

Всем привет! Ранее я разобрал и протестировал сервер с процессором ARM, который попал к нам в Selectel Lab. Сервер показал хорошие результаты по производительности в ряде классических тестов, но в этот раз захотелось проверить его в боевой задаче — в работе с базами данных. Быть может, архитектура ARM-процессора сделает всех конкурентов на этой территории?
Чтобы ответить на этот вопрос, протестировал ARM вместе с семеркой серверов разных конфигураций с процессорами Intel и AMD. В качестве баз данных для нашего эксперимента выбрал самые популярные — PostgreSQL и MySQL. Результаты тестов с графиками и комментариями — под катом. Надеюсь, они будут полезны вам при выборе сервера под БД.
Подготовка к тестированию
«Кастинг» участников
Я выбрал самые популярные и лучшие выделенные серверы Selectel, чтобы прогнать тесты баз данных на них. Вот общая табличка с конфигурациями: здесь у нас все звезды — Ampere Altra, AMD и Intel:
|
Конфиг Selectel |
AL63-NVMe |
PL64-NVME |
PL84-NVME |
ARM01-NVME |
PL23-NVME |
PL33-NVME-10GE |
AL83-NVME-10GE |
CUSTOM |
|
Процессор |
2 × AMD EPYC 7343 |
2 × Intel Xeon Silver 4314 |
2 × Intel Xeon Gold 6336Y |
1 x Ampere Altra Max M128-30 |
2 × Intel Xeon Silver 4214R |
2 × Intel Xeon Gold 6240R |
2 × AMD EPYC 7513 |
2x Xeon 6354 |
|
Всего ядер |
32 |
32 |
48 |
128 |
24 |
48 |
64 |
36 |
|
Всего потоков |
64 |
64 |
96 |
128 |
48 |
96 |
128 |
72 |
|
RAM |
256 ГБ DDR4 |
192 ГБ DDR4 |
256 ГБ DDR4 |
256 ГБ DDR4 |
192 ГБ DDR4 |
384 ГБ DDR4 |
512 ГБ DDR4 |
256 ГБ DDR4 |
|
Диски SSD |
2 × 960 ГБ SSD NVMe |
2 × 1920 ГБ SSD NVMe |
2 × 1920 ГБ SSD NVMe |
2 × 1920 ГБ SSD NVMe |
2 × 960 ГБ SSD NVMe |
2 × 960 ГБ SSD NVMe |
2 × 1920 ГБ SSD NVMe |
2 × 960 ГБ SSD NVMe |
|
Диски HDD |
2 × 10000 ГБ HDD SATA |
2 × 1920 ГБ SSD SATA |
2 × 1920 ГБ SSD SATA |
2 × 1920 ГБ SSD SATA |
2 × 1920 ГБ SSD SATA |
2 × 10000 ГБ HDD SATA |
||
|
Доп. сетевая карта |
10GbE |
10GbE |
Выбор ОС и версий баз данных
Операционную систему установил на SSD NVMe-диски. Использовал Ubuntu 22.10, так как на момент тестирования это была последняя версия ОС, которая одинаково подходит как под ARM, так и под x86.
PostgreSQL взял самую свежую — 14 версию. Выбрал ее из-за повышенной производительности. В ряде тестов она показала рост в два раза в сравнении с 12 версией БД. Также на данный момент это крайняя версия, которая способна сосуществовать с ARM-архитектурой. По той же причине выбрал MySQL 8. Базы данных разворачивал на тех же NVMe-дисках.
Выбор тестов
Использовал Pgbench, Sysbench и Mysqlslap. Тесты проводил с использованием одного и двух потоков постоянно. Далее шли тесты в размере 20%, 40%, 60%, 80%, 99% от максимального количества потоков процессора в конкретной конфигурации.
Количество клиентов, которые подключались к базе, всегда превышало число потоков в 2 раза. Здесь руководствовался рекомендациями разработчиков PostgreSQL для, так скажем, «дефолтных тестов из коробки».
Подготовка системы и баз данных
Для объективности тестирования и сравнения я постарался организовать для серверов некий «вакуум»:
- Все тесты проводил локально, непосредственно на сервере с базой данных. Чтобы исключить влияние сетевых погрешностей и пропускной способности.
- Никак не менял настройки операционной системы, которые потенциально могли повлиять на улучшение перфоманса, — оставил дефолтные значения.
- Настройкой PostgreSQL тоже не занимался — только поправил конфиг на подключение и количество подключений к БД.
В общем, попытался свести к минимуму количество настроек, которые могли повлиять на ход тестов.
Сначала развернул софт.
Начал с PostgreSQL. Тут все довольно просто: устанавливаем ПО, правим конфиг, создаем базу, задаем пароль. Есть важный нюанс: для тестов pgbench требуется файл pgpass. С ним при автоматическом запуске тестов не придется вводить пароль при каждой итерации.
#!/bin/bash
# Устанавливаем пароль для пользователя "admin"
admin_password="passwd"
# Устанавливаем PostgreSQL-14
apt install postgresql-14 sysbench
# Изменяем конфигурационный файл PostgreSQL
cd /etc/postgresql/14/main/
sed -i -e "s/^#\?\s*listen_addresses\s*[=]\s*[^\t#]*/listen_addresses = '127.0.0.1'/" postgresql.conf
sed -i -e "/^max_connections/s/[= ][^\t#]*/ = '300'/" postgresql.conf
service postgresql restart
# Создаем базу данных "test"
sudo -u postgres createdb test
# Создаем пользователя "admin" с установленным паролем
echo "admin:$admin_password" | sudo chpasswd
sudo -u postgres createuser admin
sudo -u postgres psql -d test -c "ALTER USER admin WITH PASSWORD '$admin_password';"
# Добавляем информацию о подключении к базе данных в файл .pgpass
cat >> /home/admin/.pgpass<<EOF
127.0.0.1:5432:test:admin:$admin_password
EOF
chmod 0600 /home/admin/.pgpass
chown admin:admin /home/admin/.pgpass
По тому же принципу развернем MySQL.
#!/bin/bash
# Устанавливаем пароль для пользователя "admin" MySQL
mysql_password="passwd"
# Устанавливаем MySQL-сервер 8.0 и Sysbench
apt install mysql-server-8.0 sysbench
# Изменяем конфигурационный файл MySQL
cd /etc/mysql/mysql.conf.d/
sed -i -e "/^bind-address/s/[= ][^\t#]*/ = '127.0.0.1'/" mysqld.cnf
sed -i -e "/^mysqlx-bind-address/s/[= ][^\t#]*/ = '127.0.0.1'/" mysqld.cnf
sed -i -e "s/^#\?\s*max_connections\s*[=]\s*[^\t#]*/max_connections = '300'/" mysqld.cnf
service mysql restart
# Создаем базу данных "test" и пользователя "admin" с установленным паролем
echo "CREATE DATABASE test;" | mysql
echo "USE test;" | mysql
echo "CREATE USER 'admin'@'localhost' IDENTIFIED BY '$mysql_password';" | mysql
echo "GRANT ALL ON *.* TO 'admin'@'localhost' WITH GRANT OPTION;" | mysql

Автоматизация теста pgbench
У нас получилось много конфигураций для тестирования и много сценариев с разным количеством потоков, которые мы хотели проверить. При разном количестве потоков, например, приходилось высчитывать, сколько будет 20% от 128 потоков и вносить в скрипт. Это не только отнимало время, но и повышало риск ошибки.
Поэтому я набросал скрипт, который позволил автоматизировать и облегчить тестирование. С помощью него можно было не считать количество потоков, не менять это все вручную. Также добавил в скрипт переменные: время тестирования, адрес подключения к БД, пароль и т.д.
#!/bin/bash
read -p "Введите максимальное количество потоков: " CORES
if ! [[ "$CORES" =~ ^[0-9]+$ ]] || [[ "$CORES" -le 0 ]]; then
echo "Ошибка ввода, введите положительное значение."
exit 1
fi
HOST="127.0.0.1"
TIME="600"
# Создаем базу данных
pgbench --username=admin -h "${HOST}" test -i -s 10000
THREADS=(1 2 $(echo "scale=0; $CORES * 20 / 100" | bc -l) \
$(echo "scale=0; $CORES * 40 / 100" | bc -l) \
$(echo "scale=0; $CORES * 60 / 100" | bc -l) \
$(echo "scale=0; $CORES * 80 / 100" | bc -l) \
$(echo "scale=0; $CORES * 99 / 100" | bc -l))
USERS=()
for THREAD in "${THREADS[@]}"
do
USER=$((THREAD * 2))
USERS+=($USER)
done
FILE=test.txt
# Запускаем тесты с одним и двумя потоками
for i in {0..1}
do
PARAM="-j ${THREADS[$i]} -c ${USERS[$i]}"
echo "pgbench --username=admin -h ${HOST} test ${PARAM} -T ${TIME}" >> "${FILE}"
pgbench --username=admin -h "${HOST}" test "${PARAM}" -T "${TIME}" >> "${FILE}"
echo "pgbench --username=admin -h ${HOST} test ${PARAM} -S -T ${TIME}" >> "${FILE}"
pgbench --username=admin -h "${HOST}" test "${PARAM}" -S -T "${TIME}" >> "${FILE}"
echo "pgbench --username=admin -h ${HOST} test ${PARAM} -N -T ${TIME}" >> "${FILE}"
pgbench --username=admin -h "${HOST}" test "${PARAM}" -N -T "${TIME}" >> "${FILE}"
done
# Запускаем тесты с 20%, 40%, 60%, 80%, 99% потоков
for i in {2..6}
do
PARAM="-j ${THREADS[$i]} -c ${USERS[$i]}"
echo "pgbench --username=admin -h ${HOST} test ${PARAM} -T ${TIME}" >> "${FILE}"
pgbench --username=admin -h "${HOST}" test "${PARAM}" -T "${TIME}" >> "${FILE}"
echo "pgbench --username=admin -h ${HOST} test ${PARAM} -S -T ${TIME}" >> "${FILE}"
pgbench --username=admin -h "${HOST}" test "${PARAM}" -S -T "${TIME}" >> "${FILE}"
echo "pgbench --username=admin -h ${HOST} test ${PARAM} -N -T ${TIME}" >> "${FILE}"
pgbench --username=admin -h "${HOST}" test "${PARAM}" -N -T "${TIME}" >> "${FILE}"
done
exit 0
Изначально на первых тестах скрипт выглядел так:
#!/bin/bash
pgbench --username=admin -h 127.0.0.1 test -i -s 10000
FILE=test.txt
for PARAM in "-c 2 -j 1" "-c 4 -j 2" "-c 52 -j 26" "-c 104 -j 52" "-c 154 -j 77" "-c 206 -j 103" "-c 254 -j 127"
do
##TPC-B (sort of)
echo "pgbench --username=admin -h 127.0.0.1 test $PARAM -T 600" >> $FILE
pgbench --username=admin -h 127.0.0.1 test $PARAM -T 600 >> $FILE
##select only
echo "pgbench --username=admin -h 127.0.0.1 test $PARAM -S -T 600" >> $FILE
pgbench --username=admin -h 127.0.0.1 test $PARAM -S -T 600 >> $FILE
##simple update
echo "pgbench --username=admin -h 127.0.0.1 test $PARAM -N -T 600" >> $FILE
pgbench --username=admin -h 127.0.0.1 test $PARAM -N -T 600 >> $FILE
done
exit 0
В скрипте есть один нюанс: при тестировании на ARM-платформе дистрибутив Ubuntu 22.10 не содержит предустановленного пакета bc. Его нужно установить — без него работать не будет.
Также в скрипте описаны ключи — режимы тестирования pgbench: -Т; -S -T; -N -T:
- -Т — смешанные SQL-запросы (Select, Update),
- -S -T — упорядоченная последовательность SQL-запросов (Select only),
- -N -T — режим простых SQL-запросов (Update only).
Результаты мы получим по каждому из режимов.
Автоматизация теста Sysbench
Тут скрипт похож на то, что я написал для предыдущего теста, но есть отличия. Пароль нужно указывать в скрипте выполнения, поэтому добавил переменную passwd. Также для удобства добавил переменные TIME, HOST, PORT, DB, USER, чтобы не менять их в каждой строчке.
Определяем количество потоков, исходя из поставленных условий: 1 и 2 потока — не изменяемый параметр, далее — 20, 40, 60, 80, 99 процентов от максимального количества потоков.
#!/bin/bash
FILE=sysbench.txt
# Запрашиваем максимальное количество потоков
echo "Введите максимальное количество потоков:"
read MAX_THREADS
# Задаем параметры подключения к БД и время тестирования
USER=admin
HOST=127.0.0.1
PORT=5432
PASWD=passwd
DB=test
TIME=600
# Запускаем тесты на 1 и 2 потоках
for THREADS in 1 2
do
for TEST in 'oltp_read_only.lua' 'oltp_write_only.lua' 'oltp_read_write.lua'
do
sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS "/usr/share/sysbench/$TEST" prepare
echo "sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS \"/usr/share/sysbench/$TEST\"" >> $FILE
sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS "/usr/share/sysbench/$TEST" run >> $FILE
sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS "/usr/share/sysbench/$TEST" cleanup
done
done
# Определяем количество потоков для каждого теста
for i in 20 40 60 80 99
do
# Вычисляем количество потоков для текущего теста
THREADS=$(echo "scale=0; $MAX_THREADS*$i/100" | bc)
for TEST in 'oltp_read_only.lua' 'oltp_write_only.lua' 'oltp_read_write.lua'
do
# Запускаем тест
sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS "/usr/share/sysbench/$TEST" prepare
echo "sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS \"/usr/share/sysbench/$TEST\"" >> $FILE
sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS "/usr/share/sysbench/$TEST" run >> $FILE
sysbench --db-driver=pgsql --pgsql-host=$HOST --pgsql-port=$PORT --pgsql-user=$USER --pgsql-password=$PASWD --pgsql-db=$DB --time=$TIME --threads=$THREADS "/usr/share/sysbench/$TEST" cleanup
done
done
Тест mysqlslap
Автоматизацию теста mysqlslap не делал, поскольку не уверен, что буду использовать его в дальнейшем.
Скрипт выполнения такой:
#!/bin/bash
FILE=mysqlslap.txt
for THREADS in 1 2 26 52 77 103 127
do
mysqlslap --auto-generate-sql --concurrency=$THREADS --iterations=1 --number-of-queries=100000 >> $FILE
done
exit 0
В данном тесте указывается, на какое количество клиентов разбивается количество запросов (queries). Метрика теста — время выполнения запросов.
Парсинг результатов в Google таблицу
После каждого теста на выходе получался файл .txt с большим количеством текста, в котором зарыты нужные нам числа и результаты.
#!/usr/bin/awk -f
BEGIN {
# Параметры таблицы, выравнивание
client_width = 10
thread_width = 12
tps_width = 20
trans_width = 20
latency_width = 20
init_conn_width = 25
# Вывод столбцов
printf "%-s%-s%-s%-s%-s%-s\n", "Num Clients", "Num Threads", "TPS", "Num Transactions", "Latency Average", "Initial Connection Time"
}
# Извлечение нужных значений из строки запуска pgbench
match($0, /-j\s+([0-9]+)/, arr) {
num_clients = arr[1]
}
match($0, /-c\s+([0-9]+)/, arr) {
num_threads = arr[1]
}
# Поиск по строкам нужных значений
/number of transactions actually processed:/ {
num_transactions = $NF
}
/latency average/ {
latency_average = $(NF-1) " " $NF
}
/initial connection time.*[0-9]+\.[0-9]+/ {
# Извлечение только числовых значений
for (i = 1; i <= NF; i++) {
if ($i ~ /^[0-9]+\.[0-9]+$/) {
init_conn_time = $i " " $(i+1)
break
}
}
}
/tps/ {
# Извлечение всех знаков (if present)
for (i = 1; i <= NF; i++) {
if ($i == "tps") {
tps = $(i+2)
gsub(/[()]/, "", tps) # Удаление TPS знач
break
}
}
# Вывод
printf "%-*s%-*s%-*s%-*s%-*s%-*s\n", client_width, num_clients, thread_width, num_threads, tps_width, tps, trans_width, num_transactions, latency_width, latency_average, init_conn_width, init_conn_time
}
В результате выполнения скрипта выдаются колонки в терминале с нужными данными. Остается только скопировать и вставить.
Результаты тестирования
Готовьтесь — ниже очень много диаграмм с результатами. Эти я создал в тех же Google таблицах, но, возможно, в будущем посмотрю на более удобный и ясный инструмент визуализации данных — например, на Apache superset.

Для экономии места в диаграммах указаны названия конфигов, а не процессоры. Вспомнить комплектацию того или иного сервера можно в таблице в начале текста.
Результаты pgbench postgresql
Показатели измеряли в TPS — транзакциях в секунду (это значение показывает ось слева). На нижней оси обозначено количество потоков. Каждый столбик диаграммы показывает, сколько транзакций в секунду выполнила платформа на определенном количестве потоков.
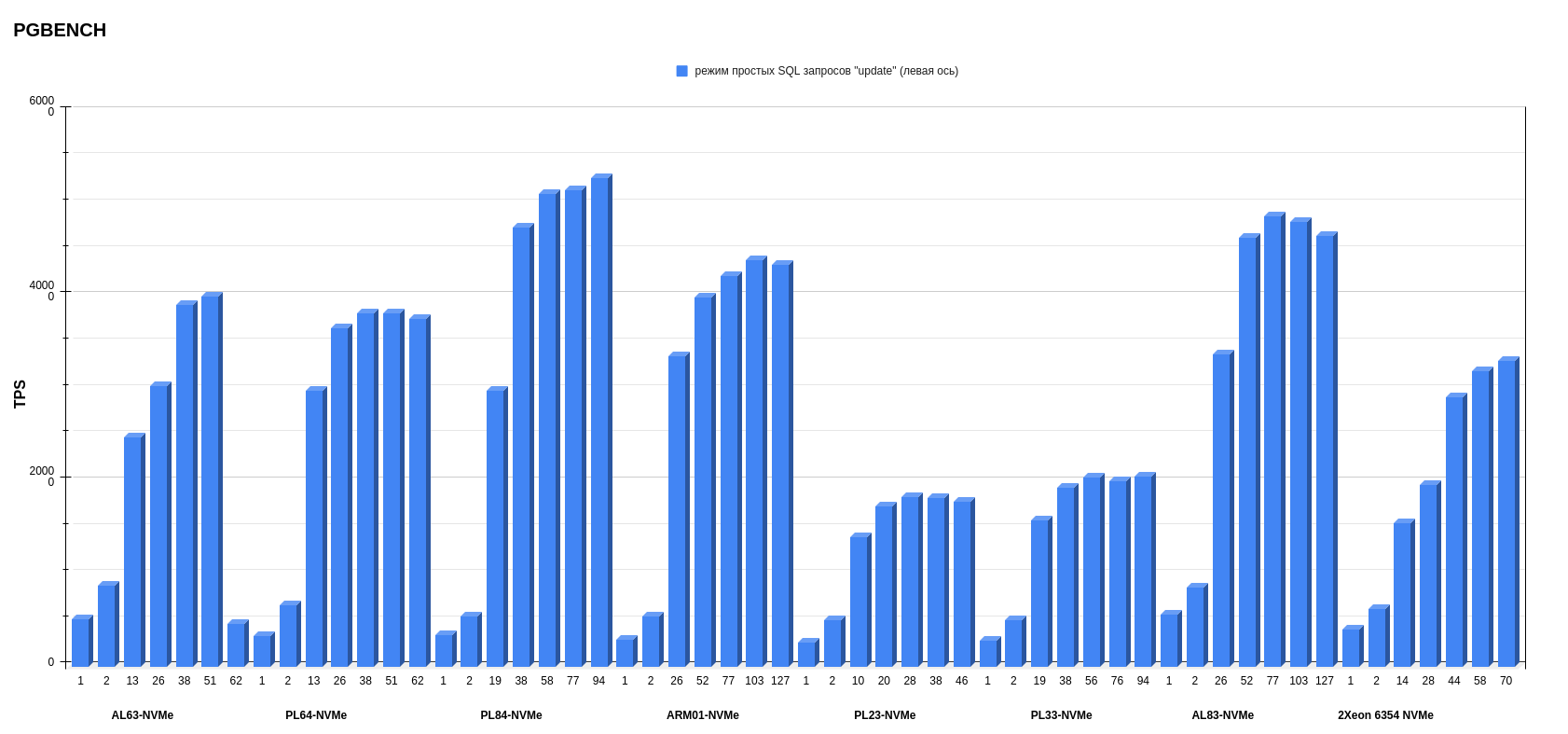
Режим простых SQL-запросов.
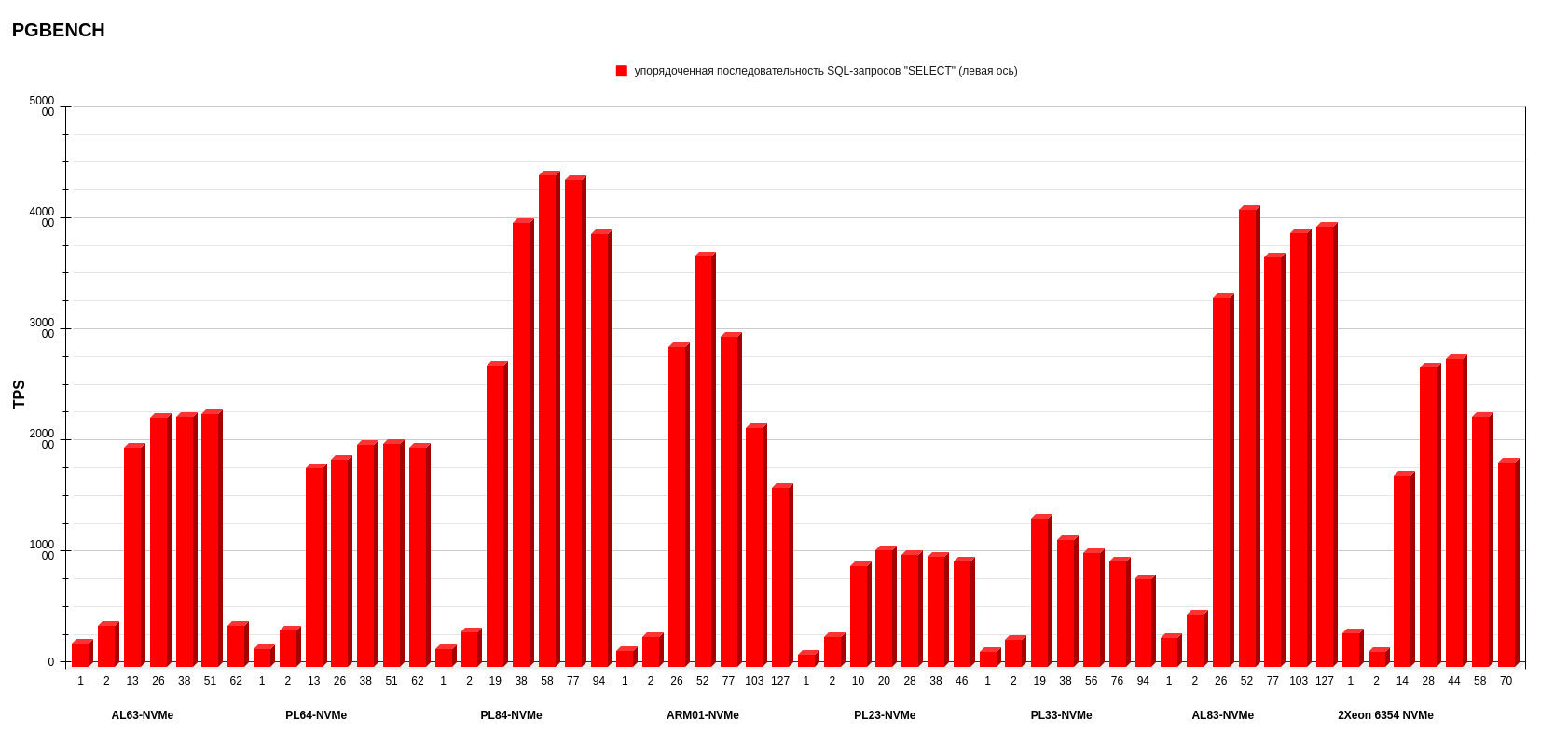
Упорядоченная последовательность SQL-запросов.
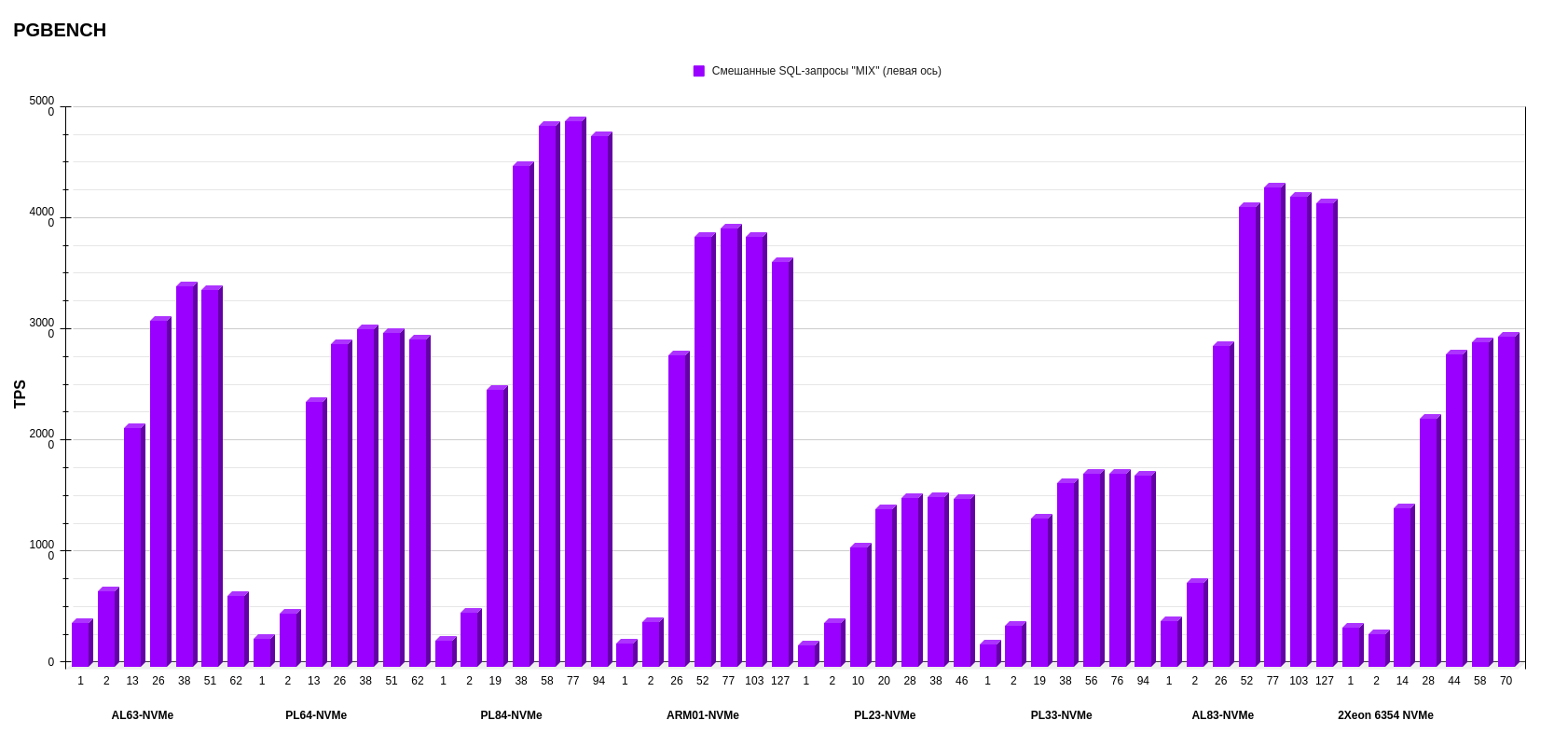
Смешанные SQL-запросы.
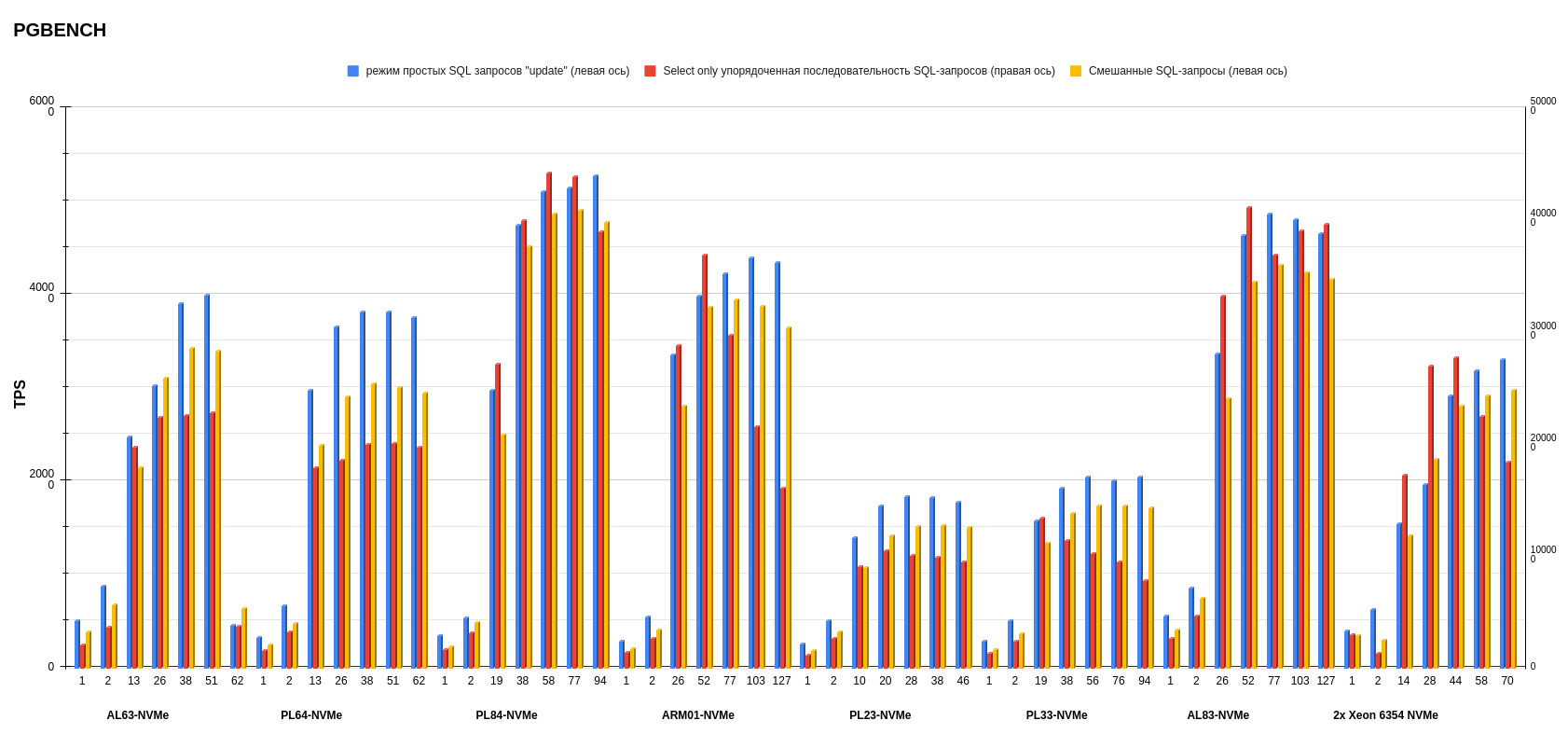
На втором месте по среднему результату — конфигурация AL83-NVME-10GE c двумя процессорами AMD EPYC 7513.
А на первом месте с небольшим отрывом от AMD (количество потоков меньше, чем у предыдущего конфига AL83) разместился PL84-NVMe c двумя процессорами Intel Xeon Gold 6336Y.
Внимательный читатель заметит, что у конфигурации ARM в режиме запросов к БД «Select only» показания TPS при увеличении числа потоков падает, чего нет в графиках x86-платформ. У меня есть несколько предположений, в чем может быть причина, — в будущем буду их изучать (повторю, что это лишь гипотезы):
- Баланс между энергопотреблением и производительностью. ARM-процессоры традиционно ориентированы на энергоэффективность и более низкое энергопотребление, что может привести к компромиссу в производительности, особенно при большой нагрузке. В ARM-платформе есть параметр, отвечающий за снижение тактовой частоты процессора для обеспечения энергоэффективности. Напомню, что, поскольку мы использовали дефолтные настройки, мы его не отключали.
- Параллелизм. x86 имеет многопоточность на уровне инструкций (instruction-level parallelism, ILP), что позволяет выполнять несколько инструкций одновременно. ARM, в свою очередь, имеет конвейер команд, который оптимизирован по-другому. Это может привести к разнице в производительности, особенно когда количество потоков увеличивается. Мы видим, как при 26 потоках ARM-процессор показывает примерно такие же результаты, как 2 × Intel Xeon Gold 6336Y при 19 потоках. То есть ARM пытается брать количеством ядер (т.к. у ARM 1 ядро = 1 поток), тогда как x86 берет многопоточностью.
- Генерация нагрузки (запросов к БД) происходила на том же сервере, где находилась тестируемая БД.
В любом случае можно говорить о показателях ARM-платформы как о потенциально перспективных и выгодных. Опять же, поскольку в данных тестах используется один процессор.
Результаты sysbench postgresql
Здесь мы посмотрели TPS в трех режимах — READ, WRITE, MIX. Графики довольно сильно отличаются друг от друга, поэтому рассмотрим их по отдельности.
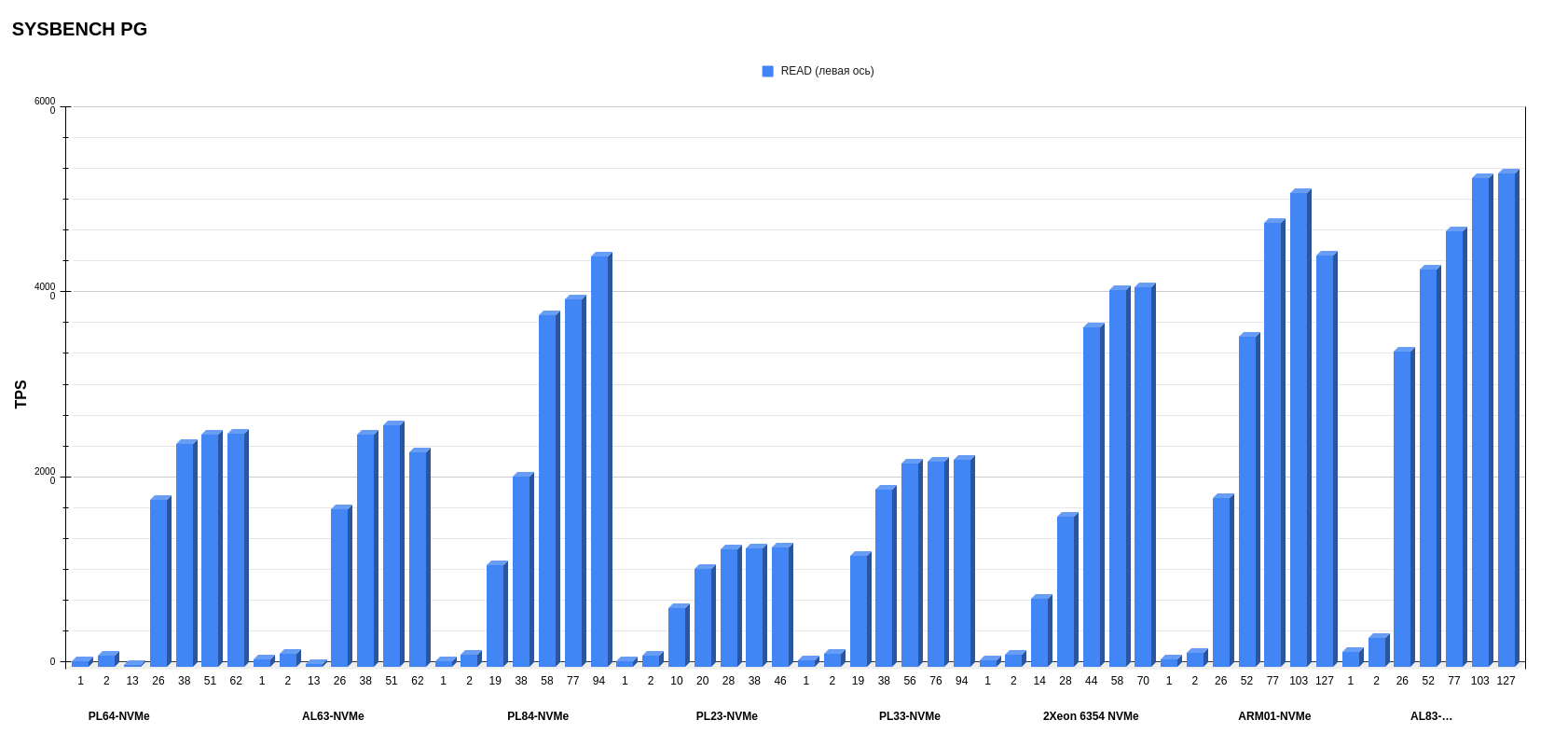
Режим READ.
Тут интересный момент с ARM-процессором. Видно, что у всех x86-конфигураций при достижении максимального количества потоков сохраняются стабильные значения, в то время как у ARM значительная просадка при 127 потоках. Здесь может быть актуальна причина, отмеченная ранее: возможно, ARM не может выполнять несколько инструкций одновременно на одном ядре.
В Sysbench в операциях чтения лидирует AL83 с AMD EPYC 7513. Второе место у сервера с Ampere Altra Max M128-30, а третье место делят между собой кастомный конфиг с Intel Xeon 6354 и PL84 с Intel Xeon Gold 6336Y.
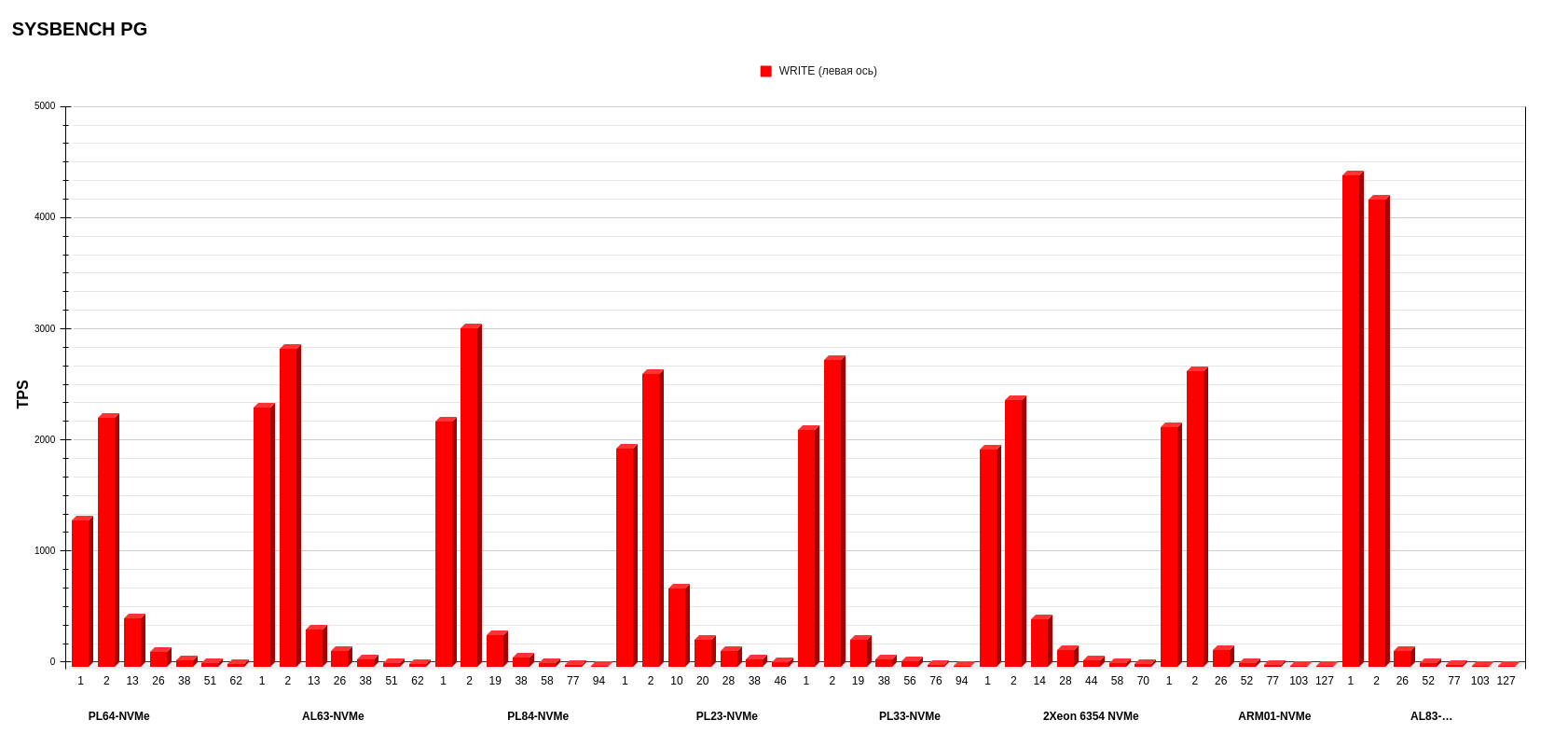
Режим WRITE.
На диаграмме видно, что при увеличении количества потоков происходит деградация производительности. Здесь причина — в дефолтных настройках PostgreSQL, при которых запись Update ведется напрямую на диск.
По операциям записи есть победитель со значительным отрывом — это AL83 с AMD EPYC 7513. Второе — у PL84 с Intel Xeon Gold 6336Y, а третье — у AL63 с AMD EPYC 7343. В данном тесте конфиги, кроме лидера, показали очень близкие результаты.
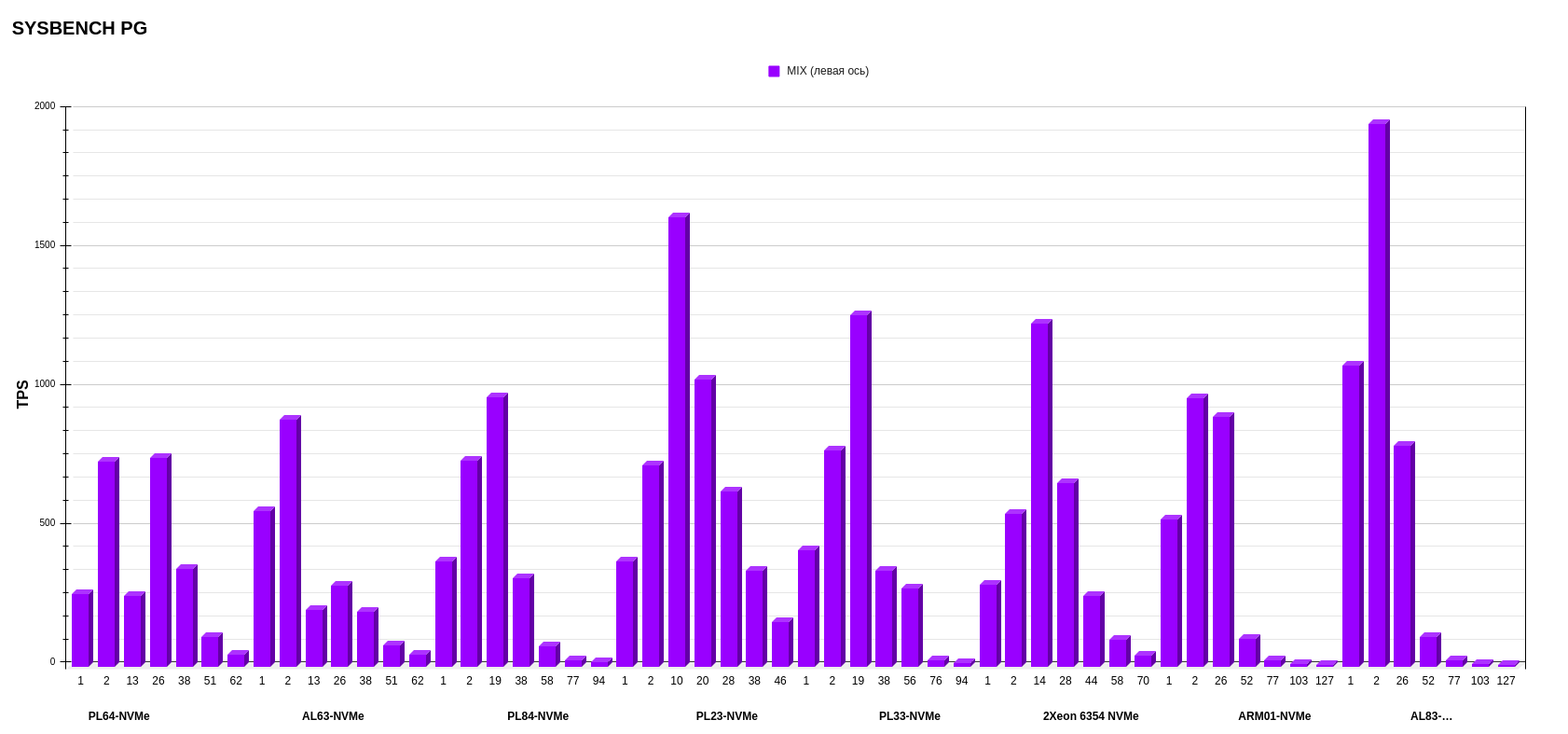
Режим MIX.
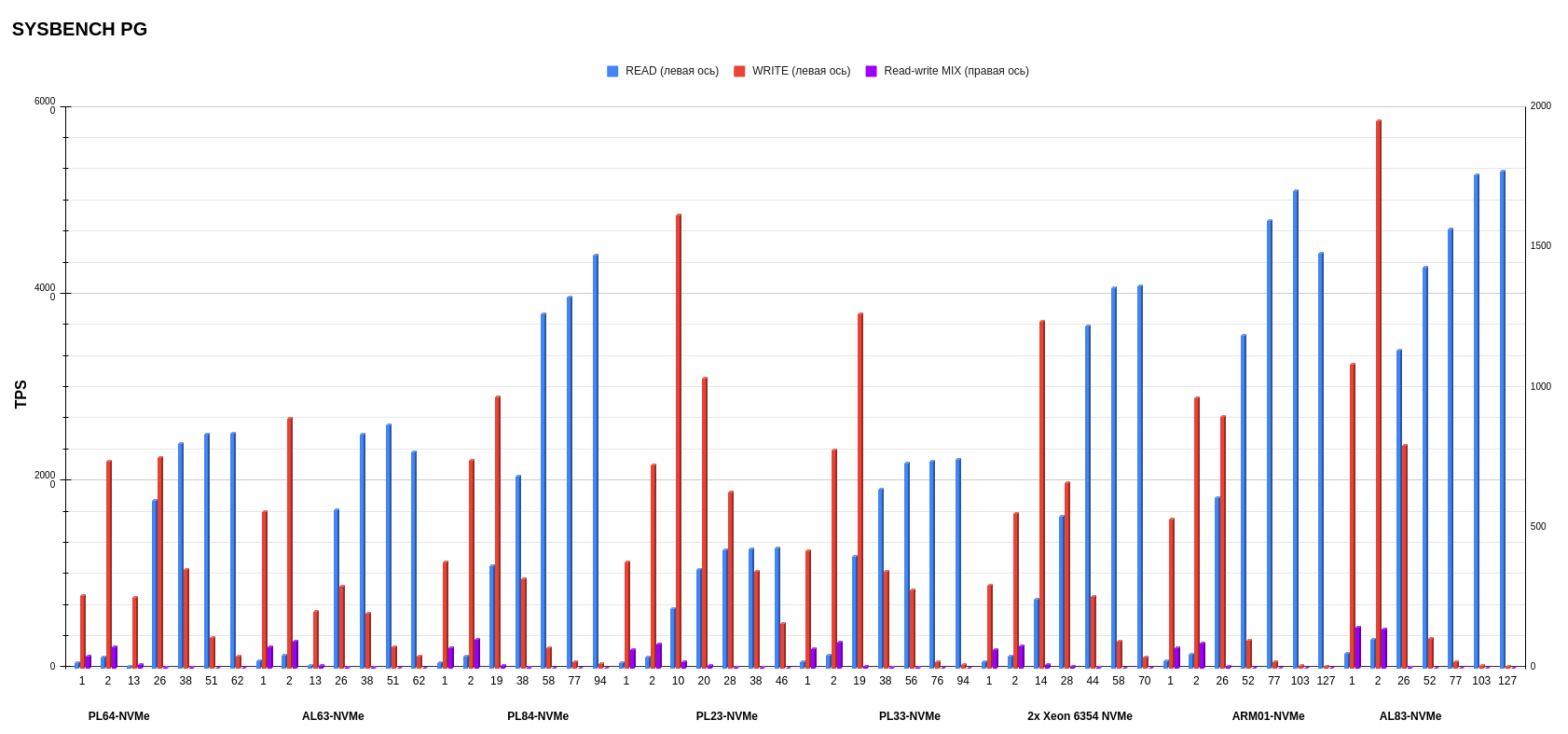
В MIX-режиме результаты интересные. Тут лучше всего себя показал все тот же AL83 с AMD EPYC 7513. А вот второе и третье место заняли PL23 c Intel Xeon Silver 4214R и PL33 c Intel Xeon Gold 6240R, что довольно любопытно, так как это процессоры второго поколения. Предположу, что микроархитектура процессоров второго поколения может быть оптимизирована таким образом, что она лучше справляется с равномерным распределением операций чтения и записи. В этом случае процессоры второго поколения могут демонстрировать лучшую производительность, если рабочая нагрузка хорошо сбалансирована между операциями чтения и записи.
Результаты MYSQL sysbench
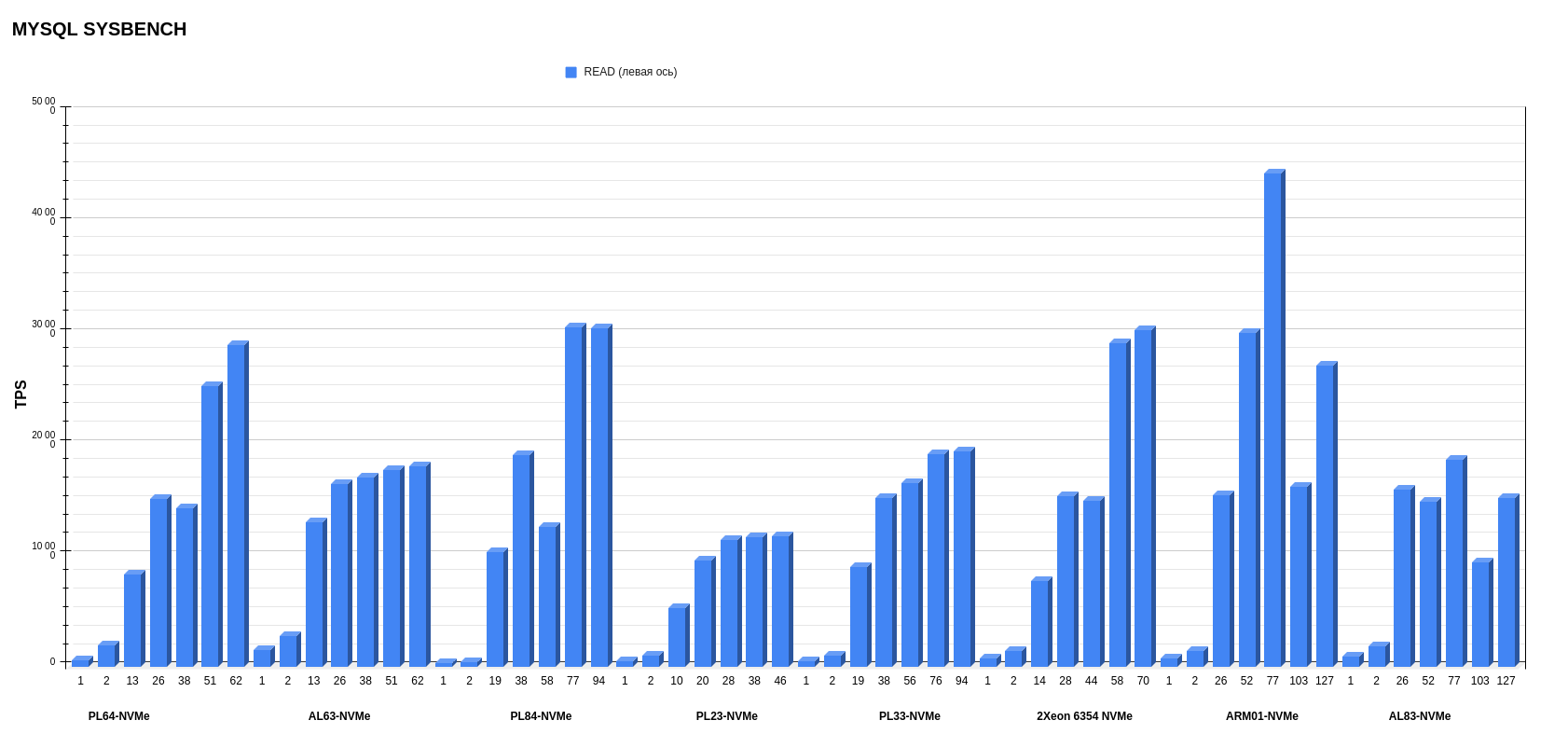
Режим READ.
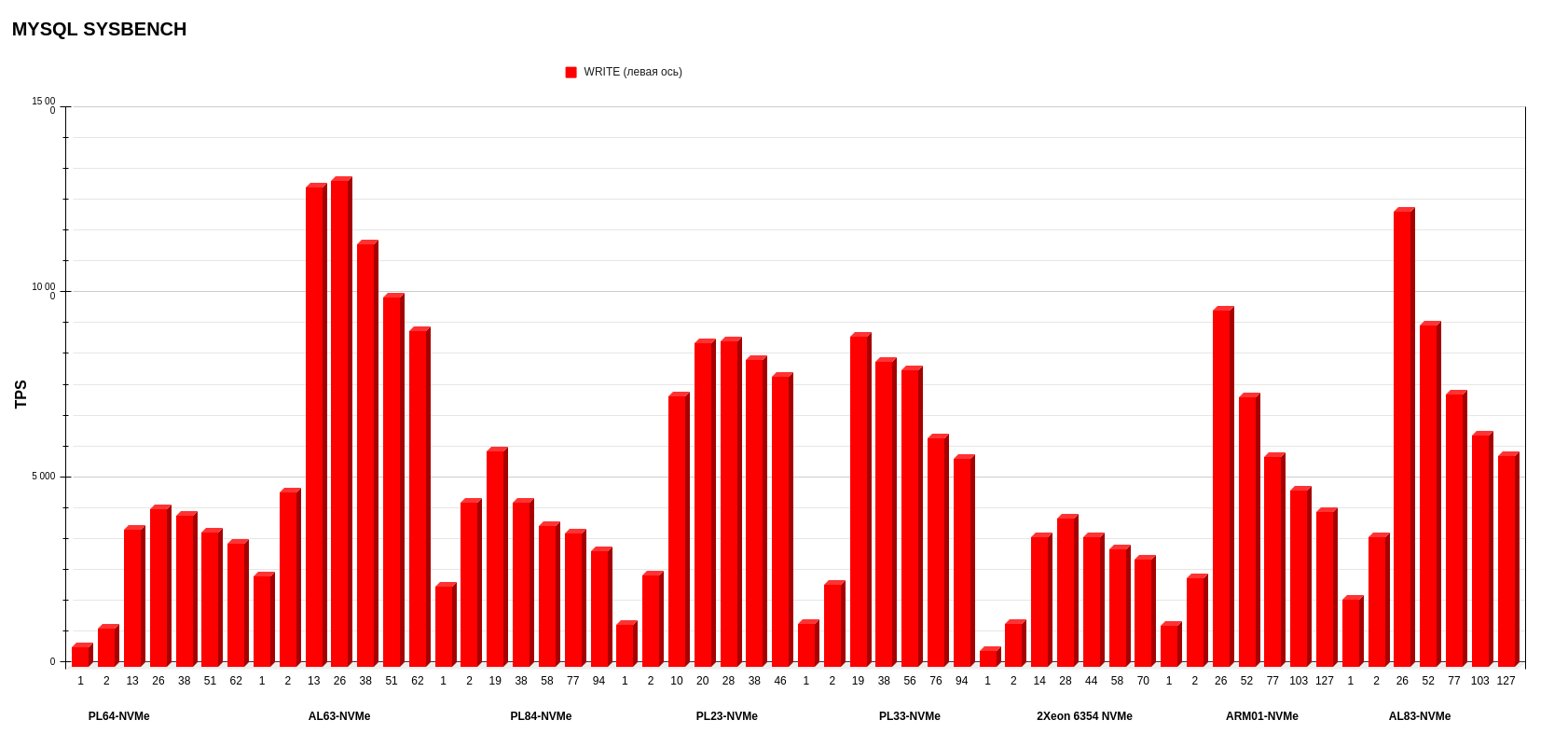
Режим WRITE.
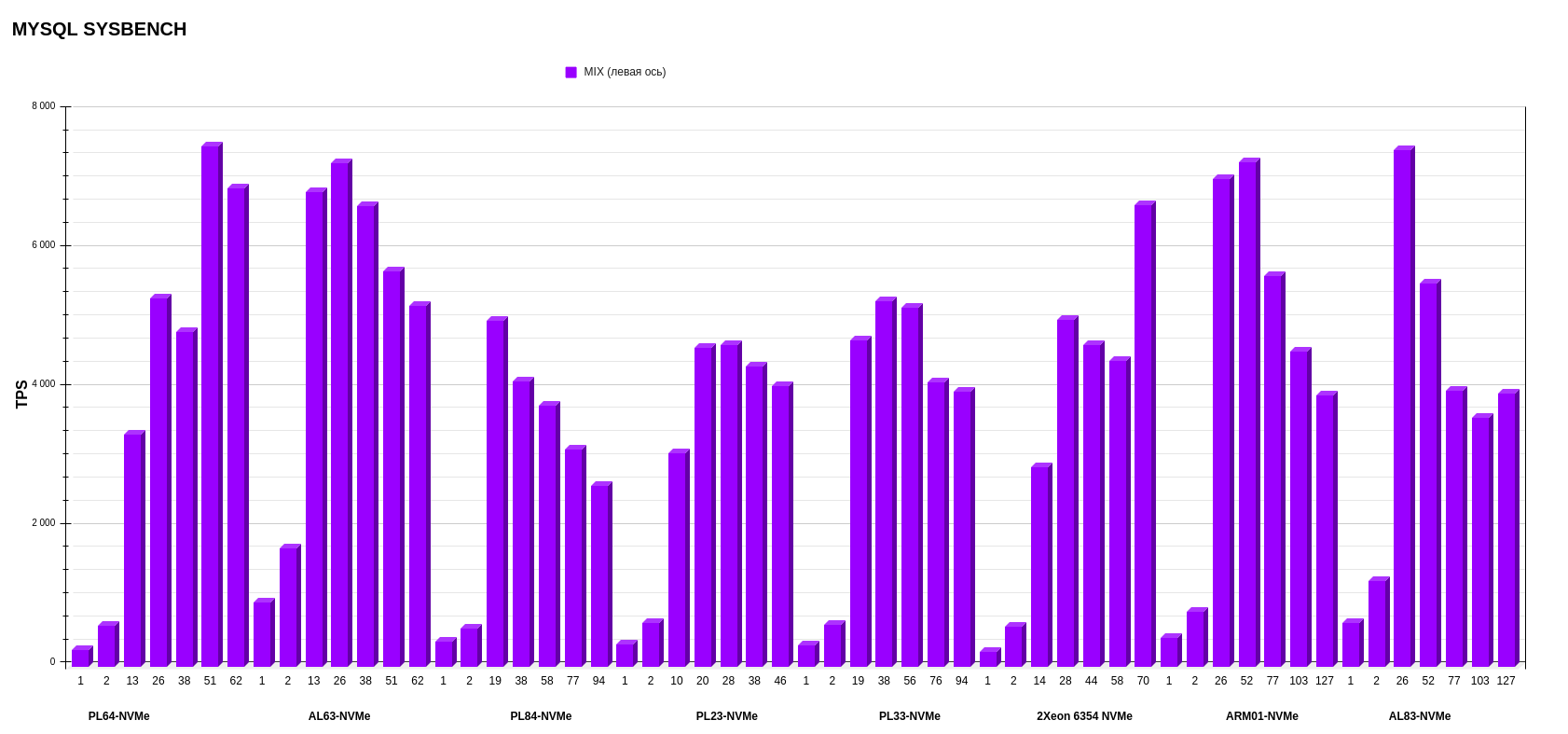
Режим MIX.
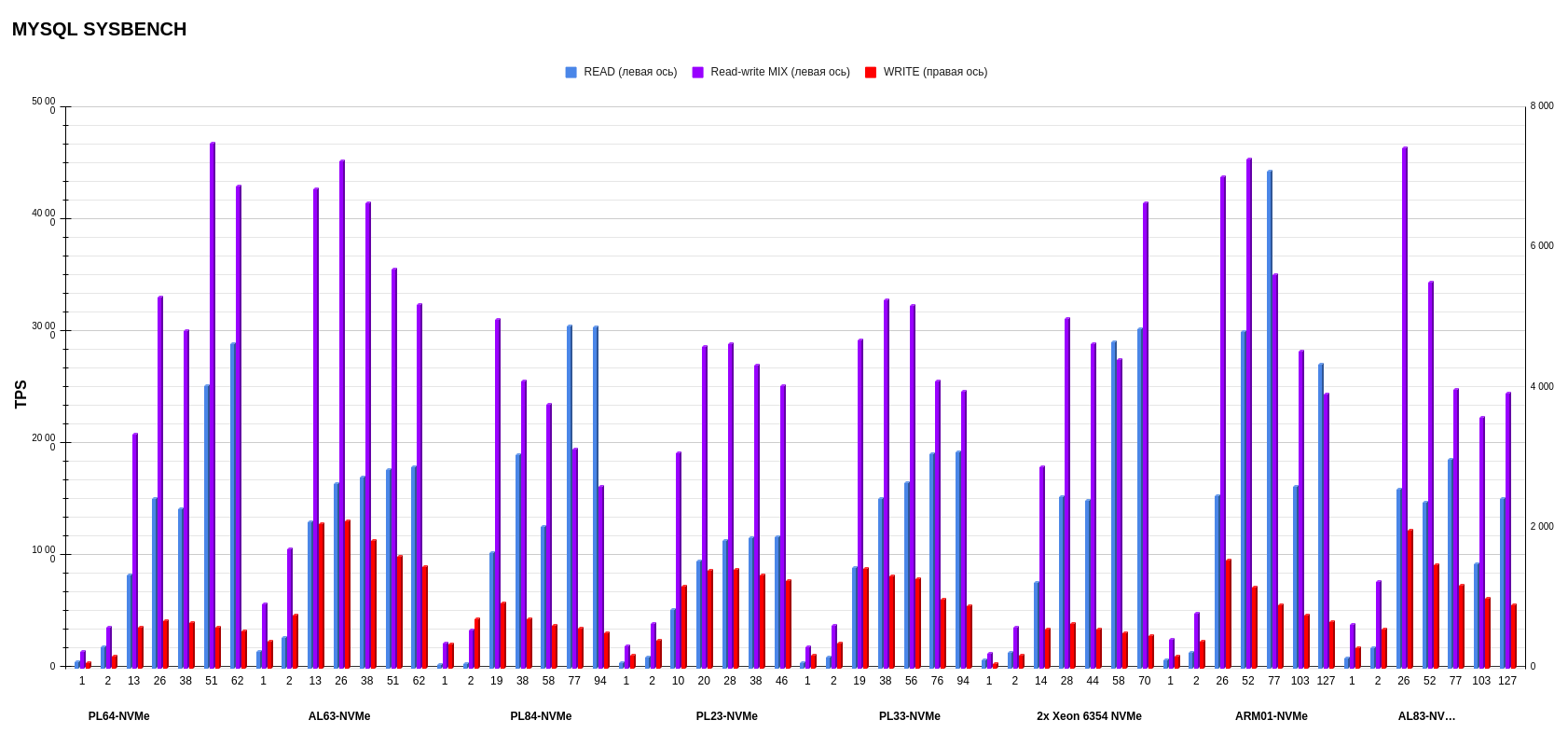
Если смотреть верхнеуровнево, по средним показателям, вперед вырываются ARM01 с Ampere Altra Max M128-30 и AL63 с AMD EPYC 7343. Но, если детально рассматривать каждую операцию, картина другая: более стабильную работу по записи показывает AL63, тогда как ARM01 значительно проседает при увеличении потоков.
Результаты на уровне показывают PL23 с Intel Xeon Silver 4214R и PL33 с Intel Xeon Gold 6240R. Эти процессоры второго поколения вырвались на уровень процессоров третьего поколения в смешанном режиме операций на чтение-запись. А в режиме записи обгоняют по показателям PL84 с Intel Xeon Gold 6336Y и Intel Xeon 6354.
Результаты MYSQLSLAP
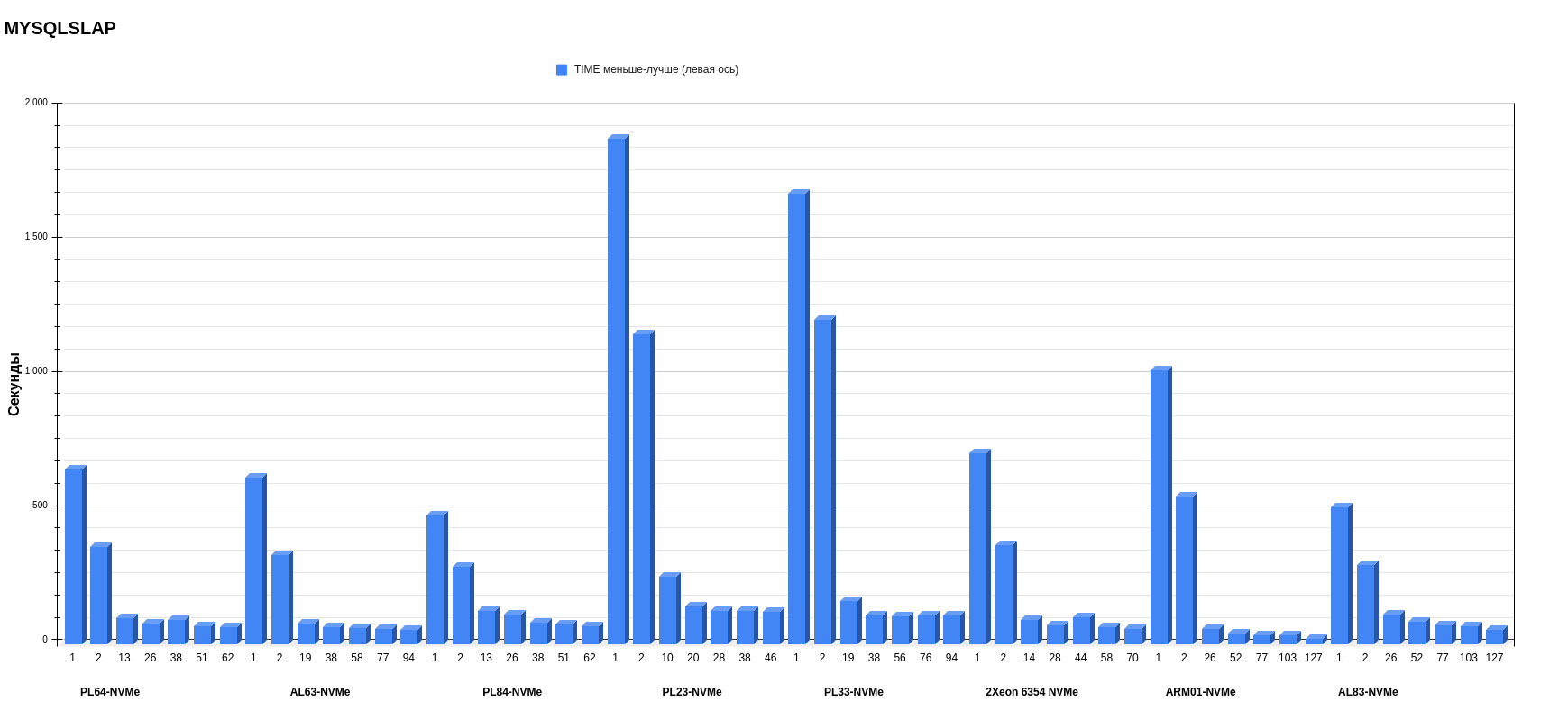
Хуже всего себя показали серверы с процессорами второго поколения — особенного в режимах 1 и 2 потоков. Чтобы определить победителей, стоит выделить две номинации: результаты в 1 и 2 потоков и результаты в многопоточных режимах. В первом случае лучшей платформой стала PL84 c Intel Xeon Gold 6336Y. Во второй категории в многопотоке с хорошим отрывом выигрывает сервер с ARM-процессором — особенно хороши результаты на 127 потоках. Скорее всего, ему на руку играет то, что он разбивает общее количество запросов на большее количество пользователей. Поэтому один пользователь должен выполнить меньшее количество запросов.
Как будет себя вести ARM-платформа с двумя процессорами, выясним в следующих тестах.
Итоги
Производительность баз данных может меняться в зависимости от конфигурации сервера, на котором она находится, и даже от архитектуры процессора в этом сервере. Выбор подходящего процессора и сервера может существенно влиять на производительность баз данных и в конечном итоге — на общую производительность приложений и сервисов.
Какие основные выводы можно сделать после всех тестов:
- Процессоры AMD EPYC 7513 показали лучшую производительность в большинстве тестов, особенно в операциях записи и смешанных сценариях (read/write). Это свидетельствует о сильной многопоточной производительности и оптимизации под рабочие нагрузки баз данных.
- Процессоры Ampere Altra Max M128-30 на ARM-архитектуре продемонстрировали хорошую производительность. Особенно в тесте mysqlslap — во многом благодаря большому количеству ядер и микроархитектурным оптимизациям. Хотя в ряде случаев они проигрывали x86-процессорам — например, в операциях записи и в одном и двух потоках из-за особенностей архитектуры.
- В некоторых тестах процессоры второго поколения Intel Xeon Silver 4214R и Intel Xeon Gold 6240R показали производительность лучше, чем более современные CPU. Это может быть связано с оптимизациями под конкретные рабочие нагрузки и микроархитектурными особенностями.
Допускаю, что некоторые артефакты производительности (например, резкие падения производительности в ряде тестов) могут быть связаны c тем, что тестовая база данных не очень большая и распределение нагрузки между процессорами неравномерное.
Выше мы рассмотрели все тесты по отдельности, но в итогах я собрал результаты работы конфигураций в совокупности. Для этого подсчитал количество транзакций по всем потокам, не разделяя показатели по одному и двум потокам. Также добавил стоимость аренды данных серверов, чтобы все заинтересованные понимали, что им выгоднее брать и для каких целей.
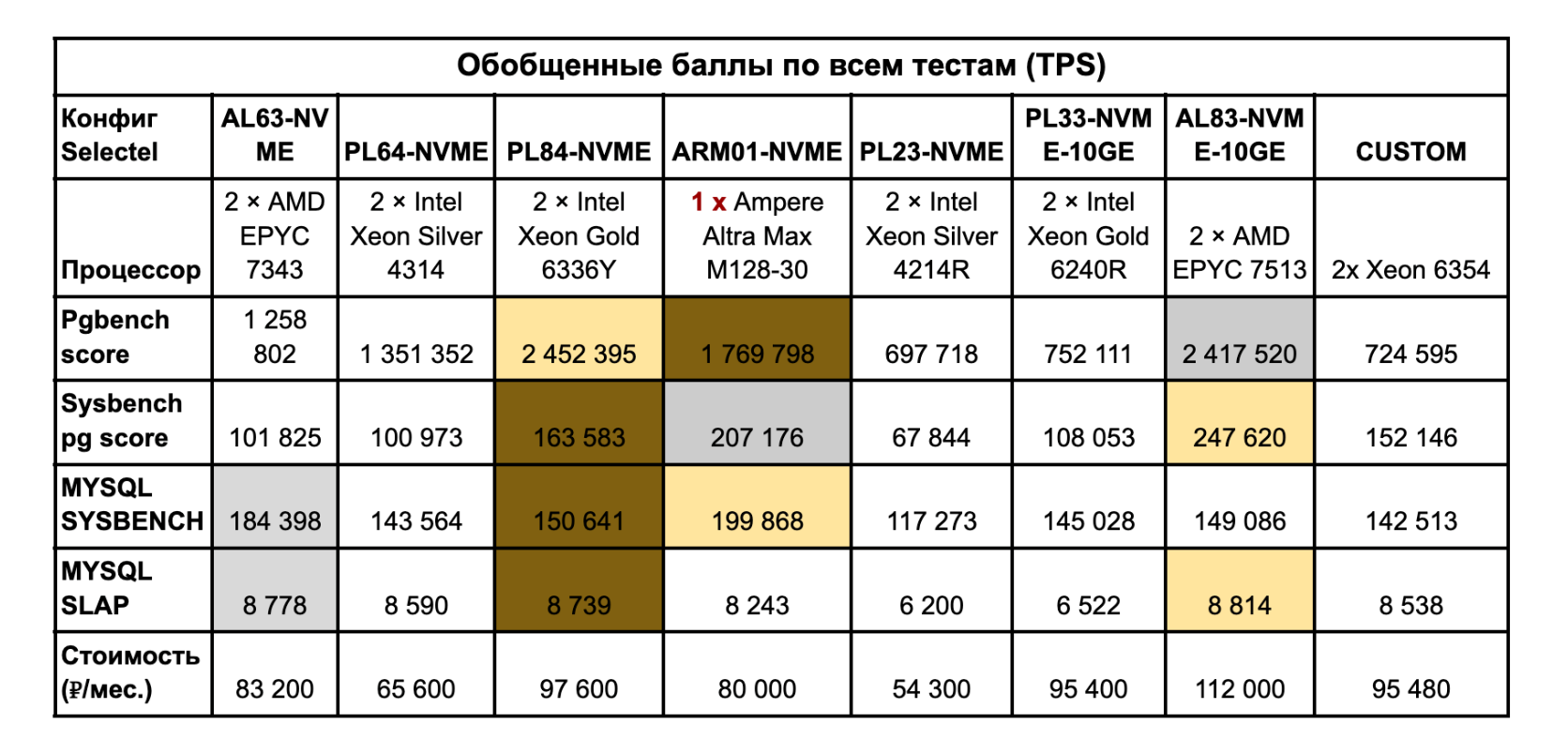
Желтый цвет (золото) — первое место. Серый (серебро) — второе. Коричневый (бронза) — третье. Обратите внимание, что в тестах MySQL SLAP данные инверсированы, это сделано специально для удобства расчетов.
Итак, мы подсчитали общие «баллы» (TPS) по каждому бенчмарку БД. Таблица поможет сориентироваться, для каких целей выгоднее брать сервер — можно даже посчитать экономику под конкретную задачу или проект. «Баллы» в таблице подсчитаны вне зависимости от количества потоков. Но, как мы поняли из диаграмм и выводов по тестам, некоторые платформы показывают себя лучше в одном и двух потоках, а некоторые — в многопотоке.
Теперь обозначим тройку лидеров:
Первое место. Явный фаворит — AL83-NVME-10GE с двумя процессорами AMD EPYC 7513. Да, этому серверу не хватило баллов, чтобы стать лидером в трех тестах, и его немного обогнала платформа PL84-NVME в тесте pgbench. Но результаты все равно очень достойные. Единственный минус — сервер не самый бюджетный из-за топового железа и дополнительной сетевой карты на 10 Гбит/c.
Второе место. Здесь у нас наш «чужак» — ARM01-NVME с одним процессором Ampere Altra Max M128-30. У этого сервера первое место в тесте MySQL sysbench, второй результат в PostgreSQL sysbench и третий результат — в pgbench. Конфиг может стать хорошим компромиссом между стоимостью и производительностью: однопроцессорная система такой стоимости составляет хорошую конкуренцию закоренелым лидерам рынка.
Третье место. Третий результат у сервера PL84-NVME с двумя процессорами Intel Xeon Gold 6336Y. На его счету первенство в тесте pgbench. По всем остальным тестам конфиг стабильно занимал третий результат по общим баллам бенчмарков.
Вот такие результаты, которые могут ответить на вопрос, на что обращать внимание при выборе платформы для проекта под базы данных — PostgreSQL и MySQL. Процессор — самый важный компонент в данном вопросе, и, как показывают тесты ARM, их не обязательно должно быть много. Также производительная платформа не всегда должна быть самой дорогой, и это положительный момент для пользователей.
В следующих тестах я расскажу, как покажут себя другие конфигурации, а также протестирую сервер с двумя процессорами Ampere Altra Max M128-30 на ARM-архитектуре. Подписывайтесь, чтобы не пропустить обновления.
Комментарии (40)

IDDQDesnik
08.06.2023 11:17+2PostgreSQL взял самую свежую — 14 версию.
На сегодня актуальная версия 15.3.

Maksvelis Автор
08.06.2023 11:17-1А под АРМ?)
IDDQDesnik
08.06.2023 11:17Maksvelis Автор
08.06.2023 11:17+1Версия postgresql 15.3 не поддерживается в Ubuntu 22.10 под arm

Melkij
08.06.2023 11:17+2ну, на самом деле действительно нетипично на сервере ставить систему, которой осталось пара недель до EOL. Вообще не LTS убунта на сервере настораживает.
Maksvelis Автор
08.06.2023 11:17Это было обусловлено работой "железа" на АРМ платформе. В проде конечно же используется LTS.

CCNPengineer
08.06.2023 11:17если я правильно понял вы сравниваете 1 ядро из 128 Ampere и 1 из 32 Xeon
Maksvelis Автор
08.06.2023 11:171, 2, потоков и так далее
CCNPengineer
08.06.2023 11:171 ядро и 2 потока Ampere сравниваете с 1 ядром и 2 потока Xeon ?
Maksvelis Автор
08.06.2023 11:17Нет, конкретно сравниваются именно потоки, 1 поток на Ampere и 1 поток на Intel-AMD.

event1
08.06.2023 11:17+3мне кажется просто выдавать места в зависимости от того, у какой конфигурации больше золота не вполне корректно. Скажем в тесте mysql slap разница между золотом и бронзой — 1%, в sysbench pg score — 30%. Возможно было бы корректней привести к единой шкале и объявить победителем того, у кого больше баллов в сумме или на 100Р
Maksvelis Автор
08.06.2023 11:17+1Спасибо, надо обдумать такой и другие варианты, это так скажем beta тестирование думаю мы сможем его улучшить.
IDDQDesnik
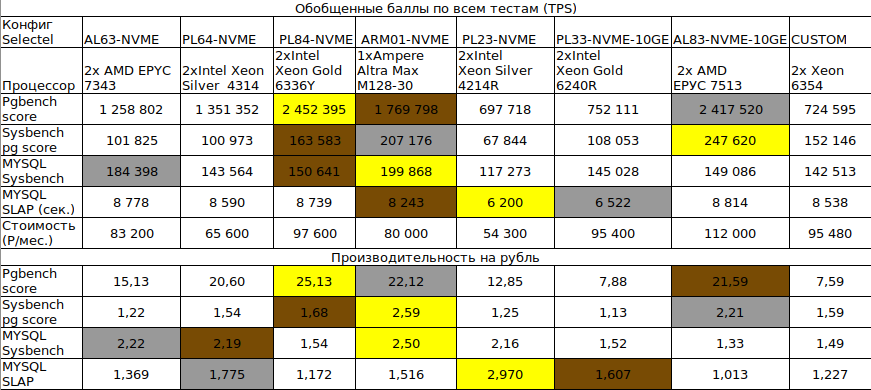
08.06.2023 11:17+2В итоговой таблице в тесте MySQL SLAP все наоборот.
Maksvelis Автор
08.06.2023 11:17Спасибо, за внимательность но там инверсированные данные, сделано специально для удобства расчетов. Если смотреть на график(диаграмму) то да там все верно чем меньше времени тем лучше. Здесь отнято общее количество(сумма) затраченного времени от 10000



vvzvlad
08.06.2023 11:17Интересно было бы сравнить на единицу стоимости
CCNPengineer
08.06.2023 11:17думаю придется сравнить 8 ядер Ampere против 1 Intel
vvzvlad
08.06.2023 11:17+2Причем тут ядра? Меня в сервере интересует производительность и то, сколько он стоит. Вот и я хочу узнать, сколько один балл стоит у того и у другого сервера. Сколько там ядер и сколько каждое ядро может перемолоть данные — мне глубоко вторично, пока у меня не появляется специфичных задач, в которых эти различия проявляются.
CCNPengineer
08.06.2023 11:17на сервере Ampere 128 ядер а на сервере intel 32 ядра и Ampere стоит дешевле на порядок думаю. и вы ставите по 32 виртуалки на каждый сервер. получается 4 у виртуалкт на Ampere и 1 ядро Intel. нет?
CCNPengineer
08.06.2023 11:17если я арендую виртуалку Oracle Cloud то там цена вроде как близкая на 4 ядра Ampere и 1 Intel

vitaly_il1
08.06.2023 11:17+1Я бы посоветовал посмотреть на оформление подобных отчетов тут https://www.percona.com/blog/comparing-graviton-arm-performance-to-intel-and-amd-for-mysql-part-3/ - по-моему, они намного легче читаются и "смотрятся".

raamid
08.06.2023 11:17+1было бы интересно кроме производительности сравнить энергопотребление и стоимость решений на данных процессорах.

ciuafm
08.06.2023 11:17Поддержу. Без графиков суммарная/средняя производительность на ватт и на доллар стоимости (можно добавить стоимость аренды если она сильно отличается) статья просто исходные данные для следующей.

Sleuthhound
08.06.2023 11:17+2Бесполезные и ни о чем не говорящие тесты. Во-первых - Настройки БД по умолчанию , Вы с таким же успехом могли запустить эти тесты на железе 2010 года и получили бы такие же попугаи. Во-вторых как можно сравнивать разное по конфигурации железо и ожидать хоть каких то результатов для сравнения? Ну как? Это бред.
Maksvelis Автор
08.06.2023 11:17Критиковать всегда легко, вы можете написать, как надо? без учета других комментариев.

tolik_anabolik
08.06.2023 11:17+2Настройкой PostgreSQL тоже не занимался
Т.е. будут дефолтные shared memory 128Мб и work memory 4Мб? И зачем тогда 256 Гб памяти в системе, для галочки?
посмотрели TPS в трех режимах — READ, WRITE, MIX
Если READ = простые select-ы, то особой работы cpu нет, это чтение из кеша бд или чтение с диска (через кеш ос).
Если WRITE = простые insert / update, то опять же особой работы cpu нет, это запись в wal и работа с буферами.
Работа cpu будет заметна в запросах с сортировками, агрегациями, аналитическими функциями. Потому без примеров данных и примеров запросов, подобные замеры не имеют особого смысла. Да, что-то измерили, но насколько это будет иметь пользу при выборе железа под нагрузку?
Использовал Ubuntu 22.10
А в чем преимущества перед debian, на основе которого ubuntu и собирается? Вы ведь не десктоп сборку накатываете.
Maksvelis Автор
08.06.2023 11:17256 Гб и больше памяти в системе из за того что это фиксированные конфигурации, а не кастом или какая-то сборка.
"Работа cpu будет заметна в запросах с сортировками, агрегациями, аналитическими функциями." Можете пожалуйста привести примеры для замеров производительности?
В Ubuntu в общем-то нет ни каких преимуществ за исключением того что она работала стабильнее на АРМ платформе.

serge-sb
08.06.2023 11:17+1Поправьте КДПВ, пожалуйста. 1 560px × 798px PNG на 1.6Мб это негуманно в ленте. Не говоря уже о том, что использовать PNG для фотографии - странно. Сделайте JPG на пару сотен кило и визуально почти ничего не изменится.
Melkij
ну я понимаю маркетинг, но заявлять что сравниваете производительность ARM и x86 в базах данных, но ставить разные диски участникам? Это же в принципе лишено смысла. В сравнении должен быть минимум различий. Одна и та же физически пара накопителей должна переставляться с сервера на сервер для корректного сравнения возможностей именно CPU, а не дисков.
Аналогично по RAM, впрочем я не вижу у вас scale factor, так что от него значение меньше.
Корректный заголовок "погоняем синтетику на наших тарифах", исключив при этом из теста кастомную конфигурацию.
Maksvelis Автор
Все диски были nvme u.2 одинакового поколения и тесты гонялись на них, по RAM вся была ddr4, разница по частоте минимальна. Не понял где увидели разные диски?
Melkij
Объём разный. Особенно на не топовых по объёму моделях это очень часто означает разницу производительности. Иногда кратную.
Ну например, самсунговый PM9A3 https://semiconductor.samsung.com/ssd/datacenter-ssd/pm9a3/ :
объёмом 960гб - 70к IOPS random write, а 1920гб - уже 130к IOPS. Почти двукратно по спецификации. Что там в реальности - тема отдельного вдумчивого теста.
Maksvelis Автор
Не всегда объем сильно влияет на IOPS вот пример моей синтетики micron 7450 разного объема не вижу сильной разницы....есть еще примеры
https://i.postimg.cc/SxVqd5Xq/2023-06-08-15-19-01.png
Melkij
Не всегда, да. Но вы это не указали в статье. Поискал внимательнее, в описании конфигурации вы вообще никак не упоминаете ни модели дисков, ни что они хотя бы одноклассники. Честно не помню, какие диски вы ставите обычно, для нас вы собирали кастомные конфигурации с оговорёнными конкретными моделями дисков под write intensive базы. Но часто если хостер говорит в описании что поставит абстрактное "2 × 960 ГБ SSD NVMe", то на двух одинаковых заказанных одновременно серверах запросто можно увидеть разные диски (а то и на одном сервере две разные модели, привет hetzner'у).
Различие конфигурации должно устраняться или хотя бы подтверждаться тестом, что оно не является значимым фактором для результата тестирования. У вас есть тест, что различие в объёме RAM 192 и 512гб не имеет значения для результата теста? (а про частоту и тайминги вы тоже не писали в статье)
В частности, вы так же не указали, сколько у вас каналов памяти вообще работает. Для того же восьмиканального 6336Y может быть значимым различие, установлено ли 16 модулей по 16гб или 8 по 32гб или максимальным поддерживаемым объёмом одного DIMM (4 по 64? 2 по 128?).
Maksvelis Автор
Полностью согласен с Вами, все выше сказанное учту в будущем тесте когда буду сравнивать 2 сокетный АРМ сервер с другими. Если же зашла речь об объективности тестирования, хотелось бы узнать Ваше мнение о том как бы вы осуществили тестирование БД и сравнение?) возможно не TPS а запросы сравнивали бы?
Melkij
performance testing is the state of art (c)
железо:
поизучать наработки годов этак 2006-2012 overclokers, fcenter, ixbt и других грандов былых времён по части тестовых стендов и методик сравнения различающегося железа. Особенно методики тестирования i7 920 как первого 3-канальника. Какие шишки на нём собрали, как сглаживали эффекты различия объёма, как тестировали изменение числа каналов памяти.
одну и ту же пару дисков переставлять физически в каждый сервер. В начале короткий fio минут на 5 для детектирования аномалий, различия результатов теста между серверами, понятное дело, должно быть минимально. Если это не так - то искать причину.
желательно использовать одну и ту же коллекцию модулей памяти, с проверкой что они стартуют в одинаковом режиме частота&тайминги среди всех участников
влияние разной конфигурации заполнения слотов памяти - идея для тестирования платформы в отдельности, на самом деле. Это лично мне, кстати, действительно интересно - имеет ли значение число каналов памяти кроме как для увеличения максимального объёма памяти. Максимум памяти в реальности не столь актуален для СУБД, даже террабайт RAM очень мало кто ставит, а вот есть ли смысл просить именно задействовать каналы памяти, а не добить до нужного объёма теми модулями что под рукой нашлись?
на разных платформах соответственно дать настолько близкую разбивку модулей по каналам и сокетам насколько получится, различия задокументировать
контроль температуры и троттлинга на протяжении тестов (для серверов тоже не шутка, да, была у нас машинка в ovh (вполне серверный xeon D-2141I, не десктоп), которая под нагрузкой перегревалась и сбрасывала частоту CPU втрое)
ОС:
NUMA. NUMA это проблема. Честно не знаю как сглаживать его артефакты кроме как переключением всей системы в interleave либо сознательно через numactl тестировать только половину сервера. Особое счастье с EPYC'ами, где по 4 NUMA ноды бывает даже в одном сокете.
cpu performance mode. В реальности под базой данных CPU решает выходить из powersafe и поднимать частоту до рабочей довольно поздно (мой опыт - это разница в полтора раза по графикам среднего времени выполнения запросов от веба). Но главное для теста - непостоянно. performance mode нам тоже не даст постоянную рабочую частоту, но куда лучше чем powersafe.
postgres
ох (с)
сейчас я упомянут даже в списках разработчиков postgresql, но понимания как корректно тестировать его производительность стало даже меньше, чем когда я про него даже не знал =)
pgbech - ну, это pgbench. Чистая синтетика, довольно бесполезная сама по себе. А вот что-то полезное моделировать... (за это DBA не любят детей ораклового маркетинга "у нас 10k tps, справится postgres?" - каких именно транзакций-то?)
Разглядел, кстати, затаивщийся в опциях scale factor, с первого раза не признал его в краткой форме. То есть примерно 150гб рабочий набор у вас на начало теста. Боюсь, что на самом деле протестировали менеджер локов и реализацию spinlock нежели собственно производительность запросов: все операции над данными postgres выполняет только в shared_buffers, а он в дефолте аж целых 128МБ. Получается конкурентные процессы активно дрались между собой, чтобы скопировать из page cache системного в shared buffers нужный именно этому процессу блок (памяти явно достаточно во всех случаях, чтобы реально на диск только писать, но не читать). А вот со spinlock'ами на ARM у postgresql действительно не всё хорошо: https://www.postgresql.org/message-id/flat/CAB10pyamDkTFWU_BVGeEVmkc8%3DEhgCjr6QBk02SCdJtKpHkdFw%40mail.gmail.com Скорей всего так до сих пор не оптимальный машинный код и компилируется в GCC для ARM.
Поскольку тестировать хотим CPU, в меньшей мере память и не хотим диск, то стоит поставить shared_buffers гигабайт в 180 (хотя на сотне процессов уже может отвалиться вот тот конфиг на 192гб памяти с OOM), synchronous_commit = off. huge_pages = on на таком объёме памяти уже точно нужен (соответственно в ОС тоже выделить huge pages)
PS: я понимаю почему выбрана модель "специально ничего не настраиваем", в этом есть смысл, но по моему опыту shared_buffers всё-таки пользователи крутят чуть менее чем всегда, думаю полезнее чем дефолтные 128мб тестировать будет.
Maksvelis Автор
Благодарю за очень развёрнутый ответ, очень полезная для меня информация, думаю следующий тест буду по вашим рекомендациям делать) по температуре и частоте тоже были мысли писать графики, но время было ограничено. С NUMA тоже экспериментировал с равномерным распределением памяти разницы не увидел, буду изучать дальше.