Привет, Хабр! Меня зовут Дарья Чувашова, я — руководитель группы отделения SAP-разработки. В процессе моей проектной деятельности мне приходилось сталкиваться с задачами выгрузки документов в .doc формат и делать это нужно было быстро. При этом эти документы могли быть с совершенно разным форматированием, кучей таблиц, реквизитов и т. д. В SAP для выгрузки в форматы pdf и excel есть удобные инструменты, возможность работать с формулярами и графическими редакторами форм. Для работы с форматом.doc инструментов меньше. В этой статье я расскажу о быстром и самом простом способе выгрузить документ любой сложности.

Почему я решила написать этот «how‑to»? Как я упомянула, задачи по выгрузке файлов в.doc мне приходилось выполнять часто. В какой‑то момент я собрала все лайфхаки и советы по ускорению работы в один материал, а сейчас хочу поделиться им с хабровской аудиторией. Надеюсь, для коллег записи будут полезными. Описанный вариант решения имеет свои особенности, поэтому я постараюсь на примерах продемонстрировать некоторые «узкие» моменты.
Пошаговая инструкция решения вопроса
Шаг 1
В первую очередь нам нужно подготовить шаблон в MS Word в нужном формате. Важно заполнить все реквизиты тестовыми данными для примера, это значительно упростит нам жизнь в последующих действиях.
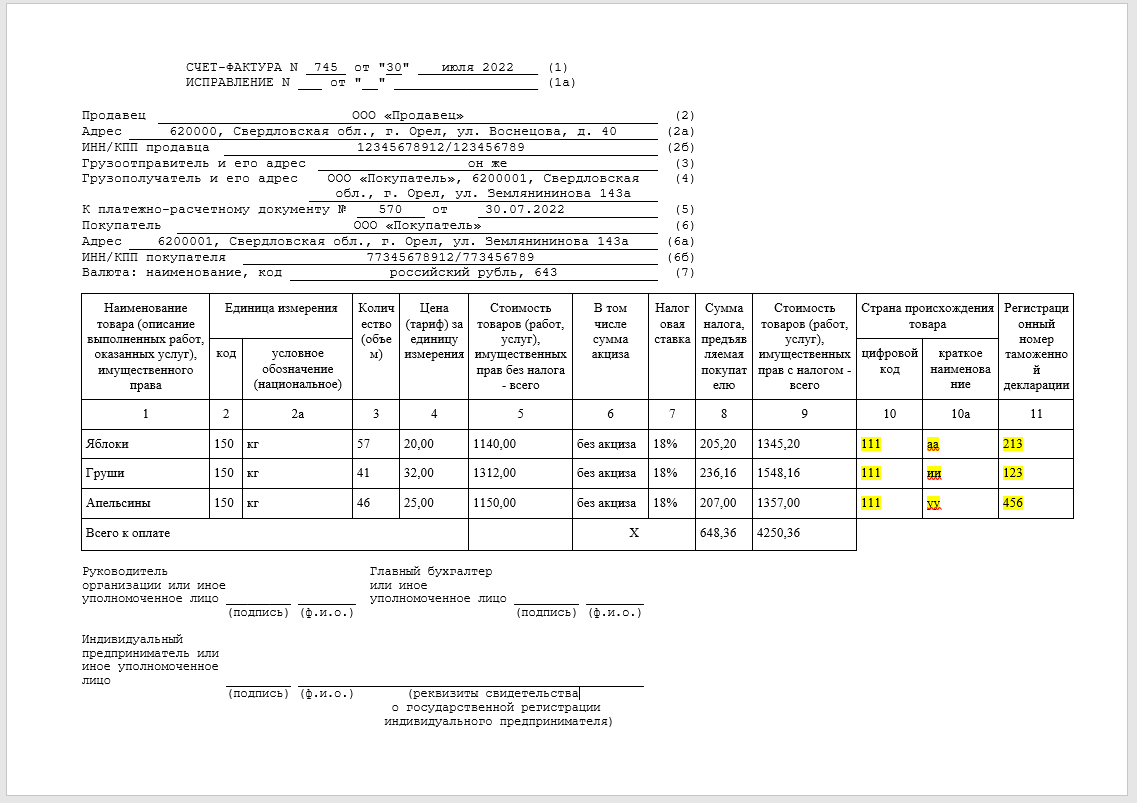
В качестве примера рассмотрим вот такой документ «Счёт‑фактура» в MS Word:

Шаблон необходимо заполнить тестовыми примерами, чтобы проверить, что при заполнении ничего не съезжает, и все реквизиты остаются на месте:
Шаг 2
Сохраним наш документ в формате XML: Файл - Сохранить как. Выбираем расширение .xml


Примечание: для большинства задач вполне достаточно формата.doc, он поддерживает ограничения редактирования, элементы управления и т. п.
Для того чтобы открыть данный файл, мне удобно использовать программу Altova XML Spy. Скорее всего нам потребуется проанализировать содержимое, а в данной программе выполнять анализ файла очень удобно за счёт подсветки синтаксиса. Вы, конечно, можете использовать любой другой редактор.
Открываем свой XML, видим примерно такую картину:

После применения команды PrettyPrinter:

Шаг 3
Переходим в SAP. В своём пакете разработки создадим Преобразование:

Выберем трансформацию XSLT:

Видим следующую картину:

Для того, чтобы наша трансформация верно работала, необходимо указать следующий код между тегами <xsl:template match="/"> </xsl:template>:
<xsl:processing-instruction name="mso-application" progid="Word.Document">
<xsl:text progid="Word.Document"/>
</xsl:processing-instruction>
Теперь можно смело вставить весь XML‑код ниже из нашего документа:

Визуально просматриваю данный XML‑код, обнаруживаю, что часть тегов подсвечивается, как текст:

Вижу, что это произошло из‑за кавычек в наименовании компании (Company), смело их удаляю:

Теперь пытаемся активировать трансформацию. В 90% случаях активация пройдёт успешно.
Но если у вас появятся подобные ошибки,

Предлагаю стереть данные коды, так как они не имеют никакого смысла для генерации документа из SAP.

Удаляем:

После удаления всех кодов трансформация успешно активируется.
Шаг 4
Переходим в программу. Для вызова трансформации и выгрузки файла привожу для примера такой код:

Данный код максимально облегчён для простоты восприятия и предельной наглядности.
После запуска программы в папке C:\TEMP сохранится файл точно в таком же виде, как наш подготовленный шаблон:

При открытии файла может возникнуть следующая ошибка:

Для того, чтобы от неё избавиться, переходим в трансформацию и ищем /word/settings.xml

Избавиться от ошибки мне помогло удаление всего блока <pkg:part … </pkg:part>. Это не повлияло на работоспособность, и файл стал открываться нормально. Без подсветки синтаксиса тяжело искать закрывающий тег, поэтому имеет смысл снова воспользоваться программой Altova XML Spy (в данной программе вы можете удалить лишний код, а затем вставить новую версию в нашу трансформацию).

Удаляем и активируем, проверяем, что ошибка ушла и с файлом всё в порядке.

Шаг 5
Переходим к выгрузке данных из контекста. Начнём с самого простого: выгрузим данные в поле «Продавец»:

Контекст представляет собой структуру c данными, например, вот такую:

Её мы заполняем и подаём в трансформацию как контекст. Далее копируем из файла, заполненного в качестве примера, текст из реквизита «Продавец» и ищем это место в нашей XML:

Вместо данного текста вставляем:

Не забываем указать нужную структуру контекста и сделать выборку данных. Для примера прописываю хардкодом наименование продавца:

Результат трансформации:

Остальные реквизиты заполняем аналогично.
Как видим, заполненный на Шаге 1 пример нам помогает выполнять быструю навигацию по XML и искать нужные места для доработки.
Отдельную сложность может представлять собой заполнение табличных данных. В структуре контекста имеем вложенную таблицу с данными T_INVOICE. Для вывода данных используем цикл for each. Начнём с 1 строки 1 столбца. Ищем поиском пример «Яблоки» и вставляем код, приведённый чуть ниже.
Теги описания таблицы довольно понятны: <w:tc> </w:tc> — стоблец, <w:tr </w:tr> — соответственно строка, ну и сам текст <w:t> </w:t>.
Если мы хотим каждую строку таблицы из контекста выводить в новую строку таблицы, то цикл ставим перед тегом строки и закрываем после окончания описания строки:

Конец цикла будет обозначен тут:

Так как таблица большая, окончание цикла будет через 400 строк, поэтому удобно воспользоваться опять же программой с подсветкой тегов, таким образом выводим все необходимые элементы таблицы.
Результат:

Видим, что строка автоматически добавилась. Так как нам не нужны старые данные из примера, удалим эти строки из таблицы. Ищем так же по тегам.

В идеале можно было бы в самом шаблоне оставить лишь одну строку для заполнения, тогда лишних действий по удалению колонок не пришлось бы делать. Но я хочу показать неидеальный случай.
Если необходимо вывести данные из таблицы контекста не в каждой строке таблицы, а текстом с переносом, то можем воспользоваться тегом переноса строки <w:br/>, например,

Получим вот такой результат:

Ещё немного полезных рекомендаций
Мы разобрали основные шаги, как сделать выгрузку любого реквизита и заполнить таблицу. При этом необязательно думать о размере шрифта или форматировании, достаточно изначально выстроить необходимые настройки и правки в исходном документе.
Что ещё записано в моих заметках?
Как поменять шрифт быстро, если он перестал подходить? Допустим, мы желаем заменить Arial на Calibri. Для этого в трансформации выполняем поиск Arial — «Заменить все» и вставляем название нового шрифта Calibri.
Как сделать защиту листа и позволить редактировать лишь некоторые реквизиты в выгруженном файле?
Для этого нужно в исходном файле на 1 шаге настроить защиту листа, тогда кодирующие эту операцию теги будут отражены в нашей трансформации.
Примеры исходного кода из статьи можно увидеть в репозитории github.
Данной информации должно быть достаточно, чтобы сделать выгрузку практически любого документа быстро и эффективно.
Комментарии (6)

PhysicalGraffiti
00.00.0000 00:00+3В первую очередь нам нужно вспомнить, что.doc формат — это по сути тот же самый XML формат.
Это не так.
В статье идет работа с docx - это zip архив, который содержит несколько файлов и папок (https://ru.wikipedia.org/wiki/Office_Open_XML).
doc - проприетарный бинарный формат (https://en.wikipedia.org/wiki/Doc_(computing)#Microsoft_Word_Binary_File_Format)
DChuvashova Автор
00.00.0000 00:00+1Спасибо за комментарий)
Мой первый блин немного комом, как говорится, буду внимательней в будущем :)

ibnteo
00.00.0000 00:00Давно ещё сделал XSLT трансформер из формата AbiWord в FB2, можно быстро создать книгу из документа, которую удобно читать на небольших экранах.
mthps
"За 5 простых шагов"
"Шаг 0"
(10 экранов текста)
"Шаг 6"
Почему в сапе всегда так?
DChuvashova Автор
0 шаг можно поручить консультанту или тому, кто лучше всех знает ворд)