Ковер-самолет, меч-кладенец, скатерть-самобранка, шапка-невидимка, молодильные яблоки, волшебный клубочек и… ? Правильно, решение для распознавания полнотекстовых документов от Smart Engines. Оно, как и все упомянутые предметы, совершенно уникально, неповторимо и обладает самым что ни на есть волшебным функционалом. Например, распознает текстовые данные со скоростью 15 страниц в секунду. А еще распознает текст на мятых листках. А еще распознает текст в темноте. А еще распознает текст на арабском. А еще на японском и на иврите. И при этом всем существует не в сказках, не в 2030 году, а наяву. Рассказываем и показываем, как выглядит OCR без слабых мест.
Сверхбыстрая OCR на 102 языках
В декабре прошлого года Smart Engines объявила о выходе собственного решения для распознавания полнотекстовых документов. Оно является частью программного продукта Smart Document Engine, который извлекает данные из бумажных документов – первичных, бухгалтерских, налоговых, нотариальных, юридических, страховых и прочих.
Это IT-решение находит документ на фотографии или скане, а затем распознает текстовые данные на 102 языках. Причем оно отлично распознает как Latin-based языки, так и языки с собственными системами письменности.
Вот так Smart Document Engine распознает текст на русском:
А вот так, к примеру, на арабском (при свете дня и ночи):
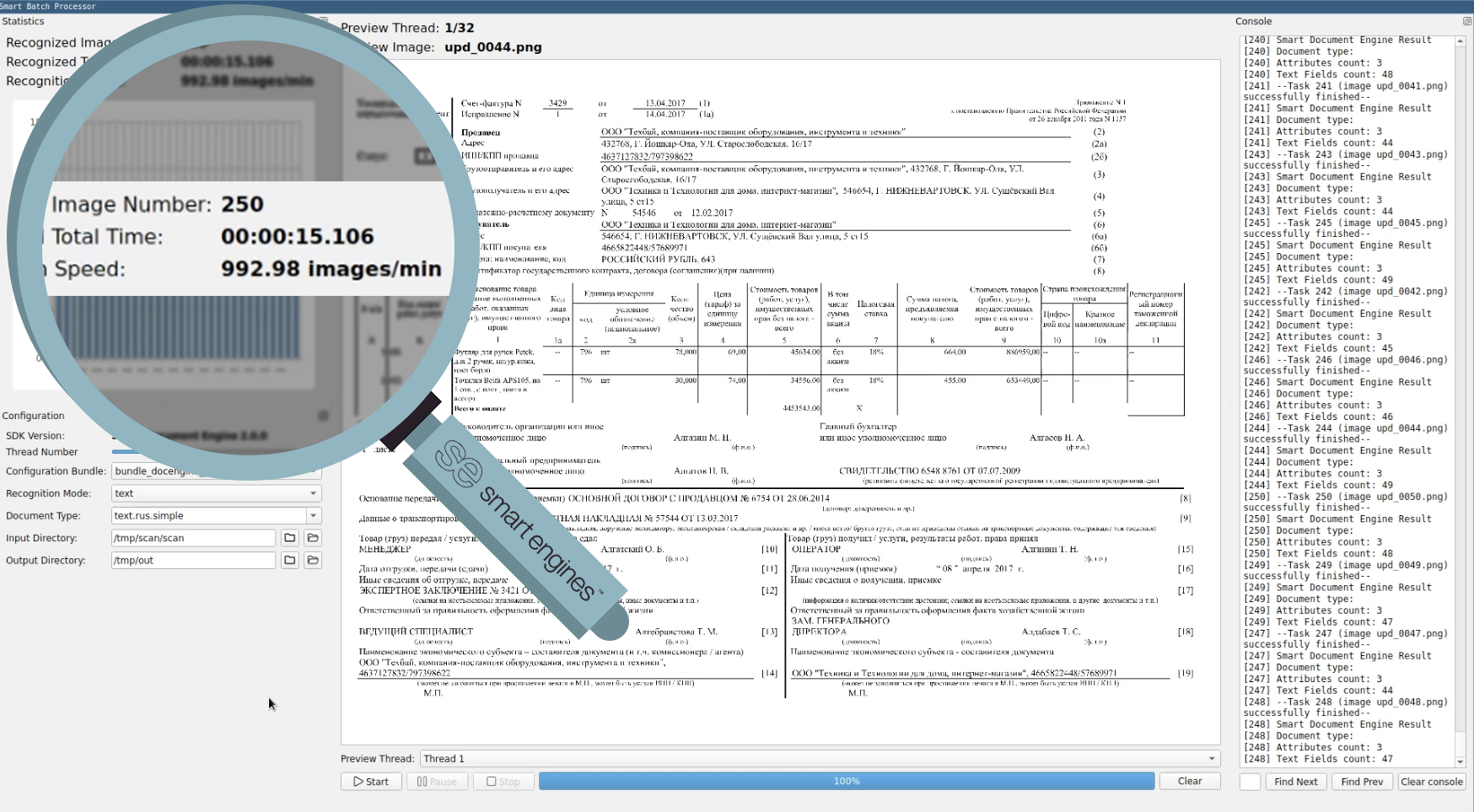
На современном смартфоне решение Smart Engines полностью обрабатывает фотографию листа A4, в том числе с таблицами, за 3-4 секунды.
Процесс в серверных решениях протекает еще быстрее: на 64-х ядерном HPC без применения GPU скорость полнотекстового распознавания достигает 15 страниц в секунду.
Система Smart Engines – и в этом, среди прочего, ее суперсила – автоматически обрезает, "разглаживает" сложенные документы и улучшает их изображения, превращая таким образом телефон в мобильный сканер.
Помимо построчных результатов распознавания, система предоставляет координаты текстовых объектов на исходном изображении и оценки уверенности распознавания на уровне символов, слов или строк.
Решение Smart Engines может быть использовано для распознавания присутствующего текста как на изображении документа целиком, так и на изображениях отдельных фрагментов документа.
Smart Document Engine, как и другим нашим продуктам, не требуется связь с внешними сервисами или ресурсами. Все вычисления производятся непосредственно на вызывающем устройстве. Наша OCR SDK может быть развернута на on-premise сервере, персональном компьютере, в рамках автономного мобильного приложения, а также в веб-приложении.
А как же общедоступные или open-source решения?
В наше время действительно существует много общедоступных open-source распознавателей текста. Такие решения могут быть очень полезны в образовательных целях или для учебного демонстрационного приложения. Однако open-source продукты могут быть не просто бесполезны, а даже опасны для субъектов КИИ и для ИТ-систем, в которых циркулируют персональные данные россиян. Существенным недостатком подобных продуктов окажутся, с одной стороны, невысокие точность и скорость распознавания. О том, чем обернулось наше сравнение с open-source продуктами, мы писали здесь.
Но более существенные минусы – отсутствие контроля над содержимым кода, а также высокие риски внешнего вмешательства. Об этих рисках мы уже рассказывали в своем блоге. Коротко напомним об этом.
Атаки на нейронные сети - это весьма популярная тема для научных исследований. Главные типы подобных атак – отравление данных и атака уклонением с помощью состязательных примеров. При отравлении данных ошибки вводятся в сеть на этапе обучения. А при применении подобной сети распознаватель может совершить специфические серьезные ошибки. Единственный способ избежать такой атаки – быть уверенными в своих данных. А как можно быть уверенным в данных, которых вы никогда не видели?
При атаке уклонением злоумышленник пытается заставить сеть дать неверный ответ. Иногда он даже может предопределить этот ответ. Для открытых систем оптического распознавания текста такие примеры можно посчитать, так как эти системы общедоступны. Можно просто скачать модель и подобрать нужные примеры.
Но Smart Engines, напомним, работает автономно на конечном устройстве. Оно никуда не передает данные клиента, не хранит их и не требует интернет-соединения. Обработка данных ведется на стороне клиента, внутри его контура безопасности. При разработке нашего OCR-модуля мы активно пользуемся генерацией искусственных данных и не используем предобученные модели. Наше решение создано с соблюдением этических принципов ИИ, признанных во всем мире.

Лучший вариант для импортозамещения
В прошлом году российские государственные органы, банки и телеком-операторы получили новую задачу по импортозамещению ПО. 31 марта 2022 г. вступил в силу указ президента РФ, запрещающий субъектам критической информационной инфраструктуры (КИИ) закупку иностранного софта. Ведомства и компании, которые десятилетиями эксплуатировали зарубежные программные продукты, должны полностью отказаться от них к 2025 году.
Запрет распространится на различные типы ПО, в том числе, программные продукты для документооборота. Решение ожидаемое: субъектам КИИ всегда приходится работать с разными типами документов, в том числе, секретными файлами. Уже сейчас, до вступления указа в силу, применение иностранного ПО для распознавания текстовых документов сопряжено с целым рядом рисков, как в сфере кибербезопасности, так и в юридической плоскости.
По новым правилам ведомства и крупные корпорации РФ, скорее всего, будут вынуждены расстаться с продуктами, правообладатели которых зарегистрированы в недружественной юрисдикции. Замена подобных решений на отечественные программы - это вопрос времени. Для импортозамещения такого ПО субъектам КИИ скорее всего потребуется не только защищенная от внешних воздействий российская программа, но и самые современные алгоритмы искусственного интеллекта.
Итак, если вы – субъект критической информационной инфраструктуры и вам необходимо провести импортозамещение ABBYY, Kofax и аналогичных иностранных систем, то Smart Document Engine – это лучший вариант ПО, гарантирующего не только высокое качество распознавания текста, но и безопасность персональных данных.
Комментарии (20)

economist75
23.06.2023 08:37+6Любое сравнение в 2023 г. без участия OSS Tesseract OCR версии 5+, совершившей гиганский скачок в скорости и точности - дает неверный посыл (или верный). Огульно заявлю что хоть не 15 стр./сек, но 4 стр./сек. из него выжимаются легко.

SmartEngines Автор
23.06.2023 08:37-3В этой статье мы ссылались на наши сравнения, опубликованные еще в 2020 году (само исследование проводилось в 2019 году). На тот момент замеры были сделаны на актуальных в то время версиях OCR Tesseract. Если мы будем проводить новые сравнения, то будем использовать актуальные сейчас версии.
Конечно, OCR Tesseract – хороший продукт. Его используют в России провайдеры сервисов распознавания документов, которые не имеют собственных технологий OCR.
Если из версии 5 можно выжать 4 страницы – это хорошо, но мы же демонстрируем, как наша OCR распознает 15 страниц в секунду (это почти в 4 раза быстрее).

iskateli
23.06.2023 08:37+3а кстати в связи с чем такой гигантский скачок? очень интересно что за история

DSRussell
23.06.2023 08:37Datamatrix`ы Умеет распознавать?
SmartEngines Автор
23.06.2023 08:37Приветствуем!
Да, наше ПО распознает линейные штрих-коды CODABAR, CODE_39, CODE_93, CODE_128, EAN_8, EAN_13, ITF, ITF14, UPC_A, UPC_E и матричные штрих-коды QR-код, AZTEC, PDF417 и DataMatrix.

blik13
23.06.2023 08:37+1отсутствие контроля над содержимым кода, а также высокие риски внешнего вмешательства.
С точки зрения пользователя какой контроль содержимого кода вашего приложения у меня есть?
SmartEngines Автор
23.06.2023 08:37Службы безопасности наших клиентов проводят проверку ПО на наличие закладок, вредоносного кода и отсутствие связи с внешним миром. Более того, мы сами заказываем аудит наших программ для выявления возможных рисков.

ss-nopol
А почему сравнение только со свободными OCR, почему нет сравнения с другим собственническим ПО?
SmartEngines Автор
Добрый день! Благодарим за вопрос.
Сравнение проприетарных решений могут осуществлять только заказчики или аналитические агентства, которые приобрели эти программы и имеют к ним официальный доступ.
Dolios
Вы ответили на другой вопрос, который вам не задавали. А на вопрос: "почему нет сравнения с другим собственническим ПО?", - вы не ответили.
SmartEngines Автор
Ответ на этот вопрос следует из того, что мы написали выше. Мы не имеем доступа к "собственническому ПО" других компаний, поэтому мы и не можем проводить таких сравнений.
Dolios
Вы разрабатываете OCR и не имеете доступа к другим продуктам конкурентов, хотя бы, для того, чтобы делать сравнения прежде всего для себя? Простите, но я вам не верю :)
SmartEngines Автор
Мы, конечно, следим за нашими конкурентами и их успехами в открытом информационном поле. Но так же, как и мы, они не дают конкурентам свои OCR решения для серьезного тестирования.
А такие сравнения имеют смысл и пользу, когда они совершены по доброй воле :)
Dolios
Что значит "не дают"? Их софт разве не продается совершенно свободно? А ваш?
SmartEngines Автор
Наше ПО распространяется как B2B-продукты. Впрочем, как и решения наших конкурентов.
Dolios
Вы опять отвечаете на вопросы, которые вам не задавали и не отвечаете на заданные.
SmartEngines Автор
А нам кажется, что вы все прекрасно понимаете. Благодарим вас за то, что повышаете рейтинг этой статьи. Но, обратите внимание, как далеко мы отошли от основной темы нашей статьи - способности отечественной OCR распознавать 15 страниц документов за 1 секунду!
Dolios
Я вот и смотрю, как стремительно рейтинг статьи до "-2" повысился. Впрочем, мне совершенно наплевать на ваши рейтинги. Я, конечно же, всё понимаю, поэтому и указываю вам на вашу явную и неприкрытую ложь. А вы тоже всё понимаете, поэтому юлите и не отвечаете на простые вопросы. Когда у кого-то есть реальное, а не выдуманное, преимущество перед конкурентами, он найдет способ это доказать.
Единожды солгавши, кто тебе поверит (с)
А какая разница, отечественный он или нет? Вы пытаетесь технический вопрос перевести в сферу эмоций?
SmartEngines Автор
У Smart Engines есть реальное преимущество – OCR, которая распознает 15 страниц документов за 1 секунду. И мы, как вы правильно заметили, нашли способ это доказать.
Это не эмоции, а просто факт, который нужно принять: такого результата достигла наша российская технология OCR.