Привет, Хабр!
В этой статье затронем тему организации процессов Machine Learning Operations (MLops) в beeline business, особое внимание акцентируем на тестировании моделей машинного обучения. Тестирование мы построили с использованием Gitlab (CI/CD), Mlflow и open-source фреймворка Seldon Core для деплоя REST API или gRPC сервисов с моделями в среде Kubernetes. А пока…
Пару слов про MLops
Ни одна статья про MLops не обходилась без иллюстрации ниже, не будем и мы нарушать традицию.

Итак, под термином MLops принято понимать набор практик на стыке Machine Learning, DevOps и Data Engineer. Цель внедрения MLops-процессов — автоматизация различных этапов разработки, тестирования, внедрения и мониторинга моделей машинного обучения. Часто диаграмма этапов создания ML-решений выглядит следующим образом:

Для создания ML-решения традиционно необходимо пройти следующие шаги, согласно рисунку выше:
подготовка данных;
анализ данных и построение фичей;
построение модели, валидация качества;
внедрение модели в продуктивную среду.
Затем необходимо обслуживать модель в продуктиве: поддерживать сервис с моделью, мониторить качество прогнозов модели, переобучать или дообучать модель, алертить в случае снижение целевых метрик. Автоматизация этих процессов входит в задачи MLops.
Внедрение MLops-практик имеет смысл, когда трудозатраты их внедрения перекрываются пользой от их использования. Например, для компании с незначительной долей проектов с использованием моделей машинного обучения ценность внедрения MLops минимальна.
Напротив, в компаниях с большим зоопарком моделей в различных проектах внедрение MLops-практик – это способ быть конкурентоспособными на рынке. Правильно организованные MLops-процессы позволяют существенно сокращать time-to-market внедрения моделей, осуществлять мониторинг, снижать издержки на другие роли в компании (например, devops инженеров или тестировщиков).
Уровень проникновения MLops в процессы компании может отличаться. Общепризнаны несколько подходов к определению уровня «зрелости» MLops-практик в компании. В Google предложили компактную модель оценки зрелости MLops.
Модель состоит из трёх уровней, каждый характеризуется определенным набором инструментов и автоматизированных процессов:
MLops level 0: Manual process;
MLops level 1: ML pipeline automation:
MLops level 2: CI/CD pipeline automation.
Останавливаться на описании уровней мы не будем, все подробно изложено авторами концепции. Заметим, что нам пока не удавалось увидеть попадания MLops-процессов компании в точное описание одного из уровней. Скорее, указанные уровни стоит воспринимать как условные ориентиры.
Более детальной альтернативой является модель от компании GigaOm. Авторами предлагается оценивать зрелость по пяти критериям:
стратегия;
архитектура;
моделирование;
процессы;
управление.
В каждом критерии достаточно подробно описаны пять уровней зрелости. Ознакомиться можно здесь. Модель от GigaOm более гибкая по сравнению с моделью от Google, ее удобнее использовать для планирования разработки и внедрения MLops-практик в компанию. Также есть модель и от Microsoft и других ИТ-гигантов.
Краткий диагноз для MLops-процессов в компании beeline business звучит так: по критериям от Googlе мы находимся между MLops level 1 и MLops level 2, уверенно приближаясь к автоматизации большинства процессов создания и развертывания ml решений.
Что такое Seldon Core и аналоги
Обсудим, что представляет из себя Seldon Core, и поясним наш выбор именно этой технологии среди конкурентов
Seldon Core
Seldon — это DatаSience-экосистема, в которой предусмотрены эргономичные инструменты для эффективной реализации ML-проектов. Одним из opensource-элементов этой экосистемы является модуль Seldon Core. Seldon Core — это платформа с открытым исходным кодом для простого и быстрого развертывания моделей и экспериментов с возможностью масштабирования сервисов в среде Kubernetes. По сути, Seldon Core является оператором Kubernetes.
Вот кому и зачем он может пригодиться.
Специалисты по анализу данных любят обучать модели, но не все из них любят писать сервисы-оболочки с вызовом моделей. Путь от появления на свет обученной модели до сервиса с интерфейсом доступа к ней может занять довольно много времени. Модель может побывать в руках разработчиков, которые будут писать сервис, devops-инженеров, которые будут заниматься деплоем сервиса, тестировщиков, которые будут его тестировать. Выглядит долго и сложно.
Такие инструменты как Seldon Core упрощают путь от обученной модели до сервиса-интерфейса и делают его равным одному шагу.
В Seldon Core из коробки можно получить:
автомасштабирование сервисов как на CPU (процессоры), так и на GPU (видеокарты);
возможность разворачивания моделей различного типа (tensorflow, pytorch, ONNX, scikitlearn, XGBoost), в том числе с кастомной предобработкой данных;
тестирование сервисов с моделями;
snooze, то есть возможность “тушить” не активные сервисы и “поднимать” при появлении нагрузки;
версионирование сервисов с моделями;
различные сценарии тестирования: canary rollouts, A/B-тесты, shadow deployments;
мониторинг сервисов с моделями;
мониторинг выбросов в данных, которые подаются на вход моделям (Outlier Detector).
Есть ряд похожих инструментов: KFServing, MlFlow Serving, BentoML. По вопросу их сравнения с Seldon Core и между собой написано довольно много материала. Можно посмотреть тут, тут или тут. Мы остановились на Seldon Core из-за наибольшего набора фичей в коробке по сравнению с аналогами, nocode-подхода, и возможности сравнительно легкого развертывания Seldon Core в Kubernetes.
Посмотрим на DS-инфраструктуру в beeline business и место в ней Seldon Core.
DS-инфраструктура
О развитии DS-инфраструктуры и ее внутренностях в beeline подробно можно узнать из докладов наших коллег тут и тут. Подробно мы расскажем об этом и о MLops в компании в одной из следующих статей.
Если кратко, то каждой DS-команде предоставляется рабочая среда, являющаяся namespace в Kubernetes c определенными ресурсными квотами (CPU, RAM, GPU). В каждой рабочей среде развернут Jupiter Hub. В JupyterHub можно поднимать сессии с JupyterLab или VS Code с заданными ресурсами.
Ресурсы выделяются на всю рабочую среду исходя из потребностей команды. В JupyterLab мы проводим обучение моделей и эксперименты над ними, для трекинга экспериментов и хранения моделей используем MlFlow, а для обмена данными - хранилище Ceph. Есть как общие Ceph-директории, доступные всем (например, с python-окружениями), так и командные и персональные. Для бесшовной авторизации в сервисах мы используем Single-Sign-On решение KeyCloak.

Целевое использование большинства моделей – это получение скоров модели в кластере на Hadoop-данных, которые представлены, как правило, в виде Hive-таблиц большого размера. Для этого мы запускали pySpark-скрипты с вычислением модели с помощью планировщика Apache Oozie на Hadoop кластере.
Что мы хотели исправить в данном процессе:
уйти от ручной передачи модели и скоров аналитикам для тестирования корректности вычислений;
уйти от ручной передачи разработчикам моделей в виде сериализованных файлов c данными для валидации деплоя;
внедрить общие для всех команд подходы к тестированию моделей;
в задаче сервинга моделей переехать с Apache Oozie на ArgoWorkflow.
Пункты 2 и 4 мы закрыли внедрением флоу с бесшовным деплоем моделей на основе ArgoWorkflow, Gitlab и MlFlow. Проиллюстрируем зависимости сервисов друг от друга:

DS-эксперименты из JupyterLab логируются в MlFlow. При окончании работы над моделью необходимая информация о модели сохраняется в Gitlab. Для создания типизированного способа хранения информации о модели в Gitlab мы используем фреймворк Cookiecutter. Темплейт репозитория выглядит следующим образом:

Для деплоя моделей мы построили пайплайн на ArgoWorkflow. Упрощенно он выглядит так:
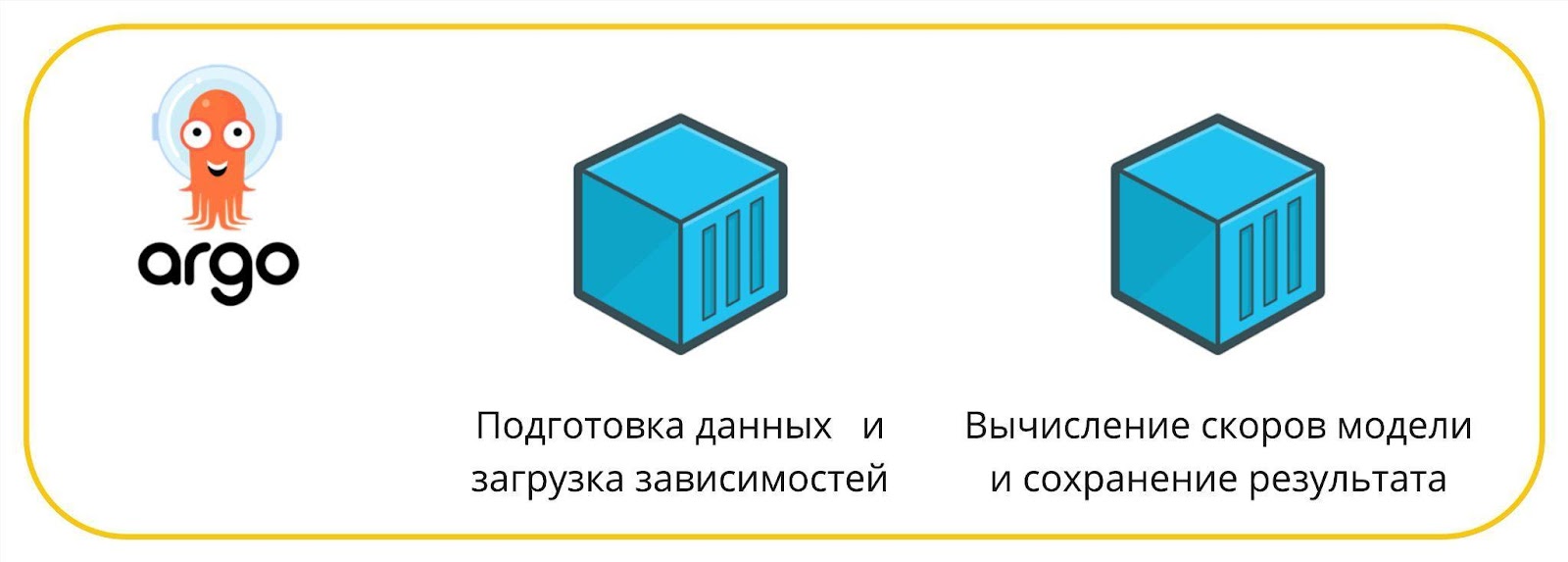
На первом шаге выполняется джоба с подготовкой данных с помощью Hive, а также из MlFlow подгружаются зависимости (requirements.txt) для python-окружения с моделью. Вторым шагом подтягиваются необходимые зависимости из ранее загруженного файла, далее из MfFlow подгружается модель и исполняется pySpark-скрипт с вычислением скоров модели. Результат сохраняется в Hive-таблицу.
Подробнее эту тему мы раскроем в одной из следующих статей, а далее речь пойдет о внедренных подходах тестирования моделей.
Тестирование с помощью Seldon Core
Выше упоминали, что Seldon Core предоставляет возможность легкого развертывания REST API или gRPC сервисов-оберток для моделей. Ввиду того, что для логирования экспериментов и хранения моделей мы используем MlFlow, нам подошел MlFlow Server для деплоя моделей из MlFlow registry.
Модели мы логируем с использованием модуля mlflow.pyfunc, который позволяет сохранять помимо модели еще скрипт с препроцессингом данных для нее. Seldon Core сервис с такой моделью вначале выполнит скрипт препроцессинга данных, затем вычислит скоры модели. В наших процессах такой сценарий представляется весьма удобным, нет необходимости где-то дополнительно хранить код препроцессинга и пользоваться им до подачи данных в модель.
Unit-тесты
При обновлении кода в git-репозитории модели мы настроили исполнения unit-тестов с помощью CI/CD в Gitlab.
Пайплайн в Gitlab выглядит вот так:

На первом шаге выполняется скрипт с подготовкой данных для ML-модели, далее поднимается сервис с нужной моделью и выполняется скрипт вычисления скоров модели и сравнение их с эталоном.
Внедрение unit-тестов позволило нам высвободить ресурсы аналитиков, которым ранее приходилось сверять корректность расчета скоров моделей.
Ретро-тесты
В нескольких продуктовых командах присутствует сценарий взаимодействия с партнерами, при котором партнеру интересно, какое качество продемонстрировали бы наши модели на исторических данных. В таком случае мы получаем от партнера запрос на расчет определенной модели за определенный период времени, затем отдаем партнеру скоры модели для проверки качества. Часто возникала ситуация, когда модель была разработана сравнительно давно, и DS-инженерам приходилось поднимать специальные версии сред для корректного использования ML-модели.
С помощью Seldon-Core мы ушли от практики использования специальных сред и построили следующий пайплайн на ArgoWorkFlow проведения ретро-тестов:
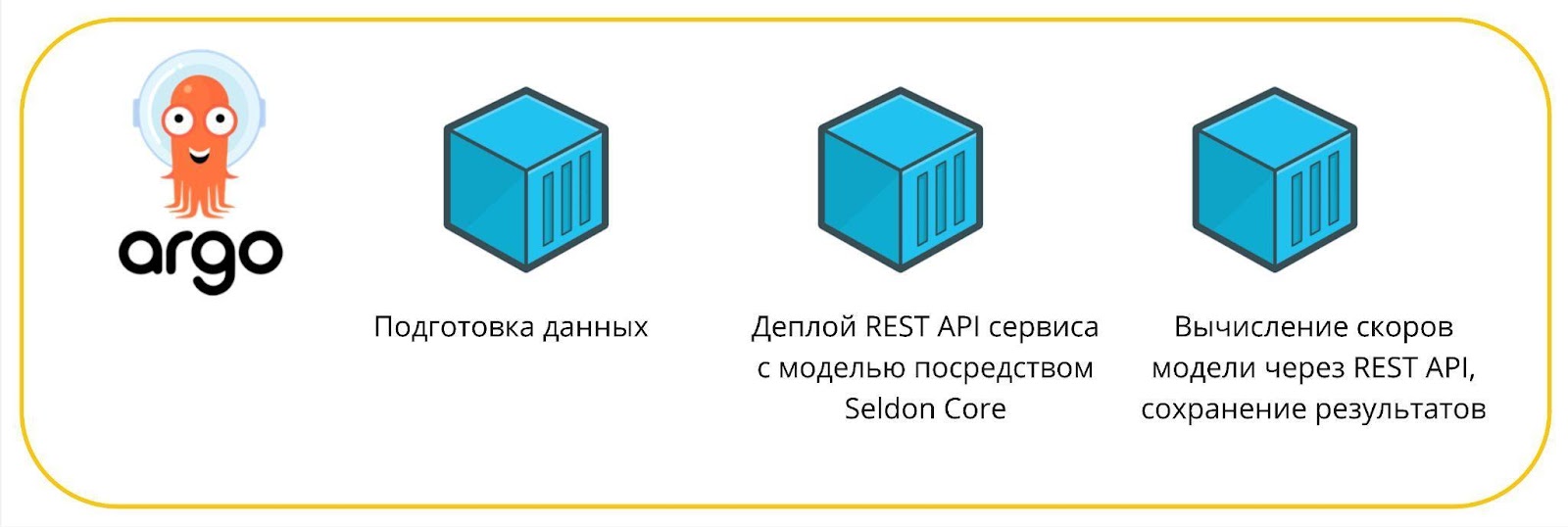
Первым шагом подготавливаем данные для модели, далее поднимаем сервис с REST API интерфейсом к модели, последним шагом вычисляем скоры модели, опрашивая поднятый сервис по REST API, и сохраняем результаты.
Выводы и планы
В заключение подведем промежуточный итог использования Seldon Core в наших MLops-процессах:
внедрение Seldon Core для проведения unit тестов позволило реализовать прозрачный пайплайн на ArgoWorkflow, что привело к исключению аналитиков в задачах проверки корректности использования ml модели;
внедрение Seldon Core для проведения ретро тестов в ArgoWorkflow пайплайне позволило сократить время обработки клиентских запросов.
В дальнейшем мы планируем использовать Seldon Core в качестве интерфейса к моделям во всех внутренних и внешних сервисах, хотим реализовать выкатку различных сценариев тестирования, а также интеграцию Seldon Core с Prometheus для мониторинга нагрузки на сервисы.