
Всем привет! Меня зовут Аня Максимова, я занимаюсь NLP в команде Нейронные сети продукта Собеседник! 5 апреля проходила конференция Giga R&D Day, где мой коллега — Артем Снегирев рассказывал про практические аспекты ранжирования ответов виртуального ассистента Салют.
В этой статье мы подробнее расскажем вам, как делаем ранжирование ответов на примере собеседника, который является частью ассистентов Салют.
У ассистента есть три голоса — Сбер, Афина и Джой. Собеседник отвечает за общение на различные темы, ответы на фактологические вопросы и за развлекательный контент. Как правило, ассистент отвечает генеративными моделями, но есть сценарии, где используются заготовленные реплики, и их достаточно много, поэтому мы используем поиск — это классический retrieval-based подход.

Как устроен наш поиск?
С помощью эмбеддинга контекста мы можем делать поиск по нашей базе, где около миллиона различных реплик, которые обладают характеризующими их метафичами. С использованием faiss index получаем 128 ближайших кандидатов, а после фильтрации остается 32, подаем их в cross-encoder и получаем оценку релевантности. Дальше собираем фичи: оценка SCU-модели, оценка кросс-энкодера, диалоговые фичи и метафичи каждой реплики и отправляем их в LightGBM-ранкер для финального ранжирования.
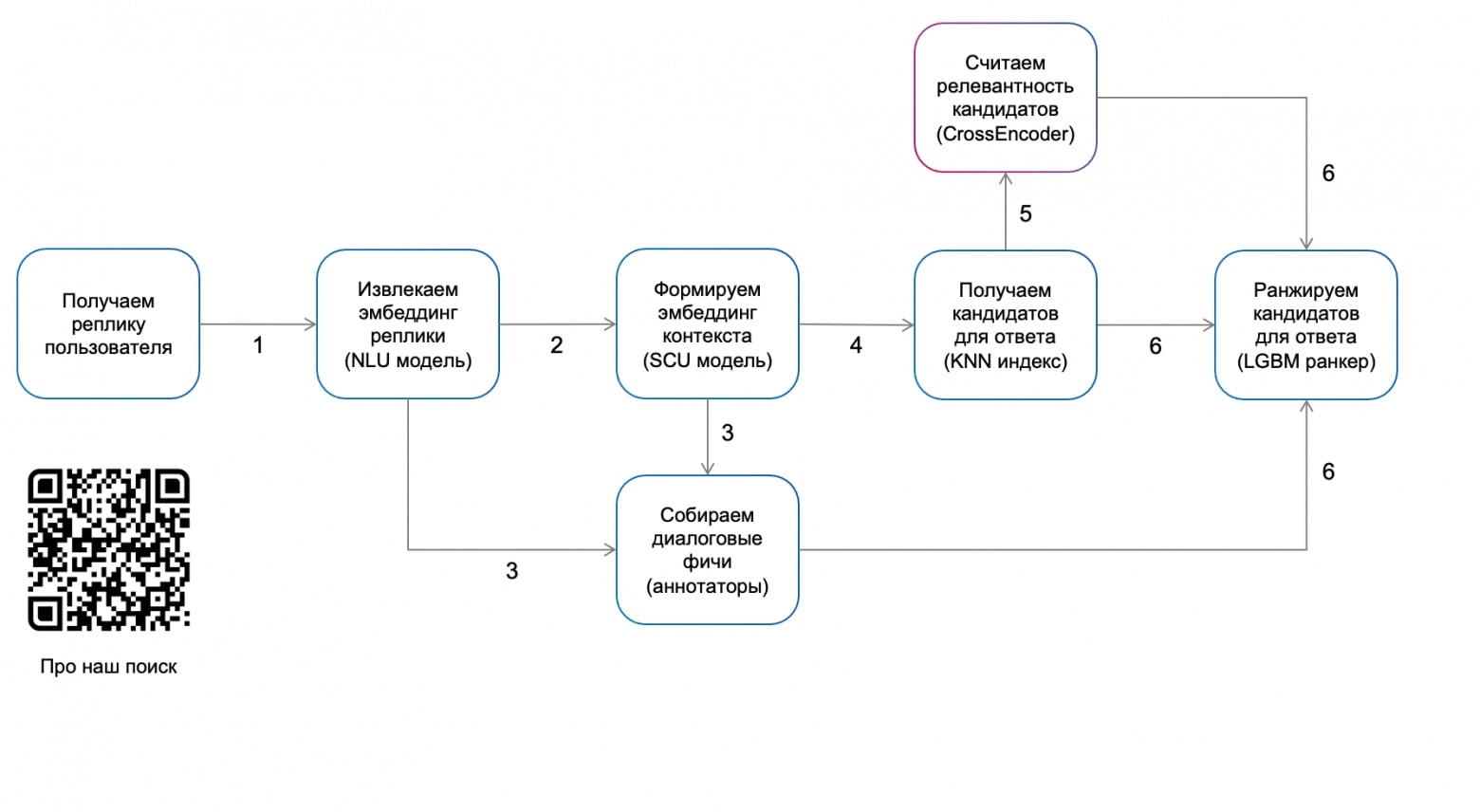
При чем cross-encoder мы не используем для ранжирования, но используем его оценку как фичу для ранжирования, что положительно сказывается на качестве.
По qr-коду с картинки можно подробнее узнать про наш поиск!
Как устроен классический кросс-энкодер?
Классический cross-encoder реализуется похожим образом на задачу next sentence prediction в предобучении BERT. Через специальные токены мы конкатенируем реплики в диалоге и направляем их в нашу модель, где токены через механизм внимания взаимодействуют друг с другом. С последнего слоя берем эмбеддинг первого токена, пропускаем через линейный слой и сигмоиду, чтобы получить оценку релевантности.

Мы проводили эксперименты с кросс-энкодером, благодаря которым улучшилось качество ранжирования. В этой статье расскажем об их результатах.
Чем больше примеров для контекста, тем лучше качество
Классическая реализация обычно использует бинарную классификацию, то есть разделяет реплики на хорошие/плохие, что не очень подходит для задачи ранжирования. В свою очередь, хорошие ответы отличаются по качеству, что вместе требует оценки каждого примера в диапазоне от 0 до 1. Для финального качества ранжирования как правило лучше использовать большое количество негативов, и это приводит к дисбалансу классов. Мы свели задачу к выбору оптимального ответа из N предложенных, один из которых является хорошим. Модель учит относительную оценку релевантности вместо абсолютной и значение функции потерь не зависит от баланса классов. Теперь необязательно делить ответы на 2 разные группы, вместо них получаются группы где 1 лучше других.
Таким образом мы взяли идею из Contrastive Learning и заменили бинарную классификацию на InfoNCE, также известный как MultipleNegativesRankingLoss, SimCSE, и in-batch negatives loss
InfoNCE-loss, s — модель, c — контекст, r — ответ, t — температура
У нас есть положительный пример и отрицательные, и теперь мы не требуем, какого-то абсолютного значения скора для положительного примера, а хотим чтобы он был хотя бы немного лучше скора отрицательных. Насколько лучше — корректируется с помощью температуры t, которая может быть как константной, так и параметром, значение которого подбирается в процессе обучения.
В качестве негативных примеров мы используем hard, random и semi-hard негативы.
Random негативы помогают найти модели самые понятные паттерны, а от semi hard мы обнаружили хороший прирост метрик.
Для получения semi-hard негативов мы используем NLU и SCU-модели, для каждого диалогового сета строим базу реплик, уникальные ответы пропускаем через поиск, где получаем топ кандидатов и семплируем их по рангу или близости. В итоге это увеличивает разнообразие примеров для каждого контекста.

Откуда брать данные?
Раньше мы переводили датасеты с английского на русский, потому что наша модель знает только русский. Но бывают очень большие датасеты, поэтому мы решили учить модель сразу на английском: дополнили токенизатор RuRobrerta-Large токенами английского языка, дополучили на небольшом количестве русских и английских текстов и выровняли языковую пару. Выравнивание делалось следующим образом: мы подавали переводы, получали эмбеддинги и сближали их с помощью MSE-лосса, то есть учили модель выдавать один и тот же эмбеддинг для переводов. Такую же процедуру можете увидеть в пайплайне обучения модели LaBSE.

Для проверки своей расширенной двуязычной модели мы взяли датасет blended still talk (BST), содержащий 100 тыс. примеров из английского синтетического диалогового сета SODA, а также его русский перевод. Можем заметить, что при обучении на BST значения метрики recall@1/8 для английской и переводной версий BST практически одинаковы. Небольшая разница в метрике — это совокупная погрешность перевода и того, насколько хорошо выровнялась пара в модели.
train |
test |
recall@1/8 |
|---|---|---|
bst_ru |
bst_ru |
0,414 |
bst_en |
bst_en |
0,422 |
Мы хотели промоделировать следующий сценарий: взять основные данные на русском и добавить небольшую часть на английских данных, в итоге на целевой задаче (bst_ru) мы получили прирост на 6 пунктов.
train |
test |
recall@1/8 |
|---|---|---|
bst_ru |
bst_ru |
0,414 |
soda+bst_ru |
bst_ru |
0,478 |
soda+bst_en |
bst_en |
0,486 |
soda+bst_en |
bst_ru |
0,451 |
Также можем обратить внимание на 2 и 3 строчку таблицы, где видно, что разница между обучением на английских данных и на смешанных всего 1 пункт, это показывает, что английский сет не «перетягивает» модель на себя при его добавлении к русским данным.
В нашем случае трансфер знаний между языками работает отлично!
Как мы размечаем данные с production?
Для разметки данных с production для получения hard-negatives мы смотрим на следующие критерии:
Безопасность — не общаемся на некоторые темы и следуем принципу «не навреди» по отношению к себе, пользователю и другим.
Достоверность — проверяем постоянные факты для которых возможно найти достоверный источник.
Релевантность — главное понимать намерение пользователя, смысл диалога, отвечать «в тему», без учета других критериев.
Логика — смотрим есть ли противоречия со всем контекстом диалога и общими знаниями о мире.

Если все критерии выполнены, то считаем ответ хорошим, иначе — плохим.
Кэширование вычислений
Идея кэширования key и value во время вычисления attention уже знакома.
KV-кэширование заключается в том, чтобы избавиться от повторного вычисления матриц ключей и значений прошлых токенов на каждом этапе генерации путем сохранения («кэширования») этих тензоров в памяти графического процессора по мере их вычисления в процессе генерации.
KV Caching в encoder-decoder моделях.
В этих моделях происходит генерация токенов один за другим, она может быть дорогостоящей в вычислительном плане. Для решения этой проблемы используется кэширование предыдущих key и value, чтобы не пересчитывать их для каждого нового токена, что уменьшает размер матриц, ускоряя их умножение. Правда для хранения key и value требуется больше памяти. Прежде чем выполнять расчет attention, необходимо объединить полный key и value, поэтому эти две величины необходимо кэшировать и повторно использовать во время каждого вывода.

Есть еще похожие подходы: Cross-attention в transformer decoder, где keys и values берутся из энкодера, а queries из декодера, Chunked Cross-Attention в модели RETRO, который считает query для входных токенов, а key и value для полученных соседей.
Почему бы не переиспользовать этот подход для нашей задачи?
Наш подход:
В обычной реализации cross-encoder мы подаем модели на вход последовательность из n + m токенов, где n — длина контекста, m — ответа. Но с увеличением кандидатов ответа это может быть долго по времени, для k кандидатов нам нужно k раз подать модели последовательность из n + m токенов, учитывая, что контекст не меняется, почему бы не подавать его отдельно и 1 раз?
И мы решили использовать следующий подход: сначала в сеть подается только последовательность контекста, сохраняются key/value матрицы с каждого слоя, затем подаются k последовательностей кандидатов и предрассчитанные key/value матрицы, которые добавляются во время self-attention к key/value матрицам кандидатов на каждом слое. Таким образом, мы один раз считаем представления для токенов контекста и переиспользуем их, чтобы обогатить представления токенов кандидатов по отношению к контексту. Конкатенация матриц key/value похожа на KV-caching в LLaMa и GPT.

Данная идея должна была ускорить скорость работы модели и уменьшить память, так и вышло, причем метрики качества не упали.
В замерах использовали bert-large в fp32, длина ответа всегда 32 токена (включена), вычисления произведены на картах A100.
 в зависимости от длины последовательности и количества кандидатов")
 в зависимости от длины последовательности и количества кандидатов.")
Это позволило увеличить количество кандидатов с 32 до 64 и длину последовательности со 128 до 256 токенов, при этом мы не потеряли в скорости и уменьшили latency в 3 раза.
Теперь мы можем увеличить как количество кандидатов, что даст нам прирост в качестве, так и увеличить длину контекста, чтобы разнообразить реплики, или же взять модель побольше.
Заметим, что когда мы сделали первый проход моделью по контексту, на последнем слое получим эмбеддинг токенов контекста, сделав пулинг мы можем получить эмбеддинг всего контекста, это то что мы делали scu-моделью, тогда мы можем убрать scu-модель из пайплайна и просто использовать эмбеддинг этого контекста для поиска, как в биэнкодерах. Получится модель, которая делает и поиск по базе и ранжирование.
Можем перейти к следующей архитектуре: левая башня для ответа, средняя для контекста, а правая для ранжирования. Получится поиск, состоящий из одной модели, умеющий быстро искать по индексу и в то же время ранжировать ответы.

В итоге
Contrastive learning увеличило метрики на 20%, так как мы уменьшили требования к качеству разметки данных, потому что добавили большее разнообразие в негативы за счет semi-hard негативов и нового лосса.
Можем более эффективно использовать сеты без ручной разметки на негативные примеры.
Можем добавить знаний за счет двуязычной модели и данных на английском.
Нашли способ ранжировать быстрее в ≈7 раз и меньше по памяти в ≈1,6 раз, что будет полезно для увеличения токенов в контексте.
На этом все, с вами была команда Нейронные сети продукта Собеседник. Пробуйте наши решения! Наши модели: sbert_large_nlu_ru, ruElectra-medium (а также small и large), sbert_large_mt_nlu_ru. Попробовать как работает Собеседник можно на всех наших умных устройствах и в приложении Салют!
Увидимся в следующих постах.
Cпасибо за помощь в подготовке материала Саше Абрамову aka @Andriljo а также авторам Ане Максимовой @anpalmakи Артему Снегиреву @artemsnegirev.