Всем привет!
Сегодня в нашем эфире новый автор - Никита Синкевич, руководитель группы анализа и реагирования Инженерного центра Angara Security. Итак, начинаем!
Иногда в ходе расследования инцидента информационной безопасности необходимо понять, имеет ли та или иная программа вредоносное воздействие на систему. Если для данной программы у вас нет исходного кода, то приходится применять метод исследования "обратная разработка", или Reverse Engineering. Я покажу, что такое "обратная разработка" на примере задания "RE-101" с ресурса cyberdefenders.
CyberDefenders — это платформа для развития навыков blue team по обнаружению и противодействию компьютерным угрозам. В этой статье будет разбор последней, шестой подзадачи из задания "RE-101". На мой взгляд, она лучше раскрывает процесс реверс-инжиниринга, чем остальные: нам предстоит восстановить из исполняемого файла кастомный алгоритм шифрования, написать скрипт-дешифратор и расшифровать флаг.
Используемые инструменты
Detect it Easy
IDA
Python3
Notepad++
Задание
Описание намекает, что в предложенном файле malware201 кто-то реализовал свой собственный криптографический алгоритм.

Запустим DiE и посмотрим информацию о файле из задания:

Видим, что это 64-разрядный исполняемый файл для Linux никакого протектора и упаковщика DiE не нашел, – это радует.
Теперь запустим программу:

Программа ничего не запрашивает, просто выводит две строчки: зашифрованный флаг и строку-подсказку, скорее всего, это строчка из исходного кода данного ПО.
Загрузим файл в IDAx64. Перед нами функция main(), разобьем ее на блоки следующим образом:

Разберем каждый блок по отдельности.
Блок 1.
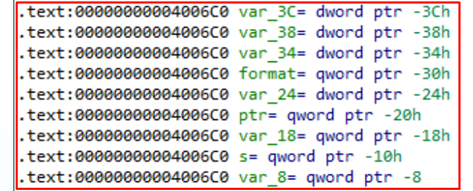
В этом блоке определяются смещения в памяти, потом они будут использоваться для определения места хранения данных в процессе работы программы.
Блок 2. Пролог функции

Это пролог, он отвечает за настройку среды функции. Первая инструкция сохраняет rbp (также называемый указателем кадра) в стеке.
Это сделано для того, чтобы его можно было восстановить после возврата из функции. В следующей инструкции значение rsp копируется в rbp, в результате и rsp, и rbp указывают на вершину стека.
rbp теперь будет хранить фиксированный адрес, и программа будет использовать rbp для ссылки на аргументы функции и локальные переменные. sub rsp, 40h уменьшает значение регистра rsp, таким образом, выделяется место (64 байта) для локальных переменных.
Блок 3 Вывод строки

Команда “mov rdi offset aTheEncryptedFl” помещает указатель на строку <The encrypted flag is: \"> в регистр rdi.
Регистр rdi используется для передачи первого аргумента в функцию. Аналогично работает следующая команда – в регистр rax помещается адрес некоторой метки unk_40082B, после чего значение rax сохраняется в памяти по адресу rbp+var_8, а в регистр al помещается 0 “mov al, 0”, чтобы последующий вызов функции printf отработал корректно. Последняя команда в данном блоке вызывает функцию printf передавая ей из rdi адрес строки aTheenc.
Данный блок можно описать одной строкой на более высокоуровневом языке программирования. Уверен, что здесь очень хорошо подошел бы C++, но навыков работы с ним у меня не хватает, поэтому я буду писать C-подобный псевдокод, который дальше будет магическим образом с помощью спецсредств преобразован в нормальную программу на C++.
Итак: псевдокод printf(“The encypted flag is: \“”);Блок 4. Вызов функции sub_4005B0
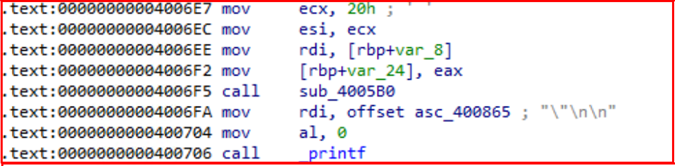
Первые две команды помещают в регистры ecx и esi значение 2016=3210. Регистр rsi используется для передачи второго аргумента в функцию.
Затем в rdi помещают значение из памяти по адресу rbp+var_8. Вспомним, что там находится адрес метки unk_40082B, который был туда помещен командой из предыдущего блока. Предпоследняя команда сохраняет значение eax в памяти по адресу rbp+var_24, это нужно, потому что последующий возврат функции sub_4005B0 перезапишет eax и предыдущие данные будут потеряны.
Представим данный блок в виде еще одной строки псевдокода: sub_4005B0(&unk_40082B, 32);Посмотрим, что хранится в &unk_40082B.
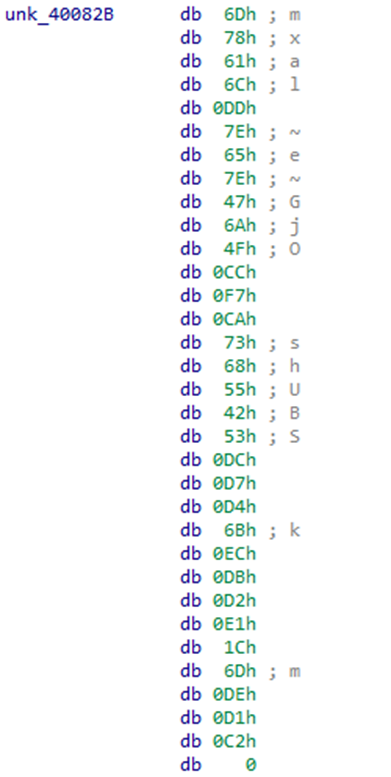
Видим массив из 32 байт, завершаемый нулем, который выводится при запуске программы. Это флаг, который нужно будет расшифровать. Дадим этому массиву имя flag.

Чтобы преобразовать этот массив в символы, скопируем первую строку вывода программы в notepad++ и удалим символы “\x”.
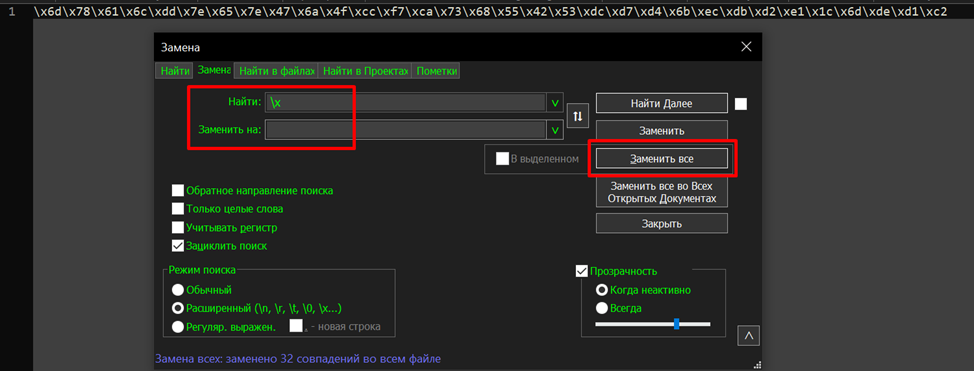
Получится такая строка.

Теперь с помощью ресурса gchq.github.io/CyberChef/ и операции “From Hex” преобразуем ее в символы.

Полученная символьная строка будет нужна для восстановления исходного кода программы.
На данном этапе можно предположить, что функция sub_4005B0 нужна для вывода строки в определенном формате. Дадим ей название printing. Для этого выделяем функцию sub_4005B0, нажимаем N и вводим название.

Псевдокод: printing (flag, 32);
Блок 5. Вывод строки

Так же как и блок 3, данный блок выводит строку <”\n\n>Псевдокод: printf("\"\n\n");
Блок 6. Вызов функции strlen
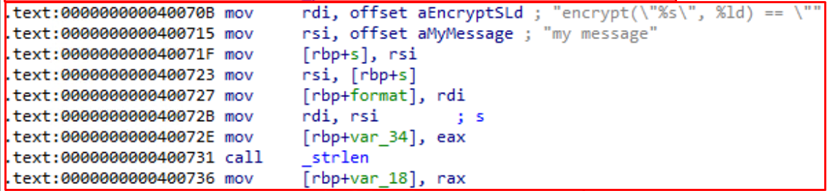
Первые две инструкции записывают адреса строк <encrypt(\"%s\", %ld) == \"> и <my message> в регистры rdi и rsi соответственно.
Следующие три инструкции сохраняют адрес строки <my message> в память по адресу rbp+s и адрес строки <encrypt(\"%s\", %ld) == \"> в память по адресу rbp+format. Затем в регистр rdi записывается адрес строки <my message>, после чего значение eax сохраняется в память по адресу rbp+var_34 и вызывается функция strlen, которая на вход приняла строку с rdi и результат записала в rax. Заключающая инструкция в этом блоке сохраняет значение rax в память по адресу rbp+var_18.
Псевдокод: var_18 = strlen(“my message”);Переименуем var_18 в len_message
Блок 7. Вывод строки в определенном формате

Первые три инструкции помещают в регистры rsi, rdx и rdi адрес строки <my message>, длину строки <my message> и адрес строки <encrypt(\"%s\", %ld) == \"> соответственно, после чего вызывается функция printf.
Напомню, что регистр rdi используется для передачи в функцию первого аргумента, rsi – второго, а rdx – третьего.
Псевдокод: printf("encrypt(\"%s\", %ld) == \"", "my message", len_message);Данный код выводит следующий участок строки:

Блок 8. Вызов функции sub_400620

Первые две инструкции передают в rdi и rsi адрес строки <my message> и ее длину соответственно, после чего происходит вызов sub_400620 с сохранением результата в память по адресу rbp+ptr.
Назовем эту функцию encrypt, так же, как и в выводе программы.

Псевдокод: ptr = encrypt ("my message", len_message);
Блок 9. Вызов функции printing (sub_4005B0)

В этом блоке снова вызывается функция sub_4005B0, но уже с другими аргументами.
Первый аргумент – результат работы предыдущей функции, хранящийся по адресу rbp+ptr. Второй аргумент – длина строки <my message>.
Псевдокод: printing (ptr, len_message);Блок 10. Вывод строки

Так же, как и блоки 3,5, данный блок выводит строку <\”\n>Псевдокод: printf("\"\n");
Блок 11. Освобождение выделенной памяти

Здесь в rdi сохраняется результат работы (скорее всего это будет указатель) функции encrypt и передается как аргумент функции free. Псевдокод: free(ptr);
Блок 12. Эпилог функции

Эпилог предназначен для действий, обратных прологу. xor eax, eax устанавливает значение eax равным 0.
Это возвращаемое значение (return 0). add rsp, 40h возвращает rsp в положение, которое было до пролога.
Это очистка стека.pop rbp восстанавливает старый rbp из стека.
Псевдокод: return 0;Объединим все ранее написанные строки в единую программу:int main() { // скорее всего это указатель, тип данных пусть будет int
int len_message;
int *ptr;
char flag[32] = mxalÝ~e~GjOÌ÷ÊshUBSÜ×ÔkìÛÒámÞÑÂ;
printf(“The encypted flag is: \“”);
printing (flag, 32);
printf("\"\n\n");
len_message = strlen(“my message”);
printf("encrypt(\"%s\", %ld) == \"", "my message", len_message);
ptr = encrypt ("my message", len_message);
printing (ptr, len_message);
printf("\"\n");
free(ptr);
return 0;
}Из листинга программы можно увидеть, что из main вызываются две пока неизвестные функции: printing и encrypt.
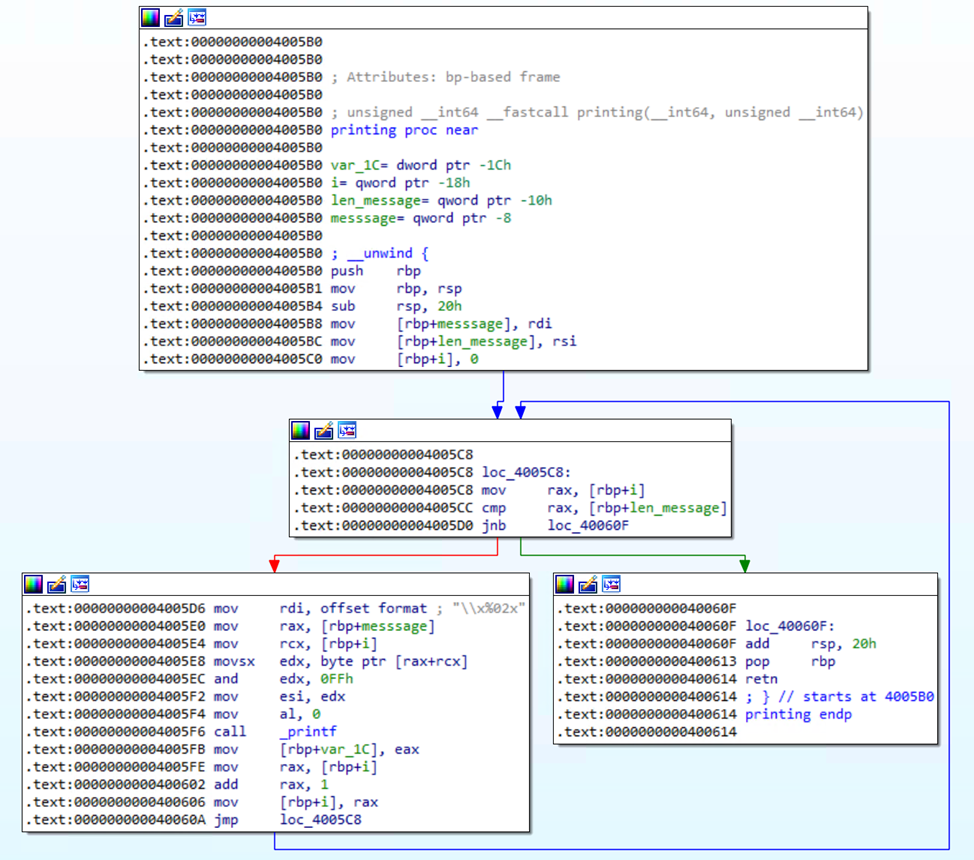
IDA разбила код на блоки, потому что инструкции в данной функции могут выполняться нелинейно. Если присмотреться, то можно увидеть цикл. Я дал названия переменным, чтобы было проще ориентироваться в коде.
Блок 1. Пролог, выделение памяти для переменных, сохранение аргументов

В первом блоке выделяется память под переменную цикла и переменных, которые предназначены для аргументов, переданных в данную функцию. Первый аргумент передан в регистр rdi – это указатель на строку message, второй аргумент передан в регистр rdi – это число, которое соответствует длине строки.
Блок 2. Предусловие
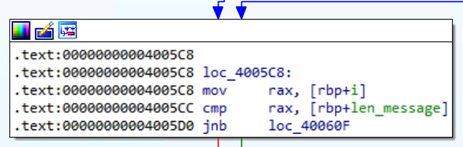
Второй блок представляет собой предусловие цикла: здесь сравнивается (cmp) переменная цикла i и переменная len_message, которая содержит в себе длину переданной строки.
Инструкция JNB (Jump if Not Below) выполняет переход, если первый операнд НЕ меньше второго (то есть больше или равен второму) при выполнении команды cmp. Таким образом, если i больше либо равно len_message, условие будет удовлетворено и выполнится выход из цикла (переход по зеленой стрелочке). В противном случае переход не случится и выполнение продолжится в теле цикла.
Блок 3. Тело цикла
Разобьем его на две части следующим образом:
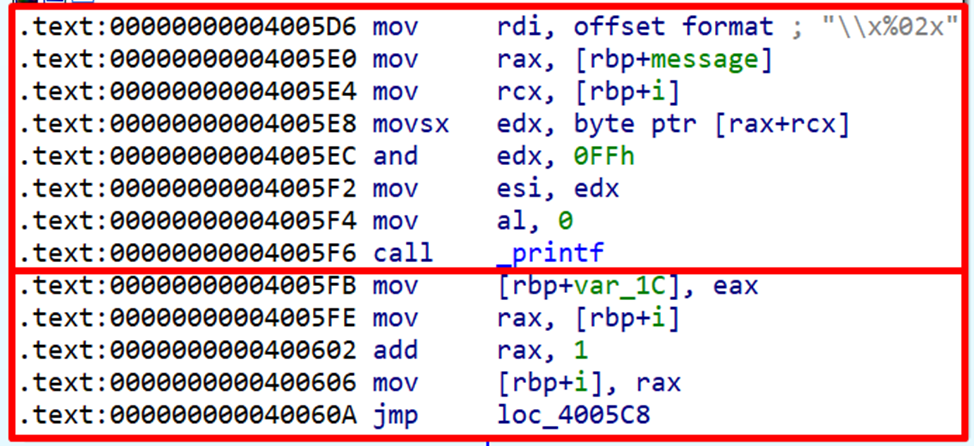
В первой части вызывается функция _printf с аргументами, список ниже.
1. rdi – указатель на строку < \\x%02x >;
2. esi – указатель на i-тый байт строки message. Он получается в результате:
2.1. перемещения в rax указателя на строку message: mov rax, [rbp+message]
2.2. перемещения в rcx значения переменной i: mov rcx, [rbp+i]
2.3. увеличения адреса указателя на значение переменной цикла: rax+rcx
2.4. перемещения в rdx значения одного байта, расположенного по адресу rax+rcx: movsx edx, byte ptr [rax+rcx]
2.5. перемещения в esi значения edx
Таким образом, данная часть выводит i-тый байт строки message в формате \х00.
Вторая часть этого блока увеличивает переменную i на 1 и осуществляет переход в предыдущий блок с условием, запуская следующую итерацию цикла.
Блок 4. Эпилог функции
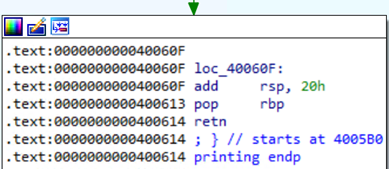
Четвертый блок представляет собой эпилог функции и возврат из нее.
Таким образом, мы поняли, что данная функция предназначена для последовательного вывода байтов переданной строки в определенном формате.
Псевдокод:
void printing (message, len_message){
for (int i = 0; i< len_message; i++){
printf(“\\x%02”, *(message + i));
}
}Анализ функции encrypt

Данная функция по структуре напоминает предыдущую – здесь тоже есть цикл. Я также дал названия переменным, чтобы было проще ориентироваться в коде.
Блок 1.

В данном блоке вызывается calloc с аргументами rdi = len_message и rsi = 1. Данная функция выделяет пространство для хранения массива из len_message элементов, каждый из которых имеет размер 1 байт и равен нулю. Указатель на данный массив сохраняется в rax, а затем помещается в переменную encrypted_message. Крайняя инструкция в данном блоке инициализирует переменную цикла i=0.
Блок 2. Предусловие

Данный блок, так же, как и аналогичный блок предыдущей функции, выполняет переход, если первый операнд больше или равен второму. Т.е. если i меньше len_message будет выполнено тело цикла (переход по красной стрелочке).
Блок 3. Тело цикла

И вот мы подобрались к самому интересному: в этом блоке реализован алгоритм шифрования.
Разобравшись в логике работы данного блока, мы сможем написать программу-дешифратор.
Разберем данный блок подробнее:
1. В ecx записывается FF.
2. В eax помещается значение i-го элемента массива message.
3. Для данного элемента выполняется побитовый сдвиг влево на 1(инструкция shl).
4. Для этого же элемента выполняется операция логического ИЛИ с единицей.
5. Результат из eax помещается в переменную part.
6. В rax помещается переменная цикла i и делится на rcx=FF (значение было присвоено в п.1), результат деления записывается в rax, в rdx записывается остаток от деления.
7. Для rdx выполняется операция логического ИЛИ с 0A0.
8. Для переменной part выполняется операция “исключающее ИЛИ” с rdx, результат записывается в rcx.
9. Результат из предыдущего пункта записывается в i-ый байт массива encrypted_message.
10. К переменной цикла прибавляется единица.
11. Переход в Блок 2.
Блок 4. Эпилог функции

В данном блоке в rax помещается указатель на массив encrypted_message, что позволяет вернуть это значение при выходе из функции, затем следуют стандартные инструкции очистки стека и восстановления старого rbp из стека.
Псевдокод:
int encrypt(message, len_message){
char *encrypted_message;
for (int i = 0; i < len_message; i++){
encrypted_message[i] = ( ( ( i % 0xFF ) | 0xA0) ^ ( ( message[i] << 1) | 1 ) )
}
return encrypted_message;
}Написание скрипта-дешифратора
В данном случае успешная расшифровка сообщения произойдет, если мы сможем узнать, чему равно message[i] из 3-го блока функции encrypt для любого i. Для этого нужно понять, какая информация у нас есть изначально. Итак, что мы знаем:
1. Переменную цикла - i. Изначально она равна нулю и увеличивается при каждой следующей итерации цикла на 1.
2. Каждый элемент зашифрованного сообщения - encrypted_message[i] и длину этого сообщения - len_message, так как у нас это сообщение есть.
Теперь, если взглянуть на данную строчку, выделив известные переменные и искомую message[i]:
encrypted_message[i] = ( ( ( i % 0xFF ) | 0xA0) ^ ( ( message[i]) << 1) | 1 ) )
У нас получается своеобразное уравнение с одной неизвестной – X, где a = encrypted_message[i], b = ( i % 0xFF ) | 0xA0
a = b ^ X, ввиду особенности XOR: A XOR (A XOR B) = B, его можно привести к следующему виду:
X = a ^ b, что соответствует ( message[i] << 1 ) | 1 = encrypted_message[i] ^ ( ( i % 0xFF ) | 0xA0 )

Осталось разобраться с (message[i] << 1 ) | 1. Здесь для message[i] применяется:
1. Сдвиг влево
2. Изменение первого бита на 1
Возьмем для примера символ J. В таблице ascii он имеет код 4A16, что соответствует значению 10010102

Получается, для того, чтобы получить исходное значение, достаточно произвести сдвиг вправо или произвести деление на 102. Оба этих действия будут иметь одинаковый эффект – удаление младшего бита. Осталось реализовать данную логику в python. Код представлен ниже:
Python3:
# Зашифрованный флагencrypted_flag = "\x6d\x78\x61\x6c\xdd\x7e\x65\x7e\x47\x6a\x4f\xcc\xf7\xca\x73\x68\x55\x42\x53\xdc\xd7\xd4\x6b\xec\xdb\xd2\xe1\x1c\x6d\xde\xd1\xc2"
# Преобразование каждого символа в шестнадцатеричное число, а затем в десятичноеdecimal_array = [int(hex(ord(char)), 16) for char in encrypted_flag]
# Создание переменной для расшифрованного флагаflag = ""
# Главный циклfor i in range (len(decimal_array)):
# Выполнение XOR для выделения нужной частиpart = ((i % 0xFF) | 0xA0) ^ int(decimal_array[i])
# Удаление последнего бита, преобразование числа в символflag += (chr (part // 2) )# Вывод расшифрованного файлаprint(flag)
После выполнения данного скрипта, будет выведен флаг:flag<malwar3-3ncryp710n-15-Sh17>
# Создание переменной для расшифрованного флагаflag = ""# Главный циклfor i in range (len(decimal_array)):# Выполнение XOR для выделения нужной частиpart = ((i % 0xFF) | 0xA0) ^ int(decimal_array[i])
# Удаление последнего бита, преобразование числа в символflag += (chr (part // 2) )
# Вывод расшифрованного файлаprint(flag)
После выполнения данного скрипта, будет выведен флаг:flag<malwar3-3ncryp710n-15-Sh17>
Восстановление исходного кода программы:
Еще помните про псевдокод? Так вот, его можно легко переписать на C++ с помощью ChatGPT. Я использовал следующий запрос:
#include <cstdio>
#include <string>
using namespace std;
void printing (message, len_message){
for (int i = 0; i< len_message; i++){
printf("\\x%02", *(message + i));
}
}
int encrypt(message, len_message){
char *encrypted_message;
for (int i = 0; i < len_message; i++){
encrypted_message[i] = ( ( ( i % 0xFF ) | 0xA0) ^ ( (2 * * message[i]) | 1 ) )
}
return encrypted_message;
}
int main() {
int len_message;
int *ptr;
string flag[32] = "mxalÝ~e~GjOÌ÷ÊshUBSÜ×ÔkìÛÒá mÞÑÂ";
printf("The encypted flag is: \"");
printing (flag, 32);
printf("\"\n\n");
len_message = strlen("my message");
printf("encrypt(\"%s\", %ld) == \"", "my message", len_message);
ptr = encrypt ("my message", len_message);
printing (ptr, len_message);
printf("\"\n");
free(ptr);
return 0;
}
Преобразуй в нормальный кодПосле ответа ChatGPT и незначительных поправок получился вот такой код
C++:
#include <cstdio>
#include <cstring>
using namespace std;
void printing(const char* message, int len_message) {
for (int i = 0; i < len_message; i++) {
printf("\\x%02x", static_cast<unsigned char>(message[i]));
}
}
char* encrypt(const char* message, int len_message) {
char* encrypted_message = new char[len_message];
for (int i = 0; i < len_message; i++) {
encrypted_message[i] = (((i % 0xFF) | 0xA0) ^ ((message[i] << 1) | 1));
}
return encrypted_message;
}
int main() {
const char flag[] = "mxalÝ~e~GjOÌ÷ÊshUBSÜ×ÔkìÛÒá mÞÑÂ";
printf("The encypted flag is: \"");
printing(flag, 32);
printf("\"\n\n");
const char* message = "my message";
int len_message = strlen(message);
printf("encrypt(\"%s\", %d) == \"", message, len_message);
char* encrypted_message = encrypt(message, len_message);
printing(encrypted_message, len_message);
printf("\"\n");
delete[] encrypted_message;
return 0;
}Он нормально скомпилировался и запустился. Вывод получившейся программы идентичен выводу первоначальной программы, так что можно считать, что мы успешно восстановили исходный код.

Заключение
Мы успешно выполнили реверс-инжиниринг программы, восстановили ее исходный код, и на основе полученных данных смогли написать скрипт-дешифратор.
Также хочу отметить, что в задачах с восстановлением исходного кода может помочь искусственный интеллект, что поможет реверсеру сохранить немного (а, может, и много) драгоценного времени.
Спасибо за интерес, проявленный к данной статье!
Если у вас возникли какие-либо замечания или вопросы, буду рад ответить в комментариях. До новых встреч!
Комментарии (8)

sekuzmin
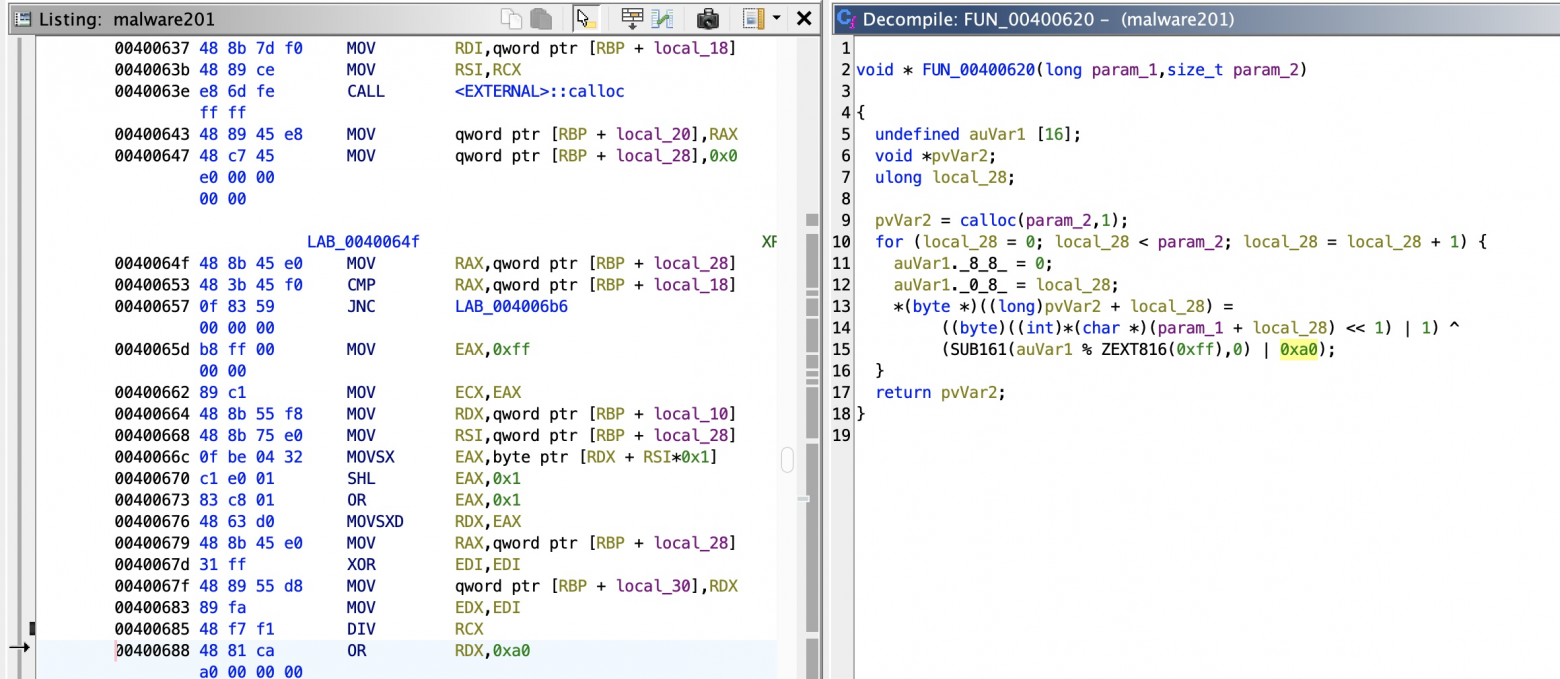
30.11.2023 18:45+2Не проще Ghidra успользовать?


AngaraSecurity Автор
30.11.2023 18:45+1Даем комментарий Никиты
По поводу первого скрина:
Декомпилятор действительно, упрощает жизнь, вы правы, но я его не стал использовать, потому что целью данной статьи было разобраться, как на низком уровне выглядит программа, как выглядят функции, циклы и т.д. и как может произойти восстановление исходника. Автоматический декомпилятор немного опускает эти моменты.
По второму скрину:
Если честно, не знал про данную возможность, обязательно возьму на вооружение, спасибо!
greg0r0
30.11.2023 18:45+1Для IDA то же самое делает выделение нужных байт (или поставить курсор на имя данных) и нажать SHIFT+E


pfemidi
Дожили! Теперь чтобы расставить отступы стали обращаться к ChatGPT. Куда катится этот мир?
GennPen
Не только отступы, еще и преобразование псевдокода в полноценный код.
AngaraSecurity Автор
Ответ от нашего автора:
Понимаю Ваш скепсис, этот момент может выглядеть не очень серьезно, но я все же решил добавить его в статью, потому что искусственный интеллект очень помог выполнить необходимые преобразования в коде, и это стало частью процесса реверса.
GennPen
Лично я не против. Если есть инструменты облегчающие разработку, то почему бы ими не пользоваться?