Luxoft Training предлагает познакомиться с переводом еще одной статьи Рандольфа Гайста «Big Nodes, Concurrent Parallel Execution And High System/Kernel Time».
 Рандольф Гайст специализируется на исправлении ошибок, связанных с производительностью баз данных Oracle. Входит в число лучших специалистов в мире в области анализа исполнения SQL-кода и технологий Oracle по оптимизации. Является сертифицированным администратором Oracle базы данных (OCP DBA) версий 8i, 9i и 10g.
Рандольф Гайст специализируется на исправлении ошибок, связанных с производительностью баз данных Oracle. Входит в число лучших специалистов в мире в области анализа исполнения SQL-кода и технологий Oracle по оптимизации. Является сертифицированным администратором Oracle базы данных (OCP DBA) версий 8i, 9i и 10g.
Нижеследующее относится только к заказчикам, которые запускают Oracle на крупных серверах с большим количеством ядер в режиме одного экземпляра (данная конкретная проблема не воспроизводится в среде RAC, смотрите ниже объяснение, почему).
К таким заказчикам относится один из моих клиентов, который использует серверы Exadata Xn-8, например, X4-8 со 120 ядрами/240 процессорами на каждый узел (но воспроизводится также и на более старых и меньших моделях с 64 ядрами/128 процессорами на узел).
Недавно базовое приложение решили переписать. Часть этого кода выполняла одни и те же операции для различных наборов данных, во многих случаях – одновременно. Это приводило к тому, что во множестве сеансов использовалось параллельное выполнение запросов. Многие запросы в этом коде не лучшим образом задействовали параллельное выполнение: запросы с очень короткой продолжительностью использовали параллельное выполнение, приводя к нескольким запускам параллельного исполнения в секунду. Такую картину можно увидеть в отчете AWR, показывающем, что в среднем каждую секунду часа запускалось несколько деревьев параллельного выполнения:

Когда новый код был протестирован на данных и нагрузке, полученных с продукционной системы, сначала профиль процессора такого крупного узла (работающего в режиме одного экземпляра) выглядел следующим образом. При этом компьютер не был загружен другими процессами.
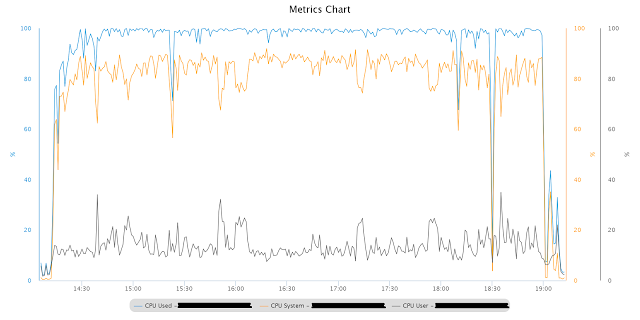
Как видно на рис., процессор узла полностью загружен, причем большую часть времени – в режиме ядра/системы. Отчеты AWR показали значительное количество нетипичных событий ожидания PX:
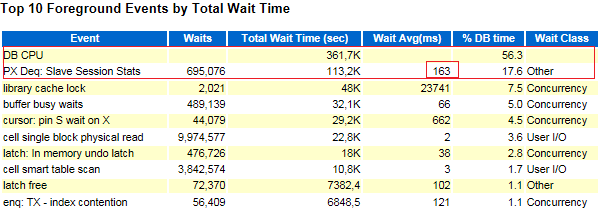
Событие «PX Deq: Slave Session Stats» не должно занимать большое количество времени, поскольку речь идет о передаче статистик сессий ведомых узлов координатору PX в момент их завершения. Очевидно, что-то значительно замедляло это PX-взаимодействие (и заметить это можно было только при чрезмерном использовании параллельного выполнения).
Кроме того, некоторые из более сложных запросов с параллельным выполнением, выполняющие большое количество объединений и приводящие к значительному количеству перераспределений данных, происходили как при замедленной съемке. Хотя почти 100% времени выполнения приходилось на CPU, в Active Session History видно – почти 90% времени относится к операции перераспределения:
Запуск того же запроса с тем же планом выполнения и теми же данными на той же машине во время ее простоя показал почти в 20 раз более высокую производительность, а на перераспределение было затрачено менее 40 % времени:
Видимо эти запросы вошли в какое-то состязание, происходящее не в Oracle, а снаружи (на уровне операционной системы), и проявляющееся как затраты времени процессора в режиме ядра. Подобное наблюдалось в предыдущих версиях Oracle при «спиннинге» мьютексов.
Снижение чрезмерного использования параллельного выполнения вызвало значительное сокращение времени ЦП. Но по-прежнему большое количество времени работы процессора в режиме ядра/системы было непонятно.
Итак, главный вопрос: на что именно в ядре операционной системы тратилось это время. Ответ на него могли бы помочь найти дополнительные подсказки.
Запуск «perf top» на узле во время такого запуска выдал следующий профиль:
Запуск «strace» по этим параллельным ведомым выдал следующее:
Вывод: много времени ЦП тратится на «спиннинг» спин-блокировок (критическая секция кода), вызванный обращениями при параллельном выполнении к «semctl» (семафорам). «strace» показывает, что все обращения к «semctl» используют один и тот же набор семафоров (первый параметр), что и объясняет состязание по этому конкретному набору семафоров (область блокирования – это набор семафоров, а не семафор).
На основании результатов «perf» инженер Oracle нашел подходящую, но, к сожалению, неопубликованную и закрытую ошибку 2013 г. в версии 12.1.0.2. Для нее есть три различных способа решения проблемы:
1. Запуск с «cluster_database» = true: при этом Oracle будет выполнять запросы по-другому, что приведет к снижению количества вызовов семафоров на два порядка. Мы протестировали этот подход, и он показал немедленную разгрузку по времени работы ядра – вот и объяснение, почему в среде RAC эта конкретная проблема не воспроизводится.
2. Запуск с другими настройками «kernel.sem»: машины Exadata пришли со следующей заранее заданной конфигурацией семафоров:
«ipcs» показал следующие массивы семафоров с этой конфигурацией при запуске экземпляра Oracle:
Иными словами, теперь Oracle выделил гораздо больше наборов с меньшим количеством семафоров в наборе. Мы протестировали эту конфигурацию вместо «cluster_database = TRUE» и получили такое же низкое время работы ядра процессора.
3. Есть и третий вариант решения проблемы. Его преимущество: не требуется менять конфигурацию хоста, и конфигурация может быть сделана для каждого экземпляра: существует недокументированный параметр «_sem_per_sem_id», который определяет верхний предел количества семафоров, выделяемых на набор. При установке подходящего значения этого параметра, такого как 100 или 128, конечный результат должен быть таким же. Oracle выделит больше наборов с меньшим количеством семафоров в наборе, но мы не проверяли этот вариант.
Некоторые способы использования экземпляра Oracle приводят к состязанию в спин-блокировках на уровне операционной системы Linux ( если Oracle работает в режиме одного экземпляра) и используются рекомендуемые настройки семафоров. Это приводит к тому, что все вызовы семафоров идут в один и тот же набор семафоров. Если заставить Oracle выделить больше наборов семафоров, то вызовы распределяются по большему количеству наборов. Следовательно, состязание значительно снижается.
Существуют, вероятно, указания для внутреннего использования в Oracle о том, что параметры семафоров по умолчанию, рекомендуемые для больших узлов, не являются оптимальными для режима одного экземпляра при определенных обстоятельствах. Но я не знаю, имеется ли исчерпывающее официальное руководство.
Это профиль CPU при точно такой же тестовой нагрузке, как и раньше, с использованием измененных настроек «kernel.sem»:
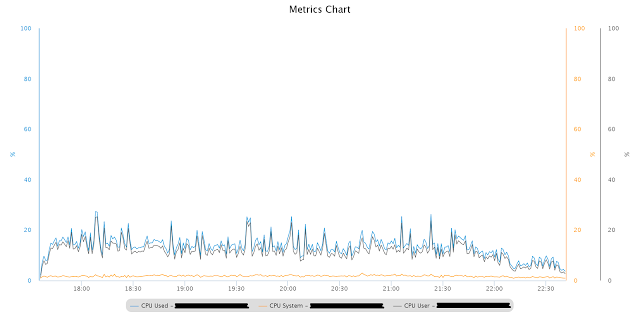
Также из отчета AWR исчезли связанные с PX события ожидания, которых быть не должно. Производительность значительно улучшилась, также и для сложных запросов, упомянутых выше.
Если вам понравился материал от Рандольфа, то 24 марта он проводит свой мастер-класс в Москве.
Рандольф Гайст специализируется на исправлении ошибок, связанных с производительностью баз данных Oracle. Входит в число лучших специалистов в мире в области анализа исполнения SQL-кода и технологий Oracle по оптимизации. Является сертифицированным администратором Oracle базы данных (OCP DBA) версий 8i, 9i и 10g. Нижеследующее относится только к заказчикам, которые запускают Oracle на крупных серверах с большим количеством ядер в режиме одного экземпляра (данная конкретная проблема не воспроизводится в среде RAC, смотрите ниже объяснение, почему).
К таким заказчикам относится один из моих клиентов, который использует серверы Exadata Xn-8, например, X4-8 со 120 ядрами/240 процессорами на каждый узел (но воспроизводится также и на более старых и меньших моделях с 64 ядрами/128 процессорами на узел).
Недавно базовое приложение решили переписать. Часть этого кода выполняла одни и те же операции для различных наборов данных, во многих случаях – одновременно. Это приводило к тому, что во множестве сеансов использовалось параллельное выполнение запросов. Многие запросы в этом коде не лучшим образом задействовали параллельное выполнение: запросы с очень короткой продолжительностью использовали параллельное выполнение, приводя к нескольким запускам параллельного исполнения в секунду. Такую картину можно увидеть в отчете AWR, показывающем, что в среднем каждую секунду часа запускалось несколько деревьев параллельного выполнения:
Когда новый код был протестирован на данных и нагрузке, полученных с продукционной системы, сначала профиль процессора такого крупного узла (работающего в режиме одного экземпляра) выглядел следующим образом. При этом компьютер не был загружен другими процессами.
Как видно на рис., процессор узла полностью загружен, причем большую часть времени – в режиме ядра/системы. Отчеты AWR показали значительное количество нетипичных событий ожидания PX:
Событие «PX Deq: Slave Session Stats» не должно занимать большое количество времени, поскольку речь идет о передаче статистик сессий ведомых узлов координатору PX в момент их завершения. Очевидно, что-то значительно замедляло это PX-взаимодействие (и заметить это можно было только при чрезмерном использовании параллельного выполнения).
Кроме того, некоторые из более сложных запросов с параллельным выполнением, выполняющие большое количество объединений и приводящие к значительному количеству перераспределений данных, происходили как при замедленной съемке. Хотя почти 100% времени выполнения приходилось на CPU, в Active Session History видно – почти 90% времени относится к операции перераспределения:
SQL statement execution ASH Summary
-----------------------------------------------
| | |
|PX SEND/RECEIVE|PX SEND/RECEIVE|
PERCENTAGE_CPU| PERCENT| CPU PERCENT|
--------------|---------------|---------------|
98| 86| 87|
Запуск того же запроса с тем же планом выполнения и теми же данными на той же машине во время ее простоя показал почти в 20 раз более высокую производительность, а на перераспределение было затрачено менее 40 % времени:
SQL statement execution ASH Summary
-----------------------------------------------
| | |
|PX SEND/RECEIVE|PX SEND/RECEIVE|
PERCENTAGE_CPU| PERCENT| CPU PERCENT|
--------------|---------------|---------------|
96| 38| 37|
Видимо эти запросы вошли в какое-то состязание, происходящее не в Oracle, а снаружи (на уровне операционной системы), и проявляющееся как затраты времени процессора в режиме ядра. Подобное наблюдалось в предыдущих версиях Oracle при «спиннинге» мьютексов.
Снижение чрезмерного использования параллельного выполнения вызвало значительное сокращение времени ЦП. Но по-прежнему большое количество времени работы процессора в режиме ядра/системы было непонятно.
Итак, главный вопрос: на что именно в ядре операционной системы тратилось это время. Ответ на него могли бы помочь найти дополнительные подсказки.
Анализ
Запуск «perf top» на узле во время такого запуска выдал следующий профиль:
PerfTop: 129074 irqs/sec kernel:76.4% exact: 0.0% [1000Hz cycles], (all, 128 CPUs)
-------------------------------------------------------------------------------------------------------------------
samples pcnt function DSO
_______ _____ ________________________ ___________________________________________________________
1889395.00 67.8% __ticket_spin_lock /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
27746.00 1.0% ktime_get /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
24622.00 0.9% weighted_cpuload /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
23169.00 0.8% find_busiest_group /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
17243.00 0.6% pfrfd1_init_locals /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
16961.00 0.6% sxorchk /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
15434.00 0.6% kafger /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
11531.00 0.4% try_atomic_semop /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
11006.00 0.4% __intel_new_memcpy /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
10557.00 0.4% kaf_typed_stuff /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
10380.00 0.4% idle_cpu /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
9977.00 0.4% kxfqfprFastPackRow /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
9070.00 0.3% pfrinstr_INHFA1 /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
8905.00 0.3% kcbgtcr /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
8757.00 0.3% ktime_get_update_offsets /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
8641.00 0.3% kgxSharedExamine /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
7487.00 0.3% update_queue /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
7233.00 0.3% kxhrPack /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
6809.00 0.2% rworofprFastUnpackRow /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
6581.00 0.2% ksliwat /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
6242.00 0.2% kdiss_fetch /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
6126.00 0.2% audit_filter_syscall /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
5860.00 0.2% cpumask_next_and /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
5618.00 0.2% kaf4reasrp1km /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
5482.00 0.2% kaf4reasrp0km /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
5314.00 0.2% kopp2upic /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
5129.00 0.2% find_next_bit /usr/lib/debug/lib/modules/2.6.39-400.128.17.el5uek/vmlinux
4991.00 0.2% kdstf01001000000km /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
4842.00 0.2% ktrgcm /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
4762.00 0.2% evadcd /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
4580.00 0.2% kdiss_mf_sc /data/oracle/XXXXXXX/product/11.2.0.4/bin/oracle
Запуск «perf» при сильно загруженных по процессору параллельных ведомых выдал следующий профиль:
0.36% ora_xxxx [kernel.kallsyms] [k]
__ticket_spin_lock
|
--- __ticket_spin_lock
|
|--99.98%-- _raw_spin_lock
| |
| |--100.00%-- ipc_lock
| | ipc_lock_check
| | |
| | |--99.83%-- semctl_main
| | | sys_semctl
| | | system_call
| | | __semctl
| | | |
| | | --100.00%-- skgpwpost
| | | kslpsprns
| | | kskpthr
| | | ksl_post_proc
| | | kxfprienq
| | | kxfpqrenq
| | | |
| | | |--98.41%-- kxfqeqb
| | | | kxfqfprFastPackRow
| | | | kxfqenq
| | | | qertqoRop
| | | | kdstf01001010000100km
| | | | kdsttgr
| | | | qertbFetch
| | | | qergiFetch
| | | | rwsfcd
| | | | qertqoFetch
| | | | qerpxSlaveFetch
| | | | qerpxFetch
| | | | opiexe
| | | | kpoal8
Запуск «strace» по этим параллельным ведомым выдал следующее:
.
.
.
semctl(1347842, 397, SETVAL, 0x1) = 0
semctl(1347842, 388, SETVAL, 0x1) = 0
semctl(1347842, 347, SETVAL, 0x1) = 0
semctl(1347842, 394, SETVAL, 0x1) = 0
semctl(1347842, 393, SETVAL, 0x1) = 0
semctl(1347842, 392, SETVAL, 0x1) = 0
semctl(1347842, 383, SETVAL, 0x1) = 0
semctl(1347842, 406, SETVAL, 0x1) = 0
semctl(1347842, 389, SETVAL, 0x1) = 0
semctl(1347842, 380, SETVAL, 0x1) = 0
semctl(1347842, 395, SETVAL, 0x1) = 0
semctl(1347842, 386, SETVAL, 0x1) = 0
semctl(1347842, 385, SETVAL, 0x1) = 0
semctl(1347842, 384, SETVAL, 0x1) = 0
semctl(1347842, 375, SETVAL, 0x1) = 0
semctl(1347842, 398, SETVAL, 0x1) = 0
semctl(1347842, 381, SETVAL, 0x1) = 0
semctl(1347842, 372, SETVAL, 0x1) = 0
semctl(1347842, 387, SETVAL, 0x1) = 0
semctl(1347842, 378, SETVAL, 0x1) = 0
semctl(1347842, 377, SETVAL, 0x1) = 0
semctl(1347842, 376, SETVAL, 0x1) = 0
semctl(1347842, 367, SETVAL, 0x1) = 0
semctl(1347842, 390, SETVAL, 0x1) = 0
semctl(1347842, 373, SETVAL, 0x1) = 0
semctl(1347842, 332, SETVAL, 0x1) = 0
semctl(1347842, 379, SETVAL, 0x1) = 0
semctl(1347842, 346, SETVAL, 0x1) = 0
semctl(1347842, 369, SETVAL, 0x1) = 0
semctl(1347842, 368, SETVAL, 0x1) = 0
semctl(1347842, 359, SETVAL, 0x1) = 0
.
.
.
Вывод: много времени ЦП тратится на «спиннинг» спин-блокировок (критическая секция кода), вызванный обращениями при параллельном выполнении к «semctl» (семафорам). «strace» показывает, что все обращения к «semctl» используют один и тот же набор семафоров (первый параметр), что и объясняет состязание по этому конкретному набору семафоров (область блокирования – это набор семафоров, а не семафор).
Решение
На основании результатов «perf» инженер Oracle нашел подходящую, но, к сожалению, неопубликованную и закрытую ошибку 2013 г. в версии 12.1.0.2. Для нее есть три различных способа решения проблемы:
1. Запуск с «cluster_database» = true: при этом Oracle будет выполнять запросы по-другому, что приведет к снижению количества вызовов семафоров на два порядка. Мы протестировали этот подход, и он показал немедленную разгрузку по времени работы ядра – вот и объяснение, почему в среде RAC эта конкретная проблема не воспроизводится.
2. Запуск с другими настройками «kernel.sem»: машины Exadata пришли со следующей заранее заданной конфигурацией семафоров:
kernel.sem = 2048 262144 256 256«ipcs» показал следующие массивы семафоров с этой конфигурацией при запуске экземпляра Oracle:
------ Semaphore Arrays --------
key semid owner perms nsems
.
.
.
0xd87a8934 12941057 oracle 640 1502
0xd87a8935 12973826 oracle 640 1502
0xd87a8936 12006595 oracle 640 1502
При уменьшении числа семафоров в наборе и увеличении числа наборов, например, так:
kernel.sem = 100 262144 256 4096
Можно увидеть следующий вывод «ipcs»:
------ Semaphore Arrays --------
key semid owner perms nsems
.
.
.
0xd87a8934 13137665 oracle 640 93
0xd87a8935 13170434 oracle 640 93
0xd87a8936 13203203 oracle 640 93
0xd87a8937 13235972 oracle 640 93
0xd87a8938 13268741 oracle 640 93
0xd87a8939 13301510 oracle 640 93
0xd87a893a 13334279 oracle 640 93
0xd87a893b 13367048 oracle 640 93
0xd87a893c 13399817 oracle 640 93
0xd87a893d 13432586 oracle 640 93
0xd87a893e 13465355 oracle 640 93
0xd87a893f 13498124 oracle 640 93
0xd87a8940 13530893 oracle 640 93
0xd87a8941 13563662 oracle 640 93
0xd87a8942 13596431 oracle 640 93
0xd87a8943 13629200 oracle 640 93
0xd87a8944 13661969 oracle 640 93
0xd87a8945 13694738 oracle 640 93
0xd87a8946 13727507 oracle 640 93
0xd87a8947 13760276 oracle 640 93
0xd87a8948 13793045 oracle 640 93
0xd87a8949 13825814 oracle 640 93
0xd87a894a 13858583 oracle 640 93
0xd87a894b 13891352 oracle 640 93
0xd87a894c 13924121 oracle 640 93
0xd87a894d 13956890 oracle 640 93
0xd87a894e 13989659 oracle 640 93
0xd87a894f 14022428 oracle 640 93
0xd87a8950 14055197 oracle 640 93
0xd87a8951 14087966 oracle 640 93
0xd87a8952 14120735 oracle 640 93
0xd87a8953 14153504 oracle 640 93
0xd87a8954 14186273 oracle 640 93
0xd87a8955 14219042 oracle 640 93
Иными словами, теперь Oracle выделил гораздо больше наборов с меньшим количеством семафоров в наборе. Мы протестировали эту конфигурацию вместо «cluster_database = TRUE» и получили такое же низкое время работы ядра процессора.
3. Есть и третий вариант решения проблемы. Его преимущество: не требуется менять конфигурацию хоста, и конфигурация может быть сделана для каждого экземпляра: существует недокументированный параметр «_sem_per_sem_id», который определяет верхний предел количества семафоров, выделяемых на набор. При установке подходящего значения этого параметра, такого как 100 или 128, конечный результат должен быть таким же. Oracle выделит больше наборов с меньшим количеством семафоров в наборе, но мы не проверяли этот вариант.
Вывод
Некоторые способы использования экземпляра Oracle приводят к состязанию в спин-блокировках на уровне операционной системы Linux ( если Oracle работает в режиме одного экземпляра) и используются рекомендуемые настройки семафоров. Это приводит к тому, что все вызовы семафоров идут в один и тот же набор семафоров. Если заставить Oracle выделить больше наборов семафоров, то вызовы распределяются по большему количеству наборов. Следовательно, состязание значительно снижается.
Существуют, вероятно, указания для внутреннего использования в Oracle о том, что параметры семафоров по умолчанию, рекомендуемые для больших узлов, не являются оптимальными для режима одного экземпляра при определенных обстоятельствах. Но я не знаю, имеется ли исчерпывающее официальное руководство.
Это профиль CPU при точно такой же тестовой нагрузке, как и раньше, с использованием измененных настроек «kernel.sem»:
Также из отчета AWR исчезли связанные с PX события ожидания, которых быть не должно. Производительность значительно улучшилась, также и для сложных запросов, упомянутых выше.
Если вам понравился материал от Рандольфа, то 24 марта он проводит свой мастер-класс в Москве.