
Всем привет! Попробую написать трилогию покорения основ Python, отражающую мой путь любителя с “паяльником”. Тут не будет основ, чистого кода, отсылок к требованиям PEP-8, практически не будет ООП.
Всех суровых Senior’ов, читающих данный материал, прошу понять и простить. Я не работаю и никогда не работал разработчиком (по крайней мере пока, но открыт к предложениям:)), не учил алгоритмов (кроме пузырька) и многого не знаю. Мне просто интересно, как мне кажется, “программировать”, а иногда даже хочется поделиться своим опытом.
Итак, что же мы будем делать. Это будет новостной ТГ-канал - новости в него будут попадать с новостного сайта с RSS-лентой. Администратор сможет модерировать новости, прежде чем они попадут в канал через ТГ-бот. Также возможна реализация автоматического рерайта/перевода новостей при помощи Chat-GPT или иной текстовой AI.
В процессе работы мы “пощупаем” работу с внешними библиотеками (их будет достаточно много) и виртуальным окружением venv, спарсим RSS-ленту и страницу новостей, заглянем в мир асинхронного Python, коснемся основ работы с SQLite и даже попробуем задеплоить нашего бота на VSD-сервер через Docker-контейнер.. если у меня хватит на описание всего этого времени и сил:)
В текущем и будущих постах на Хабр в рамках этого цикла я буду давать ссылки на полезный и нужный, на мой взгляд, тематический материал которым пользовался сам как для изучения основ Python, так и непосредственно для создания этого проекта.
Для хорошего старта всем начинающим и слабо ориентирующимся в синтаксисе Python рекомендую посмотреть вводный курс CS-50. Тут ссылка на свежую версию на-английском, на просторах YouTube есть более древняя, но переведенная на русский версия.
Первым шагом на пути к “мечте” будет выбор сайта, новости с которого мы будем транслировать в ТГ-канал. Для примера возьмем популярный в рунете сайт автоновостей Мотор.
Начнем с парсинга RSS ленты сайта. Что такое RSS можно почитать в Вики. Если кратко - это такой файл, расположенный на сайте, в который попадают ссылки на последние новости с кратким содержанием каждой новости и дополнительными материалами. Все это дано в XML-подобном формате, что существенно упрощает процесс чтения RSS-лент сторонними приложениями. У Мотор есть RSS лента, ссылка на нее - https://motor.ru/exports/rss. Она нам понадобиться совсем скоро, а пока достаем паяльник и припой создаем папку проекта и открываем ее в VSCode. Я буду использовать эту IDE, мне в ней работать удобнее. Вы в праве выбирать ту IDE, которая удобнее вам, например популярный PyCharm.
Поскольку наш проект требует подключения внешних библиотек, крайне рекомендую использовать в вашей IDE виртуальное окружение - venv. Это python со всеми библиотеками работающий только в рамках вашего конкретного проекта. Такой подход дает массу преимуществ - вы не устанавливаете в свою локальную версию python внешние библиотеки, которые могут вызвать в будущем конфликты и как следствие, некорректную работу. Узнать больше о виртуальном окружении Python можно здесь.
Для создания внешнего окружения в VSCode, после создания нового проекта, открываем Терминал и последовательно вводим следующие команды:
python3 -m venv venv - создаем виртуальную копию python в папке venv
source venv/bin/activate - активируем виртуальную среду. При повторном запуске VSCode достаточно ввести эту команду для активации окружения. Для выхода из venv - команду deactivate.
Теперь все библиотеки, которые мы будем устанавливать в рамках проекта через команду pip install будут установлены в виртуальную среду venv.

Чтобы узнать, какие библиотеки используются в проекте, достаточно ввести в терминале команду pip freeze. Поскольку проект у нас пока пустой, запрос ничего не выдаст. Чтобы сохранить информацию о всех установленных библиотеках в рамках проекта, для последующей установки на сервере/другом компьютере, необходимо ввести команду pip freeze > requirements.txt. В файл requirements.txt будут записаны все библиотеки и их зависимости в нужном для команды pip формате, для последующей установки через pip install -r requirements.txt на целевом устройстве.
Приступим к работе с RSS-лентой Мотор'а при помощи Python. Для работы с RSS в Python есть замечательная библиотека feedparser. Также нам понадобится библиотека для работы с GET-запросами - requests. В последующем мы откажемся от нее в пользу асинхронного аналога. Установим библиотеки в виртуальное окружение проекта командой:
pip install requests feedparser
После установки создаем в папке проекта файл bot.py и запишем в него следующий код:
import requests
import feedparser
def main():
rss_link = 'https://motor.ru/exports/rss'
rss_text=requests.get(rss_link).text #Загружаем RSS-ленту
rss = feedparser.parse(rss_text)#Парсим RSS ленту
print(rss.keys())
if __name__ == '__main__':
main()Через GET-запрос, при помощи библиотеки requests, загружаем в переменную rss_text текст из RSS-ленты Мотор'а, после чего парсим ленту библиотекой feedparser в переменную rss. На выходе получается структура данных, близкая к Python'овскому dictionary, ключи который и распечатываем. При удачном стечении обстоятельств, в терминале вы увидите что-то похожее на это:
dict_keys(['bozo', 'entries', 'feed', 'headers', 'encoding', 'version', 'namespaces'])Выше, по отношению к переменной я упомянул "загружаем в переменную", что может сильно покоробить слух профессионалов. В Python в переменную ничего не "загружается" и не "передается", а переменная хранит ссылку на объект с теми или иными данными. Но каждый раз писать это неудобно. Всем начинающим советую почитать что-то вроде этого.
Нам понадобятся записи 'entries'. Посмотрим, из чего они состоят, выведем на печать внутренние ключи и содержание первой новости (под номер 0):
def main():
rss_link = 'https://motor.ru/exports/rss'
rss_text=requests.get(rss_link).text #Загружаем RSS-ленту
rss = feedparser.parse(rss_text)#Парсим RSS ленту
print(rss.entries[0].keys())#выводим ключи
print (rss.entries[0])#выводим первую новостьГлавное здесь - теги, которые есть в новости:
dict_keys(['links', 'link', 'title', 'title_detail', 'summary', 'summary_detail', 'authors', 'author', 'author_detail', 'published', 'published_parsed', 'yandex_full-text', 'content', 'tags', 'yandex_genre'])Для нашего примера достаточно ссылки на новость link и заголовка - title. Почитав новость вы поймете, что стоит за остальными тегами. Пройдемся по коллекции entries при помощи цикла, выведем на печать заголовок новости и ссылку на новость:
def main():
rss_link = 'https://motor.ru/exports/rss'
rss_text=requests.get(rss_link).text #Загружаем RSS-ленту
rss = feedparser.parse(rss_text)#Парсим RSS ленту
for news in rss.entries[::-1]:
title = news['title']
news_link = news['link']
print(f"Заголовок: {title}, Ссылка:{news_link}")На выходе должно получится что-то вроде этого:
...
Заголовок: Камеры в Москве могут начать штрафовать самокатчиков, Ссылка:https://motor.ru/news/scooters-17-10-2023.htm
Заголовок: Журналисты узнали стоимость обновленной Hyundai Sonata в Казахстане, Ссылка:https://motor.ru/news/kz-sonata-17-10-2023.htm
...Отлично, теперь мы можем считывать из RSS ленты заголовок новости и ссылку на нее. В принципе, этого уже достаточно для создания простенького ТГ-бота - нужно лишь зациклить процесс просмотра RSS ленты (например, заходить туда скриптом каждый час) и написать механизм отправки заголовка и ссылки на новость в ТГ-канал. Алгоритм разработки такого бота вы может прочитать на Хабре у @DimaFromMaiтут. В целом, я вдохновился идеей создания бота прочитав его пост и первая версия моего бота как раз базировалась на описанном им алгоритме.
Но "У самурая нет цели только путь". Нагреваем остывший паяльник и идем дальше ковырять наше детище:)
Необходимо написать парсер, который будет по ссылке парсить текст новости. Это может быть полезно, если мы захотим скормить его ChatGPT. Да, я понимаю, что у Motor'a в RSS есть 'title_detail', 'summary', 'summary_detail' и этого вполне достаточно, чтобы получить содержание статьи. Но кто сказал, что вы будете делать свой канал на основе Motor'a? А может вы захотите брать информацию с иностранного сайта, рерайтить ее и переводить в автоматическом режиме? В целом, это важная и нужная опция.
Для парсинга новости воспользуемся библиотекой beautifulsoup. Установим ее командой:
pip install beautifulsoup4
На Хабре и много где еще можно прочитать основы работы с beautifulsoup. Библиотека позволяет искать в коде html страницы нужные теги/классы, например параграфы текста, а также очищать результат от тегов внутри.
Прежде чем парсить страницу, изучим структуру страницы в Chrome DevTool. Для примера возьмем https://motor.ru/news/scooters-17-10-2023.htm. Откроем ее в браузере Google Chrome и включим режим разработчика - на Mac это можно сделать сочетанием клавиш Option + Command + I или пройдя в соответствующее меню. В открывшемся внизу окне необходимо выбрать вкладку "Элементы". Для простоты поиска воспользуемся опцией "Выбрать элемент" - при нажатии на соответствующий элемент на web-странице в окне "Элементы" сразу подсветиться код нужного элемента.
Новостная страница Motor состоит из заголовка, краткого саммари и оставшегося текста новости. Нам, для наших экспериментов нужно взять только саммари и текст новости:
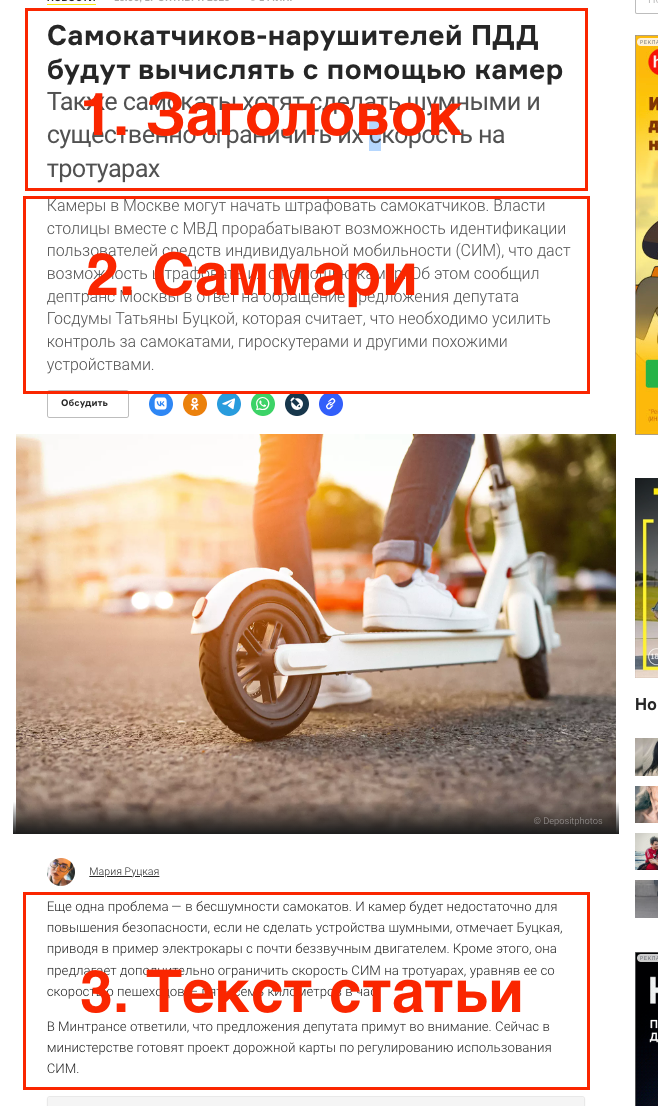
У блока "саммари" мы можем увидеть следующий тег - <p class ="jsx-4260339384">...</p>:

А текстовые блоки имеют теги <p class ="jsx-2193584331">...</p>:

Этой информации достаточно, чтобы написать парсер на BS. Создадим в папке нашего проекта отдельный файл parse.py и добавим в него следующий код:
import requests
from bs4 import BeautifulSoup as bs
def parse(link):
page = requests.get(link)
soup = bs(page.text, "html.parser")
#загружаем саммари
summary = soup.find('p', class_='jsx-4260339384').text
#загружаем все блоки с основным текстом из новости
body = "\n".join([p.text for p in soup.find_all('p', class_='jsx-2193584331')])
return summary + "\n" + body
def main():
text = parse('https://motor.ru/news/scooters-17-10-2023.htm')
print(text)
if __name__ == '__main__':
main()Создадим отдельную процедуру parse(link), которая будет возвращать уже чистый текст статьи по ссылке без заголовка.
Переменная summary получает ссылку на объект, содержащий чистый текст заголовка - конструкция soup.find('p', class_='jsx-4260339384').text как раз находит параграф с классом jsx-4260339384 и очищает его от внутренних тегов.
С парсингом тегов с основным текстом чуть сложнее. В BS есть специальная функция - find_all для поиска всех одинаковых тегов на странице. Однако у нее нет опции возвращения чистого текста - поскольку результатом работы find_all является коллекция объектов. По этой причине проходимся по коллекции циклом for и объединяем каждый абзаца через знак переноса строки "\n". В итоге переменная body ссылается на string объект чистого текста из тегов class_='jsx-2193584331'.
Командой return возвращаем конкатенированные саммари и основной текст через знак переноса строки "\n".
Полагаю, что для первой части трилогии (я даже пока не знаю, умещу ли я все задуманное в 3 части) уже достаточно. Сегодня мы:
Познакомились с виртуальным окружением venv
Спарсили RSS ленту Мотор'а при помощи библиотеки feedparser
Спарсили новостную страницу Мотор'а при помощи библиотеки beautifulsoup
Сделали два "кирпичика" для будущего бота, которые придется еще не раз дорабатывать "молотком"
Готовый пример того, что можно получить на выходе - ТГ Канал Электромобили и инфраструктура https://t.me/el_vehicles.
Комментарии (4)

MAXH0
25.10.2023 14:53+1Как написать статью на ресурс для программистов(хотя уже наверное бывший ресурс для программистов) ,если ты не программист и получить Инвайт!

kotov666
25.10.2023 14:53Может плохо ищу, но перерыл весь интернет, а как допустим не телеграмм канал парсить, а допустим если на сайте обновилась RSS лента то по ссылки скачивается страница и сохраняется в PDF формате, очень удобно для оффлайн. Допустим на планшете установил и пусть он периодически статьи сохраняет, а потом в дороге когда нет интернета можно почитать. Только надо чтоб сохранялась полностью страница со всеми изображениями (видео конечно не надо).

NIKTO56
25.10.2023 14:53Только начала изучать Python. Тема мне интересна, так как специализировалась ранее на социальных сетях. Добавила в закладки.
PixelSun
Кинула в закладки, буду ждать продолжения)