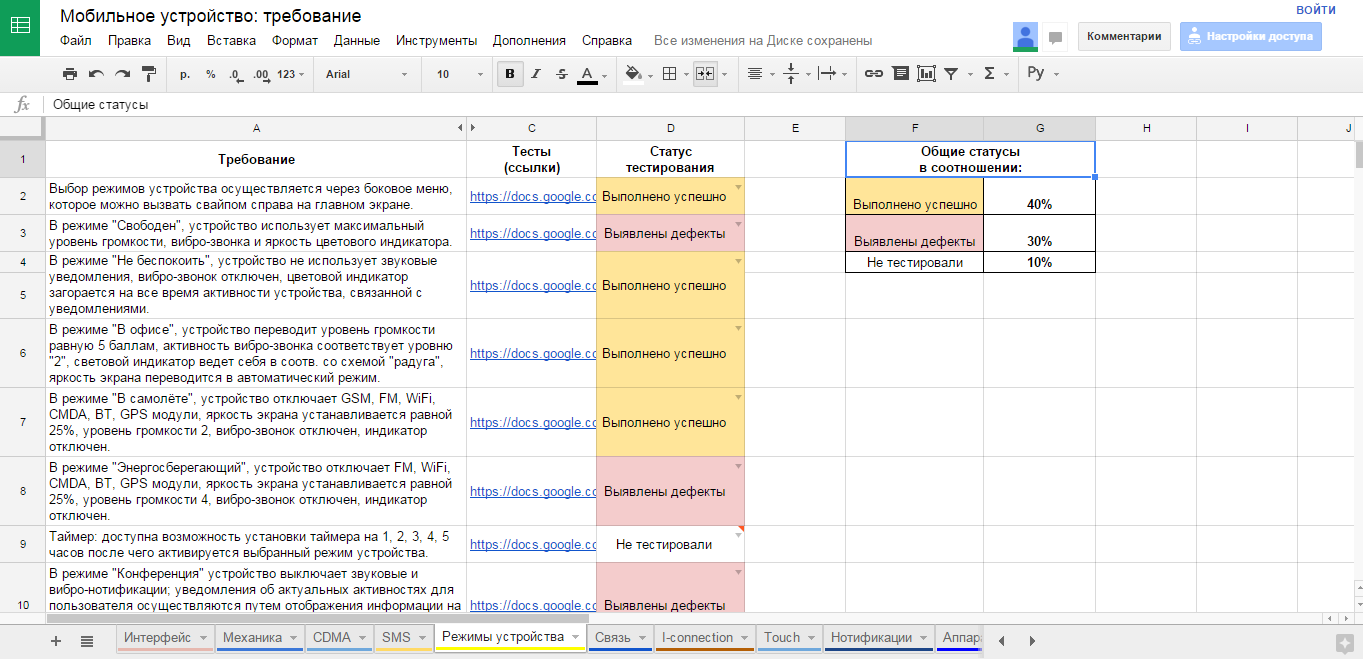
- Создаём фичелист (feature list). Сами! В виде google-таблички, в формате PBI в TFS – выбирайте любой, лишь бы не текстовый формат. Нам ещё статусы собирать надо будет! В этот список вносим все функциональные области продукта, и постарайтесь выбрать один общий уровень декомпозиции (вы можете выписать объекты ПО, или пользовательские сценарии, или модули, или веб-страницы, или методы API, или экранные формы…) – только не всё это сразу! ОДИН формат декомпозиции, который вам проще и нагляднее всего позволит не пропустить важное.
- Согласовываем ПОЛНОТУ этого списка с аналитиками, разработчиками, бизнесом, внутри своей команды… Постарайтесь сделать всё, чтобы не потерять важные части продукта! Насколько глубоко проводить анализ – решать вам. В моей практике всего несколько раз были продукты, на которые мы создали более 100 страниц в таблице, и это были продукты-гиганты. Чаще всего, 30-50 строк – достижимый результат для последующей тщательной обработки. В небольшой команде без выделенных тест-аналитиков большее число элементов фичелиста будет слишком сложным в поддержке.
- После этого, идём по приоритетам, и обрабатываем каждую строку фичелиста как в описанном выше разделе с требованиями. Пишем тесты, обсуждаем, согласовываем достаточность. Помечаем статусы, по какой фиче тестов хватает. Получаем и статус, и прогресс, и расширение тестов за счёт общения с командой. Все счастливы!
Но… Что делать, если требования ведутся, но не в трассируемом формате?
Проблема: требования не трассируемы.
На проекте есть огромное количество документации, аналитики печатают со скоростью 400 знаков в минуту, у вас есть спецификации, ТЗ, инструкции, справки (чаще всего это происходит по просьбе заказчика), и всё это выступает в роли требований, и на проекте уже все давно запутались, где какую информацию искать?
Повторяем предыдущий раздел, помогая всей команде навести порядок!
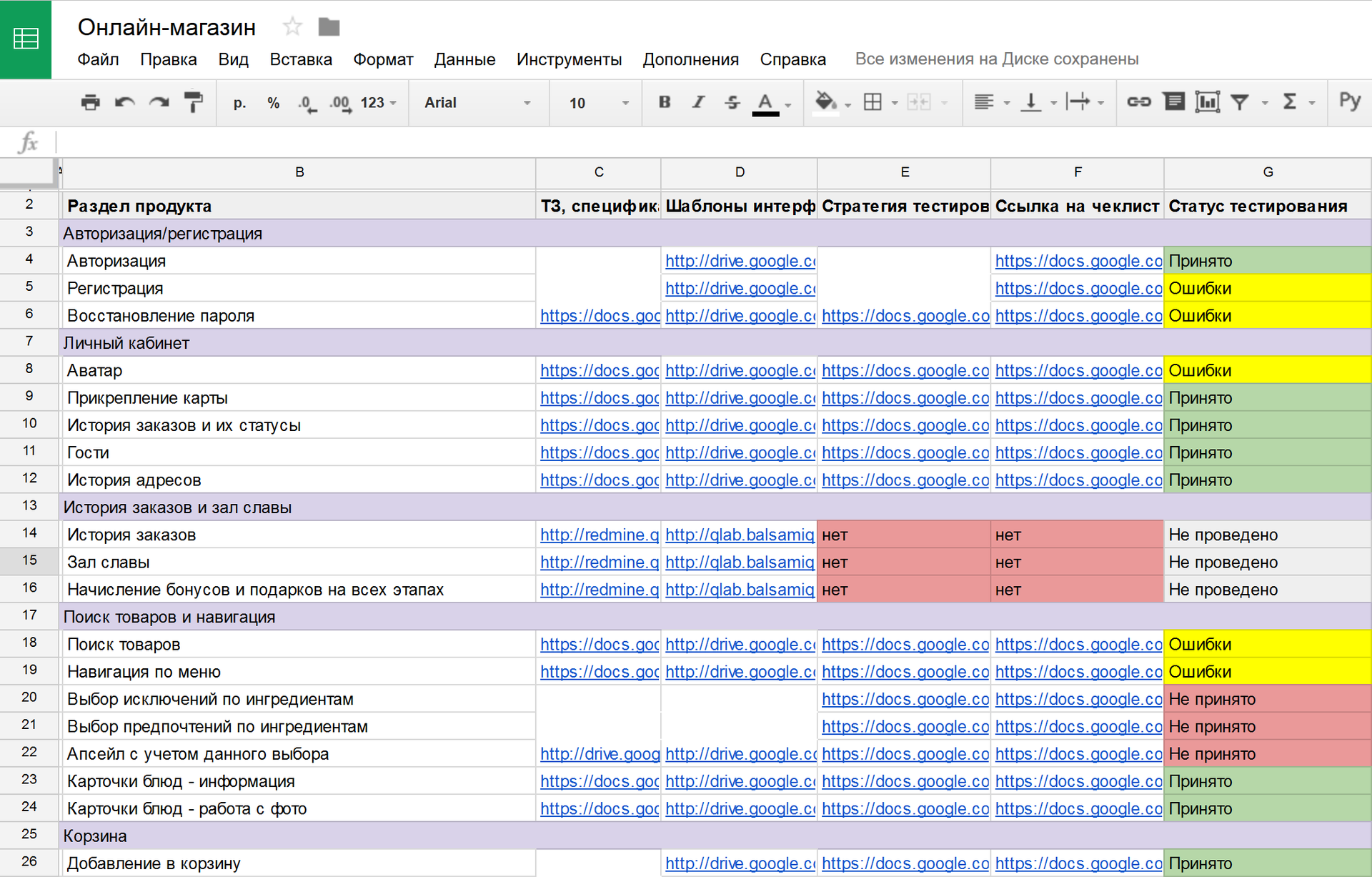
- Создаём фичелист (см. выше), но без детального описания требований.
- По каждой фиче собираем воедино ссылки на ТЗ, спецификации, инструкции, и прочие документы.
- Идём по приоритетам, готовим тесты, согласовываем их полноту. Всё то же самое, только благодаря объединению всех документов в одну табличку повышаем простоту доступа к ним, прозрачные статусы и согласованность тестов. В итоге, у нас всё супер, и все счастливы!
Но… Ненадолго… Кажется, за прошлую неделю аналитики по обращениям заказчиков обновили 4 разные спецификации!!!
Проблема: требования всё время меняются.
Конечно, хорошо бы тестировать некую фиксированную систему, но наши продукты обычно живые. Что-то попросил заказчик, что-то изменилось во внешнем к нашему продукту законодательстве, а где-то аналитики нашли ошибку анализа позапрошлого года… Требования живут своей жизнью! Что же делать?
- Допустим, у вас уже собраны ссылки на ТЗ и спецификации в виде фичелиста-таблицы, PBI, требований, заметок в Wiki и т.д. Допустим, у вас уже есть тесты на эти требования. И вот, требование меняется! Это может означать изменение в RMS, или задачу в TMS (Task Management System), или письмо в почте. В любом случае, это ведёт к одному и тому же следствию: ваши тесты неактуальны! Или могут быть неактуальны. А значит, требуют обновления (покрытие тестами старой версии продукта как-то не очень считается, да?)
- В фичелисте, в RMS, в TMS (Test Management System – testrails, sitechco, etc) тесты должны быть обязательно и незамедлительно помечены как неактуальные! В HP QC или MS TFS это можно делать автоматически при обновлении требований, а в google-табличке или wiki придётся проставлять ручками. Но вы должны видеть сразу: тесты неактуальны! А значит, нас ждёт полный повторный путь: обновить, провести заново тест-анализ, переписать тесты, согласовать изменения, и только после этого пометить фичу/требование снова как «покрыто тестами».
В этом случае мы получаем все бенефиты оценки тестового покрытия, да ещё и в динамике! Все счастливы!!! Но…
Но вы так много внимания уделяли работе с требованиями, что теперь вам не хватает времени либо на тестирование, либо на документирование тестов. На мой взгляд (и тут есть место религиозному спору!) требования важнее тестов, и уж лучше так! Хотя бы они в порядке, и вся команда в курсе, и разработчики делают именно то, что нужно. НО НА ДОКУМЕНТИРОВАНИЕ ТЕСТОВ ВРЕМЕНИ НЕ ОСТАЁТСЯ!
Проблема: не хватает времени документировать тесты.
На самом деле, источником этой проблемы может быть не только нехватка времени, но и ваш вполне осознанный выбор их не документировать (не любим, избегаем эффекта пестицида, слишком часто меняется продукт и т.д.). Но как оценивать покрытие тестами в таком случае?
- Вам всё равно нужны требования, как полноценные требования или как фиче-лист, поэтому какой-то из вышеописанных разделов, в зависимости от работы аналитиков на проекте, будет всё равно необходим. Получили требования / фичелист?
- Описываем и устно согласовываем вкратце стратегию тестирования, без документирования конкретных тестов! Эта стратегия может быть указана в столбце таблицы, на странице вики или в требовании в RMS, и она должна быть опять же согласована. В рамках этой стратегии проверки будут проводиться по-разному, но вы будете знать: когда это последний раз тестировалось и по какой стратегии? А это уже, согласитесь, тоже неплохо! И все будут счастливы.

Но… Какое ещё «но»? Какое???
Говорите, все обойдём, и да пребудут с нами качественные продукты!
Комментарии (18)

korvinriner
09.11.2015 15:42+1Наташа, спасибо! Поправьте меня, если я ошибаюсь, посыл следующий:
1. Мы работаем в тех условиях, что есть, т.е. в реальном мире.
2. Для прозрачности и поддержания процесса реализации в актуальном состоянии нам приходится модифицировать внутренние процессы тестирования таким образом, чтобы не особо задеть внешние процессы реализации (аналитика, разработка, менеджмент).
3. Мы структурируем информацию о прямых требованиях, каталогизируем ее и генерализуем (собираем в некоторые категории/направления/группы).
4. Обеспечиваем стабильное покрытие каждого «каталога» требований проверками необходимыми и достаточными для анализа этих проверок (соответствует/не соответствует, работает/не работает).
5. Живем с этим и поддерживаем в актуальном состоянии.
Т.е. стандартный подход к работе с требованиями в тестировании, хоть TDD хоть ad hoc…
Не совсем понимаю, как это противоречит точке зрения powerman… Как бы не были поставлены процессы, все равно рано или поздно объем проверок и требований превысит память выполняющей проверки команды и потребуется либо заново генерировать и отбирать ТС либо условно принимать, что то что не меняли — работает.
В сущности наверное стоит озаглавить не как оценить покрытие, а как его стабилизировать согласно требованиям. Ведь мы знаем, что оценка покрытия — это то, что нужно ПМу для собственного успокоения, т.к. адекватность этой оценки может понимать только тестировщик.
В целом хорошая статья с правильными практиками, обязательно читаю нечто подобное в каждой организации, куда прихожу ТМ работать и для подчиненных и для коллег по реализации. Теперь смогу ссылку давать :)
Еще раз спасибо, Наташа.
NatalyaRukol
10.11.2015 05:49Поправьте меня, если я ошибаюсь, посыл следующий
Да-да! Ещё лучше, чем у меня, и чётче сформулировано :)
Не совсем понимаю, как это противоречит точке зрения powerman
Мне тоже кажется, что мы об одном и том же :)
Ведь мы знаем, что оценка покрытия — это то, что нужно ПМу для собственного успокоения, т.к. адекватность этой оценки может понимать только тестировщик.
Проблемы начинаются, когда приходит босс и говорит: «посчитайте мне что-то и назовите циферку». Ничего хорошего из этого не выходит обычно :))) А когда мы для себя измеряем, и смотрим по своим табличкам, что проверено, что нет, куда копать, что доделать, что актуализировать, что важнее всего по приоритетам — то это работа не на циферку, а на результат.
NatalyaRukol
10.11.2015 05:50+1Ну и вообще, для меня, оценка — это наши планы на будущее, приоритизация, вектор движения. А не «оценка». Слово-то такое… Опошленное менеджерами :))
korvinriner
10.11.2015 10:00Ну собственно да! О том и речь, что это нужно НАМ, чтобы лучше видеть стек и прогресс работ и корректировать собственные действия. Я в своей практике это называю «стабилизация» :) Ну плюс можно давать пищу химере :) Если она просит «цыфирь».
powerman
Общее впечатление: сначала создаём (или допускаем появление, или не пытаемся исправить исторически сложившуюся) проблему, а потом героически боремся с последствиями. И в данном случае фраза «Героизм — следствие чьей-то некомпетентности.» подходит просто идеально. Почему бы не направить это время и усилия на то, чтобы нормально поставить все необходимые для нормального тестирования процессы, вместо того чтобы мириться с существующей ситуацией и пытаться в ней выживать?
sunnybear
Можно направить все усилия на то, чтобы героически ставить ВСЕ необходимые для нормального тестирования процессы. А можно просто делать качественный продукт наиболее подходящими для этого инструментами. Каждый сам выбирает :)
powerman
Я выбираю ставить процессы. По-крайней мере это однократная задача, а не непрерывный и бесперспективный процесс выживания в агрессивной среде. И по мере добавления новых процессов бардака становится меньше, а работать проще — так что даже если это проделать не в полной мере, а сколько получится — жить всё-равно станет намного легче. Собственно, то, что описано в статье — это тоже постановка процессов, только не тех, которые нужны.
sunnybear
удачи!
NatalyaRukol
Давайте по-чесноку: тестирование это вообще не тот процесс, который нужен! Писался бы сразу идеальный код — не нужно было бы продукт верифицировать. Были бы идеальные и всем понятные требования — не нужно было бы валидировать. Уберите ошибки разработки и аналитики, и тестировщики просто не нужны!
Как только такое получится, вот тогда и заживём. А пока что тестировщики неизбежно компенсируют проблемы со всех этапов разработки.
powerman
Юнит-тесты нужны не для того, чтобы проверить код на корректность (соответствие требованиям), а для того, чтобы проверить что код делает то, что предполагает написавший его разработчик (и совершенно не обязательно это то, что нужно заказчику). Ручное тестирование нужно не для того, чтобы находить баги, а для того, чтобы понять насколько результат аналитики и разработки соответствует «Хочу» заказчика (и скорректировать либо одно либо второе).
Но на практике далеко не всё возможно (понятно как и есть ресурсы) покрыть автоматическими тестами, поэтому ручное тестирование используется и для поиска багов. Что лично меня — огорчает. А поскольку на абсолютном большинстве проектов нормальные автоматические тесты вообще отсутствуют (не дают времени их писать, разработчики либо ленятся либо не умеют их нормально писать), то в результате без ручного тестирования проект вообще не жизнеспособен. Отсюда и возникает Ваше впечатление, что нужда в тестировании вызвана исключительно криворукими аналитиками и разработчиками… и будь они не столь криворукими можно было бы обойтись без тестирования — но это не так, см. предыдущий абзац. Другое дело, что количество и смысл ручного тестирования в нормальных условиях (наличие требований, актуальной спецификации, примерно 90% покрытие кода нормальными юнит-тестами) значительно отличаются от типичного для большинства проектов.
arusakov
Автоматизированные тесты (в том числе юнит тесты) — это не только проверочное средство, но еще и дополнительное орудие в борьбе со сложностью системы в целом. Без юнит тестов немыслимо развивать большие системы: фиксят одни баги — появляются другие, реализовывают новый функционал — отваливается старый. При налаженной системе тестирование вносить в код любые изменения можно быстрее и с меньшим количеством ошибок.
powerman
Вообще, если честно, когда кто-то при ручном тестировании находит у меня в коде баг — мне становится стыдно. Потому, что это означает во-первых то, что я плохо сделал свою работу, и во-вторых то, что я этим добавил кучу лишней, ручной и нудной работы по пере-тестированию другому человеку. И, на мой взгляд, это очень правильное отношение — оно стимулирует делать всё возможное, чтобы такая ситуация не повторилась. Отсюда и моё отношение к работе на проектах где нет возможности работать качественно (нет требований, юнит-тестов, etc.).
NatalyaRukol
Отличный подход!!! Всем бы такой :)
NatalyaRukol
Не поняла, если честно, ваше предложение :) Появляется на проекте тестировщик, на проекте нет нормальных требований. Что ему делать?
Бегать и махать руками «ах вы негодяи, поставьте мне все процессы, чтоб я мог нормально тестировать»?
Я смотрю с позиции специалиста по тестированию, и из двух десятков проектов последнего года, с которыми я работала, ни в одном не было хороших продуманных требований. Могу везде спихивать ответственность и говорить «постройте процессы», а могу компенсировать, насколько это возможно, со своей стороны. Наверное, оба подхода имеют право на существование, и выбирает каждый сам.
powerman
Давайте я перефразирую Ваш вопрос: «Появляется на проекте тестировщик, а в офисе для него нет рабочего места и компа. Что ему делать?». И для полноты перефразирую Ваш ответ из статьи (как я её понял): «Пристроиться за плечом разработчика/менеджера/любого другого человека работающего в данный момент с приложением которое нужно тестировать и записывать на бумажку увиденные проблемы.».
NatalyaRukol
Я поняла ваш подход, и спорить, правильный он или нет, не готова. Похоже на религиозный спор :) Мне кажется, что пока требования тестирования не удовлетворены, очень важно делать со своей стороны максимум, зависящий от нас, не прикрываясь внешними проблемами.
Я ни в коем случае не говорю, что налаживать другие процессы не нужно. Нужно! Конечно! Но когда в тестировании бардак, бегать и ругать аналитиков за нехватку требований, а разработчиков за нехватку юнит-тестов, у меня совести не хватит :))) А вот сделав всё от нас зависящее, уже можно и за другие процессы браться. Но, это не задача тестирования, изначально это всё-таки задача РМа. А нам что пришло, с тем и стараемся по максимуму работать.
NatalyaRukol
Наверное мы вообще об одном и том же говорим. На проектах, где я РМ, я мыслю как вы, и чиню анализ с анализа, а не с тестирования. А если я ТМ, то приходится мыслить совсем по-другому, и принимать внешние процессы как данность.
powerman
Очень может быть. У меня нет опыта вынужденной длительной работы в роли TM при сопротивляющемся здравому смыслу PM. Как фрилансер, я имею свободу выбора проектов и заказчиков, что даёт возможность нормально организовать работу. Либо я организую её самостоятельно, как PM, либо с проекта уходит кто-то из нас — либо я либо тот сопротивляющийся здравому смыслу PM. Мучить себя дурной и бесперспективной работой в значительных количествах я категорически не хочу — это время моей жизни.
Что касается «принимать внешние процессы как данность» — отвечу ещё одной цитатой: «Господи, дай мне спокойствие принять то, чего я не могу изменить, дай мне мужество изменить то, что я могу изменить. И дай мне мудрость отличить одно от другого.». Я многие внешние процессы принимаю как данность, даже если они с моей точки зрения — полнейшая, изумительная глупость. Но отсутствие требований на проекте, который не является одноразовым скриптом — я принять не могу.