
Сейчас я интервьирую кандидатов которые приходят на позиции в RTL design / проектировщики микросхем на уровне регистровых передач. Но 5 лет назад я интервьировал студентов и других инженеров на позиции в DV / Design Verification / верификаторы блоков микросхем.
Моим стандартным вопросом было написать маркером на доске псевдокод для упрощенного драйвера модели шины (Bus Functional Model - BFM) для протокола AXI. На этом вопросе у ~80% кандидатов наступала агония - они как ужи на сковородке пытались натянуть сову на глобус - приспособить решение для последовательной шины а-ля APB, которое они прочитали в каком-нибудь туториале - к шине AXI, которая во-первых конвейерная, а во-вторых, допускает внеочередные ответы на запросы чтения с разными идентификаторами.
Аналогия из другой области: представьте, что кто-то пытается обходить дерево или решить "ханойские башни" - не зная концепций рекурсии и стека. Или написать GUI интерфейс, не зная концепции cобытийно-ориентированной архитектуры.
Причина не в том, что студенты глупые, а в том, что: 1) в вузах верификации не учат (даже в Беркли и Стенфорде) и 2) цель авторов туториалов - не научить методам верификации, а научить синтаксису языков (SystemVerilog) и возможностям библиотек (UVM). Поэтому при попытке решить проблему студенты начинают танцевать кругами, заводят fork-и для потоков, семафоры, получают частные случаи, которые глючат. Или начинают накручивать объектно-ориентированное программирование, код внутри интерфейсов, ожидая что время интервью пройдет, хотя проблема в сердце этого кодового гарнира остается.
При этом у задачи существует простое и надежное, но несколько контр-итуитивное решение. Базовую идею я впервые увидел еще в 1990-е годы, когда я работал в Mentor Graphics (сейчас Siemens EDA) в проекте с Nokia и Ericsson, которые тогда проектировали ранние массовые сотовые телефоны. Потом я эксплуатировал тот же подход при работе в Denali (сейчас Cadence), причем клиентами моих BFM-ов были Apple, Broadcom, Xilinx. Затем делал то же самое для клиентов MIPS (PMC Sierra). У некоего японского инженера в Камакуре, которые использовал мою BFM в проекте "зеленого суперкомпьютера", следы этого решения даже просочились в BFM для open-source RISC-V проекта.
Но начнем с начала. Модель интерфейса шины (Bus Functional Model, BFM) - это программа, которая переводит транзакции в последовательности изменений сигналов, а также последовательности изменений сигналов - в транзакции. Транзакция - это высокоуровневый объект, который может передаваться по интерфейсу один или несколько тактов, возможно пересекаясь по времени с другими транзакциями (pipelining, interleave).
Транзакция может быть структурой или объектом класса в SystemVerilog или С++. Например, простая транзакция для минимального подмножества AXI (без burst, mask, locked итд) выглядит так:
class axi_transaction;
rand op_t op; // чтение или запись
rand addr_t addr; // адрес
rand data_t data; // данные
rand id_t id; // идентификатор чтобы понять к какому
// адресу на шине относятся данные
rand delay_t addr_delay; // задержка в тактах для адреса
rand delay_t data_delay; // задержка в тактах для данных
bit data_is_set; // Флаги которые устанавливаются
bit addr_is_sent; // при обработке транзакции
bit data_is_sent;Транзакции удобны для такого моделирования поведения аппаратных объектов, при котором важен только порядок событий, а не конкретный такт, в который оно произошло. BFM собственно и привязывает транзакции к тактам.
Здесь и далее я буду ссылаться на пример упрощенного Verification IP, который я написал для образовательных семинаров и которое будет в частности использоваться для занятия Школы Синтеза Цифровых Схем в субботу 1 апреля, с полудня по московскому времени (занятия проходят на 12 площадках от Питера до Томска). Вот сайт Школы и телеграм‑канал.
Так вот. Уже лет 20 писатели туториалов по SystemVerilog и BFM переписывают друг у друга один и тот же код примеров, который условно говоря выглядит так:
task run ()
while (не конец)
begin
получить следующую транзакцию из теста
выставить на шину ее адрес
если запись, то выставить данные для записи
@ (posedge clock) перейти на следущий такт
while (не готово)
@ (posedge clock) перейти на следущий такт
если чтение, получить данные чтения с шины
закончить транзакцию
end
endtask
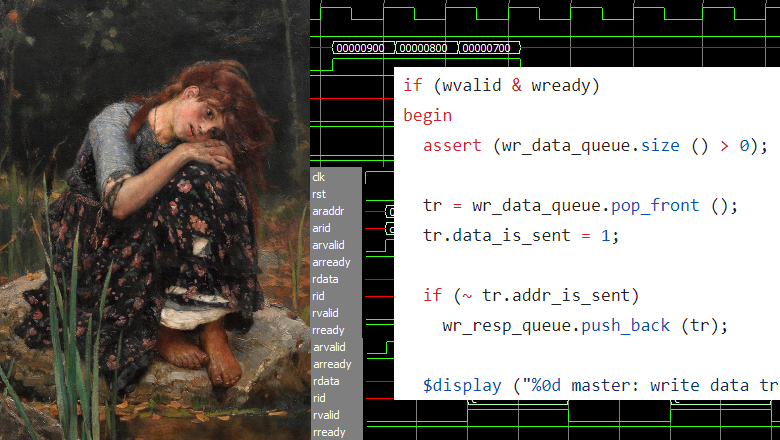
Такого рода код вполне адекватно описыват поток последовательных транзакций, когда следущая транзакция начинается после окончания предыдущей. Например:
такт 1 : адрес чтения 1
такт 2 : данные 1
такт 3: адрес чтения 2
такт 4: данные 2
такт 5: адрес чтения 3
такт 6: данные 3:
Проблема в том, что в AXI (и не только AXI, но и в AHB, OCP и других конвейерных шинах, применяемых внутри систем на кристалле) следущая транзакция может начаться, когда еще не прочитано подтверждение за предыдущую.
Например:
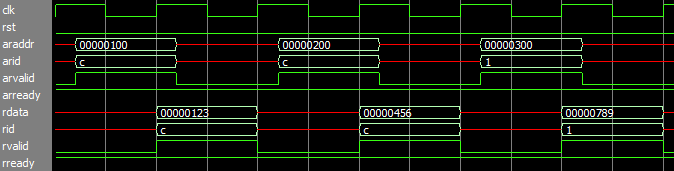
такт 1 : адрес и данные записи 1
такт 2 : адрес и данные записи 2 начинаются еще до считывания мастером подтверждения (response valid) записи 1 от слейва
такт 3: адрес и данные записи 3 начинаются еще до считывания мастером подтверждения (response valid) записи 2 от слейва:
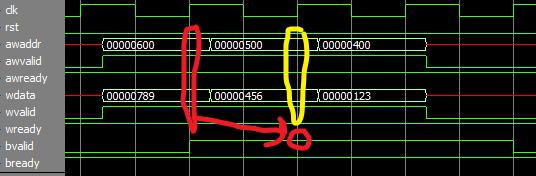
Хуже того: мастер может выдать сначала такт за тактом адрес1-адрес2-адрес3, а потом данные для этих трех адресов данные1-данные2-данные3:
Тут студент на собеседовании говорит: "нет проблем, давайте заведем три треда" и пишет что-нибудь типа:
fork
// Поток 1
begin
получить следующую транзакцию-1 из теста
выставить на шину ее адрес-1
repeat (n) @ (posedge clock) пропустить n тактов
выставить на шину ее данные-1
end
// Поток 2
begin
получить следующую транзакцию-2 из теста
выставить на шину ее адрес-2
repeat (n) @ (posedge clock) пропустить n тактов
выставить на шину ее данные-2
end
....
Тут сразу следует от меня вопрос: "а как гарантировать, что данные от транзакции 1 на окажутся на шине в том же такте, что и данные от транзакции 2"? Студент предлагает использовать семафоры.
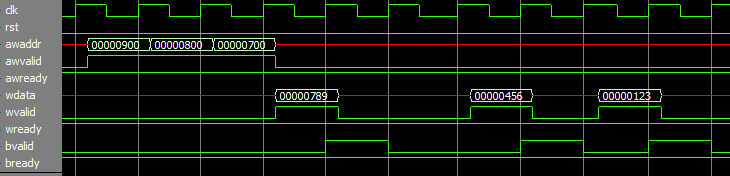
Тогда я говорю: "а вы в курсе, что данные в AXI могут прийти перед адресом?" Например такт за тактом данные1-данные2-данные3, а потом адрес1-адрес2-адрес3:
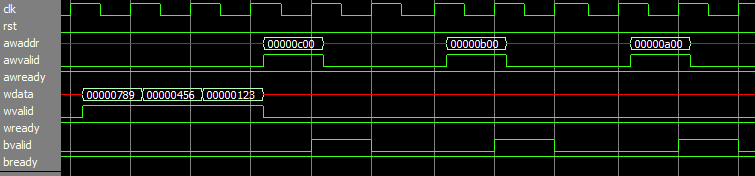
Студент начинает еще усложнять. Тогда я говорю: "и вообще на шине может быть одновременно 16 транзакций, причем ответы от запросов на чтение могут приходить не в том порядке, в котором посылались запросы. Вы так и будете 16 тредов писать и семафорами их синхронизировать?"

Одновременно на это накладывается проблема с valid-ready, но опустим ее в этом посте, так как я про нее уже писал в Что делать, когда выпускник топ-10 мирового вуза не может спроектировать блок сложения A+B.
Мой подход выглядит так: не пытаемся последовательно проходить одну транзакцию в одном треде который работает несколько тактов. Вместо этого заводим кучу очередей, между которыми перебрасываем транзакции. И работаем с этими очередями внутри одного такта, причем задом наперед: сначала обрабатываем ответы слейва, потом незавершенные передачи мастера, только в конце устанавливаем на шины адреса и данных новые транзакции если шины не заняты. Никаких семафоров, тредов (треды используются в интерфейсе к драйверу, но не в драйвере). Это вам не RTOS, а хардверный симулятор, не надо путать!
В одной компании я работал с юным инженером из юго-западной Европы, который долго сопротивлялся, не верил что так может работать, потом его пробило "ой, а что, так можно?"
Итак, заводим очереди транзакций:
// очередь транзакций, полученных от пользователя
axi_transaction send_queue [$];
// очередь транзакций, передаваемых пользователю
axi_transaction receive_queue [$];
// очередь транзакций, ждущих подтверждения ready
// для valid адреса чтения
axi_transaction rd_addr_queue [$];
// очередь транзакций, ждущих подтверждения ready
// для valid адреса записи
axi_transaction wr_addr_queue [$];
// очередь транзакций, ждущих подтверждения ready
// для valid данных для записи
axi_transaction wr_data_queue [$];
// Массив (индексируемый id) очередей
// ждущих прибытия данных чтения от слейва
axi_transaction rd_data_array [n_ids][$];
// Очередь транзакций ждущих подтверждения записи от слейва
axi_transaction wr_resp_queue [$];Далее создаем обработчик ровно одного такта ("always @ (posedge clock)", в котором делаем следущее:
Проверяем, принят ли мастером ответ от слейва по поводу чтения ("if (rvalid & rready)"). Если да, перебрасываем головную транзакцию очереди rd_data_array [read id] в хвост очереди ответов пользователю. При этом записывам в транзакцию полученные данные.
Проверяем, принят ли мастером ответ от слейва по поводу записи ("if (bvalid & bready)"). Если да, перебрасываем головную транзакцию очереди wr_resp_queue в хвост очереди ответов пользователю.
Проверяем, подтвердил ли слейв получение адреса чтения ("if (arvalid & arready)"). Если да, перебрасываем головную транзакцию очереди адресов чтения rd_addr_queue в хвост очереди rd_data_array [read id].
Проверяем, подтвердил ли слейв получение адреса записи ("if (awvalid & awready)"). Если да, помечаем головную транзакцию очереди адресов записи wr_addr_queue флагом address_is_sent и выкидываем ее из очереди. При этом, если она еще не помечена флаом data_is_sent, помещаем ее в хвост очереди wr_resp_queue.
Проверяем, подтвердил ли слейв получение данных записи ("if (wvalid & wready)"). Если да, помечаем головную транзакцию очереди данных для записи wr_data_queue флагом data_is_sent и выкидываем ее из очереди. При этом, если она еще не помечена флаом address_is_sent, помещаем ее в хвост очереди wr_resp_queue.
Получаем новые транзакции из очереди transmit_queue и заносим их, в зависимости от типа, в хвосты очередей rd_addr_queue, wr_addr_queue и wr_data_queue.
Начинаем выставлять транзакции на шины (наконец-то!) Если очередь адресов чтения rd_addr_queue непуста и при этом в головной транзакции нет задержки в количестве тактов, выставляем адрес на шину адресов чтения. Иначе ставим arvalid=0. Если очередь непуста и есть задержка в количестве тактов, уменьшаем задержку.
Для адресов записи аналогично (7).
Для данных для записи аналогично (7).
Вот и все. Выглядит незамысловато, но такими моделями шин торговала дюжина компаний, а компания по Verification IP под названием Denali была продана Cadence-у в 2010 году ровно за столько же ($315 миллионов долларов), за сколько Cadence-у же в 2005 году была продана компания Verisity, которая сделала язык "e".
Писание BFM-ов - это хороший хлеб, так как у кучи людей такое программирование вызывает взрыв мозга, при этом если его понять, то все очень просто. Их можно даже писать из Долгопрудного на американский рынок, хотя один такой случай расследовало ФБР.
И еще раз напомню, что пример будет разбираться преподавателем зеленоградского МИЭТ Сергеем Чусовым в эту субботу 1 апреля на Школе Синтеза Цифровых Схем, подробности в телеграм‑канале.
UPD: трансляция:
Комментарии (12)

Zara6502
00.00.0000 00:00+3Возможно только я такой, но "тьюториал" читается очень тяжело.
В русском ИТ-сленговом уже давно (я лет 30 вижу) спокойно пишут "туториал". На худой конец слово "руководство" совсем не испортит материал. Ну или "мануал", хотя это и немножко про другое (не "мэньюэл" же в любом случае).

shovdmi
00.00.0000 00:00+3у ~80% кандидатов наступала агония - они как ужи на сковородке пытались натянуть сову на глобус
….
Базовую идею я впервые увидел еще в 1990-е годы, когда я работал в Mentor Graphics
Интересно, а что бы сам интервьюер делал в этой ситуации

YuriPanchul Автор
00.00.0000 00:00+2До того, как я понял как это должно работать, я точно так же натягивал сову на глобус, например пробовал сделать конечные автоматы для таких транзакций. Но в то время вообще не было никаких туториалов и такого рода знания передавались лично.
Тут надо отметить, что я давал такое упражнение на собеседовании только людям, которые писали в резюме, что они понимают верификацию и знакомы с AXI. Назвался груздем - полезай в кузов.
Также были люди (например практикант из Стенфорда), которого я этому научил с нуля.

punzik
00.00.0000 00:00А как верифициоровать VIP?
YuriPanchul Автор
00.00.0000 00:00+1О! С козыря пошли :-)
Master driver верифицируется против reference slave, а они оба верифицируются пассивным монитором (все в рамках одного VIP). Об этом будет на занятии.

Myclass
00.00.0000 00:00Вы задаёте одно такое задание или несколько разных? И ещё- не выполнив или выполнив на 20% это задание - человек провалился и нет у него никакого шанса? Спасибо.
YuriPanchul Автор
00.00.0000 00:00Заданий я давал несколько - начинал с тривиальных вопросов, а потом такое задание. На основе него я видел процесс мышления человека - как он пытается решать задачу, видит ли подводные камни, с чем он знаком итд. То есть определял его уровень.
Понятно, что если человек студент и решить такого не может, но OK по другим параметрам, то его можно доучить.
Но если человек работал в данной части индустрии скажем 15 лет и не может адекватно решать таких задач - то это означает, что он везде делал что-то кондовое, то есть имеет не "15 лет опыта", а "опыт в 1 год 15 раз" - тогда его нанимать бессмысленно.
Myclass
00.00.0000 00:00Спасибо. Полностью с Вами согласен. Найти талантливых от природы несложно, но таких немного. Найти не многое ещё видавших, но с потенциалом - вот тут надо по-стараться. Желаю Вам удачи.
maquefel
В какой именно если не секрет ?
YuriPanchul Автор
Вот он https://github.com/taichi-ishitani/tvip-axi
Этот инженер работал в PEZY, японской компании, которая лицензировала у MIPS пакет, в котором была и моя BFM, которая, судя по определнным решениям в коде, оказала на этого товарища влияние
Например запись событий в транзакции https://github.com/taichi-ishitani/tvip-axi/blob/master/src/tvip_axi_item.svh