
— Смета была 200 миллионов рублей, а стала 650 миллионов! Вы обалдели?
По слухам, именно так начался этот проект на совете директоров банка. Курсовая разница по одной из поставок серверов составляла 450 миллионов рублей. Естественно, хотелось как-то уменьшить эти затраты.
Долгое время считалось, что архитектура x86 «из коробки» не предназначена для серьёзных вычислений. Самые серьёзные в мире вычисления (по нагрузке и требованиям к надёжности) — это банковское ядро, процессинг. Там не закончить считать вовремя 2–3 операционных дня подряд означает просто закрытие банка (и проблемы с банковской системой страны) из-за возникающего разрыва, который догнать уже невозможно.
Один банк из ТОП-10 ещё пару лет назад планировал докупить себе машин P-серии, известных своей надёжностью, масштабируемостью и производительностью. Про x86 там даже не думали, пока не настал кризис. Но кризис настал. Одна машина за 5–7 миллионов долларов (а нужна даже не одна и не две) — это немного перебор. Поэтому руководство решило тщательно изучить вопрос замены RISC на x86.
Ниже — сравнение двух подобных конфигураций (они не совсем одинаковые): P-серия с RISC-процессорами с ядрами на 4 ГГЦ из расчёта одно RISC-ядро на два ядра x86 2.7 ГГЦ. Всё это мы смонтировали в машзале дата-центра банка, загнали туда реальную базу, показывающую несколько банковских дней за прошлый год (у них есть специально заготовленная среда для тестов, полностью симулирующая реальность и полноценную нагрузку от транзакций, банкоматов, запросов и т. п.), и выяснили, что x86 подходит и стоит в разы дешевле.

В правом углу ринга
RISC-машины хороши своей способностью делать вычисления быстро и надёжно. До появления кластеров, как описано ниже, других альтернатив в банковском ядре не было — не получалось масштабироваться. Кроме того, RISC-машины лишены традиционного недостатка x86 при высокой нагрузке — у них не падает производительность при долгой постоянной нагрузке выше 70–80%. Но, учитывая редкость решений, цена соответствует. Плюс банки всегда берут расширенный сервис на поставку частей, а это сравнимо со стоимостью самой машины на 3 года (30% от стоимости закупки за год). Ещё одна особенность — апгрейд методом выкидывания старой железки. Например, P-серия трёхлетней давности сейчас часто списывается просто в тестовые среды, потому что боевого применения в системах ядра ей нет — надо закупать новые машины постоянно. Естественно, производители всячески мотивируют на «апгрейд покупкой» — тем и живут. Частый способ — повысить стоимость расширенной поддержки для машин старше 3 лет.
Вот график поставки таких машин по миру:

А вот соотношение стоимости покупки к операционным затратам:

В левом углу ринга
У HPE нашлось подходящее архитектурное решение Superdome — классическая реализация архитектуры ccNUMA на базе системного коммутатора «процессорных шин» с возможностью свободного расширения при добавлении ядер. До этой архитектуры фактически x86-кластеры так или иначе быстро упирались в свои пределы увеличения мощности из-за больших издержек на перетаскивание данных между ядрами.
По масштабируемости — это х86 блейды, соединённые между собой:

ОС — RED HAT + Oracle. Стоимость — в разы ниже, чем для RISC-архитектуры, поскольку все детали крупносерийные и широко распространены по рынку. Плюс лицензии выходят дешевле. Стоит добавить, что цена сервиса тоже существенно привлекательнее, поскольку и архитектура куда менее «шаманистая».
Немного гикпорна:

BL920s Gen9 Server Blade Memory Subsystem
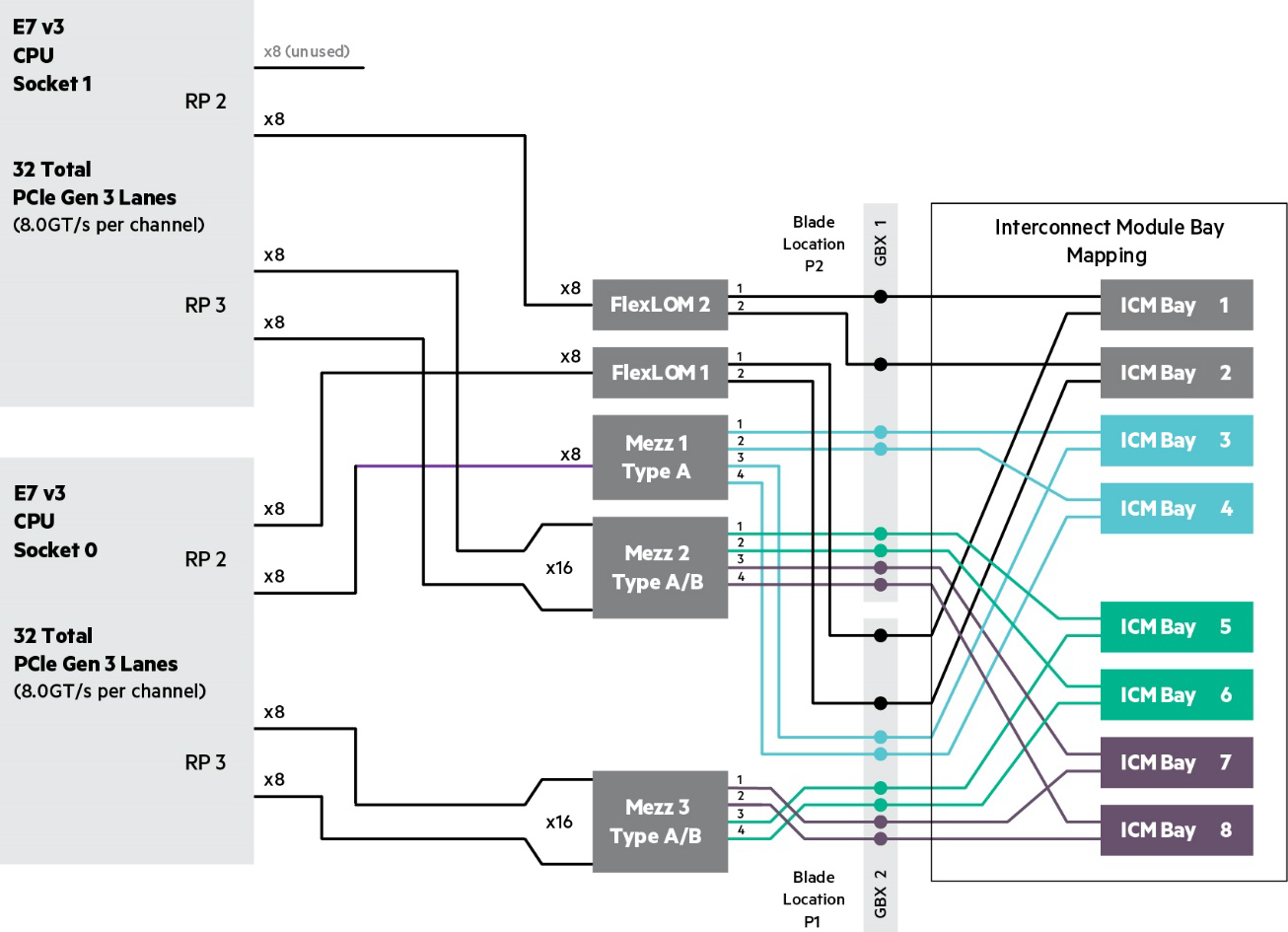
BL920s Gen9 Server Blade I/O Subsystem
Наша тестовая сборка: Integrity Superdome X, 8 x Intel Xeon E7-2890 v2, (15c / 2.8 GHz / 37.5 M / 155 W), ОЗУ
2048 GB (64 x 32 GB PC3-14900 DDR3 ECC registered Load Reduced DIMMs), Linux Red Hat 7.1, Oracle 11.2.0.4 с данными на Oracle ASM, порты 1 GbE: 4 x 1G SFP RJ45; 10GbE: 4 x 10G SFP+; 16 Gb FC: 8 x 16Gb SFP+. С ней СХД HDS VSP G1000, не менее 40K IOPS, для нагрузки, ориентированной на запись, 16 LUN по 2TB каждый, два порта по 8Gb.
Вот схема тестового стенда (часть названий замазана, это всё же банк):


Короткое резюме
x86-кластер явно может то же самое, что «тяжёлые» RISC-машины. С некоторыми особенностями, но может. Выигрыш — уменьшение итоговой стоимости владения на порядок. Ради этого стоит поковыряться и разобраться.
Да, чтобы переехать на x86, надо будет мигрировать с ОС AIX (это UNIX-подобная проприетарная операционная система) на Linux, скорее всего, в сборке RED HAT. И с одного Oracle на другой Oracle. Если для бизнеса вроде розницы это реальная сложность, то банковские коллеги восприняли всё прагматично и спокойно. И пояснили, что работа с ядром банка — это всё равно постоянная миграция с одних машин и систем на другие каждый год, и процесс не прекращается. Так что они ради той кучи денег, которую даст внедрение x86, готовы и не на такое. И с AIX на Linux они уже переходили, небольшой опыт есть. И некоторым их наследуемым подсистемам уже по 10 лет — в банке это настоящее окаменелое legacy, которое нужно поддерживать.
И поддерживают, не впервой.
Что касается нашей тестовой машины, то она пользуется дичайшим спросом. Из этого ТОП-10 банка она уже переехала в другой, где идёт похожая программа тестов. Следом — ещё один банк из десятки, а потом очередь из нескольких банков первой тридцатки. До ближайшей зимы вряд ли освободится, но ещё одна тестовая сборка есть у HPE, с ней вроде поспокойнее.
Ссылки:
- На CNEWS умными длинными словами
- Документы на Супердом: архитектура и спека Integrity Superdome X.
- Полезная ссылка — Server Performance Benchmarks — для просмотра результатов тестов и отчётов по ним для всех моделей серверов HPE. Просто выберите Superdome X и смотрите на рекордные результаты.
- Моя почта — YShvydchenko@croc.ru.
Да, решение — банк систему внедряет.
Комментарии (86)


Zifix
26.04.2016 10:03Я, конечно, далек от этой сферы, но ведь x86 уже двадцать лет как используют под капотом RISC ядро, потому ничего удивительного в возможности замены не вижу :/

Bedal
26.04.2016 11:23+1Дело, видимо, не в системе команд как таковой, а в том, что аппаратная часть по-разному работает в разных сценариях. Например, вплоть до пентиумов интеловские процессоры очень долго обрабатывали прерывания (относительно других архитектур) и это ограничивало спектр применения. Ну и так далее.



pepelac
26.04.2016 10:24+7В левом углу ринга — 120 ядер Xeon 2.8Ghz, 2Tb RAM, а в правом какие характеристики?
Sioln
26.04.2016 10:32+4Кроме того, RISC-машины лишены традиционного недостатка x86 при высокой нагрузке — у них не падает производительность при долгой постоянной нагрузке выше 70–80%.
Если это не перевод, объясните о какой особенности CPU идёт речь?pepelac
26.04.2016 10:41+1Возможно речь идёт о насыщении https://www.reddit.com/r/vmware/comments/425j0d/cpu_saturated_workload/
Sioln
26.04.2016 10:52+4Похоже на эффект гипервизора. Феномен без косяков VM имеет место быть?
Просто, если бы на домашних тачках такое происходило, наверняка бы трубили об этом.
Или фильм ты пережимаешь, у тебя estimated 1:00, а через 10 минут вдруг раз и снова 1:00. Но этого же не происходит.
svboobnov
27.04.2016 18:11Без гипервизора тоже наблюдал лично в 2009 году.
На сервер СУБД (8 ядер Intel Xeon, 16Гб ОЗУ, Win2003, MS SQL2005) около 40 минут подряд валилась нагрузка, и машина «залипла» почти намертво.
Решилось заменой на Оптероны от AMD (8 ядер, 12 Гб ОЗУ, Win2003, MS SQL 2005).
Потом, ради эксперимента, «залипавшую» машинку грузили на тестовом стенде — она так же точно залипала.DrPass
28.04.2016 08:09Мне кажется, это не особенность архитектуры x86. Это больше похоже на включение троттлинга в процессоре.

easy_john
05.05.2016 10:23+1Это особенность x86 архитектуры а не CPU.
При большой нагрузке (в unix-like осях, когда load average поднимается до 20-40 и более) производительность x86 начинает резко падать, практически эспоненциально, в то время, как на risk-архитектуре хоть и замедляется, но не сильно.
Скажем load average 60 в linux на x86 — это жестокий фриз, когда между набором даже простейшей команды типа «echo» и ее выполнением проходят десятки секунд, если не минуты, то с точно таким же load average на solaris запущенный на sparc t2000 — система оставалась отзывчивой, пользователи даже не сразу замечали, что что-то вообще не так.
> если бы на домашних тачках такое происходило, наверняка бы трубили об этом.
Ну, те, кто сталкивался — трубят. :)
> Или фильм ты пережимаешь, у тебя estimated 1:00
Пережатие фильма это один поток, он создаст load average = 1. Речь идет о случае, когда количество задач в очереди гораздо больше, чем успевает обрабатывать процессор.
nerudo
26.04.2016 10:46+8Автор упорно нигде не произносит IBM, но почему-то спалился на AIX. Может еще и на названии банка спалится? Плата ведь идет не за RISC-архитектуру — их как грязи сейчас везде, а за отработанные решения известного производителя. Если банку по силам сгородить свой собственный велосипед (или купить чей-то сторонний) из x86, linux и т.п. — флаг в руки.

nonname
26.04.2016 11:05+1Да все же просто, пока был старый курс всех устраивали решения от IBM, но времена поменялись и банки, посчитав разницу в цене, уходят в x86, что не удивительно.


teemour
26.04.2016 11:18+4… у них не падает производительность при долгой постоянной нагрузке выше 70–80%
… потому что боевого применения в системах ядра ей нет
… пределы увеличения мощности из-за больших издержек на перетаскивание данных между ядрами
… поскольку и архитектура куда менее «шаманистая»
что это вообще значит?Shvydchenko
26.04.2016 13:54В 2011 году скорее всего был HP Superdome на процессорах Itanium, а это другая архитектура и условия. Они закономерно проигрывали IBM + AIX.
Никто и не говорит, что идентичные конфигурации (одинаковое количество памяти и ядер) IBM p-series и HP SDX результаты. Речь идет о соотношении цена/качество, можно добиться сопоставимых и даже лучших результатов за существенно меньшую стоимость.
zxweed
26.04.2016 11:18А чего oracle exadata смотреть не стали?
Shvydchenko
26.04.2016 13:46Смотрели, но под другие задачи. У oracle exadata есть ограничения по возможности работать с продуктами не Oracle.
adsm
26.04.2016 11:23+4Автор,
а залицензировать Oracle 120 ядер x86 сильно дешевле 60-и паверных ядер?inbox101
26.04.2016 12:46+2Одинаково, у х86 коэфициент 0.5, у Power 1. Собственно в Oracle же не дураки маркетингом занимаются, как только ядро х86 догонит ядро Power у него тоже коэф. станет 1 :)
Shvydchenko
26.04.2016 13:55Стоимость лицензирования одинаковая. Коэффициент на ядро для HP SDX – 0,5, для IBM Power – 1. Учитывая двухкратное количество ядер для HP SDX, получается то на то.
Kan70
26.04.2016 11:24+8Имел несторожность поучаствовать в банковском проекте в 2011 где в качестве основного сервера базы данных был HP Superdom, HP Unix, Oracle.
Удовольствие неописуемое, когда на закрытии дня (а иногда это надо делать в разгар уже следующего открытого дня) десятки длинных отчетов просто забивали CPU на 100% (это не блокировки БД) и дальше все прочие короткие транзакции от онлайн-пользователей вставали в очередь (таких было около 4000, активных сессий одномоментно около 100). Рядом была инсталляция где на риск-процессорах и солярисе от фуджитсу-сименс работала еще более нагруженная система такой же конфигурации и никаких проблем такого рода не было. Т.е. при наличии длинных транзакций в сессиях, короткие транзакции успешно проходили. Выяснилась закономерность — как только количество транзакций превышало количество ядер, то система начинала страшно тупить. В отличие от риск и соляриса не было квантования времени между сессиями и дальше начинался массовое зависание.и вся эта конструкция умирала по CPU. Закончилось все приобретением сервера от IBM на AIX, а эта конструкция на HP SuperDom стала тестовой средой банка, т.к. нарастить количество ядер в той версии уже было невозможно. Так что оно может быть и экономия, но мой личный опыт показывает, что тогда надо покупать с большим запасом по сравнению с конфигурациями на RISC.teemour
26.04.2016 12:01+5я далёкий от реалий такого стека человек, поэтому мне непонятно почему весь этот конгломерат технологий сводят к разнице в архитектуре процессоров, как так получается? действительно ли risc/x86 определяет все важные показатели
mousus
26.04.2016 12:30+1В отличии от x86 ширпотреба при проектировании новых процессоров sparc часть инструкций ответственных за шифрование и sql реализована прямо в железе процессора, что сильно дороже и не нужно к примеру геймерам. Потому и работает быстрее, плюс почитайте историю самого Оракла — они исторически не на x86 разрабатывались, работали и оптимизировались по производительности.
teemour
26.04.2016 12:44про тестирование и оптимизацию понятно,
про инструкции непонятно — что, поэтому планирование обработки транзакций не такое удачное?
xaoc80
26.04.2016 12:58+4Прошу прощения заранее за, может быть, некорректный вопрос. Не подскажите, что за sql инструкции в железе в sparc реализованы?
mousus
26.04.2016 14:17+1Недавно статьи на Хабре Оракл выкладывал с презентацией новых процессоров и серверов с этой особенностью, вот первоисточник:
https://www.oracle.com/servers/sparc/resources.html#reports
http://www.oracle.com/us/products/servers-storage/sparc-m7-processor-ds-2687041.pdf
The SPARC M7 processor incorporates 32on-chip Data Analytics Accelerator(DAX) engines that are specifically designed to speed up analytic queries.
The accelerators offload query processing and perform real-time data decompression, capabilities that are also referred to as SQL in Silicon.
With such query acceleration, Oracle Database 12c delivers performance that is up to 10 times faster compared to other processors.

imotorin
27.04.2016 18:33вот ещё
What Is the SPARC M7 Data Analytics Accelerator?
https://community.oracle.com/docs/DOC-994842

tzong
26.04.2016 12:37В 2011-м не существовало Superdome X, о котором в статье. HP-UX на архитектуру x86 не портирован и вряд ли будет.
slevir
27.04.2016 18:12Осторожный вопрос — а каким образом архитектура процессора связана с планированием задач, которым по идее должна заниматься ОС? Ну т.е. может быть проблема на самом деле была в HP Unix, а не в х86?

f1inx
27.04.2016 18:43Цена контекст свича, в которую входят как минимум следующие факторы: interrupt latency, аппаратная поддержка HT/SMP/NUMA, особенности MMU, доступность управления кэш памятью и ее архитектура, цена обработки исключений, реализации атомарных операций на разных архитектурах существенно отличаются.
OS конечно тоже накладывает дополнительные ограничения например может не использовать большие страницы изза чего больше поток мета информации для поддержки многозадачности и как следстви более долгое переключение между задачами или в случае худшей чем O(1) возможности масштабирования подсистем упираться в это на определенных задачах, неправильно управлять ресурсами, что ведет к низкой эффективности использования их ПО.

impetus
26.04.2016 11:30По тексту статьи выходит, что как бы х86 они за рубли покупают, в отличие от долларовых АРМов?

Arrest
26.04.2016 11:32+1Подождите-ка. Как это железо может быть крупносерийным, если фабрики и чипсеты XNC2 — это местное решение на своих ASIC?
Shvydchenko
26.04.2016 13:56Речь идет нет только о чипсетах, это частный случай. Кроме чипсетов, используется большое количество типовых комплектующих, например процессоры Intel. А в мире HP SDX, как и другие большие сервера, не штучный продукт.

omegicus
26.04.2016 12:01+4Бред (не статья, а предубеждение). x86 по определению мощнее любой другой архитектуры.
1: x86 — это уже очень давно RISC, просто с программной вшитой прослойкой трансляции команд новых.
2: «производительность уменьшается при долгой нагрузке» — это где и это как вообще? может если у человека своп используется разве, других перспектив для реализации данного утверждения не вижу
3: 5Ghz RISC и 2 по 2.5 GHz x86 — вы меня извините, но это несравнимые величины. 1Ghz x86 — это намного больше операция чем любой 1GHz любого RISC (тот же ARM в мобильных). Поэтому странно слышать о замене 5GHz RISC на столько же гигагерц ARM.
Может дело в корявости ПО\программистов просто?
Pinkkoff
26.04.2016 13:40+6Простите за вопрос, а вы хорошо знаете предмет?
После слов про мощность x86 > RISC, а также после сравнение ARM и RISC от IBM я сильно в этом засомневался.omegicus
26.04.2016 13:42доказывать не хочу, но знаю неплохо.
в последнем предложении опечатался, про замену, имел ввиду конечно же на x86. @Поэтому странно слышать о замене 5GHz RISC на столько же гигагерц X86.@
и да, опять утверждаю, что x86 намного более производителен (я не о тактах, а о производительности), чем любой ARM\MIPSPinkkoff
26.04.2016 17:52+2и да, опять утверждаю, что x86 намного более производителен (я не о тактах, а о производительности), чем любой ARM\MIPS
Тут я даже спорить не стану, все верно. Только в статье IBM Power, а вы про ARM. Это более чем не одно и то же.
f1inx
27.04.2016 18:12+1Как вы измеряете производительность на каких задачах?
На каких алгоритмах?
Сколько по вашему у X86 регистров?
А у RISC/MISC (ARM/PPC/MIPS/Z/68K/SPARC/ALPHA/PARISC) и на что это влияет?
С какими архитектурами из этих вы знакомы как эксперт? Чем SMP отличается от NUMA? Как на них устроены/реализованы ALU? Cache? MMU? Data reader Data Writer? Атомарные операции? Какие доступны возможности управления этим (cache, mmu, data reader/writer)? Какие операции могут быть условны? И как это влияет на производительность?
Сколько тактов выполняются операции LD/ST, сравнения, условных переходов? Какие возможности SIMD? Какие на них C/C++ ABI? Как ABI влияет на производительность?
QMaster
27.04.2016 18:12+1Предлагаю загуглить какие еще, кроме ARM, существуют RISC-процессоры, и какие из них ставит в свои машины IBM. Сразу уменьшится пафосность первого предложения и п.3
mousus
26.04.2016 12:23+2позиция оракла, официальная, которую они нам рекомендовали:
sparc (серверы Sun) + solaris + Database 12c или на худой legacy случай 11g
или
x86 (серверы Exalogic) + OEL (UEK + RedHat) + Database 12c или на худой legacy случай 11g
всё остальное Оракл прямым текстом не рекомендует и фактически отказывается сопровождать при проблемах с производительностью.
AIX при проблемах производительности они кстати тоже нехотя поддерживают, не рекомендуют, и ни какой сверх производительности не гарантируют.
несколько вопросов к авторам:
Почему был выбран огород из официально не рекомендованных версий дистрибутивов ОС и железа на которых не гарантируется максимальная производительность?
Почему не был применён официально рекомендованный Ораклом InfiniBand?
Зачем был выбран медленный Fiber Channel в свете предыдущего вопроса?
В вашей инсталляции Database на голом железе без виртуализации?
Что в вашей схеме делают 1 Гигабитные сетевые подключения? Почему не 10G?
inbox101
26.04.2016 12:44Гигабиты там встроенны, а фразу «10GbE: 4 x 10G SFP+» вы не заметили?
mousus
26.04.2016 14:25+1Если внимательно изучить схему, то видно что платформа возможно этими 10 гигабитными портами и подключается к основному коммутатору, но дальше идёт чистый гигабит по схеме, вот этот момент и настораживает, особенно в резрезе связи с аналитическим сервером, это бутылочное горлышко для любой аналитики, которая при своей работе существенно нагружает канал к серверу БД, особенно если отчёты смотрят тысячи пользователей. Даже если запросы однотипные, лежат в кеше и оттуда же сервером БД и отдаются.
Pinkkoff
26.04.2016 13:42Еще бы, как же иначе, ведь они продают это железо. Странно, если бы они его не предлагали всем подряд.
С каких пор FC стал медленным? Много вы знаете внедрений IB в качестве транспорта систем хранения данных?mousus
26.04.2016 14:09Ну как сказать, давайте сравним 4 гигабита на канал и 40 гигабит на канал…
Рекомендую (но не рекламирую !) вам изучить архитектуру полношкафного решения exalogic в котором IB основной транспорт между диском, серверами БД и приложений.Pinkkoff
26.04.2016 18:02+2в статье нашел упоминание про 16Gb FC. 16Gb можно более чем сравнивать с 40Гбит.
А еще я вам один секрет скажу, сейчас никто (почти) не покупает даже 16Gb FC (хотя уже вышел 32Gb), потому что пропускная способность канала значит не так много, когда транспорт построен грамотно. Так как для всех подключений стораджа к серверам используется multipathing, то это минимум 2, а обычно 4 линка, то есть 32Gb.
Я знаю ооочень маленькое количество массивов, которые способны выдать такой поток данных и не умереть. Это High-end массивы, которые обычно подключаются гораздо бОльшим числом линков.
Так что все эти 40Gb — далеко не показатель.
SemperFi
26.04.2016 19:04… только реальная, а не маркетинговая, характеристика, которая отделяет top mid-range от Hi-End массивов — это возможность подключения по FICON.
Pinkkoff
26.04.2016 19:35я поклонник мнения, что Hi-end массивы отделяются от midrange надежностью, внутренней архитектурой. Но в сообщении выше top of mid-range я тоже отнес к категории Hi-end.
Ficon почти мертв и скоро совсем не останется таких массивов=)SemperFi
27.04.2016 11:53«FICON почти мертв»… а еще «FС почти мертв», и «HDD почти мертв»… вспоминая из своей молодости — «панк не мертв, он всегда так пахнет».
со всем уважением к вашему мнению, hi-end СХД — это то, что может работать с мейнфреймами, в таком случае кроме всех признаков (архитектура кэшей, матричная коммутация контроллеров, и пр.) явно выделяется ровно один признак — либо файкон есть, либо его нет.
например, Huawei OceanStor 18000 V3 — есть и матричная коммутация контроллеров, и инфинибэнд, и впечатляющие IOPs, и прочая прочая — но он не Hi-End.
тогда как, например — HDS G1000, он же HPE XP7 — IOPs заявлено в 4 раза меньше, чем у хуавей, но — есть FICON — и это уже Hi-End.
тот же HDS G800 — топ мидренжаPinkkoff
27.04.2016 12:23Это давний холивар, мнения по этому вопросу у каждого свое. Ваше мнение довольно распространенное, хотя его поклонников становится все меньше.
Я просто не вижу смысла выделять целый класс устройств по одному, такому незначительному признаку. Завтра какой-нибудь Huawei возьмет и добавит к своей младшей линейке поддержку FICON (ну еще пару лет потратит на сертификацию), не будем же мы S2600T называть Hi-end?
в последнее время, если смотреть на вендоров, то Hi-end оборудование часто выделяется только за счет своей цены=) Например, NetApp FAS8080 ничем архитектурно не отличается от 8020, а они называют его Hi-end.
Это уже вопрос больше религии, чем реальное разделение.
Все вышенаписанное — не более чем мои размышления. Точку зрения не навязываю, это просто мое воззрение на сегодняшний рынок СХД.
Shvydchenko
29.04.2016 14:29Позиция Oracle легко объяснима, Oracle — производитель программных продуктов в первую очередь рекомендует Oracle — производителя оборудования (серверов и СХД).
Что касается поддержки. То, что выпишите, не совсем верно — продукты Oracle официально работают и поддерживаются на множестве платформ (Linuх, AIX и т.д.), и при правильном выборе конфигурации никаких проблем с производительностью у вас не будет, а Oracle будет осуществлять полную техническую поддержку. Все остальное — это стратегия продаж: наше ПО лучше всего работает и поддерживается на нашем оборудовании.
Отказ разбираться с проблемами производительности — это достаточно стандартный случай, если вы используете мультивендорное решение. Производитель ПО будет пенять в сторону производителя железа, и наоборот.
Почему был выбран огород из официально не рекомендованных версий дистрибутивов ОС и железа на которых не гарантируется максимальная производительность?
С чего вы взяли? Полностью сертифицированная и согласованная с HP конфигурация. SDX + ОС RHEL
Выдержка из документации HP:
HPE BL920s Gen8 Server Blades
• Red Hat Enterprise Linux (RHEL)
• SUSE Linux Enterprise Server (SLES)
• Microsoft Windows Server 2012 R2 Standard and Datacenter (including Microsoft
SQL Server 2014)
• VMware vSphere 5.5 U2 and 6.0
NOTE: Please be advised there are currently no WBEM providers for VMware
running on Superdome X meaning IRS cannot report OS message traffic.
Почему не был применён официально рекомендованный Ораклом InfiniBand?
Применен где? Для подключения к SAN? В инфраструктуре заказчика не используется InfiniBand.
Зачем покупать и устанавливать специальные коммутаторы InfiniBand, подключать их к имеющемуся SAN.
Кроме того Oracle рекомендует использовать InfiniBand для определённого класса решений – облачной инфраструктуры.
Зачем был выбран медленный Fiber Channel в свете предыдущего вопроса?
Есть существующая инфраструктура, она реализована на FC. Достаточность скорости FC в реальных задачах — вопрос дискуссионный. Очень редко можно увидеть на 100% загруженный SAN.
В вашей инсталляции Database на голом железе без виртуализации?
Да
Что в вашей схеме делают 1 Гигабитные сетевые подключения? Почему не 10G?
Потому что у заказчика есть реальная сетевая инфраструктура, в которой пока активно не используется 10G. Была задача сравнить две платформы в существующем окружении.

amaksr
26.04.2016 19:23+1Из моего опыта архитектура процессора, можно сказать, вообще не влияет на общую производительность. Гораздо важнее параметрвы конфигурации дискового хранилища и роутеров для связи с этим хранилищем.
Так что статья не раскрывает полную картину.
vadimr
26.04.2016 21:22+1Я думаю, окончательные выводы можно будет делать по результатам реальной эксплуатации. x86 номинально обеспечивает гораздо лучшую производительность/стоимость, но в реальности, так как и сам Linux, и Linux в комплексе с железкой, на которой он стоит – это сборная солянка, то гораздо выше шансы напороться на хитрую несовместимость компонентов внутри системы. А потом начинается перекидывание ответственности. Но можно ли за 450 лямов решить эти проблемы? Наверное, можно.
И совсем другое дело, что известная корпорация, подразумеваемая в статье, сейчас делает всё, чтобы подорвать доверие к себе разработчиков, ликвидируя или распродавая один ключевой технологический компонент за другим.
billyevans
27.04.2016 01:34+2Я немного далек от банковской сферы, но зачем закупать такие зверские железки, а не накупить кучи обычных серваков, там по 2-4 процессора и считать в каком-нить hadoop-е, если не нужно прям сейчас это посчитать. При том как я понимаю тут нужно в основом считать, а это как раз параллелится отлично, и разница очень небольшая между процессорами последних лет 5ти. Мне не до конца ясна проблема банковкого процессина из статьи, поэтому и спрашиваю. Кажется, что не нужно такой сильно связанности между процессорами.
mousus
27.04.2016 09:27+1Это связано с природой данных и профилем нагрузки, а также с устоявшимися методами их обработки. Hadoop предназначен для решения совсем других задач, нежели отказоустойчивая онлайн репликация боевых баз в базу для хранилища, расчёта агрегатов, и онлайн аналитика для BI. Не стоит путать технологии и архитектуру для распределённых вычислений и работы с большими объёмами не структурированных данных с архитектурой для обработки больших объёмов структурированных транзакционных и партицированных массивов данных.

grigorrs
27.04.2016 18:12А почему использовали E7-2890 v2 и DDR3 вместо E7-8890 v3 и DDR4?
Сомнительная экономия: Жертва 20% производительности ради 2% денег?
Или я что-то не внимательно прочитал?
И ещё один вопрос:
Чем предложенная конфигурация лучше, чем обычные решения 4 * E7 с самым стандатным соединением по Infiniband EDR?
Это гораздо дешевле, чем предложенное в данной статье. Массштабируется в разы крупнее при практически той же пропускной способности. А уменьшение гемороя в настройке/поддержке/апгрейдах, рискну предложить, на порядок меньше будет.Shvydchenko
29.04.2016 14:31А почему использовали E7-2890 v2 и DDR3 вместо E7-8890 v3 и DDR4?
Сомнительная экономия: Жертва 20% производительности ради 2% денег?
В данном случае нельзя судить о такой экономии. Такова конфигурация демо-оборудования, которое можно было заказать осенью 2015г.
По результатам тестирования заказчик, естественно, может заказать E7 v3 и DDR4.
Чем предложенная конфигурация лучше, чем обычные решения 4 * E7 с самым стандатным соединением по Infiniband EDR?
Абсолютно другие задачи. Решения Infiniband EDR предназначены для организации облачной инфраструктуры, повышения его сетевой производительности.
Можно соединить по Infiniband 4 сервера на процессорах E7, установить на каждый ОС и распределить между ними задачи или запустить несколько приложений, но нельзя собрать один большой 120 ядерный сервер для работы с большой БД. По настройке/поддержке сложно сказать что-то, т.к. пока нет опыта по эксплуатации Infiniband EDR от Oracle, система не так давно анонсирована.
adsm
27.04.2016 18:12А что тестировали в такой сборке, имея на бэк-енде MSA2040?)
grigorrs
27.04.2016 23:01Если вопрос ко мне, то у нас back-end на дешёвой супермикре по infiniband, а не HP по FC ни разу.) VMware + Oracle трудятся под наши задачи великолепно. Чего там тестировать? Тысячи раз протестированный ширпотреб. Запустил и работает...)
Shvydchenko
29.04.2016 14:32MSA2040 используется для операционной системы. Данные для тестирования находились на Hi-end массиве, подключенному по FC.

bzzz00
29.04.2016 18:31«Кроме того, RISC-машины лишены традиционного недостатка x86 при высокой нагрузке — у них не падает производительность при долгой постоянной нагрузке выше 70–80%» — поясните этот бред, пожалуйста?
impetus
А объясните чайнику — банки вроде не вчера появились — неужто у них объём вычислений растёт быстрее Мура? Что за 10 последних лет, что за полвека? Вот 20-30 лет назад как они справлялись?
DrPass
Объем транзакций растет, растет количество оборудования, регулярно добавляются новые клиентские сервисы. Масштабируемость, кстати, нифига не линейная. Т.е. если банк, у которого количество терминального оборудования (банкоматы, киоски, POS-терминалы) пять лет назад составляло 1000 единиц, в этом году увеличил его до 5000 единиц, то вычмощности ему надо увеличивать не в 5 раз, а, грубо говоря, в 15 раз. И так далее.
Что касается RISC vs x86, ну, тут никаких чудес нет. Просто давно не секрет, что в стоимости больших черных коробок с надписью IBM ***Series и им подобных прячется очень-очень неплохая маржа производителя :) Дело же не в архитектуре, а в покупательной способности участников рынка, на который она ориентирована.
impetus
А, да, теперь же по карточкам в любом супермаркете… не_подумал-не_связал, что это на те же ВЦ выходит
(кстати, ну зачем эту аббревиатуру «ЦОД» ввели, когда было же вполне достаточное для этого понятие «ВЦ» (вычислительный центр)