Жизненно важно отслеживать проблемы с производительностью Redis. Для этого инструмента характерна низкая задержка отклика при обслуживании многочисленных запросов. Есть определенные ключевые метрики, которые можно отслеживать для контроля за производительностью вашего экземпляра Redis. В этой статье мы пройдемся по этим метрикам и рассмотрим способы их сбора с помощью встроенных в Redis инструментов.
Что такое Redis?
Redis (Remote Dictionary Server) — это СУБД с открытым исходным кодом и хранением данных в оперативной памяти. У нее много возможных способов применения. Redis разработал Сальваторе Санфилиппо в 2009 году. Это популярная NoSQL-база данных типа «ключ-значение», благодаря хранению в оперативной памяти она может обслуживать данные почти мгновенно.
Для чего можно использовать Redis:
- Кеширование. Самое популярное применение для этой СУБД: её используют в качестве быстрого и высокодоступного кеша приложения, работающие в реальном времени.
- База данных. Redis также используют и как первичную БД. Благодаря этому современные приложения уменьшают сложность их использования с базами вроде DynamoDB.
- Поточный движок. Хранение в оперативной памяти позволяет Redis обслуживать потоки данных.
- Брокер сообщений. Это критически важный компонент масштабных распределенных систем. Redis реализует pub/sub-очередь сообщений, поддерживающую механику сопоставления и различные типы структур данных.
Базы данных играют большую роль в большинстве приложений, поэтому для нас важна любая информация об их производительности. Нужно отслеживать скорость работы и доступность экземпляров Redis. Давайте рассмотрим метрики, которые следует мониторить.
Какие метрики Redis нужно отслеживать
Поскольку Redis хранит данные в оперативной памяти, важно следить за потреблением ресурсов. Также нужно мониторить его производительность с точки зрения пропускной способности или выполненной работы. Метрики можно разделить на категории:
- Производительность
- Память
- Основная активность
Вот навскидку начальный список:
| Производительность | Память | Активность |
| Задержка | Потребление памяти | connected_clients |
| Использование процессора | Степень фрагментации памяти | blocked_clients |
| Доля попаданий в кеш | Вытеснение ключей | connected_slaves |
| total_commands_processed | ||
| keyspace |
В зависимости от способа применения вы можете расширять этот список другими метриками.
Метрики производительности
Снижение производительности БД может стать причиной плохого пользовательского опыта. Производительность Redis можно оценить по уровню задержки, использования процессора, доли попаданий в кеш и других метрик. Рассмотрим подробнее.
Задержка
Это важная метрика для оценки производительности. Она представляет собой время, в течение которого сервер Redis ответил на запросы клиента. Эту СУБД часто используют в задачах, когда требуется обслуживать обращения по требованию.
Redis умеет по-разному отслеживать метрики задержки. Быстрый способ — использовать такую команду:
redis-cli --latency -h 127.0.0.1 -p 6379Этак команда непрерывно регистрирует задержку с помощью пинга и возвращает такой результат:

Какие параметры тут использованы:
-
5611 samples:сколько раз пинговал Redis CLI. В этом случае команда записала 5611 запросов и ответов. -
min:минимальная задержка между отправкой пинга CLI и получением ответа. В этом случае было 0 мс. -
max:максимальная задержка между отправкой пинга CLI и получением ответа. В этом случае было 95 мс. -
avg:среднее время ответа по всем собранным данным. В этом случае было 0,52 мс.
Есть и другие способы мониторинга задержки. В Redis 2.8.13 появился отдельный инструмент. С его помощью можно обнаруживать и устранять возможные проблемы с задержкой.
Использование процессора
Всплески использования процессора Redis’ом могут приводить к задержкам в приложении. Мы вычисляем его на основе процессорного времени: то есть сколько времени процессор обрабатывал задачу. Обычно его выражают в процентах от полной загрузки процессора.
Если вы заметили высокое использование процессора Redis’ом, то нужно изучить ситуацию внимательнее. Рекомендуется задать TTL для ключей, которые должны храниться лишь временно. Также высокое использование процессора может быть связано с командами, которым нужно больше времени на исполнение. Список таких команд можно получить с помощью журнала slowlog.
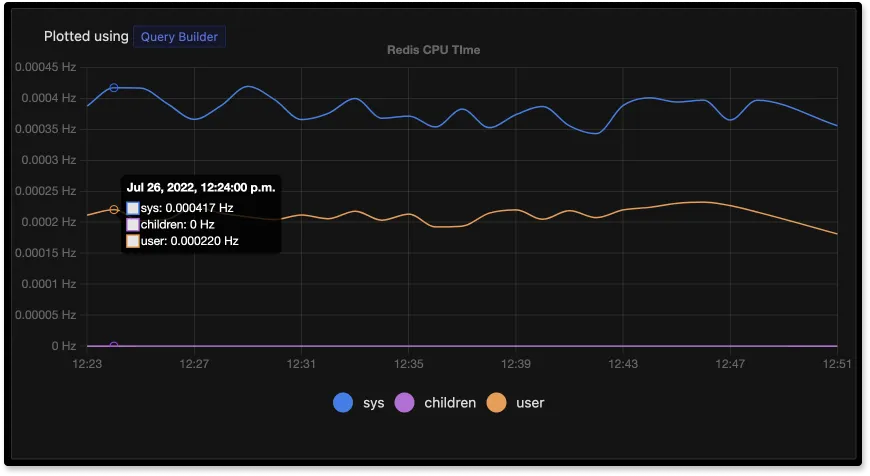
Пример мониторинга процессорного времени
Доля попаданий в кеш
Эта метрика тоже важна для отслеживания производительности, она показывает эффективность использования экземпляра Redis и представляет собой долю успешных попаданий (чтений) от всех операций чтения:
Доля попаданий в кеш = (keyspace_hits)/(keyspace_hits + keyspace_misses)Команда
INFO выводит общее количество keyspace_hits и keyspace_misses.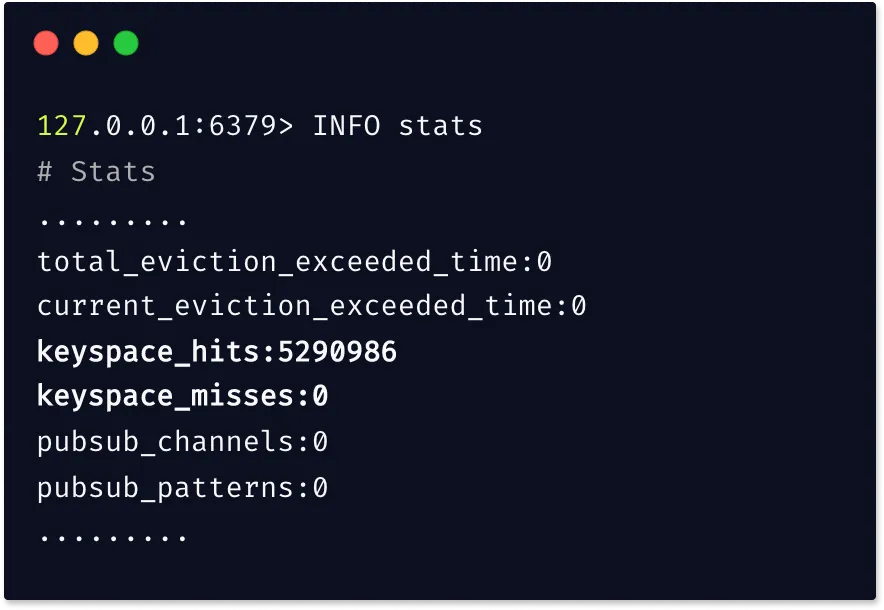
Желательно стремиться к доле попаданий выше 80 %. Если получается ниже, то это говорит о том, что значительное количество ключей устарело или вытеснено. Или говорит о нехватке выделенной памяти, потому что вытеснено большинство ключей. Для мониторинга доли попаданий в кеш рекомендуется использовать отдельный инструмент.
Метрики памяти
Память — критически важный для Redis ресурс, от её количества зависит производительность этой СУБД.
Потребление памяти
Если экземпляр Redis потребляет всю доступную память, это приводит к её подкачке: для освобождения нехватающего объёма часть данных выгружается на диск. А писать и читать с диска гораздо медленнее, чем из памяти, что лишает нас преимуществ Redis, поэтому отслеживайте эту метрику. Также вы можете настроить предел потребления памяти с помощью директивы
maxmemory. Настройки можно задать в файле redis.config или после запуска командойCONFIG SET. Когда объём используемой Redis памяти достигнет заданного предела, вы можете освободить какую-то часть с помощью политик вытеснения ключей.Степень фрагментации памяти
Высокая степень фрагментации может снизить производительность и увеличить задержку. Эта метрика определяется как отношение памяти, выделенной операционной системой, к памяти, используемой Redis. Давайте разберемся.
Операционная система выделяет каждому процессу какой-то объём физической памяти. В идеале, Redis для хранения информации нужны смежные разделы памяти, но если ОС не может найти такие, то она выделит фрагментированную память. А это приведет к её перерасходу. Фрагментацию памяти в Redis можно вычислить как отношение
used_memory_rss к used_memory.-
used_memory_rss:определяется как количество выделенных операционной системой байтов. -
used_memory:определяется как количество выделенных Redis байтов.
Степень фрагментации памяти больше или около 1 считается нормальной. Если меньше 1, то нужно немедленно выделить для Redis больше памяти, иначе он начнёт её подкачивать. Коэффициент больше 1,5 говорит о сильной фрагментации, нужно перезапустить сервер Redis, чтобы это исправить.
Вот результат исполнения команды
info memory:127.0.0.1:6379> info memory
# Memory
used_memory:1463344
used_memory_human:1.40M
used_memory_rss:2211840
used_memory_rss_human:2.11MЗдесь отношение
used_memory и used_memory_rss больше 1,5, значит память сильно фрагментирована. 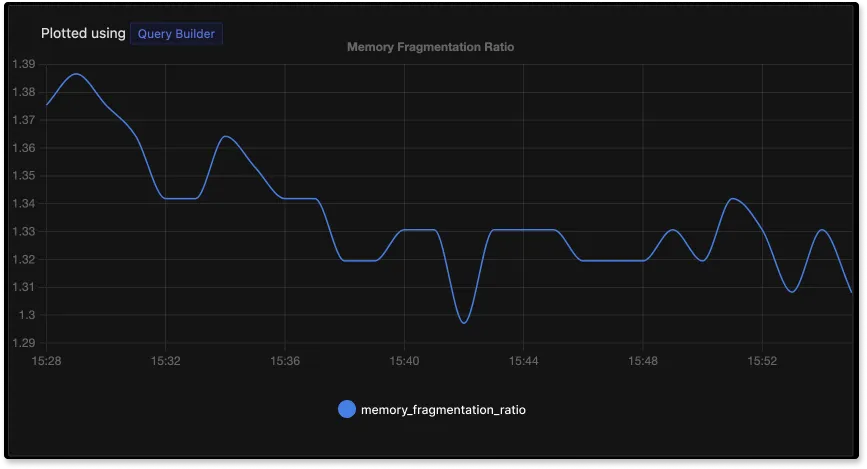
Пример мониторинга фрагментации
Вытеснение ключей
Когда Redis упирается в
max_memory_limit, вам нужно вытеснить ключи с помощью политики вытеснения: процесса автоматического избавления от старых данных по мере добавления новых. Пользователи могут использовать директиву maxmemory, чтобы ограничивать потребление памяти Redis’ом фиксированным значением. После его превышения старые ключи начнут вытесняться. Redis выполняет операции в однопоточном процессе, поэтому повышение скорости вытеснения может увеличить время отклика, и важно мониторить этот параметр.
Пример мониторинга вытеснения ключей
Базовые метрики активности
Кроме метрик производительности и памяти полезно отслеживать некоторые базовые метрики активности экземпляра Redis:
-
connected_clients:количество клиентских подключений (за исключением подключений от реплик). -
blocked_clients:количество клиентов, ожидающих блокирующего вызова. -
connected_slaves:количество подключённых реплик. -
total_commands_processed:общее количество команд, обработанных экземпляром Redis. -
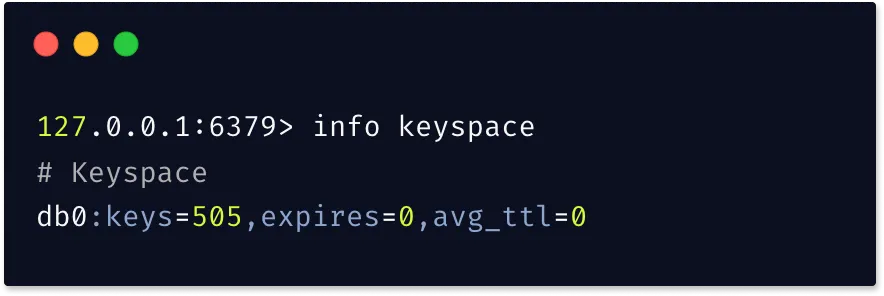
keyspace:один из разделов командыINFO.Важно знать количество ключей в БД, и параметрkeyspaceпредоставляет эту информацию, а также количество устаревших ключей.
Как собирать метрики Redis?
Вы можете получить доступ к стистике сервера Redis с помощью интерфейса командной строки — redis-cli. Команда INFO возвращает много полезной информации о состоянии и производительности работающих экземпляров БД. А на основе предоставленных этой командой метрик вы можете вычислить важные метрики Redis. Выдача INFO состоит из десяти разделов:
- Server
- Clients
- Memory
- Persistence
- stats
- replication
- CPU
- commandstats
- cluster
- keyspace
Если на вашей машине работает экземпляр Redis, вы легко можете получить следующую статистику. Ниже показан результат исполнения команды INFO с параметром server:
~ redis-cli
127.0.0.1:6379> info server
# Server
redis_version:7.0.3
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:b50a789ee26ce984
redis_mode:standalone
os:Darwin 20.6.0 arm64
arch_bits:64
monotonic_clock:POSIX clock_gettime
multiplexing_api:kqueue
atomicvar_api:c11-builtin
gcc_version:4.2.1
process_id:466
process_supervised:no
run_id:05cc64e171ca4cf1febf78e6048c335454ba6e62
tcp_port:6379
server_time_usec:1658387280157495
uptime_in_seconds:90282
uptime_in_days:1
hz:10
configured_hz:10
lru_clock:14220112
executable:/opt/homebrew/opt/redis/bin/redis-server
config_file:/opt/homebrew/etc/redis.conf
io_threads_active:0
127.0.0.1:6379>Redis Latency Monitor
Начиная с версии 2.8.13 в Redis появился инструмент Redis Latency Monitor. Вы можете его использовать для проверки и исправления возможных проблем с задержкой. Сначала нужно настроить пороговое значение задержки в миллисекундах, после чего инструмент будет журналировать все события, блокирующие сервера дольше указанного порога.
Вы можете включить мониторинг задержки во время исполнения Redis на рабочем сервере этой командой:
CONFIG SET latency-monitor-threshold 100После настройки вы можете взаимодействовать с инструментом с помощью набора команд:
-
LATENCY LATEST:возвращает последние задержки для всех событий. -
LATENCY HISTORY:возвращает временные ряды задержек для заданного события. -
LATENCY RESET:сбрасывает временные ряды задержек для одного или нескольких событий. -
LATENCY GRAPH:рисует ASCII-график задержек события. -
LATENCY DOCTOR:выдает удобочитаемый отчет по анализу задержек.
Slowlog
Команду slowlog можно использовать в redis-cli для трассировки и отладки баз данных Redis. Это поможет вам определить запросы, которые выполняются дольше, чем нужно. Пример использования:
127.0.0.1:6379> slowlog help
1) SLOWLOG [ [value] [opt] ...]. Subcommands are:
2) GET []
3) Return top entries from the slowlog (default: 10, -1 mean all).
4) Entries are made of:
5) id, timestamp, time in microseconds, arguments array, client IP and port,
6) client name
7) LEN
8) Return the length of the slowlog.
9) RESET
10) Reset the slowlog.
11) HELP
12) Prints this help.
127.0.0.1:6379>
Заключение
В этой статье мы рассмотрели некоторые ключевые метрики мониторинга Redis. Эта СУБД предлагает несколько встроенных инструментов для получения информации о текущей производительности, что полезно для быстрых проверок или отладки. Но для контроля за работой экземпляров Redis в течение длительного времени вам понадобится отдельная система мониторинга. Если она позволяет хранить, обращаться и визуализировать метрики мониторинга, то вы сможете быстрее решать проблемы с производительностью. Для современных приложения с распределенной архитектурой важно коррелировать метрики Redis с остальной инфраструктурой.
В сервисе #CloudMTS для создания и управления кластерами Redis все нужные метрики отдаются в формате прометеуса. Можно настроить самостоятельный мониторинг, а в скором времени в интерфейсе появятся и полноценные графики.
