Всем привет! Немного о себе. Меня зовут Максим, я работаю специалистом по Machine Learning в компании SimbirSoft. Последние два года я углубленно изучал область машинного обучения и компьютерного зрения и сегодня с удовольствием поделюсь с вами опытом разработки личного пет-проекта.

В этой статье я расскажу о своем пути от идеи до реализации своего первого классификатора эмоций. Мы обсудим с вами методы, инструменты и техники, которые я применял в процессе создания своего проекта. Анализ данных, выбор модели, обучение и оценка результатов – каждый этап разработки имеет свои особенности и трудности, о чем я с удовольствием поделюсь с вами.
Почему меня привлекла именно эта тема? Во-первых, я уже решал аналогичную задачу на коммерческом проекте, которая включала распознавание и идентификацию лиц. Кроме того, меня заинтересовала эта задача тем, что она состоит из двух этапов: сначала детекция лица на изображении, а затем классификация эмоций, которые испытывает человек.
Статья будет полезна начинающим разработчикам в области Computer Vision, а также всем, кому интересна тема машинного обучения. Вы узнаете, с какой стороны подходить к решению задач с распознаванием лиц и что можно для этого использовать (подходы, инструменты и технологии).
Спойлер
Ради интереса я решил использовать комбинацию классического и глубокого компьютерного зрения для решения данной задачи. Далее вы поймете, о чем я :)
Приступим!
Содержание
Введение
Для начала давайте сформулируем задачу с точки зрения бизнеса, а также компьютерного зрения. В этой части мы рассмотрим популярную методологию, следуя которой, можно добиться успехов в решении задач машинного обучения.
После проведем разведочный анализ данных (EDA), на котором сможем узнать о наших данных что-то новое.
Следующим этапом будет подготовка данных. Здесь мы приведем наши данные в пригодный для моделей вид, а также рассмотрим методы борьбы с дисбалансом классов.
На этапе моделирования мы попробуем обучить различные модели, применяя такие фреймворки как PyTorch и ultralytics, а также подберем лучшую для нашей задачи архитектуру нейронной сети.
Далее мы разработаем и внедрим нашу обученную модель в приложение и протестируем его.
Для особо искушенных я решил добавить дополнительно раздел о том, как можно проанализировать обученную модель при помощи эмбеддингов, а также попробовать решить эту задачу при помощи Keypoint Detection и классического ML.
Идея проекта
В своем личном пет-проекте я решил использовать методологию CRISP-DM по исследованию данных, подробнее о которой расскажу ниже.
Для полного погружения я смоделировал бизнес-задачу, добавив в нее свое авторское видение: необходимо реализовать классификатор эмоций и проанализировать его по методологии.

Предположим, что заказчик обратился со следующей проблемой:
«У частной школы программирования начался отток клиентов и увеличилось количество негативных отзывов, связанных с потерей интереса детей к занятиям.
В ответ на эти проблемы руководство частной школы решило внедрить систему распознавания эмоций учеников в рабочие ноутбуки. Цель состоит в том, чтобы получить статистический отчет об эффективности внедрения интерактивности на уроках и эмоциональном состоянии учеников для понимания качества работы преподавателя».
Методология CRISP-DM

Работая над проектом, я познакомился с методологией CRISP-DM, позволяющей структурировать работу с данными эффективно. Она включает в себя следующие этапы:
Понимание бизнеса (Business Understanding)
Здесь необходимо разработать организационную структуру, определить ответственных лиц, выделить бюджет и определить цели проекта. Важной частью этого этапа является понимание бизнес-целей проекта и метрик его оценки. Необходимо четко определить, что требуется от решения проекта бизнесом (оптимизация процесса, снижение затрат, повысить прибыль) и какие метрики будут использоваться для оценки успеха.
В своем пет-проекте я был за бизнес-овнера, аналитика и за команду разработки. Главные цели этого проекта — снижение оттока клиентов и негативных отзывов, а также контроль работы учителей в зависимости от эмоций учеников. В качестве метрики будем использовать Accuracy (перед этим при необходимости устранив дисбаланс классов в датасете).
Анализ данных (Data Understanding)
На этом этапе мы собираем данные (или думаем, как это лучше сделать) и проводим их анализ. Это включает в себя сбор статистики, оценку качества данных и формулирование первых гипотез для решения задачи.
Подготовка данных (Data Preparation)
После анализа данных мы приступаем к их подготовке. Необходимо отобрать данные, необходимые для решения задачи, и очистить их от ненужных элементов. При необходимости данные также могут быть сгенерированы.
Например, в моем случае нужно было решить проблему дисбаланса классов. Ниже я расскажу о различных подходах к решению данной задачи.
Моделирование (Modeling)
Этот этап моделирования является одним из самых увлекательных. Здесь мы выбираем алгоритмы и модели, которые будем обучать на данных. А после обучения уже выбираем ту модель, которая дала нам наивысшие показатели.
Оценка (Evaluation)
После моделирования мы проводим оценку результатов. Ее необходимо провести не только с точки зрения точности предсказаний, но и с учетом бизнес-аспектов. Например, важно определить, работает ли модель достаточно быстро для успешного внедрения на производство.
Кроме того, важно провести анализ хода проекта, выявить сильные и слабые стороны каждого этапа, что позволит определить, где проект продвигается успешно, а где возможно требуется улучшение. Такой анализ поможет оптимизировать процесс работы с данными и повысить эффективность будущих проектов.
Внедрение (Deployment)
Здесь происходит планирование и непосредственное внедрение полученного решения в учебный процесс школы. Также необходимо настроить мониторинг модели, чтобы следить за ее работой. Это означает, что мы должны установить механизмы для контроля за тем, как модель функционирует в реальном времени и реагировать на любые аномалии или неполадки.
Далее в конце проекта мы составляем отчет о проделанной работе, описывая все этапы и шаги, которые были выполнены. Отчет – это важный инструмент для обратной связи и анализа результатов проекта, он также предоставляет информацию для будущих работ и улучшений в области работы с данными.
CRISP-DM, или кросс-индустриальный стандартный процесс добычи знаний, действительно является ключевым понятием в области технологий больших данных (Big Data) и активно применяется аналитиками и исследователями данных (Data Scientists) в различных отраслях. Этот подход итеративный, что означает возможность возврата к предыдущим этапам в случае неудовлетворительных результатов.
По мере продвижения по этапам проекта данных, если какой-то из них выявляет недостаточность или неудовлетворительные результаты, специалисты могут вернуться на предыдущие этапы, уточнить анализ, улучшить подготовку данных или пересмотреть выбранные модели. Такой цикл повторяется до тех пор, пока не будет достигнуто удовлетворительное решение, соответствующее потребностям и целям бизнеса.
Данный итеративный подход позволяет более точно и эффективно выстраивать процесс работы с данными, минимизируя риски и улучшая качество результатов.
Понимание бизнеса
На этом шаге нам нужно определиться с целями и скоупом проекта.
Данный проект выполняется (в качестве абстрактного примера) для частной школы программирования. Нашими пользователями будут ученики, чьи эмоции мы планируем классифицировать.
Важно понять, какую цель преследует бизнес. Описание задачи указывает на желание владельца школы снизить отток учеников и повысить рейтинг своего учебного заведения.
При помощи нашего решения владелец школы сможет получать информацию о том, как много положительных и негативных эмоций испытывают ученики на занятиях определенных преподавателей, что позволит своевременно корректировать работу учителя, чтобы направить его в нужное русло.
Вопрос о данных: в данном случае заказчик не располагает размеченным набором данных, поэтому нам придется решить эту проблему самостоятельно (как мы это сделаем, будет описано ниже).
Также стоит заранее оценить, какие могут быть риски, а именно:
Недостаточное количество данных или их низкое качество, что может сказаться на эффективности модели. В данном случае мы можем решить эту проблему путем поиска данных в открытых источниках.
Данные качественные, но закономерности в принципе отсутствуют и, как следствие, полученные результаты не интересны заказчику. В нашем случае этой проблемы не возникло, о чем вы узнаете далее :)
Невыполнение сроков. Для решения этой проблемы необходимо грамотно распределить время работы над каждым этапом (разбить на спринты), что позволит равномерно распределить нагрузку и достичь нужного результата вовремя.
Последний пункт указывает на необходимость разработки плана проекта, включая определение задач на каждом этапе (см. содержание). Также он говорит нам о том, что нужно составить план проекта, а именно – понять, что и как мы будем делать на каждом этапе.
А что же мы решаем с точки зрения аналитики?
В качестве основной метрики оценки, которую мы будем представлять заказчику, будем использовать метрику точности (Accuracy). Наш минимальный порог точности составит 0.65, а оптимальный — 0.9.
Таким образом, мы определили цели бизнеса, данные, которые будем использовать, а также установили метрики оценки работы.
Давайте приступим к работе!
Анализ данных (EDA)
Название раздела говорит само за себя — здесь я опишу процесс анализа данных, основные аспекты, на которые был сделан акцент, а также представлю небольшие фрагменты кода для наглядности.
Ниже будет приведен набор библиотек, которые я использовал в работе:
import numpy as np
import pandas as pd
import os
from matplotlib import pyplot as plt
from PIL import Image
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
from torchvision import datasets, models, transforms
import time
import copy
from sklearn.ensemble import RandomForestClassifier
from sklearn import svm
from sklearn.model_selection import train_test_split
import xgboost as xgb
from sklearn.metrics import accuracy_score, classification_reportДля решения этой задачи мне было необходимо найти готовый датасет, и поиски привели меня к платформе Kaggle, на которой в открытом доступе можно найти огромное количество датасетов и примеров кода для различных задач.
Для работы я использовал 4 вида эмоций: happy, sad, neutral, surprised:
fig = plt.figure(figsize=(10, 7))
rows = 2
columns = 2
img_happy = np.asarray(Image.open(os.path.join(train_path, 'happy/im0.png')))
img_neutral = np.asarray(Image.open(os.path.join(train_path, 'neutral/im10.png')))
img_sad = np.asarray(Image.open(os.path.join(train_path, 'sad/im10.png')))
img_surprised = np.asarray(Image.open(os.path.join(train_path, 'surprised/im10.png')))
fig.add_subplot(rows, columns, 1)
plt.imshow(img_happy, cmap="gray")
plt.axis('off')
plt.title("Happy")
fig.add_subplot(rows, columns, 2)
plt.imshow(img_neutral, cmap="gray")
plt.axis('off')
plt.title("Neutral")
fig.add_subplot(rows, columns, 3)
plt.imshow(img_sad, cmap="gray")
plt.axis('off')
plt.title("Sad")
fig.add_subplot(rows, columns, 4)
plt.imshow(img_surprised, cmap="gray")
plt.axis('off')
plt.title("Surprised") 
Размеры картинок следующие:
print('Happy -', f'{img_happy.shape}')
print('Sad -', f'{img_sad.shape}')
print('Neutral -', f'{img_neutral.shape}')
print('Surprised -', f'{img_surprised.shape}')
### Happy - (48, 48)
### Sad - (48, 48)
### Neutral - (48, 48)
### Surprised - (48, 48)Можно заметить, что наши изображения черно-белые (имеют 2 измерения).
Далее посмотрим на распределение классов эмоций в обучающей и тестовой выборке:
happy_train = len(os.listdir(os.path.join(train_path, 'happy')))
sad_train = len(os.listdir(os.path.join(train_path, 'sad')))
neutral_train = len(os.listdir(os.path.join(train_path, 'neutral')))
surprised_train = len(os.listdir(os.path.join(train_path, 'sad')))
happy_test = len(os.listdir(os.path.join(test_path, 'happy')))
sad_test = len(os.listdir(os.path.join(test_path, 'sad')))
neutral_test = len(os.listdir(os.path.join(test_path, 'neutral')))
surprised_test = len(os.listdir(os.path.join(test_path, 'sad')))
d_train = {'happy' : happy_train, 'sad' : sad_train, 'neutral' : neutral_train, 'surprised' : surprised_train}
d_test = {'happy' : happy_test, 'sad' : sad_test, 'neutral' : neutral_test, 'surprised' : surprised_test}
plt.bar(d_train.keys(), d_train.values(), label='Train')
plt.bar(d_test.keys(), d_test.values(), label= 'Test')
plt.legend();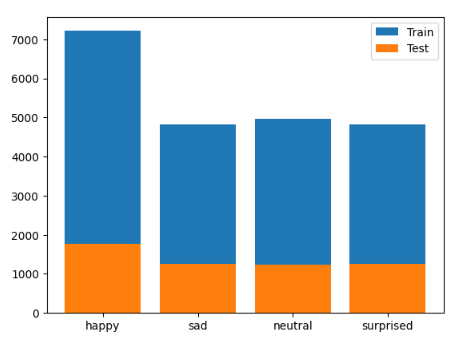
На графике виден явный дисбаланс классов. В обучающей и тестовой выборках класса happy намного больше, чем других, – это стоит иметь ввиду во время подготовки данных для обучения.
Давайте построим усредненные лица по каждому из классов – для этого мы соединим все изображения из каждого класса в тензоры:
images_happy_train = [np.asarray(Image.open(os.path.join(train_path, "happy", img))) for img in os.listdir(os.path.join(train_path, "happy"))]
images_neutral_train = [np.asarray(Image.open(os.path.join(train_path, "neutral", img))) for img in os.listdir(os.path.join(train_path, "neutral"))]
images_sad_train = [np.asarray(Image.open(os.path.join(train_path, "sad", img))) for img in os.listdir(os.path.join(train_path, "sad"))]
images_surprised_train = [np.asarray(Image.open(os.path.join(train_path, "surprised", img))) for img in os.listdir(os.path.join(train_path, "surprised"))]Усредним их:
avg_happy = np.mean(images_happy_train, axis=0)
avg_neutral = np.mean(images_neutral_train, axis=0)
avg_sad = np.mean(images_sad_train, axis=0)
avg_surprised = np.mean(images_surprised_train, axis=0)На выходе получим наши изображения:
fig = plt.figure(figsize=(10, 7))
rows = 2
columns = 2
fig.add_subplot(rows, columns, 1)
plt.imshow(avg_happy, cmap="gray")
plt.axis('off')
plt.title("AVG Happy")
fig.add_subplot(rows, columns, 2)
plt.imshow(avg_neutral, cmap="gray")
plt.axis('off')
plt.title("AVG Neutral")
fig.add_subplot(rows, columns, 3)
plt.imshow(avg_sad, cmap="gray")
plt.axis('off')
plt.title("AVG Sad")
fig.add_subplot(rows, columns, 4)
plt.imshow(avg_surprised, cmap="gray")
plt.axis('off')
plt.title("AVG Surprised");
Проделав те же действия для тестовой и всей выборки, мы получим картинки:

Их стоило проверить для того, чтобы убедиться, что тестовая выборка у нас репрезентативна, а именно – в среднем схожа с обучающей и всей выборкой.
Какие можно сделать выводы на данном этапе?
Изображения с радостным и удивленным выражениями лица заметно отличаются, скорее всего модель будет различать их хорошо.
Изображения с грустным и нейтральным выражением лица заметно похожи, есть вероятность того, что модель будет их путать. Попробуем минимизировать риск этой проблемы увеличением датасета (используя аугментацию, о ней подробно поговорим далее).
Подготовка данных
В ходе анализа стало очевидно, что наш датасет изображений лиц является несбалансированным. В данном случае класс "happy" преобладает, в то время как остальные классы представлены в равном количестве (взглянем еще раз на график).

Существуют такие подходы к устранению дисбаланса, как Oversampling и Undersampling.
Oversampling – это процесс увеличения количества примеров в менее представленных классах, в то время как
Undersampling – это процесс уменьшения количества примеров в более представленных классах.
Оба метода имеют свои преимущества и недостатки, выбор между ними зависит от конкретной задачи и характеристик данных:

При использовании метода Undersampling в нашем случае связанном с задачей классификации изображений, процесс будет довольно простым. Нам нужно просто уменьшить преобладающую выборку, сократив её размер до уровня других классов.
Для этого я собрал DataFrame с изображениями и просто обрезал их до одинакового размера:

Как мы можем заметить, метод Undersampling отличается своей простотой как с точки зрения объяснений, так и с точки зрения реализации. Однако важно учитывать структуру данных – у нас они представлены в виде изображений в папках.
Если бы наши данные, например, были в виде табличных данных, то при использовании метода Undersampling нужно было бы следить за стратификацией данных, чтобы уменьшенная выборка была репрезентативной и в среднем отражала бы весь датасет.
Давайте теперь подготовим датасет, используя подход Oversampling. Этот этап будет немного сложнее, чем предыдущий, поскольку придется как-то генерировать данные.
Учитывая, что мы работаем с изображениями, очевидным решением является аугментация данных.
Что такое аугументация данных? Простыми словами, это искусственное создание новых данных (изображений). Мы можем взять несколько шаблонов или «идеальных» примеров (например, эмоции) и с помощью различных искажений создать необходимое количество примеров для обучения. Из-за того, что мы работаем с изображениями, такой подход может хорошо сработать.
Мы можем использовать следующие виды искажений:
Геометрические искажения: аффинные, проективные и другие.
Яркостные/цветовые изменения.
Замена фона.
Искажения, характерные для решаемой задачи: блики, шумы, размытие и т. д.
Использование этих методов позволит нам эффективно увеличить количество данных в датасете и сделать обучение более эффективным.
Примеры:

Для аугментации данных очень удобно использовать библиотеку OpenCV, которая обеспечивает простую обработку изображений (и не только). Больше информации можно найти на официальном сайте.
Я использовал только два вида преобразований: зеркальное отражение по горизонтали и поворот изображения. Применил методы cv2.flip() и cv2.warpAffine() – они позволяют легко осуществлять простые трансформации изображений, что значительно упрощает процесс аугментации данных:
import cv2
import os
import numpy as np
d = {'neutral' : 2235, 'sad' :2370, 'surprised' : 4029}
for emo in os.listdir('.\\all')[1:]:
for img in os.listdir(f".//all//{emo}"):
path = os.path.join(".//all//", emo, img)
img = cv2.imread(path)
flipHorizontal = cv2.flip(img, 1)
(h, w) = flipHorizontal.shape[:2]
(cX, cY) = (w // 2, h // 2)
# rotate our image by 45 degrees around the center of the image
M = cv2.getRotationMatrix2D((cX, cY), 25, 1.0)
rotated = cv2.warpAffine(flipHorizontal, M, (w, h))
cv2.imwrite(path[:-4] + "_new.png", rotated)
d[emo] -= 1
if d[emo] == 0:
breakДля отражения изображений влево-вправо достаточно передать их в качестве аргументов функции. Однако для поворота изображений необходимо создать матрицу поворота, которую затем можно использовать с функцией warpAffine().
В словаре d рассчитывается количество необходимых изображений для каждого класса, чтобы сравнять их с классом "happy". На выходе мы получаем сбалансированный датасет по каждому классу.
Конечно, эти методы не являются единственными для расширения набора данных. Тем не менее я продемонстрировал, как можно с помощью простых методов увеличить набор данных. Это может оказаться полезным для обучения, так как увеличение данных может положительно сказаться на качестве обучения, по сравнению с использованием только Undersampling.
Моделирование
Переходим к одному из самых интересных и всеми «любимому» этапу. Обучим модель на наших изображениях для задачи классификации!
Выше мы решили проблему дисбаланса классов при помощи аугментации данных, поэтому мы будем использовать эти данные для обучения.
На данном этапе мы обучим модели и подберем лучшую, которую затем будем использовать для разработки приложения. Ниже приведен код, который мы будем применять для различных архитектур.
Для начала обучение и выбор моделей будет проведен с использованием библиотеки PyTorch.
Список используемых библиотек:
import os
import pandas as pd
import torch
import torchvision
from PIL import Image
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import cv2
from torch.autograd import Variable
from sklearn.model_selection import train_test_split
from tempfile import TemporaryDirectory
from collections import Counter
from skimage import ioДалее мы создадим класс Dataset, в котором будем преобразовывать данные в читаемый моделью вид, а далее использовать для обучения:
class MyDataset(torch.utils.data.Dataset):
def __init__(self, dataframe, transform=None):
self.dataframe = dataframe
self.transform = transform
def __len__(self):
return len(self.dataframe)
def __getitem__(self, index):
#row = self.dataframe.iloc[index]
image=io.imread(self.dataframe.iloc[index]['image'])
if len(image.shape) == 2:
image = cv2.cvtColor(image,cv2.COLOR_GRAY2RGB)
if self.transform:
image = self.transform(image)
y_label=torch.tensor(float(self.dataframe.iloc[index]['label']))
return (image,y_label)Эта удобная вещь позволяет очень гибко настраивать наши данные при обучении, за это я и люблю PyTorch :)
Можно увидеть, что в нашем классе присутствует возможность применить трансформацию, которую PyTorch предоставляет из коробки:
data_transforms = {
'train': transforms.Compose([
transforms.ToTensor(),
#transforms.Grayscale(num_output_channels=1),
transforms.Resize(256),
transforms.RandomHorizontalFlip(),
transforms.Normalize([0.51145715], [0.250773])
]),
'val': transforms.Compose([
transforms.ToTensor(),
transforms.Resize(256), ]),}Делаем трансформацию для обучающей и валидационной выборки.
Если простыми словами, то мы преобразовываем изображение в тензор, после меняем размер, в обучающей выборке используем горизонтальное отображение и производим нормализацию image = (image - mean) / std (чтобы вычислить значения mean и std, необходимо взять среднее и отклонения по всей обучающей выборке). Последнее необходимо делать для улучшения обучения нашей модели. Для валидационной выборки мы делаем только преобразование в тензор и изменение размера.
После создаем наши датасеты с трансформацией, которую мы описали выше:
def collate_fn(batch):
return {
'pixel_values': torch.stack([x[0] for x in batch]),
'labels': torch.tensor([x[1] for x in batch])
}train_data = MyDataset(pd.concat([X_train, y_train], axis=1), data_transforms['train'])
test_data = MyDataset(pd.concat([X_test, y_test], axis=1), data_transforms['val'])Далее создадим dataloader-ы, которые будут использовать для последовательной подачи данных в модель, а именно – пакетами (batch):
image_datasets = {'train' : train_data, 'val' : test_data}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=8,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}В DataLoader есть множество опций, но кроме batch_size и shuffle также следует иметь в виду num_worker. Он помогает повысить эффективность. num_workers > 0 использует субпроцессы для асинхронной загрузки данных, а не блокирует под это главный процесс.
Ниже приведен код обучения, который будет использован для различных моделей:
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
# Create a temporary directory to save training checkpoints
with TemporaryDirectory() as tempdir:
best_model_params_path = os.path.join(tempdir, 'best_model_params.pt')
torch.save(model.state_dict(), best_model_params_path)
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
labels = labels.type(torch.LongTensor)
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
#outputs = torch.nn.functional.softmax(outputs, dim=1)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), best_model_params_path)
print()
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
# load best model weights
model.load_state_dict(torch.load(best_model_params_path))
return modelДалее инициализируем функцию ошибки, оптимизатор и scheduler:
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.Adam(model_ft.parameters(), lr=0.001)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)Фух! Теперь можем выбирать модель :)
Мой взгляд упал на нейросеть ResNet. Она интересна тем, что в ее архитектуре присутствуют так называемые «соединения быстрого доступа», которые смогли улучшить модель с точки зрения ее обучения.
Вот очень интересная статья, в которой подробно описано все описано.
model_ft = models.resnet18(weights=’IMAGENET1K_V1’)
model_ft.fc = nn.Linear(in_feature=512, out_feature=4, bias=True)
model_ft = model_ft.to(‘cuda’)Я решил использовать легковесную модель, потому что в моей задачи также помимо точности необходимо еще и быстро обрабатывать изображения.
Можем заметить, что в выходном слое я выставил количество out_feature=4, поскольку изначально на выходе по дефолту выставлено 1000 классов (так как она обучалась на датасете ImageNet). Обучать модель будем на 20 эпохах.
model_ft = = train_model(model_ft, criterion, optimizer_ft, exp_lr_sheduler, num_epochs=20)Вот что получилось:

Получаем 70% точности! Неплохой результат для начала.
Давайте попробуем архитектуру EfficientNet, она также предоставляется из коробки в Pytorch. Проделываем те же самые махинации:
model_ft=torchvision.models.efficientnet_b0(models.EfficientNet_B0_Weights.IMAGENET1K_V1)
model_ft.classifier[-1] = nn.Linear(in_features=1280, out_features=4, bias=True)
model_ft = model_ft.to(device)
Итоги не сильно отличаются.
Тогда я решил обратиться к одному из современных решений. Догадываетесь, что это?:) YOLOv8!
Почему я решил остановиться на ней? В моем случае она подошла, поскольку имеет очень хороший баланс между скоростью и точностью, благодаря своей архитектуре. Вопрос о том, как она работает, оставим как задание для читателя :)
Ultralytics предоставила нам удобную и простую библиотеку, при помощи которой мы буквально можем обучить нашу модель.
Давайте посмотрим, как это происходит:
from ultralytics import YOLO
model = YOLO(‘yolo8n-cls.pt’)
result = model.train(data=’./path_data/’, epochs=20, imgsz=48)После обучения для нас в автоматическом режиме будут сохранены графики:

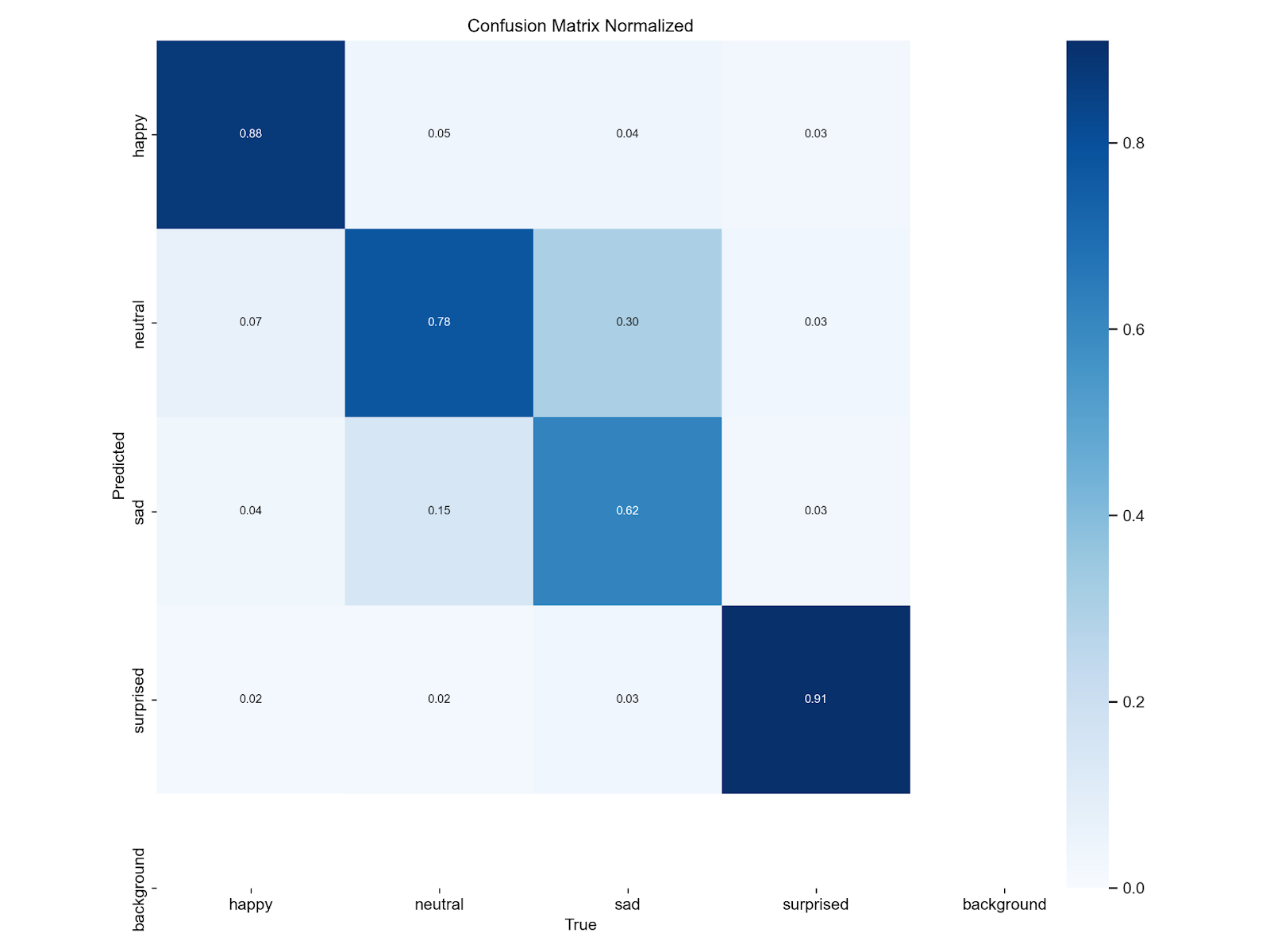
На данной модели мы смогли выбить 0.797 accuracy, но также стоит учесть полученную confusion matrix. Как и мы предполагали, происходит небольшая путаница с классами sad и neutral.
Итак, модель получена. Этап моделирования может производиться очень долго. Сначала нужно выбрать подходящую модель, после настроить входные и выходные параметры, а после сидеть и ждать конца обучения, в надежде что ничего не прервется и не закончатся вычислительные мощности на облаке :)
Внедрение модели в приложение
Завершающим шагом будет создание обертки вокруг нашей модели и ее тестирование.
Для эффективности я решил использовать метод Виолы-Джонса, с помощью которого буду находить лицо на видео, выделять и уже на выделенной части проводить классификацию. Это сработает лучше, потому что весь наш обучающий датасет в основном состоит из выделенных лиц.
Для начала подключим необходимые библиотеки:
import cv2
from ultralytics import YOLO
import numpy as np
import osПосле инициализируем необходимые компоненты для алгоритма Виолы-Джонса и нашу обученную модель:
# путь к файлу с шаблонами Хаара
cascPathface = os.path.dirname(
cv2.__file__) + "/data/haarcascade_frontalface_alt2.xml"
# инициализировали каскадный классификатор
faceCascade = cv2.CascadeClassifier(cascPathface)
model = YOLO('./best.pt')Реализуем логику нашего приложения:
vid = cv2.VideoCapture(0)
while (True):
# Capture the video frame
# by frame
ret, frame = vid.read()
# преобразуем кадр в оттенки серого
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# инициализируем детектор
faces = faceCascade.detectMultiScale(frame,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
flags=cv2.CASCADE_SCALE_IMAGE)
if len(faces) != 0:
(x, y, w, h) = faces[0]
face = gray[y:y+h, x:x+w]
# font
font = cv2.FONT_HERSHEY_SIMPLEX
# org
org = (50, 50)
# fontScale
fontScale = 1
# Blue color in BGR
color = (255, 0, 0)
# Line thickness of 2 px
thickness = 2
results = model(face)
names_dict = results[0].names
probs = results[0].probs.data.tolist()
print(names_dict[np.argmax(probs)])
# Using cv2.putText() method
image = cv2.putText(frame, f'{names_dict[np.argmax(probs)]}', org, font,
fontScale, color, thickness, cv2.LINE_AA)
# Display the resulting frame
cv2.imshow('frame', image)
else:
cv2.imshow('frame', frame)
# the 'q' button is set as the
# quitting button you may use any
# desired button of your choice
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# After the loop release the cap object
vid.release()
# Destroy all the windows
cv2.destroyAllWindows()Давайте по порядку, что здесь происходит?
Подключаем веб-камеру и в цикле начинаем считывать кадр за кадром:
vid = cv2.VideoCapture(0)
while (True):
# Capture the video frame
# by frame
ret, frame = vid.read()Переводим изображение в ч/б и инициализируем детектор:
# преобразуем кадр в оттенки серого
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# инициализируем детектор
faces = faceCascade.detectMultiScale(frame,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
flags=cv2.CASCADE_SCALE_IMAGE)Если лицо было обнаружено, вырезаем его из изображения. Далее пропускаем через модель и получаем на выходе предсказанный класс, выводим его на экране.
Как это работает:
Но, конечно, не все бывает идеально. Минус такой реализации алгоритма Виолы-Джонса в том, что он перестает видеть лицо, если чуть-чуть повернуть голову вбок:
Для решения этой проблемы можно обучить детектор, который будет находить лица на изображении, либо использовать готовые модели. Оставим это как задание читателю :)
Каков итог? Даже с такой простой реализацией мы можем использовать нашу модель на практике.
Анализ эмбеддингов
Интересной частью моей работы над проектом был просмотр эмбеддингов изображений.
Если смотреть на классическое определение эмбеддингов, то сразу приходит в голову NLP и вектора, полученные из слов или других языков сущностей.
Но не тут-то было! Я буду использовать термин эмбеддинг, под которым буду понимать следующее: у нас есть свёрточная нейронная сеть, мы обучили её для классификации, отрезали последний классифицирующий слой, взяли некие изображения, прогнали через сеть и на выходе получили числовой вектор. Его я и буду называть эмбеддингом.
Рассмотрим подробнее (в качестве примера я взял и обучил сверточную сеть VGG16):

Можем заметить, что у выходного слоя мы обрезали классифицирующий слой, то есть на выходе мы будем получать из full connected слоя вектор из 4096 чисел – это и будет наш эмбеддинг.
После обучения я пропускаю через модель наши изображения и собираю DataFrame эмбеддингов:
df_feature = pd.DataFrame(columns=[i for i in range(4097)])
for images, labels in dataloaders["train"]:
#images = images.to(device)
outputs = model(images)
for label, img in zip(labels, outputs):
df_feature.loc[len(df_feature.index)] = np.append(img.cpu().detach().numpy(), label)Далее нам необходимо понизить размерность наших данных и построить графики рассеяния, чтобы увидеть, насколько хорошо наша модель различает различные эмоции (образуются ли четко выраженные кластеры).
Для этого я использовал 2 алгоритма: PCA и t-SNE
X = df_feature.drop(4096, axis=1)
Y = df_feature[4096] # 4 эмоцииДля PCA:
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
df_pca = pd.DataFrame(X_pca)
df_pca['y'] = Y
plt.scatter(df_pca[df_pca['y'] == 0][0], df_pca[df_pca['y'] == 0][1], label='Happy')
plt.scatter(df_pca[df_pca['y'] == 1][0], df_pca[df_pca['y'] == 1][1], label='Neutral')
plt.scatter(df_pca[df_pca['y'] == 2][0], df_pca[df_pca['y'] == 2][1], label ='Sad')
plt.scatter(df_pca[df_pca['y'] == 3][0], df_pca[df_pca['y'] == 3][1], label='Surprised')
plt.legend()
plt.show()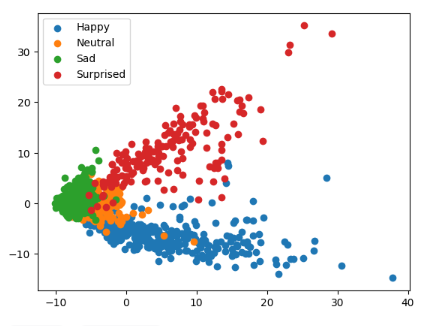
Для t-SNE:
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
df_tsne = pd.DataFrame(X_tsne)
df_tsne['y'] = Y
plt.scatter(df_tsne[df_tsne['y'] == 0][0], df_tsne[df_tsne['y'] == 0][1], label='Happy')
plt.scatter(df_tsne[df_tsne['y'] == 1][0], df_tsne[df_tsne['y'] == 1][1], label='Neutral')
plt.scatter(df_tsne[df_tsne['y'] == 2][0], df_tsne[df_tsne['y'] == 2][1], label ='Sad')
plt.scatter(df_tsne[df_tsne['y'] == 3][0], df_tsne[df_tsne['y'] == 3][1], label='Surprised')
plt.legend()
plt.show()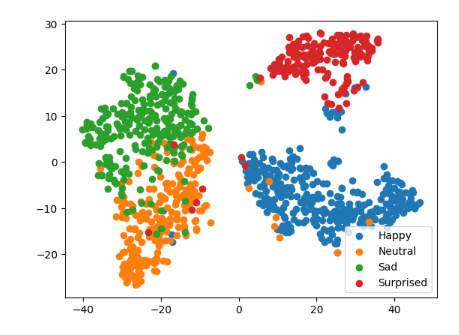
Из графики можем заметить, что образуются 4 кластера. Значит модель улавливает закономерности для каждого класса.
Также мы видим, что классы sad и neutral перемешивается, а значит подтверждается наша гипотеза, которую мы выдвинули на этапе построения усредненных лиц — о том, что возможна путаница между этими классами.
Анализ ключевых точек
Еще один подход для решения данной задачи – это использование ключевых точек на лице.
Для начала я использовал готовый инструмент.
Был собран датасет по изображением лиц:
df_happy = pd.read_csv('/kaggle/input/key-points/df_happy.csv').drop('Unnamed: 0', axis = 1)
df_sad = pd.read_csv('/kaggle/input/key-points/df_sad.csv').drop('Unnamed: 0', axis = 1)
df_neutral = pd.read_csv('/kaggle/input/key-points/df_neutral.csv').drop('Unnamed: 0', axis = 1)
df_surprised = pd.read_csv('/kaggle/input/key-points/df_surprised.csv').drop('Unnamed: 0', axis = 1)
df_happy['class'] = 'happy'
df_sad['class'] = 'sad'
df_neutral['class'] = 'neutral'
df_surprised['class'] = 'surprised'
df = pd.concat([df_happy, df_sad, df_neutral, df_surprised])
Далее я решил взглянуть на усредненные ключевые точки, а после попробовать обучить классификаторы на них, и посмотреть важность признаков, чтобы определить наиболее важные точки:
def rotate_coordinates(coordinates):
rotated_coordinates = []
for x, y in coordinates:
rotated_coordinates.append((-x, -y))
return rotated_coordinates
def get_mean_points(df):
columns = df.columns[:-1]
columns
columns = df.columns[:-1]
d = {}
for i in range(1, 99):
d[f"{i}_x"] = []
d[f"{i}_y"] = []
for index, row in df.iloc[:, :-1].iterrows():
for i in range(1, 99):
d[f"{i}_x"].append(np.array(row[f"{i}_x"]))
d[f"{i}_y"].append(np.array(row[f"{i}_y"]))
for col in columns:
d[col] = np.mean(d[col])
list_emo = list(d.items())
draw_list = []
for i in range(0, 196, 2):
draw_list.append([list_emo[i][1], list_emo[i+1][1]])
draw_list = rotate_coordinates(draw_list)
for x, y in draw_list:
plt.scatter(x, y)
count = 1
for x, y in draw_list:
plt.annotate(f'{count}', (x, y))
count += 1



Видно, что у каждой эмоции есть, возможно, и не сильные, различия.
Попробуем обучить классификаторы:
df['class'].replace({'happy' : 0, 'sad' : 1, 'neutral' : 2, 'surprised' : 3}, inplace=True)
X = df.drop('class', axis = 1)
y = df['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)param_g = {
'n_estimators': [200, 300],
'max_depth' : [4,5,6],
'criterion' :['gini', 'entropy']
}
rf = RandomForestClassifier()
CV_rfc = GridSearchCV(estimator=rf, param_grid=param_g)
CV_rfc.fit(X_train, y_train)param_grid = {'C':[1,10,100,1000],'gamma':[1,0.1,0.001], 'kernel':['linear','rbf']}
clf = GridSearchCV(estimator=svm.SVC(), param_grid=param_grid)
clf.fit(X_train,y_train)parameters = {
'max_depth': [2, 5, 10],
'n_estimators': [100, 200, 300],
}
#Creating an XGBoost classifier
model = xgb.XGBClassifier(device='cuda')
grid_search = GridSearchCV(
estimator=model,
param_grid=parameters,
verbose=True
)
grid_search.fit(X_train, y_train)Видим, что даже по ключевым точкам классификаторы показывают относительно хорошие результаты.
Готовый проект можно посмотреть здесь.
Заключение
В ходе работы над проектом были пройдены ключевые этапы, начиная с анализа данных и заканчивая созданием приложения для модели.
Анализ данных помог понять структуру и особенности набора изображений, а подготовка данных играла важную роль в обеспечении качественного обучения моделей. Благодаря использованию метода Oversampling мы смогли избавиться от дисбаланса классов в наших данных, и увеличить их с 3500 до 6500 изображений на каждый класс!
Обучение моделей — это сердце проекта, где были применены современные методы машинного обучения и глубокого обучения для достижения высокой точности классификации эмоций. Благодаря тестированию различных архитектур нейронных сетей, а также аугментации датасета мы смогли увеличить нашу точность на 10%! А именно – получить итоговую точность 80%.
Особенно важным этапом является написание приложения для модели, которое позволяет пользователям легко взаимодействовать с разработанной системой, делая ее доступной.
В ходе работы над проектом было получено множество уроков и опыта, связанных с проблемами в области компьютерного зрения.
Несмотря на достигнутые результаты, существует ряд направлений для дальнейшего совершенствования проекта, таких как улучшение точности классификации эмоций, оптимизация производительности приложения и расширение функциональности для более широкого применения.
Данный проект обладает значительной важностью для образовательного учреждения по нескольким причинам:
Улучшение качества обучения. Анализ эмоциональной реакции учеников на занятиях поможет оптимизировать методики преподавания и улучшить качество образовательного процесса.
Снижение оттока клиентов. Использование аналитики для выявления факторов, влияющих на уровень удовлетворенности и мотивации обучающихся, позволит предотвратить их возможный отток. Знание того, что именно вызывает недовольство учеников, поможет школе удерживать текущую аудиторию и привлекать новых.
Повышение рейтинга и привлечение новых клиентов. Успешная реализация проекта, направленного на анализ эмоциональной реакции учеников повысит удовлетворенность клиентов. Это, в свою очередь, приводит к увеличению числа заявок на обучение и, как следствие, к финансовой выгоде для школы.
Итак, работа над этим проектом была увлекательным и познавательным опытом, позволившим глубже погрузиться в мир компьютерного зрения и машинного обучения.
Всем спасибо за внимание!
Авторские материалы о разработке и машинном обучении также публикуем в наших соцсетях – ВКонтакте и Telegram.
Комментарии (9)

digtatordigtatorov
25.04.2024 08:54В разработке своего приложения как ни странно проделывал все те же этапы, видимо это как-то на эмпирическом уровне воспринимается)

dl21
25.04.2024 08:54как реклама навыков сделано хорошо.
как реализация инструмента крайне сомнительно - вы сидите с натянутой и перенапряженной фейсмускулатурой , а ваша нейросетка не то что бан за симуляцию не выписывает , а бодро рапортует это вот то)) понимаю что петпроект, однако как специалист испытываю неудовольствие из-за подобного

SSul Автор
25.04.2024 08:54В статье мы рассматриваем запрос заказчика на конкретный инструмент, который собирает статистику по эмоциях. С одной стороны, как клиент будет интерпретировать полученную информацию — это уже его дело :) С другой — если глубже и детальнее погрузиться в тонкости физиогномики, можно допилить систему и сделать результаты более детальными.
Edwward
Как использовать сей инструмент? К примеру, преподаватель N. Его студенты , за 5 занятий выдали: 50 % нейтральных эмоций, 10 % грусти, 20 % -радости, и 20 % "сюрпрайз". Хороший преподаватель N? Какие соотношения эмоций , должны быть у хорошего преподавателя? 90 % - "хэппи"?
datacompboy
тут понадобится собрать немного данных и обучить еще одну сеть
anonym0use
Про то что студентам может быть некомфортно от тотальной ультраслежки, где каждую милисекунду считывают их выражение лица, даже не вспомнили уже
SSul Автор
Напомним, что это пет-проект :) Ситуация с учениками и преподавателями вымышленная, но она дает четкое понимание, как можно проработать и использовать такой механизм использования ИИ до внедрения в приложения.
ogukuu
Так может и нет никаких преподавателей и студентов, и заказчик немного из другого ведомства.
SSul Автор
Интерпретировать работу преподавателя по таким показателям можно по-разному. Например, 90% эмоций «хэппи» можно трактовать так, будто студенты не слушали преподавателя, а просто веселились. А вот соотношение «нейтральных» и «веселых» 50 на 50 может говорить, что преподаватель интересно и с юмором вел занятие :)