В любом мобильном приложении нужно четко понимать, как с ним взаимодействует пользователь. Для этого добавляется аналитика, по которой мы можем отслеживать различные действия пользователя внутри приложения. Меня зовут Тимур Шафигуллин, в этой статье я расскажу, как устроена мобильная аналитика вообще и в hh.ru в частности.

Define «аналитика»
Под словом «аналитика» в данном контексте я подразумеваю, во‑первых, сами события аналитики, которые мы отправляем. Как правило, это действие пользователя: например, нажатие на кнопку или открытие экрана. Во‑вторых, трекеры. Собственно, это сервисы, куда уходят эти самые события аналитики. В трекерах мы можем смотреть, строить воронки и анализировать, как пользователь взаимодействует с нашим приложением.
Но аналитики может быть много. Даже слишком. Количество событий аналитики будет расти вместе с вашим приложением. Трекеров аналитики тоже может быть несколько, чтобы наблюдать разницу между ними. Кроме того, может быть и несколько платформ с несколькими приложениями. И перед нами встает закономерный вопрос: «А как с быть с большим количеством событий аналитики?»
Слишком много событий
Однажды событий стало так много, что помнить обо всех стало просто невозможно, ведь у нас две платформы с двумя приложениями под каждую. Тогда у нас еще полностью отсутствовало системное понимание событий. Из‑за этого было крайне тяжело вносить любые изменения. Чтобы внести какое‑то изменение или удалить событие, нужно было пойти в трекер аналитики, посмотреть, какие события сейчас отправляются или пойти к разработчикам и узнать у них. Именно поэтому мы решили все сложить в одно место — git‑репозиторий.
В git‑репозиторий мы поместили все наши события аналитики, которые отправляются с мобильных приложений. Он состоит из документации, в которой описаны все отправляемые события аналитики и схемы событий. Рассмотрим их подробнее.
События и схемы
Схема события представляет из себя обычный yaml файл и описывает само событие, которое будет отправляться. Оно состоит из нескольких частей: общей информации, названия, описания и категории для группировки событий. Также здесь можно указать приложение и платформу.
События разделяются на внешние и внутренние. События внутренней аналитики отправляются в наш внутренний сервис, где мы проводим А/В‑тестирование и проверяем гипотезы. События внешней аналитики отправляются в такие трекеры, как Firebase, AppMertica и так далее. С ними работает уже главным образом маркетинг.
У событий внутренней аналитики есть поле event. Здесь, например, оно называется button_click:

После этого задаются параметры, все они формируются по JSON‑схеме. Первый пример параметра — это hhtmSource. Он указывает, с какого экрана было отправлено событие. Здесь оно имеет константное значение и оно всегда будет отправляться с мобильного приложения. Второй пример — topicId, у него уже есть тип string или null. Значит либо будет отправляться строка, либо этот параметр может отсутствовать. Также у каждого параметра есть свое описание, чтобы понимать, для чего он нужен.
У внешних событий аналитики структура уже более строгая: есть категория и действия, например, подписка или отписка от автопоисков. Есть и лейбл, более динамичная структура. Она может быть либо строкой, либо константой. И все это отправляется во внешний сервис аналитики.
Документация
Документация представляет из себя перечень Markdown‑файлов и есть один большой Markdown‑файл с разводной страницей:

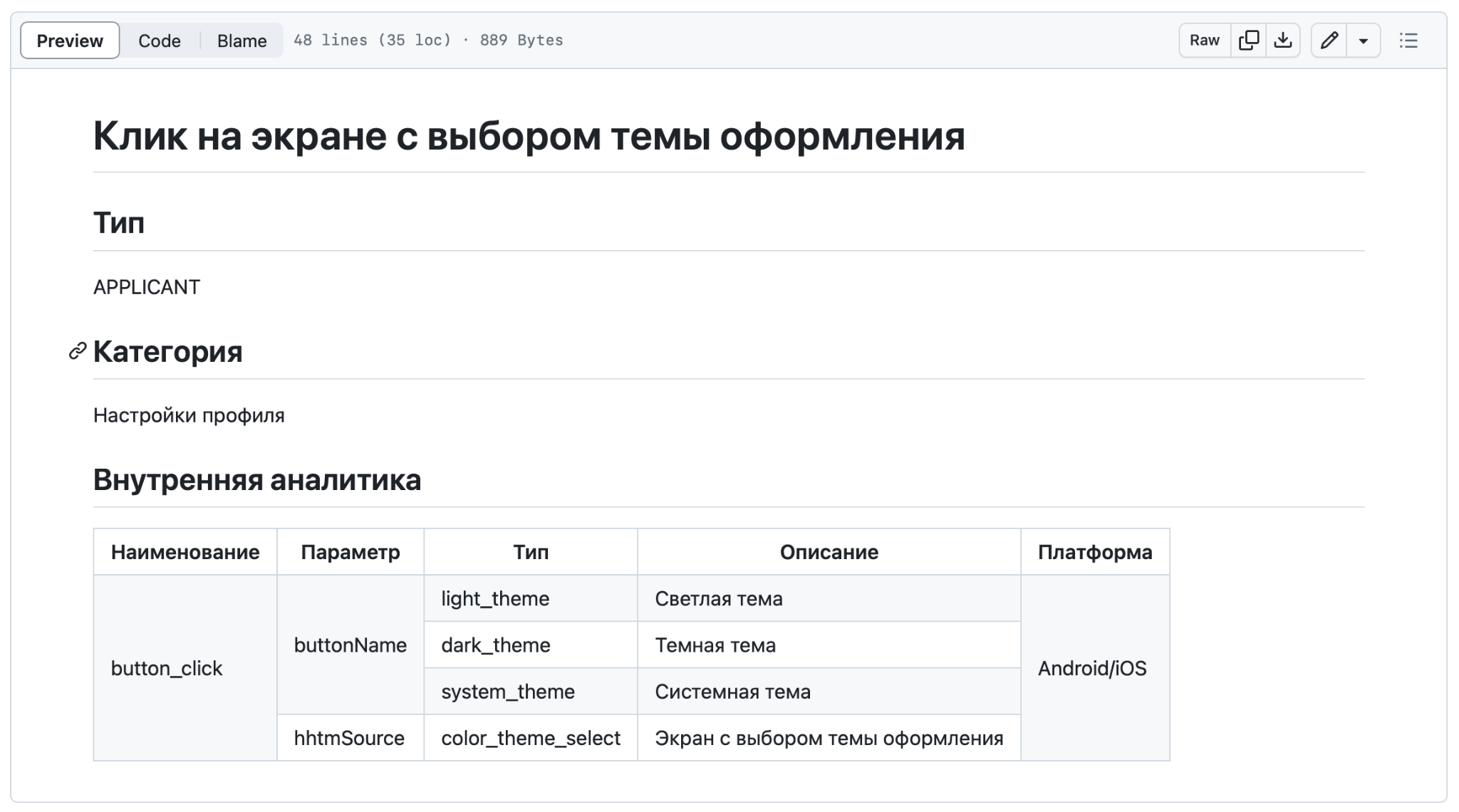
На этой странице представлены все наши события, которые отправляются с мобильных приложений. Кликнув на определенное событие, можно провалиться в его детальное описание, где отображается все, что мы видели в YAML‑схемах, только в удобном и читаемом виде.
Здесь есть и категория, и описания, и параметры с типами, и информация о том, куда отправляется событие:
YAML‑файлы превращаются в Markdown достаточно просто. У нас есть бот на CI, который проверяет изменения в master каждые 15 минут. Если у нас появились новые YAML‑схемы, он генерирует по ним Markdown‑файл и пушит в репозитории обновленную документацию. Почему именно раз в 15 минут? Так вышло. Когда мы создавали всё это, еще не было возможности использовать GitHub webhook с нашим CI, в котором мы бы просто триггерили документацию в нужный момент.
Как всё работает
Немного расскажу про наш workflow.
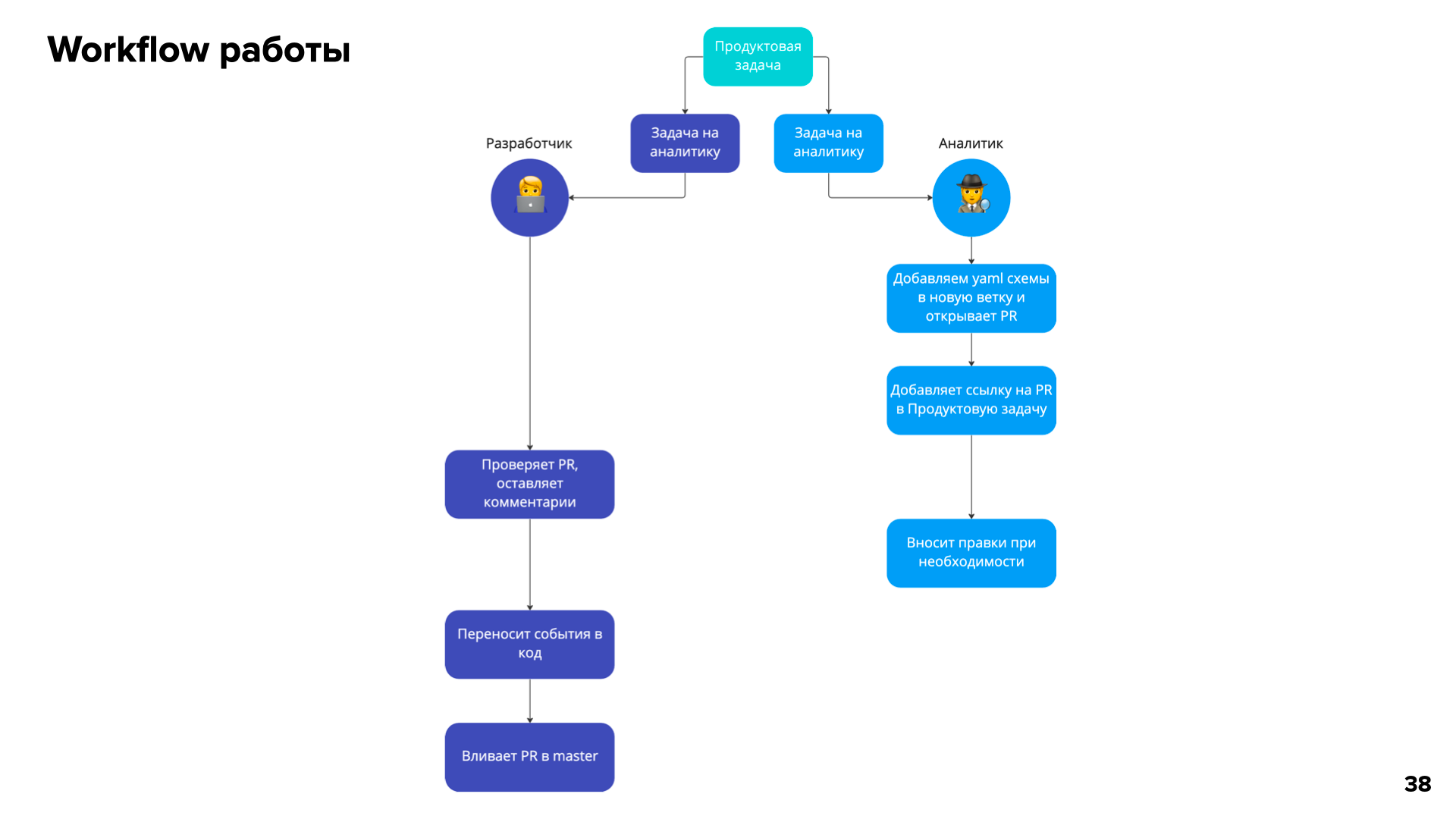
Все начинается с продуктовой задачи, которая делится на подзадачи. Задача на аналитику есть и у разработчика, и у аналитика.
Аналитик добавляет YAML‑схему в новую ветку и открывает pull request
Затем добавляет эту ссылку на pull request в продуктовую задачу
Когда разработчик берет свою задачу на аналитику, он идет в общую продуктовую задачу, смотрит pull request и при необходимости оставляет комментарий
Аналитик вносит правки, о которых сообщил разработчик
Разработчик переносит эти события в код репозитория и вливает pull request в мастер
Итак, у нас есть отдельный репозиторий как хранилище. Есть набор событий аналитики в виде схем и читаемая документация. Но как репозиторий аналитики взаимодействуют в кодовой базой?
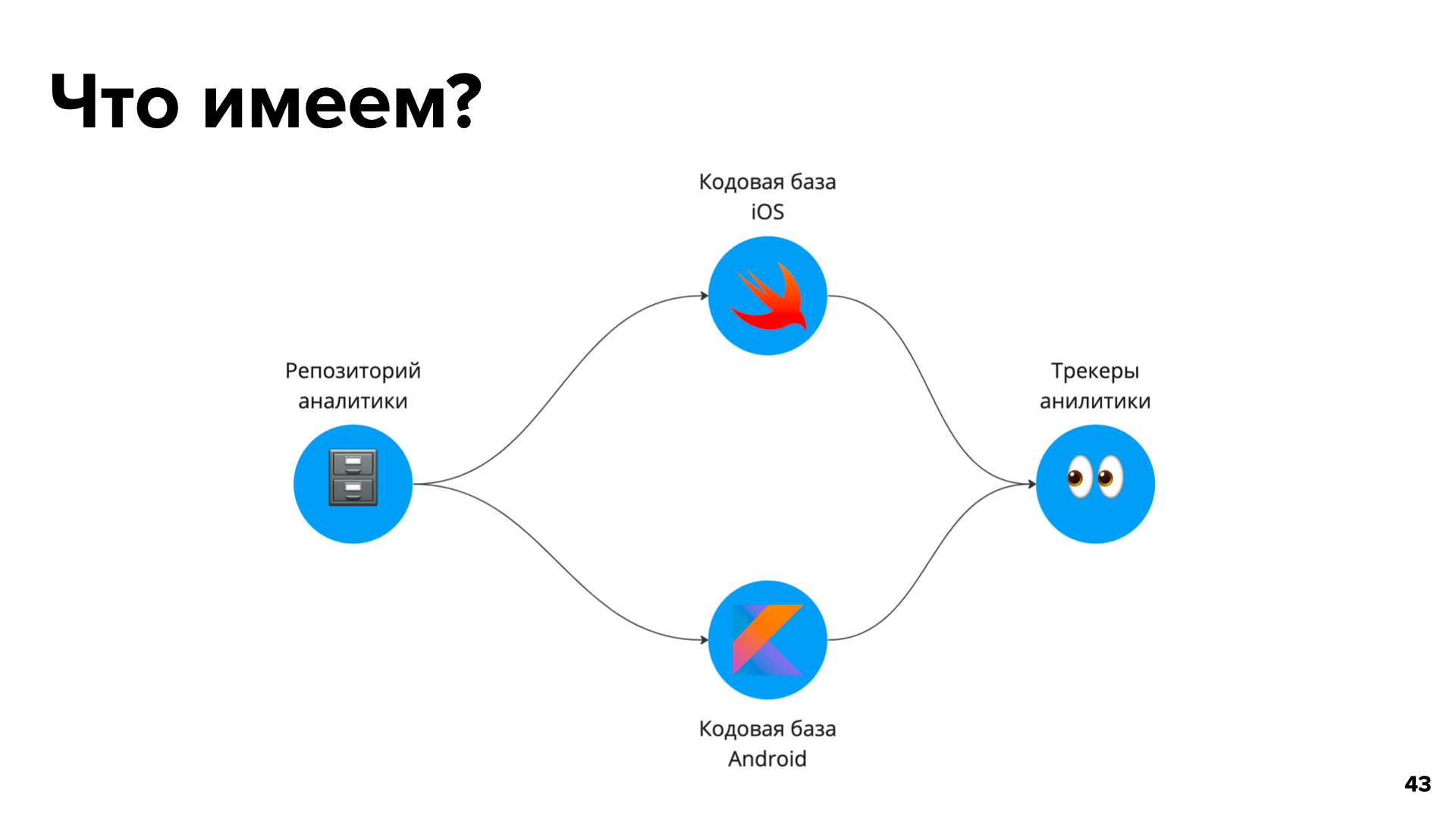
Из репозитория с аналитикой разработчики сами вручную переносят YAML‑схемы в код, и из кода они уже дальше будут отправляться в трекеры аналитики.
Синхронизация кодовых баз с репозиторием аналитики
Когда мы добавляем новые события в репозиторий аналитики и переносим его в кодовую базу, бывает, что при этом мы вносим изменения в обход репозитория. Иногда в рамках задачи мы просто добавляем параметр или удаляем событие, потому что оно нам больше не нужно. Но при этом мы не вносим изменения в репозиторий аналитики. В этом случае репозиторий уже не является источником правды и где‑то грустит один аналитик. Как этого избежать?
Так мы придумали генерировать готовый код из схем и на свет появился инструмент под названием AnalyticsGen. Он генерирует код по шаблону для любого языка из yaml схем, которые могут находится локально или удаленно в git репозитории. И все это может удобно настраиваться через config‑файл.
А что с версионностью? И как вести разработку и параллельно генерировать код? Все начинается с ветки master в репозитории аналитики. Аналитик все так же создает ветку с названием и номером задачи и вносит изменения. И уже после этого разработчики делают свою работу — сливают изменения в мастер и создают новый тег.
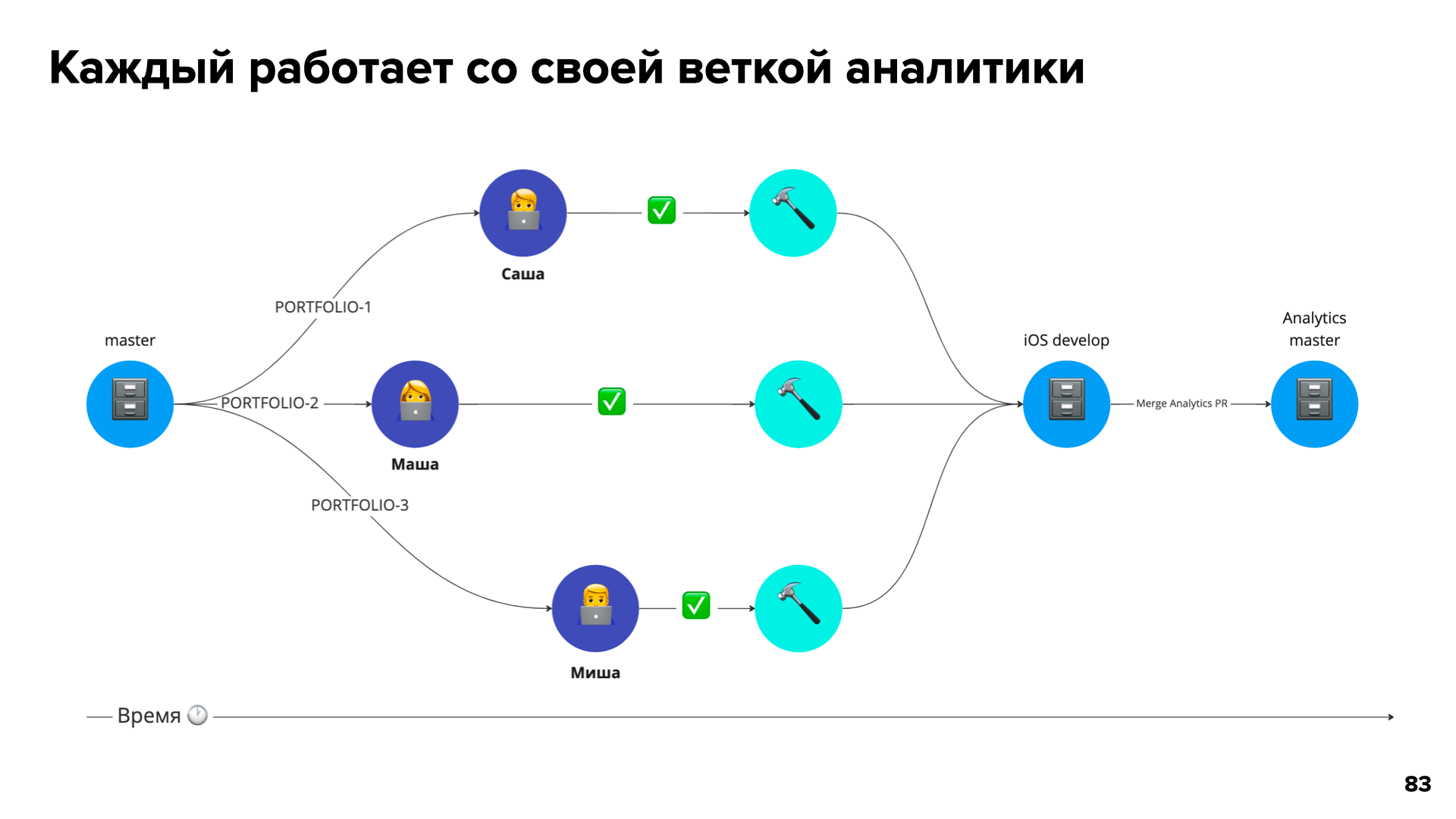
На графике ниже мы видим, что Саша слил свои изменения и сделал тег 1.0.0. После этого разработчик Маша тоже слила изменения в репозиторий аналитики и сделала тег 1.1.0. То же самое повторяет Миша:

Затем они локально генерируют по этим схемам код и работают уже с ним. Но Саша, который сделал тег 1.0.0, изменил и удалил некоторые события аналитики. Из‑за этого код у Маши и Миши теперь не собирается, потому что измененная Сашей кодовая база еще не попала в общий репозиторий iOS‑кода.
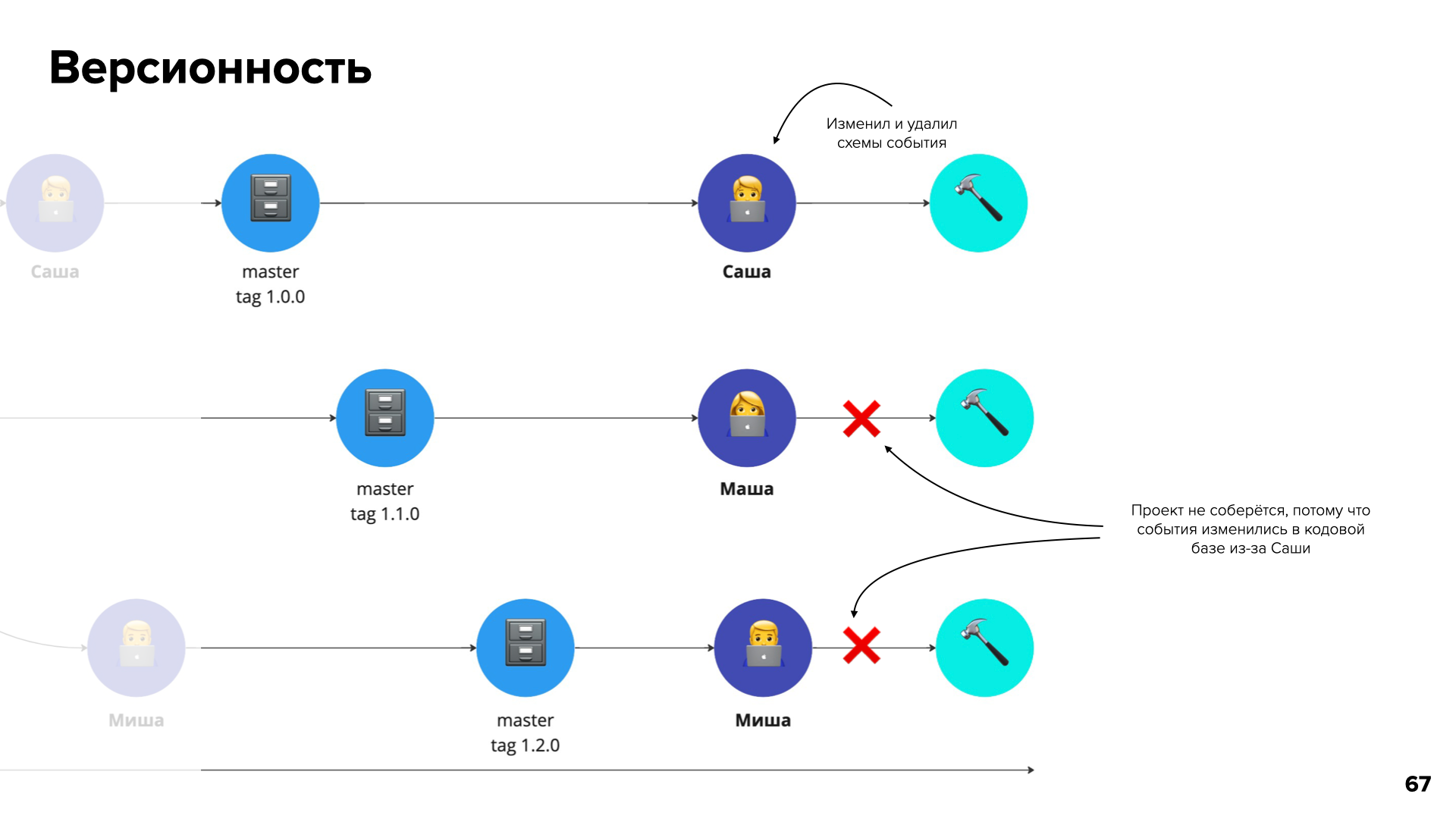
Миша и Маша заблокированы, и это грустно. Но у нас не будет проблем, если не будет изменений и удалений, верно? Так появился ADD‑ONLY‑репозиторий.
Просто добавь префикс
Теперь в репозитории аналитики нельзя изменять и удалять схемы. Теперь мы копируем старый файл, создаем новый и добавляем префикс V2. А старые события помечаем как Deprecated. Так Саша не удаляет схемы и не изменяет старые, он добавляет только новые файлы, тем самым не блокируя разработку у Маши и Миши.

ЭНо есть, как водится, нюанс. Во‑первых, нужно проводить актуализацию репозитория. Да, вот эти V2-V3 могут скапливаться, и однажды их придется чистить. Во‑вторых, мы не удаляем события, а они уже могут и не отправляться вовсе. И репозиторий теперь не является источником правды. Это немного противоречит нашему первоначальному плану. И в‑третьих, это — лишний Swift‑код. Все эти V2-V3 генерируются и замедляют собой сборку проекта. Однажды мы обнаружили, что давно не актуализировали наш репозиторий и он настолько засорился, что нам пришлось пересмотреть этот подход.
Finder
Мы пришли к новому флоу, где каждый работает со своей веткой аналитики. В iOS‑репозитории мы работаем только с отдельной веткой аналитики под каждую отдельную продуктовую задачу в конкретный момент времени. Только после того, как кодовая база в iOS‑репозитории попадет в девелоп, можно будет смерджить pull request в мастер репозитории аналитики.
В таком подходе не возникает никаких блокировок при разработке. Это стало возможно благодаря новой сущности в AnalyticsGen. Мы назвали её Finder.
Finder‑ов может быть несколько, и они могут настраиваться индивидуально для каждого проекта. Приведу пару примеров, как они работают.
Первый finder с типом matched_tag — это поиск определенного тега. Он получает значение переменной из заданного названия и проверяет его по регулярному выражению, и если оно подходит, то ищет тег с этим значением в репозитории аналитики. На скриншоте видно, как в iOS‑репозитории PORTFOLIO-3 будет работать с тегом PORTFOLIO-3 из репозитория аналитики:
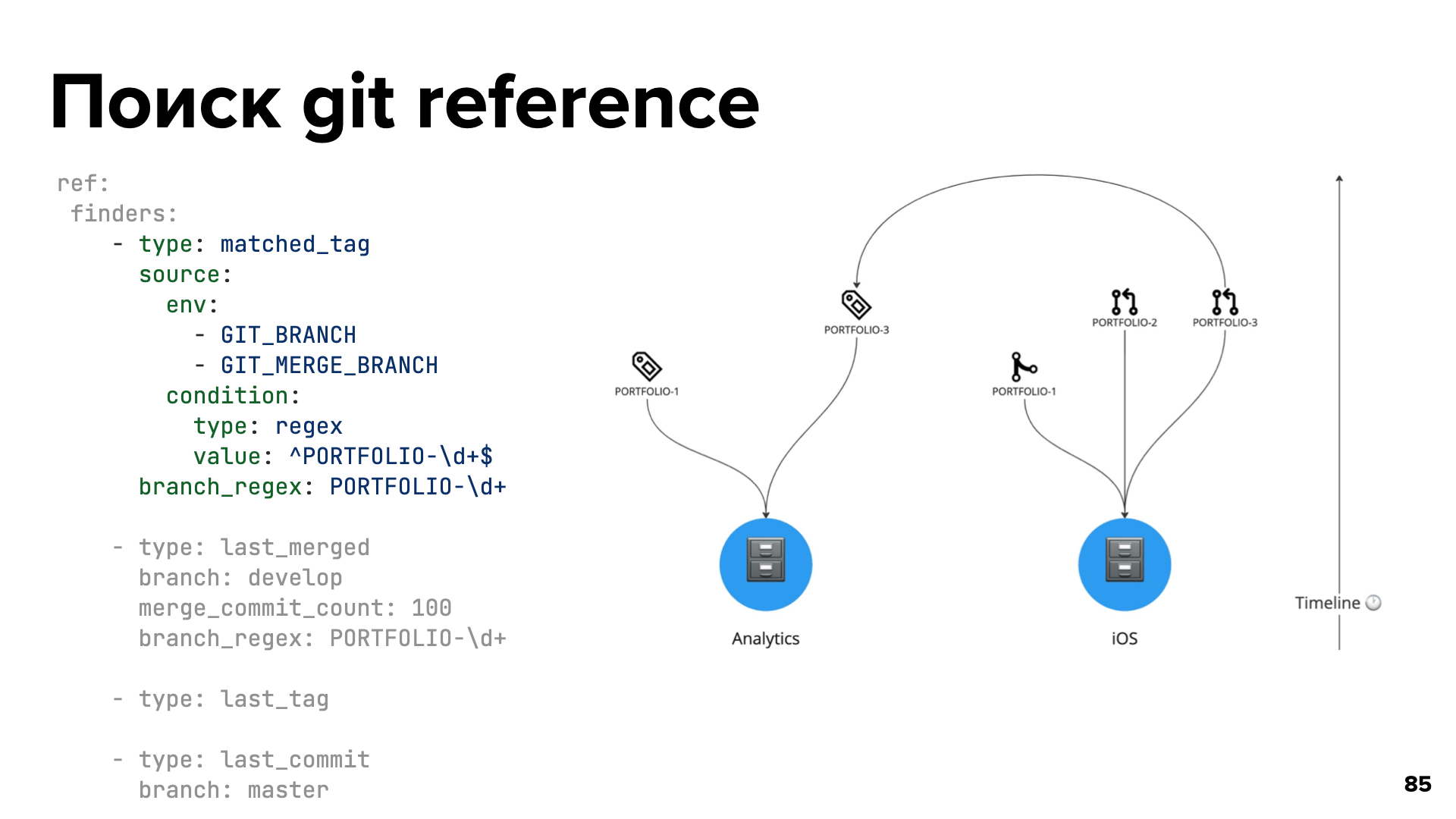
В окружение переменной GIT_BRANCH или GIT_MERGE_BRANCH задаётся название ветки и по нему подцепляется нужный тег.
Еще мы можем работать с другой веткой, например, PORTFOLIO-2. У нее нет никакой аналитики. Тогда берется последний вмердженный код в iOS‑репозитории с нужным тегом. И поскольку PORTFOLIO-1 уже влился, мы будем брать наши схемы из тега PORTFOLIO-1. Маленькая магия, но работает очень круто.

Еще есть finder с типом last_tag. Он берёт последний тег из репозитория аналитики по дате. Либо можно взять последний коммит из определенной ветки используя finder с типом last_commit. Все эти finder‑ы работают последовательно друг за другом, пока не найдут нужный git reference. Git reference — это просто определенный коммит, ветка или тег.
У нового подхода есть ряд преимуществ. У нас нет никакого ограничения ADDONLY: мы работаем с репозиторием как настоящие люди — без границ. Так мы избавляемся от V2-V3 и никак не дублируем наше событие аналитики. Этот подход не блокирует параллельную разработку и, собственно, не требует никакой отдельной актуализации. Репозиторий теперь точно является источником правды. Туда можно забраться и посмотреть, какие события аналитики отправляются сейчас, что очень удобно.
В репозитории AnalyticsGen есть примеры, где лежат схемы из наших проектов. Еще там можно сразу потрогать сам AnalyticsGen.
Какие планы
Дальше мы хотим подготовить AnalyticsGen под опенсорс. Сегодня там есть небольшие завязки под наши внутренние нужды, вроде внутренней аналитики и внешней. Но мы хотим сделать это решение более универсальным, чтобы можно было использовать его в любом проекте.
А следующим шагом мы хотим внедрить генерацию кода для Android. Сейчас она есть, увы, только на iOS, но мы работаем над этим. И в теории мы рассматриваем движение в сторону веба: в идеале хочется сделать администрирование событий аналитики через него. Но это большая работа, и поэтому до нее еще очень далеко.