
Существует популярный подход к покрытию метриками Celery: он заключается в запуске некоторого процесса, который слушает события из специальной очереди, на основе этих событий обновляются объекты метрик, а фоновый поток сервера отдаёт собранные метрики скраперу. В этой статье подробно разберём события, их жизненный цикл, откуда и как их принимать. Также поговорим про механизм удалённого управления (remote control), какие у него есть возможности и как им пользоваться. Обсудим существующие решения, чем они отличаются, и почему вам, возможно, будет выгодно сделать своё.

События Celery
У celery есть довольно гибкая система событий, которые делятся на две группы: task и worker. Рассмотрим их.
Группа событий task
task-sent. Отправляется на вызывающей стороне (producer), когда task опубликован и включен параметр task_send_sent_event.task-received. Отправляется, когда worker получает задачу.task-started. Отправляется непосредственно перед тем, как worker выполнит задачу.task-succeeded. Отправляется, если задача выполнена успешно. В этом событии дополнительно отправляется время выполнения задачи (атрибутruntime).task-failed. Отправляется, если выполнение задачи завершилось неудачей.task-rejected. Задача была отклонена worker-ом, возможно, для повторной постановки в очередь или перемещения в dead letter queue.task-revoked. Отправляется, если задача была отменена. Здесь необходимо обратить внимание, что событие, скорее всего, будет отправлено более чем одним воркером.task-retried. Отправляется, если задача завершилась неудачей, но будет повторная попытка в будущем.
Примеры событий
task-sent
{
"hostname": "gen7460@aszubarev-mac.local",
"utcoffset": -3,
"pid": 7460,
"clock": 6,
"uuid": "4e71454e-e0bf-477c-8abf-9559721de49d",
"root_id": "4e71454e-e0bf-477c-8abf-9559721de49d",
"parent_id": null,
"name": "tasks.foo",
"args": "()",
"kwargs": "{}",
"retries": 0,
"eta": null,
"expires": null,
"queue": "celery",
"exchange": "",
"routing_key": "celery",
"timestamp": 1712401950.239082,
"type": "task-sent",
"local_received": 1712401950.245164
}
task-received
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 7226,
"clock": 6,
"uuid": "4e71454e-e0bf-477c-8abf-9559721de49d",
"name": "tasks.foo",
"args": "()",
"kwargs": "{}",
"root_id": "4e71454e-e0bf-477c-8abf-9559721de49d",
"parent_id": null,
"retries": 0,
"eta": null,
"expires": null,
"timestamp": 1712401950.2415,
"type": "task-received",
"local_received": 1712401950.244245
}
task-started
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 7226,
"clock": 7,
"uuid": "4e71454e-e0bf-477c-8abf-9559721de49d",
"timestamp": 1712401950.243285,
"type": "task-started",
"local_received": 1712401950.24531
}
task-succeeded
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 7226,
"clock": 8,
"uuid": "4e71454e-e0bf-477c-8abf-9559721de49d",
"result": "None",
"runtime": 0.0063114170043263584,
"timestamp": 1712401950.2501838,
"type": "task-succeeded",
"local_received": 1712401950.2526982
}
task-failed
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 8704,
"clock": 3,
"uuid": "3ca9b52f-3a6b-4780-bf51-24bdc92a1076",
"exception": "RuntimeError(\"Can\"t process task\")",
"traceback": "Traceback (most recent call last):\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/trace.py\", line 477, in trace_task\n R = retval = fun(*args, **kwargs)\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/trace.py\", line 760, in __protected_call__\n return self.run(*args, **kwargs)\n File \"/Users/aszubarev/projects/aszubarev/celery-exporter/examples/tasks.py\", line 20, in test_failed\n raise RuntimeError(\"Can\"t process task\")\nRuntimeError: Can\"t process task\n",
"timestamp": 1712402513.966636,
"type": "task-failed",
"local_received": 1712402513.9687
}
task-rejected
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 10821,
"clock": 13,
"uuid": "5be96332-3f69-4b59-8590-b6ecce54ffaf",
"requeue": false,
"timestamp": 1712403556.524642,
"type": "task-rejected",
"local_received": 1712403556.527313
}
task-revoked
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 14394,
"clock": 30,
"uuid": "6d2f6d38-7378-461f-8e25-1cfc4aceb307",
"terminated": false,
"signum": null,
"expired": false,
"timestamp": 1712405361.334489,
"type": "task-revoked",
"local_received": 1712405362.687277
}
task-retried
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 13657,
"clock": 12,
"uuid": "904dc2f6-6aa7-49e0-acb2-7fe241563be6",
"exception": "RuntimeError(\"Can\"t process task\")",
"traceback": "Traceback (most recent call last):\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/autoretry.py\", line 38, in run\n return task._orig_run(*args, **kwargs)\n File \"/Users/aszubarev/projects/aszubarev/celery-exporter/examples/tasks.py\", line 36, in test_retried\n raise RuntimeError(\"Can\"t process task\")\nRuntimeError: Can\"t process task\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/trace.py\", line 477, in trace_task\n R = retval = fun(*args, **kwargs)\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/trace.py\", line 760, in __protected_call__\n return self.run(*args, **kwargs)\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/autoretry.py\", line 60, in run\n ret = task.retry(exc=exc, **retry_kwargs)\n File \"/Users/aszubarev/Library/Caches/pypoetry/virtualenvs/celery-exporter-ISWk3u3R-py3.10/lib/python3.10/site-packages/celery/app/task.py\", line 757, in retry\n raise ret\ncelery.exceptions.Retry: Retry in 5s: RuntimeError(\"Can\"t process task\")\n",
"timestamp": 1712404792.764382,
"type": "task-retried",
"local_received": 1712404792.767023
}
Группа событий worker
worker-online. Worker подключился к брокеру и находится в сети.worker-offline. Worker отключился от брокера.worker-heartbeat. Отправляется регулярно с указанным интервалом.
Примеры событий
worker-online
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 21516,
"clock": 1,
"freq": 2.0,
"active": 0,
"processed": 0,
"loadavg": [
7.61,
7.72,
7.12
],
"sw_ident": "py-celery",
"sw_ver": "5.3.6",
"sw_sys": "Darwin",
"timestamp": 1712408762.006613,
"type": "worker-online",
"local_received": 1712408762.01629
}
worker-offline
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 21516,
"clock": 71,
"freq": 2.0,
"active": 0,
"processed": 0,
"loadavg": [
4.64,
6.81,
6.82
],
"sw_ident": "py-celery",
"sw_ver": "5.3.6",
"sw_sys": "Darwin",
"timestamp": 1712408827.013207,
"type": "worker-offline",
"local_received": 1712408827.0157518
}
worker-heartbeat
{
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 21516,
"clock": 53,
"freq": 2.0,
"active": 10,
"processed": 80,
"loadavg": [
3.75,
4.21,
3.86
],
"sw_ident": "py-celery",
"sw_ver": "5.3.6",
"sw_sys": "Darwin",
"timestamp": 1712407095.393169,
"type": "worker-heartbeat",
"local_received": 1712407095.3960378
}
Более подробно можно ознакомится с ними в документации.
По умолчанию события группы task не отправляются. Чтобы это исправить, нужно включить опцию worker_send_task_events. Но это действие нужно делать осознанно. Желательно, чтобы был потребитель этих событий, в противном случае отправка событий будет бесполезной.
События группы worker, напротив, по умолчанию отправляются. Существует популярная рекомендация для снижения потребления ресурсов — отключение опций gossip, mingle и heartbeat. Считаю эту рекомендацию достаточно полезной. Но когда heartbeat необходим, советую обратить внимание на опцию --heartbeat-interval для указания собственного интервала отправки.
Exchanges и Queues
В случае использования RabbitMQ в качестве брокера, Celery создаст четыре exchange. Их можно увидеть на странице администрирования. Далее по статье все примеры будут на основе RabbitMQ.
celery. Используется для отправки задач.celeryev. Используется для отправки событий.celery.pidbox. Используется для отправки команд воркерам.reply.celery.pidbox. Используется для отправки ответа соответствующей команды.
Exchanges и Queues на панели администрирования


Пример из документации создаст очередь celeryev.*, куда будут попадать события из exchange celeryev для дальнейшей обработки. Очередей с таким шаблоном названия может быть несколько. Например, сообщения с routing key worker.# используются для gossip.
Панель администрирования


Эта очередь событий обладает следующими свойствами:
auto-delete: true. Очередь автоматически удалится в случае отсутствия потребителя.x-message-ttl: 5000. Через 5 секунд событие будет не актуально и не будет доставлено потребителю.x-expires: 60000. Очередь удалится спустя 60 секунд в случае отсутствия потребителя.
События доставляются потребителю без ожидания ack («выстрелил и забыл»). Это видно на графике в панели администрирования. Таким образом уменьшается задержка на доставку потребителю. Но могут быть риски потери сообщений. На мой взгляд, для мониторинга это приемлемая настройка.
Готовые решения
Существует готовое решение для обработки событий в виде Flower. У него есть весь необходимый набор метрик. Есть свой сервер на Tornado, который умеет отдавать эти метрики и не только. Он умеет даже сохранять информацию по задачам в постоянное хранилище. Отличное решение.
Однако бывают ситуации, когда возможностей Flower недостаточно. Из популярного: нет разделения по exception в метрике flower_events_total; не получится построить график ошибок в секунду с разделением по типу исключения. Разные авторы на Github решают эту задачу по-разному. На мой взгляд, их всех объединяет то, что им приходилось создавать такие решения ввиду дефицита необходимых, закрывающие конкретно их потребности. И мы не стали исключением.
Проектов много, Celery «один»
Представим ситуацию, что ваша команда разрабатывает несколько проектов. Назовём их serviceA и serviceB. В каждом из них вы решили использовать Celery для обработки задач. С учётом описанного выше появляется конфликт использования одних и тех же exchange и очередей разными проектами.
Есть несколько вариантов изолирования celery worker-ов между проектами.

Самый простой вариант: использовать для каждого проекта свой vhost в RabbitMQ. Это позволит использовать настройки Celery по умолчанию. Если нет возможности или желания выделять vhost под отдельные проекты, то можно создавать наборы exchange и очередей под каждый проект со своими уникальными названиями, соответствующими названиям этих проектов. Для этого необходимо указать следующие опции:
Пример ниже создаст exchange и очереди, которые будут использоваться исключительно сервисом serviceA.
import os
from celery import Celery
BROKER_URL = os.environ.get('BROKER_URL', 'amqp://guest:guest@localhost:8672')
app = Celery(
broker=BROKER_URL,
task_send_sent_event=True,
worker_send_task_events=True,
worker_enable_remote_control=True,
task_default_exchange='service_a',
task_default_queue='service_a',
event_exchange='service_a.celeryev',
event_queue_prefix='service_a.celeryev',
control_exchange='service_a',
)
if __name__ == '__main__':
app.start()
EventReceiver и remote control при тех же настройках Celery App также будут создавать очереди с соответствующими названиями.
Exchanges и Queues на панели администрирования


Особенности запуска экспортёра
Разберем ситуацию на примере Flower. Запуск выглядит следующим образом:
celery -A tasks flowerФайл tasks.py должен содержать сконфигурированный app Celery. И тут возникает вопрос: где и как запускать Flower? Есть несколько вариантов.
Можно установить Flower в зависимости проекта и передавать для запуска тот же app, что и для воркеров. Недостатки такого решения очевидны: в зависимостях появляется дополнительные пакеты, версия Celery вашего проекта может конфликтовать с необходимой версией для Flower, жизненный цикл экспортёра может быть привязан к жизненному циклу приложения.
Второй вариант — отделить мониторинг от приложения. Можно завести отдельный репозиторий под мониторинг конкретного проекта со своими зависимостями, настройками и жизненным циклом. Но ситуация усложняется наличием нескольких проектов. В этом случае проще всего будет создать набор переменных окружения, каждый под целевой сервис, и научиться развёртывать несколько экземпляров экспортёра с соответствующим набором настроек.
Исходя из всего этого появилась идея сделать централизованный экспортёр, который можно конфигурировать под разные сервисы, c функционалом, которого нет во Flower.
Метрики событий
Если по тем или иным причинам вам необходимо создать собственное решение, давайте разбираться. Все примеры можно посмотреть тут.
Для начала нужно определить, какие метрики мы хотим собирать. Из очевидного: счётчики всех событий группы task, гистограмму времени выполнения задачи и gauge доступности воркеров. Независимо от способа изолирования сервисов, когда мы делаем централизованный мониторинг, нужно самостоятельно организовать различия метрик между сервисами. Для этого добавим всем метрикам метку service_name.
Метрики группы task
Счётчики событий можно делать по-разному. Можно идти по пути Flower и создать один счётчик flower_events_total разделённый метками task, type и worker. Но раз уж мы здесь, сделаем по-другому. Будем вести отдельные счётчики для каждого типа события:
celery_task_sent_totalcelery_task_received_totalcelery_task_started_totalcelery_task_succeeded_totalcelery_task_failed_totalcelery_task_rejected_totalcelery_task_revoked_totalcelery_task_retried_total
Это позволит нам для некоторых из них сделать дополнительные метки. Например, как обсуждалось ранее, для счётчика неудачных задач добавим метку exception — то, чего не хватает во Flower. Однако у Flower на это есть логичные причины. В противном случае метка exception была бы у всех метрик помимо счётчика ошибок.
Событие task-succeeded содержит атрибут runtime. По его значению будем строить гистограмму времени выполнения задач celery_task_runtime_bucket. Вам может потребоваться использовать свои значения в BUCKETS, особенно если в вашем сервисе есть долгие задачи.
Для уменьшения количества метрик можно отключить метрики _created.
celery_exporter/metrics.py
from celery_exporter.conf import settings
from prometheus_client import CollectorRegistry, Counter, Gauge, Histogram, disable_created_metrics
if settings.PROMETHEUS_CLIENT_DISABLE_CREATED_METRICS:
disable_created_metrics()
BUCKETS = ( # noqa: WPS317
.005, .01, .025, .05, .075, .1, .25, .5, .75, 1.0, # noqa: WPS304
2.5, 5.0, 7.5, 10.0, 15.0, 20.0, 25.0, 30.0, 35.0, 40.0,
50.0, 60.0, 70.0, 80.0, 90.0, 100.0,
)
registry = CollectorRegistry(auto_describe=True)
events_state_counters = {
'task-sent': Counter(
'celery_task_sent',
'Sent when a task message is published.',
['task', 'worker', 'service_name'],
registry=registry,
),
'task-received': Counter(
'celery_task_received',
'Sent when the worker receives a task.',
['task', 'worker', 'service_name'],
registry=registry,
),
'task-started': Counter(
'celery_task_started',
'Sent just before the worker executes the task.',
['task', 'worker', 'service_name'],
registry=registry,
),
'task-succeeded': Counter(
'celery_task_succeeded',
'Sent if the task executed successfully.',
['task', 'worker', 'service_name'],
registry=registry,
),
'task-failed': Counter(
'celery_task_failed',
'Sent if the execution of the task failed.',
['task', 'worker', 'exception', 'service_name'],
registry=registry,
),
'task-rejected': Counter(
'celery_task_rejected',
'The task was rejected by the worker, possibly to be re-queued or moved to a dead letter queue.',
['task', 'worker', 'service_name'],
registry=registry,
),
'task-revoked': Counter(
'celery_task_revoked',
'Sent if the task has been revoked.',
['task', 'worker', 'service_name'],
registry=registry,
),
'task-retried': Counter(
'celery_task_retried',
'Sent if the task failed, but will be retried in the future.',
['task', 'worker', 'service_name'],
registry=registry,
),
}
celery_task_runtime = Histogram(
'celery_task_runtime',
'Histogram of task runtime measurements.',
['task', 'worker', 'service_name'],
registry=registry,
buckets=BUCKETS,
)
...Метрики группы worker
Сделаем свой аналог метрик Flower с дополнительным разделением по имени сервиса:
celery_worker_up. Признак доступности воркера.celery_worker_tasks_active. Количество активных задач.
Метрика celery_worker_up устанавливается в зависимости от типа события. Если приходит событие worker-online или worker-heartbeat, то устанавливается значение 1. Если приходит событие worker-offline, устанавливается 0.
Метрика celery_worker_tasks_active устанавливается, когда приходит событие worker-heartbeat. В нём есть необходимый атрибут active. Когда приходит событие worker-offline, устанавливается 0.
celery_exporter/metrics.py
...
celery_worker_up = Gauge(
'celery_worker_up',
'Indicates if a worker has recently sent a heartbeat.',
['worker', 'service_name'],
registry=registry,
)
celery_worker_tasks_active = Gauge(
'celery_worker_tasks_active',
'The number of tasks the worker is currently processing',
['worker', 'service_name'],
registry=registry,
)
...State событий
Для корректной обработки событий нам потребуется celery.events.state.State. Этот класс хранит словари состояний задач и воркеров. Эти словари являются LRU-кешем и по умолчанию имеют ограничение 10 тыс. для группы task и 5 тыс. для группы worker.
Прежде чем обрабатывать событие, нужно положить его в State. Это позволит решить несколько проблем.
Если внимательно посмотреть на пример событий группы task, то можно заметить, что название задачи есть только в событиях task-sent и task-received. Поэтому для получения имени задачи в обработчиках других событий необходимо, чтобы в кеше был экземпляр celery.events.state.Task c уже заполненным названием задачи.
События task-sent и task-received могут прийти в обратном порядке. Поэтому даже если task-sent придёт после task-received это ещё не значит, что текущий статус задачи PENDING.
examples/race_condition.py
from celery.events.state import State, Task
task_sent_event = {
"hostname": "gen7460@aszubarev-mac.local",
"utcoffset": -3,
"pid": 7460,
"clock": 6,
"uuid": "4e71454e-e0bf-477c-8abf-9559721de49d",
"root_id": "4e71454e-e0bf-477c-8abf-9559721de49d",
"parent_id": None,
"name": "tasks.foo",
"args": "()",
"kwargs": "{}",
"retries": 0,
"eta": None,
"expires": None,
"queue": "celery",
"exchange": "",
"routing_key": "celery",
"timestamp": 1712401950.239082,
"type": "task-sent",
"local_received": 1712401950.245164
}
task_received_event = {
"hostname": "celery@aszubarev-mac.local",
"utcoffset": -3,
"pid": 7226,
"clock": 6,
"uuid": "4e71454e-e0bf-477c-8abf-9559721de49d",
"name": "tasks.foo",
"args": "()",
"kwargs": "{}",
"root_id": "4e71454e-e0bf-477c-8abf-9559721de49d",
"parent_id": None,
"retries": 0,
"eta": None,
"expires": None,
"timestamp": 1712401950.2415,
"type": "task-received",
"local_received": 1712401950.244245
}
state = State()
state.event(task_received_event)
state.event(task_sent_event)
task: Task = state.tasks.get("4e71454e-e0bf-477c-8abf-9559721de49d")
print(task.state) # RECEIVED
Реализация
Полную реализацию можно посмотреть тут. Приведу лишь выжимку, чтобы показать концепцию, которая заключается в следующем. Запускаем поток, который в вечном цикле начинает прослушку событий. Указываем обработчики handlers. В отдельном потоке запускаем сервер для отдачи метрик, у prometheus_client такой есть из коробки. Обработчики должны принимать один аргумент event. Так как мы делаем решение для мониторинга нескольких сервисов, наши обработчики теперь принимают дополнительно второй аргумент service_name. Однако Receiver ничего не знает про service_name. Поэтому чтобы всё корректно работало, необходимо использовать partial.
Помним про сохранение событий в State. Для удобства вынес это действие в отдельный декоратор receive_event.
celery_exporter/exporter.py
import time
from functools import partial
from threading import Thread
import structlog
from celery import Celery
from celery_exporter import metrics, track
from celery_exporter.conf import settings
from celery_exporter.utils.celery_app_settings import CeleryAppSettings
from prometheus_client import start_http_server
logger = structlog.get_logger()
class Exporter:
CONFIGURATION: dict[str, CeleryAppSettings] = {
'default': CeleryAppSettings(
broker_url=settings.BROKER_URL,
),
'service_a': CeleryAppSettings(
broker_url=settings.BROKER_URL,
task_default_exchange='service_a',
task_default_queue='service_a',
event_exchange='service_a.celeryev',
event_queue_prefix='service_a.celeryev',
control_exchange='service_a',
),
}
def run(self) -> None:
for service_name in self.CONFIGURATION:
Thread(target=self.collect_worker_metrics, args=(service_name,)).start()
logger.info('Starting http server. http://0.0.0.0:%s/metrics', settings.PORT)
start_http_server(port=settings.PORT, registry=metrics.registry)
@classmethod
def collect_worker_metrics(cls, service_name: str) -> None: # noqa: C901
app = cls._create_celery_app(service_name)
if settings.COLLECT_WORKER_METRICS_RETRY_INTERVAL:
logger.debug('Using retry_interval of %s seconds', settings.COLLECT_WORKER_METRICS_RETRY_INTERVAL)
handlers = {
'worker-heartbeat': partial(track.track_worker_heartbeat, service_name=service_name),
'worker-online': partial(track.track_worker_status, service_name=service_name),
'worker-offline': partial(track.track_worker_status, service_name=service_name),
}
track_task_event = partial(track.track_task_event, service_name=service_name)
for key in metrics.events_state_counters:
handlers[key] = track_task_event
with app.connection() as connection:
while True:
try:
recv = app.events.Receiver(connection, handlers=handlers)
recv.capture(limit=None, timeout=None, wakeup=True)
except (KeyboardInterrupt, SystemExit) as ex: # noqa: WPS329
raise ex
except Exception:
logger.exception(
'Handle exception',
retry_interval=settings.COLLECT_WORKER_METRICS_RETRY_INTERVAL,
)
time.sleep(settings.COLLECT_WORKER_METRICS_RETRY_INTERVAL)
@classmethod
def _create_celery_app(cls, service_name: str) -> Celery:
celery_app_settings = cls.CONFIGURATION[service_name].dict(exclude_unset=True)
logger.debug('Create celery app', service_name=service_name, celery_app_settings=celery_app_settings)
return Celery(**celery_app_settings)
celery_exporter/track.py
import re
from typing import Any, Callable, TypeVar
import structlog
from celery.events.state import Task, Worker
from celery_exporter import metrics, state
from celery_exporter.conf import settings
logger = structlog.get_logger()
EventType = TypeVar('EventType', bound=dict[str, Any])
def receive_event(func: Callable[[EventType, str], None]) -> Callable[[EventType, str], None]:
def wrapper(event: EventType, service_name: str) -> None:
# put event to celery.events.state.State
(obj, _), _ = state.events_state.event(event)
contextvars = {
'event_type': event['type'],
'service_name': service_name,
'worker': getattr(obj, 'hostname', 'unknown'),
}
if isinstance(obj, Task):
contextvars['task_uuid'] = obj.uuid
contextvars['task_name'] = obj.name
contextvars['task_state'] = obj.state
with structlog.contextvars.bound_contextvars(**contextvars):
logger.debug('Received event')
func(event, service_name)
return wrapper
@receive_event
def track_task_event(event: EventType, service_name: str) -> None: # noqa: C901,WPS231
task: Task = state.events_state.tasks.get(event['uuid'])
worker_name = task.hostname
if event['type'] == 'task-sent' and settings.GENERIC_HOSTNAME_TASK_SENT_METRIC:
worker_name = 'generic'
labels = {'task': task.name, 'worker': worker_name, 'service_name': service_name}
if event['type'] == 'task-failed':
labels['exception'] = _get_exception_class_name(task.exception)
counter = metrics.events_state_counters.get(event['type'])
if counter:
counter.labels(**labels).inc()
# noinspection PyProtectedMember
logger.debug('Increment counter', metric_name=counter._name, labels=labels)
else:
logger.warning("Can't get counter")
if event['type'] == 'task-succeeded':
metrics.celery_task_runtime.labels(**labels).observe(task.runtime)
# noinspection PyProtectedMember
logger.debug('Observe', metric_name=metrics.celery_task_runtime._name, task_runtime=task.runtime)
@receive_event
def track_worker_heartbeat(event: EventType, service_name: str) -> None:
worker_name = event['hostname']
state.worker_last_seen[(worker_name, service_name)] = event['timestamp']
worker: Worker = state.events_state.event(event)[0][0]
active = worker.active or 0
up = 1 if worker.alive else 0
metrics.celery_worker_up.labels(worker=worker_name, service_name=service_name).set(up)
metrics.celery_worker_tasks_active.labels(worker=worker_name, service_name=service_name).set(active)
# noinspection PyProtectedMember
logger.debug('Update gauge', metric_name=metrics.celery_worker_up._name, value=up)
# noinspection PyProtectedMember
logger.debug('Update gauge', metric_name=metrics.celery_worker_tasks_active._name, value=active)
@receive_event
def track_worker_status(event: EventType, service_name: str) -> None:
is_online = event['type'] == 'worker-online'
value = 1 if is_online else 0
worker_name = event['hostname']
metrics.celery_worker_up.labels(worker=worker_name, service_name=service_name).set(value)
# noinspection PyProtectedMember
logger.debug('Update gauge', metric_name=metrics.celery_worker_up._name, value=value)
if event['type'] == 'worker-online':
state.worker_last_seen[(worker_name, service_name)] = event['timestamp']
else:
_reset_worker_metrics(worker_name, service_name)
def _reset_worker_metrics(worker_name: str, service_name: str) -> None:
if (worker_name, service_name) not in state.worker_last_seen:
return
metrics.celery_worker_up.labels(worker=worker_name, service_name=service_name).set(0)
metrics.celery_worker_tasks_active.labels(worker=worker_name, service_name=service_name).set(0)
# noinspection PyProtectedMember
logger.debug(
'Update gauge',
worker=worker_name,
service_name=service_name,
metric_name=metrics.celery_worker_up._name,
value=0,
)
# noinspection PyProtectedMember
logger.debug(
'Update gauge',
worker=worker_name,
service_name=service_name,
metric_name=metrics.celery_worker_tasks_active._name,
value=0,
)
_exception_pattern = re.compile(r'^(\w+)\(')
def _get_exception_class_name(exception_name: str) -> str:
match = _exception_pattern.match(exception_name)
if match:
return match.group(1)
return 'UnknownException'
Проблемы реализации
Worker timeout
Необходимо определять, что воркер более не доступен, и отразить эту информацию в метриках celery_worker_up и celery_worker_tasks_active. Для этого будем хранить в отдельном словаре время последнего heartbeat. В качестве ключа у нас будет (worker_name, service_name). В отдельном потоке периодически будем сравнивать разницу между текущим временем и временем последнего heartbeat. При превышении порога обнулим упомянутые метрики.
Проблема усложняется тем, что воркер может никогда больше не быть доступным. Например, вы запускаете Celery в K8s и в какой-то момент выкатили новую версию сервиса. В качестве hostname будет выступать имя пода, которое каждый раз разное. Старая версия сервиса больше не отправит heartbeat. Поэтому помимо обнуления метрик необходимо их удалить, включая метрики событий, отправленные этим воркером.

Хранить метрики этого воркера не имеет смысла. Более того, они засоряют Prometheus. Данные меняться больше не будут, однако будут регулярно считываться скрапером. Разумно будет установить дополнительный порог, превышая который метрики будут удаляться. У Flower есть опция purge-offline-workers, однако она влияет лишь на отображение списка доступных воркеров, но никак не реализует механизм удаления метрик из памяти. Получаем ещё одну причину в пользу собственного решения.
celery_exporter/exporter.py
class Exporter:
...
@classmethod
def collect_worker_timeout(cls) -> None:
while True:
try:
track.track_worker_timeout()
except (KeyboardInterrupt, SystemExit) as ex: # noqa: WPS329
raise ex
except Exception:
logger.exception("Can't track timed_out_workers")
time.sleep(settings.COLLECT_WORKER_TIMEOUT_METRICS_INTERVAL)
celery_exporter/track.py
from celery_exporter.utils.timezone import localtime
...
def track_worker_timeout() -> None:
current_time = localtime().timestamp()
# Make a copy of the last seen dict, so we can delete from the dict with no issues
worker_last_seen_copy = state.worker_last_seen.copy()
for worker_name, service_name in worker_last_seen_copy.keys():
since = current_time - worker_last_seen_copy[(worker_name, service_name)]
if since > settings.WORKER_TIMEOUT_SECONDS:
logger.info('Worker timeout. Resetting metrics', worker=worker_name, service_name=service_name, since=since)
_reset_worker_metrics(worker_name, service_name)
if since > settings.PURGE_OFFLINE_WORKER_METRICS_AFTER_SECONDS:
logger.info('Worker timeout. Purging metrics', worker=worker_name, service_name=service_name, since=since)
_purge_worker_metrics(worker_name, service_name)
def _reset_worker_metrics(worker_name: str, service_name: str) -> None:
if (worker_name, service_name) not in state.worker_last_seen:
return
metrics.celery_worker_up.labels(worker=worker_name, service_name=service_name).set(0)
metrics.celery_worker_tasks_active.labels(worker=worker_name, service_name=service_name).set(0)
# noinspection PyProtectedMember
logger.debug(
'Update gauge',
worker=worker_name,
service_name=service_name,
metric_name=metrics.celery_worker_up._name,
value=0,
)
# noinspection PyProtectedMember
logger.debug(
'Update gauge',
worker=worker_name,
service_name=service_name,
metric_name=metrics.celery_worker_tasks_active._name,
value=0,
)
def _purge_worker_metrics(worker_name: str, service_name: str) -> None: # noqa: C901,WPS231
# Prometheus stores a copy of the metrics in memory, so we need to remove them
# The key of the metrics is a string sequence e.g ('celery(queue_name)', 'host-1(hostname)')
# noinspection PyProtectedMember
for label_seq in list(metrics.celery_worker_tasks_active._metrics.keys()):
if worker_name in label_seq and service_name in label_seq:
metrics.celery_worker_tasks_active.remove(*label_seq)
# noinspection PyProtectedMember
for label_seq in list(metrics.celery_worker_up._metrics.keys()): # noqa: WPS440
if worker_name in label_seq and service_name in label_seq:
metrics.celery_worker_up.remove(*label_seq)
for counter in metrics.events_state_counters.values():
# noinspection PyProtectedMember
for label_seq in list(counter._metrics.keys()): # noqa: WPS440
if worker_name in label_seq and service_name in label_seq:
counter.remove(*label_seq)
# noinspection PyProtectedMember
for label_seq in list(metrics.celery_task_runtime._metrics.keys()): # noqa: WPS440
if worker_name in label_seq and service_name in label_seq:
metrics.celery_task_runtime.remove(*label_seq)
del state.worker_last_seen[(worker_name, service_name)] # noqa: WPS420
... Пустые task.name
Эта проблема есть и у Flower, проявляется она следующим образом. Приходит, например, событие task-succeeded, получаешь объект задачи из State, увеличиваешь счётчик метрики — и обнаруживаешь в метке task пустую строку.
flower_events_total{task="",type="task-succeeded",worker="celery@aszubarev-mac.local"} 2.0Это происходит потому, что воркер не получил ранее одно из событий task-sent или task-received, а именно они содержат атрибут name. Например, вы впервые запускаете экспортёр, какие-то задачи уже обрабатываются в текущий момент, и по их завершении отправляются task-succeeded. А события task-received отправлялись в тот момент, когда экспортёр ещё не был готов их принимать.
Вариации event['hostname']
Атрибут hostname в событиях имеет формат worker_name@worker_hostname, например, celery@aszubarev-mac.local. Из этого можно сделать вывод, что когда на одном хосте запускается несколько воркеров Celery с разными именами, будут создаваться отдельные метрики, соответствующие каждому воркеру. Такое поведение у Flower. Метка worker устанавливается из атрибута hostname как есть.
В зависимости от потребностей можно сделать следующие действия. Можно отказаться от детализации, какой именно из воркеров на хосте отправил событие. Для этого необходимо отделить worker_name от worker_hostname, и устанавливать в метках только worker_hostname.
from celery.utils import nodesplit
def get_hostname(name: str) -> str:
_, hostname = nodesplit(name)
return hostname
get_hostname("celery@aszubarev-mac.local") # aszubarev-mac.local
get_hostname("aszubarev-mac.local") # aszubarev-mac.localВ событиях task-sent приходит hostname содержащий автоматически сгенерированное название отправителя в качестве worker_name. Это можно увидеть в примерах событий. Hostname по типу gen90436@aszubarev-mac.local может негативно сказаться на размере метрик. Более того, если отправители запускаются в K8s, с каждой новой версией отправителя также будет меняться worker_hostname. Количество вариаций таких отправителей будет постоянно расти.
В большинстве случаев не так важно с какого именно хоста была отправлена задача. Поэтому, если ваши метрики содержат в метках либо worker либо worker_hostname, рекомендую для счётчика celery_task_sent_total в метке указывать шаблонное значение, например «generic». Это ещё одна из причин, по которой вам может понадобиться делать своё решение.
Можно пойти дальше и отказаться даже от детализации хоста. Если для ваших задач нет необходимости разделять графики по хостам, то отказ от метки worker_hostname упростит реализацию и уменьшит количество метрик.
Устаревшие задачи
Со временем сервисы развиваются. Какие-то задачи переписываются, новые добавляются, старые удаляются. Нетрудно догадаться, что для новых задач будут создаваться новые метрики, а метрики старых задачи будут находиться в подвешенном состоянии. Если ваш экспортёр переживет несколько поколений ваших сервисов, у него может скопиться в метриках достаточно приличное количество устаревших задач. Можно провести аналогию с worker timeout, только реализация будет кратно сложней. Если уж столкнулись с этим, то можно просто перезапустить экспортёр.
Remote control
По умолчанию воркер включает механизм remote control. Принцип его работы следующий. При запуске создаётся очередь с названием в формате celery@worker_hostname.worker_name.pidbox (смотри раздел Exchanges и Queues). Вызывающая сторона отправляет команду в celery.pidbox, например, ping.
{
"method": "ping",
"arguments": {},
"destination": null,
"pattern": null,
"matcher": null,
"ticket": "10ed2733-2a7e-4293-8325-bfe900f3595f",
"reply_to": {
"exchange": "reply.celery.pidbox",
"routing_key": "2a63faeb-64b2-327e-809d-c76f31423cf5"
}
}Если вызывающая сторона ожидает ответ от воркера, будет создана очередь в формате oid@reply.celery.pidbox. Этот oid представляет собой сгенерированный UUID на основе идентификатора узла, процесса, потока, экземпляра Mailbox. Он является routing_key и передаётся в соответствующем поле в reply_to в теле сообщения.
Время жизни очереди определяется настройкой control_queue_expires, по умолчанию равной 10 сек. Поэтому нет смысла в команде ping указывать timeout больше, чем значение этой настройки.
Воркер принимает команду из соответствующей очереди и при необходимости отправляет ответ в указанный в сообщении exchange с заданным routing_key.
{
"celery@aszubarev-mac.local": {
"ok": "pong"
}
}Вызывающая сторона принимает ответ и возвращает результат.
Inspect
app.control.inspect предоставляет следующий набор команд:
active_queues. Очереди, которые использует воркер.
registered. Зарегистрированные задачи в воркере.
active. Выполняющиеся в текущий момент задачи.
scheduled. Отложенных задачи (eta).
reserved. Задачи, которые были получены, но всё ещё ожидают выполнения.
stats. Длинный список полезной (или не очень) статистики.
Все перечисленные команды Flower использует лишь для отображения статистики в своей панели администрирования.
Панель администрирования flower

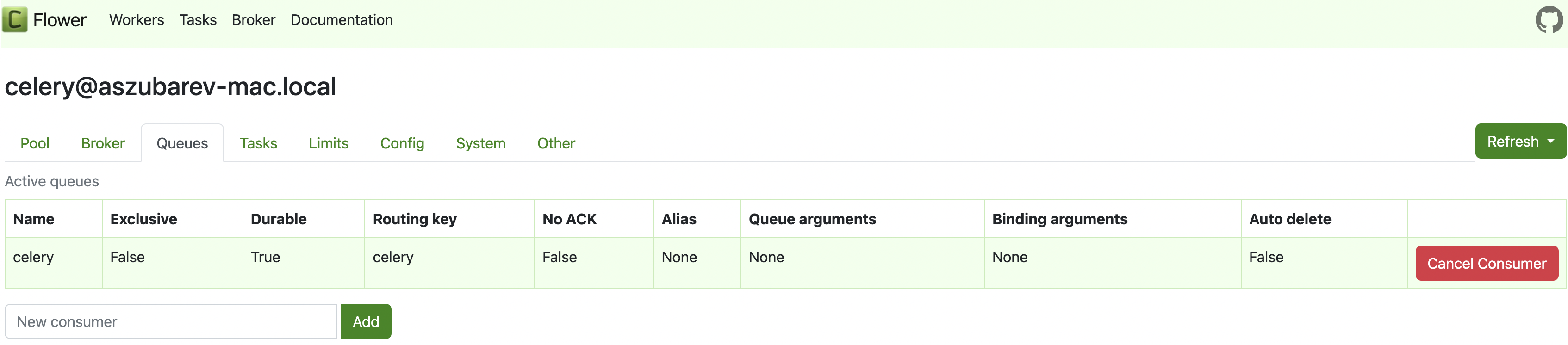

Однако все эти команды можно также использовать для построения метрик. Например, комбинируя ответ от active_queues и stats, сделаем следующие метрики:
celery_active_worker_count. Количество воркеров на очередь.celery_active_process_count. Количество процессов на очередь.
Из ответа команды stats сделаем счётчик количества процессов каждого воркера. Из ответа команды active_queues сделаем счётчик количества воркеров на очередь. Используя оба, сделаем счётчик количества процессов на очередь. Пройдя по списку очередей, обновим соответствующие метрики.
Необходимо кешировать названия очередей. Если воркеры будут недоступны, мы сможем обнулить значения для конкретной очереди и отобразить это на графиках. Внимательный читатель может вспомнить проблему с таймаутом воркеров и устаревшими задачами. Здесь она тоже есть. Если в ходе развития проекта был переезд с одной очереди на другую, то устаревшая очередь будет оставаться в памяти и отображаться в метриках.
from celery_exporter import metrics, state
...
def track_queue_metrics(
app: Celery,
connection: Connection,
service_name: str,
) -> None:
inspect = app.control.inspect()
inspect_stats = inspect.stats() or {}
inspect_active_queues = inspect.active_queues() or {}
concurrency_per_worker = {
worker: len(stats['pool'].get('processes', []))
for worker, stats in inspect_stats.items()
}
processes_per_queue: dict[str, int] = defaultdict(int)
workers_per_queue: dict[str, int] = defaultdict(int)
for worker, info_list in inspect_active_queues.items():
for queue_info in info_list:
queue_name = queue_info['name']
state.queues[service_name].add(queue_name)
concurrency = concurrency_per_worker.get(worker, 0)
workers_per_queue[queue_name] += 1
processes_per_queue[queue_name] += concurrency
for queue in state.queues[service_name]:
metrics.celery_active_process_count.labels(
queue_name=queue,
service_name=service_name
).set(processes_per_queue[queue])
metrics.celery_active_worker_count.labels(
queue_name=queue,
service_name=service_name,
).set(workers_per_queue[queue])Пример ответа команды stats
{
"celery@aszubarev-mac.local": {
"total": {},
"pid": 34389,
"clock": "5693",
"uptime": 14933,
"pool": {
"implementation": "celery.concurrency.prefork:TaskPool",
"max-concurrency": 10,
"processes": [
34397,
34398,
34399,
34400,
34401,
34403,
34404,
34405,
34406,
34407
],
"max-tasks-per-child": "N/A",
"put-guarded-by-semaphore": false,
"timeouts": [
0,
0
],
"writes": {
"total": 0,
"avg": "0.00",
"all": "",
"raw": "",
"strategy": "fair",
"inqueues": {
"total": 10,
"active": 0
}
}
},
"broker": {
"hostname": "127.0.0.1",
"userid": "guest",
"virtual_host": "/",
"port": 8672,
"insist": false,
"ssl": false,
"transport": "amqp",
"connect_timeout": 4,
"transport_options": {},
"login_method": "PLAIN",
"uri_prefix": null,
"heartbeat": 120.0,
"failover_strategy": "round-robin",
"alternates": []
},
"prefetch_count": 40,
"rusage": {
"utime": 10.662461,
"stime": 2.223827,
"maxrss": 51179520,
"ixrss": 0,
"idrss": 0,
"isrss": 0,
"minflt": 79384,
"majflt": 25,
"nswap": 0,
"inblock": 0,
"oublock": 0,
"msgsnd": 3032,
"msgrcv": 25751,
"nsignals": 0,
"nvcsw": 1227,
"nivcsw": 39649
}
}
}
Пример ответа команды active_queues
{
"celery@aszubarev-mac.local": [
{
"name": "celery",
"exchange": {
"name": "celery",
"type": "direct",
"arguments": null,
"durable": true,
"passive": false,
"auto_delete": false,
"delivery_mode": null,
"no_declare": false
},
"routing_key": "celery",
"queue_arguments": null,
"binding_arguments": null,
"consumer_arguments": null,
"durable": true,
"exclusive": false,
"auto_delete": false,
"no_ack": false,
"alias": null,
"bindings": [],
"no_declare": null,
"expires": null,
"message_ttl": null,
"max_length": null,
"max_length_bytes": null,
"max_priority": null
}
]
}
celery_exporter/metrics.py
...
celery_active_worker_count = Gauge(
'celery_active_worker_count',
'The number of active workers in broker queue.',
['queue_name', 'service_name'],
registry=registry,
)
celery_active_process_count = Gauge(
'celery_active_process_count',
'The number of active processes in broker queue.',
['queue_name', 'service_name'],
registry=registry,
)Метрики брокера
Можно самостоятельно собирать некоторую информацию у брокера. Например, размеры очередей и количество потребителей. Используя существующий Connection с RabbitMQ, можно по имени очереди получить queue_declare_ok_t c атрибутами message_count и consumer_count.
from amqp import ChannelError
from amqp.protocol import queue_declare_ok_t
...
def track_queue_metrics(
app: Celery,
connection: Connection,
service_name: str,
) -> None:
...
for queue in state.queues[service_name]:
...
consumer_count = 0
message_count = 0
rabbitmq_queue_info = _rabbitmq_queue_info(connection, queue)
if rabbitmq_queue_info:
consumer_count = rabbitmq_queue_info.consumer_count
message_count = rabbitmq_queue_info.message_count
metrics.celery_active_consumer_count.labels(
queue_name=queue,
service_name=service_name,
).set(consumer_count)
metrics.celery_queue_length.labels(
queue_name=queue,
service_name=service_name,
).set(message_count)
def _rabbitmq_queue_info(
connection: Connection,
queue: str,
) -> queue_declare_ok_t | None:
try:
return connection.default_channel.queue_declare(
queue=queue,
passive=True,
)
except ChannelError as ex:
if 'NOT_FOUND' in ex.message:
logger.debug('Queue not found', queue=queue)
return None
raise ex
celery_exporter/metrics.py
...
celery_queue_length = Gauge(
'celery_queue_length',
'The number of message in broker queue.',
['queue_name', 'service_name'],
registry=registry,
)
celery_active_consumer_count = Gauge(
'celery_active_consumer_count',
'The number of active consumer in broker queue.',
['queue_name', 'service_name'],
registry=registry,
)Дашборд
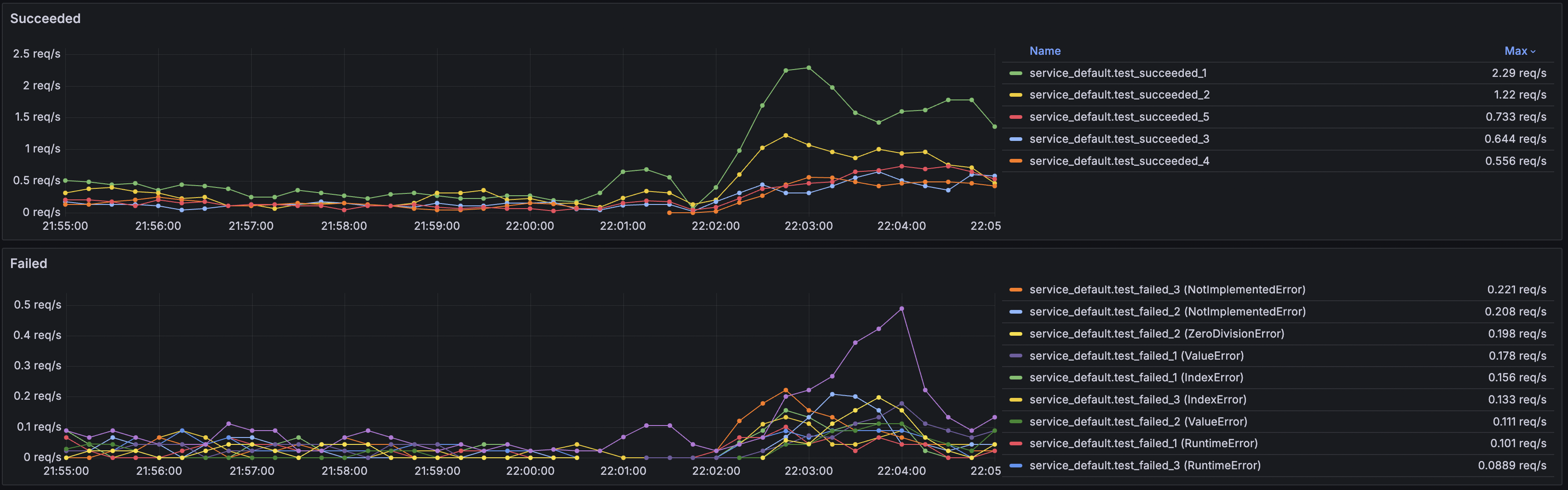
Собрав все необходимые метрики, пришло время сделать дашборд. Тут у всех вкусы разные, каждый настраивает под себя. Мы определили следующий набор графиков, которые, на наш взгляд, достаточно информативно отображают ситуацию конкретного сервиса:
Tasks per seconds c разделением по типу событий.
Latency с разделением по перцентилям.
Tasks per seconds для каждого типа событий отдельно с разделением по задачам. Для ошибок дополнительно разделяем по типу исключения.
Latency с разделением по задачам для 95-го и 50-го перцентилей.
Queue Length c разделением по имени очереди.
Active consumers count c разделением по имени очереди.
Active workers count c разделением по имени очереди.
Active processes count c разделением по имени очереди.
Для демонстрации сделал небольшой стенд. Он содержит набор воркеров, экспортёр, продюсер, RabbitMQ, Prometheus и Grafana. Конфигурацию панели можно взять из worker_tasks.json. При импорте необходимо установить переменные namespace и service_name. Вот что получилось:
Дашборд





Мониторинг
В статье упоминались такие вещи как State, метрики отправителей, метрики устаревших воркеров, задач и очередей. Всё это занимает память. Это нужно держать в голове, когда запускаете мониторинг Celery, причём независимо от того, берёте вы готовое решение или создаете своё. Все проблемы носят фундаментальный характер. Нужно понимать, хватит ли скорости обработки событий, учитывая что ack не требуется. Нужно задумываться над тем, хватит ли размера LRU-кеша в случае всплеска трафика. Или, может, указали такое большое значение, что память кончится раньше, чем начнут замещаться старые задачи.
Всё это требует особого внимания и, соответственно, мониторинга.

Заключение
Мониторинг Celery — достаточно обширная тема. Лишь зная тонкости реализации, можно разумно подойти к выбору решения или к созданию собственного.
Хотел бы отметить проекты, которыми вдохновлялся при написании статьи:
Всем спасибо за внимание! Пишите в комментариях, сталкивались ли вы с подобной проблемой и как вы её решали в своих проектах.
denaspireone
Осталось заменить prometheus на VictoriaMetrics, а что еще лучше - запустить в этой связке еще vmagent который будет собирать метрики и писать в локальную VictoriaMetrics и паралельно дублировать их куда-то еще, к примеру еще в одну VictoriaMetrics Single в другом ДЦ.
PS: Еще можно сделать иначе, а именно писать метрики сразу из приложения используя https://github.com/gistart/prometheus-push-client