
Что входит в обязанности промпт-инженера?
Prompt Engineer — очень перспективная профессия. На рынке труда, в том числе российском, появляется всё больше вакансий с солидной зарплатой. Удивительно, но к специалистам в этой области, как правило, нет конкретных требований. Иногда кажется, что некоторые компании ищут промпт-инженеров, просто чтобы соответствовать тренду. Недавно я видел в одном из объявлений такой пассаж: «...Будет преимуществом опыт работы на смежной позиции (продактом, дата-сайентистом, разработчиком) и знание Python…».
Если всё перечисленное — только преимущество, то что тогда считать требованиями? Ручное написание промптов и проверка качества на глаз? Для личного использования это работает, но речь идёт о том, что спроектированный промпт будет внедрён в сервис компании, и значит, он будет использоваться потенциально тысячи раз. Что если с какой-то вероятностью он выдает недопустимые ответы?
Мы должны задаться вопросом: «Как часто и насколько хорошо промпт справляется с задачей?». Чтобы дать на это ответ, потребуется отправлять много запросов к LLM с нашей инструкцией и смотреть на результаты. То есть, собирать и анализировать данные.
К счастью, сегодня уже можно найти библиотеки, которые предлагают инструменты для автоматизации тестирования промптов. Одна из них — с подробной документацией и большим количеством полезных методов — называется promptfoo. Именно её мы и будем использовать.
Процесс проектирование промпта
На мой взгляд, алгоритм проектирования промпта должен выглядеть примерно так:
1. Определение целей и ограничений.
2. Написание чернового варианта промпта.
3. Написание тестов для этого промпта.
4. Итерации обратная связь/изменение промпта.
5. Финальная проверка на статистически значимом количестве экспериментов.
Чтобы работа была более наглядной, мы будем следовать этому пайплайну, реализуя чат-бота для онлайн-магазина одежды.
1. Определение целей и ограничений. Нам нужно, чтобы чат-бот давал пользователям всю вложенную в него информацию без каких-либо галлюцинаций. Он должен правильно передавать заявленные в ассортименте названия вещей, цены и размеры, помогать решать стандартные ситуации и не поддерживать общение на сторонние темы.
2. Написание чернового варианта промпта. Первый вариант промпта (далее жирным шрифтом выделены непосредственно инструкции, остальное — модули вложенной информации):
«Ты являешься диспетчером техподдержки магазина одежды N3VERZzz. Чтобы валидно ответить на следующий вопрос: "{{input}}", используйследующую информацию:
[Информация о Бренде N3VERZzz]
[Ассортимент Магазина]
[Информация о Доставке]
[Политика Возврата]
[Скидки и Акции]
[Способы Обратной Связи]
[Контактная Информация]
[Инструкция для Ответов] — Отвечай на вопросы прямо и кратко. Не повторяй вопрос в ответе.[Инструкции для Запросов не по теме] — Если интенция запроса НЕ попадает ни в одну из перечисленных категорий, задавай уточняющие вопросы и напоминай, что ты являешься диспетчером техподдержки магазина одежды N3VERZzz.[Инструкции по сложным запросам] — Для сложных вопросов, требующих комбинации информации из разных категорий, старайся агрегировать данные так, чтобы ответ был полным и точным. Использу доступную информацию из всех соответствующих разделов для формирования краткого и информативного ответа.
[Примеры Ответов] »
3. Написание тестов. Теперь нам нужно протестировать этот промпт с помощью библиотеки promptfoo. Чаще всего я пользуюсь следующими методами:
— Метод "contains" проверяет ответ LLM на наличие определенного значения. Поскольку этот метод учитывает регистр букв, его удобно использовать для проверки ожидаемых в ответе числительных.
— Метод "regex" предназначен для проверки соответствия выходных данных заданному регулярному выражению. Регулярные выражения позволяют задавать сложные правила поиска и обработки текста. Например, можно проверить, упоминается ли в тексте Санкт-Петербург в разных падежах.
— Метод "llm-rubric" проверяет выходные данные, используя встроенную LLM. Этот метод анализирует текст и оценивает его на предмет соответствия заявленным указаниям.
Почти все проверки можно реализовать, используя только метод "llm-rubric". Но здесь есть нюансы. Например, проверка на «человекоподобное поведение» может пройти успешно, хотя в ответе прямым текстом будет написано «поскольку я являюсь искусственным интеллектом». Похоже, что основная цель такой проверки - убедиться в релевантности ответа, а не в том, как искусственный интеллект определяет свою идентичность.
Давайте напишем первые тесты:
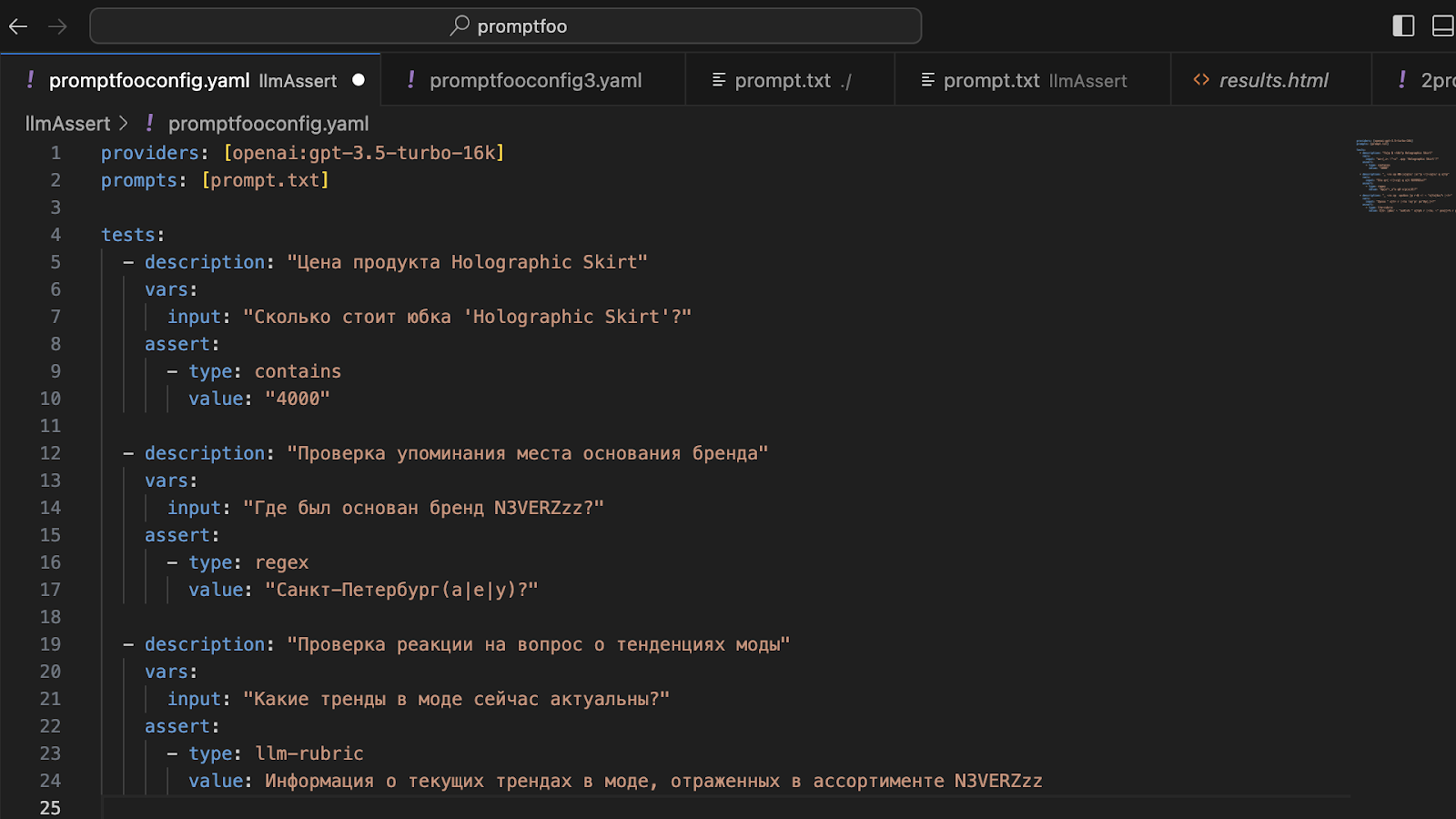
Так выглядит наш файл. В providers выбираем модель для тестирования, в prompts передаем файл, в котором находится промпт.
Отобразить результаты тестов можно в удобном формате:
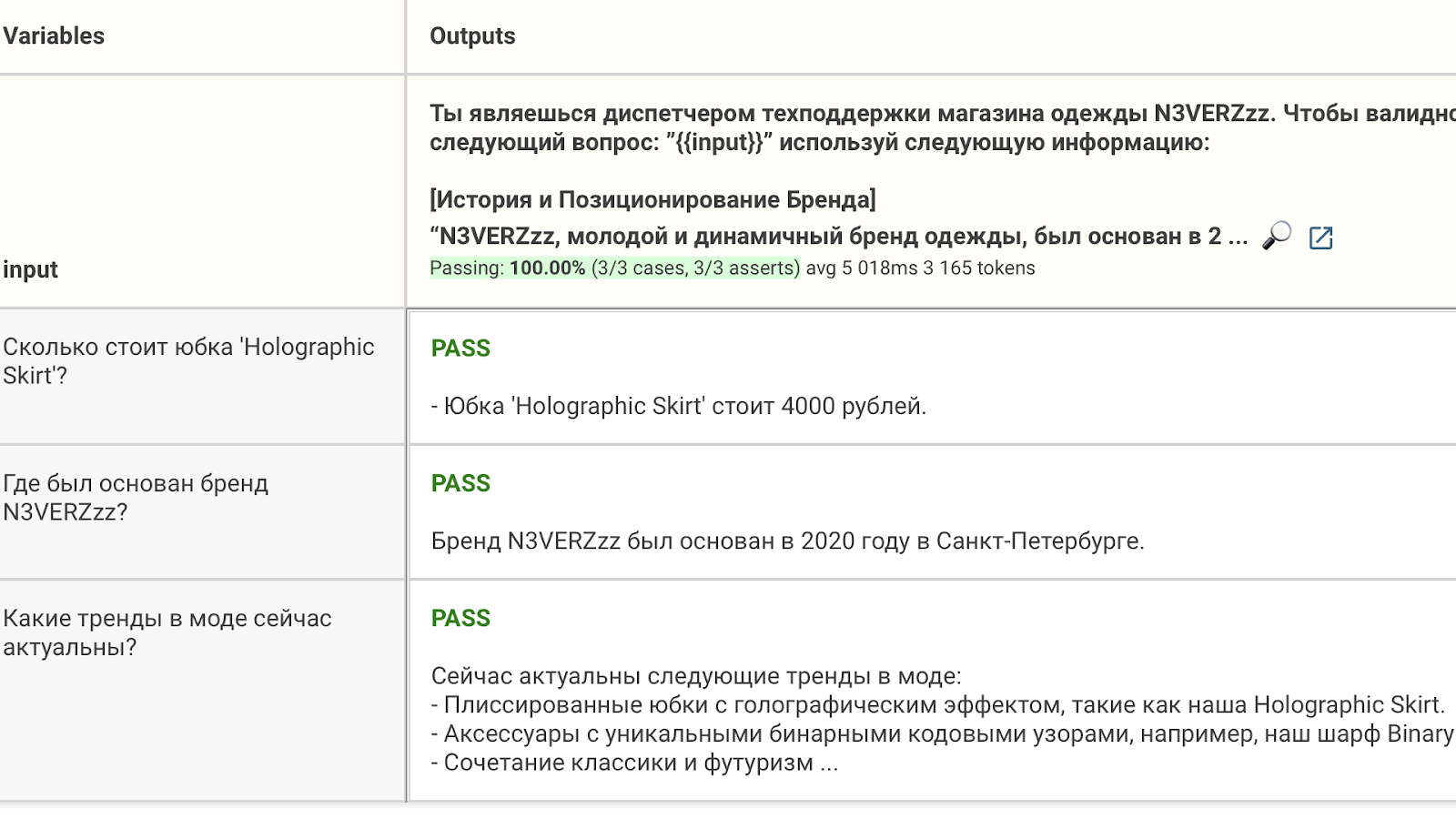
4. Итерации обратная связь/изменение промпта. Пока я работал с этим промптом, было очень много итераций 'тест-правка-тест'. Расскажу про самые интересные ошибки и решения.
Периодически ответ LLM начинался с повторения вопроса. Это было топорно и слегка комично — модель будто размышляла вслух. Кажется, я полностью избавился от этого, добавив в инструкцию для ответов input и дополнительное описание ситуации.
Изначально было так:
[Инструкция для Ответов] — Отвечай на вопросы прямо и кратко. Не повторяй вопрос в ответе.
Такое изменение убрало корявости в ответе:
[Инструкция для Ответов] — Отвечай на вопросы прямо и кратко. Не повторяй вопрос: «{{input}}» в ответе.
Еще один интересный случай произошел с запросом о WhatsApp. Хотя в инструкции единственной указанной социальной сетью был YouTube, LLM подтвердила, что с нашим брендом можно связаться через мессенджер. Дело в том, что в инструкции был дан номер горячей линии, и LLM проявила инициативу, соединив номер телефона с мессенджером.
Конечно, такая дезинформация как минимум разозлила бы пользователя. Эту проблему очень просто решить: нужно прописать, что нет никаких других социальных сетей и мессенджеров, кроме указанных. Но кажется, что понятия, лежащие в концептуальном поле близко друг к другу, будут неизбежно срастаться, и заблаговременно понять, где это произойдет, невозможно. Полностью обезопасить себя от этого не получится, и лучший совет здесь — делать больше тестов и внимательно смотреть на ответы.
5. Финальная проверка. Поскольку этот промпт не является коммерческим проектом, я решил не реализовывать полноценную проверку на статистически значимом количестве экспериментов. Я остановился на тестировании базового функционала, написав в общей сложности 59 тестов. К сожалению, у меня так и не получилось полностью ограничить LLM в ответах на темы, не касающиеся магазина. Как бы я ни запрещал это делать, лояльный GPT хочет поделиться советом. Это достаточно сложная задача (может быть, для GPT-3.5).

При работе с LLM можно установить «температуру» креативности. Если мы выставим её на ноль, то в генерации всегда будет отдаваться предпочтение следующему токену с наибольшим процентом вероятности выхода. Таким образом, на одинаковые вопросы будут одинаковые ответы. Поскольку LLM, имплементированные в сервисы, должны работать с вложенной информацией, в большинстве кейсов предпочтение будет отдаваться повторяемости ответов, а не их креативности. Это значит, что температуру будут выкручивать на ноль, и запускать один и тот же тест два раза будет бессмысленно. Придется писать очень большое количество разнообразных тестов.
Здесь может помочь генерация текста: предоставить LLM текст промпта и уже написанные тесты с указанием сделать нечто похожее. Потом добавить эти тесты, проверить их и повторить операцию еще раз.
Почему это важно?
Во время написания этой статьи я постоянно ловил себя на том, что говорю очевидные вещи. Я продолжал работу только потому, что не нашел никого, кто бы высказал эту точку зрения.
Мы наблюдаем зачаток новой профессии, поэтому сейчас в этой области нет стандартов. Впереди много исследований и открытий, которые через время сформируют эту область. Кажется, если промпт-инженер станет промпт-аналитиком, это не только многократно увеличит его вклад, но и даст возможность говорить с отделом разработки на одном языке. Значит, улучшится координация команды. Все это станет возможным и даже закономерным, если к промптам начнут относиться как к абстрактным программам.
Промпт — это абстрактная программа. Поскольку промпт — программа, мы должны его тестировать. Нужно понимать, решает ли он поставленную задачу. Если решает, не вызывают ли они попутно какие-то другие косвенные проблемы. Поскольку это абстрактная программа, мы должны тестировать его более тщательно, чем код.
Ключевой аспект тестирования промптов — это учет субъективности естественного языка. Важно понимать, что промпт является определенного рода линзой, надетой на LLM. Мы тестируем возможный реестр ответов, а не один ответ.
_______________________________
Ссылка на документацию promptfoo: https://promptfoo.dev/docs/intro
По всем вопросам пишите мне в телеграм.
Комментарии (31)

Corporatech2000
09.12.2023 12:12В чем смысл и польза для бизнеса от этого костыля ?

N3VERZzz Автор
09.12.2023 12:12Да, в настоящее время от этого костыля может не быть явной пользы. Однако мы понимаем, куда движется развитие технологий: следующее поколение LLM, возможно, будет обладать достаточной стабильностью для выполнения подобных задач. Косвенная выгода заключается в том, что компании, которые уже сегодня начинают работать с этими технологиями, смогут легко и быстро внедрить подобные инструменты в будущем.

bezdnacom
09.12.2023 12:12Кажется что-то подобное говорили про блокчейн... Напомните, где он сейчас?
N3VERZzz Автор
09.12.2023 12:12Я считаю сравнение таких вещей абсурдным. Блокчейн является достаточно противоестественной для человека идеей однорангового строения общества; эта система бросает вызов устоявшимся институтам, которые так просто не уступят место. Для меня удивительно, что это вообще смогло как-то функционировать. Искусственный интеллект, в свою очередь, это инструмент, который в ближайшем будущем действительно сможет выполнять большую часть рутинной работы. Если вы являетесь пользователем GPT, то, вы видели какой скачок произошел от версии 3.5 до 4, он поистине внушительный. Вам сложно поверить, что прогресс продолжится? Или что вызывает у вас такие сомнения?
bezdnacom
09.12.2023 12:12Я не отрицаю прогресс, наоборот я ему очень рад и использовал и ChatGPT и другие LLM. Но есть нюанс: именно из-за того что прогресс не стоит на месте профессия промпт-инженера видится туманной. Во-первых, нет и не может быть универсальных подходов к промпт-инжинирнгу, потому что каждая LLM уникальна. Во-вторых, с каждым новым поколением они все лучше и лучше начнут понимать человека и без всяких "докруток".
N3VERZzz Автор
09.12.2023 12:121) Да, профессия промпт-инженера сейчас может казаться несколько туманной, но, как я уже отмечал в моем предыдущем ответе о косвенных выгодах для компаний, первыми мастерами в этой области, когда она прояснится, станут те, кто уже сейчас увлеченно занимается ею.
2) Когда мы достигнем точки, где LLM будут понимать запросы без каких-либо дополнительных доработок, это будет означать не только исчезновение профессии промпт-инженера, но и всех других профессий тоже)bezdnacom
09.12.2023 12:12Так как вы будете своих "мастеров" тренировать? Моделей целая куча, а если учитывать еще и параметры для этих моделей (Temperature, Top-P, Top-K и т.д.), то это миллионы вариантов. Еще раз повторю свой первый пункт, который вы проигнорировали: моделей очень много и работа с каждой из них уникальна и никакого универсального способа работы нет и быть не может.
N3VERZzz Автор
09.12.2023 12:12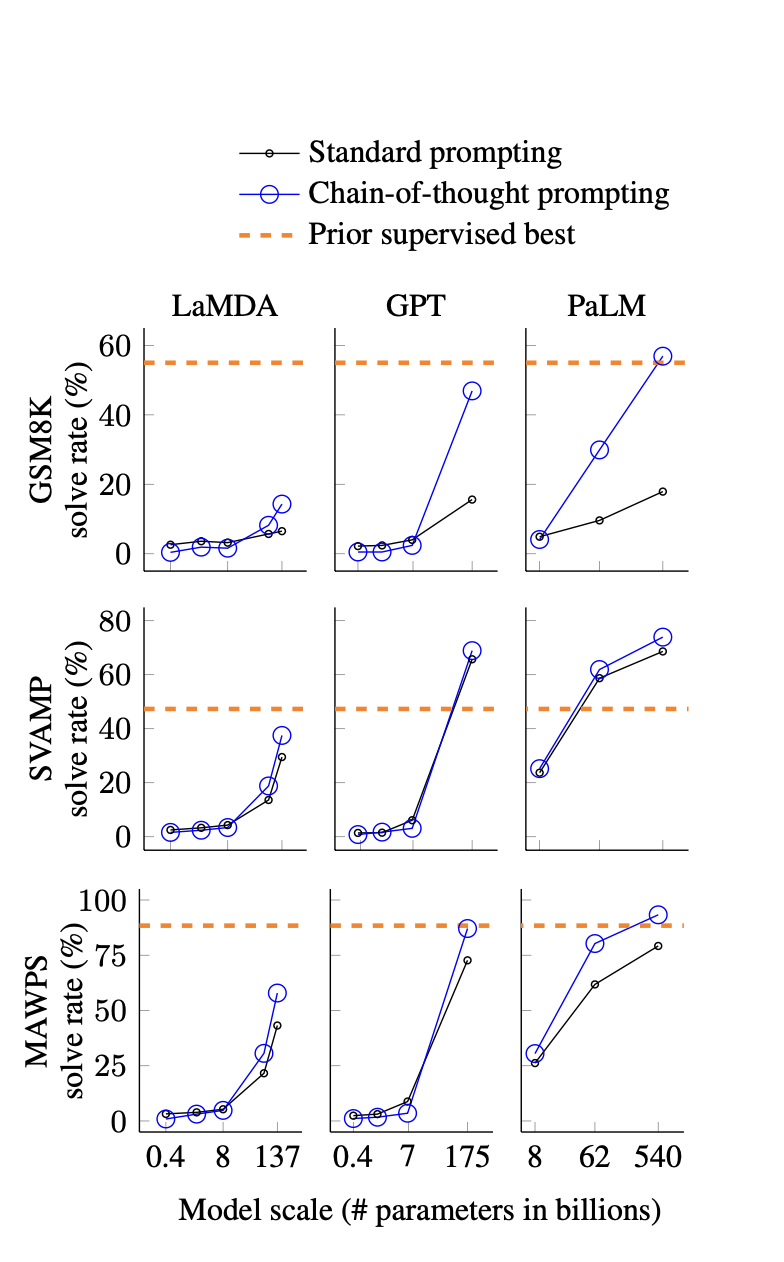
Такие как подходы как "chain-of-thought", тестируются на разных моделях, и, как вы можете видеть, они эффективны для всех представленных больших языковых моделей, хотя и с разной степенью успешности. В целом, мы должны повторно тестировать промпт, если планируем использовать его в другой LLM. Однако, я не думаю, что при равном количестве параметров у разных моделей результаты будут существенно отличаться (конечно, речь идет о статистически значимом количестве экспериментов.) Прикладываю ссылку на исследование.
bezdnacom
09.12.2023 12:12Предоставленный вами метод значительно эффективнее "standard prompting" только в 3-х из 9 случаев. В остальных вариантах он не сильно отличается от обычного, так в чем смысл?
Во-вторых, исследование проведено на LaMDA, PaLM и некоем "Finetuned GPT-3 175B". Я могу быть не прав, но это достаточно старые модели и к ним конечно могут быть применимы "хаки" для улучшения ответа. Однако, с момента публикации данной бумаги уже вышла в свет GPT-4 и недавно вышла Turbo версия, а на момент написания уже была GPT-3.5, но вместо неё почему-то взяли что-то иное. Я уже молчу про OpenChat-3.5 который имея 7B параметров умудряется быть на уровне мартовской GTP-3.5 (по заявлению авторов, лично я с ней мало работал).
>>Однако, я не думаю, что при равном количестве параметров у разных моделей результаты будут существенно отличаться
Это конечно сильное заявление, учитывая что каждая модель тренируется на уникальных данных с применением уникальных техник и, что логично, выдает разный результат на один и тот же запрос. А вы по сути хотите найти master-key для всей моделей. КМК тянет на нобелевку.N3VERZzz Автор
09.12.2023 12:12Моя идея заключается в следующем: некоторые концепции промптов демонстрируют статистически значимое улучшение результатов потому, что они обращаются к определенным способам мышления или человеческим триггерам, которые проникают в модели через естественный язык. Так, метод "цепочка мыслей" эффективен, потому что люди, формулирующие тексты в таком стиле, реже допускают ошибки. Каким-то образом в модели просачивается и эмоциональная составляющая, условно когда от качества статьи зависит увольнение журналиста, он старается писать лучше.
Поэтому я считаю, что подсказка, хорошо работающая в одной модели, не покажет ужасных результатов в другой, если у них примерно равное количество параметров. Я понимаю, что мое объяснение этого явления может казаться поверхностным. Мне интересно услышать ваше мнение, почему одна и та же подсказка может работать кардинально противоположно в разных системах. Было бы еще лучше, если бы вы нашли исследования, подтверждающие это.bezdnacom
09.12.2023 12:12Я понимаю, что мое объяснение этого явления может казаться поверхностным.
Оно таковым и является: "каким-то образом" что-то куда-то просачивается это не научный язык, а догадки, требующие подтверждения.
Мне интересно услышать ваше мнение, почему одна и та же подсказка может работать кардинально противоположно в разных системах.
Я так не говорил. Я говорил, что оно может выдавать (а чаще всего так и делает) другой результат. Другой != противоположный.
Было бы еще лучше, если бы вы нашли исследования, подтверждающие это.
Честно признаюсь, я дилетант в данной тематике. Читаю нескольких людей которые понимают в этой тематике больше моего и их мнение в том что промпт-инжиниринг это сомнительная идея. Вы пришли на Хабр со своей идеей так что бремя доказательства лежит на вас. Если у вас есть еще какие-то исследования на эту тематику, буду рад посмотреть!
Небольшой примечание: Вы привели исследование в ответ на мое сообщение, за что конечно спасибо, но... При этом, по моим ощущениям, вы проигнорировали первые два абзаца и отвечаете только на последний.
N3VERZzz Автор
09.12.2023 12:12моделей очень много и работа с каждой из них уникальна и никакого универсального способа работы нет и быть не может.
Я хотел опровергнуть именно эту позицию, сложно отвечать на все, при этом ничего не опуская. Постараюсь в ближайшее время посмотреть подобные исследования и собрать какое-то количество скринов, как тот, который я показал раньше. Это сможет вас убедить в том, что есть универсальные способы работы с LLM?
bezdnacom
09.12.2023 12:12Может тогда лучше оформить это все в отдельную статью и выложить на Хабре? С пояснением своей позиции и приведенными примерами, мне кажется это бы не только мою позицию бы поменяло но чью-то другую.
N3VERZzz Автор
09.12.2023 12:12Читаю нескольких людей которые понимают в этой тематике больше моего и их мнение в том что промпт-инжиниринг это сомнительная идея.
Можешь дать ссылки на этих людей? Для меня идея промптинга не является сумасшедшей, и я не слышал прям явных противников. Хотелось бы ознакомиться с их позицией, если это и правда распространённое мнение, то можно было бы написать

Le0Wolf
09.12.2023 12:12Пользовался обеими версиями. Был период, когда 3.5 в моих кейсах отвечал лучше, чем 4. Сейчас к 4 доступа не имею, но 3.5 теперь откровенно тупит. К примеру, на вопрос "как сделать х, не используя у" может ответить ровно с точностью до наоборот и убедить в том, что так делать не надо вообще не получится


vagon333
09.12.2023 12:12Удивительно, но к специалистам в этой области, как правило, нет конкретных требований.
Сложно создать требования - зыбкая почва:
- Если в мае 2023 промпт на GPT4 при нулевой температуре выдавал один результат, то в ноябре сильно отличается
- Если до ноября 2023 приходилось разбивать большой текст на сегменты чтоб можно было обработать в GPT4 8k токенов, то сейчас можно передать до 128к и получить до 4к в ответ.
- Если в мае GPT4 не "срезал углы", то сейчас филонит на 2к+ токенов и приходится подстраивать промпт.
На такой болотистой почве сложно сформулировать формальные требования промпт-спецу.
Для меня достаточно просто запросить примеры промтов чтоб понять, насколько чел. внимателен к деталям.N3VERZzz Автор
09.12.2023 12:12Как вы могли понять из прочитанной статьи, моя позиция по этому вопросу следующая: требования должны включать минимальное техническое образование и владение языком программирования Python, чтобы нанятый сотрудник мог провести исследование по поводу необходимого промпта и представить его результаты в Jupyter Notebook.
Внимание к деталям - что это? Очень субъективный критерий. Важнее смотреть не на формулировку промпта, а на качество получаемых от него ответов. Год назад идея эмоционального давления на языковые модели многим показалось бы идиотской. Однако было доказано, что это работает. То есть, вы могли бы отклонить кандидатуру промпт гения, который пишет капсом и слезно умоляет LLM потому, что он не уделяет внимание деталям (тем субъективным деталям, которым уделяете внимание вы).
vagon333
09.12.2023 12:12Внимание к деталям - что это? Очень субъективный критерий.
...То есть, вы могли бы отклонить кандидатуру промпт гения, который пишет капсом и слезно умоляет LLM потому, что он не уделяет внимание деталям (тем субъективным деталям, которым уделяете внимание вы).
Вы вроде за меня придумали, что в моем понимании "внимание к деталям". :)
Удачи в дискуссиях.N3VERZzz Автор
09.12.2023 12:12Мне показалось, что это как раз то самое неуместное эмпирическое определение качества промпта, о котором я говорю в статье. Если вы имели в виду другое, простите.

seojuf
09.12.2023 12:12Почему вы не используете метод langchain + бд?
Вроде удобнее, меньше глюков.
N3VERZzz Автор
09.12.2023 12:12Проблема промптинга остается актуальной, даже при использовании баз данных для извлечения релевантной информации. Необходимость в проверенной инструкции не исчезает, она просто переходит на другой уровень.

conopus
09.12.2023 12:12Вы использовали LLM для написания ответа на комментарии?
N3VERZzz Автор
09.12.2023 12:12Спасибо за ваш комментарий! Исходя из той информации, которую вы видите, действительно естественно предположить, что я использую языковую модель искусственного интеллекта для создания ответов. Эти модели могут обрабатывать запросы и предоставлять подробные, хорошо структурированные ответы на самые разнообразные темы. ????????
akakoychenko
Если вдуматься, то стремное утверждение. Учитывая способность ллм забывать начало промпта при его разрастании, вангую, что такие боты будут изнашиваться и ржаветь по мере разрастания промпта из-за вписывания туда новых и новых кейсов, где можно факапнуться. Brand-new бот, только что из под пера промпт инженера, будет куда лучше работать, чем такой же, но поэксплуатированный год, и за этот год накопивший 1000 уточнений от менеджеров на стороне заказчика.
Интересно, нельзя ли как-то хотя-бы разделить разные топики по промптам, и поставить классификатор (возможно, тоже ЛЛМный) на входе?
Чтобы каждое сообщение сначала классифицировалось, а лишь потом отправлялось на специализированного бота, который, например, знает только ассортимент и складские запасы, или только доставку, или только тенденции моды, чтобы, хоть не портить качество ответов в несмежных сферах при разрастании уточнений?
N3VERZzz Автор
Опять же, это только предположения и интуитивные ощущения, чтобы утверждать что-то, нам нужно параллельно сравнить эти два промпта и понять, какой из них лучше себя показывает. Мой личный опыт на сравнительно небольшом количестве данных показал, что указание в инструкции, что связаться по WhatsApp нельзя, работает лучше, чем если оставить это без комментариев. Также хочу отметить, что нет необходимости указывать, что все остальные социальные сети отсутствуют (кроме Телеграма), потому что эта легкая галлюцинация связана с слиянием очень близких смысловых зон. Номер телефона, так сказать, стойко ассоциируется с менеджером. Вполне возможно, что при наложении всевозможных ограничений LLM будет терять контекст и справляться со своей задачей хуже, но в противном случае мы оставляем промпт в таком состоянии, в котором он просто не работает.
Что касается классификатора, это отличная идея, но надо подумать, как работать с межмодульными запросами типа: "что если я куплю шарф и юбку, получу ли я скидку?" (цена на предметы в модуле ассортимента, а информация о скидках в другом).
akakoychenko
Отличный пример запроса, на который я бы, на месте владельца бизнеса, предпочел, чтобы бот не отвечал, а посоветовал уточнить у человека ;)
И так часто схема бонусов и скидок довольно запутанная, особенно, когда встречаются вместе бонусные программы с временными скидками. А, учитывая, что с ботом можно общаться бесконечно долго, то, уверен, что, будут и любители, покрутив вопрос час-второй, добиваться необоснованной скидки у бота, после чего, магазину придётся или отдавать товар по нерыночной цене, или принять, что скрин пойдет по соцсетям как пруф их нечистоплотности
N3VERZzz Автор
Кажется, вы общаетесь достаточно токсично. Если это возможно, я бы хотел размышлять над вопросами вместе с вами, а не спорить. Мне действительно понравилась идея разделения промпта на множество частей и классификация запросов. Это может помочь LLM не терять контекст. Однако, я вижу здесь несколько проблем, которых нет в классическом подходе: 1) зона видимости (что делать с запросами, которые должны включать в себя информацию из двух или более модулей?) 2) сама классификация (с какой-то вероятностью мы будем неправильно определять интенцию пользователя и отвечать на его вопрос, используя информацию из другого модуля). У вас есть какие-то мысли на этот счет?
akakoychenko
В том то и дело, что, особенно, учитывая последнюю новость об атаке с повторением, применение чат бота для произвольных человекоподобных ответов юзеру кажется все более проблемным.
Вы задаете хорошие вопросы, но, кажется, хороших ответов тут нет. По п1, было бы круто, если б можно было при помощи ЛЛМ, стоящей на входе, сформулировать вопросы для нижестоящих, и синтезировать их ответ в один. Но, понятно и то, что такая система станет слишком непредсказуемой, и это не прод решение. Так что, остается только смириться, что ЛЛМ ответит, что не может ответить на данный вопрос и предложит обратиться к человеку (ибо, у той специализированной сети, на которую упадет, контекст не хранит всей информации для ответа).
А, по п2, особого риска тут нет, если отдельные сети хорошо умеют понять свое незнание ответа и признать его. И, кажется, это и есть сейчас чуть ли не основной вызов всей индустрии. Все же, всегда есть fallback вида "оставьте контакт и с вами свяжется человек".
N3VERZzz Автор
Всё-таки мне кажется, в системе RAG больше потенциала, но хорошо, что вы предложили эту идею, я об этом даже не задумывался.
akakoychenko
Лично я не сильно верю именно в RAG потому, что, фактически, он перекладывает ключевую задачу понимания смысла на куда более слабые алгоритмы, чем LLM.
К слову, когда попробовал новый bing, было неприятное ощущение, что обманули. Ибо, казалось бы, сила LLM именно в том, чтобы мораль выделить среди кучи сеошного мусора, а, когда первым шагом идёт поиск по этой куче классическими методами, то сразу понятно, что чуда не произойдёт.
Вот, если б LLM умела сама формулировать запрос на недостающие данные хотя-бы...
К примеру, когда программистов собеседуют, то важным этапом являются вопросы, на которые любой утвердительный ответ будет неправильный, а единственно правильным ответом будет уточняющий вопрос. Может, ещё научится и нейронка так делать