Перед вами обновлённая коллекция вредных советов для C++ программистов, которая превратилась в целую электронную книгу. Всего их 60, и каждый сопровождается пояснением, почему на самом деле ему не стоит следовать. Всё будет одновременно и в шутку, и серьёзно. Как бы глупо ни смотрелся вредный совет, он не выдуман, а подсмотрен в реальном мире программирования.
Я буду публиковать советы по 5 штук, чтобы не утомить вас, так как мини-книга содержит много интересных отсылок на другие статьи, видео и т. д. Однако, если вам не терпится, здесь вы можете сразу перейти к её полному варианту: "60 антипаттернов для С++ программиста". В любом случае желаю приятного чтения.
Вредный совет N1. Только C++
Настоящие программисты программируют только на C++!
Нет ничего плохого в написании кода на C++. На этом языке написано множество прекрасных программ. Взять хотя бы список приложений с домашней страницы Бьёрна Страуструпа.
Here is a list of systems, applications, and libraries that are completely or mostly written in C++. Naturally, this is not intended to be a complete list. In fact, I couldn't list a 1000th of all major C++ programs if I tried, and this list holds maybe 1000th of the ones I have heard of. It is a list of systems, applications, and libraries that a reader might have some familiarity with, that might give a novice an idea what is being done with C++, or that I simply thought "cool".
Плохо, когда начинают использовать этот язык только потому, что это "круто" или это единственный язык, с которым хорошо знакома команда.
Разнообразие языков программирования отражает многообразие задач, стоящих перед разработчиками приложений. Разные языки помогают элегантно решать различные классы задач.
Язык C++ претендует на звание универсального языка программирования. Однако универсальность не означает быстроту и простоту реализации конкретных приложений. Могут существовать языки, на которых проект будет реализован с меньшими вложениями сил и времени.
Нет ничего плохого, если команда разработает небольшую вспомогательную утилиту на C++, хотя эффективнее для этого было бы использовать другой язык. Затраты на изучение нового языка могут превышать пользу от его применения.
Другое дело, когда перед командой стоит задача создания нового крупного проекта. В этот момент стоит остановиться и подумать. Эффективно ли использовать для неё хорошо знакомый язык C++? Не лучше ли выбрать для этой задачи другой язык?
Если ответ — да, использовать другой язык явно более эффективно — то, возможно, команде рационально потратить время на изучение этого языка. В перспективе это может на порядки сократить затраты на разработку и сопровождение. Или, возможно, стоит поручить этот проект другой команде, которая уже применяет более релевантный в данном случае язык.
Вредный совет N2. Табуляция в строковых литералах
Если в строковом литерале вам нужен символ табуляции, смело жмите кнопку tab. Оставьте \t для яйцеголовых. Не парьтесь.
Речь идёт о строковых литералах, в которых требуется табуляцией отделять одни слова от других:
const char str[] = "AAA\tBBB\tCCC";Казалось бы, по-другому и сделать нельзя. Тем не менее, случается, что программист вместо того, чтобы использовать '\t', не задумываясь, просто нажимает кнопку TAB. Такое встречается в самых настоящих коммерческих приложениях.
Такой код компилируется и даже может работать. Однако явное использование символа табуляции плохо сразу по нескольким причинам:
- На самом деле в литерале могут оказаться не табы, а пробелы. Это зависит от настроек редактора. Но выглядеть это будет так, как будто вставлена табуляция.
- Человеку, который будет сопровождать код, не будет сразу очевидно, используется в качестве разделителей табуляция или пробелы.
- Табуляция в процессе рефакторинга или использования утилит автоформатирования кода может превратиться в пробелы, что повлияет на результат работы программы.
Более того, однажды в реальном приложении я вообще видел приблизительно такой код:
const char table[] = "\
bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla\n\
bla-bla-bla bla-bla-bla\n\
%s %d\n\
%s %d\n\
%s %d\n\
";Строка побита на части с помощью \. Явные символы табуляции использовались в перемешку с пробелами. К сожалению, не знаю, как здесь это показать, но, поверьте, это смотрелось экстравагантно. Выравнивание от начала экрана. Бинго! Чего только не насмотришься, разрабатывая анализатор кода :).
По нормальному этот код следовало оформить как-то так:
const char table[] =
"bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla\n"
" bla-bla-bla bla-bla-bla\n"
" %s\t %d\n"
" %s\t %d\n"
" %s\t %d\n";Символы табуляции нужны, чтобы табличка смотрелась ровно при разной длине печатаемых строк. Подразумевается, что строки всегда короткие. Например, этот код:
printf(table, "11", 1, "222", 2, "33333", 3);распечатает:
bla-bla-bla bla-bla-bla bla-bla-bla bla-bla-bla
bla-bla-bla bla-bla-bla
11 1
222 2
33333 3Вредный совет N3. Вложенные макросы
Всюду используйте вложенные макросы. Так текст программы станет короче, и вы сохраните больше места на жёстком диске. Заодно это развлечёт ваших коллег при отладке.
Мои рассуждения на эту тему приводятся в статье "Вред макросов для C++ кода".
Сразу откройте ссылку в новой вкладке и пока продолжайте чтение. У вас накопится немало открытых вкладок с интересными материалами.
Вредный совет N4. Выключить предупреждения
Отключите предупреждения компилятора. Они отвлекают от работы и мешают писать компактный код.
Программисты понимают, что предупреждения компиляторов — их друзья. Они помогают выявлять ошибки ещё на этапе компиляции кода. Исправить ошибку благодаря предупреждению компилятора намного проще и быстрее, чем отлаживая неработающий код.
Однако я сам на практике обнаружил однажды в одном большом проекте, что часть его компонентов компилируется с полностью отключенными предупреждениями.
Я написал новый код, запустил приложение и увидел, что оно ведёт себя не так, как планировалось. При повторном чтении своего кода я заметил ошибку и быстро её поправил, но был удивлён, что компилятор не выдаёт предупреждение. Это была какая-то очень грубая ошибка, что-то наподобие использования неинициализированной переменной. Я точно знал, что на такой код должно быть выдано предупреждение, но его не было.
В результате небольшого исследования выяснилось, что в компилируемом DLL-модуле и некоторых других полностью отключены предупреждения. Тогда я подключил старших коллег, чтобы провести расследование, как так вообще вышло.
В итоге выяснилось, что эти модули компилируются с выключенными предупреждениями уже несколько лет. В какой-то момент одному из сотрудников было поручено перевести сборку на новую версию компилятора. И он это сделал. Обновлённый компилятор начал выдавать новые предупреждения. И особенно много как раз на legacy-код этих модулей.
Неизвестно, что двигало человеком, но он просто отключил предупреждения в некоторых модулях. Возможно, он хотел сделать это временно, чтобы предупреждения пока не мешали чинить ошибки компиляции. А затем забыл включить предупреждения обратно. Узнать, к сожалению, как именно всё было, не представлялось возможным, так как к тому моменту этот человек уже не работал в компании.
Включив предупреждения обратно, мне пришлось потратить время на рефакторинг кода, чтобы компилятор не ругался. Но ничего непосильного. Я потратил на это один рабочий день. Зато в ходе разбора предупреждений я исправил ещё несколько ошибок в коде, которые до этого момента оставались незамеченными. Любите предупреждения компиляторов и анализаторов кода!
Полезный совет
Старайтесь, чтобы при компиляции проекта у вас не выдавалось ни одного предупреждения. В противном случае вы столкнётесь с эффектом "разбитых окон". Если при компиляции кода постоянно выдаётся 10 предупреждений, то, когда появится 11-ое предупреждение, это не будет казаться недопустимым. Если не вы, так коллеги напишут код, на который будут выдаваться предупреждения. И если считать, что это "ok", это превратится в неуправляемый процесс. Чем больше предупреждений выдаётся при компиляции, тем меньше внимания обращается на новые.
Более того, постепенно предупреждения будут терять смысл. Если вы привыкли, что компилятор постоянно выдаёт предупреждения, вы просто не заметите новое, которое будет сообщать о реальной ошибке в новом написанном коде.
Поэтому ещё одним хорошим советом будет указать компилятору интерпретировать предупреждения как ошибки. Так в вашей команде будет нулевая толерантность к предупреждениям. Вы будете всегда устранять или явно подавлять предупреждения. В противном случае код просто не скомпилируется. Такой подход очень хорошо сказывается на качестве кода.
Конечно, это нужно делать без фанатизма и благоразумно:
Вредный совет N5. Чем короче имя переменной, тем лучше
Используйте для переменных имена из одной-двух букв. Так в одну строчку, помещающуюся на экране, можно уместить более сложное выражение.
Да, действительно, так можно написать короткий код. Он будет столь же коротким, насколько потом непонятным. Фактически отсутствие нормальных имён переменных делает код write-only. Его можно написать и даже сразу отладить, пока ещё помнится, какая переменная, что означает. Но по прошествии времени разобраться в нём будет крайне сложно.
Ещё один способ испортить код — это использовать аббревиатуры вместо нормального именования переменных. Пример: ArrayCapacity vs AC.
В первом случае сразу понятно, что речь идёт о "capacity" — размере зарезервированной памяти в контейнере [1, 2]. Во втором случае потом придётся гадать, что за загадочный AC.
Всегда ли следует избегать коротких имён? Нет. Ко всему нужно относиться разумно. Вполне уместно давать счётчикам в циклах такие имена, как i, j, k. Это устоявшаяся общепринятая практика, и любой программист понимает код с такими именами.
Иногда уместны и аббревиатуры. Например, в коде, реализующего численные методы, моделирование процессов и т.д. По факту этот код просто реализует вычисления по определённым формулам, описанным в комментариях или в документации. Если в формуле какая-то переменная называется SC0, то разумно использовать именно это имя и в коде.
Для примера объявление переменных в проекте COVID-19 CovidSim Model (я когда-то его проверял):
int n; /**< number of people in cell */
int S, L, I, R, D; /**< S, L, I, R, D are numbers of Susceptible,
Latently infected, Infectious,
Recovered and Dead people in cell */Допустимое именование переменных. Что они означают, описано в комментарии. Такое именование позволяет компактно записывать формулы:
Cells[i].S = Cells[i].n;
Cells[i].L = Cells[i].I = Cells[i].R = Cells[i].cumTC = Cells[i].D = 0;
Cells[i].infected = Cells[i].latent = Cells[i].susceptible + Cells[i].S;Я не хочу сказать, что это хороший подход и стиль. Но иногда рационально давать и короткие имена. К любой рекомендации, правилу, методологии нужно подходить обдуманно и понимать, когда стоит сделать исключение, а когда нет.
Хорошие рассуждения о том, как дать хорошие имена переменным, классам и функциям, есть в книге "Совершенный код" С. Макконнелла (ISBN 978-5-7502-0064-1). Всем её очень рекомендую.
Об этой мини-книге
Автор: Карпов Андрей Николаевич. E-Mail: karpov [@] viva64.com.
Более 15 лет занимается темой статического анализа кода и качества программного обеспечения. Автор большого количества статей, посвящённых написанию качественного кода на языке C++. С 2011 по 2021 год удостаивался награды Microsoft MVP в номинации Developer Technologies. Один из основателей проекта PVS-Studio. Долгое время являлся CTO компании и занимался разработкой С++ ядра анализатора. Основная деятельность на данный момент — управление командами, обучение сотрудников и DevRel активность.
Ссылки на полный текст:
Подписывайтесь на ежемесячную рассылку, чтобы не пропустить другие публикации автора и его коллег.
Комментарии (44)


sibirier
05.06.2023 11:48-3Очередная статья с очевидными советами из "Чистый код" и методологии эффективной и "правильной" разработки? Когда же уже люди напишут одну идеальную статью и будут пересылать её всем и вся? Математику же не объясняют каждые два года с нуля, потому что предыдущую объясняющую статью долго искать.
А по делу: если в языках программирования, современных технологиях, движках, методологиях, паттернах и практиках столько проблем и спорных моментов, то не повод ли это критически переосмыслить, выявить проблемы и решить их, а не давать советы "ты сюда не ходи, ты туда ходи..."? Раз многие советы для многих ЯП повторяются, то может их захардкодить в каких-то высокоуровневых статических анализаторах, которые имеют внутренние плагины трансляции этих правил в специфичные для каждого языка? Как сделали С относительно Ассемблера, который упростил огромное кол-во операций. А ещё лучше сделать автогенераторы* (даже алгоритмические, не нейросетевые) необходимого кода и правильного интерфейса с учётом этих "правил"? А ещё лучше сделать генератор всего кода и нужно лишь настраивать нюансы. Большинство же интерфейсов/классов/типов однотипные, их достаточно легко абстрагировать и можно генерировать через конфигуратор, а не писать заново код, заново тестировать, заново дебажить... Да и для шаблонов проектирования как будто бы уже давно нужно было бы сделать фреймворк, а не каждый раз реализовывать заново. Или я чего-то не знаю? Или это такой сговор айтишников, чтобы продолжать писать один и тот же код раз за разом? Вы сами-то не устали?Следующим шагом было бы создание универсального автоматического тестировщика и аналитика, который следил бы за состоянием уже работающих машин сам и маячил бы, когда что-то не так. А аналитик отгружал бы аналитику в нужной форме. Почему до сих пор выпускают статьи как это всё писать кодом, а не настраивать - не понимаю. Может мне кто-то объяснить из старших/опытных? (у меня три года опыт работы, и тот в весьма специфичных кейсах).
* - генерировать (а не интерпретировать) для эффективности и оптимизаций на местах использования + переносимость и ручное допиливание. Хотя для JIT можно и конфигуратором для интерпретатора оставлять, если JIT умеет оптимизировать и такое.

a-tk
05.06.2023 11:48+2Как Вы думаете, что на Хабре делает статья Директора по маркетингу компании, которая делает статический анализатор для C,C++,C#,Java? :)
И весьма недурной анализатор, надо сказать.
sibirier
05.06.2023 11:48Пиарит анализатор статьями о работе анализатора и показывающими (по задумке) их компетентность в этих технологиях.
Анализатор уже возникших типичных ошибок или предупреждение о тех, которые могут случиться.Я призываю избавляться от причин возникновения таких ошибок, а не устранять последствия.
Например: говорят "хороших программистов не хватает", стараются увеличить их количество. Но может стоит развернуть мышление в сторону уменьшения необходимости писать много сложного (и не очень) кода, а не в ускорение написания/этого кода (например за счёт уменьшения времени расследования ошибок)?..
То же и про ошибки: если кода будет меньше и он будет строже организован, то ошибок в нём потенциально будет меньше.
a-tk
05.06.2023 11:48+2Вы таки хотите сказать, что можно выстроить работу людей так, чтобы они никогда не ошибались?
На минутку, разработка ПО - это манипулирование сложной ментальной моделью, ограниченными мощностями нашего мозга, да и ещё детали ментальной модели разные? А ведь любая деталь имеет значение. И если она выпадает - то это путь для возникновения ошибки.
Скажите, Вы свой код хотя бы недельной давности когда-нибудь читали? Вы уверены, что всегда понимаете то, что неделю назад хотели этим кодом сказать?
Анализаторы хороши уже тем, что рутинизируют тривиальные, но почему-то распространённые ошибки. И позволяют выявлять ошибочные паттерны. Путь развития статического анализа - это выявление всё более сложных ошибок, их формализация и формирование базы, которая позволит подобные ошибки выявлять у других разработчиков, делая мир лучше. Ну да, за деньги, ок. Если хорошо делают, то имеют право иметь свой хлеб с маслом и даже с икрой, если будут те, кто платит.
(Тут подумалось, что задачи очень схожие с формированием вирусной базы для антивирусов).
И да, в действительно крупных конторах при разработке софта требуется использовать статический анализ, и рекомендуется использовать как минимум два разных статических анализатора. Речь про Boeing, NASA, ESA и многие другие.

Refridgerator
05.06.2023 11:48Используйте странные числа. Так ваша программа будет выглядеть умнее и солиднее. Согласитесь, что такие строки смотрятся хардкорно: qw = ty / 65 — 29 * s;
Никогда не понимал этих рекомендаций. Получается, что любые числа без привязки к символьным псевдонимам — странные? Как нужно правильно переписать эту формулу? Не уверен, что так лучше:const int sixtyfive = 65; const int twentynine = 29; qw = ty/sixtyfive - twentynine * s;
Я понимаю конечно, что имелось в виду что-то типа
, но иногда числа — это просто числа, исредняя_продолжительность_жизни_у_мужчин_опасных_профессий=65;
по смыслу не отличается отtwentynine = 29
вообще никак. Скорее наоборот понятно, что оно вычислено отдельно на калькуляторе с запасом по точности, и необходимости в его пересчёте не возникнет, когда пи внезапно станет равным четырём.sqrt_of_pi=1.7724538509055160273
Gromilo
05.06.2023 11:48+2Что такое sqrt_of_pi я понимаю, а что такое twentynine не очень. Почему 29, а не 30, например?
Refridgerator
05.06.2023 11:48А почему именно корень из пи, а не логарифм от шести вы тоже понимаете?
Gromilo
05.06.2023 11:48Я понимаю, что автор использовал именно корень от пи, а не что-то другое. -1 шаг на то, чтобы разобраться как работает формула.
Вообще, я согласен, что бывают случаи, когда не нужны именованные переменные. Обычно, это формулы, из других источников. Например конвертация цветов из RGB в HSV не требует объяснения, что это за переменные, но требует ссылки на то место, откуда они взялись. Я сам писал классификатор роста, которые превращал рост в "низкий", "средний" и "высокий" на верхней и нижней границы среднего роста. Константы были получены от заказчика и забиты в код как есть, без названий типа "верхняя граница низкого роста", т.к. из кода было всё очевидно.
В то же время, я против потери информации. Если использовали формулу из внешнего источника - добавь ссылку в комментарии. Если подобрал коэффициенты и хз почему они работают - добавь комментарий. Если коэффициентами в формуле можно поиграть - занеси их в константы, будет как конфиг. Если число из предметной области, назови его, облегчи труд идущего следом.
А за константы вида twentynine, нужно заворачивать ПР, ибо они не добавляют ничего кроме шума.

domix32
05.06.2023 11:48По-хорошему, в такой ситуации и qw должен быть некой осмысленной переменной в противном случае выдуманные формулы ведут к выдуманным проблемам.
Refridgerator
05.06.2023 11:48Это уже другой вопрос. (Предположительно) qw может хранить промежуточное значение, которое используется для переменных q и w. А названия q и w выбраны такими потому, потому что именно так они назывались в первоисточнике.
domix32
05.06.2023 11:48Как раз это самое "предположительно" - то о чем я и говорю. Без полного контекста это просто случайная функция без смысла, а с магическими числами ещё и дурная, т.к. информации о контексте ещё меньше.
Refridgerator
05.06.2023 11:48Ну обычно программист имеет представление о задаче и контексте, в котором пишет свой или изучает чужой код.
Refridgerator
05.06.2023 11:48-2Вредный совет N14. double == double
А здесь интересно, что на этот вредный совет вы дали ещё более вредную альтернативу. Потому что погрешность вычислений вовсе не обязательно будет укладываться в DBL_EPSILON, и в вашем примере внезапно тоже.
Andrey2008 Автор
05.06.2023 11:48+1Притензия непонятна. Там сказано, что погрешность может быть большой или малой. И даны отсылки. Предложите свой вариант правильного подхода. :)
Refridgerator
05.06.2023 11:48Претензия в том, что описанное решение не решает проблему, а только усугубляет её, создавая иллюзию того, что проблема решена. В вашем примере разница между 0.49999999999999994 и 0.5 очевидно большем DBL_EPSILON. Более того, заранее эту погрешность предсказать невозможно, потому что она будет зависеть от множества факторов, и чтобы контролировать погрешность этот контроль нужно вводить в вычисления явным образом. Кроме того, если в коде написано
double x=0.5не факт, что значение x будет точно 0.5 — оно может измениться в процессе парсинга.А правильных подходов тут даже несколько.
1) сравнивание double с константой вполне корректная операция, если программист точно знает, что он делает. Но дробные константы для double нужно вводить только через битовое представление или int8;
2) использовать тип decimal,
3) приводить сначала к целочисленному типу а только потом сравнивать. Неif(x==0.5)и неif(abs(x-0.5)<eps)аif((int)(10*x)==5)a-tk
05.06.2023 11:48В третьем варианте Вы допустили ошибку.
Refridgerator
05.06.2023 11:48Тем, что явно тип округления не прописал? Согласен, недочёт.
a-tk
05.06.2023 11:48Нет, тем что там не округление, а отсечение.
Почти корректным будет вот это решение: `if ((int)(10*x+0.5) == 5)`
Refridgerator
05.06.2023 11:48Так возможно и нужно именно отсечение. Варианты
if((int)round(10*x)==5)if((int)floor(10*x)==5)if((int)ceiling(10*x)==5)ИМХО более информативны.

datacompboy
05.06.2023 11:48+2А "к ближайшему четному"?
Refridgerator
05.06.2023 11:48Нужно отдельную функцию для этого написать типа round_even(). Мне приходилось писать и логарифмическое округление (к числам 0.5, 0.25, 0.125 etc), и 2n округление, и даже 2n·3n·5n округление.
a-tk
05.06.2023 11:48А если в общем случае числа могут быть как положительными, так и отрицательными?
Refridgerator
05.06.2023 11:48+1Размер указателя и int — это всегда 4 байта. Смело используйте это число. Число 4 смотрится намного изящнее, чем корявое выражение с оператором sizeof.
А ещё можно явно писать int4/int8/etc. А для указателя использовать тип «указатель», который можно переопределить глобально.
Вообще складывается ощущение, что большинство антипаттернов — это проблемы языка, а не программиста, там практически каждый можно оспорить с контр-аргументом.
domix32
05.06.2023 11:48Плохо, когда начинают использовать этот язык только потому, что это "круто"
Забавно, что есть организации, которые до сих пор показывают промо кандидатам, которых они нанимают, как они с гордостью произносят "мы используем си плас плас"
вы столкнётесь с эффектом "разбитых окон".
Это кстати поясняет, почему у яблок настолько плохой код. Xcode практически невозможно отучить ругаться не по делу. Поэтому пол проекта будет светить жёлтым.
Refridgerator
05.06.2023 11:48-3Вы же не против пообщаться о паттернах? Решение
if (!((ch >= 0x0FF10) && (ch <= 0x0FF19)) || ((ch >= 0x0FF21) && (ch <= 0x0FF3A)) || ((ch >= 0x0FF41) && (ch <= 0x0FF5A)))плохо вне зависимости от того, записано оно в столбик или строчку. Правильное решение — ввести дополнительный слой абстракции в виде нового класса с методами bool in_range(a,b) и bool out_of_range(a,b), тогда эти кучи проверок в одном if будут намного более читабельны.

Kelbon
05.06.2023 11:48а класс то вам зачем...
Refridgerator
05.06.2023 11:48-1Потому что это си++, а не си. ООП парадигма. Чтобы проверку вхождения в диапазон вызывать как метод. А математические операции, которые не имеют смысла, не реализовывать. Тогда не получится ошибиться, складывая километры с помидорами из-за опечатки в названии переменной (ну типа seed вместо speed), потому что из-за разных типов компилятор обругается.

eao197
05.06.2023 11:48+2Потому что это си++, а не си. ООП парадигма.
С++ не зациклен на ООП, это мультипарадигменный язык. И использовать класс просто ради класса -- это моветон.
Andrey2008 Автор
05.06.2023 11:48+2О нет, только не класс! Про это будет в "Вредный совет N56. Больше классов!".
Refridgerator
05.06.2023 11:48-1Ну то есть size_t вместо int в циклах для вас нормально, а разные классы для разных сущностей уже нет. Противоречие.

KanuTaH
05.06.2023 11:48+1Вы же даже не знаете исходной задачи, а уже готовы предложить "правильное решение" и налепить классов.
datacompboy
05.06.2023 11:48Конечно, есть же boost!
a-tk
05.06.2023 11:48О! Моё воспалённое сознание предлагает сделать класс с адекватным именем, который в конструкторе получает искомый синтаксис, и вычисляет принадлежность к некоторому классу символов (непереводимая игра слов) внутри
operator bool()datacompboy
05.06.2023 11:48+1Хочу послушать за адекватное имя для проверки вхождения числа в указанные диапазоны. открытые, закрытые, полуоткрытые. А потом в объединение диапазонов. И пересечение. Мы еще про константные диапазоны и переменные поговорим, конечно же.
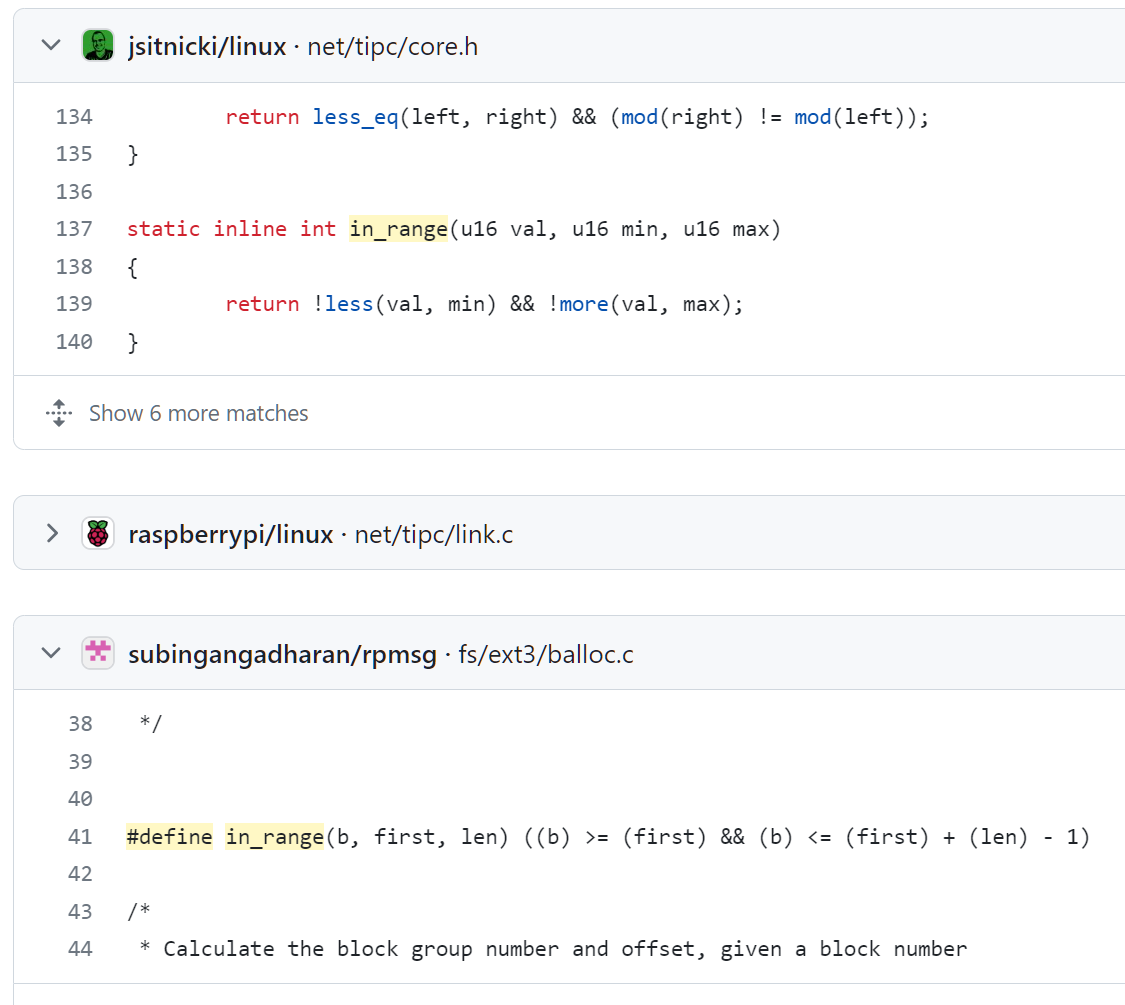
Буде оно так нужно, был бы ворох библиотек для такой радости -- однако вместо этого ворох местных и местячковых вариантов in_range, где на одной странице с и без проверки вхождения правой границы:
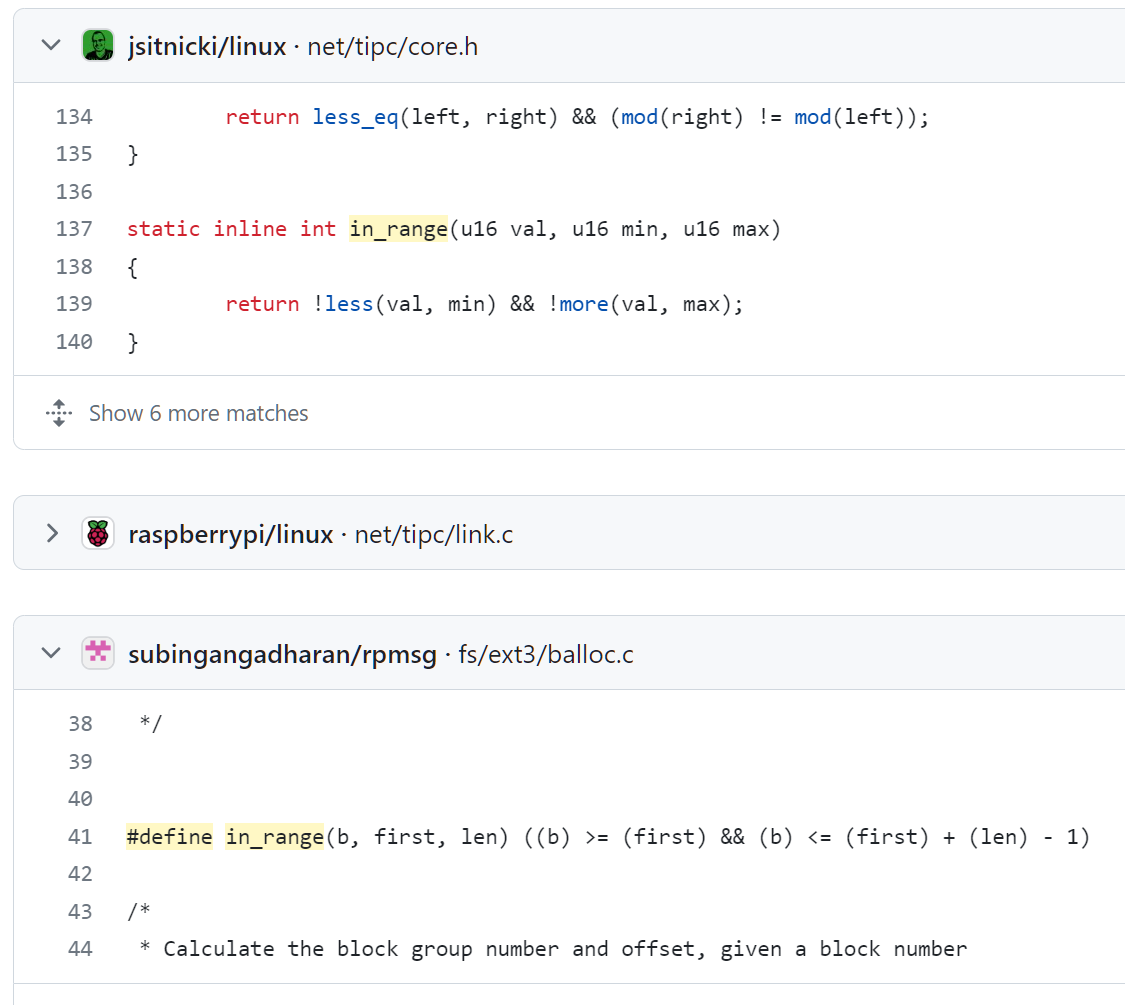
Refridgerator
05.06.2023 11:48+1Буде оно так нужно, был бы ворох библиотек для такой радости — однако вместо этого ворох местных и местячковых вариантов
Использование #define для определения функции выдаёт си-программиста с головой. Понятно, что им сложно в ООП стиле мыслить.Хочу послушать за адекватное имя для проверки вхождения числа в указанные диапазоны
Можно и без имён обойтись, через перегрузку операторов сравнения. На шарпе мне потребовалось 3 класса, чтобы такая конструкция компилировалась:IntE x = 12; if ((3 <= x < 7) | (11 < x <= 13)) { ... }datacompboy
05.06.2023 11:48Согласен, выглядит красиво (надеюсь, | это опечатка а не требование использовать | вместо ||).
минусов вижу два -- x таки не просто число, и обеспечить бесшовность для смесей с разными комбинациями (одно сравнение и несколько сравнений) в одном выражении надо постараться. Плюс, неопределённость "x <= 3" это bool или что -- обычно плохо.
Красивым мне кажется решение когда можно "x in [3...7)" записать.
Refridgerator
05.06.2023 11:48-1Это не опечатка, это неявное приведение к bool. Частичное сравнение в обе стороны тоже будет работать, если добавить ещё один класс и доработать напильником.
Refridgerator
05.06.2023 11:48Кстати в boost-е есть сценарий прямого сравнения чисел в формате с плавающей точкой, о котором я упоминал чуть ранее:
Real barycentric_rational_imp<Real>::operator()(Real x) const { ... if (x == m_x[i]) { return m_y[i]; } ... }
А рядом подробный комментарий,почему так можноPresumably we should see if the accuracy is improved by using ULP distance of say, 5 here, instead of testing for floating point equality. However, it has been shown that if x approx x_i, but x != x_i, then inaccuracy in the numerator cancels the inaccuracy in the denominator, and the result is fairly accurate. See: epubs.siam.org/doi/pdf/10.1137/S0036144502417715
datacompboy
А порядок этих советов какой? Внезапный переход от выбора языка к табуляции в строковых литералах... Вызывает легкую оторпь
Andrey2008 Автор
Порядка нет, только путь фейспалма :)
a-tk
SELECT * FROM incidents ORDER BY rand();