Доброго времени суток habr, на связи Николай Иванов, студент-магистр 1 курса Сколтеха факультета Data Science. С почином, так как это моя первая, и, надеюсь, не последняя статья на habr. С того момента как я познакомился с областью Deep Learning прошло уже около двух лет. С самого начала мне была интересна область обработки естественного языка (Natural Laguage Processing, NLP), о некоторых задачах которой и результатах я попробую рассказать в этой статье. В мае 2023 года начался мой путь в Sber AI Lab в замечательном центре медицины. Мой рассказ будет в какой-то степени сравнением того что было сделано до меня и того, какие идеи мы развили, что получилось, а что не получилось. Хочу сослаться на замечательную статью Даниила (ссылка), который использовал модель RuBioBERTa для задач из MedBench. Я же буду использовать другое решение, посмотрим, чем оно лучше, чем хуже и вообще насколько подходит для NLP-задач в медицине.
Немного оффтопа
Я очень рад, что каждый месяц появляются новые, более сложные и интересные архитектуры, реализующие смелые идеи, которые двигают вперёд области Deep Learning, NLP и Computer Vision (CV), но сколько из них реально используются в прикладных задачах? Вот оценка внедрения AI решений по странам (на основании отчёта IBM Global AI Adoption Index 2022):

А что с данными по России? Статистика (ссылка) за 2021 год показывает, что около 21% компании в России внедрили ИИ. Данных за 2022 пока нет, экстраполируем примерно на 25%, что весьма неплохо.

Теперь более предметно, что с медициной? Ведь медицина — очень деликатное и регламентированное направление. Пока что около 16% организаций сферы здравоохранения внедряют технологии искусственного интеллекта (ссылка). Потенциал роста огромный! В 2022 году вышла очень интересная статья: "Почему внедрение ИИ в медицину отстаёт?", где весьма аргументировано написано, почему человечество сталкивается с трудностями в этом процессе. Анализ изображений в медицине однако, достаточно хорошо принял ИИ: IRA LABS, UNIM, DINGOCAT и др. компании уже используют ИИ для анализа мед снимков. В таких задачах действительно происходит уменьшение времени работы врача, улучшается конверсия пациентов (больше пациентов получают более качественные услуги за меньший промежуток времени, следовательно система успевает принять больше пациентов).
NLP
А что с NLP в медицине? 98% медицинских организаций или уже имеют стратегию использования ИИ или планируют внедрять ИИ, клац. Мечта любого врача получить на стол сразу результаты анализов пациента и предварительный список диагнозов, предлагаемое лечение, чтобы совершить корректировку и назначить успешное лечение. А так ли мы далеки от этого? Какие модели сегодня умеют "понимать" медицинский текст, выдавать предварительный диагноз, выполнять какой-то осмысленный анализ и помогать врачам? Сегодня попробуем прикоснуться к пониманию этого вопроса, похвалить нас рассказать о результатах нашего центра, что конкретно сделал я, и чуть-чуть о наших планах.
Данные - наше всё?
Самое главное для решения большинства supervised (обучение с учителем) ML задач — использование большого количества «хороших» данных. Их использование уже помогает обучению, что было доказано в куче статей, чисто для примера эта (клац). Обычно для серьёзных исследований лаборатории сами собирают дата сеты, вот пример русскоязычных медицинских данных (интернет-посты с мед форума) на hugginface medical_qa_ru_data; в англоязычном сообществе популярен гораздо более полный и основательный поликлинический дата сет MIMIC-III. Однако, в последнее время с развитием отрасли MedTech доступность медицинских данных повышается, улучшается качество ML/DL-моделей. Наиболее популярные англоязычные медицинские дата сеты можно найти, например, здесь ссылка.
MedBench
Некоторые дата сеты стали появляются и для русского языка. Например в рамках одной из таких инициатив был подготовлен ресурс MedBench (Ссылка для ознакомления), включающий четыре типа задач:
RuMedDaNet — измерить способность модели "понимать" медицинский текст и правильно отвечать на уточняющие вопросы.
RuMedNLI — определить тип логической связи между двумя текстами на естественном языке.
RuMedTest — проверка "знаний" модели в рамках специальности "Общая врачебная практика".
ECG2Pathology — оценка качества multilabel-классификации ЭКГ-сигналов.
На момент написания статьи Лидерборд выглядит так:

В сопутствующей этому бенчмарку работе (ссылка на статью) помимо перечисленных задач также представлены дополнительные:
RuMedTop3 — задача прогнозирования диагноза на основании исходного медицинского текста, включающего симптомы и жалобы пациента.
RuMedSymptomRec — учитывая неполный медицинский текст, задача состоит в том, чтобы порекомендовать лучший диагноз для проверки.
RuMedNER — задача распознавания именованных сущностей в отзывах пользователей, связанных с препаратами, лекарствами (классическая задача NLP)
Лидерборд на момент написания статьи выглядел так:

Accuracy базовая метрика для оценки. Для некоторых задач введены дополнительные:
RuMedTop3 and RuMedSymptomRec —
hit@3RuMedNER —
F1-score
Попробуем разобраться, что здесь происходит. Как видно, на тот момент модель RuBioRoBERTa показывает хорошие метрики на RuMedSymptomRec и RuMedNER, Feature-based подход обходит по метрике accuracy, но не hit@3 на задаче RuMedTop3, задачи RuMedDaNet и RuMedNLI остаются за людьми, пока что....
Почему RuBioRoBERTa?
Тут чуть-чуть подробнее об архитектуре, как, что и зачем. С момента появления Трансформеров как архитектуры, а точнее с появления статьи "Attention is all you need" (у которой на сайте paperswithcode.com аж 105 тысяч звёздочек), прошло уже 6 лет. За это время исследователи в области ИИ как только не крутили эту архитектуру, выбрасывали запчасти, добавляли и получили три принципиальные архитектуры: Encoder-Decoder models, Encoder-based models, Decoder-based models. Рассмотрим подробнее Encoder-based модели, куда как раз и относится отец нашего RuBioRoBERTa— BERT. Не хочу сильно перегружать тех, кто не знаком со всем этим зоопарком трансформеров (кто не в теме, вот отличная статья, рекомендую), краткое напоминание: BERT обучается под две задачи — text Classification и Masked Language Modeling (MLM). Тут основной момент в том, что в задаче MLM мы маскируем только определённое количество токенов — 15% и делаем это детерминированно. Попробуем чуть-чуть оптимизировать подбор гиперпараметров, сделаем динамическую маскировку слов и вуаля — RoBERTa. Модель для русского языка — RuRoBERTa была обучена коллегами из отдела NLP R&D SberDevices (ссылка). Уже после этого наши коллеги дообучили эту модель на медицинских текстах и вот она — RuBioRoBERTa.
В чём проблема архитектуры RoBERTa?
Как довольно быстро выяснилось на практике потенциальная проблема такого решения в том, что у BERT и производных от него архитектур детерминированная длина контекста, для классического BERT это 512, а что, если нужно больше? Вот очень красивая схема, на которой видно, что происходит.

Input'ами в архитектуре BERT является сумма Positional embedding (отвечает за позицию слова в контексте), Segment embeddings (какому сегменту принадлежит токен для задачи классификации), Token Embeddings (токенизированные слова). У архитектуры типа BERT positional embedding — обучаемые параметры, следовательно, более 512 токенов наша модель не может обработать за раз, а это может быть критично при обработке длинной истории пациента, или при обработке длинного медицинского текста.
Так что же делать? Попробуем Longformer!
Longformer
Longformer — архитектура и модель, призванные решить проблему ограниченного контекста и как-то его расширить. В основе всё так же лежит архитектура RoBERTa, однако предлагается разделение механизма attention на две части: глобальное и локальное.

В локальном внимании «токен смотрит» на N соседей с каждой стороны, это могут быть как ближайшие соседи, так и взятые с каким-то шагом для увеличения длины покрываемого контекста (но так делается только на верхних слоях, нижние обрабатывают узкий локальный контекст). N растёт линейно с ростом номера слоя. У глобального и локального внимания свои отдельные веса для подсчёта матриц Q-query, K-key и V-value, которые участвуют в расчёте внимания (обычно названия этих матриц не переводят на русский язык). Как видно из графика выше, модель способна обрабатывать более длинный контекст эффективно, а это нам и нужно!
Теперь осталось только посмотреть, что же получится, как долго это обучается, и будет ли лучше?
Имплементация решений
Под каждую задачу бенчмарка я буду дообучать модель longformer. Начнём с общего подхода к обучению. (далее будет достаточно много технических деталей, кому не интересно смотреть на графики — смотрите сразу вывод)
-
Seed
Сиды для сравнимости результатов будут браться из предыдущих результатов моих коллег, а именно: 3558, 2375, 1906, 1042, 2960, 70, 1785, 3502, 3411, 3527. Метрики будут усредняться, а также будет рассчитываться СКО (средне-квадратичное-отклонение, по-английски — std), чтобы понимать насколько стабильно ведёт себя модель.
-
Гиперпараметры
epochs = 25, batch_size = 16, lr = 3e-5, оптимизатор — adamw_torch_fused.
-
Ускорение обучения
Чтобы сделать код более читаемым и универсальным была использована библиотека huggingface и их замечательный Trainer, в котором уже реализованы многие методы ускорения обучения, о которых мы сейчас поговорим.
AdamW vs AdamW_torch_fused более быстрая версия Адама реализованная на torch, чуть легче по параметрам.
Torch_compile нестабильно работающая фича, когда-то может ускорить и уменьшить потребление памяти, когда-то выбрасывает кучу warning'ов.
fp16 vs tf32 отсылаю вас к данной статье на сайте Nvidia link. Вкратце: используем тензорные ядра — специальная архитектура Ampere, позволяющая сократить precision при хранении чисел до 10 bit вместе 23 в стандартном fp32. По скорости уступает fp16, но сходится лучше.
Вот сравнение в виде графиков, которое я провёл для одного из сидов:
Время обучения
График отражает время обучения для одной эпохи, нормированное на default (время обучения с оптимизатором adamw + torch.float32).

Для всех задач формат fp16 и tf32 с оптимизатором adamw_fused показывают хорошие значения по времени, значительно (более чем в 2 раза ускоряя процесс обучения). Следовательно, мы получаем хорошие инструменты для оптимизации скорости, что не может не радовать, а всё ли хорошо с точностью? Всё-таки отбрасывание знаков после запятой не всегда приводит к точным результатам, а это может ухудшить сходимость! В абсолютных значениях, например, для задачи MedTop3 мы получаем уменьшение с 1000 секунд до 417.
Accuracy

А почему мы вообще можем использовать точность (accuracy) ? Это ведь не очень хорошая метрика для задач классификации, а что если классы несбалансированные ? Во-первых, да, метрика на несбалансированных классах не очень репрезентативная, но так как дата сеты сбалансированы по количеству классов, всё ок! Во-вторых для задачи MedNER использовалась также метрика F1-score, которая ведёт себя идентично. В абсолютных значениях, например для задачи Top3 мы имеет уменьшение hit@3 метрики с 62.77 до 1.21 для fp16. Вывод: для формата fp16 точность получается низкой для некоторых задач, иногда же различий с tf32 нет, но мы хотим, чтобы модель вела себя стабильно, поэтому возьмём fp16 на карандаш.
Memory

Видим ожидаемый график: fp16 занимает меньше памяти, чем tf32 и float32, tf32 меньше чем обычный float32, добавить тут особо нечего, это то, чего мы и хотели достичь. Разница получилась не столь огромной для fp16 и fp32 — около 25%, в абсолютных значениях для той же MedTop3 задачи снижение с 29.1 Гб до 24.2 Гб.
Вывод: как можно заметить, самым оптимальным сочетанием является tf32 + adamw_torch_fused, это позволяет заметно прибавить в скорости (сокращение времени в 2 раза), и не потерять в точности по сравнению с оригинальным adamW, fp16 работает нестабильно для некоторых задач, мы не хотим, чтобы наш оптимизатор не сходился в угоду скорости, так что между очень лёгким, но нестабильным и стабильным, но более тяжёлым мы выберем стабильность, tf32 — наш друг. Про torch_compile добавить нечего, вещь нестабильная, надеюсь, в будущем это поправят.
Вперёд к обучению
Предобученный Longformer обучается на Кристофари в течении 3-х месяцев на медицинских текстах (от наших партнёров). В нашем распоряжении были 6 чекпоинтов: 80k шагов, 120k, 180k, 220k, 260k, 300k. Обучение заняло достаточно много времени. Под каждую задачу модель дообучалась отдельно. Из 25 эпох брался чекпоинт модели, который показывал лучшие метрики на валидации. На всех графиках бралось среднее значение + СКО на 10 сидах БЕЗ УЧЁТА ВЫБРОСОВ.
RuMedTop3
В самом начале модель ведёт себя нестабильно и разброс большой — недообучение, однако при дальнейшем обучении мы видим минимум и далее рост, скорее всего где-то здесь и находится максимальная точность.

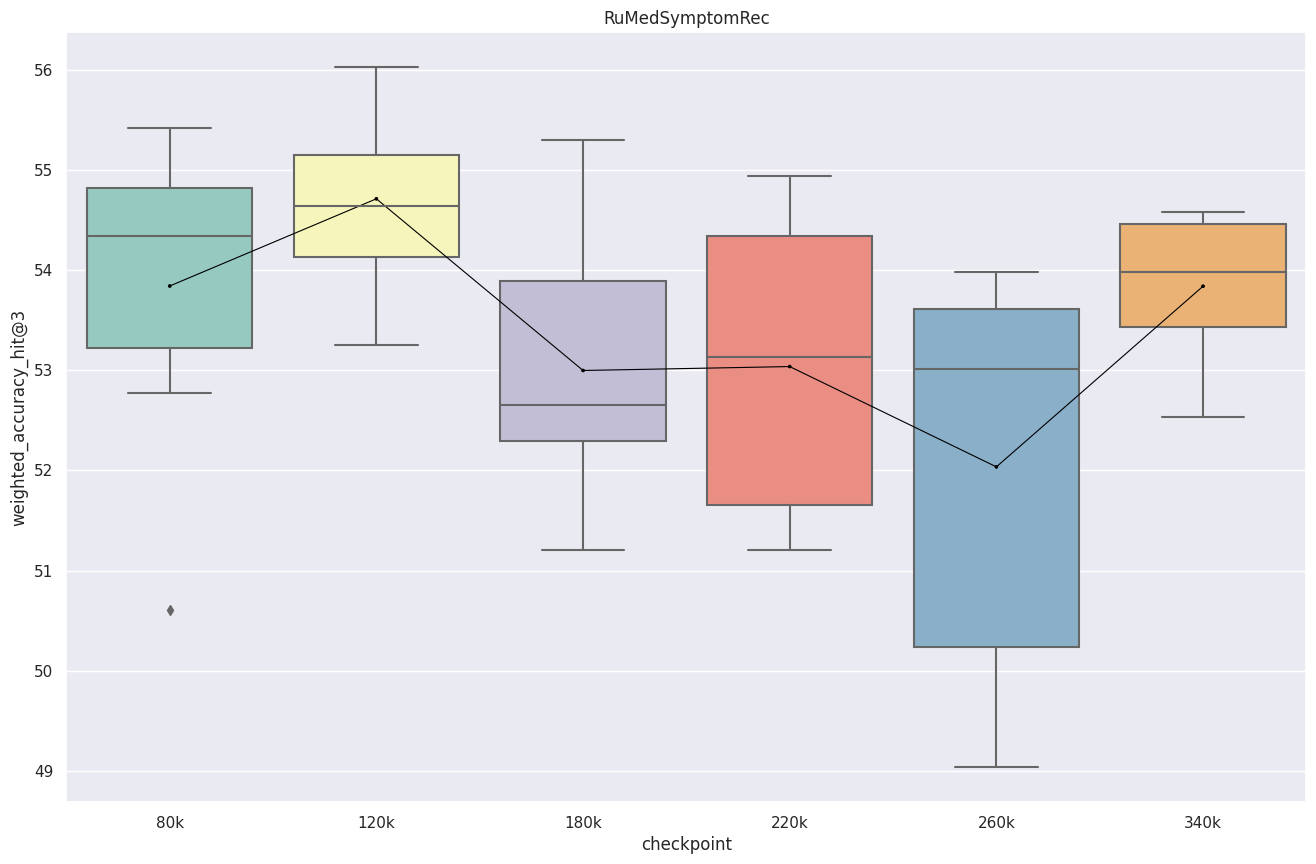
RuMedSymptomRec
Видно очень нестабильное поведение, на некоторых задачах модель выдаёт очень низкую точность порядка 5-6%, также большие значения СКО не внушают доверия. Чекпоинты 120k и 220k были стабильны на всех 10 сидах.
RuMedDaNet
Тут также заметно очень нестабильное поведение модели, СКО то большое, то маленькое. В начале обучения разброс большой, к чекпоинту 180k точность достигает минимума, а далее растёт.

RuMedNLI
Вот тут интересно, модель сначала показывает большой СКО и низкую точность, дальше точность растёт и СКО падает, отлично, а далее опять растёт, по всем канонам машинного обучения здесь и находится оптимальная глубина обучения.

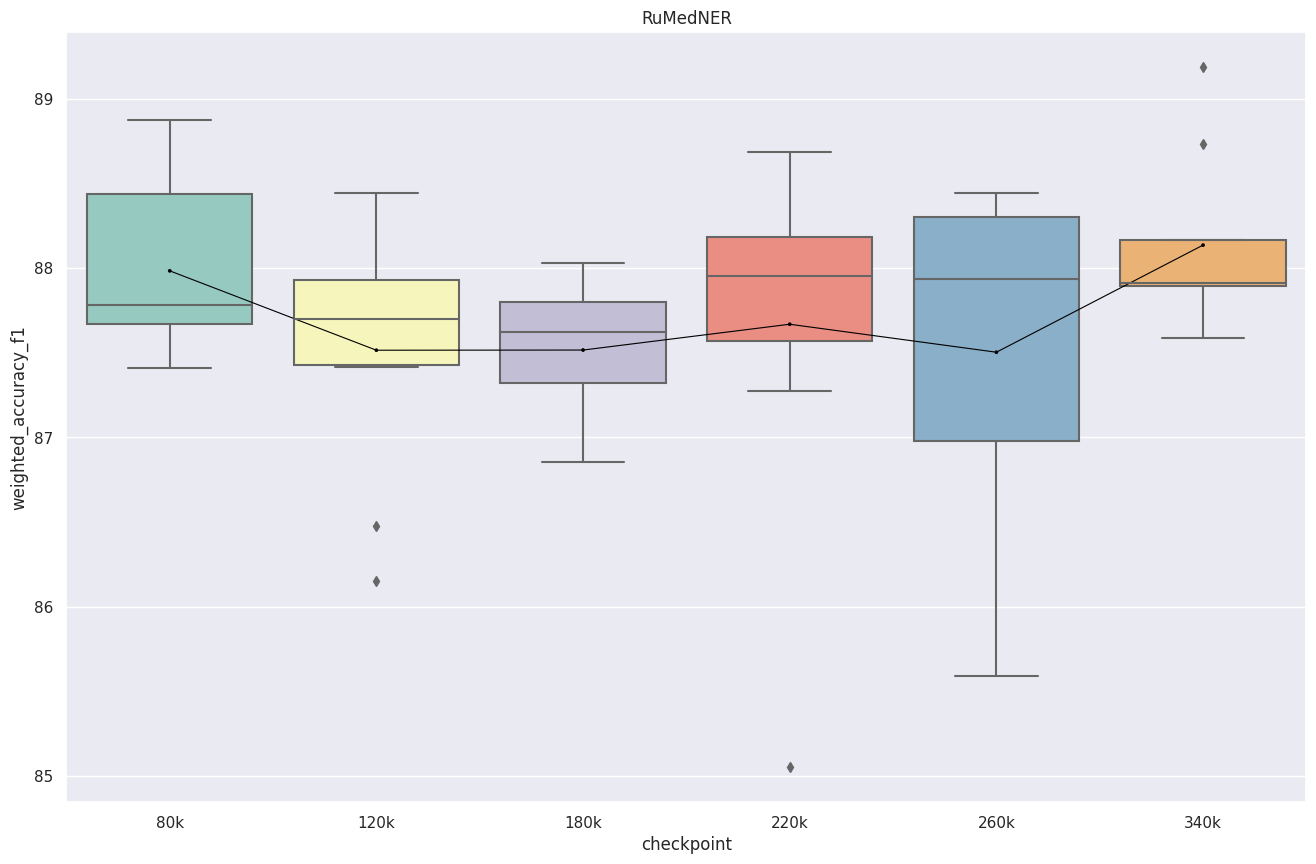
RuMedNER
Модель стабильна и мы видим примерно одинаковый результат на всех чекпоинтах, кроме 260k. Модель переобучилась? Далее видим рост метрик.
Overall
Таблица результатов по всем сидам:

Лучшим для Longformer'a оказался чекпоинт 120k шагов. На нём модель показывает себя наиболее стабильно на всех задачах, поэтому в качестве итоговой модели возьмём его. Можно заметить, что на задачах RuMedSymptomRec мы видим значительные улучшения по сравнению с предыдущими результатами! А на задаче RuMedNER F1-score вырос, хотя точность чуть хуже чем у RuBioRoBERTa, интересно…. А почему на задаче RuMedDaNet результат такой плохой?

А что если...
К концу написания статьи хочется подметить один интересный момент, почему на некоторых сидах модель ведёт себя как наивный алгоритм? точность 33% в задаче с тремя классами, хмм... возможно модель недостаточно «прогрелась». Как мы все знаем, влияние warmup'a на сходимость Adam'a особенно критично в архитектурах типа трансформеры. В этот раз мы ещё раз в этом убедились. Ниже представлены boxplot'ы для чекпоинта 80k с warmup_steps = 1000 в тех местах, где оптимизатор решил не сходиться:

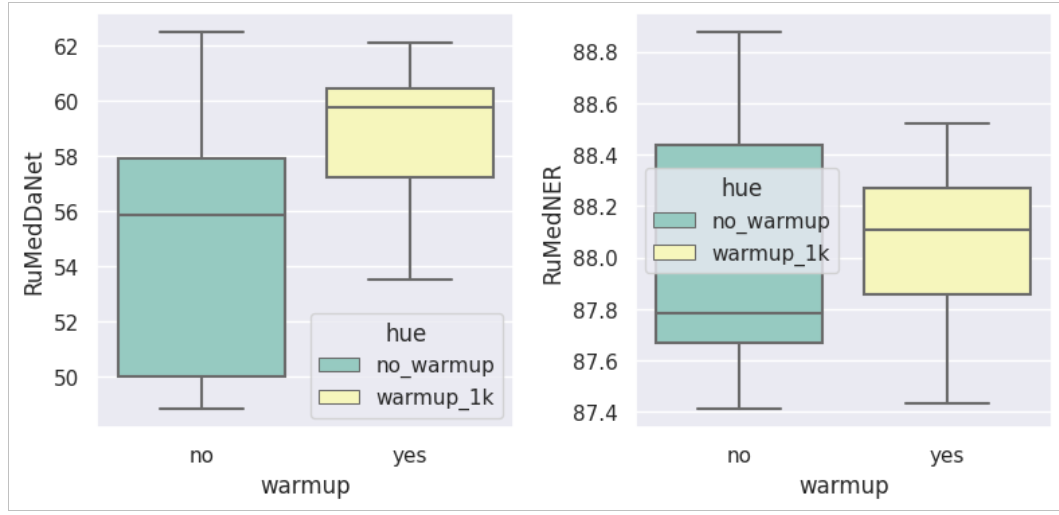

Как можно заметить, даже на сидах, где модель сходится достаточно хорошо, мы видим прирост точности, что не может не радовать. Очевидно, что при увеличении warmup steps необходимо обучать на большем количестве эпох, так как оптимизатор не успевает «сходиться».
Вернёмся к реальности
Эти результаты выглядят конечно хорошо (или нет?), а что эти цифры значат для реальных врачей, терапевтов, больниц? Давайте рассмотрим несколько примеров анамнез пациента и предложенные диагнозы нашей модели из тестового дата сета, который модель не видела при обучении:
RuMedSymptomRec
-
idx "q6fb3825" : "Жалобы осиплость голоса, повышение температуры до 38 кашель , першение в горле, заложенность носа"
реальный диагноз : "сухой кашель"
-
3 предсказания модели с наибольшей уверенностью: "насморк", "боль в горле", "озноб"
-
idx "qb53a600": "Боли в правой лопатки, в правом плечевом суставе, мышцах плеча несколько уменьшились. Период. боли в правом т\бедренном суставе с иррад. в ногу. Утренняя скованность 30 минут."
реальный диагноз : "боль в эпигастрии"
3 предсказания модели с наибольшей уверенностью: "боль в эпигастрии", "сухость во рту", "боль в области лопатки"
-
idx "q45f6321": "на головные боли давящего характера, усиливающиеся при эмоциональном перенапряжении,"
реальный диагноз : "боль в шее"
3 предсказания модели с наибольшей уверенностью: "тошнота", "головная боль в теменной области", "ощущение дурноты"
Если посмотреть отдельно наhit@3,то для задачи SymptomRec это значение на уровне 62%, что уже станет отличным помощником. Чаще всего среди трёх предсказаний модели будет именно то, что нужно врачу.
RuMedTop3
В этой задаче болезни представлены в МКБ формате.
-
idx "qaf1454f": "Головную боль, "мелькание мушек перед глазами " на фоне повышения цифр АД до 150\100 мм.рт.ст., учащенное сердцебиение"
реальный диагноз : "I11" — Гипертензивная болезнь сердца [гипертоническая болезнь сердца с преимущественным поражением сердца]
-
3 предсказания модели с наибольшей уверенностью:
"I11"— Гипертензивная болезнь сердца [гипертоническая болезнь сердца с преимущественным поражением сердца]
"I20" — Стенокардия [грудная жаба]
"I25" — Хроническая ишемическая болезнь сердца
-
idx "q28fa7aa": "Кашель приступообразный, на протяжении 3-х месяцев, эпизоды дистанционно слышимых хрипов при кашле, отделяется небольшое количество вязкой желтоватой мокроты. Ощущение диспноэ при вдыхании холодного воздуха, не ветре."
реальный диагноз: "J42" — Хронический бронхит не уточненный
-
3 предсказания модели с наибольшей уверенностью:
"J42"— Хронический бронхит не уточненный
"J45" — Астма с преобладанием астматического компонента
"J84" — Другие интерстициальные легочные болезни
Рассмотрим неудачный пример:
-
idx "qe64eefb": "Жалобы на сердцебиение приступами, при этом головокружение, в течение 2-3 дня, купируется приемом донормила 1/2 т , с положительным эффектом, учащение мочеиспускания."
реальный диагноз : "J84" — Другие интерстициальные легочные болезни
-
3 предсказания модели с наибольшей уверенностью:
"I49" — Другие нарушения сердечного ритма
"I11" — Гипертензивная болезнь сердца [гипертоническая болезнь сердца с преимущественным поражением сердца]
"I10" — Эссенциальная (первичная) гипертензия
Видно, что во всех этих случаях модель была близка к пониманию болезни, но истинный диагноз оказался слишком специфичен и сложен для модели.
Если посмотреть отдельно на hit@3 то для задачи RuMedTop3 это значение на уровне 70-75%, что впечатляет! Чаще всего среди трёх предсказаний модели будет именно то, что нужно врачу! А это значит такая модель будет хорошим ассистентом врача, но лишь ассистентом. Мнение врача специалиста критически важно и остаётся решающим.
Итог для врачей!
Модель хорошо справляется с предсказанием диагнозов и выводит их с большой точностью. А там, где модель не угадывает точный диагноз, она даёт очень близкие по классификации болезни. Такое отличное дополнение сможет ускорить время выставления диагнозов для пациентов, сократить время работы врача и в какой-то степени облегчить его работу, оптимизировать процесс работы.
Итог для разработчиков!
Как мы видим, использование Longformer'a позволяет превзойти RuBioRoBERTa почти на всех задачах. Так как задача изначально стояла в сравнении моделей при одних и тех же параметрах, я решил не использовать warmup, так как при обучении RuBioRoBERTa использован warmup не был. Используя warmup и подобрав гиперпараметры — мы получаем новую SOTA модель бенчмарка MedBench.
Будущие идеи
Тут хотелось бы рассказать, что можно попробовать ещё, чтобы улучшить качество модели.
Ещё одним улучшением архитектуры BERT является DeBERTa, которая сочетает в себе плюсы двух других сильных архитектура: RoBERTa и ELECTRA. Хочется протестировать данную модель.
Также хочется протестировать другие улучшения скорости сходимости и обучения по типу sophia(ссылка), LoRA (ссылка).
Подбор гиперпараметов для Longfomer'a и RuBioRoBERTa.
Благодарю тебя, наш читатель, комментарии всегда открыты для тебя.
Комментарии (60)

nikolz
15.07.2023 07:42+4"Статистика (ссылка) за 2021 год показывает, что около 21% компании в России внедрили ИИ. Данных за 2022 пока нет, экстраполируем примерно на 25%, что весьма неплохо."
Согласно Вашей ссылке, внедрение ИИ даст рост ВВП на 1 процент лишь к 2025 году, но уже повысило рентабельность на 5%(!!!) . Почему же это повышение не повлияло на ВВП сейчас ? Что же хорошего в том, что внедрение пятой частью компаний ИИ никак не ощущается в изменении ВВП? Что-то тут не так с данными - которые наше все.

Viroslav_Venskii Автор
15.07.2023 07:42Спасибо за замечание. Это оценки, которые дал директор АНО "Цифровая экономика". Я не обладаю образованием в области экономики, но попробую ответить. Рост рентабельности говорит лишь о том, что компания работает эффективнее, чем раньше, и это уже влияет на ВВП. То есть компании могли иметь низкую рентабельность и повысить её, например, до средней, что уже хорошо). ВВП России 1,779 триллиона USD (2021 г.), рост по данным на 2021 г. - 4.7% , если к этом добавить прирост в 1% мы получаем 5.7%, а это увеличение на целых 21% - уже более значимые цифры)
nikolz
15.07.2023 07:42+4А как Вам такой вариант. раньше в компаниях отвечали клиентам люди, а теперь им отвечает программа. В итоге рентабельность повысилась - людей уволили, так как теперь клиенты не могут до технарей достучаться, то тех тоже сократили. В итоге - затраты на зарплату сократились, а освободившиеся деньги направили в бонусы (а это прибыль) руководству. А на ВВП это не влияет, так как выручка не изменилась.
nikolz
15.07.2023 07:42+7-
реальный диагноз : "сухой кашель"
реальный диагноз : "боль в эпигастрии"
реальный диагноз : "боль в шее"
Это не диагноз, а всего лишь первичные и скорее всего очевидные признаки , по которым ставится диагноз.
Диáгноз (греч. διάγνωσις, лат. diagnosis «распознавание»; от dia «через, посредством» + gnosis «знание») — медицинское заключение о состоянии здоровья обследуемого, а также сущности болезни и состоянии пациента, выраженное в принятой медицинской терминологии и основанное на всестороннем систематическом изучении пациента.
Viroslav_Venskii Автор
15.07.2023 07:42Абсолютно верно! В задаче SymptomRec мы оперируем симптомами! Описался) Спасибо за замечание!

Robastik
15.07.2023 07:42+1Только сегодня от врача и она не смущаясь сообщила диагноз "что-то болит" в формулировке "дисфункция с болевым синдромом". Особенности национальной медицины.
nikolz
15.07.2023 07:42+2У меня был еще прикольней случай.
Пришел к врачу.
Она взглянула и воскликнула - "Это что такое у Вас, первый раз такое вижу?"

eton65
15.07.2023 07:42+4Она взглянула и воскликнула — "Это что такое у Вас, первый раз такое вижу?"
Так это как раз не проблема, если врач поймет, что надо проконсультироваться с другими специалистами. То есть для ситуаций с непонятными диагнозами должны быть простые способы их эскалации.
nikolz
15.07.2023 07:42+1Так там, все было банально просто - хрящ переломан.
Она так и сказала позже, но я с этим к ней и пришел. Результат -ноль, само зажило. Давно это было, но ИИ тогда давал в медицине такие же результаты как и сейчас , только назывался он Системой распознавания образов в медицине. Теперь таких врачей уж нет.
Сейчас ИИ - это всего лишь генератор текста. Обучают его на текстах из интернет. Вот он и генерирует правдоподбные наборы букв на основе того, чему учили. Своих мыслей у него нет , а интеллект весь на основе интернета.

vaslobas
15.07.2023 07:42Это куда лучше, чем как мне терапевт только на основании моих жалоб поставил мне на первом приёме диагноз - СРК. Хотя это диагноз исключение, т.е. нужно меня было всего обследовать и если ничего не нашли, то только тогда ставить этот диагноз.
-

vasyakolobok77
15.07.2023 07:42+1там, где модель не угадывает точный диагноз, она даёт очень близкие по классификации болезни
В вашем же примере, модель сообщает о проблемах с сердцем, а в реальности – легочная болезнь.
сможет ускорить время выставления диагнозов для пациентов
Ускорить сможет, главное чтобы процент ложных диагнозов не вырос.
Все эти лингвистические модели – это просто улучшенная версия бредо-генераторов из нулевых. Модели НЕ понимают механик окружающего мира, в них это не закладывают. Модели просто имеют статистику цепочек слов и по вводным данным рандомно генерируют ответ.
Viroslav_Venskii Автор
15.07.2023 07:42Спасибо за комментарий. В нашем веке произошёл значительный прорыв области Больших Языковых Моделей (LLM). Сейчас такие модели представляют собой достаточно сложные архитектурные решения и показывают отличные результаты в области перевода, генерации текста (тот же Chat GPT) и других задачах. Статистика цепочек слов - это скорее к старым статистическим моделям, которые уже не используются. Вот интересная статья про динамику развития этих моделей (ссылка).

GospodinKolhoznik
15.07.2023 07:42+2Я правильно понимаю, что данные для обучающей модели взяты из поликлиник? Ну т.е. не частных клиник, а обычных бесплатных? Там где очереди по 2-3 часа, из за этого среднее время на прием пациента 5 минут, и "реальный диагноз" ставит выгоревшая, замученная, уставшая врачиха, работающая за копейки, которая не может устроиться в частную клинику на большие деньги, потому что ей квалификации не хватает. А медицину она учила давно в ВУЗе, по учебникам 50-60 годов и с тех пор ничего больше не учила. И всякий, кто ходил в такую поликлинику знает, насколько там адекватные диагнозы ставят.
А ещё данные взяты с интернет форума, ну это вообще балдёж!

jasiejames
15.07.2023 07:42Ну, что вы накинулись? Нормальная интересная статья. Тем более с чего вы решили, что частные клиники бесплатно будут делиться историями болезни пациентов или вообще выкладывать их в открытый доступ?
GospodinKolhoznik
15.07.2023 07:42+1Как из моих слов следует, что я решил, что частные клиники бесплатно будут делиться историями болезни?
jasiejames
15.07.2023 07:42-2Ой-ой-ой! Нетушки, так дело не пойдёт)))
Если вы думаете, что я решил вступить с вами в полемику, то глубоко заблуждаетесь))
Не ищите в моём комментарии выше того, чего там нет. Я написал лишь то, что написал. Тем более учитывая ваш бэкграунд комментариев)))
Viroslav_Venskii Автор
15.07.2023 07:42Спасибо за развернутый комментарий! Данные для обучения модели могут браться из разных источников, в том числе и форумов, почему? Чем больше данных модель увидит, тем более разнообразные ситуации она встретит. Да, нечистые данные (данные с неточными диагнозами) могут повлиять на обучение модели в худшую сторону! Но ключевой момент в тестировании модели: для тестирования были отобраны подтверждённые диагнозы (с помощью анализов и других видов исследования). Ну и не стоит забывать, что модель лишь призвана ускорить процесс работы врача, а не стать его заменой!

IvanPetrof
15.07.2023 07:42+1"реальный диагноз" ставит выгоревшая, замученная, уставшая врачиха, работающая за копейки
"...Ну что вы хотите, больной. Это старость.."
eton65
15.07.2023 07:42+4Здесь будет очень большая польза только в случае тренировки ИИ на правильных диагнозах и методах лечения. А вот как их отобрать — вот основной вопрос.
Viroslav_Venskii Автор
15.07.2023 07:42Спасибо за комментарий! Очень интересный момент в том, что данные для тренировки должны быть разнообразными, а вот тест модели должен ОБЯЗАТЕЛЬНО проводиться на подтверждённых диагнозах (с помощью анализов, ЭКГ, снимков и др.), как и было сделано в данной статье)
eton65
15.07.2023 07:42данные для тренировки должны быть разнообразными
Что это означает — на всех подряд? Может лучше тогда тренироваться на медицинских справочниках?
Viroslav_Venskii Автор
15.07.2023 07:42Имеется в виду на разнообразных медицинских данных (таких как, например, данные с форумов), потому что иногда и там встречаются ответы квалифицированных врачей, либо тех, кто через них прошёл и помогает людям с похожими диагнозами

berng
15.07.2023 07:42+1Не боитесь, что средний по больничке диагноз пациента будет искривление потока жизненной энергии? Тренировка на неправильных исходных данных обычно к хорошим результатам не приводит.
Вроде по правилам статистического обучения тестовый, обучающий и валидационный датасеты должны быть из одного распределения, а обучать на одном, а тестировать на другом - далеко можно зайти.
Viroslav_Venskii Автор
15.07.2023 07:42Да, всё верно, все дата сеты должны быть из одного распределения. Даже если мы добавляли в наш дата сет данные с форумов, мы брали ответы, квалифицированных врачей. Вы всегда можете сами ознакомиться с нашими данными) Вот ссылочка)
berng
15.07.2023 07:42Вы реально хотите на 1.5 тыс записей взятых из различных источников обучить сложную задачу? Завидую вашему оптимизму. Даже для трансфера знаний от уже обученной сети этот объем выглядит маленьким на грани фола, а для прямого обучения это кажется слишком скромным датасетом.
Кардиограммы (последний датасет) - да, такие задачи известны, и они вроде решаются на таких датасетах, в том числе видел международные врачебные квесты, даже на кагле что-то подобное видел, но остальное выглядит несколько маловатым.
Viroslav_Venskii Автор
15.07.2023 07:42+1Вы, наверное, имеете в виду задачу DaNet, там действительно 1.5 тыс. записей, но мы лишь дообучаем наш Лонгформер под конкретную задачу, до этого, как упоминалось выше, мы обучали Лонгформер на всём объёме текстов, который имеется в нашей лаборатории. Но не могу не согласиться, 1.5 тыс. - это маловато) Например, в той же задаче NLI 15 тыс. записей и результат гораздо лучше) Вообще это очень интересная дискуссия про объём данных, сейчас общепринятое мнение, что важен не общий размер данных, а количество "чистых данных".
berng
15.07.2023 07:42Более менее понятно, спасибо. С трансфером знаний наверное задача и может быть решена с некой нерандомной точностью.

nikolz
15.07.2023 07:42Почему-то никто не вспоминает результаты применения обучающихся алгоритмов в медицине пол века назад не только в СССР, но и в США. Результаты были впечатляющие. Но не потому что можно было 200 миллиардов узлов сделать и потом полгода обучать их непонятно чем, а потому, что не было таких суперкомпьютеров а диагностика была и прогнозирование после операционного состояния было. Правда американцы сделали вывод, то достоверность диагноза выше 90% получить не получится так высокая погрешность исходных признаков - т е измеряемых параметров организма, а не букв в интернете, которого еще и в помине не было.
Ну и что же достигли за эти 50 лет? Ничего кроме бла-бла- бла и глупых вопросов ИИ с последующим восторгом "как он здорово сгенерировал буквы."

Sarjin
15.07.2023 07:42+1поделитесь ссылкой на упоминаемые алгоритмы/статьи о результатах?
nikolz
15.07.2023 07:42+1Давно это было, уже не помню точного названия. Могу лишь сказать, что в ту пору вышел переводной тематический журнал О результатах применения ЭВМ для диагностики в медицине ( США) и книга о применении ЭВМ для прогнозирования послеоперационного состояния, а также сборник алгоритмов и программ на Алгол-60 по распознаванию образов . В книге в основном использовался метод главных компонент.
Viroslav_Venskii Автор
15.07.2023 07:42Случайно не вот это? https://en.wikipedia.org/wiki/Man-Computer_Symbiosis
nikolz
15.07.2023 07:42нет, это фантастика, а то было подведение итогов 5 летней работы (это журнал), а книга была под редакцией какого-то академика. Я тогда начинал заниматься этой тематикой. Спаял персептрон и потестил кучу программ из сборника алгоритмов и программ.
nikolz
15.07.2023 07:42Распознавание образов и медицинская диагностика / Ю. И. Неймарк [и др.]; под ред. Ю. И. Неймарка. — Москва : Наука, 1972. — 323 с.: ил. — Библиогр.: с. 313-325. — Предметный указатель: с. 326-328.
Viroslav_Venskii Автор
15.07.2023 07:42Не могли бы вы поделиться ссылкой на результаты о которых упомянули, с удовольствием прочитаю!

sentimentaltrooper
15.07.2023 07:42+3Добавил в закладки, попозже почитаю детально. Если что я сам "впариваю", в смысле внедряю AI / ML в разных прикладных проект для разных компаний. До этого работал с больницами на тему smart textiles, wearables и так далее и через университеты как исследователь и как консультант частных компаний. По итогу сейчас мы не трогаем медицину и 20 метровой палкой по двум основным причинам: 1) мы не хотим получить иск за ошибочный диагноз 2) ИИ в общем случае не дает объяснений, acceptance level у врачей очень низкий. Куда более известный пример от IBM, ИИ говорит: "судя по снимку у этого рак". Почему? Ну потому что натаскали на снимках тех у кого он был (так же как на кошечках и собачках), но этот ответ не годится для врача. В итоге мы делаем только wellbeing решения, например делаем оценку позы, но не даем никакого заключения: только углы / отклонения рисуем. Заключение будет делать врач (и отвечать за это заключение своей лицензией). Мы всегда даем такой "угол", что мы вам делаем помощника, а не замену. Хотя чаще это продиктовано не техническими причинами.
Viroslav_Venskii Автор
15.07.2023 07:42Спасибо за развёрнутый и интересный комментарий!!! Соглашусь со всеми тейками) Поэтому мы тоже готовим только помощника для врача) Зачастую интерпретировать результаты больших моделей достаточно сложно, хотя попытки есть. Вот статья о том, как можно развернуть нейронную сеть в дерево решений (ссылка), но это далеко от того, что будет действительно всех устраивать)
nikolz
15.07.2023 07:42+2Аналогично, но из области технической диагностики. В одной из бесед с представителем гражданской авиации еще в СССР, я с энтузиазмом рассказывал ему, что можно сделать полностью автоматическую систему ,на основе конечно нейронной сети и самообучения , диагностики самолета в эксплуатации ( в ту пору упали два самолета по причине того, что проморгали трещину в диске турбины и летали пока диск неразорвало. )
А представитель мне и говорит - это все хорошо, но кто подпишет разрешение на взлет, если диагностику будет делать ЭВМ? кто ответит за безопасность полета?
Viroslav_Venskii Автор
15.07.2023 07:42+1Да, регулирование всех современных моделей - это очень важная и актуальная тема) Не даром в последнее время очень много форумов и лекций на тему AI Regulation. Действительно довольно щепетильная и тонкая тема)
sentimentaltrooper
15.07.2023 07:42+1Preventive maintenance сейчас заходит очень хорошо даже небольшим компаниям, обычно в связке с IoT-решением (которое мы вам отдельным проектом разработаем). Техника-то все равно гонять, но если можно спланировать когда, куда и до того как турбина/ котел/ гидравлический цилиндр накроется, то выгода очевидна. А если показать что устройство эксплуатировалось вне рекомендованных условий и съехать с гарантии - вообще красота. Например гидравлический цилиндр грузовика гарантирован на 10 000 циклов, но если вы перегруженный грузовик на косогоре постоянно ставите и возникают боковые нагрузки от чего цилиндр сдох на 4000 циклах.... то клиент (производитель цилиндров) очень сильно нас полюбит за пруфы и сэкономленные $$$ и отдельно за предсказание, что скоро еще один накроется и пора оповестить клиента и предложить пути решений (читай: занести еще денег).
А так да, автономный шатл с парковки концертного комплекса не ездит исключительно потому что никто не хочет лично отвечать: ни разработчик, ни городской чиновник. А посади человека, застрахуй ответственность и никаких проблем. Пока увы так.nikolz
15.07.2023 07:42Когда упал самолет , ныне это Питер, то выяснили, что он успел слетать с трещиной в диске в Новосибирск и возвращался обратно и его разнесло, а это был Ту, а не кукурузник. Погибли все пассажиры и экипаж. А все было банально просто. Пилоты подкручивали показания прибора повышенной вибрации, чтобы тот напрасно не сигналил, ну и доподручивались.
GospodinKolhoznik
15.07.2023 07:42Очевидно, что "подпись" ставит тот, кто получил деньги за внедрение AI/ML системы диагностики. С него и ответственность в случае ЧП.
Viroslav_Venskii Автор
15.07.2023 07:42+1Да, Вы правы! Поэтому сейчас многие компании стараются сделать модели более интерпретируемыми, дабы иметь возможность отслеживать поведение, а также понимать на чём основываются предсказания алгоритмов) Многие не решаются браться на свою компанию ответственность за использование "чёрного ящика".

kaichou
15.07.2023 07:42+2Серьезно? Прям "врываются"?
Историю последнего полувека гораздо более серьёзных работ забыли?
Выглядит как рассказ студента авиационного института про постройку авиетки, когда мир летает на 300-местных лайнерах.
Viroslav_Venskii Автор
15.07.2023 07:42+1Спасибо за комментарий. Цель данной статьи показать разработки нашей лаборатории) Да и в целом для русскоязычного сообщества эта тема актуальна)

AgenSmith
15.07.2023 07:42+2Спасибо за статью!
Вопрос, а по такой схеме в теории разве не должно получится лучше, чем просто обучение с 0 по диагнозам, где нейронка по коротким диагнозам должна понять как работает организм:
Обучаем или берём хорошую общую LLM, чтобы хорошо понимала взаимосвязь слов/текст
Дообучаем на большом корпусе медицинских книжек. Можно даже разбить на несколько частей - обучаем вначале по общей медицине, затем дообучаем узкоспециализированным направлениям, биохимии. Для того чтобы нейронка хорошо знала как устроен и работает организм.
Дообучаем уже на тестовом датасете к конкретной задаче. Чтобы нейронка правильно пользовалась своими знаниями и делала выводы.
Viroslav_Venskii Автор
15.07.2023 07:42+1Вам спасибо за прочтение! Это как раз так и работает, наш Лонгформер был сначала обучен на большом корпусе текстов = общая LLM модель. Потом мы дообучили на медицинских текстах от наших партнёров с помощью Кристофари в течение нескольких месяцев) И уже третий шаг был дообучение под нашу задачу на Бенчмарке. Так что да, Вы всё правильно поняли)
AgenSmith
15.07.2023 07:42Спасибо за разъяснения! А медицинские тексты от ваших партнёров включают общий курс по медицине, скажем так главную базу по работе организма? Думаю тут важный момент. Если это просто разрозненные статьи, то тут даже человеку наверное будет трудно составить общее понимание, а нейронке подавно. Или там базовые учебники включены?
И ещё вопрос - я не оч глубоко разбираюсь в архитектурах, но так понимаю были какие то преимущества у bert перед архитектурой gpt? И существуют ли какие то ещё новые интересные архитектуры которые могут выстрелить в скором?
Viroslav_Venskii Автор
15.07.2023 07:42+1Всегда пожалуйста) Да, мы старались в том числе добавить и базовые учебники по медицине, какие конкретно я сказать в данный момент не могу) По поводу архитектур, Вам, наверное, лучше почитать данную статью ссылка, но попробую ответить кратко и понятно) BERT и GPT - это две разные архитектуры. BERT основан на энкодерной архитектуре, а GPT на декодерной. Энкодерные архитектуры обучаются под другие задачи, нежели декодерные. Когда обучали классический BERT брали две задачи - классификация предложений (идёт ли это предложение следующим после другого) и предсказание замаскированного слова (случайно маскируем слова в тексте и пытаемся их восстановить), поэтому такие архитектуры хорошо могут классифицировать тексты, улавливать взаимосвязь между предложениями, выполнять sentiment analysis и др. А Декодерные архитектуры появились из задачи генерации текста, то есть они отлично подходят под задачу Language Modeling. Поэтому исходя из наших целей было решено выбрать Longformer ( если супер просто, то это RoBERTa + cross-attenton, который позволяет расширить длину контекста, а чем больше контекста, тем лучше). Надеюсь ответил на Ваш вопрос)
А если про новые архитектуры, то крайне интересно выглядит PALMv2 (ссылка), по поводу GPT4 не могу ничего сказать, так как она ещё не вышла) Сейчас много интересных новых архитектур, так что будем пробовать)

MillerJr
15.07.2023 07:42+1Я врач анестезиолог-реаниматолог. Применение ИИ в моей специальности, действительно, имеет огромный потенциал. Ещё лет 20 назад говорили о концепциях мониторинга лабораторных данных, показателях газовой смеси на вдохе/выдохе, инвазивного мониторинга гемодинамики в режиме реального времени с параллельным анализом этих данных машиной в реальном же времени с целью коррекции глубины анестезии, например, или параметров вентиляции пациентов на ИВЛ. Это, безусловно, круто.
Только, как и происходит сейчас во всех отраслях, где ИИ "отбирает работу у людей", работа эта по преимуществу интеллектуальная. Разбудите меня, когда будет создано устройство для интубации трахеи без участия врача. Когда биомеханическая рука сможет катетеризировать центральную вену, или пунктировать спинномозговой канал, или поставить пломбу/сделать аборт/вправить вывих. Вот на это я бы посмотрел )
А пока, удачи с ИИ. Перспективы вырисовываются, конечно, фантастические. Только мне кажется, что для перехода из разряда фантастики требуется в первую очередь переход от государственного финансирования к частным инвестициям. Единственные инновации сколково, действительно поражающие воображение - масштабы и скорость усвоения бюджета.
Viroslav_Venskii Автор
15.07.2023 07:42Спасибо за комментарий, всегда приятно читать комментарии от специалистов из области) Да, все возлагают на ИИ надежды, как на некую "волшебную таблетку". Особенно когда только начали появляться действительно хорошие и качественные модели, мы видели заголовки по типу: "нас всех скоро заменят", "ИИ уничтожит человечество" и др. Сейчас люди постепенно приходят к понимаю, как и где можно применять нейронные сети, как они могут помочь и облегчить работу специалистов. Поэтому мы и позиционируем себя как помощники врачам, а не что-то отдельное и решающее все проблемы.
Перспективы и потенциал огромен, главное понимать, что действительно можно улучшить, а куда лезть не следует) На счёт финансирования не могу точно сказать, что будет лучше. Хотелось бы сказать, что чем больше финансирование, тем лучше, но это не всегда так)
nikolz
реальный диагноз : "сухой кашель"
реальный диагноз : "боль в эпигастрии"
реальный диагноз : "боль в шее"
Это не диагноз, а всего лишь первичные и скорее всего очевидные признаки , по которым ставится диагноз.
Диáгноз (греч. διάγνωσις, лат. diagnosis «распознавание»; от dia «через, посредством» + gnosis «знание») — медицинское заключение о состоянии здоровья обследуемого, а также сущности болезни и состоянии пациента, выраженное в принятой медицинской терминологии и основанное на всестороннем систематическом изучении пациента.