Привет всем.
Мы классический web 2.0 сайт сделаный на Drupal. Можно сказать, что мы медиа сайт, т.к. у нас очень много всевозможных статей, и постоянно выходят новые. Мы уделяем много внимания SEO. У нас для этого даже есть специально обученные люди, которые работают полный рабочий день.
К нам заходит более 400k уникальных пользователей в месяц. Из них 90% приходит из поиска Google.
И вот уже почти полгода мы разрабатывали Single Page Application версию нашего сайта.
Как вы уже наверное знаете, JS это вечная боль сеошников. И нельзя просто так взять и сделать сайт на JS.
Перед тем как начать разработку мы начали исследовать этот вопрос.
И выяснили, что общепринятым способом является отдача google боту уже отрисованой версии страницы.
Making AJAX applications crawlable
Также выяснилось, что этот способ более не рекомендуется Google и они уверяют, что их бот умеет открывать js сайты, не хуже современных браузеров.
We are generally able to render and understand your web pages like modern browsers.
Т.к. на момент принятия нашего решения Google только-только отказались от подобного метода, и еще никто не успел проверить как Google Crawler на самом деле индексирует сайты сделаные на JS. Мы решили рискнуть и сделать SPA сайт без дополнительной отрисовки страниц для ботов.
Зачем?
Из-за неравномерной нагрузки на сервера, и невозможности гибко оптимизировать страницы, было решено разделить сайт на backend (текущая версия на Drupal) и frontend (SPA на AngularJS).
Drupal будет использовать исключительно для модерации контента и отправки всевозможной почты.
AngularJS будет рисовать все что должно быть доступно пользователям сайта.
Технические подробности
В качестве сервера для frontend было решено использовать Node.js + Express.
REST Server
Из Drupal сделали REST сервер, просто создав новый префикс /v1/т.е. все запросы приходящие на /v1/ воспринимались как запросы к REST. Все остальные адреса остались без изменения.
Адреса страниц
Для нас очень важно, чтобы все публичные страницы жили на тех же адресах, как и раньше. По этому мы перед разработкой SPA версии структуризировали все страницы, чтобы они имели общие префиксы. Например:
Все forum странички должны жить по адресу /forum/*, при этом у форума есть категории и сами топики. Для них url будет выглядеть следующим образом /forum/{category}/{topic}. Не должно быть никаких случайных страниц по случайным адресам, все должно быть логично структурированно.
Redirects
Сайт доступен с 2007 года, и за это время очень многое изменилось. В том числе адреса страниц. У нас сохранена вся история, как страницы переезжали с одного адреса на другой. И при попытке запросить какой-нибудь старый адрес вы будете переправлены на новый.
Для того чтобы новый frontend также перенаправлял, мы перед отрисовкой страницы в nodejs отправляем запрос обратно в Drupal, и спрашиваем каково состояние запрашиваемого адреса. Выглядит вот так:
curl -X GET --header 'Accept: application/json' 'https://api.example.com/v1/path/lookup?url=node/1'На что Drupal отвечает:
{
"status": 301,
"url": "/content/industry/accountancy-professional-services/accountancy-professional-services"
}После чего nodeJS решает оставаться на текущем адресе, если это 200, либо сделать редирект на другой адрес.
app.get('*', function(req, res) {
request.get({url: 'https://api.example.com/v1/path/lookup', qs: {url: req.path}, json: true}, function(error, response, data) {
if (!error && data.status) {
switch (data.status) {
case 301:
case 302:
res.redirect(data.status, 'https://www.example.com' + data.url);
break;
case 404:
res.status(404);
default:
res.render('index');
}
}
else {
res.status(503);
}
});
});Images
В контенте приходящем с Drupal могут присутствовать файлы, которые не существуют в frontend версии. По этому мы решили просто стримить их с Drupal через nodejs.
app.get(['*.png', '*.jpg', '*.gif', '*.pdf'], function(req, res) {
request('https://api.example.com' + req.url).pipe(res);
});sitemap.xml
Т.к. sitemap.xml постоянно генерируется в Drupal, и адреса страниц совпадают с frontend, то было решено просто стримить sitemap.xml. Абсолютно также как с картинками:
app.get('/sitemap.xml', function(req, res) {
request('https://api.example.com/sitemap.xml').pipe(res);
});Единственное на что стоит обратить внимание, это на то чтобы Drupal подставлял правильный адрес сайта, который используется на frontend. Там есть настройка в админке.
robots.txt
- Доступный для google crawler bot контент не должен дублироваться между нашими двумя серверами.
- Весь запрашиваемый через frontend у Drupal контент должен быть доступен для просмотра ботом.
В результате чего наши robots.txt выглядят следующим образом:
В Drupal запретить все кроме /v1/:
User-agent: *
Disallow: /
Allow: /v1/В frontend просто разрешить все:
User-agent: *Подготовка к релизу
Перед релизом мы поместили frontend версию на https://new.example.com адрес.
А для Drupal версии зарезервировали дополнительный поддомен https://api.example.com/
После чего, мы связали frontend чтобы он работал с https://api.example.com/ адресом.
Релиз
Сам релиз выглядит как простая перестановка местами серверов в DNS. Мы указываем наш текущий адрес @ на сервер frontend. После чего сидим, и смотрим как все работает.
Тут стоит отметить, что если использовать CNAME записи, то замена сервера произойдет мгновенно. Запись A будет рассасываться по DNS до 48 часов.
Производительность
После разделения сайта на frontend и backend нагрузка на сервер стала размеренной. Также стоит отметить, что мы особо не оптимизировали sql запросы, все запросы проходят сквозь без кеширования. Вся оптимизация была запланирована уже после релиза.
У меня не осталось метрики до релиза, зато есть метрика после того как мы откатились обратно :)
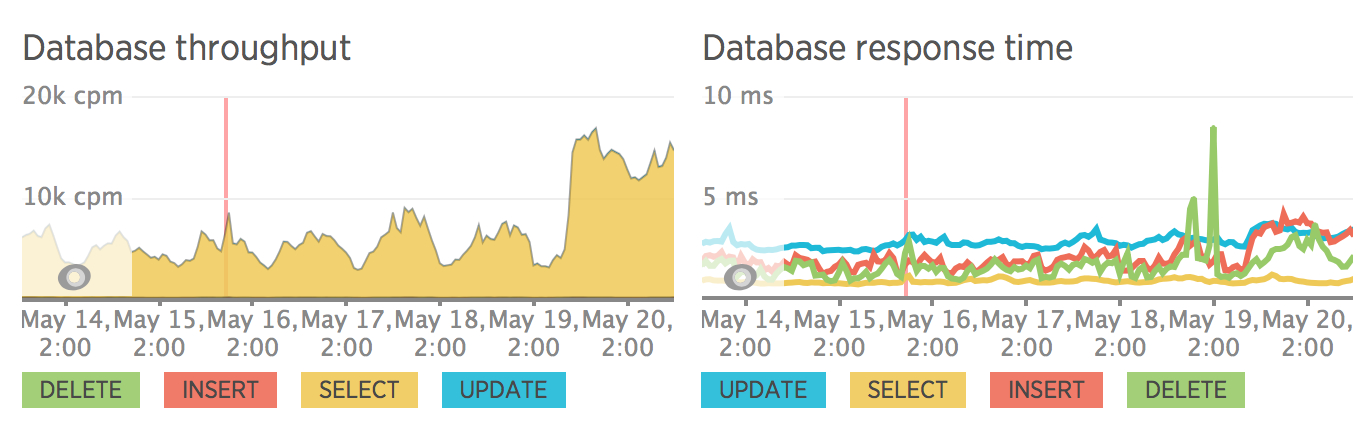
Web transactions response time

Throughput

Top 5 database operations by wall clock time
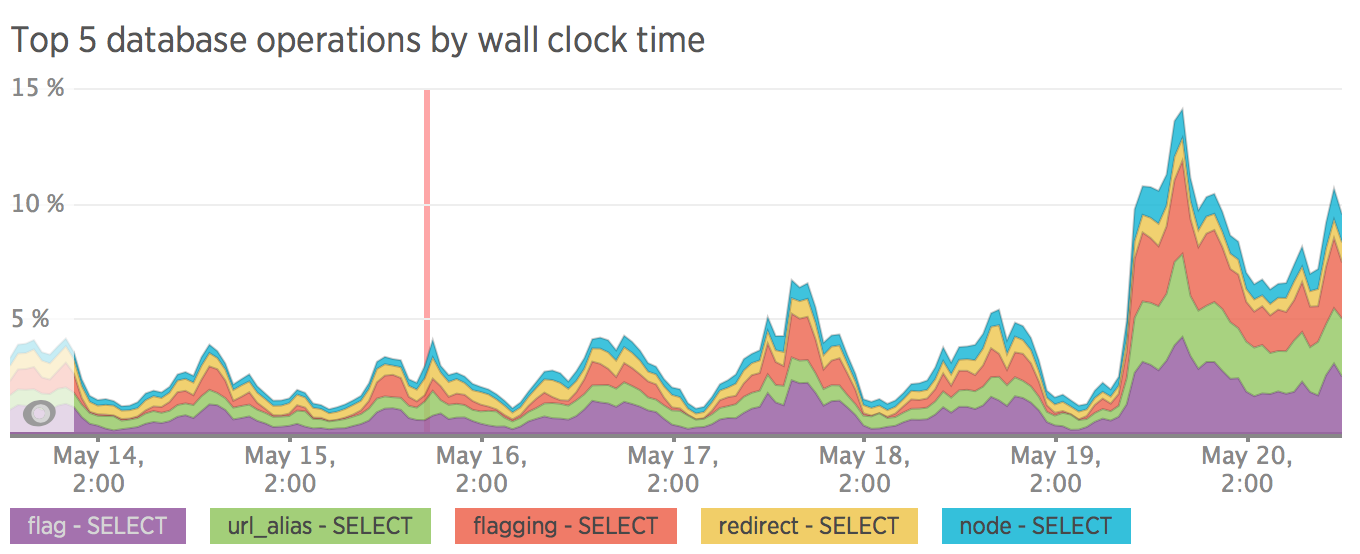
Database
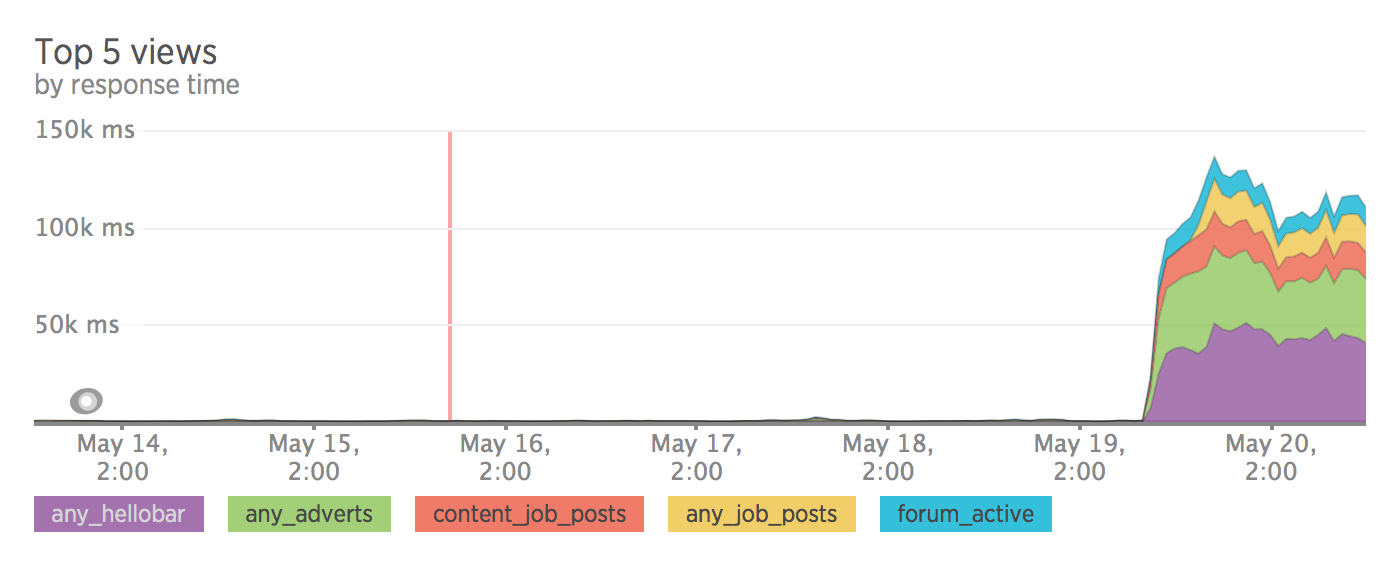
Views usage
SEO
Вот тут все оказалось не так хорошо, как хотелось бы. После чуть более недели тестирования трафик на сайт упал на 30%.

Какие-то страницы выпали из индекса google, какие-то стали очень странно индексироваться, без meta description.
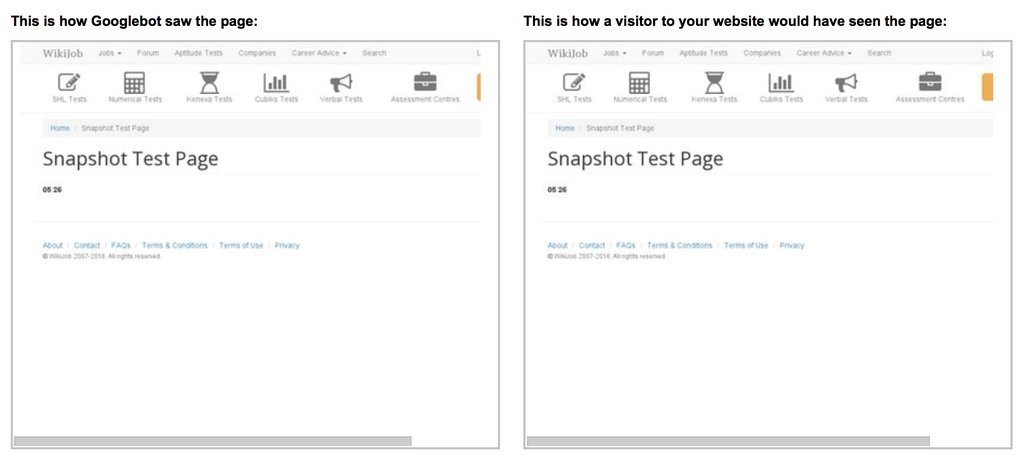
Пример того, как Google проиндексировал вот эту страницу.

Результат / Выводы
Из-за проблем с индексированием было принято решение откатиться назад на Drupal, и думать что мы сделали не так.
Все усложняется тем, что google является некой черной коробкой, которая если что-то идет не так просто удаляет страницы с индекса. И любые наши эксперименты требуют пары дней, чтобы это отразилось на результатах поиска.
Одной из более вероятных версий является то, что у Google Crawler есть определенные ограничения. Это может быть память, либо время отрисовки страницы.
Я сделал небольшой тест, создав страницу с секундомером, и попробовал отрисовать ее как crawler в Google Search Console. На скриншоте секундомер остановился на 5.26 секундах. Думаю crawler ждет страницу около 5 секунд, и потом делает снапшот, а все что загрузилось после — в индекс не попадает.
Полезные ссылки
Update
- Добавил график из google analytics показывающий на как просел трафик.
- Выяснил, что Google Crawler имеет около 5 секунд на отрисовку страницы.
Комментарии (91)

mannaro
20.05.2016 19:00А, собственно, в чем проблема сделать SSR на NodeJS? Берем phantomjs, и если в адресе есть _escaped_fragment_=, то прогоняем текущий адрес через phantomjs, убираем оттуда все JS скрипты и выдаем гуглу/яндексу/etc. Это же работы на час, максимум?

mrded
20.05.2016 19:03+3У нас проблемы нету. Просто Google больше не рекомендует этот способ.
mannaro
20.05.2016 19:06-3Ну так можно же сделать SSR, а когда гугл научится окончательно хавать SPA, то убрать?
Или, как сделали мы, просто выдаем гуглу и компании голую страничку, со всеми данными, которые надо скормить поисковику. Да и вид можно сделать такой, чтобы поисковик доволен остался.
А рекомендует это гугл или нет, это не важно, пока это работает.mrded
20.05.2016 19:14+8Google также штрафует за то что для клиента и для бота отдаются две разные версии страницы. Зная то что Google более не рекомендует способ отрисовки отдельных страниц для бота, он может в один день начать штрафовать за это.
Как я уже сказал ранее, мы решили не делать SSR не потому что мы не можем, а по тому что Google сам отказался это этого метода. И мы решили попробовать скормить наш сайт без SSR. И выяснили что на сегодняшний день лучше все-таки использовать SSR.mannaro
20.05.2016 21:10-3Ну у нас задачи немного разные :) Мы делали это больше для соц. сетей, нежели для гугла. А так, да. Отдаем лендинг как HTML страничку, без всяких там SPA.
mrded
21.05.2016 02:52-1На сколько мне известно, Facebook не понимает JS, и для него нужно дополнительно отрисовывать странички.

miolini
20.05.2016 22:46+3Разве отдача разного контента для разных User-Agent не считается клоакингом?

vintage
21.05.2016 00:36Не для разных User-Agent, а для разных
_escaped_fragment_=. Мы так делали, всё отлично индексируется разными поисковиками. Более того, сайт давно мёртв, а ссылки всё ещё в индексе :-)
PSDCoder
21.05.2016 13:41+2В статье упомянуто об этом способе, а заодно указана ссылка на спеку в которой говорится что данный метод deprecated.
vintage
21.05.2016 13:58-4И что? Он как работал так и будет работать. Причём работает он не только с гуглом. А если гугл когда-нибудь и выпилит его поддержку — ничего не сломается.
PSDCoder
21.05.2016 14:06Да собственно ничего)
У меня есть сайт на angular работающий на данном способе. Но сейчас, с приходом react'а, я предпочитаю пререндерить страницу не только для SEO, но и для пользователей (что имеет свои плюсы). При этом например метод с _escaped_fragment_ не понимали боты соц. сетей и для них приходилось городить определение по user-agent'у на уровне nginx'a и перенапрявлять на тот же _escaped_fragment_.
В общем я за простоту, особенно если спека помечена как deprecated)

J_K
21.05.2016 01:19+5Полезная, правильная статья. Человек описал свой опыт, явно неудачный. Тема важная. Очень хотелось бы получить комментарий от представителей гугла, иначе, к сожалению, так и остается непонятным, как же все-таки правильно отдавать результат поисковику.
vintage
21.05.2016 02:05+2https://webmasters.googleblog.com/2015/10/deprecating-our-ajax-crawling-scheme.html
Кроме того, не стоит забывать, что гугл — не единственный поисковик.
mrded
21.05.2016 02:15Для нас — единственный. Суммарный трафик со всех остальных поисковиков менее 1%.
J_K
21.05.2016 02:15Спасибо за ссылку. Да, это верно насчет гугла. Но все-таки это какая-то, извините, лажа получается. Допустим, я делаю одностраничный сайт, наполнение которого в браузере происходит ТОЛЬКО за счет JS. Ну как с ангуляром, загружаем данные, обновляем модель. Но вот же ж — поисковики не могут все это прочитать. И что тогда, вся эта прекрасная технология MVVM псу под хвост, потому что надо чтобы сайт индексировался или же приделывать какие-то костыли в виде дополнительного рендеринга только для поисковиков?
mrded
21.05.2016 02:30+1Тут важно все разбить на страницы. Чтобы определенный контент показывался по определенным страницам.
Если все будет в одной куче — Google Crawler не поймет как это индексировать.
summerwind
21.05.2016 02:50{
«status»: 301,
…
}
Зачем этот костыль? Есть же стандартные коды состояний HTTP.mrded
21.05.2016 02:54Это не костыль, а статус запрашиваемой страницы. Я у backend спрашиваю состояние страницы, и он мне отвечает. Если backend мне вернет 503 — это будет означать что backend мертв, а не запрашиваемая страничка мертва.
mrded
21.05.2016 03:02Если не понятно — могу подробнее объяснить.
summerwind
21.05.2016 03:56+2Если честно, больше всего мне непонятно, зачем вообще в этой схеме nodejs. Только для того, чтобы отдавать стартовый index.html и редиректить?
mrded
21.05.2016 11:33Для того чтобы отрабатывать редиректы, 404 и стримить недостающие файлы с бэкэнда.

Dreyk
21.05.2016 11:34все это может продолжать делать друпал в режиме апи
mrded
21.05.2016 11:43+1Нет, не может.
- У друпала слишком медленная инициализация, для того чтобы просто вернуть статику.
- Я не могу перегружать существующие адреса, т.к. они используются для модерации контента.
summerwind
21.05.2016 16:14+2Почему не делать отдачу статики и редирект со старых роутов на новые через nginx?
Dreyk
21.05.2016 11:33я вот тоже не понял, вначале подумал, что фронтенд полностью независим от друпала, у них просто общая база, но потом увидел, что весь контент все же отдает друпал через апи. В таком случае для Angular хватило бы просто статической странички в паблик-папке (не знаю, как точно в друпале это сделано, думаю, так же как и у всех остальных фреймворков)
offline15
21.05.2016 09:06Насколько я знаю, гугл хорошо умеет индексировать js сайты, но с одним условием, он не ждёт результатов ajax запросов. Поэтому если первичные данные для отрисовки любой страницы вы подтягиваете ajax'ом — гугл пройдёт мимо.
mrded
21.05.2016 11:36+1А как иначе, если не подгружать данные? Это уже не JS сайт получается.
offline15
21.05.2016 16:20данные уже нужно подгрузить вместе с хтмл и использовать в виде
<script> window.initialData = {}; </script>
Но естественно на каждую страницу не хочется в бекэнде прописывать какие данные должны быть в хтмл. Я решил эту проблему путём проверки вида запроса при обращении к странице, если запрос ajax — значит это реальный пользователь ходит туда сюда по сайту, если запрос get — значит это поисковик, соотвественно когда это поисковик, я запускаю phantomjs он идёт по этому же адресу (по user agent исключаем рекурсию) и ждём скажем 3 секунды, после этого ответ отдаём гуглу. По идее за три секунды все ajax'ы должны были отработать.offline15
21.05.2016 16:24Правда если обычный человек зайдёт сразу на внутреннюю страницу, ему придётся ждать 3 секунды. Можно попробовать по user agent гугл ботов такую логику делать.
mrded
21.05.2016 16:25+1Если данные передавать уже вшитыми в страницу, тогда эта страница будет очень долго отдаваться. Весь смысл перехода на JS пропадает.
offline15
21.05.2016 16:27Если оптимизируете SQL запросы, то оверхед не будет превышать 10мс.
mrded
21.05.2016 16:30А если все на ассемблере переписать, то ваще быстро будет.
offline15
21.05.2016 16:40+2Я описал варианты решения, вам выбирать. В любом случае я не вижу логики быстро отдавать хтмл без самих данных и ждать пока аяксом они подгрузятся. Ведь так будет ещё дольше.
mrded
21.05.2016 16:47+1Вовсе нет. Если данные отдельно подгружать, их можно закешировать как статику и положить в CDN. Что мы собственно и сделали.
В этом случае клиент практически мгновенно получает страницу, которая подгрузит данные с ближайшего географически распределенного кэша. Что также значительно снимает нагрузку с основного сервера.
offline15
21.05.2016 16:49В вашем случае тогда наверное побольше вариантов решить проблему, у меня все запросы были динамические и ничего закешировать было нельзя. Исхитрялся как мог.

storuky
21.05.2016 15:30+1Он ждет. Но робот ограничен в этом ожидании, как и в оперативной памяти. Может часть высоконагруженной страницы просто недорендерить. Или не дождаться ответа от медленного АПИ. В общем черный ящик.
mrded
21.05.2016 15:42Да, очень может быть. Мы заметили что у нас некоторые страницы попали в индекс, а некоторые нет. Вы не вкурсе какие ограничения у бота?

arusakov
21.05.2016 10:10+6Интересный опыт. Не понял только зачем гонять картинки и sitemap.xml через node.js. У вас же наверняка наружу смотрит nginx, который может это делать лучше и с помощью конфигурации, без лишних строк кода.

oe24
21.05.2016 10:23+1Что такое v1 в robots.txt?
mrded
21.05.2016 11:52Это разрешение поисковым роботам на доступ к адресам вида /v1/*
Этот префикс мы используем для REST API.
samizdam
22.05.2016 20:47+1А зачем индексировать api, это же программный интерфейс, а не человекочитаемый контент, за которым приходит гугл.
mrded
23.05.2016 10:59Если запретить api в robots.txt то Google бот не сможет загрузить данные для странички.
samizdam
23.05.2016 22:58Это проверенная информация или гипотеза?
Я вот, полагал, например, что сферический бот в вакууме, он да — при заходе на сайт ищет все ссылки и пытается их открыть, честно учитывая то что в robots.txt,
Но когда у поисковиков пошёл тренд на поведенческие факторы, SPA, AJAX и т.п. я представлял себе, что они со своей стороны открывают страницу неким юзер-агентом приближенным к полноценному, которому, разумеется до robots.txt нет дела, если часть контента получается через AJAX.mrded
24.05.2016 01:52+1Да, это проверенная информация. Google Search Console ругается на это, если заблокировать, и страницу на предпросмотре показывает без данных.

fetis26
21.05.2016 10:42Вот мы тоже повелись на это сообщение Гугла и даже проверили в Search Console что он сайт полностью показывает. А по факту оказалось, что он все равно только голый HTML индексирует. Пришлось в срочном порядке прикручивать prerender.io

catanfa
21.05.2016 10:51На каждый запрос пользователя на новую версию вы внутри делаете https запрос на старую версию, чтобы вытянуть информацию по редиректам?
При этом у вас response time для PHP в районе 70ms. Сколько времени из этого занимает https-запрос к старому бекенду за редиректом?mrded
21.05.2016 12:08Верно, каждый запрос пользователя посылает запрос на старый backend. Единственное что, первый запрос делается с node.js для того чтобы отработать HTTP status code. Остальные запросы будут уходить с клиента.
Сколько времени занимает https-запрос я сказать не могу, т.к. мы все это кэшируем в CloudFlare, и запрос на прямую не проходит. А он там уже по своему распределяет кэш по миру.

handymade
21.05.2016 11:00Статья свежая — значит самое время начать переписывать на Angular2, там с SEO в смысле сервер-сайд рендеринга все намного лучше
mrded
21.05.2016 12:09А angular 2 уже зарелизился?
soshnikov
22.05.2016 02:44Еще нет. Более того, там штатного SSR не было 2 месяца назад. Есть сторонее решение, но я его не проверял пока.
handymade
22.05.2016 19:24нет, пока в RC1. но если вы говорите что первую версию пол-года пилили, то сейчас как раз можно начинать
mrded
23.05.2016 11:02Мы ее делали на компонентах 1.5, так что мы готовимся к предстоящему обновлению. Как зарелизится 2.0 — так начнем, при условии что мы заставим Google индексировать наш контент.
Qird
21.05.2016 12:10У нас был API на php и фронтенд на ангуляре, то того момента пока это была исключительно админка для клиентов компании, вопроса о поисковиках вообще не стояло. А вот когда нужно было сделать публичный фронтенд к API, который бы индексировался поисковиками, решили сделать прототип с SSR на node.js + react.js. Суть в том что если юзер агент не может js, не зависимо от того краулер это или браузер, в котором отключили js, то все рендерится на сервере. Если же в браузере включен js, то пользователь работает с нормальным SPA.
Как результат, яндекс и гугл проиндексировали все страницы, которые предполагались. Сайтик, который строит сайтмап автоматом, тоже без проблем это прожевал.
За основу для прототипа брали вот эту репу github.com/erikras/react-redux-universal-hot-examplemrded
21.05.2016 12:10А как вы в версии без JS сделали авторизацию?
Qird
21.05.2016 14:43+1Вопрос интересный ) На самом деле в прототипе пока никак, и не уверен что мы это будем делать, т.к. все-таки не предполагается что юзер будет полноценно работать с выключенным JS. Но если это очень надо, то ведь сабмит формы работает и без JS, так что я думаю особых проблем тут не будет.
mrded
21.05.2016 14:59Тогда придётся поддерживать две версии сайта, с JS и без. Для сабмитов надо будет ещё второстепенные страницы создавать.
fetis26
23.05.2016 13:59А как вы определяли на уровне запроса идет он с js или без?
Qird
24.05.2016 09:08Если запрос пришел на бэк node.js, то значит у клиента нет js (или это первое обращение к сайту), рендерим все на сервере (используя нужные данные от API) и отдаем. Если же у клиента есть js, то все запросы будут уходить с фронта сразу к API, минуя бэкенд на node.js
vintage
24.05.2016 09:42NodeJS у вас выполняет презентационную функцию, а значит является фронтендом. А вот то, что вы называете "API" — и есть бэкенд.


avolver
21.05.2016 18:28Как вариант — можно использовать вот эту разработку для поддержания SPA и HTML-static версии: prerender.io
mihvas
22.05.2016 02:45-4Хорошая статья. Я делал сайты на Drupal и занималя изучением этого вопроса en.wikipedia.org/wiki/Single-page_application…
Потом делал А/В тестирование одиноквых по объему и контенту сайтов с нагрузкой — на Drupal и WordPress + WP Cache (minify CSS+JS) и + WP Rocket. Потом тестировал на SEO — GOOGLE PAGESPEED INSIGHTS & Pingdom. Все для потребителя как говорится, в итоге получилось на WordPress + WP Rocket все намного лучше, плагин укладывает JS в один файл прекрасно, получил 96/100 от Гугл: www.seo-website.ru/website-speed-improve Так что, вот поделился результатми, кому будет интересно, отвечу как!
questor
23.05.2016 00:09Тут стоит отметить, что если использовать CNAME записи, то замена сервера произойдет мгновенно. Запись A будет рассасываться по DNS до 48 часов.
С чего бы это? Сколько ни вдумываюсь — не понимаю, в чём эффект: у каждой записи свой TTL (который подействует при следующем обновлении), откуда же у вас уверенность, что CNAME обновляется быстрее?mrded
23.05.2016 11:20На сколько показывает моя практика, при использовании cloudflare, CNAME изменения применяются практически мгновенно, по сравнению с ALIAS. При открытой консоли приложения, можно увидеть что пользователи перестают обращаться к сайту.
Если делать тоже самое с ALIAS, при том же TTL, то это занимает какое-то время.

yurist38
23.05.2016 11:06Лично мне статья показалась полезной в виду того, что информации по этой теме не так много. Веб приложения набирают популярность, а гугл не особо спешит их воспринимать. Сам столкнулся с этим, так пока и не нашел решения для себя. Пререндер выглядит уж больно временным решением, не хочется на нем концентрироваться. В идеале бы поторопить поисковики :) В общем спасибо за описание вашего опыта!
J_K
24.05.2016 19:42Если не секрет, какое решение вы нашли?
yurist38
25.05.2016 05:32Мой проект написан на MeteorJS (https://github.com/InstaPhobia/instaphobia.com), я поставил сео-плагин, который генерирует мета-данные для страниц. По описанию и отзывам он вроде бы должен читаться как минимум гуглом, но в итоге на данный момент гугл в поиске показывет title, а description пустой. Так что, можно сказать, что я не нашел пока решение… Но на своем опыте тоже убедился, что с обработкой поисковиками одностраничных приложений пока «все не так прозаично» (см. «Да Здравствует Цезарь»), как они утверждают…
J_K
25.05.2016 05:33Спасибо за ответ. Вот ведь фигня. Одностраничным приложениям сто лет в обед, а поисковики упорно их игнорируют.
yurist38
25.05.2016 05:37Получается, что так. Но по ощущениям, приложения должны быть еще популярнее со временем. Так что надеюсь, гугл тоже будет работать над этим. А там глядишь и Яндекс.

Steinmar
25.05.2016 09:37Учитывая тренды веб приложений, без SPA будет всё труднее обойтись, там глядишь и поисковики проснуться, начав решать нашу проблему более активно.
mrded
25.05.2016 12:27Мы тоже вставляем meta tags динамически через js. Попробуйте рисовать странички быстрее 5 секунд, я думаю это поможет.
У нас все странички рисуются одинаково, разница лишь во времени отрисовки. И какие-то страницы все-таки попали в индекс, во всеми meta tags.

mrded
Просьба к людям людям сливающим мне карму и минусующим топик, объяснить с чем связана такая реакция?
ivlis
Я не могу сказать за тех кто минусовал, я не минусовал. Но вот подумайте, о чём ваша статья. Вот мы тут делали, делали и у нас не получилось? Ну и что? В чём новизна и интерес-то?
mrded
Новизна в том, что Google официально отказались от SSR, а в интернете все еще нету никаких фидбэков на эту тему. Мы, как компания с относительно большим и серьезном сайтом, наступаем на эти грабли и даем вам фидбэк, бесплатно.
edogs
Не минусовали, но фидбэк все же хотелось бы видеть в виде «проверили, реально с яваскриптом проблема у гугла, доказано так-то так-то и так-то» или даже "(то же самое) + проблема решается так-то и так-то", а у Вас лишь «попробовали обойтись без SSR, появились некоторые проблемы, с чем связано непонятно»:)
Mugik
Спасибо за ссылку на вики, объясняющая нерадивым умам, что такое одностраничный сайт. Благодарен за полезную статью, как только будет необходимость обращаться к drupal как rest сервису..., сразу же обращусь к этой статье, прямо по шагам буду идти.
Levka9
Человек поделился своим опытом. Сегодня многие делают SPA, вот что бы они не делали таких ошибок он и написал.
Хотя согласен что не хватает продолжения и счастливого конца )
Phantaminuum
Вспомните ошибку выжившего, читать сплошные success-story не особо полезно, порой куда интересней взглянуть на тех у кого не взлетело.
Steinmar
Спасибо за интересный фидбек. Гугл вообще ведёт себя непонятно, сначала они выпускают фреймворк для того что бы на нём что то пилили, а потом своим алгоритмом индексирования — убивают весь смысл использовать его для создания сайтов требующих SЕО. Тоесть по факту дла SPA остаються только админки, приложения на phoneGap и какие то комерческие системы чисто для автоматизации внутренней кухни у коркретных заказчиков. Можно конечно не смотря ни на что — делать сайты на ангулялре, но я ещё не видел людей которые были готовы вот так вот пожертвовать SEO ради того, что бы сайт был SPA.
istinspring
Prerender.io наверное дешевле выйдет чем откат назад.
mrded
Откат назад, в нашем случае, это просто перемена адресов в DNS. Мы предполагали что надо будет откатываться назад.