
Проблема именования — взгляд под необычным углом.
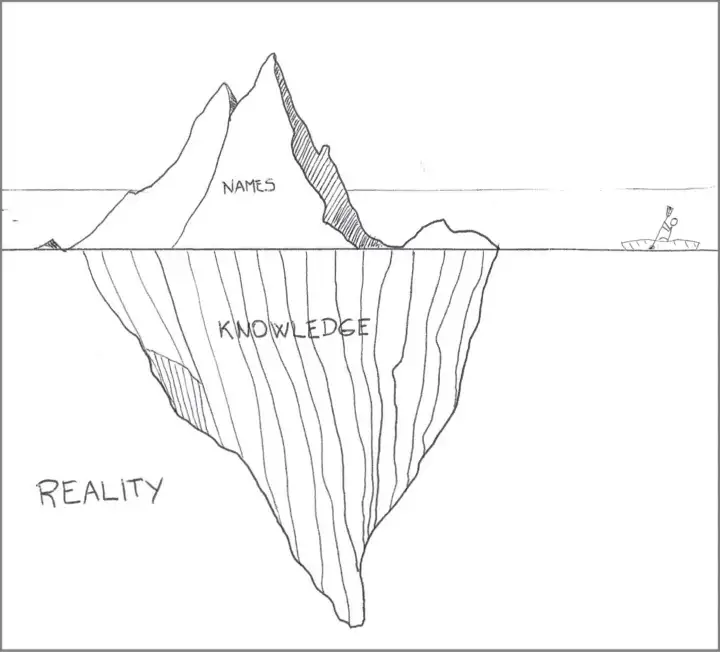
Фил Карлтон как-то сказал: «В информатике есть только два сложных вопроса: инвалидация кэша и присвоение имен».
Первое — это вполне реальная проблема; второе — проблема определения реальности.
Неверный алгоритм кэширования ставит под угрозу целостность системы. Неадекватные имена могут поставить под угрозу само существование системы.
На первый взгляд, это может показаться весьма спорным утверждением. Тем не менее, оно обретает смысл, если вникнуть в то, как мы учимся и выстраиваем общее понимание мира.
Наши знания происходят из опыта и интерпретации окружающей нас действительности. С помощью программного обеспечения мы создаем миры, виртуальные миры. При этом я не имею в виду виртуальные миры в смысле метавселенной. Я имею в виду виртуальные миры внутри нашего сознания.
Мы строим новые миры, потому что реальность уже переполнена... ну, всем подряд. Если попытаться воспроизвести реальный процесс в виртуальном мире, то вы неминуемо пройдете через три следующих этапа
Воспроизвести процесс или действие как есть.
Определить и удалить лишние шаги и задачи, которые не способствуют получению нужного эффекта.
Добавить полезные функции, которые не имеют аналогов в физическом мире.
В качестве примера возьмем онлайн-шопинг.
Опыт совершения покупок в интернете включает в себя многие аспекты реальной жизни, такие как просмотр товаров и их оплата. Остальные концепции, например, поездка в магазин на машине, не добавляют никакой ценности и не включают в виртуальный опыт. А есть концепции, полезные и возможные только в виртуальном мире, например, сохранение номера кредитной карты для будущих покупок.
Когда мы строим новые реальности, сначала нужно что-то изобрести, а затем дать этому название. Непонятное, нестандартное или неадекватное восприятие реальности приводит к путанице в именах.
Запутанные названия затрудняют обмен знаниями, скрывающимися под этими названиями. Без достаточного количества людей, разделяющих одну и ту же интерпретацию реальности, системы неизменно терпят крах.
Видите, как эта тема, еще не успев стать технической, уже приобрела философский подтекст?
Семантика реальности
Прежде чем понять, почему сложно (и крайне важно) придумывать хорошие названия, следует разобраться, как наш мозг «преобразует» окружающий мир в знания.
Имена — это не просто последовательности символов и звуков, они символизируют понятия в системе, которую психологи называют схемой.
Для целей разработки программного обеспечения схемы могут быть немного абстрактными, поэтому я предпочитаю использовать особую разновидность схем, называемую семантическими сетями.
Простейшая форма семантической сети содержит сущности и отношения:
Сущность представляет собой отдельный тип объекта, реальный или концептуальный. Если речь идет о деревьях, то можно выделить такие узнаваемые сущности, как «ствол», «ветви», «листья», «плоды», «цветы» и «семена».
Отношения характеризуют связь между двумя сущностями. Например, лист «соединяется с веткой», а плоды «растут на деревьях».
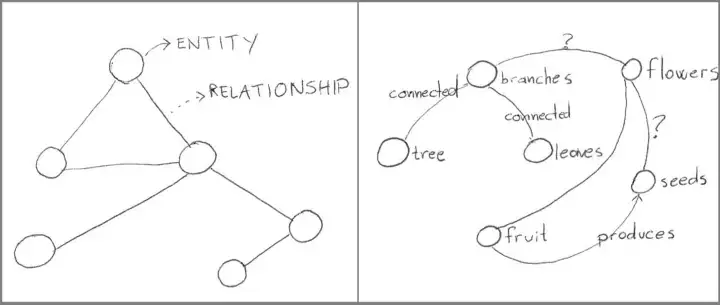
На рисунке слева изображен график с несколькими кругами, соединенными линиями. Круги обозначены как «сущности», а линии, соединяющие круги, — как «отношения». Справа показан граф с конкретными сущностями и отношениями, напоминающий то, как человек запоминает строение дерева. В этом графе есть узлы, обозначенные как «дерево», «ветви», «листья» и «плоды».
Семантические сети (слева) определяют и связывают сущности. По мере того как мы узнаем больше о предмете, семантические сети становятся все более разветвленными, и в них постоянно появляются новые сущности. Наш мозг также реорганизует их, когда мы узнаем о предмете больше.
Несмотря на то, что семантические сети неплохо представляют мир, существуют и другие, не менее правдивые представления. Одни представления различны по глубине (и позволяют увидеть мир более детально), а другие — по ракурсу (дают видение мира под разными углами).
Начнем с простого примера: как объяснить, откуда берутся фрукты.
Малыш, спрашивающий о происхождении фруктов, может довольствоваться простой семантической сетью из слов «деревья», «ветки», «цветы» и «фрукты».
Позже в жизни, возможно, будучи студентом-биологом, этот же ученик будет готов к пониманию более сложной модели. В этой модели будут новые сущности, такие как «семена», «пыльца», «пыльцевые трубки», «завязи» и «пыльцевые мешки». Эти новые сущности потребуют больше отношений в рамках семантической сети, соединяющих ранее существовавшие сущности с новыми. Например, «пыльца» хранится» в «пыльцевом мешке», а пыльцевой мешок является «составляющей» цветка.
Эти две семантические сети различаются своей глубиной.
В семантических сетях апиологов (экспертов по медоносным пчелам), исследующих растения, безусловно, есть многие из этих понятий. Однако семантические сети могут включать и менее распространенные сущности, такие как «лесные буферы» и «ветрозащитные полосы», относящиеся к жизнедеятельности пчел и общей устойчивости экосистемы. Эти семантические сети по-прежнему содержат дополнительную информацию о деревьях, но только при условии, что эта информация связана с пчёлами.
Это и есть разница в ракурсе.

Рисунок трех груш. В центре находится вполне приличный рисунок груши, с затенением и кое-какими деталями вокруг стебля и листьев. Слева — грубый рисунок груши, фактически набросок. Справа — детальный рисунок, с вырезом, демонстрирующим расположение семян, и более подробным изображением листьев. На детальном рисунке также имеется множество выносок, где изображены таблицы с информацией о сезонах посадки и витаминах.
Изучение предмета на протяжении целой жизни заставляет разных людей видеть один и тот же объект по-разному. Простой фрукт может пробуждать всё более сложные и не связанные между собой представления в зависимости от опыта наблюдателя.
Из-за этих различий в работе с реальностью возникают две фундаментальные проблемы, которые проявляются при разработке программного обеспечения:
Различные уровни квалификации означают различную глубину семантических сетей. Одни люди могут увидеть в пути клиента больше нюансов, чем другие. Это не значит, что дополнительное восприятие всегда будет оказывать существенное влияние на конечное решение, но оно есть.
Разница в приоритетах влияет на то, как мы классифицируем одну и ту же информацию. Разработчики программного обеспечения могут осознавать сущности, которые лежат в основе работы целой системы в рамках сложной физической и логической паутины серверов, подключений и движков рендеринга. А пользователь, вероятно, может воспринимать только «приложение», незначительную сущность в его повседневной рутине.
С различиями в глубине мы более или менее освоились. Но к различиям в перспективе (ракурсе, угле зрения) мы приспособлены гораздо хуже.
Виртуальный мир, где все ново
Теперь можно сказать, что самое сложное — это не финальный акт присвоения чему-то названия.
Под хорошим названием скрывается четкое восприятие реальности и качество семантической сети. Концепции и отношения должны сформироваться в результате наблюдения, до того момента, как мы дадим им название.
На определённой стадии человеческой истории кто-то наверняка посмотрел на высокую палку, торчащую из земли и назвал её деревом — точнее, как-то еще, по-своему.
Но что случится, если чья-либо реальность не будет подчиняться правилам пространства, материи и времени?
Это и есть проблема программного обеспечения, с акцентом на «мягкое» (виртуальное) в отличие от «жесткого» (реального). Разработчики ПО не просто присваивают имена сущностям в своем мире. Часто они же и создают эти сущности.
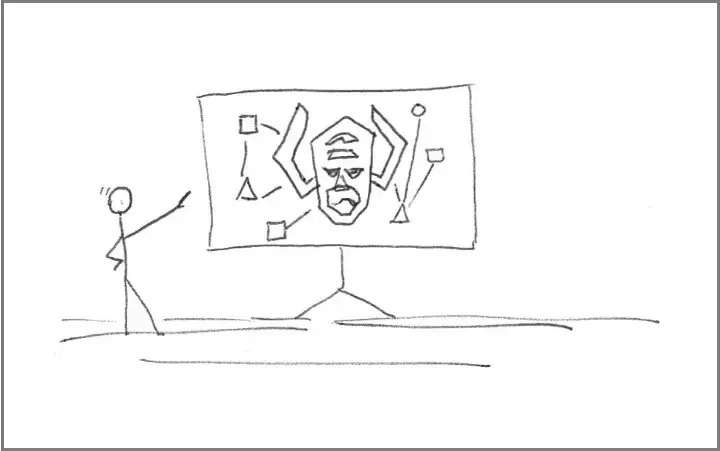
Разработчик программного обеспечения с точки зрения стороннего наблюдателя может интерпретировать реальность более или менее очевидными способами. Некоторые концепции могут быть простыми и общепринятыми среди множества разработчиков. Другие же понятия могут требовать сложных объяснений и формирования новых семантических сетей в команде, прежде чем люди смогут наладить совместную работу.
Как таковые, разработчики программного обеспечения сталкиваются с решениями о присвоении названий чаще, чем люди других профессий.
Чтобы привести несколько примеров того, как представители других профессий сталкиваются с проблемой наименования новых вещей, нужно изучить, как часто они сталкиваются с новыми вещами.
Физики препарируют основы Вселенной с помощью приборов, которые заглядывают в самое сердце субатомных частиц. Астрономы заглядывают далеко и глубоко, используя при этом ограниченные возможности, в надежде обнаружить объект, которому понадобится новое название. Предпринимателям же нужно сначала создать компанию или новый продукт, прежде чем давать ему имя.
Логика ясна: куча работы, долгие периоды открытий, ограничения реального мира, и, пожалуй, лучшие представители своей профессии ежегодно (или раз в десятилетие) получат считанное количество возможностей дать чему-то имя.
Разработчики программного обеспечения? У них такая возможность появляется десятки, возможно, сотни раз на дню.
Такие широкие полномочия появляются вследствие того, что они имеют дело с инструментами, представляющими мысли и концепции в виде программ. Причем эти представления должны быть жестко и однозначно доступны другим программам.
Передача знаний, от теории к практике
После того как всему новому дано название, наступает время познакомить с этими новыми мирами остальных членов команды разработчиков.
Поскольку большинство разработчиков программного обеспечения не имеют формального образования, они часто полагаются на сочетание своего опыта в обучении и преподавании другим.
И пусть формальное обучение преподаванию и выходит за рамки этой статьи, мы можем хотя бы поверхностно ознакомиться с некоторыми аспектами теории обучения.
Более глубокий анализ теории обучения заслуживает отдельного материала. Тем не менее, даже беглое ознакомление с такой концепцией, как «передача знаний», демонстрирует потенциал для разъяснений и улучшения традиционных методов совместного использования программного обеспечения.
Стоит отметить, что именно на традиционных методах по-прежнему должна основываться любая передача знаний:
Проектная документация
Диаграммы компонентов
Терминологические словари
Диаграммы взаимодействия
Остановимся, чтобы обратить внимание на то, что объяснения «на доске» лишь дополняют проектную документацию, а не заменяют её.
Для ясности, живое собрание — это отличный инструмент для передачи знаний. «Студенты» могут взаимодействовать с «преподавателем», чтобы исследовать концепции и постепенно дополнять свои семантические сети.
С другой стороны, качество тренинга во многом зависит от опыта преподавателя. Индивидуальная форма проведения занятий приводит к непоследовательным результатам на разных сеансах. Индивидуализированное обучение также плохо масштабируется и маргинализирует коллег за пределами ваших социальных сетей, города и часового пояса.
Метафоры: Остерегайся «готовых» семантических сетей.
Разные люди формируют семантические сети по-разному. В разработке программного обеспечения это особенно верно для тех ситуаций, когда приходится иметь дело с абстрактными понятиями, подходящими под несколько возможных категорий.
Неудивительно, что дизайнеры и разработчики время от времени отдают предпочтение метафорам для моделирования или описания своих систем. Считается, что метафоры могут ускорить передачу знаний, поскольку опираются на семантические сети, уже освоенные людьми ранее.

Метафора — это консервированная версия новой семантической сети. Получатель может построить новую семантическую сеть «с нуля», но может быть способен построить ее немного быстрее, если не менее идеально, на основе уже существующего фрагмента похожей семантической сети.
Пример простой метафоры — использование иконки «корзины» для удаления файлов с компьютера. Более сложный пример метафоры — понятие «очереди» в системах обмена сообщениями.
Однако в использовании метафор есть (как минимум) две проблемы.
Проблема метафор №1: Кому она хорошо известна?
Первая проблема заключается в том, что привычное понятие не обязательно является универсальным.
Прекрасный пример есть в эпизоде «Звездного пути» под названием «Darmok».
Пример идеален, поскольку фанаты «Звездного пути» уже поняли, что я имел в виду, и ничего больше говорить не нужно. Между тем, не-фанатам остается только гадать, какое смысловое значение имеет этот эпизод.
В этой серии инопланетная раса общается с помощью метафор, уходящих корнями в исторические события их родного мира. В результате общение с любым другим обществом было затруднено из-за отсутствия общего контекста, что приводило к долгим и бесплодным попыткам установить контакт.
С другой стороны, эта история также показывает невероятную силу общего контекста, когда минимальные вербальные сигналы могут быстро передать плотно упакованную информацию.
Сокат, его глаза раскрыты!
Проблема метафоры №2: глубина и ракурс.
И снова мы сталкиваемся со злодеями из наших семантических сетей.
Если я говорю, что что-то «работает как Интернет», то технически грамотные люди могут более или менее представить себе, о чем идет речь. В то же время рядовые интернет-пользователи без опыта работы с облачной инфраструктурой могут воспринимать его как набор непонятных трубок.
Абстракции
Считайте, что абстракции — это попытка сгруппировать целые семантические сети в меньшее количество сущностей в новой семантической сети.
Абстракция позволяет общаться на более высоком уровне, как между людьми, так в отношениях человека и машины.
В качестве примера абстракции в реальном мире вспомним онлайн-шопинг, где процесс приобретения товара изображается с помощью картинок и кнопок на экране компьютера.

Разработчик системы, изучая реальность, должен принять обоснованное решение о том, какие части этой реальности важны для формирования новой реальности — новой системы. Такая новая реальность будет являться абстракцией исходной реальности.
Хотя в мире программного обеспечения абстракции не являются чем-то уникальным, индустрия разработки ПО отличается тем, как быстро она наслаивает абстракции на абстракции. В результате создаются непостижимо сложные слои семантических сетей, требующие сложного обучения.
Чтобы проиллюстрировать, насколько «высокими» могут быть эти программные абстракции, попробуем рассказать неспециалисту о кластере Kubernetes:
Кластер Kubernetes объединяет различные узлы Kubernetes в логическую вычислительную единицу с совокупной вычислительной мощностью этих узлов. Узел Kubernetes — это абстракция для вычислительного устройства, которое может быть как виртуальной машиной, работающей на основе гипервизора, так и настоящим bare-metal сервером или даже крошечной стойкой из Raspberry Pi, стоящей на чьем-либо столе.
На узле Kubernetes можно запустить программу. Но сначала следует понять суть pod'а, абстракции, которая представляет собой группу «контейнеров», развернутых вместе.
Это объяснение можно продолжать до тех пор, пока оно не перегрузит возможности человека по расширению его семантической сети.
Отсюда следует вывод: упрощение не всегда ведет к простоте. Некоторые технологии по своей природе являются сложными, потому что они решают комплексные проблемы.
И поскольку все мы вынуждены рационально рассуждать и эффективно общаться по решению этих проблем, мы продолжаем накладывать абстракцию на абстракцию, пока объяснения не станут похожи на стишок про «Дом, который построил Джек».
По мере того, как мы познаём новое, растет и число, и объемы наших семантических сетей. Они разрастаются подобно деревьям, когда к существующим понятиям присоединяются новые. Можно реорганизовать отдельные фрагменты семантических деревьев внутри нашего мозга, но полностью «переписать» их бывает нелегко.
Семантические сети двух разных людей могут совпадать на самом базовом уровне, особенно если эти люди имеют много общих контекстов.
По мере повышения уровня абстракции общий контекст ослабевает, и на внешнем контуре эти семантические сети приобретают всё больше различий. Когда сети становятся слишком разными, люди перестают разделять общие точки зрения.
В качестве разминочного упражнения по разработке ПО рассмотрим вопрос об именовании переменных внутри функции. Семантические сети внутри функции очень ограничены по цели, и программисты пытаются подогнать имена под локализованный управляющий контур или часть алгоритма.
Циклы требуют именования индексных переменных или перечисляемых элементов. Подобные решения по именованию в значительной степени являются производными и несущественными. Например, когда дело доходит до индексных переменных, то принимаемое по умолчанию решение часто следует историческому шаблону односимвольных имен типа «i», «j» и «k».

Два разных разработчика с одинаковой подготовкой, столкнувшись с одним и тем же абстрактным определением простой задачи, могут прийти к решениям, которые выглядят очень схоже. Однако это сходство может развеяться, когда эти же разработчики столкнутся с абстракциями более высокого уровня.
Если выйти за рамки управления циклами, мы столкнемся с именованием сущностей с более высокой семантической ценностью. Вероятно, здесь необходимо постараться, чтобы имена переменных соответствовали назначению функции.
По мере того, как мы продвигаемся вверх по иерархической лестнице концепций, имена все сильнее начинают приводиться в соответствие с концепциями системы. Например, если в системе есть компонент, представляющий корзину для покупок, то, скорее всего, у нас будет файл или системный класс, названный соответствующим образом.
Важно отметить, что разные люди создают разные семантические сети для одной и той же реальности. Когда эта реальность очень узкая, например, «пройтись циклом по конкретному массиву», семантические сети оказываются в равной степени ограниченными и, как правило, полностью совпадают.
С увеличением масштаба задачи (потоки управления, моделирование алгоритма как программы или определение системы), согласованность рассеивается.
Возвращаясь к примеру с корзиной, написали бы два разных разработчика полностью идентичный исходный код для ее реализации? Скорее всего, нет.
Гораздо важнее то, насколько они будут согласны с чужим решением и подкорректируют ли собственные ментальные модели? Не исключено.
Согласие означает «гармонизацию» семантических сетей разных людей в команде, и для этого есть несколько хороших методик. Некоторые формальные методы были упомянуты ранее (проектная документация, словарь терминов, диаграммы компонентов, диаграммы последовательности).
Я бы добавил сюда регулярное перекрестное обучение и даже парное программирование как виды деятельности, дополняющие формальную документацию.
Обсуждение вопроса о расхождении семантических сетей переносит нас в следующий раздел.
Переписывание реальности с помощью кода
Переделывать чью-то работу — это исключительно распространенная практика в индустрии разработки программного обеспечения.
Переделывание кода может показаться нерациональным делом. На первый взгляд и, возможно, с точки зрения менеджера проекта, если блок кода выполняет свою задачу, разработчики должны оставить его в покое. Если для добавления новой функции в блок кода требуется внести минимальные изменения, то логичнее дополнить его дельтами, а остальное оставить нетронутым. Верно?
Неувязка здесь в том, что менеджеры нередко считают, что написание кода — это своего рода строительство домов. По инстинктивным ощущениям или в силу обучения они исходят из того, что когда ты что-то построил в реальном мире, оно уже готово и не должно переделываться.
Тем не менее, повторюсь, разработчики программного обеспечения не занимаются строительством в реальном мире; они лишь интерпретируют реальность для создания виртуального мира.
Если оставить в стороне законные причины для рефакторинга кода, разработчик программного обеспечения, «наследующий» кодовую базу от своего предшественника, все равно будет испытывать желание переписать значительную часть этой базы.
Почему так происходит?
Если коротко — конструктивизм.
Переписывание кода — это не бесцельное мероприятие по воссозданию того, что уже имеется в кодовом архиве. Это процесс создания равновесия между тем, что знает разработчик, и письменным представлением этих знаний. Это позволяет разработчику более продуктивно работать с кодовой базой. Переписанная кодовая база — это побочный продукт обучения.
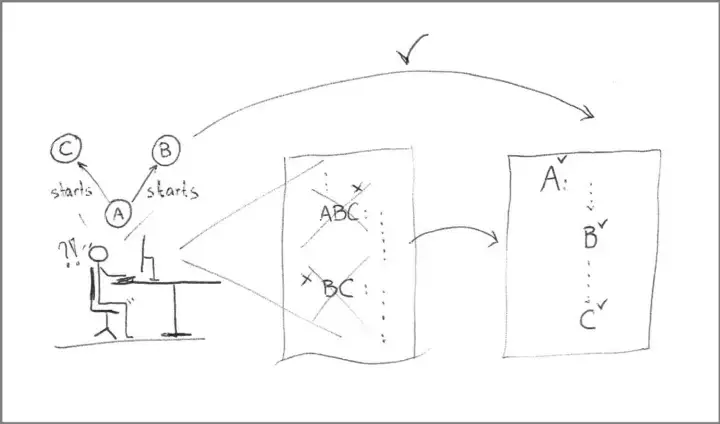
Если код не соответствует представлениям разработчика о том, что этот код должен делать, то ему проще всё переписать, чем перестраивать собственные «чертоги разума» в соответствии с мышлением предшественника.
Заключение
Придумывание имен чему-либо при разработке программного обеспечения является кульминацией сложного процесса создания абстрактных миров.
Некоторые части этих миров являются прямыми представлениями физического мира, в то время как остальные элементы — абсолютно новы.
Процесс присвоения имен охватывает и узкие задачи (написание циклов), и широкие (создание новых абстракций).
Из-за отсутствия исторических ориентиров — разработка программного обеспечения является относительно новой дисциплиной — для объяснения новых парадигм зачастую приходится использовать неидеальные метафоры.
Беспрецедентный технологический прогресс требует постоянного увеличения слоев абстракции для разбиения умопомрачительных возможностей современных систем на отдельные уровни.
Многие из этих проблем — следствие юности нашей с вами профессии, однако в смежных областях иногда получается позаимствовать парочку подходящих концепций, способных качественно объяснить, согласовать и сделать общедоступным какое-то новое явление.
Комментарии (26)

panzerfaust
06.02.2023 07:10+5Фил Карлтон как-то сказал: «В информатике есть только два сложных вопроса: инвалидация кэша и присвоение имен».
Мне порой даже удивительно, насколько просто научить джуна любой технологии от веб-фреймворка до машинного зрения. Но при это невозможно ни с первого ни иногда с десятого раза донести мысль, что если функция называется
doesContainerIncludeItem, то она должна возвращатьBooleanи не должна ни писать в базу, ни отправлять эвенты, ни общаться с UI, ни что-то еще. Ну и наоборот, если функция проверят факт наличия чего-то в контейнере, то у тебя буквально пара вариантов ее нейминга и всего один вариант возвращаемого значения, а не бесконечный карнавал бессвязного нечитаемого бреда. До джуна из наших широт иногда еще и новозможно донести, чтоdoesContainerIncludeItem- правильно, аisContainerIncludesItem- уже нет.
hardtop
06.02.2023 09:43+4До джуна из наших широт иногда еще и новозможно донести, что
doesContainerIncludeItem- правильно, аisContainerIncludesItem- уже нет.А можно чуть подробнее, почему does правильно, а is - нет? Может есть хорошая статья на эту тему? Был бы признателен.
panzerfaust
06.02.2023 10:07+1Насколько хорошая вам требуется статья, чтобы построить вопрос к утверждению "Container includes item" (опуская ненужные тут артикли)? Подозреваю, что это откуда-то из первого года обучения языку.

vadimr
06.02.2023 10:16+12Однако не будет лишено оснований мнение, что шаблон имён предикатов, начинающийся с is, более важен в тексте программы, чем грамматика английского языка.
panzerfaust
06.02.2023 10:34+1Согласен, вопрос договоренности. Конкретно в наших гайдах был принят более естественный подход: isCompleted, doesExist, hasProperty.

mayorovp
06.02.2023 10:29+1Потому что глагол "есть" ожидает существительного, прилагательного либо причастия, но никак не глагола. Глагол же превращается в причастие суффиксом -ing либо третьей формой, но вовсе не суффиксом -s.
Вот так будет тоже синтаксически правильно —
isContainerIncludingItem, но это звучит странно. Как будто нам важно подчеркнуть что контейнер содержит элемент прямо сейчас.Ещё есть вариант
isContainerIncludedItem, но тут мне не хватает знания языка чтобы понять что именно подразумевает эта фраза. Однако, тоже не то что элемент просто лежит в контейнере.

PrinceKorwin
06.02.2023 09:48+2Однажды на ревью кода мне попался метод isDoGetAndSet(...)
Кто первым догадается какого типа результат этого метода?
panzerfaust
06.02.2023 10:04Если выкрутить трэшак на максимум, то это должна быть какая-нибудь монада Either<Void, String>. Чтобы противника окончательно ввести в заблуждение.

MentalBlood
06.02.2023 10:40Понимаю что речь про нейминг, но не лучше ли что-то вроде
bool Container::include(Item item)?panzerfaust
06.02.2023 10:45Ну если это прям класс Container и вы его редактор (или вы используете Kotlin), то само собой.

TIEugene
06.02.2023 12:11+3> Фил Карлтон как-то сказал: «В информатике есть только два сложных вопроса: инвалидация кэша и присвоение имен».
На самом деле он сказал «В информатике есть только два сложных вопроса: инвалидация кэша, присвоение имен и переполнение».

gandjustas
06.02.2023 14:51+9There are only two hard things in Computer Science: cache invalidation, naming things and off-by-one error

ksbes
06.02.2023 15:00Аж зубы заныли! Сейчас как раз решаю off-by-one error в программе, которую клепали 5 поколений программистов, пришедших с разных языков (плюсы, питон, джаваскрипт и т.п). С соответсвующей кашей в нейминге. На полном серьёзе хочу выкинуть и переписать всё заново, если сроки дадут

klvov
07.02.2023 10:39Не могу не процитировать в комментариях к такой статье известное:
Цзы Лу спросил: «Вэйский правитель намеревается привлечь Вас к управлению государством. Что Вы сделаете прежде всего»?
Учитель ответил: «Необходимо начать с исправления имен».
Цзы Лу спросил: «Вы начинаете издалека. Зачем нужно исправлять имена?»
Учитель сказал: «Как ты необразован, Ю! Благородный муж проявляет осторожность по отношению к тому, чего не знает. Если имена неправильны, то слова не имеют под собой оснований. Если слова не имеют под собой оснований, то дела не могут осуществляться. Если дела не могут осуществляться, то ритуал и музыка не процветают. Если ритуал и музыка не процветают, наказания не применяются надлежащим образом. Если наказания не применяются надлежащим образом, народ не знает, как себя вести. Поэтому благородный муж, давая имена, должен произносить их правильно, а то, что произносит, правильно осуществлять. В словах благородного мужа не должно быть ничего неправильного».
boopiz
Оч хорошая статья.
Вообще говоря, именование всего вокруг и есть то, что делает нас человеком. Сознание не может находится в семантической пустоте. Нет ничено узнанного в нашей реальности, что бы ни было поименовано.
Но с другой стороны, обилие информационных потоков порождают защитные механизмы типа эгоистичной ленности мышления, когда проще не искать уже имеющиеся названия, а использовать то, что тебе уже известно. так и появляется засилие бездарных специальных "словечек" типа "контекстолог", "онбординг", "тичинг"... эдакие куски говнокода, встраивпемого ленивыми разработчиками, которым надо побыстрее запилить кусок кода и отчитаться. а красиво ли это, гормонично ли по отношению к общей системе. ему пофиг.
aamonster
Правильное именование – это и есть проявление лени. Можно было бы все переменные назвать a, b, c и так далее (кто застал бейсики на 8-битках – вспомнит), но мы находим способ облегчить себе чтение кода.
Deosis
Правильная лень - поработать сейчас больше, чтобы потом пришлось работать меньше.
MentalBlood
Смотря насколько больше сейчас и насколько меньше потом
boopiz
KvanTTT
И почему эти слова бездарные?