
Привет! Меня зовут Игорь, я управляющий партнёр и системный архитектор в KTS. Мы занимаемся разными проектами, от создания корпоративных систем до нестандартных спецпроектов, мобильной разработкой и DevOps. Накопленный опыт позволяет помогать нашим клиентам справляться с инфраструктурой и её проблемными местами с помощью разных инструментов.
В этой статье, подготовленной по мотивам моего доклада в «Школе мониторинга» Slurm, хочу поделиться своим набором best practices «Как лучше всего настроить Grafana Loki для сбора логов в инфраструктуре».
На мой взгляд, порог входа в Loki достаточно низкий, и в Интернете много туториалов. Поэтому я расскажу о более сложных и не совсем очевидных настройках, с которыми не раз сталкивался при работе с Grafana Loki.
Что будет в статье:
Задача сбора логов
Четыре основных вопроса, которые нужно себе задать перед тем, как пытаться интегрировать какую-либо систему сбора логов:
Как собрать логи?
Как извлечь из них нужные метаданные, чтобы в будущем было легче идентифицировать логи?
Как хранить эти данные, чтобы быстрее их записывать и находить? (самый сложный вопрос, пожалуй)
Как найти логи?
Каждая система, будь то syslog, Elasticsearch, или системы, которые построены на ClickHouse — даже сама Grafana Loki — отвечают на эти вопросы по-разному.
Поэтому когда мы будем обсуждать архитектуру, то вернёмся к тому, чем концептуально отличается Grafana Loki от Elasticsearch, и почему она выигрывает в стоимости хранения логов.
Пайплайн сбора логов обычно выглядит просто и понятно.
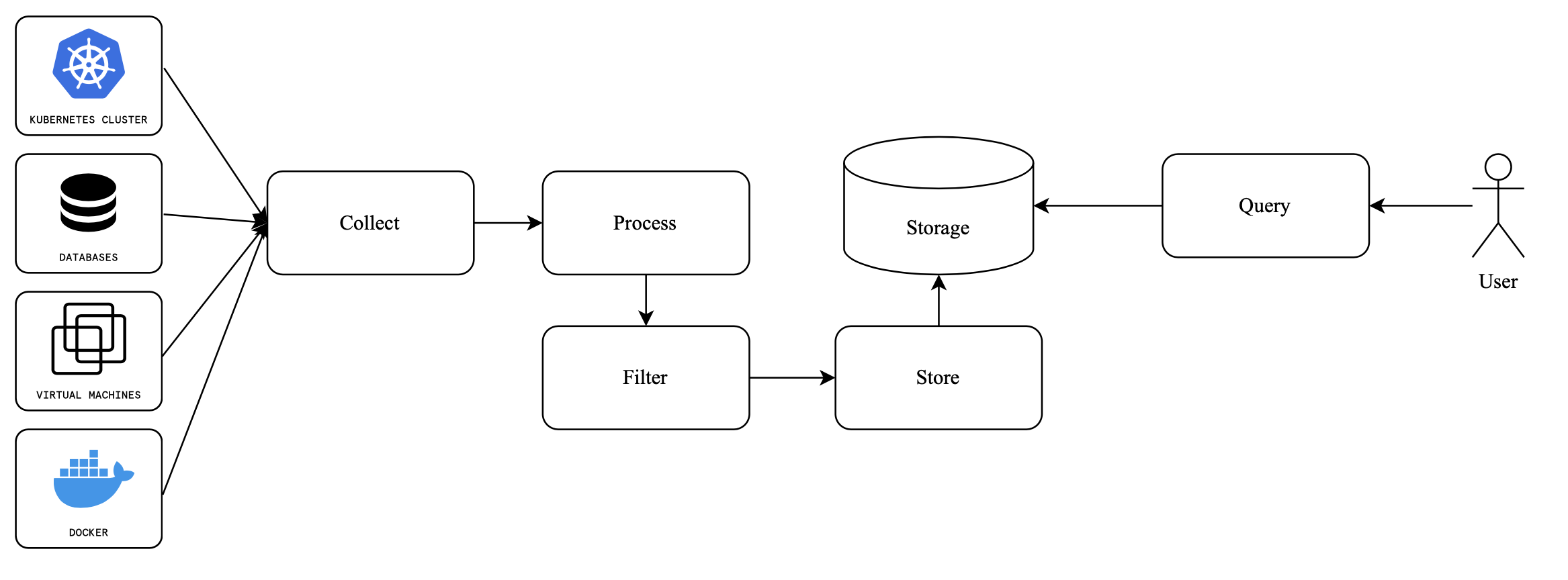
Итак, у нас есть большое количество разнообразных источников данных, откуда к нам прилетают логи: Kubernetes-кластеры, виртуальные машины, Docker-контейнеры и другие. Они проходят фазу сбора, процессинга, фильтрации.
Затем сохраняются в определенном виде, в зависимости от того, какое хранилище вы используете. Например, в виде базы данных, если работаете с ClickHouse, или в S3 Bucket в Grafana Loki. Но обратите внимание, что у каждого пользователя, который извлекает данные с другой стороны, могут быть разные сценарии действий. Например: извлечь логи за год или за последние 10 минут, чтобы отфильтровать данные по ним.
Способы запуска Loki
Существуют три способа запуска, которые, по большому счету, отличаются масштабированием.
Single-binary

Этот способ самый простой и используется в основном в первичных туториалах по Loki. Логика такая: мы берем бинарь, запускаем его, подключаем к storage.
Роль Storage может исполнять как файловая система, на которой запущен наш процесс, так и удалённый S3 Bucket. Здесь это значения не имеет. Такой подход имеет свои плюсы. Например, лёгкость запуска — потребуется минимум конфигурации, которую мы рассмотрим ниже. Минус — плохая отказоустойчивость: если машина выпадает, то логи не пишутся вообще.
Ситуацию можно улучшить так:
На двух разных виртуальных машинах запустить один и тот же процесс Loki с одинаковым конфигом
Объединить их в кластер с помощью секции
memberlistПеред этим поставить любой прокси —например Nginx или Haproxy
Главное — подключить всё к одному Storage
Соответственно, можно масштабировать процесс дальше, то есть запустить три, четыре, пять узлов.
Получится примерно такая схема:

Обратите внимание, что Loki занимается как записью, так и чтением. Поэтому нагрузка равномерно распределяется по всем инстансам. Но по факту она совсем неравномерная, потому что в одни моменты времени бывает много чтений, а в другие — много записей.
SSD - Simple Scalable Deployment
Второй способ следует из первого и позволяет разделить процессы чтения и записи, чтобы мы могли запустить, например, более дискозависимые процессы на одном «железе», а менее дискозависимые на другом.
Для запуска вам необходимо передать флажок -target=write или -target=read, и в каждом из этих процессов запускаются те сущности, которые отвечают за конкретный путь запроса: write или read. Точно так же нужно поставить прокси перед всеми инстансами, который будет проксировать:
запросы на запись → на узлы записи
остальные запросы → на узлы с чтением

Этот способ запуска Grafana считает наиболее рекомендуемым в плане работы и Grafana активно развивает именно его.
Microservices mode
Microservices mode — более развёрнутый путь, когда мы каждый компонент Loki запускаем самостоятельно.
Компонентов очень много, но они легко отделяются друг от друга, и их можно распределить на две группы или даже три.

Группа компонентов на запись: дистрибьюторы и инджесторы, которые пишут в Storage.
Группа компонентов на чтение: query-frontend, querier, index gateway. Это те компоненты, которые занимаются исполнением запросов.
Все остальные утилитарные компоненты: например, кеши, compactor и другие.
Как устроена архитектура Grafana Loki
Остановимся чуть подробнее на архитектуре, чтобы в дальнейшем понимать, что вообще конфигурируется в той или иной секции.
Для начала — как индексируются данные в блоке. В отличие от Elasticsearch, который по дефолту индексирует все документы полнотекстово и целиком, Grafana Loki идет по другому пути - он индексирует не содержимое логов, а только их метаданные, то есть время и лейблы.
Эти лейблы очень похожи на Prometheus-лейблы. Я думаю, многие из вас с ними знакомы.
В итоге в Grafana мы храним очень маленький индекс данных, потому что данных в нем очень мало. Здесь хочу заметить, что у Elasticsearch индекс раздувается зачастую больше, чем сами данные.
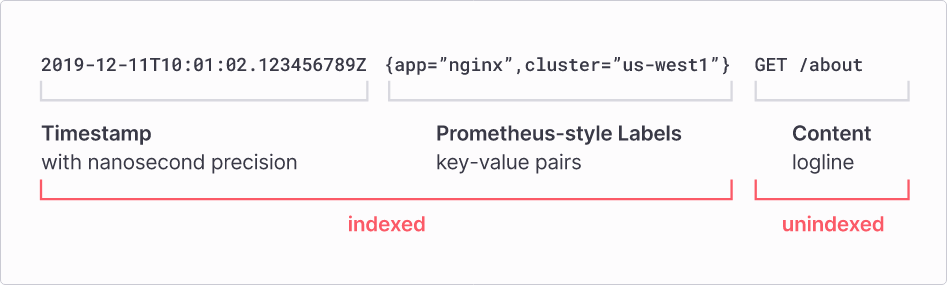
Неиндексируемые данные мы храним как они есть в порядке появления. Если их нужно отфильтровать, пользуемся "grep", своего рода встроенным в Loki.
Stream — уникальный набор лейблов, несмотря на то, что логи могут идти из одного источника.

В данном случае лейбл component="supplier" порождает новый стрим. Нам это понадобится в дальнейшем, т.к. настройки, которые связаны с рейт-лимитами и ограничениями, зачастую распространяются именно на стрим.
Чанки — набор из нескольких строчек логов. Вы взяли строчки лога, поместили их в одну сущность, назвали ее chunk, сжали и положили в Storage.
Теперь вернёмся к архитектуре и подробнее рассмотрим write path и read path и их различия.
Write path. Точкой входа для записи логов в Loki является сущность под названием «Дистрибьютор». Это stateless-компонент. Его задача — распределить запрос на один или несколько инджесторов.
Инджесторы — это уже stateful-компоненты. Они объединены в так называемый hash ring — систему консистентного хеширования. Она позволяет проще добавлять и удалять инджесторы из этого кластера. Все они подключены к одному Storage.

Read path устроен сложнее, но принцип похожий. Есть stateless-компоненты — query frontend и querier. Query frontend — компонент, который помогает разделить запрос, чтобы быстрее его выполнить.
Например, нужно запросить данные за месяц. С помощью query frontend делим запрос на более мелкие интервалы и направляем в параллель на несколько querier, а потом объединяем результат.
Querier — компонент, который запрашивает логи из Storage. Если есть новые данные из инжесторов, которые в Storage еще не записаны, querier запрашивает их тоже.

Минимальная конфигурация Loki (filesystem)
Эта конфигурация нацелена на работу с файловой системой, когда Loki запущен в single instance режиме. Остановлюсь на более важных конфигурационных секциях.
Loki — это инструмент, который постоянно развивается, чтобы упростить и улучшить работу с конфигурацией. Пару версий назад появилось одно из самых лучших изменений — секция common. Когда в конфигурации есть несколько повторяющихся элементов, common объединяет их в разных частях конфига. То есть, если раньше приходилось настраивать ring, storage и другие элементы для инджестора, querier, дистрибьютора отдельно, то сейчас это все можно сделать в одном месте.
auth_enabled: false
server:
http_listen_port: 3100
common:
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
instance_addr: 127.0.0.1
kvstore:
store: inmemory
schema_config:
configs:
- from: 2020-09-07
store: boltdb-shipper
object_store: filesystem
schema: v12
index:
prefix: loki_index_
period: 24hЗдесь видно, что storage настроен в виде файловой системы, и указано, где хранятся чанки. Там же можно указать, где хранить индекс, правила для алертинга и т.д.
schema_config — это конфиг для указания, как хранятся данные: чанки, индекс. Здесь в целом ничего не меняется с давних времен, но иногда появляются новые версии схемы. Поэтому рекомендую периодически читать чендж-логи, чтобы вовремя обновлять схемы в Loki и иметь последние улучшения.
Как только появляется несколько инстансов, необходимо объединить их в кластер, который работает на протоколе memberlist (также можно использовать сторонние системы, такие как etcd или consul). Это Gossip-протокол. Он автоматически находит узлы Loki по определенному принципу:

auth_enabled: false
server:
http_listen_port: 3100
common:
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: memberlist
schema_config:
configs:
- from: 2020-09-07
store: boltdb-shipper
object_store: filesystem
schema: v12
index:
prefix: loki_index_
period: 24h
memberlist:
join_members:
- loki:7946Есть множество разных способов автоматической конфигурации кластера, которые отлично работают. Например, в секции memberlist.join_members можно указать разные настройки:
Адрес одного хоста
Список адресов
dns+loki.local:7946— Loki сделает A/AAAA DNS запрос для получения списка хостовdnssrv+_loki._tcp.loki.local— Loki сделает SRV DNS запрос для получения не только списка хостов, но и портовdnssrvnoa+_loki._tcp.loki.local— SRV DNS — запрос без A/AAAA запроса
Зачем это нужно? Внутри Loki есть компоненты, которые должны знать друг о друге. Например, дистрибьюторы должны знать об инджесторах. Поэтому они регистрируются в одном кольце. После этого дистрибьюторы знают, на какие инджесторы отправить запрос на запись. Еще в пример можно привести компакторы, которые должны работать в единственном экземпляре в кластере.
S3 в качестве storage
S3 — наиболее рекомендованный способ хранения логов в Loki, особенно, если вы деплоите Loki в Kubernetes. Когда мы используем S3 в качестве storage, немного меняется конфигурация:
auth_enabled: false
server:
http_listen_port: 3100
common:
path_prefix: /tmp/loki
storage:
s3: # Секция filesystem меняется на s3
s3: https://storage.yandexcloud.net
bucketnames: loki-logs
region: ru-central1
access_key_id:
secret_access_key:
replication_factor: 1
ring:
kvstore:
store: memberlist
schema_config:
configs:
- from: 2020-09-07
store: boltdb-shipper
object_store: filesystem
schema: v12
index:
prefix: loki_index_
period: 24h
memberlist:
join_members:
- loki:7946Несколько советов:
Используйте
https://вместоs3://- так вы гарантируете использование шифрованного соединенияbucketnamesможно указать несколько для распределения храненияМожно использовать
ACCESS_KEY_IDиSECRET_ACCESS_KEYпеременные окружения для конфигурации ключей доступа к S3

Мы меняем storage на S3, указываем endpoint, bucketnames, и другие конфигурации, которые относятся к S3.
Обратите внимание, что bucketnames во множественном числе, а значит, их можно указать сразу несколько. Тогда Loki начнёт равномерно распределять чанки по всем указанным бакетам, чтобы снизить нагрузку на один бакет. Например, это нужно, когда в вашем хостере есть ограничения по RPS на бакет.
Конфигурация кластерных и High Availability решений
Допустим, мы записали логи в несколько узлов. Один из них отказал и запросить данные из него нельзя, потому что он не успел записать их в storage.
High Availability в Loki обеспечивается через опцию replication_factor. Благодаря этой настройке дистрибьютор отправляет запрос на запись логов не в одну реплику, а сразу в несколько.
auth_enabled: false
server:
http_listen_port: 3100
common:
path_prefix: /tmp/loki
storage:
s3:
s3: https://storage.yandexcloud.net
bucketnames: loki-logs
region: ru-central1
access_key_id:
secret_access_key:
replication_factor: 3 # Обратите внимание на это поле
ring:
kvstore:
store: memberlist
schema_config:
configs:
- from: 2020-09-07
store: boltdb-shipper
object_store: filesystem
schema: v12
index:
prefix: loki_index_
period: 24h
memberlist:
join_members:
- loki:7946replication_factor:
Distributor отправляет чанки в несколько Ingester
Минимум – 3 для 3х нод
Позволяет не работать 1 из 3 нод
maxFailure = (replication_factor / 2) +1
Дистрибьютор отправляет чанки сразу в несколько инджесторов. Теперь в storage будет храниться в три раза больше данных.

Да, это больше, чем нужно. Проблему можно решить через дедупликацию данных. Для этого есть компонент-компактор. Работает так:
Мы пишем с тремя инджесторами одни и те же данные;
Обеспечиваем этим отказоустойчивость;
Потом подчищаем с помощью компактора ненужные данные, которые лежат в дуплицированном виде в сторадже.
Тайм-ауты
Достаточно тяжелая тема, потому что очень часто при неправильной настройке Loki можно встретить ошибки типа 502, 504.

Чтобы лучше разобраться в ошибках, нужно, во-первых, увеличить таймауты до достаточных значений в вашем проекте, а во-вторых — правильно сконфигурировать несколько видов таймаутов.
Таймауты
http_server_{write,read}_timeoutнастраивают базовый таймаут на время ответа веб сервера-
querier.query_timeoutиquerier.engine.timeoutнастраивают максимальное время работы движка, непосредственно исполняющего запросы на чтениеserver: http_listen_port: 3100 http_server_write_timeout: 310s http_server_read_timeout: 310s querier: query_timeout: 300s engine: timeout: 300s -
В случае использования прокси перед Loki, например NGINX, следует увеличить таймауты и в нём (
proxy_read_timeoutиproxy_write_timeout)server { proxy_read_timeout = 310s; proxy_send_timeout = 310s; } -
Также необходимо увеличить таймаут на стороне Grafana. Это настраивается в секции
[dataproxy]в конфиге.[dataproxy] timeout = 310
Лучше всего, если вы поставите минимальный из всех 4-х видов таймаутов у querier (в примере – 300s). Так он завершится первым, а все следующие — например НТТР-серверы, Nginx или Grafana — чуть дольше.
Дефолтный тайм-аут очень маленький, поэтому я рекомендую увеличивать эти значения.
Размеры сообщений
Тема может показаться сложной, потому что природа происхождения некоторых ошибок неочевидна.
Размеры сообщений, grpc_server_max_{recv,send}_msg_size — это ограничения на возможный размер логов. При этом дефолтные значения очень маленькие. Например, если есть большой stack trace и в одной лого-линии отправляются логи размером 20 Мб, то он в принципе не влезет в этот лимит. Значит, его нужно увеличивать.
server:
http_listen_port: 3100
grpc_server_max_recv_msg_size: 104857600 # 100 Mb
grpc_server_max_send_msg_size: 104857600 # 100 Mb
ingester_client:
grpc_client_config:
max_recv_msg_size: 104857600 # 100 Mb
max_send_msg_size: 104857600 # 100 MbДефолт 4Mb
Непосредственно влияет на размер логов обрабатываемых Loki
Энкодинг чанков тоже нельзя обойти стороной. Дефолтное значение — gzip, то есть максимальное сжатие. Grafana рекомендует переключиться на snappy — и я по опыту с ними согласен. Тогда логи может и занимают чуть-чуть больше места в сторадже, но становятся более производительными чтения и записи данных.
ingester:
chunk_encoding: snappy-
Дефолт — gzip
Лучшее сжатие
Медленнее запросы
-
Рекомендуем snappy
Сжатие чуть хуже
Однако очень быстрое кодирование/декодирование
Чанки
С чанками связано много настроек относительно их размеров и периодов времени жизни. Рекомендую их сильно не трогать. Но при этом нужно понимать, что вы делаете, когда меняете значения.
ingester:
chunk_idle_period: 2h
chunk_target_size: 1536000
max_chunk_age: 2hДефолты достаточно хорошие:
chunk_block_sizeиchunk_retain_periodне рекомендуется менять совсем.сhunk_target_sizeможно увеличить, если чанки в основном полные. Это даст им больше пространства.сhunk_idle_periodозначает, сколько чанк будет жить в памяти инджестора, если в нём нет вообще никаких записей. Так вот, если ваши стримы в основном медленные и полупустые, лучше увеличить период. По дефолту — 30 минут.
Параллелизм
Еще один важный вопрос связан с конкурентностью.
querier:
max_concurrent: 8
limits_config:
max_query_parallelism: 24
split_queries_by_interval: 15m
frontend_worker:
match_max_concurrent: truequerier.max_concurrentпоказывает, сколько запросов в параллель может обрабатывать один querier. Рекомендовано ставить примерно удвоенное количество CPU, дефолт = 10 (будьте внимательны к этим цифрам).-
limits_config.max_query_parallelismпоказывает, сколько максимум параллельности есть у тенанта. Значения querier.max_concurrent должны матчится с max query parallelism по формуле:[queriers count] * [max_concurrent] >= [max_query_parallelism]В нашем примере должны быть запущены минимум 3querier, чтобы обеспечить параллелизм 24.
Оптимизация Write Path
Здесь есть несколько настроек, связанных с записью — ingestion_write_mb, ingestion_burst_size_mb.
limits_config:
ingestion_rate_mb: 20
ingestion_burst_size_mb: 30Если здесь стоят достаточно низкие дефолты, рекомендую увеличить их. Это позволит гораздо больше и чаще писать логи. Остальные значения относятся к tenant, поэтому с ними нужно быть аккуратнее.
Для стримов есть отдельная настройка — per_stream_rate_limit.
limits_config:
per_stream_rate_limit: "3MB"
per_stream_rate_limit_burst: "10MB"На примере показаны более-менее нормальные дефолты. Но если вы начинаете в них упираться, то рекомендую разбить стрим на несколько — добавить лейбл. Это уменьшит rate-limit стрима. В обратной ситуации можно пробовать увеличивать лимиты.
Объемы данных в Grafana Cloud
Эти данные я вытащил из одной их презентации.
Grafana Loki обрабатывает:
500 МБ логов в секунду
43 ТВ в день;
1,25 ПВ в месяц.
Они стремятся обеспечивать нагрузку примерно 10 МВ в секунду на инджестор. При этом использование памяти всего лишь около 10 GB.
Эти данные позволяют пользователям примерно представить, какую инфраструктуру им запускать. Для примера: у нас на одном из проектов rate гораздо ниже, около 20 или 30 GB в день. Тем не менее три инджестора справляются с таким потоком данных с большим запасом.
Итоги
В статье и докладе, по которому она написана, я постарался подробно описать работу с Loki в контексте конфигурирования:
задача сборов логов и её 4 основных вопроса
архитектура Loki
3 вида запуска Loki
HA в Loki с помощью replication factor
конфигурация тайм-аутов и размера сообщений
параллелизм — следите за этими настройками очень внимательно!
оптимизация write path — в целом несложный процесс. Вам нужно просто посмотреть на показатели на графике и оптимизировать соответствующим образом
Другие статьи про DevOps для начинающих:
Другие статьи про DevOps для продолжающих:
За последние годы де-факто стандартом оркестрации и запуска приложений стал Kubernetes. Поэтому умение управлять Kubernetes-кластерами является особенно важным в работе любого современного DevOps-инженера.
Порог входа может казаться достаточно высоким из-за большого числа компонентов и связей между ними внутри системы. На курсе «Деплой приложений в Kubernetes». мы рассмотрим самые важные концепции, необходимые для управления кластерами любой сложности и научим применять эти знания на практике.
???? Почитать про курс подробнее можно здесь: https://vk.cc/cn0ty6
Комментарии (6)

ufoton
12.04.2023 12:47Наверное надо уточнить что для SSD нужно /loki/api/v1/push проксировать на write ноды. Всё остальное на read.
По поводу retention. Я настроил lifecycle policy на AWS S3 так как я могу его там настроить в зависимости от tenant. Это мне чем то грозит? Кроме запросов в никуда?
igorcoding Автор
12.04.2023 12:47+2Loki поддерживает 2 вида ретеншена - через table manager и через компактор. Ретеншн через table manager полагается на lifecycle policy в S3. Поэтому это обязательно (но при условии что включен непосресдтвенно ретеншн через table_manager). Это нужно для того, чтобы правильно очищались индексы. Иначе Loki может считать что чанки есть (потому что индекс на них ссылается), а по факту их нет - и может выливаться в ошибки при запросах.
Более гибким является настройка ретеншена через компактор - она так же позволяет настраивать его для отдельных тенантов. При этом выставлять в таком случае какие-либо полиси в бакете лучше не стоит - точно так же - чревато потерей данных. Поэтому, если честно, я не вижу причин не использовать ретеншн через компактор.
Резюмируя, настраивать ретеншн нужно через один из двух механизмов - table manager или compactor. При этом для первого нужны lifecycle policy в S3 бакете. Полиси без настройки ретеншена могут привести к ошибкам в запросах.

MrAlone
12.04.2023 12:47-3Задача сбора логов
Каждая система, будь то syslog, Elasticsearch, или системы, которые построены на ClickHouse — даже сама Grafana Loki — отвечают на эти вопросы по-разному.А вы точно настоящий строитель? syslog - стандарт для передачи, обработки и хранения логов, Elasticsearch - поисковый движок(слово search в названии не смущает?) ClickHouse -DBMS, Loki - агрегатор.
Дальше статью не читал.
Vacilio
Спасибо за статью. Можно ли как то управлять временем хранения логов?
igorcoding Автор
Здравствуйте! Для управления временем хранения логов отвечает компактор. Вот тут подробная документация на эту тему - https://grafana.com/docs/loki/latest/operations/storage/retention