
Привет, Хабр! Меня зовут Андрей Чернов, я Java-архитектор микросервисов в СберТехе — компании, которая создала цифровую облачную платформу Platform V для разработки бизнес-приложений. Наша команда развивает продукт Platform V SessionsData — высокопроизводительное распределённое in-memory-хранилище для общего контекста сессионных и key-value-запросов, которое СберБанк Онлайн использует в качестве микросервиса на своей серверной стороне. Продукт актуален не только для решения задач СберБанка Онлайн: он доступен рынку и может использоваться для аналогичных целей в любых отраслях.
В статье расскажу, почему мы решили создать собственный микросервис, чем он нам помогает, а также как мы справлялись с нагрузкой СберБанка Онлайн. У статьи будет продолжение. Во второй части поговорим о том, как мы достигаем высокой доступности сервиса, а в третьей — какие доработки нужны нам, чтобы развивать Platform V SessionsData.
Задача: хранение данных активных сессий СберБанка Онлайн в оперативной памяти
Крупные сервисы обслуживают огромное количество онлайн-клиентов. При этом в сессии клиента накапливаются уникальные для него данные, которые нужно где-то хранить. Например, СберБанк Онлайн объединяет сотни микросервисов, и каждому при работе с клиентом нужно сохранять результаты своей работы, чтобы другие микросервисы могли обслуживать пользователей далее.
При этом данные всех существующих в моменте сессий важно хранить в оперативной памяти, чтобы к ним был быстрый доступ. Само хранилище должно располагаться в бэкенде, потому что данные могут быть конфиденциальными. Изначально для этой задачи в Сбере использовался in-memory data grid IBM WebSphere eXtream Scale, но он плохо зарекомендовал себя под нагрузкой в эксплуатации. Нужно было найти новое решение.
Platform V SessionsData
Таким решением стал продукт Platform V SessionsData. Вот как выглядела его исходная архитектура:
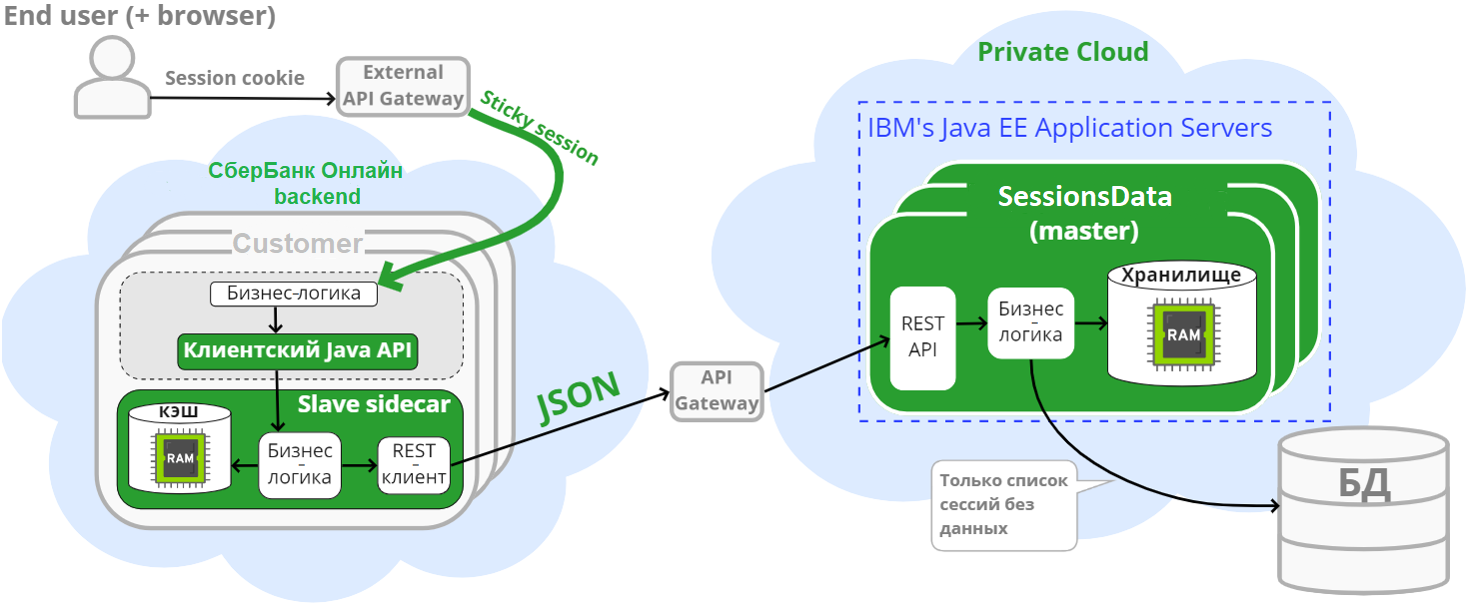
In-memory-хранилище находится в памяти отдельно развёртываемого мастер-компонента сервиса. В нём хранятся данные сессий пользователей, а в базе данных мы храним только список активных в настоящий момент сессий.
На каждый хост потребителей ставится служебное приложение — slave sidecar. Потребитель обращается к нему REST-вызовами по localhost, используя наш клиентский JAR. А сам slave ходит по сети к мастеру за данными и активно их кеширует, чтобы лишний раз не обращаться к сети.
Чтобы кеширование на slave экономило как можно больше запросов по сети, мы «приклеили» сессию конкретного пользователя к конкретному узлу микросервиса-потребителя. Так конкретная сессия пользователя всегда попадает в один и тот же кеш на slave. В итоге, в среднем каждый третий запрос потребителя к сессионным данным не приводит к сетевому запросу в мастер-хранилище. Неплохой результат.
Работа с данными и их передача по сети
Подробнее расскажу про работу с данными в Platform V SessionsData, чтобы пояснить, как они передаются по сети в мастер-хранилище. Данные каждой сессии клиента хранятся в Platform V SessionsData независимо от других сессий. В каждой сессии пары key-value логически группируются в именованные секции. И уже секция — это минимальная единица для передачи данных по сети.
Потребитель с помощью нашего Java API сохраняет в атрибуты секции произвольные Java-объекты: нужно просто передать любой объект в метод setAttribute(). Для этого мы воспользовались сериализацией в JSON с помощью библиотеки Jackson, доработав определённым образом создаваемые JSON-строки.
При создании ObjectMapper пришлось задать целую серию нестандартных параметров. Например, обратите внимание на enableDefaultTyping(). Это означает, что в JSON нужно зашивать полные имена Java-классов для каждого объекта:

Так при этом выглядит JSON, зато после десериализации мы получаем те же объекты, какие сохранили:

Выше мы рассмотрели один атрибут с нестандартным объектом потребителя, то есть одну пару key-value. А секции данных, как мы говорили, — это логические наборы таких пар. Каждую секцию после сериализации мы сжимали с помощью Zip, получали байтовые массивы и помещали в DTO, отправляемые по сети в мастер. Эти DTO мы уже сериализовали в обычный JSON тем же Jackson.
Таким образом, в Platform V SessionsData мы используем два уровня сериализации. На бизнес-уровне сериализуются секции с бизнес-объектами потребителя в парах key-value, а на транспортном — DTO с несколькими секциями для передачи по сети.
С передачей данных разобрались, теперь посмотрим, какие способы помогли нам справиться с высокой нагрузкой в СберБанке Онлайн.
Выдерживание highload
Три года назад мы вышли в эксплуатационную среду СберБанка Онлайн. Для понимания масштабов нагрузки: это более 110 тысяч новых сессий в минуту. Каждая сессия активна примерно пять минут. Получается, что в каждый момент времени активны более 550 тысяч сессий, которые выполняют в секунду более 120 тысяч запросов к Platform V SessionsData.
В СберБанке Онлайн больше сотни разработчиков, пользующихся нашим сервисом. Постепенно они сохраняли всё больше сессионных данных. Время отклика сервиса под нагрузкой иногда превышало 10 мс. Это сильно отражалось на производительности, и мы занялись оптимизацией.
Мы отпрофилировали JVM в наших мастер-компонентах и slave sidecar и выяснили, что нас сильно тормозила сериализация в JSON библиотекой Jackson. Суммарные задержки составляли более 50 % времени работы сервиса. Основные тормоза были на транспортном уровне, при сериализации DTO с секциями данных для передачи по сети.
Напомню, как выглядят такие DTO: это сериализованные на бизнес-уровне данные в виде байтовых массивов, которые входят в состав секций:

Так вот, это — нетипичный случай для сериализации в JSON. JSON — это текст, а байтовые массивы сначала нужно как-то в него преобразовать. Jackson для этого кодирует байтовые массивы в base64-строки. Это происходит гораздо медленнее, чем сериализация в JSON строки аналогичного размера. Например, byte[] в один килобайт сериализуется в JSON примерно в 2,5 раза медленнее, чем строка в 1024 символа. Кроме того, кодирование в base64 для передачи по сети ещё и на треть увеличивает трафик.
Мы немного оптимизировали процесс: стали создавать строку в латинской кодировке из байтового массива и помещать в DTO String, а не byte[]. Теперь тот же килобайт сериализовывался медленнее аналогичной строки не в 2,5, а в 2,3 раза. Да и лишний сетевой трафик остался не меньше. Дело в том, что в JSON-строках обязательно нужно экранировать восемь специальных символов и ещё 32 управляющих с кодами от нуля до 1F. Поэтому Jackson ничего не оставалось, как выполнять такие преобразования по спецификации JSON. Вот какой получался результат:

Размер таких экранированных строк в JSON получался даже немного больше, чем у кодированных в base64 байтовых массивов. Вывод: не стоит хранить данные в byte[], если хотите сериализовать их в JSON.
Сериализация данных в бинарный формат One Nio
Мы поняли, что с нашими DTO бессмысленно пытаться настраивать Jackson, и стали искать другие способы сериализации. Перед нами стояла задача найти сериализатор, который подходил бы нам и на бизнес-, и на транспортном уровне.
Для нас было важно, чтобы на бизнес-уровне сериализация не предъявляла требований к структуре объектов потребителя. Поэтому мы не рассматривали Google Protocol Buffers, Apache Thrift, Apache Avro и другие библиотеки для структурированных данных. На транспортном уровне нам была нужна эффективная сериализация byte[] и минимальный размер результата, поэтому мы рассматривали только сериализаторы в бинарный формат.
Чтобы выбрать оптимальный сериализатор, мы устроили соревнование между семью библиотеками: Java standard, Jackson Smile, Bson4Jackson, BSON MongoDb, Kryo, FST, One Nio. Дополнительным участником стал Jackson для сравнения с текущим положением дел.
Вначале мы провели гонки: заставили сериализовывать и десериализовывать нашу DTO с byte[]. У нас специфичные DTO, поэтому мы не стали доверять имеющимся бенчмаркам, а создали свой. Нам важно было узнать скорость сериализации именно наших DTO, причем на разных размерах byte[]. Этот бенчмарк я опробовал на своем ноутбуке, используя IBM JDK и Java 7: именно их мы тогда использовали в эксплуатации. Результаты получились следующими, а подробности можно узнать из моей статьи на Хабре:

Библиотеки-участники в нестандартных конфигурациях отражены пунктиром. Четко видны аутсайдеры: Jackson JSON (что ожидаемо), Bson4Jackson (как ни странно) и стандартная Java-сериализация.
Лидерами стали две библиотеки: FST в конфигурации unsafe (пунктирная линия) и One Nio в стандартной конфигурации (сплошная линия). Они лучше всех масштабируются с увеличением размера данных, но и на небольших данных одни из самых быстрых.
Далее мы взвесили результаты сериализации у всех участников соревнования. Это важно, потому что эти результаты мы будем передавать по сети. Мы также проверили, насколько хорошо они «жмутся», ведь каждая сериализованная на бизнес-уровне секция данных ещё сжимается с помощью Zip. Самые «компактные» размеры получились у One Nio, на втором месте — Bson4Jackson и BSON MongoDb, на третьем — FST и Kryo.

На следующем этапе мы сравнивали гибкость сериализаторов. Это важно с точки зрения бизнеса, потому что мы должны обеспечить потребителей разных версий возможностью работы с одними и теми же сохранёнными объектами. Для сравнения гибкости мы составили 20 критериев оценки. Пройдёмся по трём наиболее важным и интересным, про остальные можно узнать в моей статье.
Основной критерий гибкости сериализаторов — обратная совместимость. Это возможность так десериализовать данные, полученные от старых приложений, чтобы новые поля объекта оставались null-ами. Оказалось, что такой возможности нет у FST и у One Nio в стандартной конфигурации.
Следующий важный критерий — прямая совместимость. Это возможность так десериализовать данные, полученные от новых приложений, чтобы игнорировалась информация о новых полях объекта, которых у тебя нет. Такой возможности также не оказалось у FST и у One Nio в стандартной конфигурации.
Ещё один интересный показатель гибкости — возможность десериализовать объект, класс которого отсутствует в classpath. Оказалось, что такое есть только у One Nio в конфигурации for persist. Она на лету генерирует из байткода новый класс, идентичный отсутствующему в classpath. Ещё и так, что при повторной сериализации получается тот же самый byte[].
Потребитель при этом может прочитать секцию, где есть атрибуты неизвестных классов, изменить в ней какие-то известные атрибуты и сохранить секцию без потери неизвестных атрибутов.
Посмотрим на результаты:

Обидно, но лидеры по результатам гонок и «взвешивания» FST и One Nio в стандартной конфигурации оказались аутсайдерами по гибкости. Но вот что интересно: One Nio в не самой быстрой и не самой компактной конфигурации “for persist” набрала больше всех баллов по гибкости — 19 из 20.
Мы стали разбираться, как повысить гибкость стандартной быстрой конфигурации One Nio. Оказалось, в ней есть встроенный обмен схемами объектов, после которого она становится максимально гибкой. В итоге One Nio стала победителем в общем зачёте нашего соревнования. Поэтому мы решили использовать её не только на транспортном, но и на бизнес-уровне сериализации. Для этого нам пришлось форкнуть библиотеку у «Одноклассников» и немного доработать. Что мы для этого сделали:
Добавили возможность использовать Unsafe вместо MagicAccessorImpl, который на IBM JDK не даёт нужных возможностей. Кроме того, на Java выше 9-ой от него невозможно унаследовать из-за JPMS. Мы автоматически определяем, можно ли использовать в текущем runtime MagicAccessorImpl. Если нет, то используем Unsafe.
Оптимизировали в One Nio сериализацию строк. Методом
getBytes()доставали байты из строки и копировали их в выходной поток черезUnsafe.copyMemory(). В результате скорость сериализации строк увеличилась на 30-40 %.Позволили переименовывать сериализуемые классы несколько раз. Аннотация @Renamed позволяет указать только одно предыдущее имя класса или поля. Это мешает дальше развивать классы при наличии старых потребителей. Мы добавили новую аннотацию @Renames. С её помощью можно указать несколько переименований.
Добавили возможность регистрировать нестандартные сериализаторы для нестандартных классов.
Например, мы зарегистрировали сериализаторы для immutable-коллекций Guava, в которых нет стандартных конструкторов, а те, что есть, — приватные.
Сделали так, чтобы при десериализации Collection или Map с приватным стандартным конструктором получался бы исходный класс, а не в ArrayList/HashSet/HashMap.
В результате замены JSON на бинарный формат One Nio суммарное время отклика нашего микросервиса сократилось примерно в два раза.
Сохранение данных «дельтами»
Мы продолжили повышать производительность, чтобы выдерживать высокую нагрузку на сервис. На этот раз мы обратили внимание на объём сетевого трафика, создаваемого Platform V SessionsData.
Напомню, что секция данных — это минимальная единица для передачи по сети. Это касается и сетевого взаимодействия slave-master (теперь у нас здесь передаются бинарные данные One Nio), и localhost-взаимодействия между клиентским JAR и slave sidecar.
Также напомню, что секция данных состоит из атрибутов, в которые потребитель сохраняет свои бизнес-объекты. Посмотрим подробнее, как данные передаются по сети при работе с Platform V SessionsData.
Предположим, что один микросервис создаёт сессию в СберБанк Онлайн, а другой сохраняет в неё секцию clientInfo и записывает туда атрибуты: фамилию, имя, отчество клиента, список его карт, вкладов и прочее:

Секция целиком сериализуется, сжимается в byte[] и сохраняется в Platform V SessionsData. Лишнего трафика не видно.
Допустим, что клиент в этой сессии открыл новый вклад, например, «Лучший процент». Какой-то микросервис добавляет название нового вклада в атрибут deposits секции clientInfo. При её чтении по сети из мастера или из кеша slave нам прилетают все её атрибуты. Это нормально: мы не знаем, какими атрибутами секции будет пользоваться потребитель.
Но после изменения одного из пяти атрибутов вся секция снова целиком сериализуется, сжимается и сохраняется. Очевиден overhead: зачем зря сериализовывать, сжимать и передавать по сети четыре неизменных атрибута?

Напрашивалось решение: запоминать и отправлять на сохранение только изменённые атрибуты. Что мы и сделали. В DTO пришлось превратить наши монолитные byte[] с данными секций в Map-ы byte[]-ов, где ключи — это имена атрибутов. Теперь каждый атрибут секции отдельно сериализуется библиотекой One Nio и сжимается с помощью Zip в свой собственный byte[].
Также пришлось доработать хранилище на мастере и кеш на slave, чтобы сохраняемые дельты объединялись в цельные секции. Для этого на уровне хранения данных мы тоже использовали Map-ы с byte[], а не монолитные byte[], как раньше. После такой доработки среднее по потребителям время отклика Platform V SessionsData сократилось примерно на треть. А вместе с двукратным ускорением от сериализации One Nio мы получили уже трёхкратное ускорение.
Чтение данных пачками
Мы уже добились неплохих результатов благодаря замене JSON на бинарный формат One Nio и сохранению данных «дельтами». Но нам нужно было продолжать улучшать производительность, поэтому мы решили посмотреть, как у нас обстоит дело с чтением данных.
Итак, мы не знаем, какими атрибутами прочитанной секции будет пользоваться потребитель. Поэтому секция данных всегда запрашивается целиком, а не «дельтами», как при сохранении. А значит, трафик тут не сэкономить.
Однако мониторинг показал, что иногда потребители в одном end user-запросе создают несколько запросов на чтение сессионных данных. До этого нас немного спасало активное кеширование на slave. Благодаря ему до сети не доходило каждое третье чтение. Но нам хотелось, чтобы лишних запросов не было вовсе.
Напомню, что сессия состоит из секций, которых может быть довольно много. Например, в сессии СберБанка Онлайн могут накопиться десятки секций. Рассмотрим пример микросервиса СберБанка Онлайн, выполняющего открытие вклада. Пусть в нём используется Spring MVC и RestController, который POST-запросом от end user создаёт вклад, как принято в RESTful:

Для этого вызывается метод createDeposit() какого-нибудь Spring-бина. Первым делом он получает из cookie сессию по ID. Затем для открытия вклада нужна информация о клиенте: получаем её из секции данных clientInfo. Здесь уходит запрос на чтение к slave sidecar, а возможно и к мастеру по сети.
Также нужна валюта вклада: берём её из секции defaultCurrency. Это ещё один запрос на чтение. Для открытия вклада требуется и процентная ставка: читаем её из секции interestRates, что приводит к ещё одному запросу на чтение.
Так у нас и создавались лишние запросы на чтение. Мы загружали секции по одной, потому что не могли предсказать, какие именно будут нужны потребителю.

Но если бы мы знали, то предоставили бы все нужные секции в одном запросе. Поэтому при получении объекта сессии через наш Java API мы дали потребителю возможность указать параметр и перечислить в нём имена нужных секций. А мы, в свою очередь, ищем сессию по ID и загружаем все указанные секции данных за один запрос:

Мы также предоставили потребителям Java-аннотацию, которая позволяет добиваться того же эффекта, не меняя вызовы Java API.
Вернёмся к RestController для создания вклада. Разработчик этого бизнес-сервиса понимает, что в методе createDeposit() ему точно потребуются три секции, и навешивает на этот метод аннотацию. В ней указывает связь URL, обрабатываемого методом контроллера, с набором нужных секций.
Дальше наш клиентский JAR сам загрузит эти три секции при получении объекта сессии где угодно внутри указанного метода контроллера.

Такой способ может быть более наглядным и удобным для конкретного потребителя.
В итоге у наших потребителей, которые читают несколько секций за один пользовательский запрос, суммарное время на обращения к Platform V SessionsData сократилось в несколько раз.
Напомню, что после сериализации One Nio и сохранения «дельтами» мы уменьшили задержку примерно в три раза — получилось чуть больше 3 мс. Да, средняя задержка увеличилась от чтения секций пачками, но незначительно: один большой запрос эффективнее суммы маленьких. Да и не все секции у нас большие.
Зато из-за чтения секций пачками среднее время обращения к одной секции уменьшилось кратно, примерно до 1 мс. А это уже уровень современных распределённых кешей, таких как Ignite, Redis, Hazelcast. Но они приносят за эту миллисекунду один ключ, а в нашей секции несколько атрибутов.
Подводим итоги
В качестве замены вендорского решения мы создали собственный продукт Platform V SessionsData, который помогает микросервисам СберБанка Онлайн хранить данные сессий клиентов. Сегодня продукт доступен рынку и подойдёт также другим компаниям, так как подходит не только для СберБанка Онлайн и справится с аналогичными задачами и в других системах.
В этой статье я рассказал, как мы дорабатывали Platform V SessionsData для выдерживания высоких нагрузок. Хочу поделиться основными выводами, которые мы сделали в ходе работы:
Не сериализуйте byte[] в JSON. JSON — это текст, а байтовые массивы приходится преобразовывать в текст, нагружая процессор.
Используйте One Nio для Java-сериализации. Это лучшая библиотека из тех, что мы тестировали.
Используйте сеть максимально эффективно: экономьте как сетевой трафик, так и количество сетевых обращений.
А в следующей статье обсудим, как мы добиваемся высокой доступности сервиса. Спасибо за внимание и до встречи!