
Если вы разработчик и когда-либо писали интеграционные тесты — скорее всего, вы использовали TestContainers. Появившись в 2015 году, эта библиотека изменила то, как мы производим автоматизацию тестирования, позволив разработчикам запускать интеграционные тесты с участием баз данных на локальных машинах, что существенно сократило сложность интеграционных тестов и время, необходимое для их запуска и прогона.
Testcontainers "по щелчку пальцев" запускают базы данных, но для того, чтобы тесты начали проходить, нужно кое-что ещё: начальные данные внутри базы. Их необходимо подготовить перед запуском тестов, а по мере того, как схема растёт и усложняется, делать это становится всё труднее.
Комбинируя Testcontainers с одной из доступных на сегодня библиотек для синтеза реляционных данных, мы теперь можем заполнять любую Testcontainers-базу данных сгенерированными данными, что позволяет быстро разрабатывать тесты для логики, предполагающие взаимодействие с базой данных, избегая при этом необходимости разрабатывать и поддерживать большие объемы кода.
Какую задачу мы будем решать
Мы будем говорить про интеграционные тесты на логику работы с реляционной базой данных. Т. е. такие, для выполнения которых нужно относительно немного записей в таблицах: нам нужно чётко, прозрачно и детерминированно проверить работу бизнес-логики.
Наряду с этим сценарием, существуют, конечно, и другие ситуации, в которых возникает желание, например, использовать копию рабочей базы с большим количеством данных, но замаскированную (со стёртыми или рандомно изменёнными критическими данными). Также бывает нужно использовать подмножество данных рабочей базы (если данных слишком много) или, наоборот надмножество — если данных ещё недостаточно, а хочется проверить систему на производительность. Все эти случаи выходят за рамки этой статьи (хотя также поддерживаются инструментами генерации данных, и в частности тем, о котором пойдёт речь).
Чем мы будем решать задачу
Synthesized TDK — коммерческий продукт, решающий задачи маскинга и генерации данных для реляционных баз (PostgreSQL, MySQL, SQL Server, Oracle, H2 и некоторых других). У Synthesized TDK существует довольно функциональная бесплатная версия, которая без проблем подходит для генерации не очень больших баз данных, и на её основе мы и построим пример.
Как это работает
Для начала рассмотрим маленький модельный проект микросервиса, созданный с использованием распространённого стека технологий: Java, SpringBoot и SpringJDBC-модуль, использующий PostgreSQL в качестве своей базы данных. Наше модельное приложение будет автоматизировать планирование докладов и участников для большой технической конференции и, следовательно, хранить информацию о конференциях, спикерах и их выступлениях. База данных PostgreSQL имеет вот такую схему:
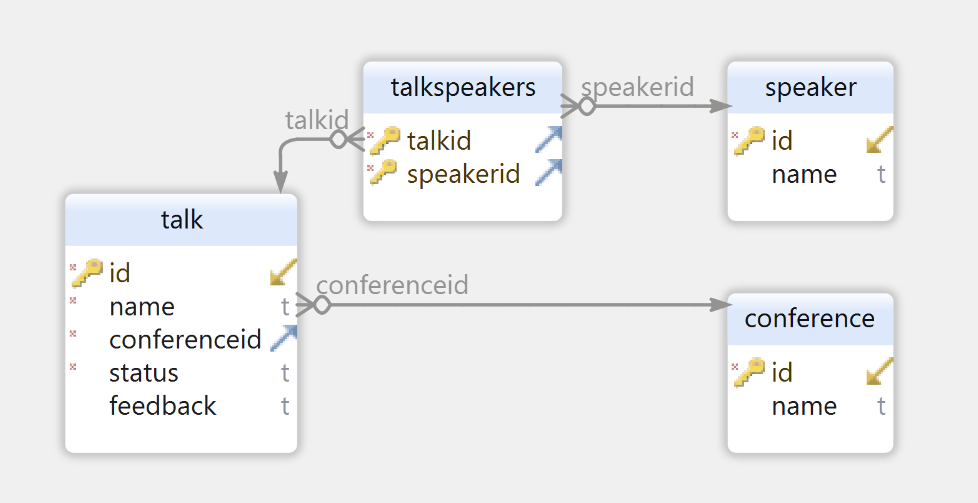
Несмотря на свою простоту, схема требует аккуратной работы с порядком вставки записей, чтобы удовлетворить ограничениям всех вторичных ключей. Если, например, нас интересует всего один доклад, т. е. запись в таблице talk, нам надо прописать связанные записи во всех таблицах. В реальных условиях сложность прописывания тестовых данных ещё выше: я думаю, многим знакома ситуация что для заполнения поля "Адрес" необходимы записи в таблицах "Улица", "Город", "Регион" и "Страна".
Какие подходы существуют для подготовки тестовых данных для интеграционных тестов? Традиционно их два:
- Создание скрипта инициализации, который предварительно заполняет базу данных записями.
- Вставка специфических для теста записей на setup-этапе теста с использованием так называемых "фабрик фикстур".
Оба этих подхода требуют создания некоторого кода и, следовательно, времени для написания реальных тестов. А ведь по мере того, как база данных развивается, этот код ещё необходимо и поддерживать в рабочем состоянии!
Давайте посмотрим, как эта задача может быть полностью автоматизирована.
Всё начинается, как обычно, с добавления зависимости через Maven Central:
<dependency>
<groupId>io.synthesized</groupId>
<artifactId>tdk-tc</artifactId>
<version>1.03</version>
<scope>test</scope>
</dependency>tdk-tc — это небольшая библиотека с лицензией MIT, которая действует как оболочка для бесплатной версии Synthesized TDK, работающей в докер-контейнере. Он предоставляет простой класс SynthesizedTDK, которому потребуются два экземпляра JdbcDatabaseContainer для подготовки тестовой базы данных. Если мы используем SpringBootTest, мы можем выполнить подготовку тестовой базы данных как часть нашей @TestConfiguration.
Давайте теперь определим конфигурацию для подготовки вашей тестовой базы данных.
Предполагая, что в переменной PostgreSQLContainer<?> input находится пустая база данных с развернутой схемой (вы можете получить такой контейнер с помощью простого DDL-скрипта или библиотеки миграций, такой как Flyway или Liquibase), а в PostgreSQLContainer<?> output — полностью чистая база данных, вы можете создать базу данных, предварительно заполненную сгенерированными данными с помощью SynthesizedTDK (обратите внимание, что все контейнеры создаются в одной сети):
private PostgreSQLContainer<?> getContainer(String name, boolean initData) {
...
}
network = Network.newNetwork();
input = getContainer("input", true);
output = getContainer("output", false);
Startables.deepStart(input, output).join();
new SynthesizedTDK()
.transform(input, output,
"""
default_config:
mode: "GENERATION"
target_row_number: 10
tables:
- table_name_with_schema: "public.talk"
transformations:
- columns: [ "status" ]
params:
type: "categorical_generator"
categories:
type: string
values:
- "NEW"
- "IN_REVIEW"
- "ACCEPTED"
- "REJECTED"
probabilities:
- 0.25
- 0.25
- 0.25
- 0.25
global_seed: 42
""");Первые два аргумента метода transform — это контейнеры ввода и вывода. Третий — строка YAML, содержащая параметры генерации данных. Synthesized TDK требует конфигурации, которая подробно описана здесь. Вы можете настроить параметры генерации для каждой конкретной таблицы и поля.
Например, в нашем случае библиотека "не знает", какие значения допустимы в поле status, и их нужно подсказать, сконфигурировав categorical generator (всего же имеется порядка двух десятков доступных типов генераторов и маскеров).
Но если вы не выполните настройку для какой-либо (или для всех) таблиц, Synthesized TDK будет использовать разумные значения по умолчанию, основываясь на типах данных и ограничениях уровня таблицы. Скорее всего, вышеприведённый пример без секции tables будет работать для вашей схемы базы данных, но если нет (или если результат вас не удовлетворит) — то придётся повозиться и дописать этот YAML так, чтобы подсказать системе, как именно имеет смысл генерировать данные.
Два параметра, которые нам нужно понимать в этом примере:
-
target_row_numberопределяет желаемое количество записей, генерируемых для каждой таблицы. -
global_seed— это seed для генератора случайных чисел. Результат генерации будет гарантированно одинаковым каждый раз, если генерация запускается с одним и тем же начальным seed-ом, не изменившейся схемой базы данных и не изменившейся YAML-конфигурацией.
Обратите внимание, что для того, чтобы иметь непустую тестовую базу данных, нам больше не нужен полный скрипт с INSERT-ами! Просто выбрав фиксированный seed для генератора случайных чисел, мы можем быть уверены, что результирующие данные в базе данных будут одинаковыми каждый раз, когда выполняется метод SynthesizedTDK.transform(...).
Когда выходная база данных готова, мы можем создать ссылающийся на неё источник данных, который будет использоваться тестами, например, объявив соответствующий @Bean в нашей @TestConfiguration:
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl(output.getJdbcUrl());
config.setUsername(output.getUsername());
config.setPassword(output.getPassword());
return new HikariDataSource(config);
}Arrange, Act, Assert
Теперь давайте рассмотрим метод, который мы хотим протестировать — как следует из его названия, он возвращает информацию о докладах для данной конференции:
public Set<Talk> getTalksByConference(Conference conference)Нам нужен объект conference в качестве входных данных, а затем нам нужно сравнить результат с некоторым эталонным значением.
Поскольку наша база данных не пуста и удовлетворяет всем ограничениям, мы можем использовать наши собственные DAO-классы, чтобы получить первую попавшуюся конференцию:
//The object under test
@Autowired
private TalkDao dao;
//The object needed to get a conference
@Autowired
ConferenceDao conferenceDao;
private Conference conference;
@BeforeEach
void init() throws SQLException {
conference = conferenceDao.getConferences().iterator().next();
}Фактически это вся "Arrange"-часть теста. Поскольку генерация данных детерминирована, конференция (и ее связь со всеми другими объектами) будет одинаковой для всех прогонов теста.
"Act"-часть состоит всего из одной строки:
@Test
void getTalksByConference() {
//Act
Set<Talk> talks = dao.getTalksByConference(conference);
//Assert
JsonApprovals.verifyAsJson(talks);
}
Как насчет "Assert"-части? Поскольку генерация является детерминированной, мы можем выяснить фактические свойства возвращаемого Set<Talk>, а затем добавить проверки. Однако есть более простой способ сделать это с помощью Approval-тестов. Библиотека Approvals — ещё один из инструментов, облегчающих написание интеграционных и e2e тестов — создает моментальный снимок нашего Set<Talk>, сериализованного в виде JSON, и сохраняет его в текстовом файле в папке с тестовым кодом. В нашем случае вывод выглядит так:
[
{
"id": 3,
"name": "MnkVLBcSGJeelU190EZAwq",
"conference": {
"id": 5,
"name": "9zx3i8oNspCHrkIhneNYG18"
},
"status": "NEW",
"feedback": "RoopSXMfpkPYSNA1W4N",
"speakers": [
{
"id": 2,
"name": "c"
}
]
}
]Судя по этому файлу, можно сделать вывод, что наш метод действительно возвращает набор докладов с заполненными свойствами conference и speakers. Этот файл должен быть зафиксирован в системе управления версиями, и он будет использоваться каждый раз при запуске теста, чтобы гарантировать, что результат не изменится.
Обратите внимание, что мы прилагаем очень мало или вообще ноль усилий, чтобы написать "Arrange" и "Assert". Таким образом, используя Synthesized TDK, мы можем значительно сократить время написания тестов.
Конечно, мы можем добавить больше проверок для возвращаемого значения, например, проверить, что возвращенные доклады действительно принадлежат конференции:
for (Talk talk : talks) {
assertThat(talk.getConference()).isEqualTo(conference);
}В приведенном выше примере мы только что проверили метод, извлекающий данные из базы данных, но это не требует сложной бизнес-логики. Давайте теперь рассмотрим кое-что посложнее.
Представьте, что у нас есть сервисный класс TalkService, который имеет дело со статусами заявок на доклады, и мы хотим проверить, что ни один доклад не может быть переведен в статус REJECTED без заполнения поля feedback с объяснением причин отказа.
Для этого тестового сценария нам нужен доклад (экземпляр Talk) с предопределенным состоянием. Мы можем проделать следующее: взять любой доклад из базы данных и изменить его состояние на желаемое. Здесь мы проверяем, что обсуждение с непустым полем feedback может быть переведено в статус REJECTED:
@Test
void rejectInReviewWithFeedback() {
//Arrange
dao.updateTalk(talk.withStatus(Status.IN_REVIEW)
.withFeedback("feedback"));
//Act
service.changeStatus(talk.getId(), Status.REJECTED);
//Assert
Assertions.assertThat(dao.getTalkById(talk.getId()).getStatus())
.isEqualTo(Status.REJECTED);
}В этом тесте мы проверяем, что попытка отклонить доклад с пустым полем feedback вызывает исключение:
@Test
void doNotRejectInReviewWithoutFeedback() {
//Arrange
dao.updateTalk(talk.withStatus(Status.IN_REVIEW)
.withFeedback(""));
//Act, Assert
Assertions.assertThatThrownBy(() ->
service.changeStatus(talk.getId(), Status.REJECTED))
.hasMessageContaining("feedback");
Assertions.assertThat(dao.getTalkById(talk.getId())
.getStatus()).isEqualTo(Status.IN_REVIEW);
}
Заключение
Чтобы попробовать Synthesized TDK с Testcontainers, ознакомьтесь с демо-проектом здесь. Все примеры кода взяты из этого проекта. Если вы хотите освоить написание сложных конфигураций для синтеза данных, или использовать TDK для других задач, полезно прочесть документацию по Synthesized TDK. Поставьте звёздочку на tdk-tc, если тема генерации тестовых данных вам интересна :-)
Комментарии (5)

aleksandy
00.00.0000 00:00+3Генерация хороша для демонстраций, у любого теста (модульного/интеграционного/etc.) главное, чтобы он был воспроизводимым. А этого можно добиться только контролем начального состояния.
Вот, надо мне проверить, что сервис ищет какие-то данные в БД, используя внешнее соединение таблиц, как я буду это проверять, если я, в общем случае не контролирую записи, которые имеются в таблице? На ум приходит только вставка в начало теста проверок того, что БД находится в том состоянии, которое мне нужно. Но чем это будет отличаться от той же ручной вставки данных?

IvanPonomarev Автор
00.00.0000 00:00+2Вот, надо мне проверить, что сервис ищет какие-то данные в БД, используя внешнее соединение таблиц
Посмотрите ещё раз на
getTalksByConference.В нем мы проверяем, что из доклада вытаскивается и конференция, и спикеры, т. е. ровно то, о чём Вы и пишете :-)Помимо шуток -- я согласен с тем, что в общем случае случайно выбранная запись может не обладать нужным состоянием и её придётся в это состояние загонять. Но по опыту можно исходить из того, что делать это придётся реже (и прикладывать меньше усилий), чем пытаясь заполнить базу с нуля. Здесь мы имеем классический инженерный трейд-офф, что за какие-то преимущества приходится платить какую-то цену. Преимущество, которое мы получаем -- объективно меньше кода для сетапа тестов и меньше затрат на его поддержку. Цена, которую платим: тесты надо писать, помня о том, что по умолчанию мы ничего не можем "подразумевать" о входных данных, не прописав в них явно какое-то состояние. В 9 случаях из 10 нам подойдёт и то, что сгенерировано случайным образом. В 1 случае из 10 придётся заморочиться. Не используя генерацию, мы будем заморачиваться в 10 случаях из 10.

souls_arch
00.00.0000 00:00+1Хорошая была статья до 24 февраля прошлого года. Теперь ни бесплатных сервисов по генерации тест данных не поюзать без vpn ни платных купить нельзя(без танцев с бубнами), если живешь в рф. Как наши импортозаместят - пишите. (
insomnia77
Добрый день, спасибо за интересную статью.
К сожалению в бесплатной версии разрешено использовать максимум 20 таблиц. Вы случайно, не знаете ориентировочную стоимость платной подписки?
IvanPonomarev Автор
Насколько я понимаю, цена там сейчас определяется индивидуально, но: а сколько у вас примерно таблиц? Не исключено, что проще уговорить подвинуть лимиты бесплатной версии