
Привет! Я Кирилл Мамонов, главный аналитик отдела монетизации данных в Почтатехе. Расскажу, как мы создали модель, которая предсказывает до 97% возможных пропаж международных отправлений.
Почему антифрод в логистике — нетривиальная задача
Представим такую ситуацию. Петя поехал в отпуск в Китай и решил оттуда отправить Васе посылку. По какой-то причине посылка до Васи не дошла.
В процессе доставки задействовано множество участников — со стороны не только Почты, но и ее контрагентов. Проблемы с посылкой могли возникнуть у любого из них.
Первый из участников — зарубежная почта, которая приняла, запаковала и доставила посылку до границы. При этом отправление, скорее всего, прошло через несколько сортировочных центров, побывало в контейнерах с другими посылками и перемещалось в разном транспорте.
Раз наша доставка международная, в процессе участвуют две таможни — китайская и российская. Каждая из них проводит досмотр и решает, пропускать отправление или нет.
По территории России посылка тоже проходит большой путь. Ее сортируют, запаковывают в емкость с остальными посылками, перевозят разным транспортом из одного логистического узла в другой и пересортируют.
С посылкой производится множество операций, и в них участвуют как автоматизированные системы, так и люди. Чтобы ситуаций, таких как у Пети с Васей, становилось меньше, нужно выявить принцип, по которому происходят потери. А для этого придется проанализировать огромное множество операций на всех возможных этапах доставки.
При этом ежедневно через Почту проходит до 1,5 миллиона отправлений. Они курсируют между 6 логистическими центрами, 1100 сортузлами и 38 000 отделениями. Отправления перевозят как собственные автомобили, поезда и самолеты, так и партнерские.
Как вы понимаете, без помощи ML что-то предсказать на таком объеме информации невозможно.
Какие данные легли в основу модели
Объем данных
Информация о том, какие операции проводятся с посылкой, поступает в наше единое хранилище данных — так формируется цифровой след отправления. Сейчас в хранилище порядка 7,7 петабайт.
Работа с отправлением заканчивается выдачей получателю. Если конечной становится какая-то другая операция, то мы считаем это обрывом цифрового следа.
Соответственно, наша цель — предсказать вероятность, что произойдет обрыв.

Из всех отправлений, проходивших через Почту за последние годы, мы насемплировали 1 млн с обрывом цифрового следа и 2 млн доставленных. Зачем мы так сделали? По результатам наших экспериментов, модель с таким дисбалансом классов показала более высокое качество, чем сбалансированная или использующая дисбаланс всего объема данных.
В итоге у нас получилось 3 млн отправлений и 80 млн операций с ними. Эти объемы позволили сохранить репрезентативность выборки и укладывались в ограничения вычислительных мощностей.
Блоки данных
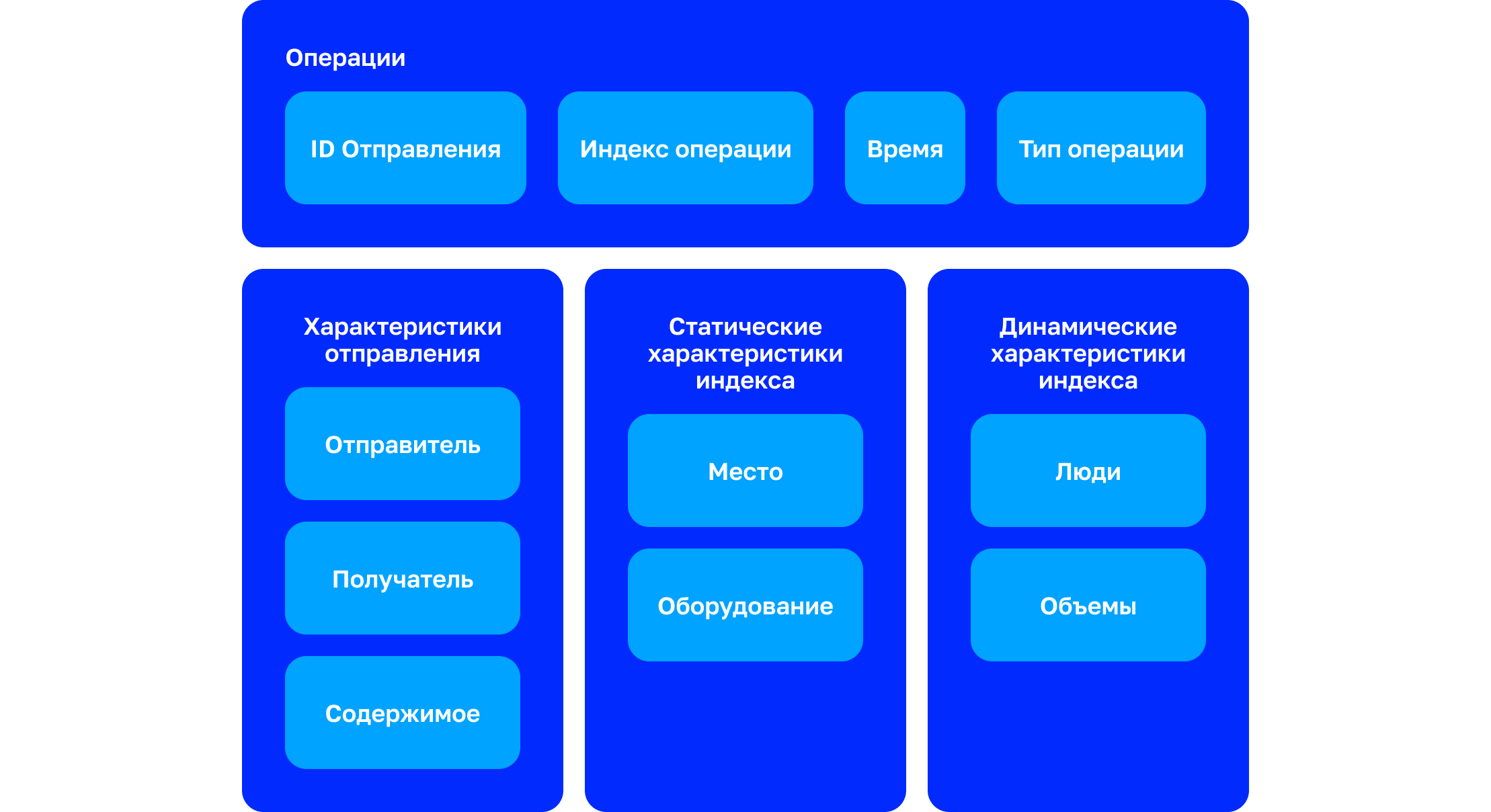
Характеристики операций
Каждая из 80 млн операций характеризуется следующей информацией:
Идентификатор отправления
Место (индекс) и время совершения операции
Тип операции
Но этого недостаточно для того, чтобы предсказать обрыв цифрового следа. На одном и том же индексе — огромное множество одинаковых операций — например, распаковка или пересортировка. А проводят их над разными отправлениями (мелкий пакет, письмо, бандероль и т. д.), причем разные системы, люди или даже подразделения. К тому же такая информация от месяца к месяцу меняется.
Поэтому мы дообогатили этот блок данных еще тремя.
Характеристики отправления
Кто получатель
Кто отправитель
Что внутри (по данным продавца/отправителя)
Этот блок добавляется к характеристикам операций с помощью поля «ID отправления».
Статические характеристики почтового объекта
Где объект находится
Какое в нем оборудование
Какой тип объекта — логистический центр или место международного почтового обмена, почтовое отделение и т. д.
Добавляем их к первому блоку по полю «индекс».
Динамические характеристики почтового объекта
Это особый блок характеристик. Мы собираем их первого числа текущего месяца. Причем берем характеристики именно за прошедший календарный месяц — например, 1 июня собираем данные за май.
Вот что входит в блок:
Сколько всего отправлений прошло через индекс
Сколько отправлений конкретного типа прошло через индекс
Сколько людей задействовано в обработке отправлений конкретного типа
Сколько обрывов цифрового следа произошло с отправлениями конкретного типа
В общем, стремимся охарактеризовать объемы груза и работающих на каждом объекте людей.
Этот блок сопоставляется с остальными с помощью трех полей: индекс, тип отправления, месяц, предшествующий месяцу проведения операции. Приведу пример.
Допустим, на индексе 126789 15 февраля 2023 года в емкость запаковали бандероль. Тогда мы будем добавлять к этой операции следующие динамические характеристики: как на этом индексе в январе 2023 года запаковывались в емкость бандероли.
Как формировали обучающую и тестовую выборку
После того как мы разобрались с данными, разбили их на тестовую и обучающую выборки. Для этого взяли 80 млн операций и положили их на временную ось.

Тестовая выборка
Берем операции только за последний месяц. Убираем среди них вручения. Дальше для каждого отправления берем только последнюю операцию, а все остальные убираем. Почему важна только она?
Допустим, с отправлением за этот месяц произошло 10 операций. После каждой из первых девяти точно не произошло обрыва цифрового следа, ведь у нас есть 10-я. Как раз на ней существует некая неопределенность, будет следующая операция с отправлением или нет. Поэтому ее и оцениваем.
Обучающая выборка
В обучающую выборку включили операции с теми отправлениями, которые не вошли в тестовую. Причем взяли только последние операции за каждый день.
Приведу пример такой операции. Посылку приняли в сортировочном центре и обработали в 23:00, но передать ее в отделение сегодня не получится — там уже закончился рабочий день. То есть в конце дня отправление «зависло» на определенной сортировочной точке.
На проде модель будет оценивать отправления ночью, и неопределенность возникнет именно для этой «последней» операции, поэтому важно, чтобы и при обучении модель смотрела на операции аналогичной природы.
Какую модель выбрали
Итак, мы разобрались с данными и сформировали выборки. Какую же модель теперь на этих данных обучать?
В нашем случае данные последовательные — операции идут по порядку, и каждая предыдущая влияет на следующую. Мы выделили для себя два основных метода обработки этих данных:
Рекуррентные нейронные сети — в них связи между элементами образуют направленную последовательность
Классические модели классификаций — они позволяют внедрить последовательность в сами обучающие данные
В итоге остановились на втором способе. Причин две.
Интерпретируемость для бизнеса. Мы хотим понимать, почему модель сказала, что именно эта операция для отправления станет с высокой вероятностью последней. А такая же операция для другого отправления — наоборот. В этом плане классические модели легче интерпретировать.
Вычислительные ресурсы. Ожидаемо, вычислительные ресурсы у нас не бесконечны. А классические модели классификаций к ним менее требовательны.
Мы провели несколько экспериментов, попробовали много разных классических моделей. Некоторые не подошли — они не могли отличить операции, предшествовавшие обрыву цифрового следа, от всех остальных. А модели, которые по отдельности показывали неплохие результаты, попробовали ансамблировать. Но и ансамбли показывали себя не лучшим образом.

В итоге пришли к модели бустинга из LightGBM. Она показала хорошее качество из коробки — превзошла даже те модели, для которых мы подобрали оптимальные гиперпараметры.
Как интерпретировали модель

Справа — количественные показатели качества при пороге отсечения по вероятности 0,1. То есть все, что выше 0,1, относится к обрыву цифрового следа. Все, что ниже, — к успешному прохождению отправления в текущей операции.
Как мы видим, распределение вероятности выглядит здраво с точки зрения реальности. У нас действительно не так много отправлений, вероятность потери которых — 95–100%. При этом у основной массы отправлений вероятность обрыва низкая — от 0,3 до 0,5. Это тоже похоже на правду: в реальной жизни для обрыва нужны благоприятные факторы, которые редко сходятся воедино.
Что касается количественных показателей, то у нас высокая точность предсказания успешной доставки (успешного выполнения операции) и высокая полнота предсказания обрыва цифрового следа. Мы знаем о 97% отправлений, у которых произойдет некорректный обрыв цифрового следа. Точность нашего предсказания больше 2/3. То есть из 3 отправлений, которым мы предсказали обрыв, 2 действительно потерялись.

Вверху — визуализация feature importance. На ней видно, что самым важным для предсказания стало место операции (index_oper) и ее тип (oper_type+oper_attr).
Следующим по важности идет блок динамических характеристик — объем отправлений и люди, которые их обрабатывали:
Сколько отправлений прошло через данный индекс месяц назад, и в системе проставлено имя оператора, который их обрабатывал (dist_qty_oper_login_1)
У скольких отсутствует оператор — например, обработка автоматизирована (dist_qty_oper_login_0)
Сколько всего было операций с оператором (total_qty_oper_login_1)
Сколько всего отправлений через себя пропустил этот индекс месяц назад (total_qty_over_index)
Сколько отправлений конкретного типа через него прошло (total_qty_over_index_and_type)

Теперь рассмотрим визуализацию SHAP. Серым обозначены качественные характеристики, а градацией от синего до красного — количественные и числовые. Красные характеристики имеют большее значение, а синие — меньшее.
Качественные (серые) характеристики мы так ранжировать не можем, потому что к ним нельзя применить понятие «больше» или «меньше». Например, если прибавить единичку к весу отправления, то он станет больше. А если то же самое сделать с номером индекса, то изменится сам объект почтовой связи.
Вторая визуализация показала закономерность: если в отправлении едет набор чего-то (is_sets_in_rpo), то вероятность обрыва цифрового следа повышается. Как мы это определяем? У нас есть две полуплоскости графика: положительная (справа) и отрицательная. Если значение shap value лежит в положительной полуплоскости, то при данном значении характеристики вероятность обрыва цифрового следа увеличивается. Если в отрицательной — уменьшается.
Еще выяснили, что вероятность обрыва цифрового следа повышается, если отправление едет через конкретные индексы. А значит, можно снизить риск обрыва — например, изменив маршрут.
Что в итоге
Одна из наших основных задач — безопасность почтовых отправлений, и процент сохранности посылок составляет 99,9993%. По этому показателю Почта России приближается к международному лидеру — Почте Японии (99,99999%).
Теперь, когда мы знаем, какие посылки рискуют потеряться, наша служба безопасности уделяет им повышенное внимание, чтобы каждая из них доехала в целости и сохранности до получателя. Помимо этого мы составляем риск-профиль каждого объекта почтовой связи. Он помогает понять, где нужно улучшить процессы, например провести тренинги для сотрудников.
Комментарии (13)

v-milenin
07.06.2023 08:27+2Пару лет назад подписался на несколько познавательных журналов для ребёнка с доставкой через почту. Примерно половину из них приходилось получать через какие-то скандалы в отделении. Сиуации разные - то не принесли вообще журнал, то на почиу пришёл, но до ящика не донесли, то 2 месяца журнала нет, а на почте говорят, что к ним не поступил, хотя в киосках соседних он уже 2 месяца назад и появился. И постоянно мне утверждали, что в этих проблемах виноват каким-то образом я.
В итоге, решил купить своё спокойствие примерно за +20% от стоимости, заказывая журналы напрямую или покупая в киосках.

Yuriy_krd
07.06.2023 08:27+2Поддержу предыдущих ораторов в том, что почта стала работать гораздо лучше. У меня только одна претензия — в отделениях все еще много народа. Чтобы получить или отправить что-то — я там провожу не меньше 15-30 минут. Причем это не какое-то конкретное отделение, а несколько, в разных частях города-миллионника.

Alligattor
07.06.2023 08:27поэтому уже как 2 года (если не больше) записываюсь в очередь через приложение - указал что нужно сделать (получить/отправить), в какое время. К указанному времени приходишь и без очередей тебя обслуживают. Как только эта возможность появилась и я со входа прямиком подходил к окошку, минуя живую очередь, то приходилось объяснять, что я не наглый, а умный - предлагал даже научить, но некоторым нужно было просто выплеснуть агрессию, что и происходило. При этом работники почты были осведомлены об этом и "защищали" меня ))

ezhonok
07.06.2023 08:27Приятно удивлен, как (в лучшую сторону) изменилась работа почты. Хоть у меня и не было потерь посылок, но было множество других неприятных ситуаций, связанных с почтой. Сейчас как-то более цивильнее стало, что ли

Zharik
07.06.2023 08:27Хорошие результаты и понятные инсайты.
Вы не пытались разбить индекс на бакеты с разной частотой потерь? Может случиться, что есть несколько, на которые может падать десятки % пропаж.
Вы ничего не казали про очистку данных. Обрабатывали и исключали ли понятные массовые пропажи, например авария, когда уничтожается все содержимое контейнера и т.д.

kmamonov Автор
07.06.2023 08:27-1Спасибо
В рамках EDA такие бакеты не выделились, поэтому оставили индекс просто как фичу, она и стала одной из наиболее важных. В % от объема распределение по индексам было близко к равномерному с длинным хвостом у 0
У любого "понятного" события(даже у "аварии") есть цифровой след, задача модели была предсказать "непонятный" обрыв цифрового следа. Некорректных объемов отправлений, способных зашумить модель, на рассматриваемом нами временном промежутке не было - это проверили.

avacha
07.06.2023 08:27+1Мне кажется, что думать о пропаже посылок надо с другого конца. Например, с нормальных зарплат и запрета продажи тушенки, тазов и прочего трэша в отделениях ПР.
Серьезно, 2023 год на дворе, а такое впечатление что руководят вчерашние колхозники, устроившие из почты в городах-миллионниках хорошо знакомое им сельпо.

M_AJ
07.06.2023 08:27+3Буквально на днях на Пикабу появился пост, где человек писал о сортировочном отделении, в котором подозрительно часто попадают посылки. Было бы неплохо, если бы подняли реальную статистику по нему, и подтвердили или опровергли гипотезу автора того поста. Речь шла про отделение 424950.

xaosxaos2
07.06.2023 08:27+4Ммм как всё круто! Хотелось бы сказать. Но давайте взглянем на проблему с другой стороны, много лет на моей почте не хватает почтальонов, да что там их руководитель отсутствует. И желающих нема. Плюс людей работающих на почте посути заставляют покупать-то, что никому не нужно. Ну да менеджмент зато наверное радуется о покупают значит надо. Раньше почта обрабатывала посылки 6 дней в неделю теперь 4 угадайте почему?

Buharovsky
07.06.2023 08:27+1Когда я вижу на дверях своего почтового отделения объявление "требуются" и указанную зарплату, мне становится жалко женщин, работающих там
xaosxaos2
07.06.2023 08:27+1Согласен. Только на моем отделении объявление даже без указания зарплаты. А сколько за 5 лет сменилось операторов. Они работают в основном месяц ну два потом место снова вакантно.
Aquahawk
Принято хаять почту, а я скажу что почта проделала колоссальный объём работ и письма и посылки реально доставляются. У меня в архиве отслеживания 272 посылки за 10 лет, из них потерялось одна или две безтрековых из Китая с копеечными вещами, в остальном всё отлично ходит. У меня из проблем только то, что уведомления о заказных письмах всё ещё приходят бумажкой, хотя я зарегистрирован на электронные уведомления. Это немного портит работу с госорганами с которыми переписка ведётся почтой.
Viacheslav01
Полностью согласен почта работает очень хорошо, по крайней мере в больших городах.
Но вот с уведомлениями беда, за последние пару лет были отличные случаи:
1) Прихожу на почту за письмом, в уведомлении еще 10 дней срока хранения, а нет письма уже нет, срок хранения истек! Как так спрашиваю, говорят программа поменялась и уведомление из старой не отражает данные в новой! Бинго почта потеряна!
2) Это совсем свежее, жду письма от суда каждый день проверяю почтовый ящик, получаю уведомление, на следующий день иду на почту, но увы письмо отправлено обратно истек срок хранения.