Для предотвращения подобных проблем часто используют распределенную архитектуру, то есть архитектуру с возможностью горизонтального масштабирования всех компонентов. Но к сожалению, при реализации SOA возникают новые проблемы, а именно: связность и сложность конфигурации сервисов.

В данной статье мы расскажем об одном из discovery-сервисов под названием Consul, с помощью которого можно решить вышеизложенные проблемы и сделать архитектуру более прозрачной и понятной.
Распределенные архитектуры(SOA) и проблемы их построения
Проектируя приложение как набор слабо связанных компонентов, мы изначально получаем возможность масштабирования любого компонента.
SOA (Service Oriented Architecture) — это архитектурный паттерн, описывающий архитектуру приложения в виде автономных компонентов со слабой связанностью, общающихся между собой по стандартным протоколам (например REST). Логическим продолжением (или подмножеством) SOA является микросервисная архитектура. Она базируется на увеличении количества сервисов вместо увеличения функциональности конкретного сервиса (отражение принципа Single Responsibility в архитектуре) и глубокой интеграции с continuous-процессами.
Если заниматься реализацией микросервисной архитектуры, то, несомненно, ответственность за взаимодействие наших сервисов переходит в сторону инфраструктурного решения нашего приложения. Сервисы, которые соответствуют принципу Single Responsibility, умеют только принимать запрос и возвращать ответ. При этом нужно балансировать трафик между узлами системы, нужно связать, пусть и слабо, но все равно зависимые друг от друга сервисы между собой. И конечно же нам нужно реагировать на изменения конфигурации нашей системы:
- Cервисы постоянно добавляются.
- Hекоторые сервисы перестают реагировать на healthcheck.
- Новые компоненты появляются в системе и нужно максимально эффективно распространить информацию о них.
- Обновляются версии отдельных компонентов — ломается обратная совместимость.
В любой системе это непрерывный и сложный процесс, но при помощи сервиса discovery мы сможем его контролировать и сделать его прозрачнее.
Что такое discovery?
Discovery — это инструмент (или набор инструментов) для обеспечения связи между компонентами архитектуры. Используя discovery мы обеспечиваем связность между компонентами приложения, но не связанность. Discovery можно рассматривать как некий реестр метаинформации о распределенной архитектуре, в котором хранятся все данные о компонентах. Это позволяет реализовать взаимодействие компонентов с минимальным ручным вмешательством (т.е. в соответствии с принципом ZeroConf).
Роль discovery в процессе построения распределенной архитектуры
Discovery-сервис обеспечивает три основных функции, на которых базируется связность в рамках распределенной архитектуры:
- Консистентность метаинформации о сервисах в рамках кластера.
- Механизм для регистрации и мониторинга доступности компонентов.
- Механизм для обнаружения компонентов.
Раскроем значения каждого пункта подробно:
Консистентность
Распределенная архитектура подразумевает, что компоненты можно масштабировать горизонтально, при этом они должны владеть актуальной информацией о состоянии кластера. Discovery-сервис обеспечивает (де)централизованное хранилище и доступ к нему для любого узла. Компоненты могут сохранять свои данные и информация будет доставлена ко всем заинтересованным участникам кластера.
Регистрация и мониторинг
Вновь добавляемые сервисы должны сообщить о себе, а уже запущенные обязаны проходить постоянную проверку на доступность. Это является необходимым условием для автоматической конфигурации кластера. Балансеры трафика и зависимые ноды обязательно должны иметь информацию о текущей конфигурации кластера для эффективного использования ресурсов.
Обнаружение
Под обнаружением подразумевается механизм поиска сервисов, например, по ролям которые они выполняют. Мы можем запросить местоположение для всех сервисов определенной роли, не зная их точного количества и конкретных адресов, а зная лишь адрес discovery-сервиса.
Consul.io как реализация discovery
В данной статье рассматривается реализация discovery на базе Consul.
Consul — это децентрализованный отказоустойчивый discovery-сервис от компании HashiCorp (которая разрабатывает такие продукты как Vagrant, TerraForm, Otto, Atlas и другие).
Consul является децентрализованным сервисом, то есть Consul agent устанавливается на каждый хост и является полноправным участником кластера. Таким образом, сервисам не нужно знать адрес discovery в нашей сети, все запросы к discovery выполняются на локальный адрес 127.0.0.1.
Что еще необходимо знать про Consul:
Для распространения информации использует алгоритмы, которые базируются на модели eventual consistency.
Агенты для распространения информации используют протокол gossip.
Серверы для выбора лидера используют алгоритм Raft.
Лидер — это сервер, который принимает все запросы на изменение информации. Если провести аналогию с БД, то это master в контексте master/slave — репликации. Все остальные серверы реплицируют данные с лидера. Ключевое отличие от БД-репликации в том, что в случае выхода из строя лидера все остальные серверы запускают механизм выборов нового лидера и после выборов автоматически начинают реплицироваться с него. Механизм переключения полностью автоматический и не требует вмешательства администратора.
Каждый инстанс может работать в двух режимах: агент и сервер. Разница в том, что агент является точкой распространения информации, а сервер — точкой регистрации. Т.е. агенты принимают запросы только на чтение, а сервер может выполнять изменения уже имеющейся информации (регистрация и удаление сервисов). Фактически мы, в любом случае, выполняем запрос к локальному адресу, разница лишь в том, что запрос на чтение будет обработан агентом на локальном хосте, а запрос на изменение данных будет переадресован лидеру, который сохранит и распространит данные по всему кластеру. Если наш локальный агент не является лидером в данный момент, то наш запрос на изменение будет полностью обработан локально и распространен по кластеру.
Использование Consul в кластере
Consul кластер представляет собой сеть связанных узлов, на которых запущены сервисы, зарегистрированные в discovery. Consul гарантирует, что информация о кластере будет распространена по всем участникам кластера и доступна по запросу. Также реализована поддержка не только однорангового, но и многорангового, разделенного по зонам, кластера, которые в терминологии Consul называются датацентрами. При помощи Consul можно работать как с конкретным датацентром, так и выполнять действия над любым другим. Датацентры не изолированы друг от друга в рамках discovery. Агент в одном ДЦ может получить информацию из другого ДЦ, что может помочь в построении эффективного решения для распределенной системы.
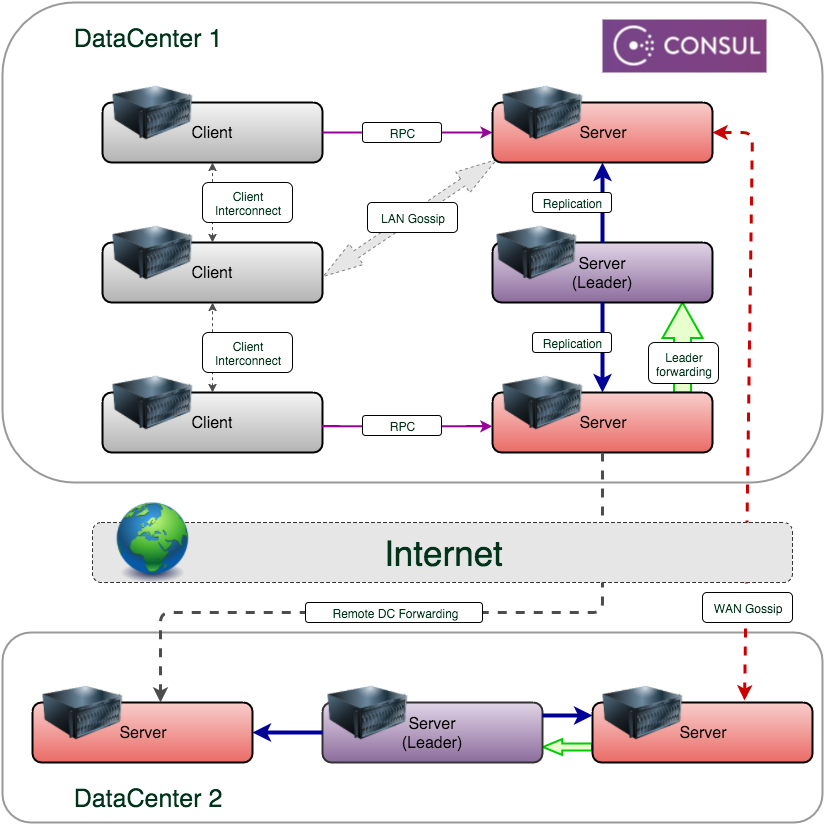
Агенты Consul, запущенные в режиме server, помимо своей основной роли, получают еще и роль потенциального лидера кластера. Рекомендуется использовать в кластере не менее трех агентов в режиме server для обеспечения отказоустойчивости. Использования режима server не накладывает никаких ограничений на основную функциональность агента.
При вводе нового узла в кластер, нам необходимо знать адрес любого узла в кластере. Выполнив команду:
consul join node_ip_addressмы регистрируем новый узел в кластере и, спустя короткое время, информация о состоянии всего кластера будет доступна этому узлу. Соответственно, новый узел окажется доступным для запросов от остальных узлов.
Типы узлов: internal, external
В Consul мы можем зарегистрировать наш сервис двумя способами:
- Использовать HTTP API или конфигурационный файл агента, но только в том случае если ваш сервис может общаться с Consul самостоятельно.
- Зарегистрировать сервис как 3d-party компонент, в случае если сервис не может общаться с Consul.
Рассмотрим оба случая чуть подробнее.
При помощи HTTP API, предоставляемого Consul, есть возможность сделать корректную регистрацию компонента и удаление сервиса в discovery. Помимо этих двух состояний, можно использовать состояние
maintenance. В этом режиме сервис помечается как недоступный и перестает отображаться в DNS и API-запросах.Рассмотрим пример запроса регистрации компонента (JSON должен быть передан в PUT-запросе):
http://localhost:8500/v1/agent/service/register
{
"ID": "redis1",
"Name": "redis",
"Tags": [
"master",
"v1"
],
"Address": "127.0.0.1",
"Port": 8000,
"Check": {
"Script": "/usr/local/bin/check_redis.py",
"HTTP": "http://localhost:5000/health",
"Interval": "10s",
"TTL": "15s"
}
}
Пример запроса на удаление компонента из каталога:
http://localhost:8500/v1/agent/service/deregister/[ServiceID]
Пример запроса на перевод сервиса в режим maintenance:
http://localhost:8500/v1/agent/service/maintenanse/[ServiceID]?enable=true|false
При помощи флага enable мы можем переключать состояние и добавить необязательный параметр reason, который содержит текстовое описание причины перевода компонента в режим обслуживания.
Если нам необходимо зарегистрировать какой-либо внешний сервис и у нас нет возможности “научить” его регистрироваться в Consul самостоятельно, то мы можем зарегистрировать его не как сервис-провайдер, а именно как внешний сервис (external service). После регистрации мы сможем получить данные о внешнем сервисе через DNS:
$ curl -X PUT -d '{"Datacenter": "dc1", "Node": "google",
"Address": "www.google.com",
"Service": {"Service": "search", "Port": 80}}'
http://127.0.0.1:8500/v1/catalog/register
Помимо HTTP API вы можете использовать конфигурационные файлы агента с описанием сервисов.
Во второй части мы завершим рассказ о сервисе Consul, а именно расскажем о его следующих функциях:
- Интерфейс DNS.
- HTTP API.
- Health Checks.
- K/V storage.
И конечно же подведем итоги работы с Consul.
Комментарии (8)

nwalker
03.03.2016 16:23Получается, каждый сервис должен знать IP, по которому доступен?
LogPacker
03.03.2016 16:40Нет, не совсем так. Каждый сервис регистрируется в консуле, как раз для того, чтобы не знать свой IP. Агент консула запускается рядом с каждым сервисом и берет на себя всю работу по распространению информации по кластеру.

grossws
03.03.2016 17:39Строго говоря, часто ip этого сервиса должен знать тот, кто его регистрирует, а это не обязательно сам сервис. Вот запускается у меня сервис в своём netns, где у него на условном eth0 ip 172.17.0.22, стучится в консул на бридже 172.17.0.1. В netns, где работает консул есть три адаптера: eth0 (внешний с условным ip 203.0.113.12), tap0 (vpn с условным 10.8.0.33) и бридж с 172.17.0.1. Если что, описанный setup — модель хоста с сервисом, запущенным в docker/systemd.
Какой из ip адресов должен быть указан в консуле? Каким образом он его выберет? Тот же registrator решает эту проблему явным указанием адреса, на который надо регистрировать сервисы.LogPacker
04.03.2016 07:18Да, вы правы. Прелесть консула в его децентрализованности, то есть нужды держать discovery на бридже у вас нет, агент консула всегда доступен для вашего сервиса на локальном интерфейсе. Если вы запускаете сервис в контейнере, то там будет всего два интерфейса — локальный и внешний, консул успешно разместится на обоих:
root@2bc788f155da:~# ifconfig eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:02 inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0 inet6 addr: fe80::42:acff:fe11:2/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:14 errors:0 dropped:0 overruns:0 frame:0 TX packets:7 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1156 (1.1 KB) TX bytes:578 (578.0 B) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B) root@2bc788f155da:~# ./consul agent -data-dir /tmp/consul/ ==> Starting Consul agent... ==> Starting Consul agent RPC... ==> Consul agent running! Node name: '2bc788f155da' Datacenter: 'dc1' Server: false (bootstrap: false) Client Addr: 127.0.0.1 (HTTP: 8500, HTTPS: -1, DNS: 8600, RPC: 8400) Cluster Addr: 172.17.0.2 (LAN: 8301, WAN: 8302) Gossip encrypt: false, RPC-TLS: false, TLS-Incoming: false Atlas: <disabled>
Посмотрите на Cludter Addr — это именно тот интерфейс, который будет доступен для кластера Consul извне
Теперь попробуем запустить консул на хост-машине, там явно больше двух интерфейсов
docker@consul:/mnt/sda1/tmp$ ifconfig docker0 Link encap:Ethernet HWaddr 02:42:7A:86:C8:9D inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0 inet6 addr: fe80::42:7aff:fe86:c89d/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:8 errors:0 dropped:0 overruns:0 frame:0 TX packets:8 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:536 (536.0 B) TX bytes:648 (648.0 B) eth0 Link encap:Ethernet HWaddr 08:00:27:89:88:DF inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fe89:88df/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:883 errors:0 dropped:0 overruns:0 frame:0 TX packets:573 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:128760 (125.7 KiB) TX bytes:104274 (101.8 KiB) eth1 Link encap:Ethernet HWaddr 08:00:27:A2:68:2C inet addr:192.168.99.100 Bcast:192.168.99.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fea2:682c/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:165 errors:0 dropped:0 overruns:0 frame:0 TX packets:112 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:21390 (20.8 KiB) TX bytes:22364 (21.8 KiB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:16 errors:0 dropped:0 overruns:0 frame:0 TX packets:16 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1376 (1.3 KiB) TX bytes:1376 (1.3 KiB) veth01e9663 Link encap:Ethernet HWaddr 6A:0F:14:E9:35:D2 inet6 addr: fe80::680f:14ff:fee9:35d2/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:8 errors:0 dropped:0 overruns:0 frame:0 TX packets:16 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:648 (648.0 B) TX bytes:1296 (1.2 KiB) docker@consul:/mnt/sda1/tmp$ ./consul agent -data-dir=/tmp/cns ==> Starting Consul agent... ==> Error starting agent: Failed to get advertise address: Multiple private IPs found. Please configure one.
Не стартует. Необходимо явно указать адрес, на который будет биндиться интерфейс кластера
docker@consul:/mnt/sda1/tmp$ ./consul agent -data-dir=/tmp/cns -bind=172.17.0.1 ==> Starting Consul agent... ==> Starting Consul agent RPC... ==> Consul agent running! Node name: 'consul' Datacenter: 'dc1' Server: false (bootstrap: false) Client Addr: 127.0.0.1 (HTTP: 8500, HTTPS: -1, DNS: 8600, RPC: 8400) Cluster Addr: 172.17.0.1 (LAN: 8301, WAN: 8302) Gossip encrypt: false, RPC-TLS: false, TLS-Incoming: false Atlas: <disabled>
Вот теперь все ок.
Дальше кейс использования очень простой. Ваш сервис (или то, что его запускает :) ) всегда знает, что на локальном интерфейсе есть API консула, а консул дальше распространяет эту информацию по кластеруgrossws
04.03.2016 10:02Этот подход имеет четыре недостатка:
- не работает, если у вас больше одного хоста (или требует ручного геморроя с подсетями для бриджа), т. к. адрес сервиса 172.17.0.22 абсолютно не говорит о том, как к этому сервису обращаться, если он реально на другом хосте;
- требует ухода от SRP, модификации образов контейнеров и запуска связки супервизор+консул+сервис в каждом контейнере;
- резко увеличивает поверхность атаки, т. к. статические ключи для serf'овского gossip'а и ключи+сертификаты для tls будут присутствовать в каждом контейнере;
- требует внесения изменений во все сервисы, что трудоёмко и не всегда возможно.
Мне больше импонирует подход с вынесением этого счастья на уровень инфраструктуры (вышеупомянутый registrator, подход с systemd unit'ом с BindsTo.LogPacker
04.03.2016 10:38Возможно, в вашем случае все описанные недостатки существенны и имеют место быть. В таком случае вы правы и вам действительно лучше выбрать другой подход и другие инструменты.
Suvitruf
Вообще, настройку лучше не ручками делать. У нас, к примеру, всё это через Ansible. Используем плейбук вроде этого.
LogPacker
Да, несомненно это так. Просто в статье мы описывали не особенности конфигурации консула, а, скорее, применимость его для discovery в целом. Мы описали ситуацию, которую можно воспроизвести как “посмотреть на его возможности”.