
Проект представлял из себя идею предсказания влияния новости на финансовый рынок. Были получены новости из раздела "Бизнес" и "Технологии", подгруженные с New York Times. Однако, перед тем, как приступать к предсказанию влияния, необходимо было очистить данные и отсечь новости, которые явным образом не повлияли бы на рынок. И тут нам на помощь пришла кластеризация.
Что мы делали:
Предобработали данные
Построили матрицу эмбеддингов
Кластеризовали то, что получилось
А теперь обо всем по порядку.
Очистка и предобработка данных
Учитывая, что модель машинного обучения не может воспринимать текст в принципе, появляется необходимость в его векторизации (то есть создания матрицы эмбеддингов, но об этом позже). Однако, перед векторизацией данные должны быть хорошо очищены.
Что включает в себя очистка данных:
Приведение всего текста к нижнему регистру;
Удаление пунктуации;
Удаление стоп-слов;
Стемминг или лемматизация слов;
Разбиение на токены.
С приведением текста к нижнему регистру и удалением пунктуации - в принципе все понятно. Рассмотрим подробнее удаление стоп-слов, стемминг\лемматизацию текста и токенизацию.
Стоп-слова - это символы, служебные части речи, местоимения, союзы, междометия, и любые слова не несущие самостоятельно никакой смысловой нагрузки. Их удаление необходимо для корректного построения эмбедингов.
Стемминг\лемматизация - это приведение всех слов к начальной форме. Чтобы одни и те же слова, но стоящие в разных частях речи\родах и т.д. не рассматривали как отдельные слова.
Токенизация (иногда – сегментация) по словам – это процесс разделения предложений на слова-компоненты.
Построение матрицы эмбедингов
На данном этапе происходит построение матрицы эмбедингов для обучения на ней моделей. Для этого была подгружена предобученная нейронная сеть Word2Vec и дополнительно обучена на наших данных.
Кластеризация
А теперь, когда матрица эмбедингов готова, наступает самый интересный этап - построение кластеризации и отсеивание аномалий.
В исследовании новостей силами кластеризации возможно отсечь нерелевантные новости. Но проблема состоит в том, что число кластеров для кластеризации нам неизвестно. Данный проект требовал подбора определенных моделей кластеризации, не требующих на вход количество кластеров. Были выбраны следующие модели: DBSCAN, Affinity, иерархическая кластеризация и также попытки выделения оптимального количества кластеров методом локтя для Kmeans.
Также стоит отметить, что для визуализации результатов работы моделей использовалось Стохастическое вложение соседей с t-распределением (коротко t-SNE) - это алгоритм машинного обучения для визуализации. Он является техникой нелинейного снижения размерности, хорошо подходящей для вложения данных высокой размерности для визуализации в пространство низкой размерности (двух- или трехмерное).
В результате адекватные результаты показали две модели: DBSCAN и иерархическая кластеризация. Результаты представлены ниже.
DBSCAN
В результате обучения DBSCAN было получено два кластера. Основным является нулевой кластер, а отсекаемые новости вошли в отдельный кластер, получив признак «-1».
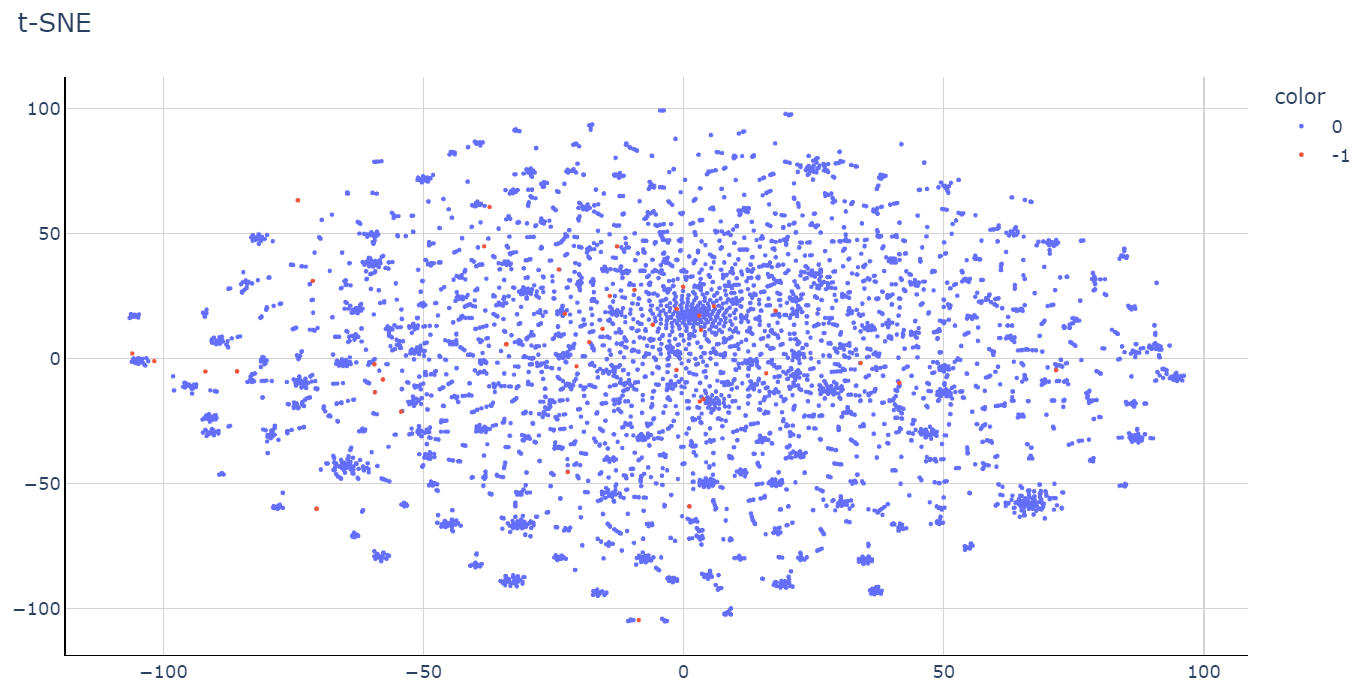
Стоит отметить, что кластера «-1» обозначают, что модель не смогла распознать их принадлежность к какому-либо кластеру.
Иерархическая кластеризация
В результате обучения иерархической кластеризации также было получено два кластера. В данном случае отсекаемых новостей получилось значительно больше, чем при DBSCAN. Основным кластером является нулевой кластер, а отсекаемые новости сформировали кластер с признаком «1».

Affinity
Алгоритм кластеризации при всех наших попытках и стараниях не смог выделить отсекаемые новости в отдельный кластер, а адекватные - в другой :(

Вместо этого она наплодила нам множество различных кластеров, а понять какие аномалии, какие нет, в данных условиях достаточно трудно.
Kmeans: метод локтя
Метод локтя заключается в подборе оптимального количества кластеров для алгоритма кластеризации. Однако, применив данный метод, мы не смогли определить тот самый “локоть”. Результаты представлены ниже:

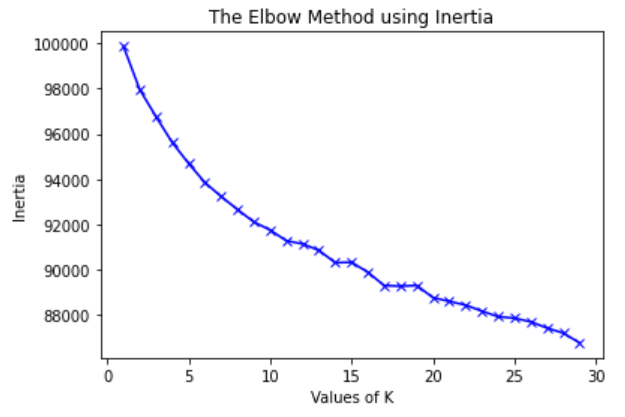
Подведение итогов и очистка аномалий
В итоге проведения всех манипуляций и исследований в лидеры выбились две модели: DBSCAN и иерархическая кластеризация (как уже было сказано выше) и очистка данных шла уже на основе результатов этих двух моделек.
Далее поиском пересечений между двумя моделями исключаем новости, одновременно попавшие в исключаемые кластеры. В результате применения данного подхода со стороны кластеризации к выявлению нерелевантных данных среди общего набора удалось достаточно точно определить новости, не имеющие отношения к финансовому рынку и бизнесу в целом. В результате были получены чистые (т.е. без сторонних данных) данные, которые в дальнейшем не будут ухудшать процесс их последующего анализа и обработки.
Комментарии (4)

Alfair
00.00.0000 00:00У меня сын (студент ВШЭ СпБ) делал точно такую же лабораторную работу по питону, а я ему помогал немного, знаю... И, судя по всему, использовал ту же методичку: нижний регистр, стоп-слова, лемматизация, токенизация, кластеризация; тот же Word2Vec и KMeans; картинки те же. Правда в отличие от, данные брались иные, и кластеризация отработала как надо. Хорошо что этого достаточно на статью на Хабре :)
Ну или если достаточно, то можно дополнить её ссылкой на те методические материалы, на основе которых этот "неудачный опыт" (с) ставился.

SanSanychSeva
00.00.0000 00:00Интересно было бы сравнить результаты не только метриками моделей на векторизированных параметрах, но и просто посмотреть на сами новости, которые попали в аномалии на разных моделях - еще лучше как-то прогнать их через разметку целевой аудиторией биржевых игроков, чтобы иметь обучение с подкреплением.
А насколько вообще идея рассмотрения новостей по отдельности релевантна задаче - предсказания влияния на биржу? Не разумно ли ожидать, что одна и та же новость - в зависимости от контекста всей ситуации в мире - может вызвать различную реакцию на биржах, ну или хотя бы различную по интенсивности, если не по знаку?

CrazyElf
Кажется, тут что-то пропущено. Новости же были не из одного слова? А тогда как вы строили вектор новости из векторов слов? Это же тоже можно по-разному делать. Кроме того, можно было попробовать topic modeling новостям сделать, то бишь LDA или как его там. А вдруг бы на топиках кластеризация лучше взлетела.