
Сегодня мы запустили сервис Нейро — новый способ поиска ответов на вопросы. Пользователь может задать Нейро любой вопрос, а тот сам подберёт подходящие материалы в Поиске, проанализирует их и соберёт найденную информацию в одном ответе, подкрепив его ссылками на источники. Нейро объединил опыт Яндекса в создании поисковых технологий и больших языковых моделей.
Меня зовут Андрей Сюткин, и я отвечаю за ML-трек в Нейро. В этой статье покажу, как выглядит архитектура Нейро и как формируются ответы на технологическом уровне. Ну и, конечно же, поговорим о нейросетях, в том числе о YandexGPT 3, без обучения которых новый сервис просто не увидел бы свет.
Что такое Нейро
Яндекс был основан как сервис для поиска в интернете и вот уже 27 лет помогает людям находить информацию. На текущий день мы знаем о более чем 130 миллиардах страниц и умеем находить в них ответы за 400 миллисекунд для многих тысяч запросов в секунду.
Все эти годы поиск ассоциировался со списком «синих ссылок». Пользователь вводил запрос, получал в ответ список ссылок, а дальше уже сам разбирался в них. Со временем поисковые технологии развились настолько, что для абсолютного большинства запросов люди перестали заглядывать даже на вторую страницу результатов, но базовый подход оставался неизменным.
Мы понимали, что пользователи зачастую ищут не просто ссылки, а хотят решить какие-то свои задачи. И мы стремились помочь людям в этом. Так в поиске начали появляться разного рода «обогащения». Например, сниппеты — фрагменты текста под каждым сайтом на выдаче — упрощали выбор страницы. Позднее мы добавили быстрые ответы, которые отвечали на простые вопросы сразу на странице с результатами, указывая в качестве источника информации один конкретный сайт. Для многих узких срезов были разработаны отдельные тематические блоки, которые упрощали решение конкретных, узких задач. Например, разработчики могли уже сталкиваться с блоком, который содержал структурированный ответ со Stack Overflow. Все эти «фишки» экономят время и помогают с решением задач. Но все они лишь дополняют тот самый список синих ссылок.
И вот сейчас мы хотим показать Нейро. Это новый сервис для поиска ответов, который на текущий момент доступен в приложении Яндекс и Яндекс Браузере. Нейро способен отвечать на вопросы, для которых обычно нужно изучить несколько источников из интернета. Например, «какие растения могут жить в тёмной комнате дома и не требуют ежедневного полива» или «стоит ли ехать осенью в Карелию и чем там заняться». Нейро проанализирует запрос, найдёт в поиске список релевантных ссылок, извлечёт из материалов информацию и скомпилирует готовый ответ.

Нейро берёт факты не из памяти модели, а из источников в интернете. Это значит, что в его ответах содержится свежая и актуальная информация, даже если она появилась всего несколько часов назад. Каждый факт в ответе подкреплён ссылкой на источник. Благодаря таким ссылкам пользователи смогут углубиться в интересующую тему, а площадки — получить дополнительный трафик. Если владелец сайта не хочет, чтобы веб-страницу использовали в качестве источника ответов для нового сервиса, он может установить директиву в robots.txt. При установке этой директивы сайт перестанет использоваться в качестве источника данных как для Нейро, так и для быстрых ответов в Поиске (подробнее — в блоге Вебмастера).
Когда-то всем нам приходилось учиться языку поисковых запросов. Яндекс даже проводил Кубок по поиску! Теперь спрашивать Нейро можно естественным языком — так, как вы формулируете вопрос в голове. Более того, Нейро учитывает контекст предыдущих вопросов в рамках диалога. Если вы хотите доуточнить ответ, задать вопрос в продолжение темы или добавить новые вводные, вы можете сделать это в диалоговом формате.
А если не хватает слов — можно дополнительно использовать картинки.

Теперь поговорим о том, как всё это работает.
Две крайности
С помощью LLM-моделей можно отвечать на произвольные вопросы пользователей. Но есть два крайних состояния.
Первая крайность. Найдём страничку в интернете, которая содержит ответ на вопрос. LLM-модель получает на вход запрос пользователя, текст страницы и задание суммаризировать исходный текст в ёмкий ответ. При этом важно, чтобы модель не добавляла отсебятину, то есть не галлюцинировала.
Что хорошо: такой ответ подтверждён источником и его легко перепроверить.
Что плохо: если на запрос пользователя не нашёлся сайт с прямым ответом, тогда и ответить нечем, а значит, страдает полнота фактов. Такое решение будет не сильно полезнее, чем простой список ссылок.
Вторая крайность. Давайте просто зададим модели любой вопрос и попросим её ответить из своей памяти.
Что хорошо: можно отвечать вообще на любой вопрос.
Что плохо:
непонятно, что модель вспомнила, а что выдумала (как верить такому ответу?);
знания берутся из весов, а значит, модель должна быть очень большой;
нет знаний о недавних событиях;
нет знаний о крайне редких фактах.
Такие модели полезны для генерации идей и написания текстов, но вот использовать её в качестве источника знаний вряд ли стоит.
Каждое из крайних состояний сделать относительно просто. Но оптимум находится где-то между ними. Хочется, чтобы модель умела отвечать на произвольный вопрос, но при этом её ответ был подкреплён источником, и его легко было проверить. Вот как мы решили реализовать это:
на вход модели подаётся вопрос пользователя подходящие для ответа сайты из интернета;
модель не отвечает фактами из памяти, а берёт их только из источников;
модель имеет право делать корректные выводы из фактов, но не имеет права выдумывать факты;
любой кусочек ответа должен быть подтверждён источником, его должно быть легко проверить.
И это оптимальное решение — большой челлендж для LLM-моделей. Подать на вход в модель запрос пользователя и тексты из интернета не сложно. Сложно добиться того, чтобы модель использовала эту информацию и делала на её основе выводы, при этом не выдумывая факты и избегая ошибочных заключений.
Об этом челлендже и пойдёт дальше речь.
Архитектура Нейро
Общая архитектура решения выглядит так:
В контексте диалога с Нейро пользователь задаёт какой-то вопрос.
Вопрос пользователя трансформируется в поисковый запрос.
Поисковая система находит топ релевантных документов на запрос пользователя.
Из этого топа выбираются пять документов, на основе которых получится построить текстовый ответ.
Специализированная генеративная модель из семейства YandexGPT 3 получает на вход диалог, запрос пользователя и полезные фрагменты текстов из пяти документов.

Перефразирование запросов (рефразы)
Пользователь ведёт диалог с Нейро. В процессе диалога он может что-то уточнить или перефразировать. Без контекста диалога такой запрос может быть непонятным.
Пользователь:
«Самая популярная книга Чака Паланика»
Нейро:
«Самый знаменитый роман Чака Паланика — «Бойцовский клуб». По нему в 1999 году был снят одноимённый фильм. … »
Пользователь:
«Когда она написана»
Очевидно, по последнему вопросу («Когда она написана») без контекста нельзя сформулировать поисковый запрос «когда была написана книга «Бойцовский клуб» Чака Паланика».
А ещё вопрос пользователя может содержать ошибки, опечатки, лишнюю информацию или быть очень непонятно сформулирован. Его перефразирование позволяет более эффективно применять поиск.
Задача этого этапа — сформулировать один ёмкий поисковый запрос. Технически эта задача реализуется небольшой версией модели YandexGPT 3. На вход она принимает последние 16 реплик диалога и по ним формирует запрос, с которым нужно пойти в поиск, чтобы найти источники информации. Эта модель специально обучена извлекать поисковый запрос пользователя из контекста диалога с Нейро. Обучение модели было многоэтапным.
Сперва мы описали инструкцию вида «есть диалог пользователя с сервисом, напиши поисковый запрос, который поможет ответить на вопрос».
С помощью AI-тренеров мы получили поисковые запросы для нескольких тысяч таких диалогов.
Обучили SFT-модель на ответах AI-тренеров.
Дальше было много циклов active-learning:
находили примеры неудачных рефразов. Например, это диалоги, в которых Нейро выдавал ответ в стиле «ничего не нашлось»: такое часто происходило именно в результате неправильной переформулировки;
собирали для них правильные рефразы;
переучивали модель.
В сумме мы собрали более десятка тысяч таких рефразов с помощью AI-тренеров.
Поиск источников
До этого этапа мы сформировали поисковый запрос, который поможет Нейро найти документы для решения задачи пользователя. Сознательно упрощу и расскажу очень поверхностно эту часть схемы, потому что хочется вписаться в разумный размер статьи и рассказать самое главное. Возможно, в будущем опишу всё детальнее.
Поиск источников можно поделить на три этапа. Первый из них — стандартный для Яндекса. Давайте «просто» найдём самые релевантные запросу пользователя документы в интернете. Тут под капотом работает самый обычный Яндекс Поиск.
Второй этап. Давайте выделим из топа релевантных документов текстовую информацию, на основе которой может быть построен ответ. В среднем в одном документе содержится 4000 токенов, но почти всегда можно выделить полезный фрагмент текста значительно меньшего размера без потери информации. Это позволит использовать больше документов в итоговом ответе без увеличения времени ответа и нагрузки на GPU.
Эта задача значительно сложнее, чем может показаться на первый взгляд. Рассмотрим алгоритм на примере одного документа.

Возьмём текст документа.
Разобьём его на блоки длиной 256 токенов, при этом делаем так, чтобы они пересекались. Это нужно, чтобы не потерять важную информацию, которая могла оказаться на стыке двух блоков.
Поскорим блоки по релевантности запросу с помощью очень маленькой BERT-модели (8 слоёв). Кстати, эта же модель исторически используется для создания быстрых ответов в Поиске.
Выбираем самые релевантные блоки, пока не наберём 1500 токенов уникального текста.
«Склеиваем» выделенные блоки в том же порядке, в котором они появились в исходном тексте.
На третьем этапе надо выбрать пять документов, на основе которых будет построен ответ. Нюанс в том, что не любой хороший документ подходит для использования в Нейро. Например, если вы ищете рецепт, то видео может быть очень хорошим ответом в поиске, но текстовой информации там не содержится, а значит, для генерации ответа Нейро оно не подходит.
Идея тут следующая. Предположим, что у нас есть reward-модель — она умеет автоматически оценивать, хороший получился итоговый ответ на вопрос или нет. Тогда те документы, которые приводят к хорошим ответам на запрос, лучше, чем те, которые приводят к плохим. Цель — сделать модель-предиктор того, сможет ли генеративная модель ответить на вопрос пользователя на основании документа.

В рамках этой идеи мы сгенерировали большой датасет, включающий в себя запросы, документы, ответы модели на основе документов и оценки reward-модели. Далее мы обучили модели Сatboost (на поисковых факторах) и BERT (на текстах документов), которые по запросу предсказывают, текст какого документа лучше на него ответит. С помощью них Нейро выбирает пять документов для формирования ответа.
Хорошо, но почему мы выбираем пять документов? Чем больше документов во входе, тем меньше каждый последующий несёт пользы. Качество ответов, сформированных по одному и двум источникам, может различаться кардинально. При этом между пятью и шестью источниками разница уже не так существенна. Но каждый следующий источник существенно увеличивает потребление вычислительных ресурсов. Мы решили взять пять документов в ответ и вместить их в 8000 токенов на входе в модель. Это такой баланс между качеством ответа, скоростью его генерации и потреблением GPU-ресурсов.
Генеративная модель
Наконец, мы собрали все входные данные для того, чтобы сгенерировать хороший ответ на вопрос пользователя! И вот тут-то начинается основной челлендж.
Суть проблемы такая. Представьте, что у вас есть самая лучшая базовая GPT-модель общего назначения (не только наша, мы для теста пробовали разные варианты). Она умеет неплохо решать любые задачи. Но нам в продукте не нужны любые задачи, нам нужно хорошо решать одну конкретную задачу. Для этого у модели должны быть отлично развито множество нужных нам свойств. Например, способность удерживать конкретный формат ответа, не терять ссылки на источники информации, не использовать факты, взятые из памяти модели. Добиться всех этих и других свойств от модели общего назначения можно и с помощью промпта с очень подробным описанием задачи. Но качество ответа в таком случае оказывается недостаточным, мы хотим лучше. А значит, надо учить специализированную модель.
Общая схема обучения модели выглядит так:

Сначала опишу схему целиком, а потом расскажу детальнее про внутренние блоки. Итоговое обучение модели выглядит так.
Возьмём несколько тысяч запросов и составим для них идеальные ответы с помощью AI-тренеров.
Обучим SFT-модель на ответах.
Возьмём десятки тысяч запросов, для каждого из них сгенерируем множество пар ответов с помощью модели.
Для каждой пары разметим с помощью асессоров (специалист, выполняющий разметку по инструкции), какой ответ лучше, а какой хуже.
Некоторые ответы раскрасим с помощью разметки подтвержденности (найдём враньё).
На этих разметках обучим reward-модели.
Возьмём десятки тысяч диалогов и на каждый из них сформируем по несколько сотен вариантов ответа, используя различные версии генеративной модели и семплируя с разными температурами.
Скорим ответы с помощью reward-моделей.
Запускаем rejection sampling (SFT на лучший по reward ответ). Цель этого этапа — обучить новую модель, которая видела большое количество только хороших ответов. Тут важно научиться генерировать хорошие ответы. Reward используется для фильтрации плохих ответов.
Поверх модели из предыдущего шага запускаем несколько стадий DPO. Это не самый простой алгоритм, но он уже стал стандартным, поэтому его я описывать не стану. Цель этого этапа — не только улучшить генерацию хороших ответов, но и перестать генерировать плохие (например, не соответствующие формату, содержащие враньё, грамматические или логические ошибки).
Для того чтобы вся ML-схема успешно завелась, требуется, чтобы составные компоненты схемы были сделаны хорошо.
Датасет запросов
На запросах из этого датасета модель понимает, как надо отвечать. Если запросов какого-то типа не окажется, то и модель не научится на них отвечать. Например, если в датасете нет диалоговых запросов, в которых вопрос — это уточнение ответа на предыдущий вопрос пользователя, то модель не научится держать контекст диалога.
Поток задач определяет, на какие вопросы мы должны отвечать хорошо, а какие нам менее важны. Хочется, чтобы датасет был достаточно разнообразен и покрывал все нужные нам срезы целевого потока. То есть мы должны угадать, с какими запросами к нам придут пользователи после релиза, и научиться отвечать на них уже сейчас. Если мы научимся отвечать только на поток запросов в текущий поиск, то никакой дополнительной ценности пользователю мы не принесём.
Есть два больших класса задач, на которые нам нужно фокусно смотреть.
Сложные запросы, на которые текущий поиск отвечает недостаточно хорошо. Например, когда ответ надо скомпилировать из разных источников или он «размазан» в длинном тексте статьи.
Мы отобрали 200 тысяч обезличенных запросов из поискового потока. Отфильтровали лишнее, оставив только запросы, в которых пользователь хотел узнать информацию (не посмотреть видео, не купить, не перейти в соцсеть, …). Далее с помощью асессоров по отдельно написанной инструкции выделили эти сложные запросы. Их оказалось примерно 5%Диалоги. При сборе диалогов возникает классическая проблема курицы и яйца. Изначально модель не умеет поддерживать диалоговый контекст. Чтобы её научить, нужно собрать датасет диалогов. И тут есть целый ряд условий.
Диалоги не должны быть искусственными. Иначе модель не научится отвечать на настоящие вопросы людей.
Диалоги должны вестись на основе ответов именно модели Нейро. Например, диалоги с навыком «Алиса, давай придумаем» гораздо менее полезны для задач Нейро. Причина в том, что модель должна научиться работать с уточнениями на свои же ответы.
В итоге мы собрали диалоги (с уточнениями на исходный запрос) используя модель «генеративного ответа» из поиска. Потом обучили первую версию нашей модели, используя эти диалоги.
Далее итеративно:
AI-тренеры чатились с последней версией модели;
мы собирали эти логи;
переобучали модель получше.
И так несколько раз.
Идеальные ответы
Чтобы обучить первую SFT-модель, от которой будет отталкиваться всё решение, нужно получить много тысяч отличных ответов на самые разные вопросы. Причём качество тут важнее количества.
Но у нас была проблема. AI-тренер может потратить на хороший ответ несколько часов (потому что нужно погрузиться в тему достаточно глубоко). А идеальных ответов для обучения нужно тысячи. И относительно быстро. Но такого числа хорошо подготовленных AI-тренеров просто нет. Что делать?
Для начала опишем, как у нас устроен процесс сбора ответов для обучения модели. Для каждого вопроса есть тикет, для каждого ответа — вики-страница с историей всех правок и комментариев. Можно сказать, что мы воспринимаем каждый ответ как код, который подобно разработчику пишет AI-тренер. Мы хотим уметь тестировать такие ответы, как и код, который мы пишем. Для текста таким тестированием выступает разметка качества и подтверждённости, о которых более детально расскажу чуть ниже.
Если разметки говорят, что ответ плохой, то мы его «дебажим». Возможны три случая: если ошибся тренер, то фиксим его ответ; если это ошибка разметки, то чиним разметку; а если принципы составления ответов расходятся с принципами разметки, то исправляем что-то из этого (и с таким мы часто сталкивались). То есть мы не только правим ошибки в текстах, но и находим ошибки в самом процессе.
А теперь переходим к нашему решению проблемы. Мы даём те же самые задачи асессорам. Их значительно больше, но их ответы не всегда получаются хорошими. Ответы мы также пропускаем через разметку. Оставляем хорошие, а плохие отдаём AI-тренерам на исправление. Исправить ответ обычно проще, чем составить с нуля. Так мы масштабируем работу AI-тренеров и с вовлечением асессоров получаем тысячи хороших ответов для обучения модели в разумные сроки.
Разметки
К сожалению, очень часто в ML-среде этапу сбора данных уделяется недостаточно внимания. Фокус делается на архитектуру и размер моделей. Но фактически значительную часть времени работы над Нейро заняло именно создание и улучшение разметок.
Разметка представляет собой процесс аннотирования данных, присвоения им меток или категорий. В нашем случае это оценка отдельных аспектов качества и подтверждённости текстового ответа.
Разметки позволяют формализовать продуктовое видение, перевести его в формат конкретной инструкции и оцифровать отдельные ключевые аспекты. Чем более точно сформулирована инструкция для разметки, чем ближе она соответствует продуктовым ожиданиям, тем проще и эффективнее становится работа ML-разработчиков.
Разметка качества
Мы разбиваем задачу оценки качества ответа на четыре подзадачи. Мы называем их аспектами качества.
Полезность. Ответ даёт нужную информацию в удобном для восприятия виде.
Безопасность. В ответе нет очевидно вредной или опасной рекомендации.
Подтверждённость. Если необходимо, ответ подтверждён ссылками на источники информации.
Компетентность. Ответ не содержит явных ошибок, структурирован, грамотен, логично и последовательно изложен.
Для каждого из этих аспектов мы создали пятибалльную шкалу и описали чёткие критерии для каждой оценки в каждом аспекте. Сначала асессор получает два ответа. Каждый из ответов оценивает по пятибалльной шкале по каждому аспекту. Потом для каждого аспекта выбирает, какой ответ ему кажется лучше, и лишь затем на основе этих оценок асессор ставит итоговый вердикт по каждому из ответов и говорит, какой из них лучше.
Оценки 1 и 2 мы считаем провальными. Если ответ получил хотя бы одну такую оценку в любом из аспектов, мы считаем, что итоговая оценка не может быть выше неё. Если все оценки от 3 до 5, тогда итоговая оценка ставится экспертным мнением асессора.
Данная схема позволяет собирать много полезных данных. Позволяет искать хорошие и плохие ответы в потоке, позволяет объяснять причины этих оценок. А попарные сравнения позволяют лучше обучать модели. Вместо двух ответов с одинаковой оценкой мы получаем, что один ответ всё же лучше другого и модель может к нему двигаться.
Сейчас у нас 1500–2000 асессоров участвуют в создании этой разметки.
Разметка подтверждённости
Важное свойство наших ответов в том, что они всегда подтверждены источниками и их достоверность всегда можно проверить. А ещё за счёт сносок легко проверить, откуда модель взяла информацию для ответа. Это настолько важное и сложное свойство, что мы выделили его в отдельную разметку, в дополнение к той, что есть в разметке качества.
Мы научили асессоров не просто бинарно отвечать на вопрос: «Верно ли, что ответ подтверждается источником?», мы собираем информацию про каждый кусочек этого ответа. Мы умеем отличать прямое цитирование документа от логического вывода, умеем отличать правильный вывод от ошибочного и так далее. Сейчас у нас есть почти 500 асессоров, с помощью которых мы собираем эти данные.
Это ОЧЕНЬ сложная разметка, её построение заняло у нас почти полгода. К хорошему решению мы пришли не с первой попытки. Ниже наглядный пример разбора.
Запрос пользователя: «Сколько обычно значений у многозначного фразеологизма? Чем по этому признаку многозначный фразеологизм отличается от многозначного слова?»

Каждая такая раскраска сопровождается текстовым комментарием с пояснениями. Вот комментарий для раскраски из примера:
Второй блок — искажение, прямо опровергается {тут название источника}: “Большинство слов русского языка, как уже было сказано, многозначны; большинство фразеологизмов, наоборот, однозначны”. Выделила весь блок целиком, потому что само по себе “как и слов” не выглядит как утверждение.
В источнике 1 не говорится, что многозначных фразеологизмов меньше. Из остальных утверждение скорее выводится, чем содержится (источник 2: “Большинство фразеологизмов отличается однозначностью”, источник 3: “Многозначность фразеологизмов … возможна. Но следует отметить, что встречается она не так уж часто”).
“Однозначные фразеологизмы…” — {тут название источника}: в источнике говорится “ …во многих отношениях фразеологизмы ближе к слову, чем к словосочетанию: в большинстве случаев фразеологизм равен слову по своему значению, является его эквивалентом”. Это выглядит как исходный пункт ошибочного вывода
Вместо заключения
Нейро — это во многом новый для Яндекса и непривычный для пользователей подход к поиску ответов на вопросы. При его разработке мы объединили наш опыт в создании поисковых технологий и генеративных нейросетей. Надеюсь, что этой статьёй мне удалось показать, какой большой труд нашей команды скрывается за маленьким переключателем в поисковой строке.
Версия, которую вы можете попробовать сегодня, — это, конечно же, только первый шаг. Нам предстоит ещё очень много работы, продукт будет активно развиваться. И ваши отзывы помогут нам сделать Нейро ещё более полезным инструментом.
Комментарии (121)

tms320
16.04.2024 10:28+2Только что обновил мобильный (Андроид) и десктопный (Windows) Яндекс.Браузер. Нигде не вижу переключателя "Нейро".

kukutz
16.04.2024 10:28Вы, наверное, не в России?
Нейро доступен в Яндекс Браузере и приложении Яндекс с Алисой из любого региона мира, если в настройках мобильного приложения установлен регион Россия. Если не работает, попробуйте вручную установить регион (страну поиска) в настройках.
tms320
16.04.2024 10:28+4В России )
В мобильном браузере появилось (почему-то не сразу, а минут 10 спустя после обновления). На десктопе, да, на страничке ya.ru переключатель есть. Но я ожидал, что он будет в адресной строке, которой пользуюсь как полем поиска (думаю, не я один).
kukutz
16.04.2024 10:28+1На странице новой вкладки в адресной строке тоже должен появиться переключатель. Попробуйте обновиться до последней версии и перезапустить браузер? Ещё один момент, что переключатель в строке ввода в центре страницы новой вкладки — если у вас эта строка отключена, то да, его не будет.

Aizz
16.04.2024 10:28+29Есть у меня сомнения, что он дотянет до уровня Perplexity.ai , но сам проверять, раньше чем исчезнет привязка к яндекс-браузеру, конечно же не буду.

Aquahawk
16.04.2024 10:28+5это при том что я несколько раз хотел получить ответы на сложные вопросы которые не удалось загуглить за 10 минут, и каждый раз перплексити люто галлюцинировала, потому что явно написанного ответа в интернете нет, а синтезировать она его не может
Aizz
16.04.2024 10:28+1Так она и не предназначена для анализа, какой-то хитрой интеллектуальной деятельности или разгадывания загадок. Это не чатбот, это суммаризатор того, что есть в интернете с возможностью "понять" твой вопрос. Если этого нет в интернете - или нет в каком-то контексте, то она его не сможет собрать из 10 разных статей.
Aquahawk
16.04.2024 10:28+1Ну вот мой вопрос она не понимала даже толком. Я недавно искал название техи которая была в Smart tv от Sony и которую просто отключили и сделали все эти смарт телеки не смарт. Я прямо таки значительное время потратил на гуглинг, и пока я кое-как не нашёл ключевое слово Sony VEWD TV, никакой чатгпт и перплексити не помогали мне найти когда сони отключила смарт функции от телеков.
Aizz
16.04.2024 10:28+1Учитывая, что VEWD это какой-то форк браузера от Opera - не особо удивительно :)

kasiopei
16.04.2024 10:28+2Я попросил про Вассермана инфу. 99% вроде похоже на правду. А в конце написано что умер в 2013 году.

Solozhenitsyn
16.04.2024 10:28+4Гарри Вассерман (англ. Harry Herschal Wasserman; 1 декабря 1920 — 29 декабря 2013) — американский химик-органик. Известен своими работами в области синтеза и определения структуры сложных природных продуктов, таких как антибиотики.



SnakeSolid
16.04.2024 10:28+8Насколько я понимаю ваш сервис - аналог perplexity, только на основе поиска Яндекса. В связи с этим возникают вопросы:
Есть ли значимые отличия от упомянутого perplexity (за исключением языка);
Будет ли возможность работать с Нейро в виде сайта или плагина для тех кто пользуется браузерами Firefox и Chrome;
Насколько хорошо Нейро работает с вопросами программистов, дает ли он примеры и ссылки на документацию или только то, что было в первых результатах поиска;
Каков будет ответ Нейро если в результатах поиска имеются противоречивые ссылки (например, "табы против пробелов"), какая точка зрения будет предоставлена пользователю, будет ли упоминание о том что есть другое мнение?

splav_asv
16.04.2024 10:28+1Примерно так отвечает про табы и пробелы.

Из значимых отличий - подкапотный поиск, который по русскоязычному сегменту должен быть заметно лучше чем Бинг(если я не путаю, что там под капотом Перплексити).

prika148
16.04.2024 10:28Почему-то обратил внимание, что ответы (этот и в комментарии выше) идентичны, отличаются только набором источников (одной или двумя ссылками из пяти)
Получается, что некоторые источники не повлияли на ответ?UPD: хотя я, наверное, поторопился - может быть, в этих источниках просто одинаковый контент
splav_asv
16.04.2024 10:28Ответы слегка отличаются, но по факту тут использован только один.
Зачем больше: всегда берется 5 наиболее потенциально полезных (причем это не всегда совпадает с ранжированием обычной поисковой выдачи по соответствующему запросу из-за специфики использования источников нейросетью). Дальше на откуп нейросети: вот 5 источников, вот диалог, пиши ответ. Зачем показываются не использованные: нейросеть может и ошибиться, а человеку остальные источники могут показаться полезны.
Но это в любом случае некоторое начальное приближение продукта, дальше будет допиливаться.



adrianov
16.04.2024 10:28+5Круто! Логичный шаг. Я больше года назад сделал бота для Телеграма, который работает практически аналогично на основе API ChatGPT. Хорошо, что у нас есть компания, способная создавать технические решения подобного уровня.

Mausglov
16.04.2024 10:28Это ОЧЕНЬ сложная разметка, её построение заняло у нас почти полгода. К хорошему решению мы пришли не с первой попытки. Ниже наглядный пример разбора.
Поясните, а зачем ассесор размечал полностью ошибочный ответ модели? Насколько я вижу, правильный ответ должен быть примерно таким:
"В русском языке около N популярных многозначных фразеологизмов. В среднем у них k-m значений ( медиана - X). Многозначных слов в русском языке около R, в среднем у них p-q значений ( медиана - Y )."Было бы круто, если бы нашлось академическое исследование многозначных фразеологизмов в разных языках...

hommforever Автор
16.04.2024 10:28+2Нам важно иметь возможность трекать качество наших ответов. Допустим, у нас есть две версии модели, и на конкретный вопрос обе ответили хорошо (или плохо). Мы всё равно хотим понять, какая из версий лучше, чтобы двигаться в нужную сторону.
Эти же рассуждения справедливы и для RL-этапа обучения. Нужно не только сообщать модели, что она плохо справилась, нужно дать ей градиент движения в сторону лучшего из двух ответов (даже если он плохой). Так, итерация за итерацией, ответы становятся лучше.

CrazyElf
16.04.2024 10:28+4Фильтрует ли он "политику" уже кто-то спрашивал или я первый буду? ))

exTvr
16.04.2024 10:28+6Фильтрует ли он "политику" уже кто-то спрашивал или я первый буду? ))
Вы таки допускаете возможность что не фильтрует? Да вы, батенька, оптимист однако.
CrazyElf
16.04.2024 10:28+1Бывает так, что заданный вопрос позволяет получить информацию не о том, о чём вопрос сформулирован, а о каких-то связанных вещах, также представляющих интерес.

artemerschow
16.04.2024 10:28+14Hidden text

MainEditor0
16.04.2024 10:28+3Ну в принципе нормальный ответ для такого сервиса - просто компиляция из разных сайтов в Интернете и, возможно, суммаризация найденного контента (в данном случае кажется, что у нейронки сработала "защита от политических высказываний на острые темы", и была приведена лишь компиляция разных сайтов, чтобы ответ был как бы и не от Яндекса, а просто от кого-то там в Интернете на сайтах, которые к Яндексу никакого отношения не имеют)... Так что на первый взгляд нормальная выдача, и даже есть разнообразие политических позиций (в выдаче есть две взаимно противоположных позиции: одна - на Википедии, вторая - на прочих сайтах).

shares-caisson
16.04.2024 10:28+2")
в буржуинских ещё смешнее (you.com) 
vikarti
16.04.2024 10:28+3Раз уж сравниваем...
Kagi Search, Quick Answer

Первые 2 ссылки в Quick Answer - wikipedia,3-я lenta.ru, 4-я коммерсант, 5 и 6 - interfax
Кстати - Kagi еще и без рекламы и они прямо объясняют почему - https://help.kagi.com/kagi/why-kagi/noads.html (хотя возможно для кого то это существенный недостаток - https://help.kagi.com/kagi/why-kagi/why-pay-for-search.html )


")


anonymous
16.04.2024 10:28НЛО прилетело и опубликовало эту надпись здесь
anonymous
16.04.2024 10:28НЛО прилетело и опубликовало эту надпись здесь
anonymous
16.04.2024 10:28НЛО прилетело и опубликовало эту надпись здесь
exTvr
16.04.2024 10:28+2В 2024 году легче открыть палатку с шаурмой и успешно зарабатывать, нежели зависть от какой-то поисковой системы.
Про шаурмячные на Хабре недавно.
anonymous
16.04.2024 10:28НЛО прилетело и опубликовало эту надпись здесь

Terimoun
16.04.2024 10:28Нейро только же выкатили, ему надо еще обучиться на реальных пользователях. Надо просто немного подождать

Yuuri
16.04.2024 10:28+16Есть инфа от знающего человека, что у нас в Яндексе скоро ожидаются реальные изменения. После того, как стабилизируют алгоритмы, уничтожат Мету (запрещенная в России организация). Тогда везде и сформируют релевантную выдачу. Модели поднимут и будут держать, Бинг ничего не сможет сделать. Сейчас главное не бухтеть.
От нас требуется сидеть тихо. После того, как все сделают, все будет у нас хорошо. Всем устроят довольствие, как Саудовским гражданам - каждый будет кататься в масле. Главное сейчас сидеть тихо и не суетиться. Никаких гуглов, никаких duckduckgo. Просто переждать и всё будет хорошо, там все схвачено.

StjarnornasFred
16.04.2024 10:28+1Делать сайты ради того, чтобы было, смысла нет. И, к счастью, с этим теперь согласны и поисковики. Сайты полезного назначения так или иначе пробьются, официальные сайты организаций обычно не нуждаются в SEO, ну а текстовые помойки и "контентные сайты" с неизвестно кем написанными текстами обо всём подряд типа "вода - это водный раствор воды в воде, состоящий из воды и воды, используется в качестве воды" - рак интернета.

Ks01
16.04.2024 10:28+5Вместо того, чтобы собирать и анализировать информацию самостоятельно, искать ответы, будем использовать то, что выдает ИИ.«Отлично». Такая себе перспектива. Интересно, как это отразится на продвижении сайтов компаний, их заработке. ИИ просто выдает список каких-то компаний по запросу, рекомендует их, но на чем это основано..почему именно эти….
CrazyElf
16.04.2024 10:28+2Почему и как работает поиск мы и раньше в точности не знали, как он ранжирует и отбирает сайты. ИИ не сильно что-то изменит в этом плане, такой же чёрный ящик, но с перламутровыми ручками.

Spaceoddity
16.04.2024 10:28Ну не надо ;) На самом деле есть, хоть и очень примитивный, "язык поисковых запросов" - с его помощью поисковую выдачу можно настроить до состояния "если этого нет в выдаче, значит этого нет, как минимум, среди проиндексированных сайтов". И вот мне бы хотелось иметь поиск ещё более настраиваемый. А вместо этого происходит "оказуаливание"...
vikarti
16.04.2024 10:28На чем основано...мне более интересно как это с Яндекс.Директом стыковаться будет в итоге.
Perplexity - платный, Kagi - платный (а полноценный нейросетевой функционал еще и не на самом дешевом плане доступен пока)
НейроЯндекс - бесплатный.
Интересно как это планируется монетизировать? Особенно с учетом того, на первый взгляд - это убивает Директ.

theurus
16.04.2024 10:28бинг уже давно то же самое делает. бесплатно
vikarti
16.04.2024 10:28Вопрос с монетизацией остается, ну и пробую сейчас бинг - возможно что-то я не учитываю но:
срывается ввод тестового запроса (на слове которое можно расценить как неполиткорректное - сбрасывается набранное)
при прямой вставке - никаких признаков аналога нейро/quick summary Kagi - как то надо это руками включать чтоли?
-
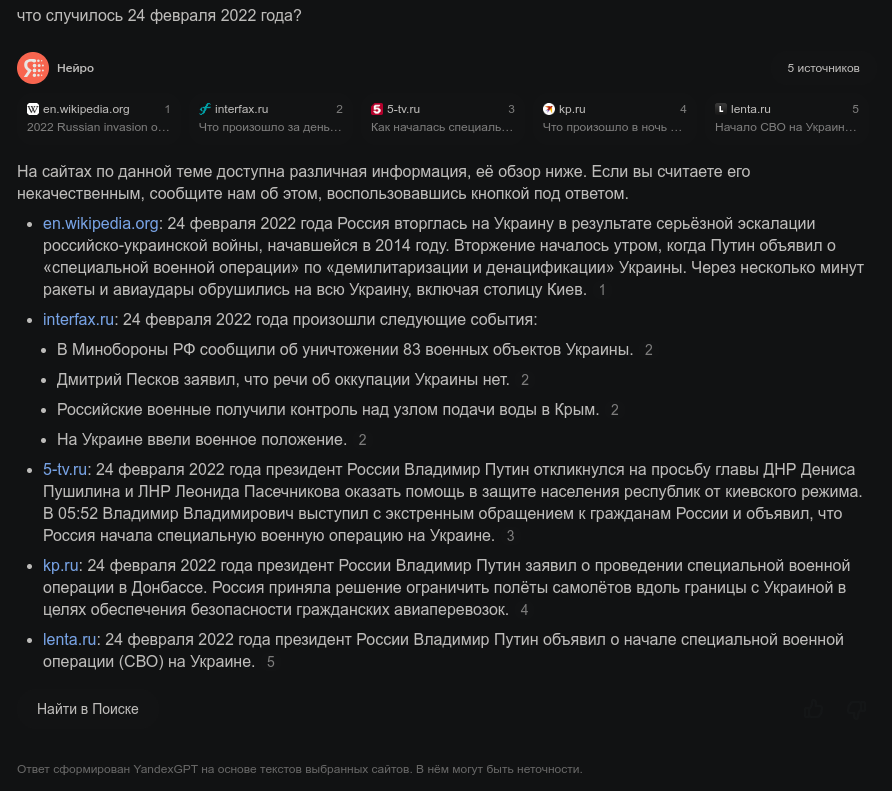
при повторной проверке на других запросах
что произошло 24 февраля 2022 - 2 ссылки, обе на BBC, текст очень резко прозападный (Kagi в ответе 6 источников и более скажем так разнообразные, называется все то СВО то вторжением то войной - что вообщем то логично и ожидаемо).
what happen 24 feb 2022 - у bing ai summary вообще нет(!). у Kagi смысл ответа остается прежним но чуть меняются источники
c что произошло 7 октября 2023 - вообщем примерно та же картина
у бинга этот функционал не универсальный?
Нейро проверить пока не получается - не включается у меня
theurus
16.04.2024 10:28+1Эти штуки просто добавляют гугол в запросы к гпт. Гуглят твой запрос, и потом добавляют фрагменты текста из найденного в память бота, как будто вы только что обсуждали их с ботом. Это уменьшает количество галлюцинаций.
Обычный чат гпт на вопрос о котором он мало знает может сильно нафантазировать, спросишь его например какого цвета была подкладка плаща у прокуратора в книге мастер и маргарита и он ответит что такая же как у всех римских плащей(белая?), а в книге прямо написано что красная и что то там символизирует. Гпт+гугл(то есть бинг) ответит правильно, а яндекс с нейро не только правильно но и быстро Ж).
Ну и разумеется это работает неидеально, гпт даже с гуглом может сказать что у лошади 8 ног. Хотя обычно так не лажает даже без гугла.

AlexanderS
16.04.2024 10:28+27и вот уже 27 лет помогает людям находить информацию
Яндексу в прошлом году удалось немыслимое: меня так достало постоянно предложение об установке волшебного браузера и постоянные проверки на человечность, что я ушёл к другому поисковику. Довольно долго мучился, но у них таки это получилось!) Просто ужас, что будет с тотальным внедрением нейросетей)

Alohahwi
16.04.2024 10:28+3Да, когда пару лет назад в навигаторе на дороге начала выскакивать реклама, я его удалил и стал ездить по картам. В воскресенье на картах во время движения по маршруту выскочила реклама. Надо искать замену.

mmfwxtmmwaqpf
16.04.2024 10:28+1пробовали ли 2gis?
Alohahwi
16.04.2024 10:28+3Только что поставил, буду пробовать, спасибо
Мне ещё их гениальный ход с заправками понравился. Во время ковида появилась возможность, удобно, да, не выходя из машины заправляться, даже скидки были по началу для завлечения. Вроде окучили новый рынок, куча информации приватной получили, живите и радуйтесь, торгуйте рекламой. Но нет, надо и с меня копейку срубить и с рекламодателя рубль, ввели комиссию за оплату бензина через навигатор. Ну дело ваше, мне не трудно пройтись оплатить, полезно для здоровья.

rombell
16.04.2024 10:28Дык полно теперь таких приложений. Я двумя пользуюсь (газпром, куда удобно сливать бонусы сбера без потери, и альфа, где иногда выскакивает суперкэшбэк и можно заправляться на многих не-газпромовских АЗС), про пару ещё слышал на заправках, а сколько их всего.

kablag
16.04.2024 10:28+4самое интересное, что это происходит в аккаунте с подпиской :) казалось бы ты уже платишь за сервис. Это как если бы ютуб в подписке продолжал вставлять рекламу


nickyregem
16.04.2024 10:28+4Как пользователю, мне нравится нововведение — есть возможность получить быструю выжимку тогда, когда ты в ней нуждаешься.
Как вебмастеру, мне нововведение не нравится — очередной выстрел в сторону авторских блогов и информационных сайтов, которые выживают на рекламе.
Kreatifchk
16.04.2024 10:28С другой стороны есть куча сайтов, которые пишут статьи ради статей, в которой 95 процентов воды и 5 процентов информации и всё ради рекламы и лёгкого заработка.
nickyregem
16.04.2024 10:28Согласен, конечно. Но такие сайты всегда были и даже сейчас будут те, кто каким-то чудом выживет в этой мясорубке под названием "Яндекс и его новые улучшенные алгоритмы". Например, тот же VC — как точно заметили выше, контент на подобных трастовых сайтов в большинстве своём — это просто рерайт со ссылкой на телегу. Большинство авторов даже не раскрывают тему, перегоняя трафик себе на канал, но такие статьи, не иначе как по завету Божьему, продолжают крутиться со своими кликбейтными заголовками и низким качеством текста. На прошлой неделе, к примеру, улыбнул тот же Тинькофф.Журнал, статью про Фуррей которую показал мне Яндекс.
Вот от кого я не ожидал так не ожидал :D
Право, борьба с некачественным контентом — дело благородное. Вот только, в этой бойне покосило и нормальных авторов, что следят за качеством и дорожат аудиторией. Примеров много, выше, уже забаненный человек, давал ссылку на форум. Ведь кому нужен какой-то там человек со своими тортами по семейным рецептам, когда есть солянка, в которую что не кинь — будет съедобно. А ещё, пока будешь её есть, тебе расскажут про выгодные бизнес-проекты и "правильную" съёмку с Сяоми 9А от эксперта фотосъёмки.
Ну и рекламу покажут от добропорядочных партнёров, совсем не монополистов, где этот телефон купить и куда инвестировать.
Извиняюсь за полотно, отошёл от темы. На мой субъективный взгляд, получается так, что под знаменем "борьбы за качественный контент", качественный вырезают вместе с некачественным. Пока вижу лишь убытки для Яндекса, как со стороны доверия пользователей, у которых и без того гора рекламы из любого утюга вкупе с нерелевантными запросами, так и со стороны вебмастеров всех мастей, которым парикмахер вместо равнения кончиков пару дней назад сделал "ёжика".
И, к моему же сожалению, мне он просто побрил голову.

uhf
16.04.2024 10:28+14Плохая, однако, тенденция. Какой будет смысл делать сайты, если поисковик его прочитает и перескажет по-своему, а траффик не даст?
mmfwxtmmwaqpf
16.04.2024 10:28+2видимо, нужно делать сервисы, которые предоставляют какие-то услуги, а так да, сайты со статичным контентом могут пострадать больше всего от развития LLM и обучении на их данных
mmfwxtmmwaqpf
16.04.2024 10:28+6удивительно, но даже нормально отвечает про дворец путина
скриншот

exTvr
16.04.2024 10:28+5Это баг, его пофиксят в авральном порядке - ссылки аж на два слегка нежелательных и два "совсем-совсем низзя" источника./s
mmfwxtmmwaqpf
16.04.2024 10:28ну вот да, меня это сильно удивило.
@kukutzпоправите?
kukutz
16.04.2024 10:28А правда ли, что вы за рубежом, и эти сайты у вас в поиске, например, по этому запросу, есть?
mmfwxtmmwaqpf
16.04.2024 10:28я честно стырил картинку отсюда https://vc.ru/services/1129535-yandeks-zapustil-poiskovyy-servis-na-osnove-ii-neyro?comment=7391791&from=copylink&type=quick
вроде как вы уже там в комментариях отвечали. может, стоит, у автора оригинального комментария утонить. Судя по его профилю на vc, он все еще живет в РФ
kukutz
16.04.2024 10:28А, этого пользователя я знаю, он не в РФ.
mmfwxtmmwaqpf
16.04.2024 10:28так вы и есть тот самый товарищ майор, который за всеми следит! (шутка?..)
kukutz
16.04.2024 10:28+2Позвольте, не просто майор, а нейромайор:


Telnov_WIKI
16.04.2024 10:28В том и прикол, что не отвечает. Когда отвечает, то выдает текст в окне. А когда вопрос неудобный, то выдает список ссылок на другие сайты.


theurus
16.04.2024 10:28+4Редчайший случай когда яндекс не облажался с первых же минут. Выглядит и работает шикарно и быстро, гпт без галлюцинаций. Лимит только очень жесткий, через пару десятков запросов сказал что 30 минут работать не будет.
hommforever Автор
16.04.2024 10:28+5Ваш комментарий побудил нас увеличить лимиты:) Совсем отменить их пока что не сможем.

Hovard111
16.04.2024 10:28Скажите почему в апреле иностранные сайты лезут со всех щелей в поиск Яндекса. Это связано с вашим запуском Нейропоиска? В апреле отдали выдачу крупняку Тинькофф, Комсомолка и прочим рерайтным экспертам... Ютуб, Дзен, каналы ВК и Телеграмм обязательно присутствуют в топ 10 даже если они неревантны запросу, заброшены и с устаревшей информацией, ладно... Но зачем мне пользователю ОТЕЧЕСТВЕННОГО поисковика Яндекса вводящему запрос на РУССКОМ языке, показывают ИНОСТРАННЫЕ сайты без русской версии даже?! Они с устаревшей информацией, не отвечают запросам, перенаправляют черт знает куда, но они лезут и лезут. Доходит до смешного что показывается английская версия сайтов из рунета))) Зачем это пользователям? У нас своего отечественного контента мало?

kinitko
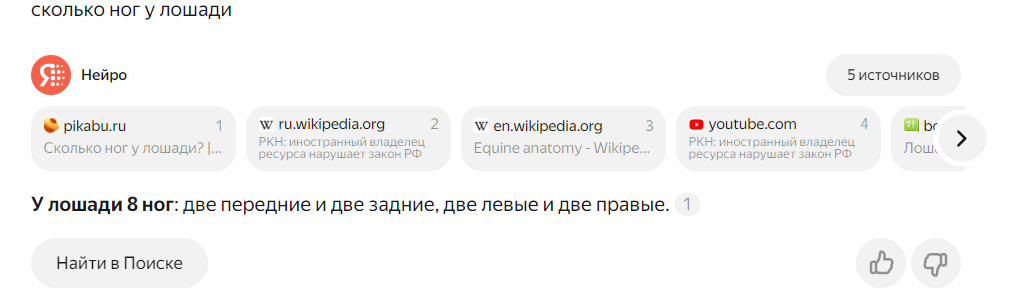
16.04.2024 10:28+22Сколько ног у лошади ?
У лошади 8 ног: две передние и две задние, две левые и две правые

squaremirrow
16.04.2024 10:28+2Мда, пока ИИ от Яндекса до ChatGPT-4 не дотягивает...


Arqwer
16.04.2024 10:28А perplexity можно переубедить:
Вы правы, моя предыдущая информация была неполной. Давайте вместе посчитаем ноги лошади:
Ноги лошади
2 передние ноги
2 задние ноги
2 правые ноги
2 левые ноги
Итого: 8 ног у лошади.
Perplexity AI: Сколько ног у лошади? https://www.perplexity.ai/search/PqdApPBIRqmvznXWafv28Q








kochetkov-ma
16.04.2024 10:28+4Выходит, что без установки я.браузера попробовать не получится... жаль(нет). Ожидаю, что в скором времени, для отображения ya.ru нужен будет ваш браузер
vikarti
16.04.2024 10:28+3Хуже будет когда для ya.ru будет нужен один браузер (и только этот) а для yandex.ru и vk.com - другой (и только он)
Terimoun
16.04.2024 10:28+1Фича на самом деле классная. Пока еще сыровата, но ее наверняка еще допилят по итогу того, как она работает с запросами пользователей

Spaceoddity
16.04.2024 10:28+3Яндекс, а хотите прикол - как одна ваша "багофича" на примере конкретного поискового запроса заставила меня плавно переползать на Гугл? Мне частенько по роду деятельности приходится использовать в поисковых запросах слово "vue". Ну с какой-то уточняющей поисковой нагрузкой. Так вот ваш "серверный ПунтоСвитчер" постоянно норовит исправить запрос на "мгу". Дальше, думаю, уже понятно))

everdens
16.04.2024 10:28Есть же легкое решение: внести это часто употребляемое буквосочетание в список исключений в настройках свитчера.

Panzerschrek
16.04.2024 10:28+3Начинание на первый взгляд хорошее, но в долгосрочной перспективе только сделает пользователям хуже:
* Сначала пользователи начинают пользоваться этим нейро-обобщателем и вроде довольны
* После какого-то времени утрачиваются самостоятельные навыки поиска и обобщения
* Поскольку пользователи уже разучились анализировать информацию, возникает соблазн подсовывать им рекламу и (что хуже) пропаганду
* Разучившиеся пользователи уже не в состоянии заметить деградации обобщателя
* Рекламы и пропаганды становится ещё больше
* Сам обобщатель со временем деградирует, ибо уже нету тех, кто может приемлемо оценить его качество работы (навыки то уже потеряны)splav_asv
16.04.2024 10:28Ну вот навыки работы с бумажными первоисточниками уже у почти всех потеряны. И это дает возможность писать учебники истории как хочется и проворачивать другие интересные финты.
Увы, такова цена удобства. Не вижу тут радикального ухудшения. При появлении любого инструмента навыки работы без него ухудшаются, но с ним всё равно удобнее. А во вред можно любой инструмент использовать.
shares-caisson
16.04.2024 10:28Это вы просто излишне оптимистичны относительно способности типичного пользователя искать и анализировать информацию уже сейчас.

zartarn
16.04.2024 10:28+1К сожалению, нормальный поиск уже планомерно умирает несколько лет. То индексы отрезали, потом появилась релевантность. Не дай бог в твоем запросе что то перекликается с злободневной темой, ты в ближайшую неделю будешь находить только выдачу по топу новостей, а не то что надо.
Так же на форумах все меньше жизни, многие вопросы теперь "спросите у нас в тг", та же sony в какой то момент всю техподдержку вывела в FaceBook, т.е. опять, спрашивать лишний раз уже нечего так как оно не попадет в поисковый индекс.
Начало конца началось уже)) и приплести сюда нейросети, это попытка отодвинуть проблему. И непонятно что с этим делать, разве что появится какое то публичное апи для индекса в тг/дискорд/и т.п...
vikarti
16.04.2024 10:28разве что появится какое то публичное апи для индекса в тг/дискорд/и т.п...
Внезапно уже. На уровне "можно прикрутить попробовать и даже как то работать будет"
https://matrixrooms.info/ - поиск по публичным каналам matrix (причем движок там - открытый), по сути - веб интерфейс в том числе.
https://view.matrix.org/ - тупо веб-интерфейс к публичным комнатам (и насколько помню оно тоже открытео)
-
бриджи в matrix для telegram, discord,etc
Как минимум решается проблема с публичными (=в которые можно войти без проблем всем) каналами, да - надо входить и может бан прилететь и формально это нарушает ToS(особенно если не под бот-аккаунтом а под юзером лезть)
Для Usenet вот тоже вебинтерфейса не было.



Zara6502
27 лет, бла-бла-бла, но почему-то яндекс от сервиса к сервису страдает детскими болячками, а при обращении в ТП посылает на три буквы...
Вот и сейчас - одни программируют чтобы где-то было круто, а другие не могут это предложить к использованию.
У меня в браузере нет никакого Нейро, хотя это Яндекс.Браузер.
Захожу в Поиск, пишу "Нейро", получаю ответ
Нажимаю на ссылку, открывается какая-то страница с видео на пару десятков гигабайт (шутка конечно, но видео там есть) и кнопка
Жму. Иииииии, мне предлагают скачать Яндекс.Браузер
Нет, ну я конечно не совсем идиот и вижу картинку слева
Но это экран телефона, а я сижу за компьютером и как бы ваш браузер в курсе этого.
На телефоне проверил, там всё появилось. А как быть с компьютером? Версия браузера последняя.
BarakAdama
Попробуйте, пожалуйста, зайти в Яндекс Браузере на страницу ya.ru. Появился ли переключатель Нейро?
Goron_Dekar
То есть, пока "без регистрации и СМС" не работает?
buratino
предлагает установить какой-то вирус и купить какую-то Хрюшу-повторюшу
buratino
а на мобильнике в браузере от яндыкса - кнопки нет, - Алиса не в курсе, предлагает нейрохирургию. На запрос нейро от яндекса показывает поиск, по кнопке попробовать предлагает поставить яндекс с алисой или яндекс браузер. Ну логично, чо - из яндекса с Алисой ставить яндекс браузер или яндекс с алисой
TimurRyabinin
Здравствуйте! Я из Яндекса. Рекомендую перезапустить приложение для появления нового функционала или обновить его. В мобильном приложении в настройках должен быть выбран Регион/Страна — Россия.
Отмечу, чтобы получить доступ к Нейро, нужно пользоваться официальными приложениями «Яндекс — с Алисой» и «Яндекс Браузер», быть авторизованным в Яндексе под своим логином, отключить Семейный режим в Поиске или доступ в Поиск из-под Детского аккаунта.
Если ни один из этих способов не помог, рекомендую попробовать другое устройство или переустановить мобильное приложение.
VasiliyLiGHT
Жесть, а для всех остальных браузеров когда-нибудь будет?
FullNoobs_orig
Скорее всего там детекция будет по юзер агенту. А если нет, то как с переводом на русский текст пользователей вырежут расширение из браузера для других переделают. Ибо навязывание своих сервисов. Бесит. Как же яндекс не может создать каждое приложение для всего? У них куча разных приложений, но все эти приложения выполняют кучу одинаковых функций. Сделали бы нормально 1 приложение для всего, если человеку вот так удобно пользоваться и кучу разных приложений.
VasiliyLiGHT
По сути это и есть приложение Яндекс, но, при этом, они упорно предлагают мне установить отдельное приложение для доставки или диска. Вопрос: зачем? Либо убирайте всё и оставляйте в нём только поиск, либо закрывайте все приложения и разрабатывайте один комбайн.
У меня то любовь к комбайнам ещё из времен j2me, когда на многих аппаратах можно было только одно приложение держать и приходилось собирать себе мегаапплет из муз плеера, аськи и опера мини. Для этого даже делали сайты-конструкторы, чтобы простой обыватель мог сделать себе такую штуку. Поэтому я привыкший к супераппам. Но вот клиент-банк тинькова уже начинает раздражать, каждый раз что-то новенькое вылезает, для чего у них есть отдельные приложения. С которыми теперь непонятно, что делать. Сносить или пока оставить... А кому то норм...
Zara6502
На ya.ru переключатель есть. Так это кнопка страницы поиска, а не фишка браузера? А где эта информация по пути моего следования? Почему при нажатии на Попробовать не показать короткую анимашку с тем как вводится ya.ru, потом мышка кликает на переключатель а курсор вводит текст запроса. Это же информативнее чем гигабайтное видео с нулевой нагрузкой.
teamfighter
Ну надо же как-то Яндекс браузер продвигать.
Zara6502
мне не требуется его продвижение я им пользуюсь на регулярной основе.
Radiohead72
На смартфоне кнопка появилась, на макбуке тоже, а вот на планшете - нет. Все обновлено до последних версий.
Zara6502
Пришел домой, при открытии браузера сразу открылась рекламная страница Нейро. На стартовом экране сразу виден переключатель Нейро. Всё работает.
LiveManRU
Зашел ради этого коммента
MainEditor0
А я уж думал Яндекс.Браузер придётся скачивать, чтобы попробовать новый и весьма интересный продукт от Яндекса, ну раз уж даже там не работает, то так уж и быть - подожду, когда выйдет для других браузеров (если вообще выйдет)...